Механизм сигналов
В операционной системе Linux для реагирования на различные события также определено множество сигналов. Мы можем просмотреть все сигналы через команду kill -l
# kill -l
1) SIGHUP 2) SIGINT 3) SIGQUIT 4) SIGILL 5) SIGTRAP
6) SIGABRT 7) SIGBUS 8) SIGFPE 9) SIGKILL 10) SIGUSR1
11) SIGSEGV 12) SIGUSR2 13) SIGPIPE 14) SIGALRM 15) SIGTERM
16) SIGSTKFLT 17) SIGCHLD 18) SIGCONT 19) SIGSTOP 20) SIGTSTP
21) SIGTTIN 22) SIGTTOU 23) SIGURG 24) SIGXCPU 25) SIGXFSZ
26) SIGVTALRM 27) SIGPROF 28) SIGWINCH 29) SIGIO 30) SIGPWR
31) SIGSYS 34) SIGRTMIN 35) SIGRTMIN+1 36) SIGRTMIN+2 37) SIGRTMIN+3
38) SIGRTMIN+4 39) SIGRTMIN+5 40) SIGRTMIN+6 41) SIGRTMIN+7 42) SIGRTMIN+8
43) SIGRTMIN+9 44) SIGRTMIN+10 45) SIGRTMIN+11 46) SIGRTMIN+12 47) SIGRTMIN+13
48) SIGRTMIN+14 49) SIGRTMIN+15 50) SIGRTMAX-14 51) SIGRTMAX-13 52) SIGRTMAX-12
53) SIGRTMAX-11 54) SIGRTMAX-10 55) SIGRTMAX-9 56) SIGRTMAX-8 57) SIGRTMAX-7
58) SIGRTMAX-6 59) SIGRTMAX-5 60) SIGRTMAX-4 61) SIGRTMAX-3 62) SIGRTMAX-2
63) SIGRTMAX-1 64) SIGRTMAX
Более 60 видов. Среди них общие сигналы:
1: HUP, терминал выходит из процесса и завершается, и может быть захвачен
2: INT, то есть crtl+c, завершает процесс переднего плана;
8: FPE, ошибка арифметической операции, переполнение, деление на 0 и т.д.;
9:9 KILL, принудительно завершить процесс, нельзя заблокировать, захватить, проигнорировать.
15: TERM, процесс завершается нормально, обычно захватывает его, обрабатывает последствия, такие как высвобождение ресурсов, а затем завершает работу; kill по умолчанию равен 15
19 SIGSTOP Этот сигнал может приостановить активный процесс, что эквивалентно вводу сочетания клавиш Ctrl+Z
(9, 15 нельзя заблокировать, захватить и игнорировать)
20 SIGSTP также является приостановленным процессом, но его можно заблокировать, захватить , и проигнорировано
14 Сигнал будильника ALARM, используемый для функции alarm(), чтобы установить продолжительность приема сигнала, а затем установить функцию обработки для его обработки.
17 CHILD сигнал: предотвратить зомби-процесс. Дочерний процесс завершается и отправляет сигнал CHILD родительскому процессу.Вы можете установить функцию обработки асинхронного ожидания для этого сигнала без ожидания. На самом деле по умолчанию стоит игнорировать, и вам не нужно с этим бороться, просто сразу освобождайте ресурс.
Существует три метода обработки сигнала.Первый
используется по умолчанию: если это терм, то он закрыт по умолчанию.Например, по умолчанию для ядра записывается файл ядра после закрытия, чтобы облегчить последующий анализ причины.
Захват сигнала: напишите функцию обработки сигнала для обработки сигнала (ID, функция обработки сигнала)
Игнорировать сигналы: такие как sigchild
(убить и остановить нет возможности захватить, проигнорировать и заблокировать)
**
Схема обработки сигналов
**
В основном включает сигнал регистрации и сигнал отправки.
Если мы не хотим, чтобы сигнал выполнял операцию по умолчанию, один из способов — зарегистрировать соответствующую функцию обработки сигнала для конкретного сигнала с помощью функции сигнала.
сигнал sighandler_t (int signum, обработчик sighandler_t);
На самом деле signal — это не системный вызов, а функция gilbc. (То же, что и malloc, brk, mmap)
На самом деле системный вызов — это sigaction, он по-прежнему связывает сигнал с действием, но это действие представлено структурой struct sigaction.
struct sigaction { __sighandler_t sa_handler; unsigned long sa_flags; __sigrestore_t sa_restorer; sigset_t sa_mask; /* маска для расширения */ }; Другие переменные-члены позволяют более детально управлять поведением обработки сигналов. И функция сигнала не дает вам возможности установить их. Например, что означает, что параметр sa_flags по умолчанию имеет значение SA_ONESHOT? Это означает, что установленная здесь функция обработки сигнала работает только один раз. Мы не хотим этого и определенно хотим, чтобы это работало, пока я явно не отключу его.
SA_NOMASK означает, что во время выполнения этой функции обработки сигналов, если есть другие сигналы, даже если поступает тот же самый сигнал, эта функция обработки сигналов будет прервана. Для работы с определенной структурой данных, поскольку это один и тот же сигнал, он, вероятно, будет работать с одним и тем же экземпляром.В этом случае необходимо учитывать взаимоблокировку и синхронизацию. Так что лучше блокировать другие сигналы
SA_RESTART, сигнал поступает при системном вызове, в это время системный вызов будет автоматически перезапущен, и звонящему не нужно самому писать код. Например, при чтении символа прерывается, а затем снова считывается символ, если пользователь больше не вводит, то он останавливается на этом, и пользователю нужно снова ввести тот же символ.
Поэтому рекомендуется использовать функцию подписи и настраивать параметры в соответствии с вашими потребностями.
В ядре rt_sigaction вызывает do_sigaction для установки функции обработки сигнала. В task_struct каждого процесса есть sighand, указывающий на struct sighand_struct, которая представляет собой массив, нижний индекс — это сигнал, а содержимое внутри — функция обработки сигнала. (Это опять же связано с пространством памяти процесса, в нем есть функции обработки сигналов, а системный вызов находится в пространстве ядра)
(Подводя итог, код системного вызова находится в первом 1 МБ пространства ядра. Корень находит код при прерывании. Функция обработки при прерывании сигнала находится в пространстве режима ядра процесса, в частности, сигнал структура часть task_struct.Общая часть попадет в режим ядра)
(Мягкие прерывания имеют сигналы (аномальные), системные вызовы, они прописаны в инициализации ядра trap_init(), процесс обработки прерывания заключается в защите сцены (сохраняется в структуре ptg состояния ядра) - выполнение системных вызовов или обработка прерывания функции - восстановление
оборудования Прерывания это прерывания генерируемые IO.Это немного сложнее.В середине сигнал прерывания-вектор прерывания-глобальный вектор прерывания-найти обработчик прерывания(управляемый))
посылка сигнала
Иногда, когда мы вводим определенные комбинации клавиш в терминале , процессу посылается сигнал, например, Ctrl+C генерирует сигнал SIGINT, а Ctrl+Z генерирует сигнал SIGSTOP.
Иногда аппаратные исключения также генерируют сигналы. Например, если выполняется инструкция деления на 0, ЦП сгенерирует исключение, а затем отправит процессу SIGFPE. Например, если процесс обращается к недопустимой памяти, модуль управления памятью сгенерирует исключение, а затем отправит процессу сигнал SIGSEGV.
Самый прямой способ отправить сигнал — отправить сигнал с помощью команды kill . Например, все мы знаем, что kill -9 pid может послать сигнал процессу, убивая его. Вы также можете использовать tkill или отправить сигнал в определенный поток, и, наконец, вызвать функцию do_send_sig_info . Важной вещью в этой функции является структура подписи.
В структуре sigpending есть два члена: один — набор sigset_t, указывающий, какие сигналы были получены, и связанный список, который также указывает, какие сигналы были получены . Его структура выглядит следующим образом:
struct sigpending { struct list_head list; сигнал sigset_t; };
В коллекцию будут помещены сигналы меньше 32, что ненадежно. Например, всего имеется 5 SIGUSR1, а именно A, B, C, D и E.
Если эти пять сигналов приходят слишком плотно. Приходит A, но до того, как функция обработки сигнала сможет его обработать, приходят B, C, D и E. Согласно приведенной выше логике, поскольку A поместил SIGUSR1 в набор sigset_t, последние четыре будут потеряны. Если другой случай, когда приходит А и уже обработан функцией обработки сигналов, перед тем, как ядро вызовет функцию обработки сигналов, мы очистим флаги в коллекции, в это время, когда снова придет Б, Б все равно войдет коллекция или быть Если вы имеете дело с ним, вы не потеряете его.
Сигналы больше 32 будут монтироваться в связанный список, что является надежным сигналом.
Тайминг обработки сигнала.
Когда сигнал, посланный kill, зависает на структуре task_struct, нам нужно, наконец, вызвать complete_signal . Мы собираемся вызвать signal_wake_up, чтобы попытаться разбудить его.
В signal_wake_up_state есть две основные вещи. Во-первых, установить TIF_SIGPENDING для этого потока, что означает, что обработка сигналов и планирование процессов фактически используют тип механизма.
Когда процесс должен быть вызван, мы не загоняем его напрямую, а устанавливаем флаг TIF_NEED_RESCHED, что означает ожидание планирования, а затем ждем окончания системного вызова или окончания обработки прерывания. состояние из состояния ядра, вызов Функция расписания выполняет планирование.
Сигнал также похож.Когда сигнал приходит, мы не обрабатываем сигнал напрямую, а устанавливаем флаг TIF_SIGPENDING, чтобы указать, что уже есть сигнал, ожидающий обработки. Точно так же, когда завершается системный вызов или завершается обработка прерывания, и состояние ядра возвращается в пользовательское состояние, сигнал обрабатывается.
Подводя итог:
используйте sianal, siaaction для регистрации сигнала signal, и он будет помещен в массив signal структуры task_struct процесса;
При отправке сигнала с помощью kill или иным образом фактически вызывается send_sig_info. Подписание очень важной структуры. Отправка сигнала - это фактически повесить сигнал на подписывающую структуру процесса task_struct, и если набор монтирования меньше 32, то он будет потерян, если он ненадежен, а если больше 32, то список монтирования надежный .
Затем обработайте синхронизацию сигнала. Если процесс запущен, обработчик сигнала выполняется напрямую.
Но процесс может выполнять системный вызов или аппаратное прерывание (и находиться в прерываемом состоянии сна, таком как ожидание ввода-вывода), в этом случае обработка сигналов и планирование процесса являются механизмом. Сначала он выдаст флаг вытеснения или флаг обработки сигнала, а затем попытается разбудить процесс, когда процесс найдет сигнал, он прервется и вернется, то есть системный вызов прерывается сигналом. При возврате есть возможность обработать сигнал, войти в пользовательский режим и скопировать функцию обработки сигнала в пользовательский режим для выполнения. После выполнения вернуться в исходное положение.
(Конечно, после того, как системный вызов или аппаратное прерывание прерываются сигналом, выполняемая операция может быть определена пользователем, никакие действия не могут быть предприняты или системный вызов может быть перезапущен)
И, если это непрерывное спящее состояние, сигнал не может быть активирован, когда система вызывает спящий режим. Прервать его никак нельзя, и kill -9 тоже не сработает. Он в основном используется для некоторого бесперебойного процесса ядра, гарантирует атомарность? Точно так же, например, если при чтении символьного устройства произойдет прерывание, это приведет к тому, что устройство окажется в неуправляемом состоянии, поэтому оно должно быть установлено как непрерываемое.
Принцип анонимной трубы
Чтобы создать конвейер, вам нужно передать следующую функцию
int pipe(int fd[2])
Здесь мы создаем канал канала и возвращаем два файловых дескриптора, которые представляют два конца канала, один — дескриптор чтения fd[0] канала, а другой — дескриптор записи. дескриптор fd[1] канала
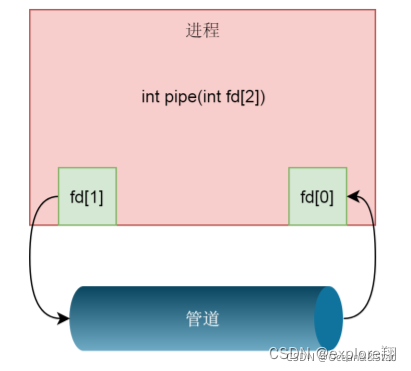
Эта функция фактически вызывает системный вызов pipe2. Основной принцип этой функции заключается в том, чтобы сначала создать файл конвейера. Он также создается в файловой системе, но это просто специальная файловая система, создающая специальный файл, соответствующий специальному иноду, файл имеет свою собственную структуру (включая инод, фактические данные, соответствующие файловые операции), внутри содержит специальные inodes, которые указывают не на диск, а на буферы ядра в памяти. Снова вызовите fd_install , чтобы связать два файла fd с двумя файлами структур.
Файл здесь на самом деле является файлом конвейера, то есть fd1 открывает файл для чтения, а fd2 открывает файл для записи.
В это время это все еще процесс, поэтому необходимо разветвить дочерний процесс, чтобы дочерний процесс скопировал struct file_struct родительского процесса, а массив fd был скопирован сюда , но файл struct указал to by fd по-прежнему имеет только одну копию одного и того же файла (поскольку это конвейерный файл). Затем родительский процесс закрывает чтение fd и сохраняет только записанный fd, а дочерний процесс закрывает записанный fd и сохраняет только чтение fd, если требуется двусторонний трафик, следует создать два канала.
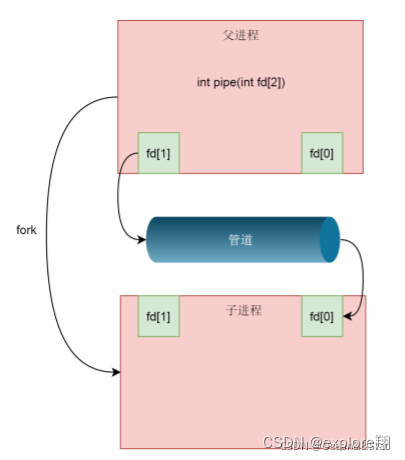
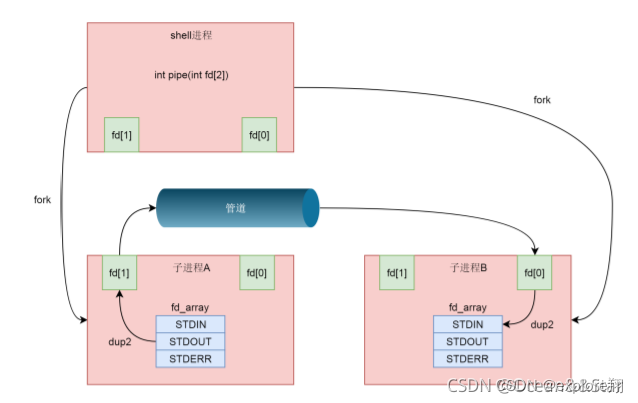
Но это не относится к нам в оболочке. При запуске A|B в оболочке как процесс A, так и процесс B являются дочерними процессами, созданными оболочкой, и между A и B нет отношения родитель-потомок.
Таким образом, dup2(int oldfd, int newfd); используется для присвоения старого файлового дескриптора новому файловому дескриптору, чтобы значение newfd было таким же, как и oldfd.
В массиве fd первые три элемента фиксированы, нулевой элемент STDIN_FILENO означает стандартный ввод, первый элемент STDOUT_FILENO означает стандартный вывод, а третий элемент STDERR_FILENO означает вывод ошибок. dup2(fd[1], STDOUT_FILENO), STDOUT_FILENO (первый элемент) больше не указывает на стандартный вывод, а на канальный файл сцены исполнения, тогда все, что будет записано на стандартный вывод в будущем, будет записано в файл пайпа . То же самое касается стороны чтения.
Именованные каналы
в основном решают проблему, когда два процесса без родства хотят общаться. Функция mkfifo
в Glibc вызовет системный вызов mknodat (named pipe — это тоже устройство, поэтому также используется mknod) для фактического создания файла в файловой системе ext4, но вызовет init_special_inode для создания специального inode в памяти с Структура файла канала, индекс хранения, сущность (буфер ядра), соответствующая операция.
Описание:
Anonymous и named на самом деле являются буферным пространством памяти ядра. Все конвейеры и устройства являются файлами, а интерфейсы доступа согласуются с точки зрения пользователя, разница в том, что их иноды особенные, в соответствии с этим отличием они могут соответствовать разным файловым структурам (включая соответствующие операции, иноды и файловые дескрипторы). сущности) и реализовывать различные реализации. Например, чтение файла — это чтение файла,
чтение устройства — фактически чтение драйвера с устройства, а чтение конвейера — чтение из буфера ядра. Нам все равно.
Зачем трубы?
Почему бы просто не использовать обычный файл на диске в качестве места для общения?
Недостатки: 1: Нет контроля доступа. Если родительский процесс пишет очень медленно или закрывается, дочерний процесс не завершится и вернет 0, в результате чего дочерний процесс не сможет выполнить перезапуск и произойдет утечка памяти 2. Очевидно, что доступ к дисковым файлам
будет медленнее;
Конвейер представляет собой файл памяти с контролем доступа, если скорость слишком медленная или слишком высокая, он будет заблокирован. Закрытие одной стороны останавливает другую.
Подводя итог: как операционная система работает с различными типами файлов (обычными файлами, каталогами, устройствами, конвейерами) через унифицированное открытие?
Процесс будет иметь массив fd, который содержит имя файла.При создании файла операционная система создаст dentry, который содержит отображение между именем и структурой инода, но иноды разных типов файлов разные ( индексный дескриптор содержит тип файла, владельца, информацию о модификации, такую как время и место хранения). Когда он открыт, он отличается в зависимости от индекса. Будет создана структура file_struct файлов разных типов, в которой записываются связанные операции разных файлов (такие как операция открытия, чтение, запись)
( fd-inode-file_struct )
Общая память IPC
Благодаря механизму разделяемой памяти два процесса могут обращаться к переменным в разделяемой памяти точно так же, как к переменным в своей собственной памяти . Но в то же время возникают и проблемы.Когда два процесса делят память, будут проблемы одновременного чтения и записи, что требует защиты разделяемой памяти, для чего нужен механизм синхронизации типа семафора
int shmget(key_t key, size_t size, int shmflag);
key — это сгенерированный ранее ключ.
Если shmflag равен IPC_CREAT, это означает новое создание, и вы также можете указать разрешение на чтение и запись 0777.
Для разделяемой памяти необходимо указать размер. Насколько велико это приложение? Лучшая практика заключается в том, что мы помещаем данные, которые должны совместно использоваться несколькими процессами, в структуру, а затем размер здесь должен соответствовать размеру структуры. Таким образом, после того, как каждый процесс получит этот кусок памяти, пока он вынужден преобразовать тип в этот тип структуры, он может получить доступ к общим данным внутри.
После того, как разделяемая память сгенерирована, следующим шагом является сопоставление этой разделяемой памяти с виртуальным адресным пространством процесса
:
id, addr указывает, что отображение где-то есть. Если не указано, ядро автоматически выберет адрес и вернет его в качестве возвращаемого значения. После получения адреса возврата нам нужно привести указатель к структуре struct shm_data, после чего мы можем использовать данные и длину данных, установленные этим указателем.
Когда разделяемая память израсходована, мы можем отменить ее сопоставление с виртуальной памятью с помощью команды shmdt
int shmdt(const void *shmaddr);
Семафор
Нам нужно создать коллекцию семафоров, которая также создается с помощью xxxget: семафор нужно инициализировать определенным значением через semctl
int semget(key_t key, int nsems, int semflg);
семафор часто представляет количество определенных ресурсов , Если семафор используется для взаимного исключения, семафор часто устанавливается равным 1. Для семафоров часто определяются две операции: P-операция и V-операция. Мы можем использовать этот семафор для защиты структуры shm_data в разделяемой памяти, чтобы только один процесс мог работать со структурой одновременно.
Конкретный механизм ядра упоминаться не будет.
сетевая системная розетка
Предыдущая связь - это связь между разными процессами на одной машине, а сокет используется для связи процессов на разных машинах.Основные
знания этой части должны быть хорошо освоены, и сетевое общение очень важно.
Базовые знания:

Программирование сокетов должно быть основано на дескрипторе файла, файловом дескрипторе сокета. Системный вызов socket(2) используется для создания файловых дескрипторов сокетов.
int socket(int domain, int type, int protocol);
первый параметр - в основном протокол UNIX, IPV4, IPV6, второй - тип сокета (байтовый поток и пакет данных, для TCP, UDP), протокол: обычно устанавливается до 0. Если произошла ошибка, верните -1, в противном случае верните дескриптор файла сокета.
Файловый дескриптор, созданный bind через системный вызов socket, не может использоваться напрямую, и основные элементы, такие как протокол, IP и порт, задействованные в протоколе TCP/UDP, не отражаются, а системный вызов bind(2) предназначен для объединить эти элементы с файловым дескриптором
Функция выглядит следующим образом:
#include <sys/socket.h>
int bind(int socket, const struct sockaddr *address, socklen_t address_len); Второй параметр определяет поля для протокола, IP, порта и других элементов. address_len: Длина структуры адреса протокола.
Если привязанный адрес неправильный или порт уже занят, функция привязки обязательно сообщит об ошибке, в противном случае, как правило, ошибка не будет возвращена.
Функция прослушивания
немного сложнее.
При использовании системного вызова socket для создания сокета предполагается, что это активный сокет (клиентский сокет), а вызов системного вызова listen(2) должен преобразовать активный сокет в пассивный. Указывает, что ядро должно принять запросы на подключение, направленные на этот сокет.
listen Еще одной важной задачей является создание незавершенной очереди соединений (полуподключенной очереди) и завершенной очереди соединений (полной очереди соединений). Ядро поддерживает эти две очереди для каждого слушающего сокета.Соединения, которые не завершили трехэтапное рукопожатие, временно сохраняются в незавершенной очереди.Соединения, которые завершили трехстороннее рукопожатие и еще не были обработаны сервером, обращающимся к системный вызов accept сохраняются в завершенной очереди Connection queue.
Прототип функции выглядит следующим образом:
#include <sys/socket.h>
int listen(int socket, int backlog);
Для серверных программ со сценариями с высокой степенью параллелизма необходимо соответствующим образом увеличить отставание (значение невыполненной работы по умолчанию для Nginx и Redis — 511). На самом деле отставание представляет собой размер полной очереди соединений, что означает, что трехстороннее рукопожатие было завершено, но не принято.После превышения порога запрос на синхронизацию клиента будет отклонен. На самом деле полный размер соединения определяется min(backlog, somaxconn).
Анализ ядра:
1. В listen мы по-прежнему используем sockfd_lookup_light, чтобы найти структуру сокета struct в соответствии с файловым дескриптором fd . Далее мы вызываем функцию прослушивания ops в структуре сокета struct . (Это фактически отражает операцию, что все является файлом, и соответствующий инод тоже находится через fd, но его нет на диске в памяти ядра, а актуальная информация и местонахождение файла находятся через инод. Открытие fd будет иметь соответствующую запись файловой структуры Соответствующая операция)
/ 2. Если сокет не находится в состоянии TCP_LISTEN, он вызовет inet_csk_listen_start для входа в состояние прослушивания.
3. Преобразование активных сокетов в пассивные сокеты фактически соответствует struct inet_connection_sock *icsk = inet_csk(sk), фактически выполняется принудительное преобразование типа. Структура struct inet_connection_sock более сложная. Если его открыть, то можно увидеть очереди в разных состояниях, с разными таймаутами, контролем заторов и другими словами. Мы говорим, что TCP ориентирован на соединение, то есть и клиент, и сервер имеют структуру для поддержания состояния соединения, которое ссылается на эту структуру.
4. reqsk_queue_alloc(&icsk->icsk_accept_queue) — выделить полную очередь соединений.
accept
Системный вызов accept(2) попытается обслужить соединение из головы очереди завершенных соединений, поэтому образовавшийся пробел в очереди будет заполнен соединением из очереди незавершенных соединений. Если в это время очередь завершенных соединений пуста, а файловый дескриптор сокета является режимом блокировки по умолчанию, то процесс будет приостановлен.
int accept(int sockfd, struct sockaddr *addr, socklen_t *addrlen);
сокет: сокет слушает дескриптор файла.
addr: адрес протокола подключенного однорангового процесса. Если вас не волнует информация об одноранговых узлах, вы можете установить ее в NULL.
addrlen: указатель длины адресной структуры. Может быть установлено значение NULL, если для параметра addr установлено значение NULL.
Возвращаемое значение: Вернуть -1 в случае ошибки, в противном случае вернуть дескриптор файла подключенного сокета.
Анализ ядра:
1. Они все одинаковые Через sockfd_lookup_light найти структуру сокета struct по дескриптору файла fd .
2. newsock = sock_alloc() и создайте на его основе новый ньюсок. Это сокет подключения
3. Если icsk_accept_queue пуст, вызовите inet_csk_wait_for_connect для ожидания, во время ожидания вызовите schedule_timeout, чтобы отказаться от ЦП, и установите статус процесса в TASK_INTERRUPTIBLE. Прерываемое состояние сна, может быть разбужено сигналом.
Если ЦП снова просыпается, мы затем оцениваем, пуста ли очередь icsk_accept_queue, и в то же время вызываем signal_pending, чтобы увидеть, есть ли какой-либо сигнал, который можно обработать. Как только icsk_accept_queue не станет пустым, вернитесь из inet_csk_wait_for_connect, извлеките объект struct sock из очереди и назначьте его для newsk.
connect (реализовать трехстороннее рукопожатие)
Сторона (клиент), создающая активный сокет, вызывает системный вызов connect(2) для установления соединения с пассивной стороной сокета (сервером).
int connect(int sockfd, const struct sockaddr *addr, socklen_t addrlen);
Среди них первый параметр — это соединение fd, установленное accept, а addr — это ip+порт сервера
Трехстороннее рукопожатие обычно инициируется клиентом, вызвавшим соединение: после завершения он войдет в полную очередь соединений
1. Шаги те же.Согласно fd, найдите структуру сокета struct и найдите соответствующую операцию соединения.
2. Если обнаружено, что сокет находится в состоянии SS_UNCONNECTED, будет вызвана функция tcp_v4_connect. В основном делать выбор маршрутизации. (Поскольку у клиента нет Bind, он автоматически выберет сетевую карту и порт.) Перед отправкой SYN мы сначала устанавливаем состояние клиентского сокета в TCP_SYN_SENT, затем инициализируем порядковый номер инициализации ISN TCP, а затем вызываем tcp_connect для отправки; в
tcp_connect есть новая структура struct tcp_sock , если вы откроете ее, вы обнаружите, что это расширение структуры inet_connection_sock, структура inet_connection_sock находится в начале структуры tcp_sock**, доступ к которой осуществляется через обязательное преобразование типов, и фокус повторяется снова**. struct tcp_sock поддерживает больше состояний TCP
3. inet_wait_for_connect всегда будет ждать, пока клиент получит ACK от сервера . И мы знаем, что после того, как сервер примет, он тоже ждет. Сервер получает син через tcp_v4_send_synack. Нам не важен конкретный процесс отправки. Мы можем узнать из комментариев. После получения SYN мы отвечаем SYN-ACK . После завершения ответа сервер находится в состоянии TCP_SYN_RECV
4. Он вызовет tcp_send_ack и отправит ПОДТВЕРЖДЕНИЕ-ACK, после отправки клиент находится в состоянии TCP_ESTABLISHED. После того, как сервер его получит, он также будет находиться в состоянии ESTABLISHED.
Системный вызов Socket имеет три уровня параметров: семейство, тип и протокол.С помощью этих трех уровней параметров связанный список типов находится в таблице net_proto_family, а соответствующая операция протокола находится в связанном списке типов. Эта операция разделена на два уровня: для протокола TCP первым уровнем является уровень inet_stream_ops, а вторым уровнем — уровень tcp_prot.
Отправить пакет данных для записи
ssize_t write(int fd, const void*buf, size_t nbytes);
Функция записи записывает содержимое nbytes байтов в buf в файловый дескриптор fd . В случае успеха она возвращает количество записанных байтов. В случае неудачи она возвращает -1. , И установить переменную errno
Он включает в себя отправку сетевых пакетов с уровня VFS на уровень IP, а затем на уровень MAC для анализа операции записи сокета.
1. Первый шаг — унификация. Найдите соответствующую файловую структуру struct через fd, и системный вызов записи, наконец, вызовет операцию file_operations, на которую указывает файловая структура struct: sock_write_iter; здесь, в соответствии с двумя уровнями, являются уровень протокола ip и уровень TCP/UDP, последний вызов — tcp_sendmsg VFS —
Socket
2. Реализация tcp_sendmsg все еще очень сложна, и здесь делается несколько вещей. Первый — скопировать данные из пользовательского режима в буфер ядра, второй — отправить данные.
Копирование в ядро представляет собой цикл, объявите копид и скопируйте += копировать в конце цикла, суммируя номер каждой копии. Что нужно сделать за один цикл:
вычислить MSS (заголовок MTU-TCP-IP-заголовок), если копия меньше 0, значит последнюю структуру sk_buff хранить негде, нужно вызвать sk_stream_alloc_skb, перераспределить структуру sk_buff, а затем вызовите skb_entail, поместите только что выделенный sk_buff в конец очереди (в нем есть некоторые оптимизированные структуры данных)
3. Отправлять сетевые пакеты. Независимо от __tcp_push_pending_frames или tcp_push_one, для отправки сетевых пакетов будет вызываться tcp_write_xmit . Основная логика здесь — цикл, который используется для обработки очереди отправки, пока очередь не пуста, она будет отправлена.
В цикле многие алгоритмы передачи, использующие уровень TCP (включая сегментацию, управление перегрузкой, управление потоком и т. д.), в конце цикла вызывают tcp_transmit_skb для фактической отправки сетевого пакета. Нужно сделать две вещи.Первое – заполнить заголовок TCP.После того, как все настройки будут выполнены, для отправки будет вызвана функция ip_queue_xmit .
4. От уровня IP до уровня MAC
ip_queue_xmit состоит из трех частей логики.
Первая часть — это выбор маршрута , то есть с какой сетевой карты должен выходить пакет, который я хочу отправить. Функция fib_table_lookup выполняет поиск в этой таблице. Запросите по префиксу, надеясь найти тот, у которого самое длинное совпадение, например, и 192.168.2.0/24, и 192.168.0.0/16 могут соответствовать 192.168.2.100/24. Однако мы должны использовать эту запись для 192.168.2.0/24. Для того, чтобы сделать это удобнее, воспользуемся структурой trie-дерева.Преобразуем IP-адрес в бинарный вид и поместим его во
вторую часть trie-дерева 2, которая заключается в подготовке заголовка IP-слоя и заполнении его содержание.
3 Третья часть — вызов ip_local_out для отправки IP-пакетов, включая nf_hook. На уровне IP нужно передать правила iptables
(nf_hook. Что это такое? nf означает Netfilter, механизм ядра Linux, который используется для добавления функций-ловушек к ключевым узлам сетевой отправки и пересылки, эти функции могут перехватывать пакеты данных и вмешиваться в пакеты данных.Известной реализацией является модуль ядра ip_tables.В пользовательском режиме также существует клиентская программа iptables, которая использует командную строку для вмешательства в правила ядра.Есть два основных типа
таблицы iptable, каждая таблица имеет несколько цепочек.Итого, если iptable имеет определенные правила, он будет фильтровать или изменять функцию
фильтрации обработки таблицы фильтрации IP-адресов, в основном включая следующие три цепочки.Входная цепочка: фильтровать все целевые адреса Это пакет данных этой машины; цепочка FORWARD: фильтровать все пакеты данных, проходящие через эту машину; цепочка OUTPUT: фильтровать все пакеты данных, сгенерированные этой машиной
Таблица nat в основном имеет дело с трансляцией сетевых адресов, которая может выполнять SNAT (изменение исходного адреса) и DNAT (изменение адреса назначения), включая следующие три цепочки. Цепочка PREROUTING: может изменить адрес назначения при поступлении пакета данных Цепочка OUTPUT: может изменить адрес назначения локально сгенерированного пакета данных Цепочка POSTROUTING: изменить исходный адрес пакета данных при выходе пакета данных Для записи это будет проходить через
цепочку вывода и POSTROUTING. Затем вызовите ip_finish_output. Войдите на уровень MAC.
4. Что должен делать уровень MAC, так это протокол ARP. Уровень MAC нуждается в ARP для получения MAC-адреса, поэтому ему нужно вызвать ___neigh_lookup_noref, чтобы найти соседей, принадлежащих к тому же сетевому сегменту, и он вызовет neigh_probe для отправки ARP. С MAC-адресом вы можете вызвать dev_queue_xmit для отправки сетевого пакета уровня 2, и он вызовет __dev_xmit_skb для помещения запроса в очередь. Отправка сетевого пакета вызовет мягкое прерывание, и данные будут взяты из очереди и помещены в очередь отправки аппаратной сетевой карты.
Подводя итог, можно сказать, что есть несколько слоев
уровня VFS-SOCKET: найдите соответствующую файловую структуру через fd и вызовите соответствующую операцию записи tcp_sendmsg . Он содержит два уровня;
После прибытия на уровень TCP первое, что нужно сделать, — это скопировать данные из состояния пользователя в буфер ядра, а второе — отправить данные. Этот уровень включает в себя некоторые характеристики соединений TCP, такие как MSS, управление перегрузкой, управление потоком, заполнение заголовка TCP и т. д. Вызовите функцию ip_queue_xmit для отправки на уровень ip.
После достижения IP-уровня необходимо сделать три основные вещи: во-первых, выбрать маршрут, с какой сетевой карты отправлять данные, и использовать структуру дерева дерева Преобразовать IP-адрес в двоичный код и поместить его в дерево дерева для более быстрого сопоставления, второе — подготовить информацию заголовка IP-уровня, третье — через правила iptables, а затем вызвать ip_finish_output . Войдите на уровень MAC.
Когда дело доходит до MAC, главное, что нужно сделать, это ARP находит MAC-адрес, помещает его в очередь запросов после его обнаружения и запускает мягкое прерывание, а сетевая карта извлекает данные и отправляет их.
Чтение функционального анализа (фактически обратный процесс)
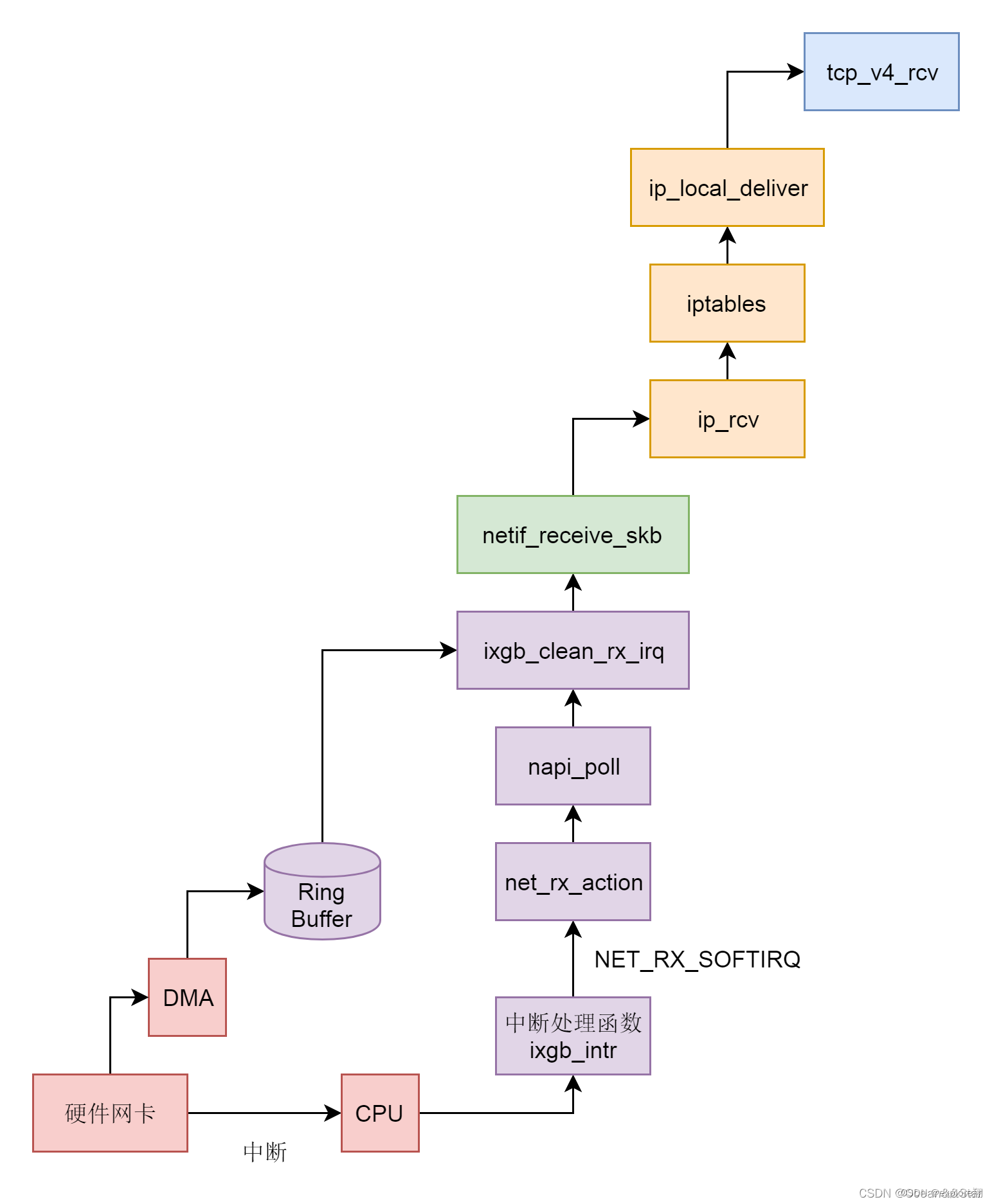
Процесс примерно таков:
1. После того, как аппаратная сетевая карта получает сетевой пакет. Технология DMA помещается в кольцевой буфер, а затем через NAPI (т.к. время поступления данных неопределенно, при обычной обработке прерывания она может быть неэффективной сразу после обработки. Таким образом, NAPI прерывается, просто опрашивается до тех пор, пока не будет данных, а затем Вернитесь назад) поместите данные в буфер, а затем уведомите ЦП о необходимости чтения данных из кольцевого буфера в структуру ядра sk_buff.
2. Вызовите netif_receive_skb, чтобы войти в стек сетевых протоколов ядра, и после выполнения некоторой логической обработки уровня 2 в VLAN вызовите ip_rcv, чтобы войти на уровень IP уровня 3.
3. На уровне IP будут обработаны правила iptables, а затем будет вызван ip_local_deliver для доставки на верхний уровень TCP. Вызовите tcp_v4_rcv на уровне TCP.
4. Уровень TCP в основном обрабатывает несколько очередей. Если текущий сокет не читается, поместите его в очередь невыполненных работ, если он читается и не нуждается в реальном времени, поместите его в очередь предварительной очереди, в противном случае вызовите tcp_v4_do_rcv; если серийный номер можно подключить, поставить его Войти в очередь sk_receive_queue, если серийный номер не может быть подключен, временно поместить его в очередь out_of_order_queue, а затем поставить его в очередь sk_receive_queue, когда серийный номер может быть подключен. (Вот почему у http2 все еще есть проблема с блокировкой головы очереди, но это на уровне TCP, и серийный номер должен быть подключен перед входом в приемную очередь)
На этом процесс получения сетевых пакетов ядром закончен, и следующим шагом является процесс чтения сетевых пакетов в пользовательском режиме , этот процесс разбит на несколько уровней.
Уровень VFS: системный вызов чтения находит файл структуры и вызывает функцию sock_read_iter в соответствии с определением файловых_операций внутри. Функция sock_read_iter вызывает функцию sock_recvmsg. Затем после двух уровней inet и TCP вызовите функцию реального чтения tcp_recvmsg. Функция tcp_recvmsg по очереди считывает очередь receive_queue, очередь prequeue и очередь невыполненных работ.