A continuación, presentaré la red neuronal de conocimiento de física integrada (PINN) para resolver ecuaciones diferenciales. En primer lugar, se introduce el método básico de PINN y, basándose en el marco de solución de PINN de Pytorch, se resuelve la ecuación bidimensional de Navier-Stokes con término de tiempo.
Red neuronal integrada de conocimiento físico (PINN) Introducción y documentos relacionados
Aprendizaje profundo para resolver ecuaciones diferenciales Serie 1: Marco de solución de PINN (Poisson 1d)
Aprendizaje profundo para resolver ecuaciones diferenciales Serie 2: PINN para resolver problemas de reenvío de ecuaciones de hamburguesa
Aprendizaje profundo para resolver ecuaciones diferenciales Serie 3: PINN resuelve el problema inverso de la ecuación de la hamburguesa
Deep learning para resolver la ecuación diferencial serie IV: Basado en la función de activación adaptativa PINN resuelve el problema inverso de la ecuación de la hamburguesa Deep learning
para resolver la ecuación diferencial serie V: PINN resuelve el problema directo e inverso de la ecuación de Navier-Stokes
1. Introducción a PINN
Como una poderosa herramienta de procesamiento de información, la red neuronal se ha utilizado ampliamente en los campos de la visión por computadora, la biomedicina y la ingeniería de petróleo y gas, lo que ha desencadenado cambios tecnológicos en muchos campos. La red de aprendizaje profundo tiene una capacidad de aprendizaje muy fuerte, no solo puede descubrir leyes físicas, sino también resolver ecuaciones diferenciales parciales. En los últimos años, la solución de ecuaciones diferenciales parciales basadas en el aprendizaje profundo se ha convertido en un nuevo foco de investigación. La red neuronal informada por la física integrada (PINN) es una aplicación de máquinas científicas en el dominio numérico tradicional, que se puede utilizar para resolver varios problemas relacionados con ecuaciones diferenciales parciales (PDE), incluida la resolución de ecuaciones, inversión de parámetros, descubrimiento de modelos, control y optimizacion etc
2. Método PINN
La idea principal de PINN se muestra en la Figura 1, primero construya un resultado de salida como u ^ \hat{u}tuLa red neuronal de ^, que se usa como un modelo proxy para la solución PDE, y la información PDE se usa como una restricción, codificada en la función de pérdida de la red neuronal para el entrenamiento . La función de pérdida incluye principalmente cuatro partes: pérdida de estructura diferencial parcial (pérdida PDE), pérdida de condición de valor límite (pérdida BC), pérdida de condición de valor inicial (pérdida IC) y pérdida de condición de datos reales (pérdida de datos).

En particular, considere el siguiente problema PDE, donde la solución de la PDE u ( x ) u(x)u ( x )在Ω ⊂ R d \Omega \subset \mathbb{R}^{d}Oh⊂Rd definición, dondex = ( x 1 , … , xd ) \mathbf{x}=\left(x_{1}, \ldots, x_{d}\right)X=( X1,…,Xre):
f ( x ; ∂ tu ∂ x 1 , … , ∂ tu ∂ xd ; ∂ 2 tu ∂ x 1 ∂ x 1 , … , ∂ 2 tu ∂ x 1 ∂ xd ) = 0 , x ∈ Ω f\left( \mathbf{x} ; \frac{\parcial u}{\parcial x_{1}}, \ldots, \frac{\parcial u}{\parcial x_{d}} ; \frac{\parcial^{2} u}{\parcial x_{1} \parcial x_{1}}, \ldots, \frac{\parcial^{2} u}{\parcial x_{1} \parcial x_{d}} \right)=0 , \quad \mathbf{x} \in \OmegaF( X ;∂ x1∂ tu,…,∂ xre∂ tu;∂ x1∂ x1∂2 y,…,∂ x1∂ xre∂2 y)=0 ,X∈Ω
Al mismo tiempo, satisfaga el siguiente límite
B ( u , x ) = 0 en ∂ Ω \mathcal{B}(u, \mathbf{x})=0 \quad \text { on } \quad \partial \OmegaB ( tú ,x )=0 en ∂ Ω
El proceso de solución de PINN incluye principalmente:
- El primer paso es definir el modelo de red neuronal de la capa totalmente conectada de la capa D:
N Θ : = LD ∘ σ ∘ LD − 1 ∘ σ ∘ ⋯ ∘ σ ∘ L 1 N_{\Theta}:=L_D \circ \ sigma \circ L_{D-1} \circ \sigma \circ \cdots \circ \sigma \circ L_1norteel:=LD∘pag∘Lre - 1∘pag∘⋯∘pag∘L1
式中:
L 1 ( x ) : = W 1 x + segundo 1 , W 1 ∈ R re 1 × re , segundo 1 ∈ R re 1 L yo ( x ) : = W ix + bi , W yo ∈ R di × di - 1 , bi ∈ R di , ∀ yo = 2 , 3 , ⋯ re - 1 , LD ( X ) : = WD X + segundo re , Wd ∈ RN × re re - 1 , segundo re ∈ RN . \begin{alineado} L_1(x) &:=W_1 x+b_1, \quad W_1 \in \mathbb{R}^{d_1 \times d}, b_1 \in \mathbb{R}^{d_1} \\ L_i (x) &:=W_i x+b_i, \quad W_i \in \mathbb{R}^{d_i \times d_{i-1}}, b_i \in \mathbb{R}^{d_i}, \forall i =2,3, \cdots D-1, \\ L_D(x) &:=W_D x+b_D, \quad W_D \in \mathbb{R}^{N \times d_{D-1}}, b_D \ en \mathbb{R}^N . \end{alineado}L1( X )Lyo( X )LD( x ): =W1X+b1,W1∈Rd1× re ,b1∈Rd1: =WyoX+byo,Wyo∈Rdyo× reyo − 1,byo∈Rdyo,∀ yo=2 ,3 ,⋯D−1 ,: =WDX+bD,WD∈RN × rere - 1,bD∈RN. _
y σ \sigmaσ es la función de activación,WWW ybbb son los parámetros de peso y sesgo. - El segundo paso, para medir la red neuronal u ^ \hat{u}tu^和约束之间的差异,考虑损失函数定义:
L ( θ ) = wf LPDE ( θ ; T f ) + wi LIC ( θ ; T i ) + wb LBC ( θ , ; T b ) + wd LD ata ( θ , ; T datos ) \mathcal{L}\left(\boldsymbol{\theta}\right)=w_{f} \mathcal{L}_{PDE}\left(\boldsymbol{\theta}; \mathcal{ T}_{f}\right)+w_{i} \mathcal{L}_{IC}\left(\boldsymbol{\theta} ; \mathcal{T}_{i}\right)+w_{b} \mathcal{L}_{BC}\left(\boldsymbol{\theta},; \mathcal{T}_{b}\right)+w_{d} \mathcal{L}_{Datos}\left(\ boldsymbol{\theta},; \mathcal{T}_{datos}\right)L( yo )=wfLP D E( yo ;Tf)+wyoLyo c( yo ;Tyo)+wsegundoLB C( yo ,;Tsegundo)+wreLdatos _ _ _( yo ,;Tdatos _ _ _)
donde:
LPDE ( θ ; T f ) = 1 ∣ T f ∣ ∑ x ∈ T f ∥ f ( x ; ∂ tu ^ ∂ x 1 , … , ∂ tu ^ ∂ xd ; ∂ 2 tu ^ ∂ x 1 ∂ x 1 , … , ∂ 2 tu ^ ∂ X 1 ∂ xd ) ∥ 2 2 LIC ( θ ; T yo ) = 1 ∣ T yo ∣ ∑ X ∈ T yo ∥ tu ^ ( X ) − tu ( X ) ∥ 2 2 LBC ( θ ; T segundo ) = 1 ∣ T segundo ∣ ∑ x ∈ T segundo ∥ segundo ( tu ^ , x ) ∥ 2 2 LD ata ( θ ; T datos ) = 1 ∣ T datos ∣ ∑ x ∈ T datos ∥ tu ^ ( x ) − u ( x ) ∥ 2 2 \begin{alineado} \mathcal{L}_{PDE}\left(\boldsymbol{\theta} ; \mathcal{T}_{f}\right) &=\frac{1 }{\left|\mathcal{T}_{f}\right|} \sum_{\mathbf{x} \in \mathcal{T}_{f}}\left\|f\left(\mathbf{x } ; \frac{\parcial \hat{u}}{\parcial x_{1}}, \ldots, \frac{\parcial \hat{u}}{\parcial x_{d}} ; \frac{\parcial ^{2} \hat{u}}{\parcial x_{1} \parcial x_{1}}, \ldots, \frac{\parcial^{2} \hat{u}}{\parcial x_{1} \partial x_{d}} \right)\right\|_{2}^{2} \\ \mathcal{L}_{IC}\left(\boldsymbol{\theta};\mathcal{T}_{i}\right) &=\frac{1}{\left|\mathcal{T}_{i}\right|} \sum_{\mathbf{x}\in \mathcal{T }_{i}}\|\hat{u}(\mathbf{x})-u(\mathbf{x})\|_{2}^{2} \\ \mathcal{L}_{BC} \left(\ballsymbol{\theta};\mathcal{T}_{b}\right) &=\frac{1}{\left|\mathcal{T}_{b}\right|}\sum_{\ mathbf{x} \in \mathcal{T}_{b}}\|\mathcal{B}(\hat{u}, \mathbf{x})\|_{2}^{2}\\ \mathcal {L}_{Datos}\left(\símbolo en negrita{\theta}; \mathcal{T}_{datos}\right) &=\frac{1}{\left|\mathcal{T}_{datos} \ right|} \sum_{\mathbf{x} \in \mathcal{T}_{datos}}\|\hat{u}(\mathbf{x})-u(\mathbf{x})\|_ { 2}^{2} \end{alineado}=\frac{1}{\left|\mathcal{T}_{b}\right|}\sum_{\mathbf{x}\in \mathcal{T}_{b}}\|\mathcal{B} (\hat{u}, \mathbf{x})\|_{2}^{2}\\ \mathcal{L}_{Data}\left(\negrita{\theta}; \mathcal{T} _ {datos}\right) &=\frac{1}{\left|\mathcal{T}_{datos}\right|} \sum_{\mathbf{x}\in \mathcal{T}_{datos} } \|\hat{u}(\mathbf{x})-u(\mathbf{x})\|_{2}^{2} \end{alineado}=\frac{1}{\left|\mathcal{T}_{b}\right|}\sum_{\mathbf{x}\in \mathcal{T}_{b}}\|\mathcal{B} (\hat{u}, \mathbf{x})\|_{2}^{2}\\ \mathcal{L}_{Data}\left(\negrita{\theta}; \mathcal{T} _ {datos}\right) &=\frac{1}{\left|\mathcal{T}_{datos}\right|} \sum_{\mathbf{x}\in \mathcal{T}_{datos} } \|\hat{u}(\mathbf{x})-u(\mathbf{x})\|_{2}^{2} \end{alineado}LP D E( yo ;Tf)Lyo c( yo ;Tyo)LB C( yo ;Tsegundo)Ldatos _ _ _( yo ;Tdatos _ _ _)=∣ Tf∣1x ∈ Tf∑∥∥∥∥F( X ;∂ x1∂tu^,…,∂ xre∂tu^;∂ x1∂ x1∂2tu^,…,∂ x1∂ xre∂2tu^)∥∥∥∥22=∣ Tyo∣1x ∈ Tyo∑∥tu^ (x)−tu ( x ) ∥22=∣ Tsegundo∣1x ∈ Tsegundo∑∥ B (tu^ ,X ) ∥22=∣ Tdatos _ _ _∣1x ∈ Tdatos _ _ _∑∥tu^ (x)−tu ( x ) ∥22
wf w_{f}wf,con w_{i}wyo、wb w_ {b}wsegundoy wd w_{d}wrees el peso V f \mathcal{T}_{f}Tf,T i \mathcal{T}_{i}Tyo、T b \mathcal{T}_{b}Tsegundo和T data \mathcal{T}_{data}Tdatos _ _ _Representa puntos residuales de PDE, valor inicial, valor límite y valor verdadero. Aquí T f ⊂ Ω \mathcal{T}_{f} \subset \OmegaTf⊂Ω es un conjunto predefinido de puntos para medir la salida de la red neuronalu ^ \hat{u}tu^ Grado de coincidencia con PDE. - Finalmente, use el algoritmo de optimización de gradiente para minimizar la función de pérdida hasta que se encuentren los parámetros de red que cumplan con la precisión de la predicción .
Vale la pena señalar que para problemas inversos, es decir, algunos parámetros en la ecuación son desconocidos. Si solo se conocen la ecuación PDE y las condiciones de contorno, y se desconocen los parámetros PDE, el problema inverso es un problema indeterminado, por lo que se debe conocer otra información, como algunos puntos de observación uuel valor de ud . En este caso, el método PINN puede utilizar los parámetros de la ecuación como variables desconocidas y agregarlos al entrenador para su optimización.La función de pérdida incluye la pérdida de datos.
3. Definición de resolución de problemas: problemas directos e inversos
ut + λ 1 ( uux + vuy ) = − px + λ 2 ( uxx + uyy ) vt + λ 1 ( uvx + vvy ) = − py + λ 2 ( vxx + vyy )
\begin{alineado} &u_t+\lambda_1\left(u u_x+v u_y\right)=-p_x+\lambda_2\left(u_{xx}+u_{yy}\right) \\ &v_t+\lambda_1\left(u v_x+ v v_y\right)=-p_y+\lambda_2\left(v_{xx}+v_{yy}\right) \end{alineado}tut+yo1( Uu uux+tu _tu)=- pagx+yo2( tux x+tuyy _)vt+yo1( u vx+vv _tu)=- pagtu+yo2( vx x+vyy _)
Problema positivo :
- parámetroλ 1 = 1 \lambda_{1}=1yo1=1 ,λ 2 = 0,01 \lambda_{2}=0yo2=0 . 0 1 es un parámetro conocido, el problema son condiciones de contorno y ecuaciones diferenciales conocidas, y u, v, p están resueltas.
Problema inverso: - Sencillo 1 , 2 \lambda_{1},\lambda_{2}yo1,yo2Para parámetros desconocidos, el problema son condiciones de contorno conocidas y ecuaciones diferenciales, pero los parámetros en la ecuación son desconocidos, resuelva u, v, p y los parámetros de la ecuación.
Considere resolver el campo de flujo incompresible en el área rectangular que se muestra en la Figura 2. En particular, la solución de la ecuación del fluido satisface funciones libres de divergencia al mismo tiempo, que se pueden expresar como: ux + vy = 0 u_x+ v_y=
0tux+vtu=0
red, la salida debe ser tridimensional (u , v , pu,v,ptu ,v ,p ), pero en el proceso de solución se puede introducir la función latente,ψ ( x , y , t ) \psi(x,y,t)ψ ( x ,y ,t ) , cumple con los requisitos,
u = ψ y , v = − ψ xu=\psi_y, \quad v=-\psi_xtu=pagtu,v=- pagx
salida de la red, se puede expresar como una bidimensional ( ψ , p \psi,ppd ,pag )
。
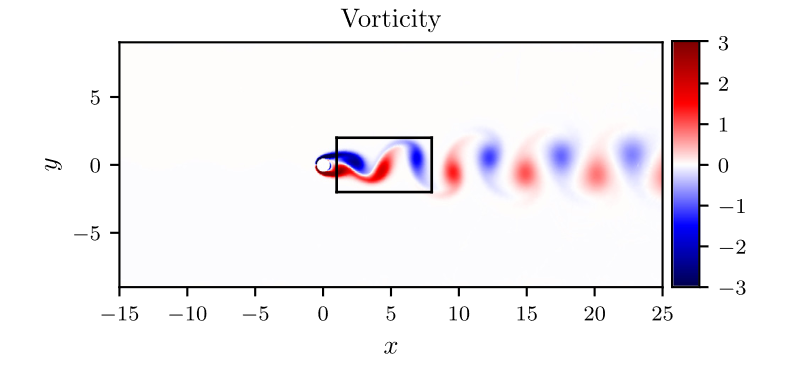
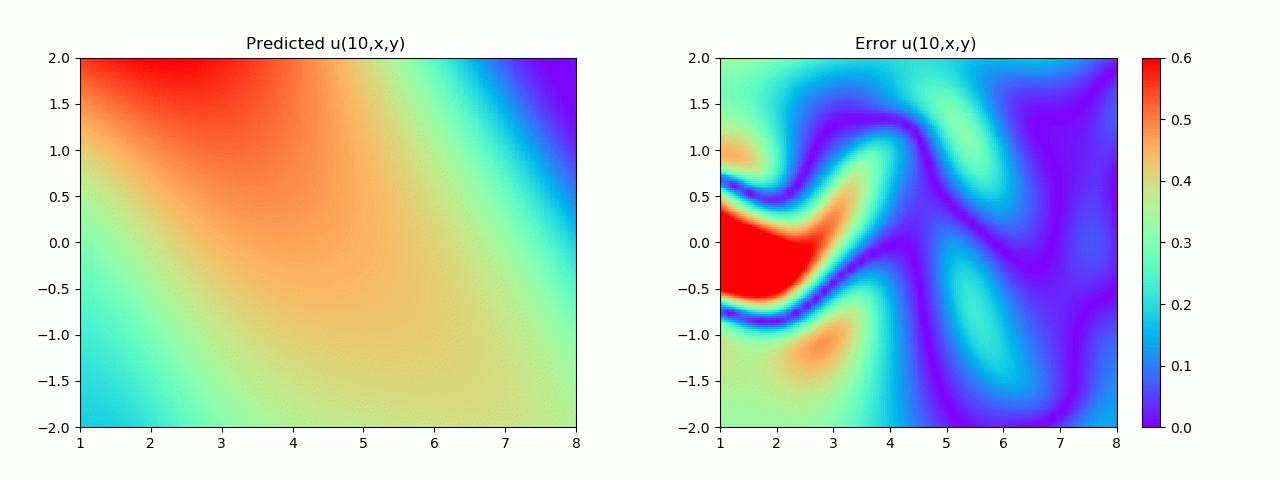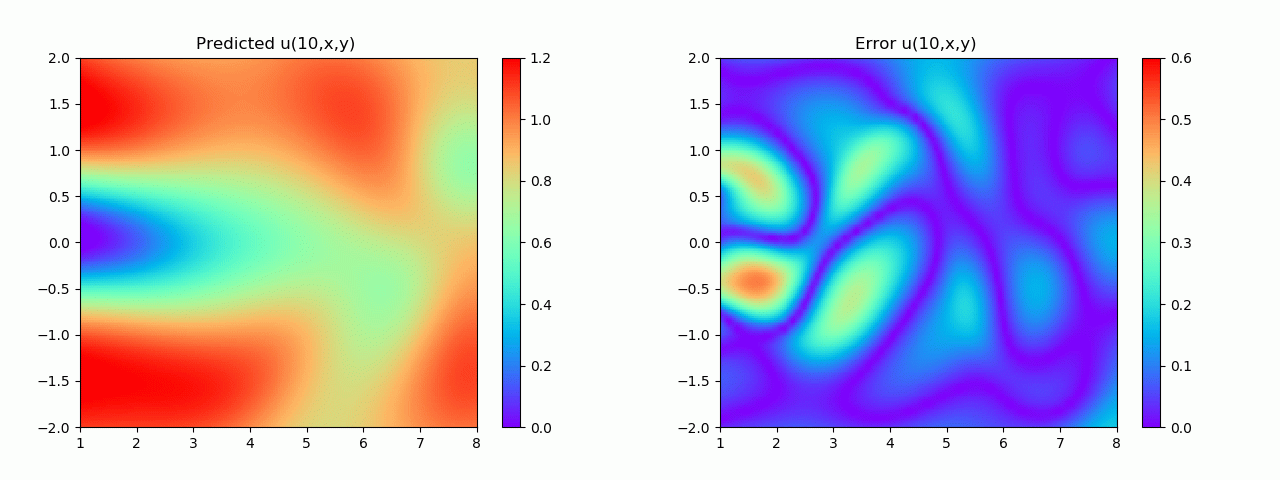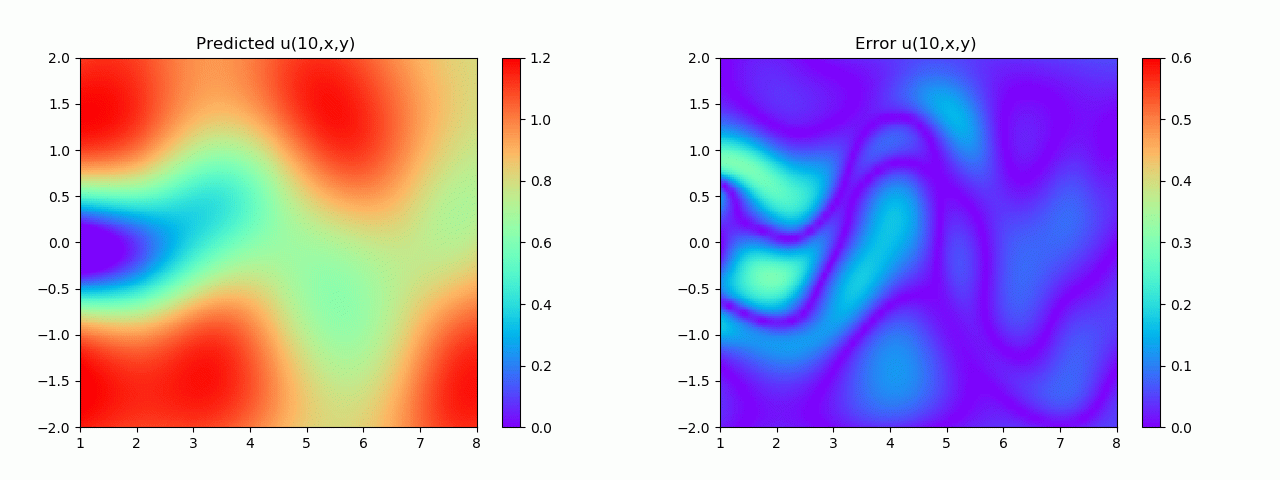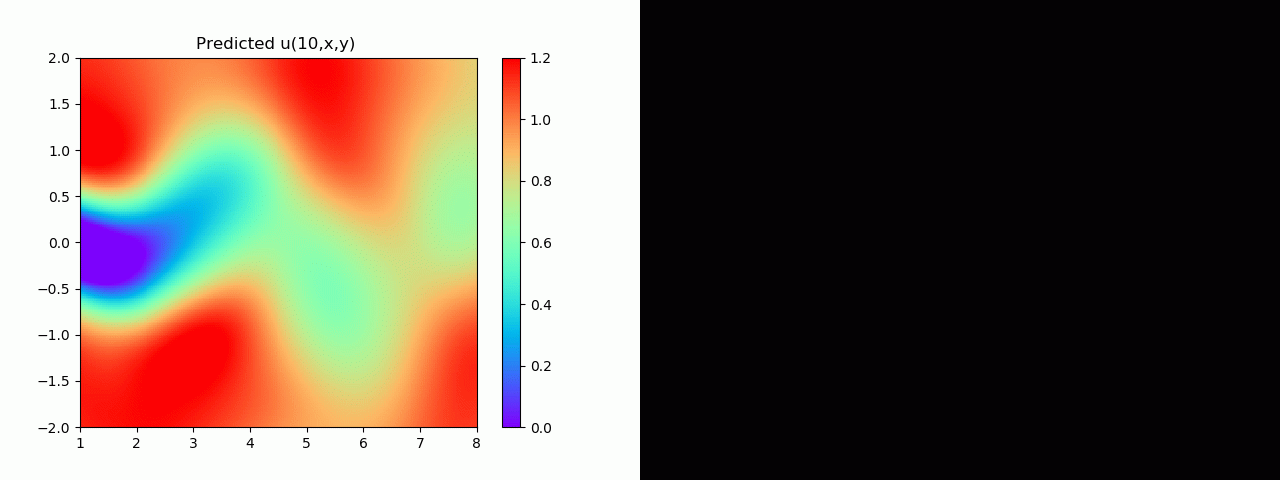
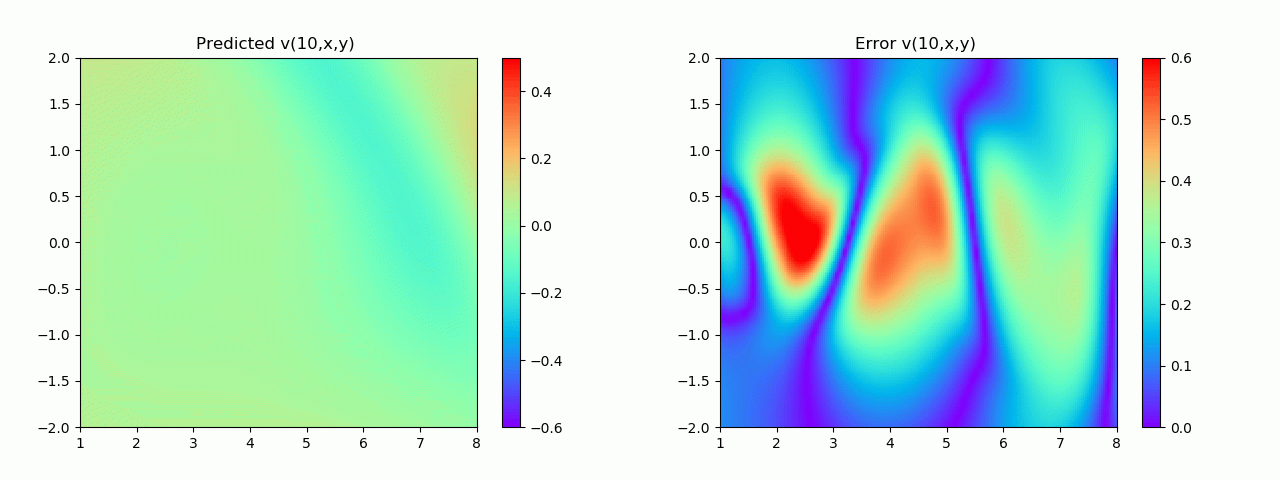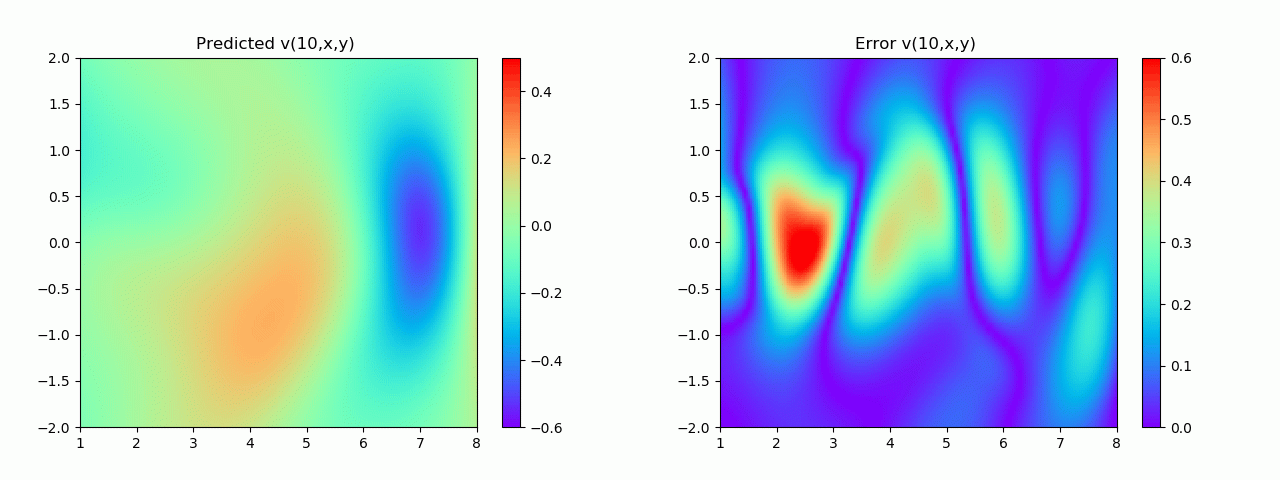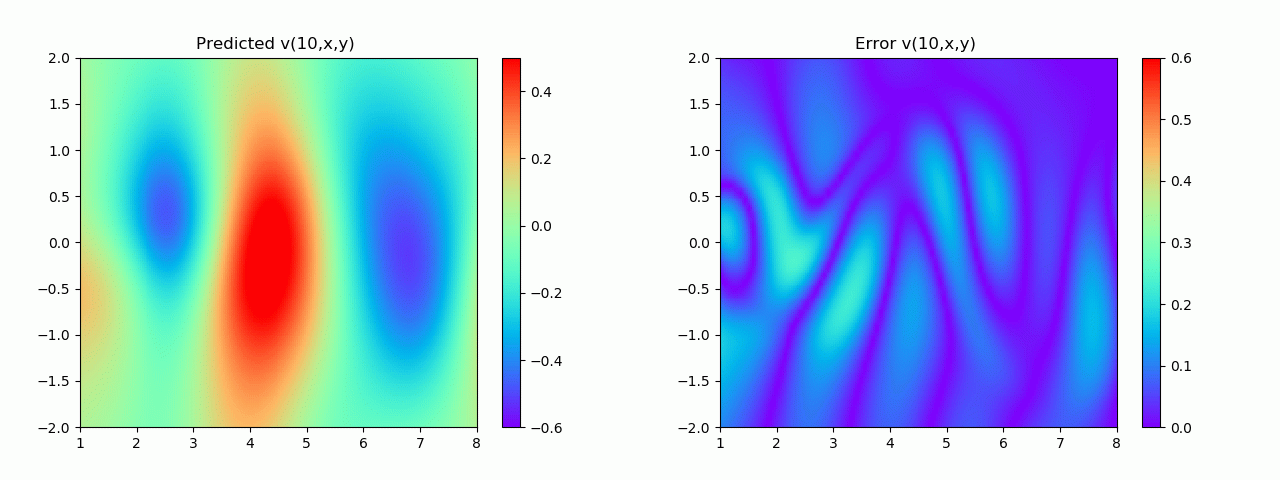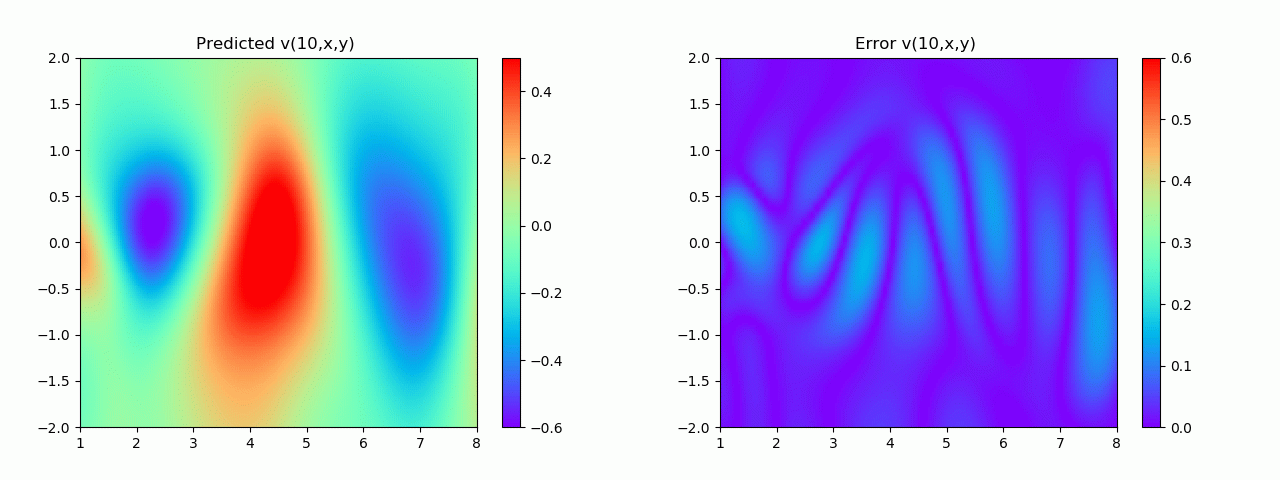
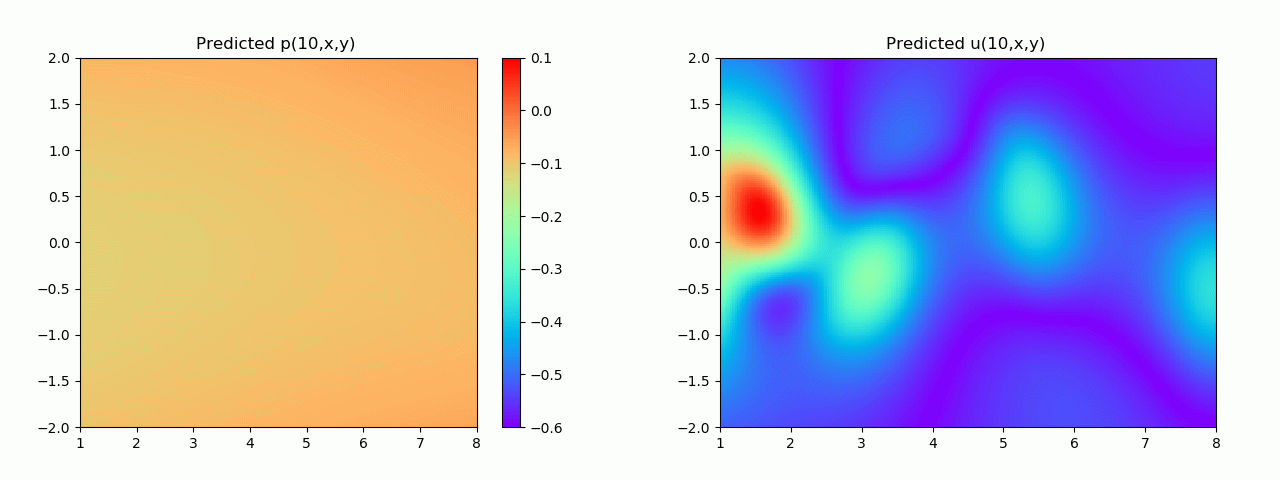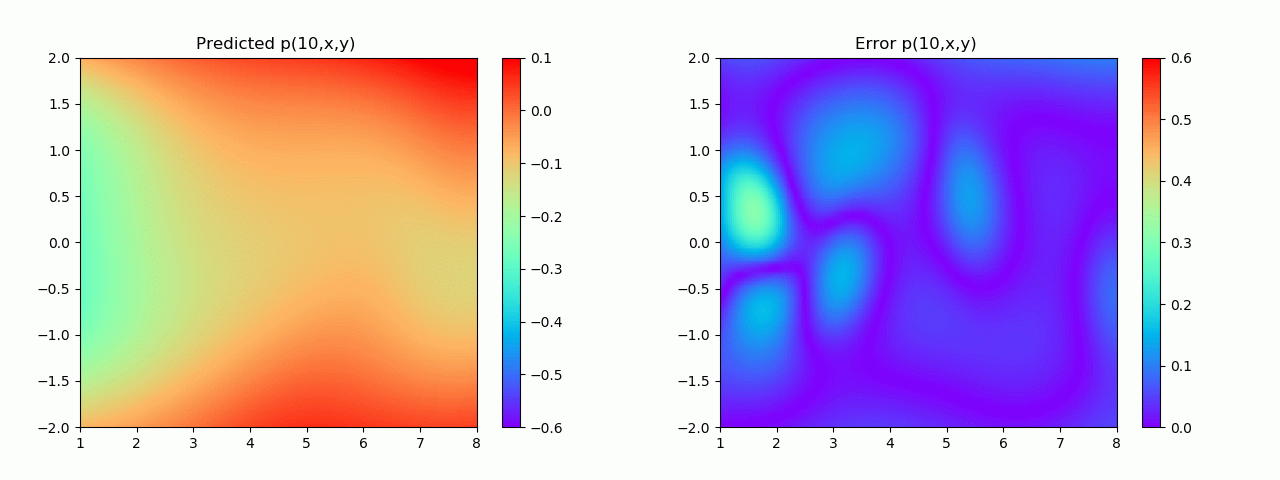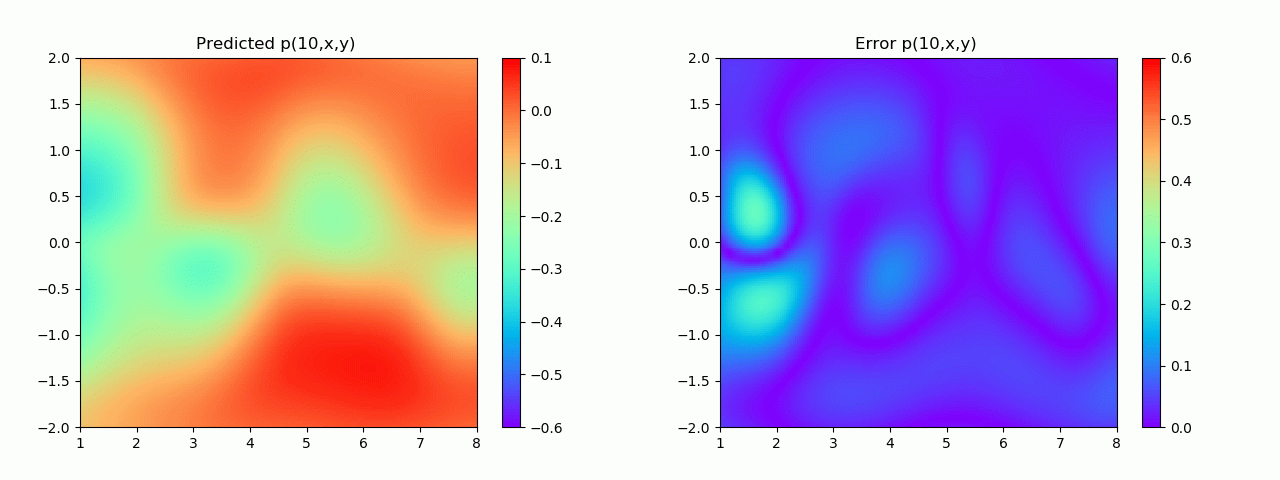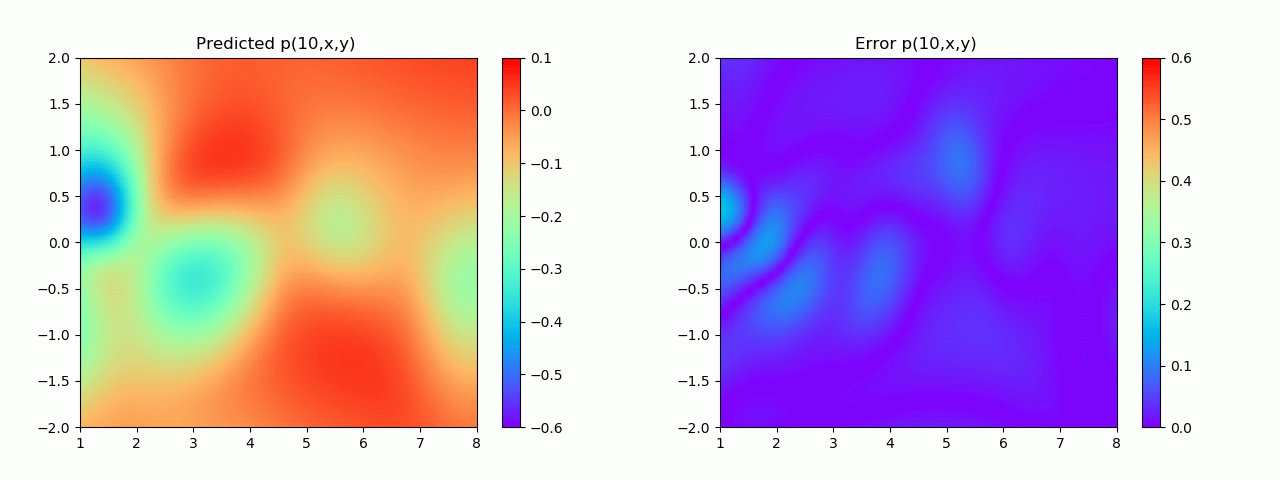
En particular, para demostrar el efecto, aquí elegimos el efecto de predicción de comparación de campo de flujo por debajo de 10 s.
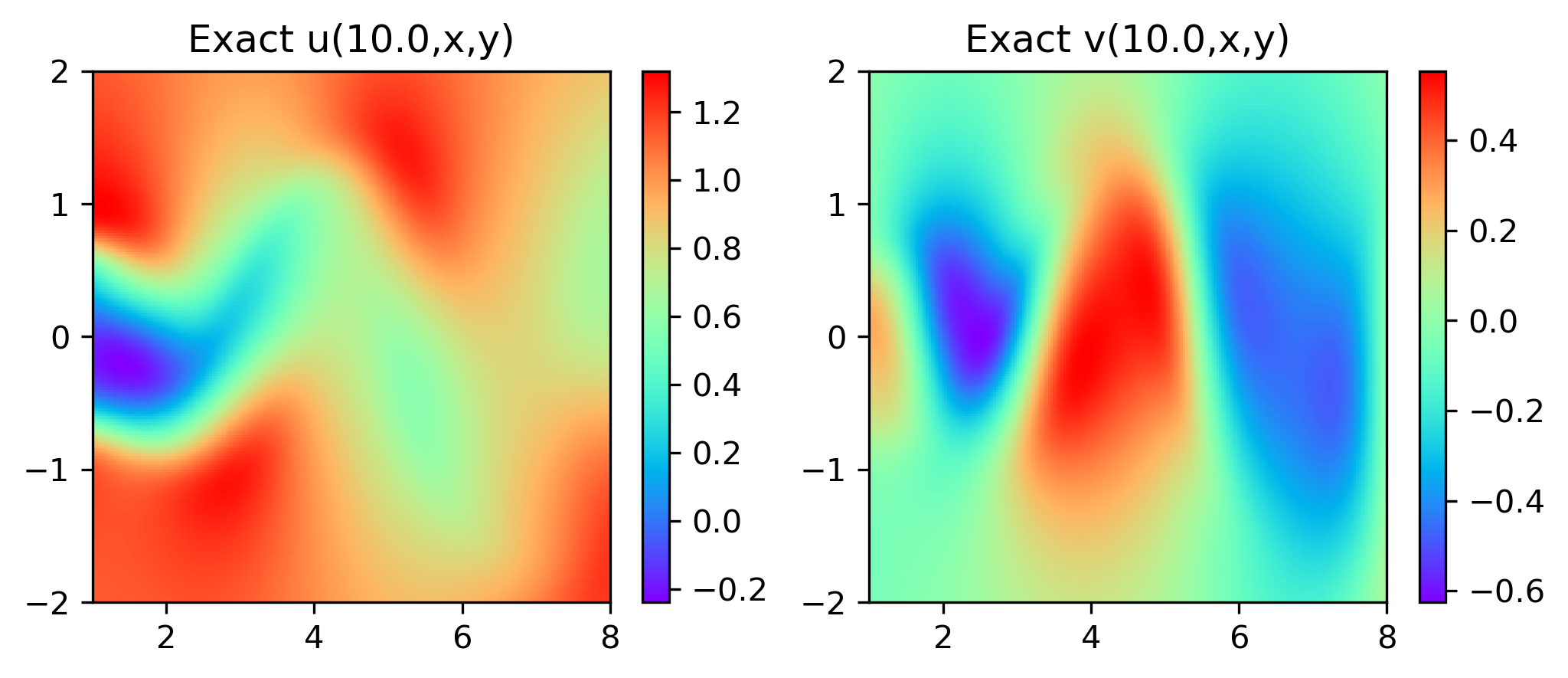
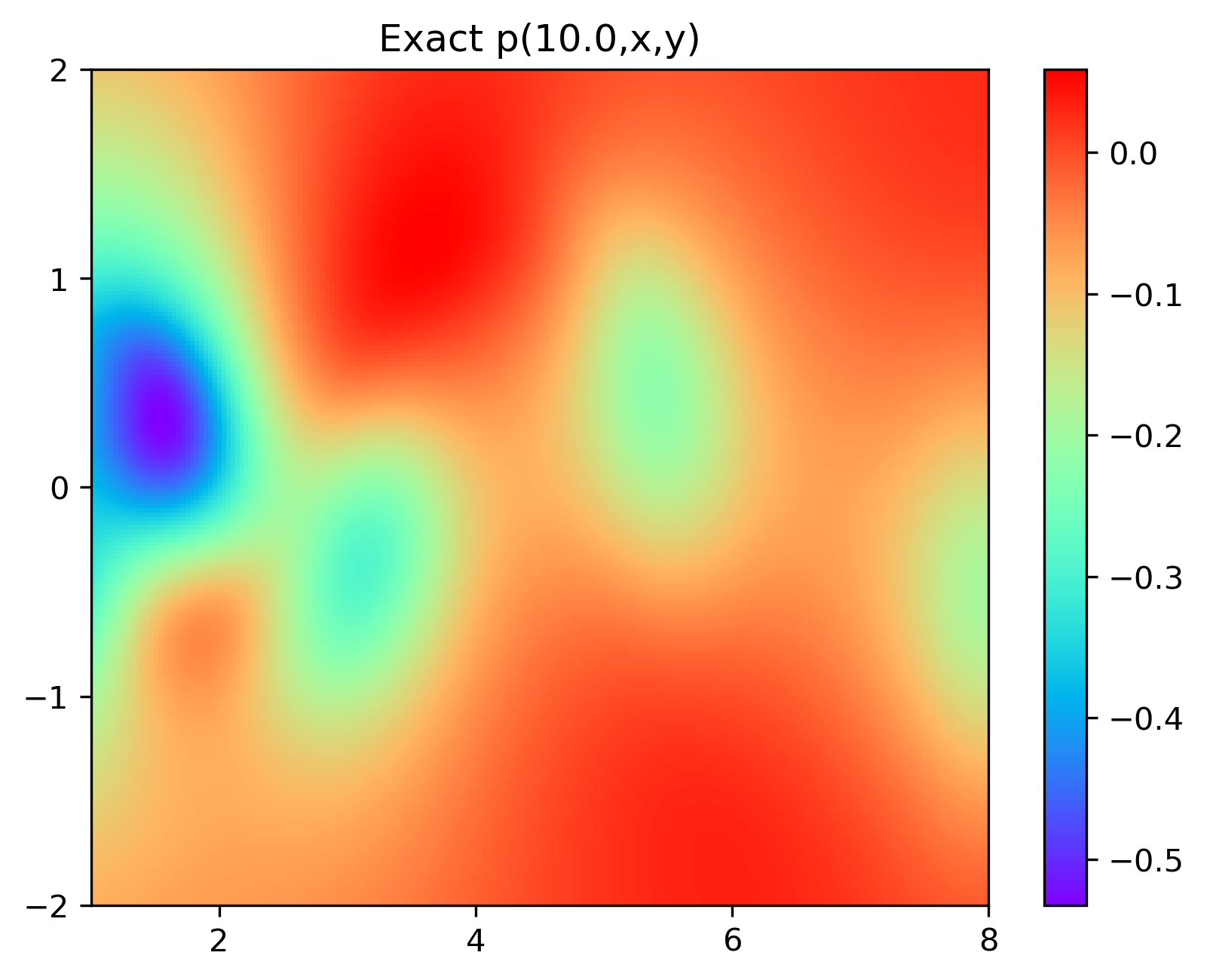
4. Visualización de resultados
4.1 Resultados experimentales del problema positivo
Los resultados experimentales se muestran en la figura 6-8 A través del entrenamiento, PINN puede lograr
una predicción