Este artículo se reproduce de Qubit.
Fengse se envía desde el qubit cóncavo no si
| cuenta pública QbitAI
Todos sabemos que la simplicidad y la legibilidad de Python se obtienen a expensas del rendimiento——
Especialmente en casos computacionalmente intensivos como bucles for múltiples.
Pero ahora, el jefe Hu Yuanming dijo:
¡Simplemente importe una biblioteca llamada "Taichi" y podrá acelerar su código 100 veces !

¿No creen?
Veamos tres ejemplos.
Calcular el número de números primos, velocidad x120
El primer ejemplo es muy, muy simple, encuentra todos los números primos menores que un entero positivo dado N.
La respuesta estándar es la siguiente:
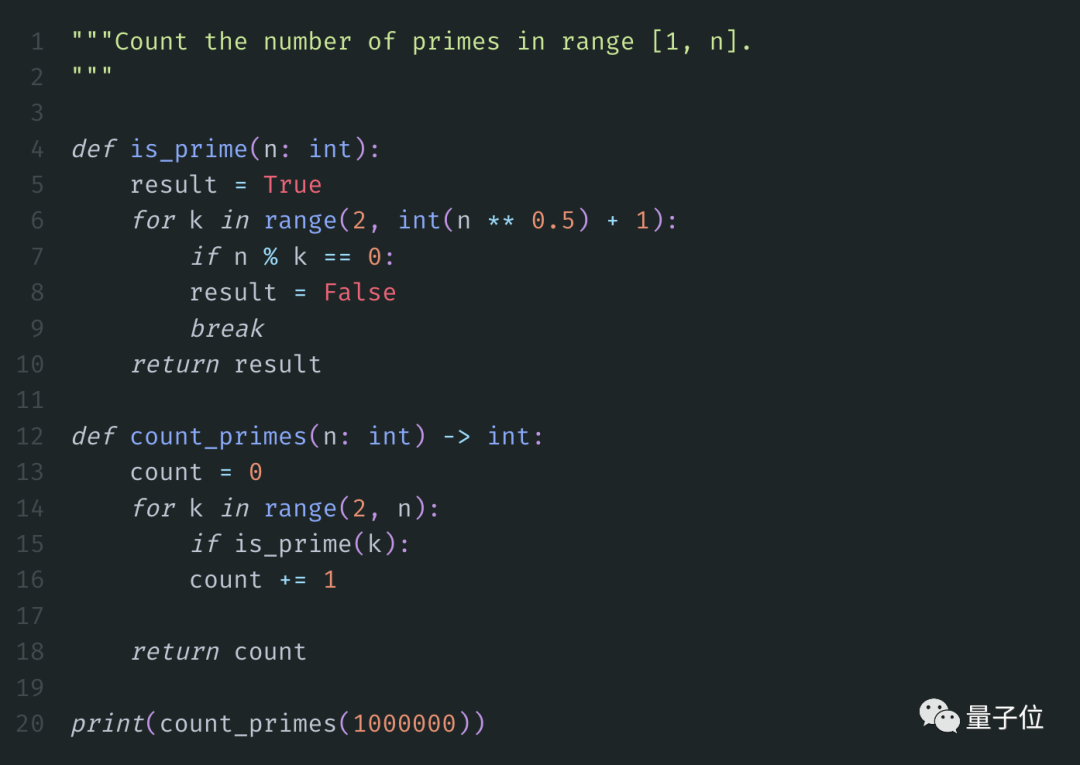
Guardamos el código anterior y lo ejecutamos.
Cuando N es 1 millón, se necesitan 2,235 s para obtener el resultado:

Ahora, hagamos la magia.
Sin cambiar ningún cuerpo de función, importe la biblioteca "taichi" y luego agregue dos decoradores:
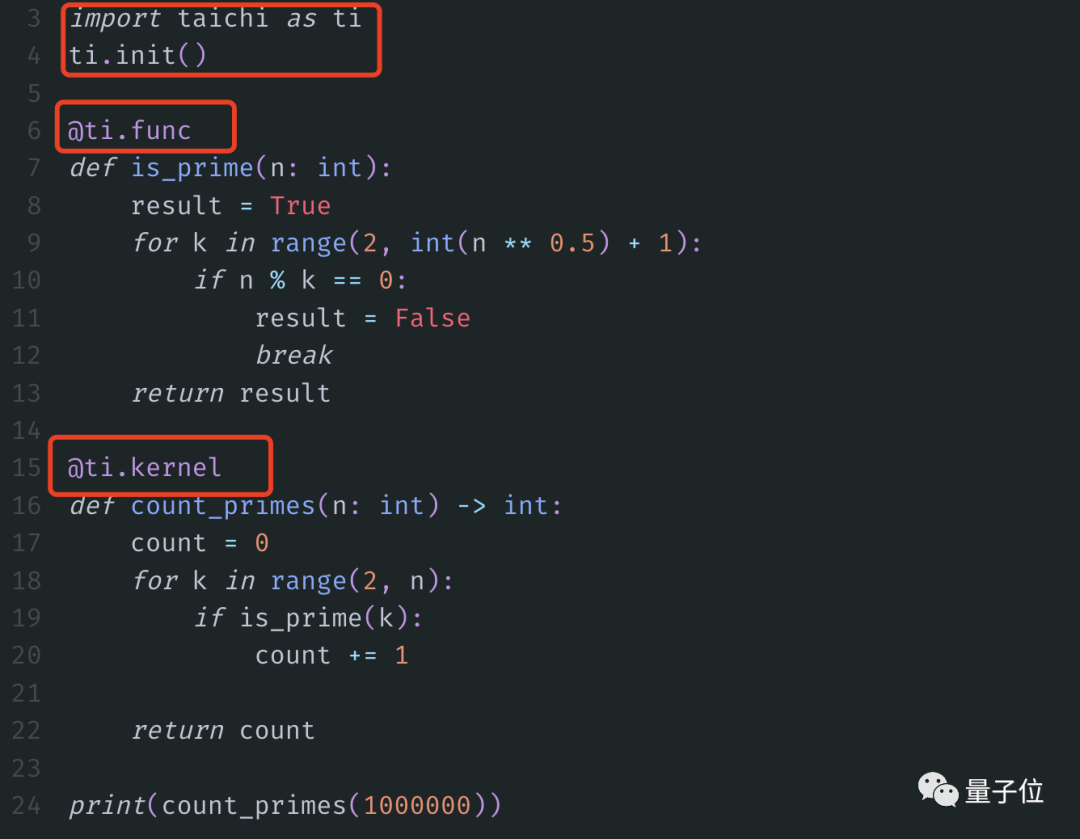
¡Bingo! El mismo resultado solo toma 0.363s, casi 6 veces más rápido.

Si N = 10 millones, solo toma 0,8 s; ya sabes, sin él, toma 55 s, ¡lo que es 70 veces más rápido !
No solo eso, también podemos agregar un parámetro a ti.init() a ti.init(arch=ti.gpu) para permitir que taich realice cálculos en la GPU .
Entonces, en este momento, solo se necesitan 0,45 s para calcular todos los números primos menores de 10 millones, ¡lo cual es 120 veces más rápido que el código Python original !
¿Es genial?
¿Qué? ¿Crees que este ejemplo es demasiado simple y no lo suficientemente convincente? Veamos uno un poco más complicado.
Programación dinámica, velocidad x500
No hace falta decir que la programación dinámica, como algoritmo de optimización, reduce el tiempo de cálculo al almacenar dinámicamente los resultados de los cálculos intermedios.
Tomemos como ejemplo el caso clásico de programación dinámica "Problema de la subsecuencia común más larga (LCS)" en el libro de texto clásico "Introducción a los algoritmos" .
Por ejemplo, para la secuencia a = [0, 1, 0, 2, 4, 3, 1, 2, 1] y la secuencia b = [4, 0, 1, 4, 5, 3, 1, 2], su LCS es:
MC(a, b) = [0, 1, 4, 3, 1, 2]。
Calcular LCS con la idea de programación dinámica es primero resolver la longitud de la subsecuencia común más larga de los primeros i elementos de la secuencia a y los primeros j elementos de la secuencia b, y luego aumentar gradualmente el valor de i o j, repetir el proceso y obtener el resultado.
Usamos f[i, j] para referirnos a la longitud de esta subsecuencia, es decir, LCS((prefix(a, i), prefix(b, j). Entre ellos, prefix(a, i) representa la primera i elementos de la secuencia a , a saber a[0], a[1], ..., a[i - 1], se obtiene la siguiente relación de recurrencia:

El código completo es el siguiente:

Ahora, usamos Taichi para acelerar:
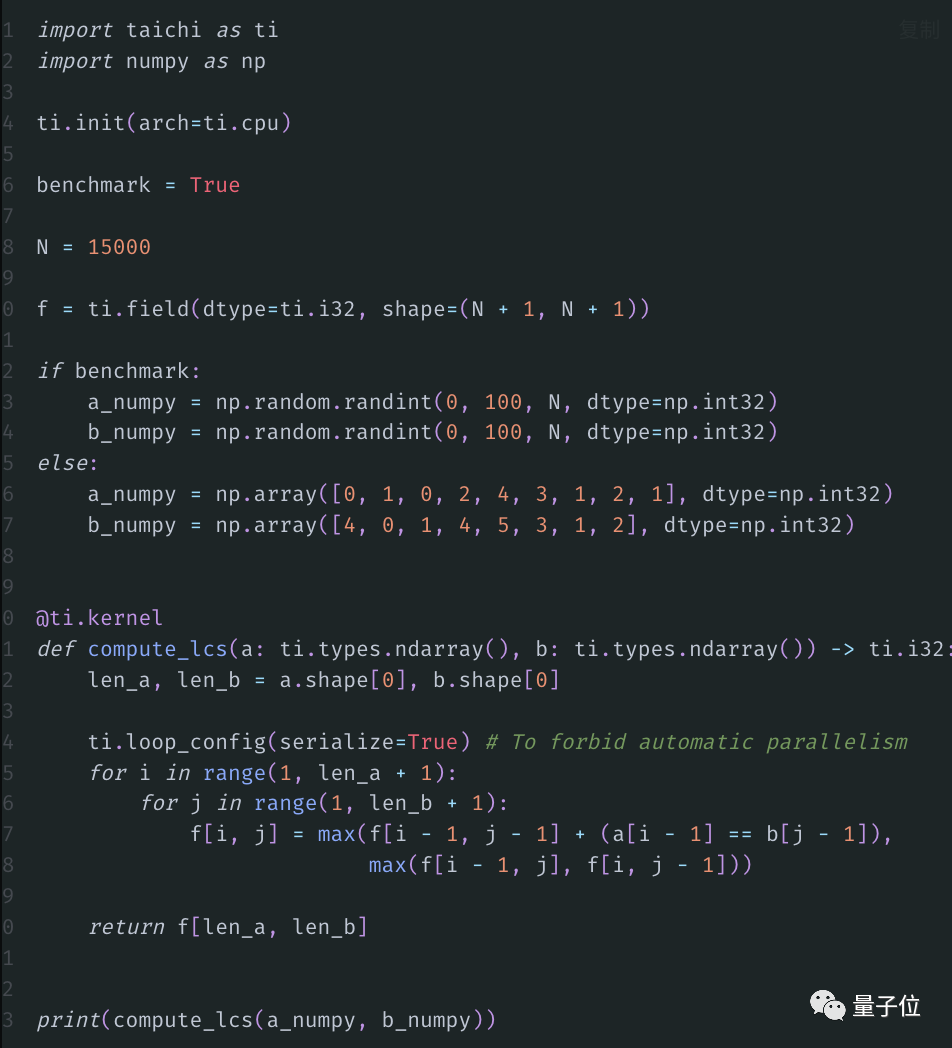
El resultado es el siguiente:

El programa en la computadora de Hu Yuanming se puede completar en 0,9 segundos como máximo , mientras que se necesitan 476 segundos para implementarlo con NumPy, ¡la diferencia es más de 500 veces!
Finalmente, tomemos un ejemplo diferente.
La ecuación de reacción-difusión con efectos sorprendentes
En la naturaleza, siempre hay algunos animales con patrones que parecen desordenados pero que no son completamente aleatorios.

Alan Turing, el inventor de la máquina de Turing, fue el primero en idear un modelo para describir este fenómeno.
En este modelo, se utilizan dos productos químicos (U y V) para simular la generación de patrones. La relación entre estos dos es similar a la de presa y depredador, se mueven e interactúan por sí mismos:
Inicialmente, U y V se distribuyen aleatoriamente sobre un dominio;
En cada paso de tiempo, se difunden gradualmente en espacios adyacentes;
Cuando U y V se encuentran, una parte de U es tragada por V. Por tanto, la concentración de V aumenta;
Para evitar que U sea erradicado por V, agregamos un cierto porcentaje (f) de U y eliminamos un cierto porcentaje (k) de V en cada paso de tiempo.
El proceso anterior se describe como la "ecuación de reacción-difusión":
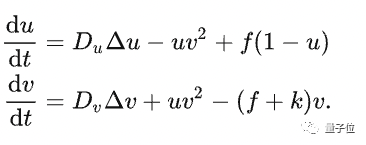
Hay cuatro parámetros clave: Du ( la velocidad de difusión de U), D v (la velocidad de difusión de V), f (la abreviatura de feed, que controla la adición de U) y k (la abreviatura de kill, que controla la eliminación de V).
Si esta ecuación se implementa en Taichi, primero cree cuadrículas para representar dominios y use vec2 para representar los valores de concentración de U, V en cada cuadrícula.
El cálculo de los valores laplacianos requiere acceso a cuadrículas adyacentes. Para evitar actualizar y leer datos en el mismo bucle, debemos crear dos cuadrículas de la misma forma W×H×2.
Cada vez que se accede a los datos desde una cuadrícula, escribimos los datos actualizados en otra cuadrícula y luego cambiamos a la siguiente cuadrícula. Entonces el diseño de la estructura de datos es así:

Inicialmente, establecemos la concentración de U en la cuadrícula en 1 y colocamos V en 50 ubicaciones elegidas al azar:

Luego, el cálculo real se puede realizar en menos de 10 líneas de código:
@ti.kernel
def compute(phase: int):
for i, j in ti.ndrange(W, H):
cen = uv[phase, i, j]
lapl = uv[phase, i + 1, j] + uv[phase, i, j + 1] + uv[phase, i - 1, j] + uv[phase, i, j - 1] - 4.0 * cen
du = Du * lapl[0] - cen[0] * cen[1] * cen[1] + feed * (1 - cen[0])
dv = Dv * lapl[1] + cen[0] * cen[1] * cen[1] - (feed + kill) * cen[1]
val = cen + 0.5 * tm.vec2(du, dv)
uv[1 - phase, i, j] = valAquí usamos una fase entera (0 o 1) para controlar de qué cuadrícula leemos los datos.
El último paso es colorear el resultado de acuerdo con la concentración de V, y puedes obtener un patrón tan sorprendente :

Curiosamente, Hu Yuanming introdujo que incluso si la concentración inicial de V se establece al azar, se pueden obtener resultados similares cada vez.
Y en comparación con la implementación de Numba que solo puede alcanzar unos 30 fps, la implementación de Taichi puede superar fácilmente los 300 fps porque la GPU se puede seleccionar como backend.
instalar pip para instalar
Después de leer los tres ejemplos anteriores, ¿lo crees ahora?
De hecho, Taichi es un DSL (Dynamic Scripting Language) integrado en Python. Utiliza su propio compilador para compilar las funciones decoradas por @ti.kernel en varios hardware, incluidos CPU y GPU, y luego realiza una computación de alto rendimiento.
Con él, ya no tendrá que envidiar el rendimiento de C++/CUDA.
Como sugiere el nombre, Taichi proviene del equipo de Taichi Graphics Hu Yuanming. Ahora solo necesita usar pip install para instalar esta biblioteca e interactuar con otras bibliotecas de Python, incluidas NumPy, Matplotlib y PyTorch.
Por supuesto, ¿cuál es la diferencia entre Taichi y estas bibliotecas y otros métodos de aceleración? Hu Yuanming también proporcionó una comparación detallada de las ventajas y desventajas. Los amigos interesados pueden hacer clic en el siguiente enlace para ver en detalle:
https://docs.taichi-lang.org/blog/accelerate-python-code-100x