テクノロジースタック:
Flask フレームワーク、Selenium クローラー、機械学習、重回帰予測モデル、LayUI フレームワーク、Echarts ビジュアル大画面、淘宝網データ収集
このトピックの中心的な内容は、背景としてのデータ分析プラットフォームの基本的なニーズであり、プラットフォームは事前に設計されたアイデアに従って構築されます。Selenium クローラー テクノロジーを使用してデータをクロールし、Pandas でクリーンアップした後、データを MySQL にインポートし、データ視覚化テクノロジーを使用してデータを視覚的に表示します。また、機械学習の重線形回帰アルゴリズムを使用して製品の売上を予測し、バックグラウンドをインポートします。バックグラウンド管理で表示または使用します。最後に、プラットフォームはブラックボックス テストを使用してデータ管理とバックグラウンド管理に関する機能テストを実行し、テスト結果は期待どおりであり、プラットフォームは正常に動作します。
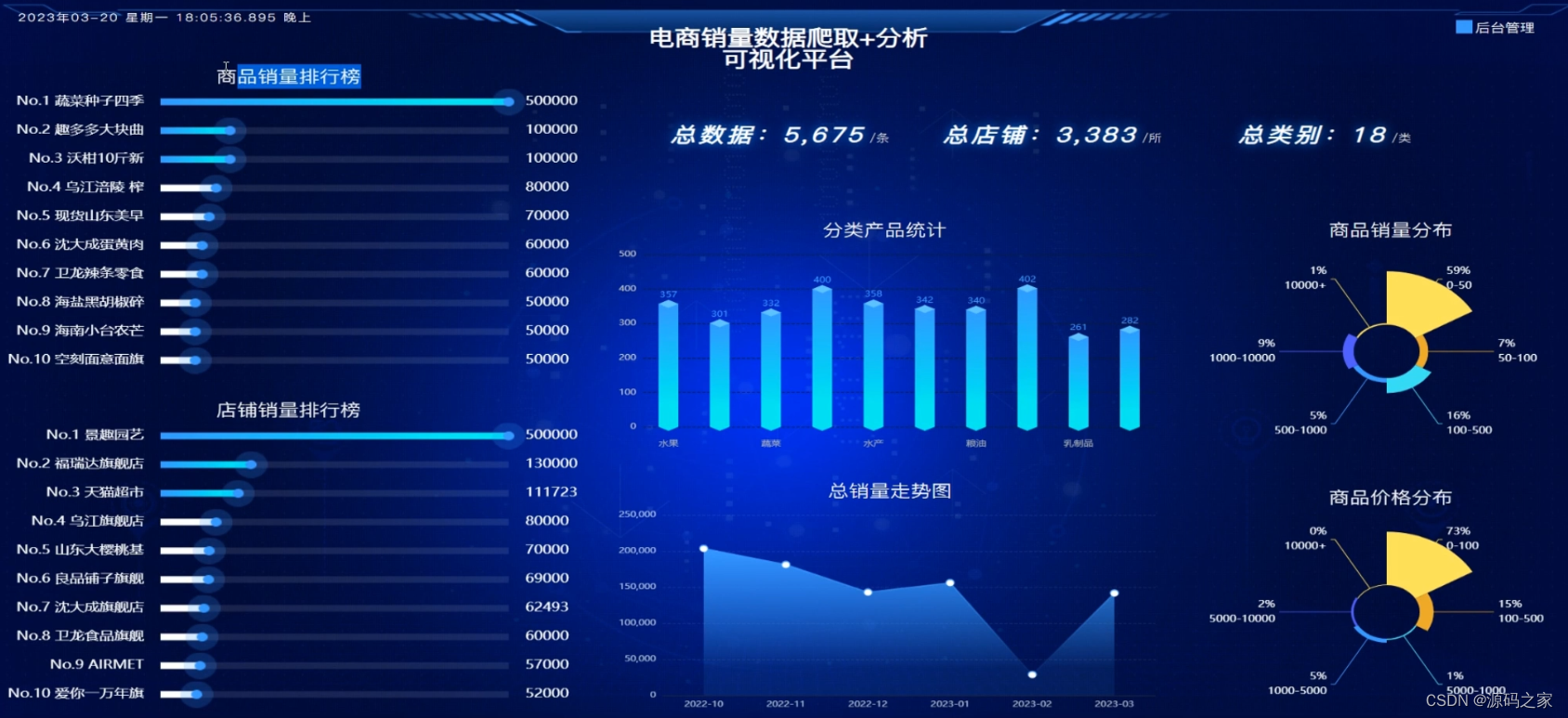
データ管理モジュールの主な目的は、データを収集、クリーニング、分析、視覚化、予測することです。そして、取得したデータをデータベースに保存し、売上予測、データ視覚化、バックグラウンド管理のさまざまなモジュールで異なるデータが必要なときにデータベースから呼び出し、対応するインターフェイスにレンダリングします。
(1) データ収集モジュールの設計
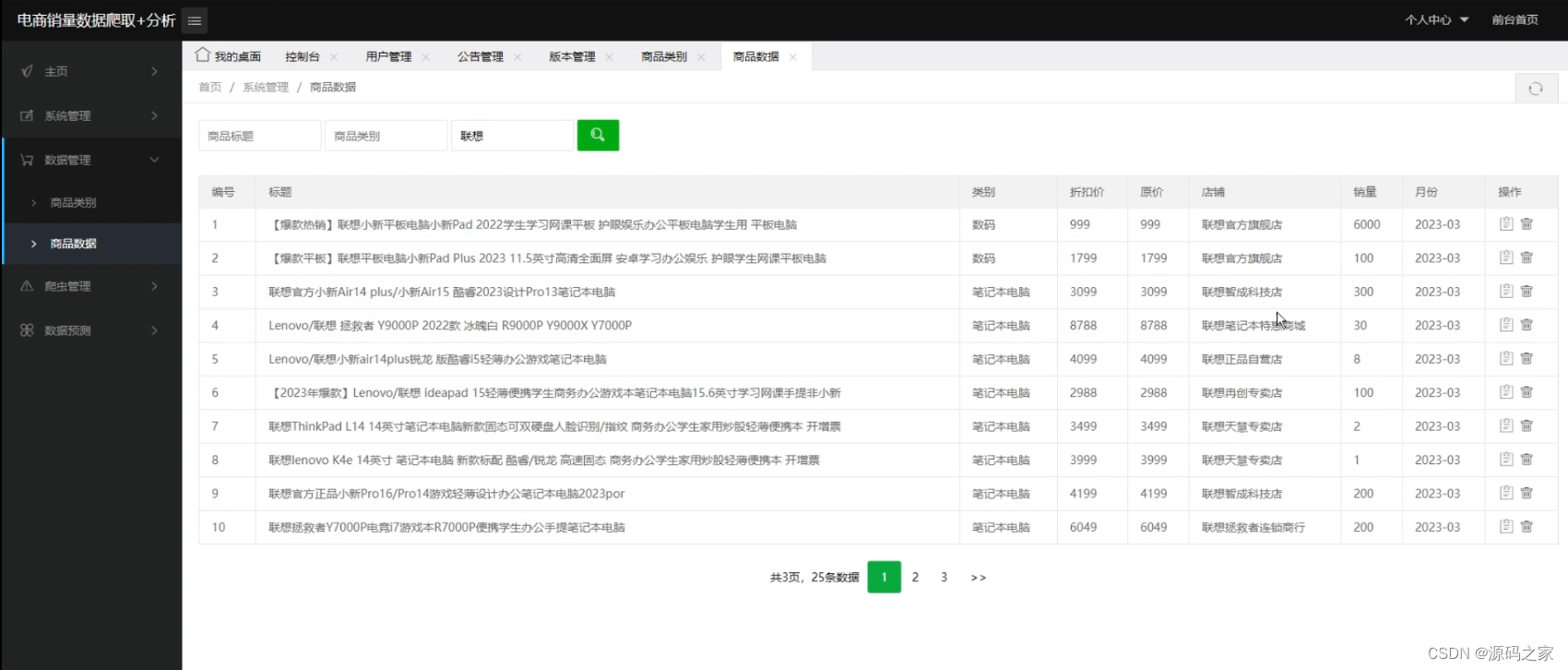
データ収集はデータ分析の基礎です。データ収集では、淘宝網の電子商取引をクローリング対象とし、セレン クローラー テクノロジーを使用して製品関連データをクローリングし、それらをさまざまな製品カテゴリに分割します。null 値と異常値については、 Python の Numpy ライブラリと Pandas データベースは、データ内のダーティ データと空のデータを削除し、データを正規化し、さまざまな指標を分析して、データをデータベースに保存します。必要に応じてデータを取り出し、後続のデータ視覚化と機械学習にデータを提供します。
一般的なデータ ソースは、オープン データ ソース、クローラー、ログ収集、センサーの 4 つのカテゴリに分類されます。本稿ではデータ収集を実現するためにクローラクローリングの手法を採用した。Selenium は、ブラウザを開いた後の人間の動作を模倣し、Web ページ上のさまざまな情報を直接抽出できる自動テスト ツールです。
(2) データ予測モジュールの設計
正確な販売予測は、在庫過剰や在庫不足によって引き起こされる利益損失を効果的に削減し、管理者がマーケティング戦略をより適切に策定し、顧客満足度を向上させるのに役立ち、コミュニティ電子商取引が長期的な競争上の優位性を確立することができます。データ予測部分では、事前にデータを分析し、データの基本的な特性を理解し、データの特性に応じて前処理を行い、データを機械学習に必要な形式に変換する必要があります。機械学習重線形回帰アルゴリズムを使用して予測モデルを構築すると、データ プールに基づいてトレーニング セット、検証セット、テスト セットを分割できます。トレーニング セット データはモデルのトレーニングに使用され、モデルは特徴値とターゲット変数の間のマッピング関係を学習できます。モデルのパフォーマンスは、損失関数を最小化することによって評価されます。正しいアルゴリズムを選択した後、より良いパフォーマンスを得るためにハイパーパラメーターを調整して改善することができます。最後に、テスト セットで評価した後、モデルを適用します。
(3) データ可視化モジュールの設計
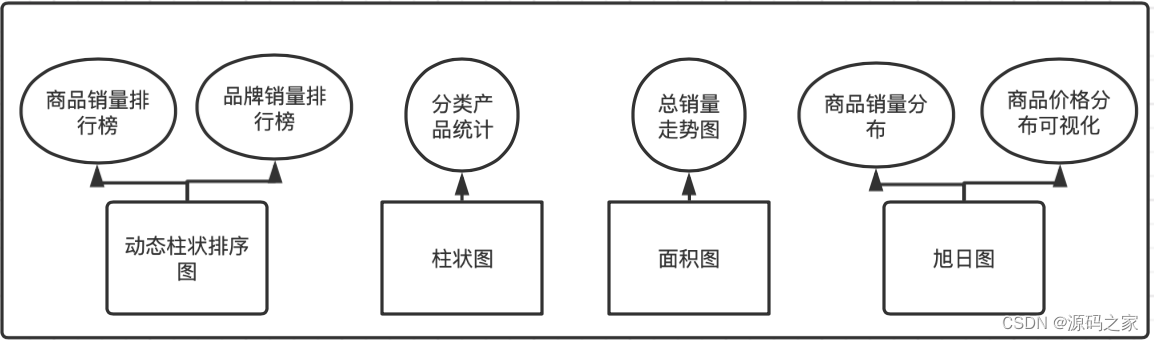
可視化は、過去の商品売上ランキング、ブランド売上ランキング、分類された製品統計、総売上推移グラフ、商品売上分布、商品価格分布の可視化に分かれています。商品売上ランキングとブランド売上ランキングは、淘宝網の売上と製品名、ブランドの売上とブランド名をクロールし、データの特性とデータ視覚化チャートの特性に従って、echartsで動的な列ソートチャートを選択して、製品をより詳しく表示します売上データとブランド売上データ、分類された製品統計グラフは、タオバオがクロールした商品データに従って分類され、製品カテゴリの数がカウントされ、表示する製品カテゴリ数の特性に応じてヒストグラムが選択されます。 ;クロールと月次売上統計には、この時点でレンダリングするエリアマップを使用し、エリアの変化を通じて売上の変化がわかります;製品の売上の分布と商品の価格の分布に応じて、サンマップを使用しますレンダリングする。ビジュアル表示ページには、コミュニティ電子商取引データ分析プラットフォームによって表示されるデータを要約する必要があり、店舗の合計数、データ量の合計、カテゴリの合計を含める必要があります。
管理者とユーザーが対応するバックグラウンド管理に簡単にアクセスできるように、バックグラウンド管理ボタンがジャンプするように設定されています。ログインしていない場合はログイン ページにジャンプし、すでにログインしている場合は直接ジャンプします。バックグラウンド管理ページ。
プロジェクトのソースコード部分:

コミュニティ電子商取引によって生成される大量のデータについては、データ分析プラットフォームを使用してデータを詳細にマイニングし、企業やユーザーにとっての価値を見つけ出します。コミュニティ電子商取引企業はこれらのデータを使用し、現在の疫病の状況と製品の売上高 今日のコミュニティ電子商取引プラットフォームの爆発的な流入において、意思決定とマーケティング戦略は有利な位置を占めています。
複雑な商品データと現在の疫病状況の不安定な経済市場に直面して、コミュニティの電子商取引データをクローリングし、データの特性と一致する重回帰アルゴリズムを使用して売上を予測し、シンプルなデータ視覚化を使用します。コミュニティを表示する eコマースデータ分析プラットフォームは、データ収集、データ保管、データ分析、データ可視化、プラットフォーム管理の課題をワンストップで解決します。コミュニティ電子商取引だけでなく、金融、鉱業、メディアなどの他の業界でも同様のデータ分析プラットフォームを構築して商品データを分析し、データ情報の裏にある付加価値の獲得を優先し、企業の競争力を強化することができます。
論文の主な仕事は次のとおりです。
まず、コミュニティ電子商取引プラットフォームの現状を分析する。
第二に、このプラットフォームで使用されている香港のテクノロジーを徹底的に分析し、Flask、Bootstrap、Lay-UIフレームワークを合理的に使用し、内部フレームワークと基本原則を分析し、Ajax、Echarts、Selenium、およびマシンを導入および分析します。同時に学ぶこと。
第三に、プラットフォーム全体のシステム設計を分析し、システムの 2 つのコア セクション (データ クローリングと販売予測) の設計に焦点を当て、システム全体を段階的に構築しました。
4 番目に、プラットフォームの機能テストと非機能テストを実行します。
プロジェクトのソースコード共有、相互学習、相互進歩~