Esta vez, nuestro proyecto utiliza el servidor Alibaba Cloud y las siguientes tecnologías y protocolos de marco para el análisis de datos:
- HDFS
- Colmena
- Chispa SQL
- zepelín
Por supuesto, también podemos usar los datos limpiados por la base de datos, usando
1. Cuadro
2.Python+echarts+interfaz web
3. Tencent Cloud, informe de inteligencia de negocios de Alibaba Cloud
4. Por supuesto, también podemos usar tablas dinámicas de Excel y gráficos dinámicos para hacer
En primer lugar, la configuración de la máquina virtual en el servidor de la nube
1.Configuración de Hadoop
Consulte el siguiente blog para configurar el entorno pseudodistribuido de hadoop en centos7.2 del servidor Aliyun.
Creación de bajo centos7.2 del servidor en la nube de Alibaba.un entorno :
Asegúrese de prestar atención: ¡entorno de configuración de Java! ! !

¡Evite que Hadoop encuentre Java!
2. Configuración de la base de datos MySQL
Consulte el siguiente blog
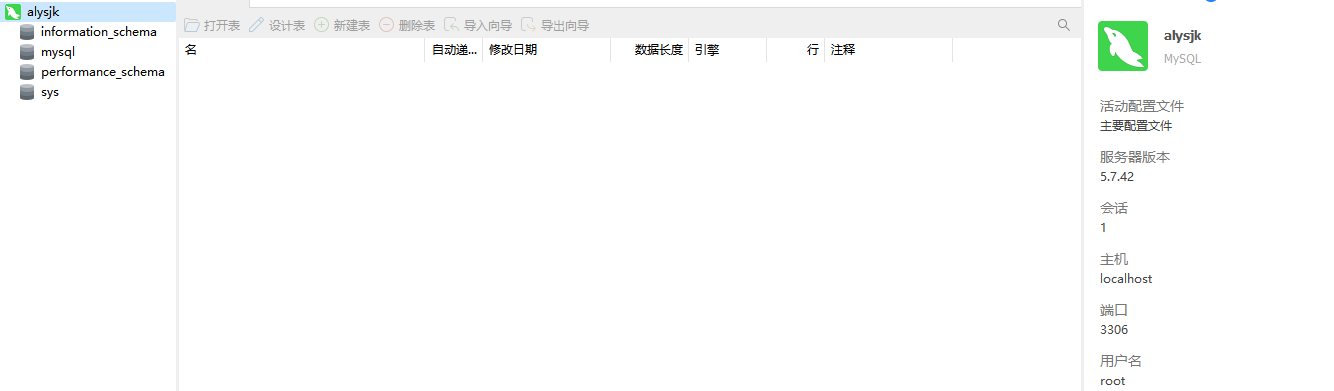
Use servidorNavicat para conectarse a la base de datos MySQL en el
3. Instalar la configuración de colmena
En el directorio local
wget https://mirrors.aliyun.com/apache/hive/hive-3.1.2/apache-hive-3.1.2-bin.tar.gzDescomprima el paquete tar en /usr/local/el directorio y cámbiele el nombre a hive:
tar -zxvf apache-hive-x.y.z-bin.tar.gz
mv apache-hive-x.y.z-bin hive
Configurar variables de entorno
Agregue lo siguiente al ~/.bashrco :/etc/bashrc
export HADOOP_HOME=/usr/local/hadoop
export HIVE_HOME=/usr/local/hive
export PATH=$PATH:$HADOOP_HOME/bin:$HIVE_HOME/bin
Haz que los cambios surtan efecto inmediatamente:
source ~/.bashrc
En este punto, la instalación y configuración de Hive está completa.
Configure las variables de entorno: puede agregar las siguientes variables de entorno en /etc/profileel archivo :
export HADOOP_HOME=/usr/local/hadoop
export HIVE_HOME=/usr/local/hive
export PATH=$PATH:$HADOOP_HOME/bin:$HIVE_HOME/bin
-
source /etc/profileA continuación, inicialice la metabase.
-
Configurar la metabase de Hive: Hive usa una metabase para almacenar información de metadatos. Puede usar los siguientes comandos para crear una base de datos MySQL y autorizar a los usuarios de Hive a usar la base de datos:
-
mysql -u root -p create database metastore; grant all privileges on metastore.* to 'hive'@'localhost' identified by 'your_password';Luego, las propiedades como y
hive-site.xmlen el archivo de configuración de Hive deben establecerse como información dejavax.jdo.option.ConnectionURLconexión de MySQL.javax.jdo.option.ConnectionUserNamejavax.jdo.option.ConnectionPassword -
Iniciar Hive: Hive se puede iniciar con el siguiente comando:
hive
Si todo salió bien, debería poder ver la interfaz de línea de comandos de Hive y poder ejecutar comandos SQL de Hive.

4.hive se conecta a la base de datos
