
Guía:
YOLO, es un marco de detección de objetos popular. Si se introduce YOLO en la tarea de detección de poses, ¿cuál será el resultado? Este artículo implementa una detección de pose humana 2D de una sola etapa. A diferencia de los métodos de arriba hacia abajo o de abajo hacia arriba, este método combina la detección humana y la estimación de puntos clave sin mejorar los datos, como voltear, multiescala, etc. Se logra el rendimiento en el punto clave COCO, y el método se puede integrar en otros algoritmos de detección de objetivos para lograr la estimación de la pose sin aumentar la cantidad de cómputo, lo cual es muy crítico para la estimación en tiempo real de la pose humana.
ArXiv: https://arxiv.org/abs/2204.06806
Código abierto (Pose es de código abierto): https://github.com/TexasInstruments/edgeai-yolov5/tree/yolo-pose
Tabla de contenido
Resumen
Este artículo presenta YoLoPose, que implementa una novedosa detección de articulaciones sin mapas de calor y una estimación de pose de varias personas en 2D basada en el popular marco YOLO. Actualmente, los métodos basados en mapas de calor son de dos etapas, que no son óptimos porque no están capacitados de extremo a extremo, y el entrenamiento se basa en una pérdida L1 alternativa, que no es equivalente a la estrategia de evaluación de maximización, es decir, similitud de punto clave de objeto (OK). Este artículo implementa un modelo entrenado de extremo a extremo y optimiza el propio indicador OKS. Este modelo puede detectar conjuntamente el marco humano y la pose 2D correspondiente en el proceso de propagación hacia adelante unidireccional, por lo que es el mejor para los métodos de arriba hacia abajo o de abajo hacia arriba. El método no requiere el procesamiento posterior de los métodos ascendentes, que agrupan los puntos clave detectados en un esqueleto, ya que cada cuadro de detección tiene una pose asociada, lo que da como resultado una agrupación inherente de puntos de unión. Además, a diferencia de los enfoques de arriba hacia abajo, los pases múltiples hacia adelante se cancelan ya que todas las personas se localizan junto con sus poses en una inferencia unidireccional. YOLOPose ha logrado resultados líderes en COCO val, logrando un 90,5 % en AP50 y un 90,3 % en test-dev, superando todos los métodos actuales basados en la base en un solo paso hacia adelante, sin voltear, multiescala u otros métodos de aumento de datos son usados.

Imagen del efecto de la estimación de la actitud de YOLOPose en una multitud densa

En comparación con YOLOPose, HigherHRNet-w32 no es efectivo para lidiar con multitudes densas
1. Introducción
La estimación de poses 2D de varias personas es la tarea de comprender los cuerpos humanos en imágenes. Introduce una imagen, el objetivo es detectar a cada persona y localizar sus puntos de unión correspondientes. Es un desafío adivinar las poses de varias personas en la imagen, debido a factores como cambios en la cantidad de personas en la imagen, cambios de escala, oclusión de partes del cuerpo y falta de rigidez del cuerpo humano.
Los métodos actuales para la estimación de la pose se dividen principalmente en dos categorías: de abajo hacia arriba y de arriba hacia abajo. El enfoque de arriba hacia abajo o de dos etapas es actualmente la solución más avanzada. Primero adoptan un poderoso detector de personas y luego realizan una estimación de pose individual para cada persona. La complejidad de los métodos de arriba hacia abajo aumenta linealmente con el número de personas en la imagen. La mayoría de las aplicaciones en tiempo real requieren un tiempo de ejecución limitado y no tienden a adoptar un enfoque de arriba hacia abajo debido a su alta complejidad. Por el contrario, los enfoques de abajo hacia arriba proporcionan un tiempo de ejecución constante, ya que se basan en mapas de calor para detectar todos los puntos clave en una sola detección, seguidos de un procesamiento posterior complejo para agruparlos en individuos. El posprocesamiento puede implicar pasos como NMS a nivel de píxel, integración de línea, adelgazamiento, agrupación, etc. El ajuste y el refinamiento de coordenadas reducen el error de cuantificación de los mapas de calor submuestreados, donde NMS se usa para encontrar máximos locales en el mapa de calor. Incluso después del procesamiento posterior, es posible que el mapa de calor no sea lo suficientemente claro para distinguir dos puntos clave cercanos del mismo tipo. Del mismo modo, los enfoques de abajo hacia arriba no se pueden entrenar de extremo a extremo, por lo que el paso de posprocesamiento no es diferenciable y, por lo tanto, ocurre fuera de la red convolucional. Difieren mucho en su enfoque, desde la programación lineal hasta varias heurísticas. Es difícil acelerarlos con los aceleradores CNN y, por lo tanto, lentos. Existen métodos de inferencia de disparo único que, si bien evitan agrupar tareas, no son comparables con los métodos ascendentes. Se basan en un procesamiento posterior adicional para mejorar el rendimiento.
La motivación de este artículo es resolver la estimación de poses sin usar mapas de calor, pero ser coherente con la detección de objetivos, porque los desafíos en la detección de objetivos son similares a los de la estimación de poses, como la diversidad de escala, la oclusión, la falta de rigidez del cuerpo humano, etc. . Por lo tanto, si una red de detección humana puede manejar estos problemas, también puede manejar la estimación de poses. Por ejemplo, los marcos de detección de objetos recientes intentan abordar la variación de escala haciendo predicciones en múltiples escalas. Aquí, adoptamos la misma estrategia para predecir poses humanas de múltiples escalas para cada detección. Del mismo modo, todos los avances importantes en el campo de la detección de objetos se transfieren sin problemas a la estimación de poses. El método de estimación de pose propuesto en este documento se puede integrar fácilmente en otros métodos para ejecutar la detección de objetos en sistemas de visión por computadora, con un aumento casi nulo en el cálculo.
El método YOLOPose se basa en el popular framework YOLOv5. Esta es la primera vez que se propone un método para resolver la estimación de poses en 2D sin usar mapas de calor, y se deshace de muchas operaciones de posprocesamiento no estandarizadas que se usan comúnmente en la actualidad. Este método logra un rendimiento líder en COCO utilizando el mismo procesamiento posterior en la detección de objetos.
En YOLOPose, cada cuadro de anclaje o punto de anclaje, emparejado con el cuadro de verdad del suelo, almacena su pose 2D completa y la posición del cuadro delimitador. Dos puntos de unión similares de diferentes cuerpos humanos pueden estar cerca uno del otro en el espacio. Es difícil distinguir este caso usando un mapa de calor. Sin embargo, si las dos personas coinciden con anclas diferentes, será fácil distinguir puntos de unión similares que estén espacialmente cerca. De nuevo, se agrupan los puntos clave asociados con los anclajes. En el enfoque de abajo hacia arriba, las articulaciones de una persona se confunden fácilmente con las de otra persona, como se muestra en la figura anterior; sin embargo, este método esencialmente puede resolver este problema. A diferencia de los métodos de arriba hacia abajo, la complejidad de YOLO-Pose es independiente del número de personas en la imagen. Por lo tanto, tenemos lo mejor de los enfoques de arriba hacia abajo y de abajo hacia arriba: tiempo de ejecución constante, posprocesamiento simple. Las contribuciones se resumen de la siguiente manera:
- Alineamos la estimación de poses de varias personas con tareas de detección de objetos, ya que existen desafíos similares, como multiescala, oclusión, etc. Se dio así un primer paso hacia la unificación de los dos campos. El método se beneficia directamente de cualquier avance en el campo de la detección de objetos.
- Basado en mapas atérmicos, el método utiliza pasos estándar de posprocesamiento de detección de objetos en lugar de complejos pasos de preprocesamiento de abajo hacia arriba, y se entrena de manera integral sin un posprocesamiento independiente.
- Ampliación de la pérdida de IoU para la detección de cajas de objetos a la estimación de puntos clave. OKS no solo se usa para la evaluación, sino también para el error de entrenamiento. La pérdida de OKS es invariable en la escala e inherentemente proporciona diferentes pesos para diferentes puntos de unión.
- En comparación con el algoritmo DEKR líder, obtuvo un 89,8 % AP50 con 4 veces menos cómputo, que es un 0,4 % más alto.
- El marco que combina detección y estimación de pose logra la estimación de pose casi sin operaciones adicionales en el marco de detección de objetivos.
- Se proponen variantes de modelos de baja complejidad que superan significativamente a los modelos centrados en tiempo real, como EfficientHRNet.
2. Trabajo relacionado
Se investigan principalmente dos tipos de métodos, de arriba hacia abajo y de abajo hacia arriba. Se omite aquí, dependiendo de la obra específica, referirse al texto original.
3. Postura de YOLO
YOLO-Pose es un método de disparo único como otros métodos ascendentes. Sin embargo, no utiliza mapas de calor. En su lugar, utiliza anclas para asociar las articulaciones del cuerpo humano. Se basa en el marco de detección de YOLO5 y también se puede extender a otros marcos. Los autores también tienen una validación limitada en YOLOX. La siguiente figura muestra la arquitectura general, incluido el cabezal de detección de puntos clave.

Arquitectura YOLO-pose basada en YOLOv5. La imagen de entrada pasa a través de la red troncal darknetcsp que genera mapas de características en varias escalas {P3, P4, P5, P6}. PAnet se utiliza para fusionar estos mapas de características en múltiples escalas. La salida de PANet se alimenta a cabezas de detección.Finalmente, cada cabeza de detección se ramifica en cabeza de caja y cabeza de punto clave.Arquitectura
YOLO-Pose basada en YOLOv5. La imagen de entrada se pasa a través del esqueleto de la red oscura para generar mapas de características de diferentes escalas (P3, P4, P5, P6). PANet se adopta para fusionar mapas de características de diferentes escalas. La salida de PANet se utiliza como entrada del cabezal de detección. Finalmente, cada cabezal de detección se ramifica en cabezales de marco de detección y cabezales de llave.
3.1 Resumen
Para demostrar el potencial del método, los autores deben elegir un marco que funcione bien para la detección humana. YOLOv5 es actualmente el detector líder en términos de precisión y cálculo. Por lo tanto, se seleccionó YOLOv5 y se usó como base para construir. Se enfoca principalmente en 80 detecciones de categoría en el conjunto de datos COCO, donde el encabezado del cuadro en cada ancla predice 85 elementos. Corresponden a cuadros delimitadores (4), puntajes de objetos (1) y confianzas para 80 clases (80). Para cada posición de la cuadrícula, habrá tres anclas de diferentes formas.
问:YOLOv5的box head输出为什么有85个元素?
其中,80个元素对应类别,边界框对应4个元素,1个目标分数
Para la estimación de la pose del cuerpo humano, detecta una categoría que es el cuerpo humano, cada cuerpo humano tiene 17 puntos de unión, y cada punto de unión está determinado por la posición y la confianza { x , y , conf } \{x,y,conf\}{
x ,y ,conf } Determinado . _ Por tanto, cada anclaje estará asociado a 51 elementos de 17 puntos de articulación. Por lo tanto, para cada ancla, la cabeza de clave predice 51 elementos y la cabeza de caja predice 6 elementos. Para un ancla con n puntos de unión, todos los elementos necesarios se pueden expresar como un vector, a saber:
P v = { C x , C y , W , H , boxconf , classconf , K x 1 , K y 1 , K conf 1 , ⋅ ⋅ ⋅ , K xn , K yn , K confn } P_v=\{C_x,C_y,W,H,box_{conf},class_{conf},K^1_x,K^1_y,K^1_{conf}, \cdot \cdot \cdot, K^n_x,K^n_y,K^n_{conf}\}PAGv={
Cx,Ctu,W ,H ,caja _ _co n f,clase _ _ _ _co n f,kX1,ky1,kcafé _ _1,⋅⋅⋅ ,kXn,kyn,kcafé _ _n}
问:YOLOPose,在YOLOv5基础上增加了什么?
答:YOLOPose,除了YOLOv5原有的box head,还增加了keypoint head。box head只检测人体类别,输出6个元素;keypoint head检测关键点,输出x和y位置、置信度共三个元素。一种17个关键点,输出51个元素。
La confianza del punto clave se entrena en función de si es visible o no. Si un punto clave está visible u ocluido, la confianza de la anotación manual se establece en 1; si está fuera del campo de visión, se establece en 0. En la etapa de inferencia, mantenemos los puntos clave con una confianza superior a 0,5. Otros puntos clave pronosticados se descartan. Las confianzas previstas del punto clave no se utilizan para la evaluación. Sin embargo, dado que la red genera 17 puntos clave para cada detección, debemos filtrar los puntos clave que están fuera del campo de visión. De lo contrario, quedarán llaves colgando que harán que el esqueleto se deforme. Los métodos ascendentes actuales basados en mapas de calor requieren esta operación porque los puntos clave fuera del campo de visión no se detectarán en la primera etapa.
YOLOPose usa CSP-darknet53 como esqueleto, y PANet integra características de múltiples escalas. Siga la práctica de los cuatro cabezales de detección a diferentes escalas. Finalmente, hay dos cabezales acoplados para predecir cuadros delimitadores y puntos clave.
Esta arquitectura limita su cálculo a 150 GMACS (cómputo de multiplicación y acumulación, aproximadamente de 1 a 1,2 veces GFLOP en operaciones de punto flotante) y puede lograr resultados competitivos. En el caso de aumentar aún más la cantidad de cómputo, la brecha con el método de arriba hacia abajo se puede reducir. Sin embargo, no perseguimos eso, sino que nos enfocamos en el modelo en tiempo real.
3.2 Representación de gestos de varias personas basada en anclas
Para una imagen dada, un ancla se empareja con un cuerpo humano, que contiene el cuadro de pose y posición 2D del cuerpo humano. Las coordenadas del cuadro de ubicación se convertirán según el centro del ancla, y el tamaño del cuadro de ubicación se normalizará según el ancho y la altura del ancla. Asimismo, las posiciones de los puntos clave se transforman según el centro del ancla, pero los puntos clave no se normalizan por el ancho y la altura del ancla. Dado que dicha mejora es independiente del ancho y la altura del anclaje, es más fácil extenderla a otros marcos sin anclaje como YOLOX y FCOS.
3.3 Función de pérdida de cuadro delimitador basada en IoU
La mayoría de los detectores de objetos modernos utilizarán variantes de IoU optimizadas, como GIoU, DIoU y CIoU, en lugar de pérdidas basadas en la distancia para una mejor detección de cuadros delimitadores, ya que estas pérdidas no varían en escala y tienen la capacidad de optimizar directamente la estrategia de evaluación en sí. Los autores utilizan la pérdida de CIoU para la supervisión del cuadro delimitador. Para un cuadro delimitador de verdad fundamental dado, corresponde al kthk^{th}kel ancla coincide en la posición( i , j ) (i,j)( yo ,j ) , cuya escala essss , entonces la pérdida entre ellos se puede definir como:
L box ( s , i , j , k ) = ( 1 − CI o U ( B oxgts , i , j , k , Box oxpreds , i , j , k ) ) L_{caja}(s,i,j,k)=(1-CIoU(Caja^{s,i,j,k}_{gt},Caja^{s,i,j,k}_{pred } ))Lcaja _ _( s ,yo ,j ,k )=( 1−C I o U ( Caja _ _g ts , yo , j , k,Caja _ _antes de _ _s , yo , j , k))
其中,Box oxpreds , i , j , k Box^{s,i,j,k}_{pred}Caja _ _antes de _ _s , yo , j , kes el kthk^{th}kLos anclajes están en la posición( i , j ) (i,j)( yo ,j ) , la escala esssEl cuadro de predicción de s . En el diseño del autor, cada ubicación tiene tres anclas y se predicen cuatro escalas.
3.4 Expresión de la función de pérdida de pose humana
OKS es la estrategia más popular para evaluar puntos clave. Tradicionalmente, los métodos ascendentes basados en mapas de calor emplean la pérdida L1 para detectar puntos clave. Sin embargo, la pérdida de L1 puede no ser adecuada para obtener OKS optimizados. Debido a que la pérdida L1 es la más ingenua, no considera la escala de un objeto o el tipo de puntos clave. Dado que el mapa de calor es un mapa de probabilidad, es imposible utilizar OKS como la función de pérdida del método de mapa de calor puro. OKS puede usarse como una función de pérdida solo cuando la posición del punto clave está en regresión. Se propuso una pérdida L1 normalizada a escala para la regresión de puntos clave, que es un paso hacia la pérdida OKS.
Por lo tanto, regresamos directamente al punto clave, el centro de anclaje, y podemos optimizar la estrategia de evaluación en sí misma en lugar de una función de pérdida. Extendemos la pérdida de IoU desde los cuadros delimitadores hasta los puntos clave. Entre los puntos clave, OKS se trata como IoU. Por lo tanto, la pérdida de OKS es intrínsecamente invariable en la escala, sesgando la importancia de puntos clave específicos. Por ejemplo, los puntos clave en la cabeza de una persona, como las orejas, la nariz y los ojos, se penalizan más por errores a nivel de píxel que los elementos del cuerpo, como los hombros, las rodillas y las caderas. Este factor de ponderación fue seleccionado empíricamente por los autores de COCO del conjunto de validación etiquetado redundante. A diferencia de la pérdida de IoU original, que sufre gradientes que se desvanecen en casos que no se superponen, la pérdida de OKS no se estanca. Por lo tanto, la pérdida de OKS es más como la pérdida de dIoU. OKS se calcula para cada punto clave individual y se acumula hasta la pérdida de OKS final o IoU de punto clave, es decir,

para cada punto clave, el autor aprende un parámetro de confianza, que puede indicar si la persona existe en el punto clave. Por lo tanto, el indicador de si el punto clave es visible o no, sirve como anotación de verdad básica. Disponible:

si el cuadro delimitador de la etiqueta real es el mismo que el K th K^{th}kLos anclajes coinciden, luego en la posición( i , j ) (i,j)( yo ,j ) , escalasss y la pérdida de ese ancla será efectiva. Finalmente, la pérdida total en todas las escalas, anclas y ubicaciones se expresa como:

2.5 Estrategia de mejora del tiempo de prueba
El volteo de imágenes y las pruebas de múltiples escalas son dos métodos comúnmente utilizados. Voltear aumentará la cantidad de cálculo en 2 veces, y la escala múltiple suele estar en tres escalas como ( 0.5 × , 1 × , 2 × ) (0.5\times,1\times,2\times)( 0,5 × ,1 × ,2 × ) , etc., el aumento correspondiente en el cálculo es( 0,25 + 1 + 4 ) (0,25+1+4)( 0.25+1+4 ) Es decir, 5,25 veces el monto del cálculo original. Este método no utiliza ninguna estrategia de aumento de datos.
2.6 Puntos clave fuera del cuadro delimitador
Los métodos de arriba hacia abajo no funcionan bien en situaciones de oclusión. Una ventaja de YOLOPose sobre los métodos de arriba hacia abajo es que no hay restricciones en los puntos clave dentro del cuadro delimitador. Por lo tanto, si un punto clave se encuentra fuera del cuadro delimitador debido a una oclusión, aún se detectará correctamente. Sin embargo, en los enfoques de arriba hacia abajo, la estimación de pose también falla si la detección humana es incorrecta. Desafíos como la oclusión y la detección incorrecta del cuadro delimitador se alivian un poco con este método.

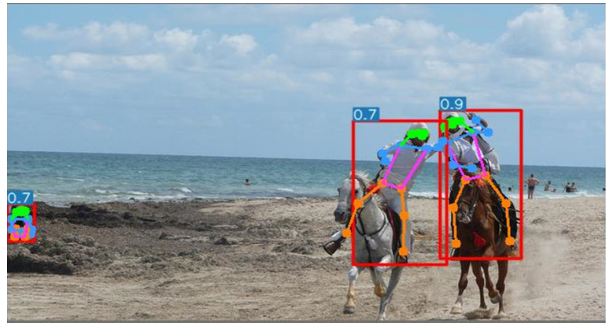
Podemos ver que los puntos clave fuera del cuadro delimitador también se detectan. Para los métodos de arriba hacia abajo, esto definitivamente perderá la detección.
experimento
conjunto de datos:
Conjunto de datos COCO. Contiene 200.000 imágenes y 250.000 instancias de cuerpos humanos.
Estrategia de evaluación:
Usando la estrategia de evaluación estándar, la estrategia OKS se usa para la estimación de pose. Se evaluaron la precisión y el recuerdo, en diferentes umbrales y escalas.
tren:
Adoptamos una estrategia similar de aumento, selección de anclas y ponderación de pérdidas a YOLOv5 [1]. Usamos aumento de datos con escala aleatoria ([0.5, 1.5]), traducción aleatoria [-10, 10], volteo aleatorio con probabilidad 0.5, aumento de mosaico con probabilidad 1 y varios aumentos de color.
prueba:
Primero cambiamos el tamaño del lado grande de la imagen de entrada al tamaño deseado, manteniendo la relación de aspecto. La parte inferior de la imagen se rellena para producir una imagen cuadrada. Esto asegura que todas las imágenes de entrada tengan el mismo tamaño.
resultado:

YOLOpose ha logrado un rendimiento líder y la cantidad de cálculo es casi la mitad de la de DEKR líder en el mismo período.
Resumir
Este documento propone un marco integral para la detección conjunta y la estimación de poses de varias personas basado en YOLOv5. Se ha demostrado que YOLOPose supera a los métodos ascendentes existentes con una complejidad significativamente reducida. Este trabajo es un primer paso hacia la unificación de los campos de la detección de objetos y la estimación de la pose humana. La mayoría de los avances en la estimación de poses hasta la fecha se han producido de forma independiente como un problema distinto. Creemos que este resultado de SOTA animará aún más a la comunidad investigadora a explorar el potencial de resolver conjuntamente estas dos tareas. La principal motivación de este trabajo es transferir todos los beneficios de la detección de objetos a la estimación de la pose humana, ya que estamos presenciando un rápido progreso en el campo de la detección de objetos. Hemos realizado experimentos preliminares que amplían este enfoque para el marco de detección de objetos YOLOX con resultados prometedores. Los autores también extenderán esta idea a otros marcos de detección de objetos y ampliarán aún más los límites de la estimación efectiva de la pose humana.