이전 글 "R Language Drawing Cox Regression Survival Curve (Kaplan-Meier) for Complex Sampling Design"에서 jskm 패키지의 svykm 기능을 사용하여 복잡한 샘플링 설계 데이터에 대한 cox 회귀 생존 곡선(Kaplan-Meier)을 그리는 방법을 소개했습니다. 데이터"라는 글을 올렸지만, 아직 상세하지 않다는 팬분들이 계셨고, 좀 더 상세했으면 하는 바램이 있습니다. 오늘 계속해서 소개하도록 하겠습니다.
먼저 R 패키지와 데이터를 가져옵니다.
library(jskm)
library(survey)
library(jskm)
pbc<-read.csv("E:/r/test/pbc.csv",sep=',',header=TRUE)

이것은 원발성 담즙성 담관염의 데이터, 공식 계정 답변: 담관염 데이터, 데이터를 얻을 수 있음, 데이터는
나중에 사용할 여러 변수를 설명합니다, 연령: 나이, trt: 치료 계획: 1D-penem, 2 위약, 부종 : 부종, 상태: 결과 변수 0/1/2는 재검토, 이식, 사망을 의미합니다.
먼저 작은 작업을 수행하고 예측값을 생성하고 다음 작업을 기다리겠습니다. 마음에 들지 않으면 이 부분을 건너뛸 수 있으며 후속 작업에는 영향을 미치지 않습니다.
pbc$randomized <- with(pbc, !is.na(trt) & trt>0)
biasmodel <- glm(randomized~age*edema,data=pbc)
pbc$randprob <- fitted(biasmodel)
예측값 randprob을 생성한 후 이를 정식으로 분석할 수 있습니다.먼저 설문조사 데이터를 생성합니다.
dpbc <- svydesign(id=~1, prob=~randprob, strata=~edema, data=subset(pbc,randomized))
svykm 함수를 직접 사용하여 예측 값을 생성하고 여기에서도 신뢰할 수 있는 간격을 유지해야 합니다.
s1 <- svykm(Surv(time,status>0)~sex, design=dpbc,se=T)
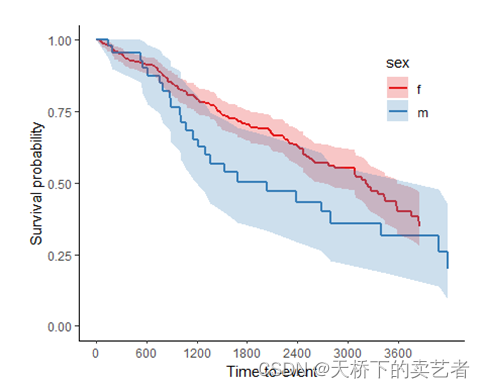
이제 svyjskm 함수를 직접 사용하여 그림을 그립니다.
svyjskm(s1)
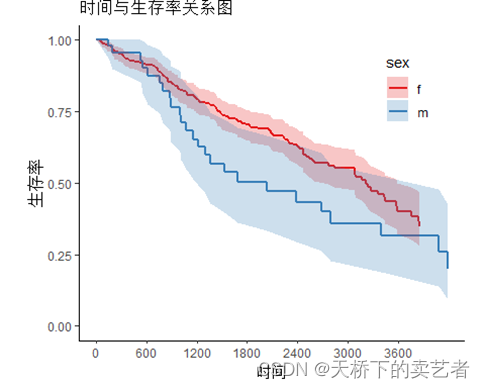
X축, Y축 레이블 및 제목 변경
svyjskm(s1,xlabs = "时间",ylabs = "生存率",main = "时间与生存率关系图")
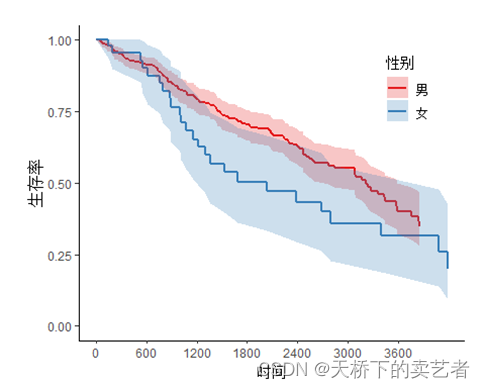
범례를 변경합니다.
svyjskm(s1,xlabs = "时间",ylabs = "生存率",ystrataname = "性别",ystratalabs=c("男","女"))
X축의 범위를 제한하고 Y축에 대해서도 동일하게 제한합니다.
svyjskm(s1,xlabs = "时间",ylabs = "生存率",ystrataname = "性别",
ystratalabs=c("男","女"),xlims=c(0,3000))
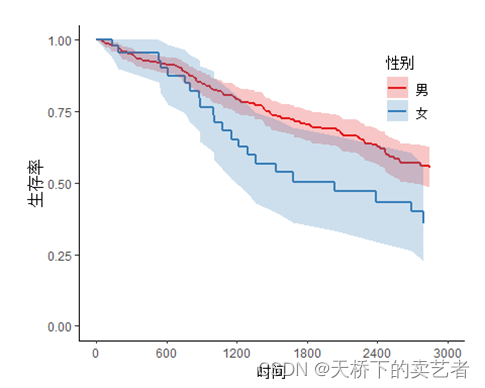
백분율로 표시되도록 Y축 변경
svyjskm(s1,xlabs = "时间",ylabs = "生存率",ystrataname = "性别",
ystratalabs=c("男","女"),surv.scale="percent")
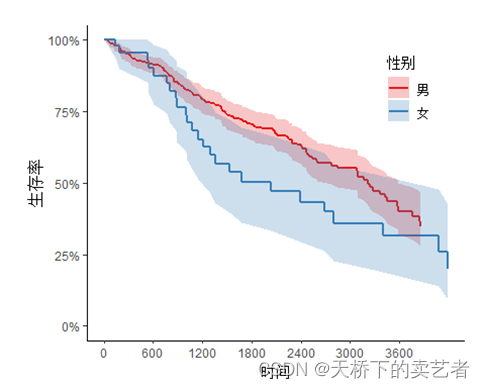
표시되는 시간 축 포인트의 수를 변경합니다. 기본값은 7포인트입니다.
svyjskm(s1,xlabs = "时间",ylabs = "生存率",ystrataname = "性别",
ystratalabs=c("男","女"),timeby=700)
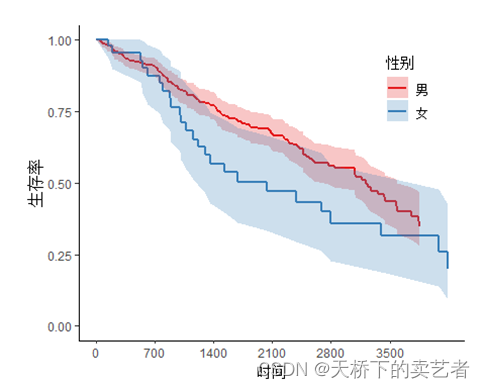
플롯에서 P 값 생성
svyjskm(s1,xlabs = "时间",ylabs = "生存率",ystrataname = "性别",
ystratalabs=c("男","女"),timeby=700,pval=T)
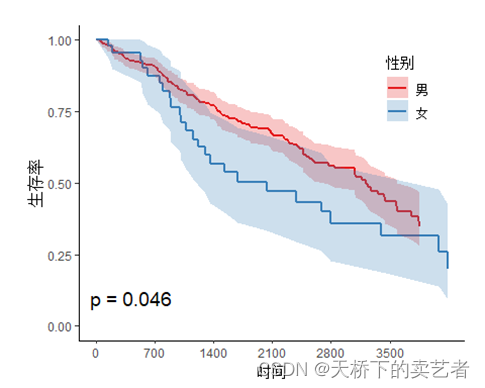
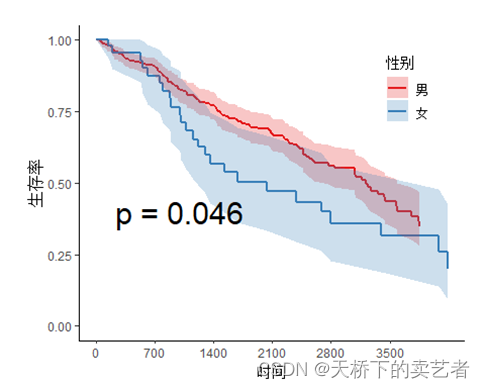
텍스트에서 P 값의 위치 및 글꼴 크기 조정
svyjskm(s1,xlabs = "时间",ylabs = "生存率",ystrataname = "性别",
ystratalabs=c("男","女"),timeby=700,pval=T,pval.coord=c(1000,0.4),pval.size=8)
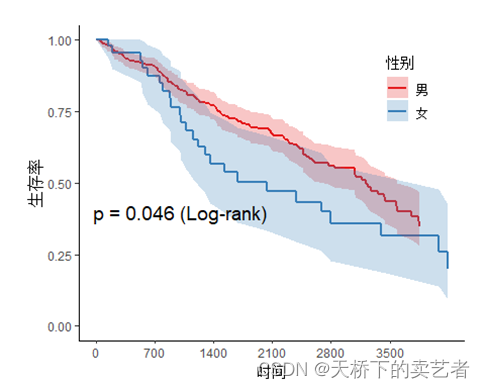
P 값 뒤에 로그 순위 추가
svyjskm(s1,xlabs = "时间",ylabs = "生存率",ystrataname = "性别",
ystratalabs=c("男","女"),timeby=700,pval=T,
pval.coord=c(1000,0.4),pval.testname=T)
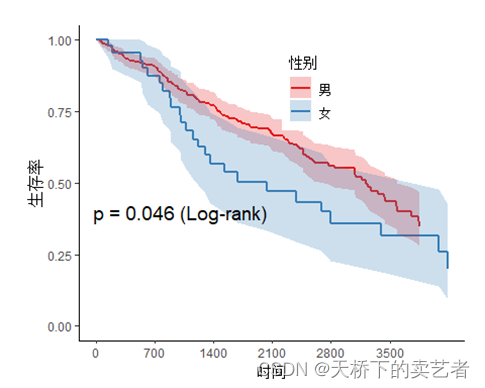
범례 위치 조정
svyjskm(s1,xlabs = "时间",ylabs = "生存率",ystrataname = "性别",
ystratalabs=c("男","女"),timeby=700,pval=T,
pval.coord=c(1000,0.4),pval.testname=T,legendposition=c(0.6,0.8))
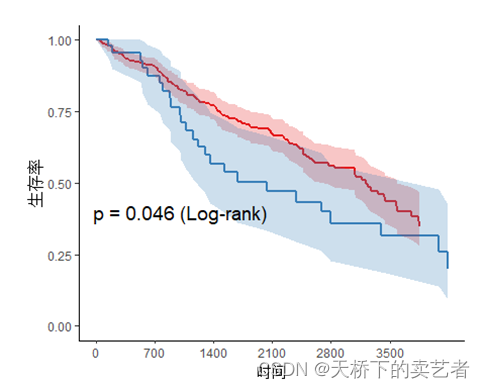
범례를 표시하지 않음
svyjskm(s1,xlabs = "时间",ylabs = "生存率",ystrataname = "性别",
ystratalabs=c("男","女"),timeby=700,pval=T,
pval.coord=c(1000,0.4),pval.testname=T,legendposition=c(0.6,0.8),legend=F)
색상 스타일을 변경합니다. 기본값은 Set1입니다.
svyjskm(s1,xlabs = "时间",ylabs = "生存率",ystrataname = "性别",
ystratalabs=c("男","女"),timeby=700,pval=T,
pval.coord=c(1000,0.4),pval.testname=T,linecols="Set2")
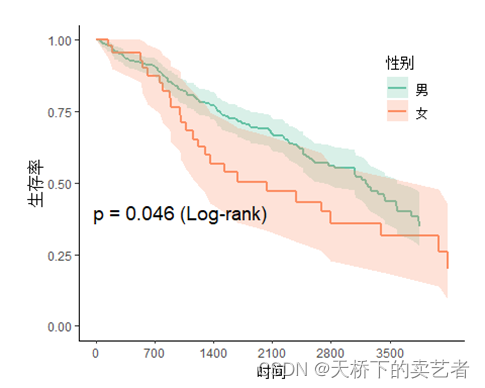
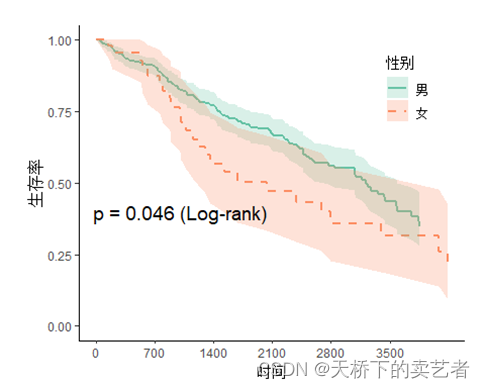
dashed는 점선을 설정하는데 한 줄만 설정할 수 있는 것 같습니다.
svyjskm(s1,xlabs = "时间",ylabs = "生存率",ystrataname = "性别",
ystratalabs=c("男","女"),timeby=700,pval=T,
pval.coord=c(1000,0.4),pval.testname=T,linecols="Set2",dashed=T)
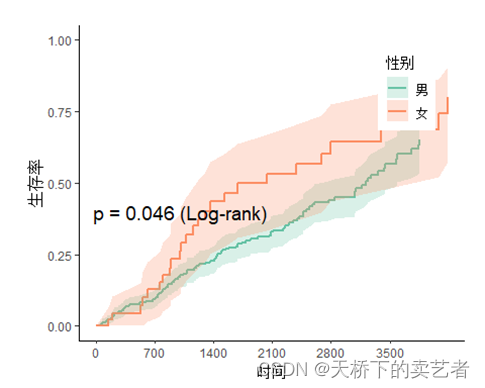
누적 발생률 함수 표시
svyjskm(s1,xlabs = "时间",ylabs = "生存率",ystrataname = "性别",
ystratalabs=c("男","女"),timeby=700,pval=T,
pval.coord=c(1000,0.4),pval.testname=T,linecols="Set2",cumhaz=T)
ggpubr::ggarrange 함수를 호출하여 테이블을 구성하는 것이 많은 영감을 주었습니다.
svyjskm(s1,xlabs = "时间",ylabs = "生存率",ystrataname = "性别",
ystratalabs=c("男","女"),timeby=700,pval=T,
pval.coord=c(1000,0.4),pval.testname=T,linecols="Set2",table=T)
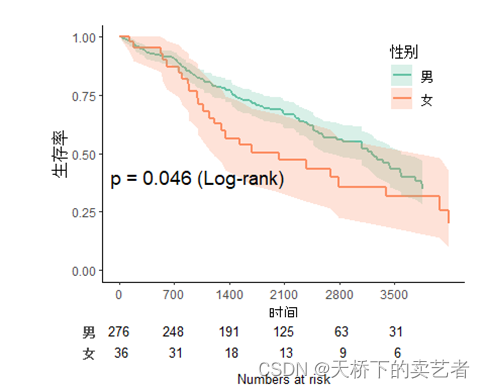
표 아래 자막 이름 수정
svyjskm(s1,xlabs = "时间",ylabs = "生存率",ystrataname = "性别",
ystratalabs=c("男","女"),timeby=700,pval=T,
pval.coord=c(1000,0.4),pval.testname=,
linecols="Set2",table=T,label.nrisk="生存人数")
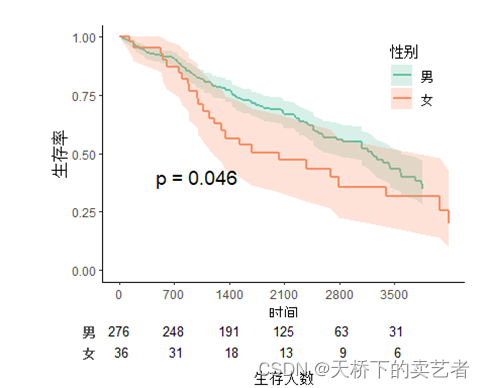
Numbers at risk 글꼴 크기를 설정합니다. 기본값은 10입니다.
svyjskm(s1,xlabs = "时间",ylabs = "生存率",ystrataname = "性别",
ystratalabs=c("男","女"),timeby=700,pval=T,
pval.coord=c(1000,0.4),pval.testname=T,
linecols="Set2",table=T,label.nrisk="生存人数",size.label.nrisk=12)
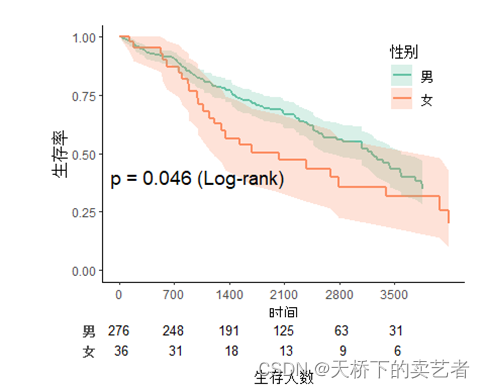
곡선에 백분율 표시 추가
svyjskm(s1,xlabs = "时间",ylabs = "生存率",ystrataname = "性别",
ystratalabs=c("男","女"),timeby=700,pval=T,
pval.coord=c(1000,0.4),pval.testname=T,
linecols="Set2",table=T,label.nrisk="生存人数",size.label.nrisk=12,showpercent = T)
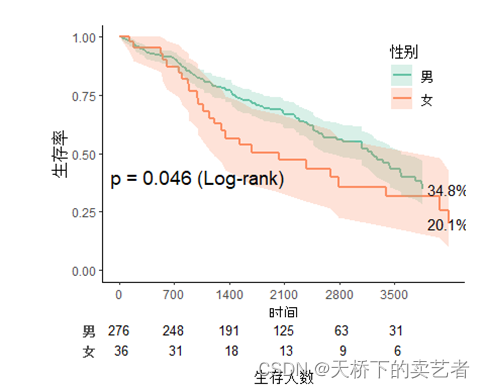
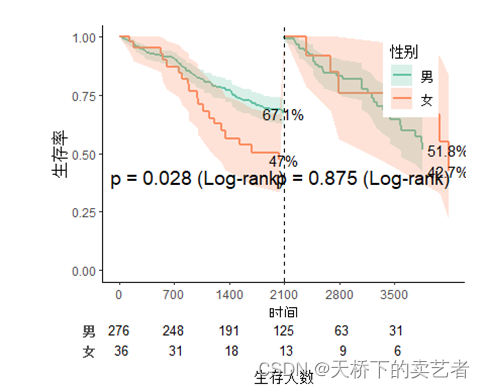
cut.landmark는 새로운 랜드마크를 설정하는 것입니다.
svyjskm(s1,xlabs = "时间",ylabs = "生存率",ystrataname = "性别",
ystratalabs=c("男","女"),timeby=700,pval=T,
pval.coord=c(1000,0.4),pval.testname=T,
linecols="Set2",table=T,label.nrisk="生存人数",size.label.nrisk=12,showpercent = T,cut.landmark=2100)