Directorio de artículos
- prefacio
- 1. Seis tipos de problemas típicos de puntero nulo
-
- 1.1 Problema de puntero nulo de tipo contenedor
- 1.2 Problema de puntero nulo de llamadas en cascada
- 1.3 Problema del puntero nulo en el lado izquierdo del método Equals
- 1.4 Los contenedores como ConcurrentHashMap no admiten la clave y el valor es nulo.
- 1.5 Conjuntos, las matrices obtienen elementos directamente
- 1.6 Los objetos obtienen propiedades directamente
- 2. El hoyo de la configuración del formato de fecha YYYY
- 3. Dificultades en la precisión del cálculo del valor del importe
- 4. La codificación predeterminada de FileReader conduce a caracteres ilegibles
- Cinco, pozo de caché de enteros
- 6. Las variables estáticas estáticas se basan en variables de creación de instancias de resorte, lo que puede provocar errores de inicialización
- 7. Usando ThreadLocal, la reutilización de hilos conduce a pozos de confusión de información
- Ocho, ignora el regreso y la ruptura del interruptor.
- 9. Varios pozos de Arrays.asList
-
- 9.1 El tipo básico no se puede utilizar como parámetro del método Arrays.asList, de lo contrario se tratará como un parámetro.
- 9.2 La Lista devuelta por Arrays.asList no admite operaciones de adición y eliminación.
- 9.3 Al usar Arrays.asLis, la modificación del arreglo original afectará la Lista que obtengamos
- 10. Pozo de transferencia forzada ArrayList.toArray()
- 11. Varios pozos de uso anormal
-
- 11.1 No pierda la información de excepción de su pila
- 11.2 No defina excepciones como variables estáticas
- 11.3 No utilice e.printStackTrace() en el entorno de producción
- 11.4 ¿Qué debo hacer si ocurre una excepción durante el envío del grupo de subprocesos?
- 11.5 También se debe prestar atención a la excepción de que finalmente se vuelven a lanzar
- 12. Serialización JSON, ¡el tipo largo se convierte en tipo entero!
- Trece, use Ejecutores para declarar el grupo de subprocesos, el problema OOM de newFixedThreadPool
- 14. Dirigir archivos grandes o leer demasiados datos de la base de datos a la memoria al mismo tiempo puede causar problemas de OOM
- 15. Consulta primero, luego actualiza/elimina el problema de consistencia concurrente
- 16. La base de datos se almacena en utf-8 y se inserta el hoyo con expresión anormal
- 17. El tajo donde no se ha producido la transacción
- 18. Cuando la reflexión se encuentra con el pozo de la sobrecarga de métodos
- Diecinueve, mysql time timestamp pit
- 20. La zona horaria de la base de datos mysql8
- referencia y gracias
prefacio
Espero que pueda ser útil para todos, gracias por leer ~
1. Seis tipos de problemas típicos de puntero nulo
- Problema de puntero nulo con tipos envueltos
- Problema de puntero nulo con llamadas en cascada
- Problema de puntero nulo en el lado izquierdo del método Equals
- Los contenedores como ConcurrentHashMap no admiten que la clave y el valor sean nulos.
- Colecciones, matrices obtienen elementos directamente
- Los objetos obtienen propiedades directamente
1.1 Problema de puntero nulo de tipo contenedor
public class NullPointTest {
public static void main(String[] args) throws InterruptedException {
System.out.println(testInteger(null));
}
private static Integer testInteger(Integer i) {
return i + 1; //包装类型,传参可能为null,直接计算,则会导致空指针问题
}
}
1.2 Problema de puntero nulo de llamadas en cascada
public class NullPointTest {
public static void main(String[] args) {
//fruitService.getAppleService() 可能为空,会导致空指针问题
fruitService.getAppleService().getWeight().equals("OK");
}
}
1.3 Problema del puntero nulo en el lado izquierdo del método Equals
public class NullPointTest {
public static void main(String[] args) {
String s = null;
if (s.equals("666")) {
//s可能为空,会导致空指针问题
System.out.println("demo is ok");
}
}
}
1.4 Los contenedores como ConcurrentHashMap no admiten la clave y el valor es nulo.
public class NullPointTest {
public static void main(String[] args) {
Map map = new ConcurrentHashMap<>();
String key = null;
String value = null;
map.put(key, value);
}
}
1.5 Conjuntos, las matrices obtienen elementos directamente
public class NullPointTest {
public static void main(String[] args) {
int [] array=null;
List list = null;
System.out.println(array[0]); //空指针异常
System.out.println(list.get(0)); //空指针一场
}
}
1.6 Los objetos obtienen propiedades directamente
public class NullPointTest {
public static void main(String[] args) {
User user=null;
System.out.println(user.getAge()); //空指针异常
}
}
2. El hoyo de la configuración del formato de fecha YYYY
En el desarrollo diario, a menudo es necesario formatear la fecha, pero cuando el año se establece en YYYY en mayúsculas, existen dificultades.
Contador de ejemplo:
Calendar calendar = Calendar.getInstance();
calendar.set(2022, Calendar.DECEMBER, 31);
Date testDate = calendar.getTime();
SimpleDateFormat dtf = new SimpleDateFormat("YYYY-MM-dd");
System.out.println("2022-12-31 转 YYYY-MM-dd 格式后 " + dtf.format(testDate));
resultado de la operación:
2022-12-31 转 YYYY-MM-dd 格式后 2023-12-31
"Análisis:"
¿Por qué se cambia la fecha al 31 de diciembre de 2023, aunque es el 31 de diciembre de 2022? Debido a que YYYY se basa en la semana para calcular el año, apunta al año al que pertenece la semana del día actual. Una semana comienza el domingo y termina el sábado. Siempre que esta semana cruce el año nuevo, entonces esta semana será considerado como el próximo año. La postura correcta es utilizar el formato yyyy.
Ejemplo positivo:
Calendar calendar = Calendar.getInstance();
calendar.set(2022, Calendar.DECEMBER, 31);
Date testDate = calendar.getTime();
SimpleDateFormat dtf = new SimpleDateFormat("yyyy-MM-dd");
System.out.println("2022-12-31 转 yyyy-MM-dd 格式后 " + dtf.format(testDate));
3. Dificultades en la precisión del cálculo del valor del importe
Eche un vistazo a este ejemplo de cálculos de coma flotante:
public class DoubleTest {
public static void main(String[] args) {
System.out.println(0.1+0.2);
System.out.println(1.0-0.8);
System.out.println(4.015*100);
System.out.println(123.3/100);
double amount1 = 3.15;
double amount2 = 2.10;
if (amount1 - amount2 == 1.05){
System.out.println("OK");
}
}
}
resultado de la operación:
0.30000000000000004
0.19999999999999996
401.49999999999994
1.2329999999999999
Se puede encontrar que el resultado de la liquidación es inconsistente con nuestras expectativas, de hecho, porque la computadora almacena valores en binario, y lo mismo ocurre con los números de coma flotante. Para las computadoras, 0.1 no se puede expresar exactamente, por lo que los números de coma flotante causan una pérdida de precisión. Por lo tanto, "los cálculos de cantidad son generalmente del tipo BigDecimal"
Para el ejemplo anterior, cambiémoslo a BigDecimal y luego observemos el efecto de ejecución:
System.out.println(new BigDecimal(0.1).add(new BigDecimal(0.2)));
System.out.println(new BigDecimal(1.0).subtract(new BigDecimal(0.8)));
System.out.println(new BigDecimal(4.015).multiply(new BigDecimal(100)));
System.out.println(new BigDecimal(123.3).divide(new BigDecimal(100)));
resultado de la operación:
0.3000000000000000166533453693773481063544750213623046875
0.1999999999999999555910790149937383830547332763671875
401.49999999999996802557689079549163579940795898437500
1.232999999999999971578290569595992565155029296875
El resultado sigue siendo incorrecto. "En realidad", para usar BigDecimal para representar y calcular números de punto flotante, debe usar el "método de construcción de cadenas" para inicializar BigDecimal, de la siguiente manera:
public class DoubleTest {
public static void main(String[] args) {
System.out.println(new BigDecimal("0.1").add(new BigDecimal("0.2")));
System.out.println(new BigDecimal("1.0").subtract(new BigDecimal("0.8")));
System.out.println(new BigDecimal("4.015").multiply(new BigDecimal("100")));
System.out.println(new BigDecimal("123.3").divide(new BigDecimal("100")));
}
}
Al calcular la cantidad y usar BigDecimal, también debemos "prestar atención a los puntos decimales de BigDecimal y sus ocho modos de redondeo".
4. La codificación predeterminada de FileReader conduce a caracteres ilegibles
Echale un vistazo a éste ejemplo:
public class FileReaderTest {
public static void main(String[] args) throws IOException {
Files.deleteIfExists(Paths.get("jay.txt"));
Files.write(Paths.get("jay.txt"), "你好".getBytes(Charset.forName("GBK")));
System.out.println("系统默认编码:"+Charset.defaultCharset());
char[] chars = new char[10];
String content = "";
try (FileReader fileReader = new FileReader("jay.txt")) {
int count;
while ((count = fileReader.read(chars)) != -1) {
content += new String(chars, 0, count);
}
}
System.out.println(content);
}
}
resultado de la operación:
系统默认编码:UTF-8
���,�����ݵ�С�к�
从运行结果,可以知道,系统默认编码是utf8,demo中读取出来,出现乱码了。为什么呢?
FileReader lee archivos en función del "conjunto de caracteres predeterminado de la máquina actual". Si desea especificar un conjunto de caracteres, debe utilizar InputStreamReader y
FileInputStream directamente.
Por ejemplo:
public class FileReaderTest {
public static void main(String[] args) throws IOException {
Files.deleteIfExists(Paths.get("jay.txt"));
Files.write(Paths.get("jay.txt"), "你好".getBytes(Charset.forName("GBK")));
System.out.println("系统默认编码:"+Charset.defaultCharset());
char[] chars = new char[10];
String content = "";
try (FileInputStream fileInputStream = new FileInputStream("jay.txt");
InputStreamReader inputStreamReader = new InputStreamReader(fileInputStream, Charset.forName("GBK"))) {
int count;
while ((count = inputStreamReader.read(chars)) != -1) {
content += new String(chars, 0, count);
}
}
System.out.println(content);
}
}
Cinco, pozo de caché de enteros
public class IntegerTest {
public static void main(String[] args) {
Integer a = 127;
Integer b = 127;
System.out.println("a==b:"+ (a == b));
Integer c = 128;
Integer d = 128;
System.out.println("c==d:"+ (c == d));
}
}
resultado de la operación:
a==b:true
c==d:false
¿Por qué el valor entero no es igual si es 128? "El compilador convertirá Integer a = 127 a Integer.valueOf(127)." Veamos el código fuente.
public static Integer valueOf(int i) {
if (i >= IntegerCache.low && i <= IntegerCache.high)
return IntegerCache.cache[i + (-IntegerCache.low)];
return new Integer(i);
}
Se puede encontrar que si i está dentro de un cierto rango, se devolverá el caché.
De forma predeterminada, este intervalo de caché es [-128, 127], por lo que en nuestro desarrollo comercial diario, si se trata de la comparación de valores enteros, debemos prestar atención a este escollo. Además, configurar los parámetros de JVM y agregar -XX:AutoBoxCacheMax=1000 puede ajustar los parámetros de intervalo. Puede probarlo usted mismo.
6. Las variables estáticas estáticas se basan en variables de creación de instancias de resorte, lo que puede provocar errores de inicialización
He visto código como este antes. Las variables estáticas dependen del grano del contenedor de primavera.
private static SmsService smsService = SpringContextUtils.getBean(SmsService.class);
Este smsService estático puede no estar disponible, porque el orden de carga de la clase no está determinado, la forma correcta de escribir puede ser la siguiente:
private static SmsService smsService =null;
//使用到的时候采取获取
public static SmsService getSmsService(){
if(smsService==null){
smsService = SpringContextUtils.getBean(SmsService.class);
}
return smsService;
}
7. Usando ThreadLocal, la reutilización de hilos conduce a pozos de confusión de información
El uso de ThreadLocal para almacenar información en caché puede causar confusión en la información. Eche un vistazo al ejemplo a continuación.
private static final ThreadLocal<Integer> currentUser = ThreadLocal.withInitial(() -> null);
@GetMapping("wrong")
public Map wrong(@RequestParam("userId") Integer userId) {
//设置用户信息之前先查询一次ThreadLocal中的用户信息
String before = Thread.currentThread().getName() + ":" + currentUser.get();
//设置用户信息到ThreadLocal
currentUser.set(userId);
//设置用户信息之后再查询一次ThreadLocal中的用户信息
String after = Thread.currentThread().getName() + ":" + currentUser.get();
//汇总输出两次查询结果
Map result = new HashMap();
result.put("before", before);
result.put("after", after);
return result;
}
Es lógico que el antes obtenido cada vez sea nulo, pero el programa se ejecuta en Tomcat, el subproceso que ejecuta el programa es el subproceso de trabajo de Tomcat, y el subproceso de trabajo de Tomcat se basa en el grupo de subprocesos.
El grupo de subprocesos reutilizará un número fijo de subprocesos. Una vez reutilizado el subproceso, es probable que
el valor obtenido de ThreadLocal por primera vez sea el valor dejado por la solicitud anterior de otros usuarios. En este momento, la información del usuario en ThreadLocal es la información de otros usuarios.
Establezca el subproceso de trabajo de Tomcat en 1
server.tomcat.max-threads=1
Cuando el usuario 1 lo solicite, se obtendrán los siguientes resultados, que están en línea con las expectativas:
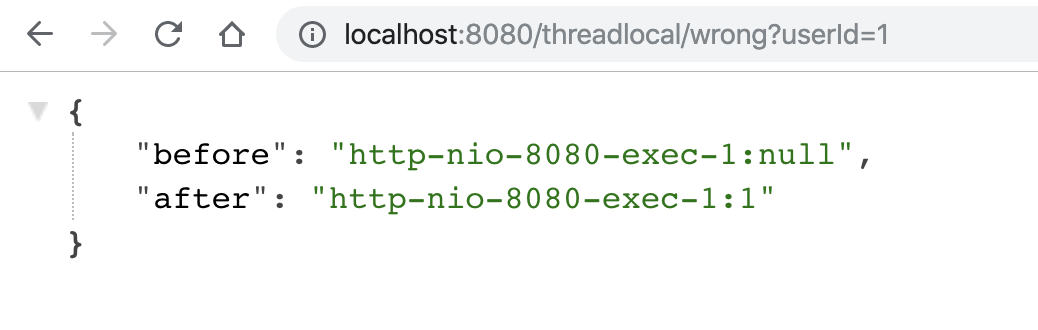
Cuando el usuario 2 solicite, se obtendrán los siguientes resultados, "no cumple con las expectativas":

Por lo tanto, cuando use herramientas como ThreadLocal para almacenar algunos datos, debe prestar especial atención a borrar explícitamente los datos establecidos después de que se ejecute el código, de la siguiente manera:
@GetMapping("right")
public Map right(@RequestParam("userId") Integer userId) {
String before = Thread.currentThread().getName() + ":" + currentUser.get();
currentUser.set(userId);
try {
String after = Thread.currentThread().getName() + ":" + currentUser.get();
Map result = new HashMap();
result.put("before", before);
result.put("after", after);
return result;
} finally {
//在finally代码块中删除ThreadLocal中的数据,确保数据不串
currentUser.remove();
}
}
Ocho, ignora el regreso y la ruptura del interruptor.
Estrictamente hablando, este punto no debe considerarse una trampa, pero cuando escribes código, algunos amigos tienden a ser negligentes. Solo mira el ejemplo
public class SwitchTest {
public static void main(String[] args) throws InterruptedException {
System.out.println("testSwitch结果是:"+testSwitch("1"));
}
private static String testSwitch(String key) {
switch (key) {
case "1":
System.out.println("1");
case "2":
System.out.println(2);
return "2";
case "3":
System.out.println("3");
default:
System.out.println("返回默认值");
return "4";
}
}
}
Resultado de salida:
测试switch
1
2
testSwitch结果是:2
El interruptor "coincidirá en todo el caso hasta que encuentre un retorno o una ruptura." Por lo tanto, preste atención al escribir el código para ver si es el resultado que desea.
9. Varios pozos de Arrays.asList
9.1 El tipo básico no se puede utilizar como parámetro del método Arrays.asList, de lo contrario se tratará como un parámetro.
public class ArrayAsListTest {
public static void main(String[] args) {
int[] array = {
1, 2, 3};
List list = Arrays.asList(array);
System.out.println(list.size());
}
}
resultado de la operación:
1
El código fuente de Arrays.asList es el siguiente:
public static <T> List<T> asList(T... a) {
return new ArrayList<>(a);
}
9.2 La Lista devuelta por Arrays.asList no admite operaciones de adición y eliminación.
public class ArrayAsListTest {
public static void main(String[] args) {
String[] array = {
"1", "2", "3"};
List list = Arrays.asList(array);
list.add("5");
System.out.println(list.size());
}
}
resultado de la operación:
Exception in thread "main" java.lang.UnsupportedOperationException
at java.util.AbstractList.add(AbstractList.java:148)
at java.util.AbstractList.add(AbstractList.java:108)
at object.ArrayAsListTest.main(ArrayAsListTest.java:11)
La Lista devuelta por Arrays.asList no es la java.util.ArrayList que esperábamos, sino la clase interna ArrayList de Arrays. La ArrayList de la clase interna no implementa el método add, sino la implementación del método add de la clase principal, que generará una excepción.
9.3 Al usar Arrays.asLis, la modificación del arreglo original afectará la Lista que obtengamos
public class ArrayAsListTest {
public static void main(String[] args) {
String[] arr = {
"1", "2", "3"};
List list = Arrays.asList(arr);
arr[1] = "4";
System.out.println("原始数组"+Arrays.toString(arr));
System.out.println("list数组" + list);
}
}
resultado de la operación:
原始数组[1, 4, 3]
list数组[1, 4, 3]
A partir de los resultados en ejecución, podemos ver que la matriz original cambia, y la lista convertida de Arrays.asList también cambia. Debe prestar atención al usarlo. Puede envolverlo con el nuevo ArrayList(Arrays.asList(arr)).
10. Pozo de transferencia forzada ArrayList.toArray()
public class ArrayListTest {
public static void main(String[] args) {
List<String> list = new ArrayList<String>(1);
list.add("测试");
String[] array21 = (String[])list.toArray();//类型转换异常
}
}
Dado que se devuelve el tipo de objeto, si la matriz de tipo de objeto se convierte en una matriz de cadenas, se producirá una ClassCastException. La solución es usar toArray() para sobrecargar el método toArray(T[] a)
String[] array1 = list.toArray(new String[0]);//可以正常运行
11. Varios pozos de uso anormal
11.1 No pierda la información de excepción de su pila
public void wrong1(){
try {
readFile();
} catch (IOException e) {
//没有把异常e取出来,原始异常信息丢失
throw new RuntimeException("系统忙请稍后再试");
}
}
public void wrong2(){
try {
readFile();
} catch (IOException e) {
//只保留了异常消息,栈没有记录啦
log.error("文件读取错误, {}", e.getMessage());
throw new RuntimeException("系统忙请稍后再试");
}
}
La forma correcta de imprimir debe ser
public void right(){
try {
readFile();
} catch (IOException e) {
//把整个IO异常都记录下来,而不是只打印消息
log.error("文件读取错误", e);
throw new RuntimeException("系统忙请稍后再试");
}
}
11.2 No defina excepciones como variables estáticas
public void testStaticExeceptionOne{
try {
exceptionOne();
} catch (Exception ex) {
log.error("exception one error", ex);
}
try {
exceptionTwo();
} catch (Exception ex) {
log.error("exception two error", ex);
}
}
private void exceptionOne() {
//这里有问题
throw Exceptions.ONEORTWO;
}
private void exceptionTwo() {
//这里有问题
throw Exceptions.ONEORTWO;
}
exceptionTwo抛出的异常,很可能是 exceptionOne的异常哦。正确使用方法,应该是new 一个出来。
private void exceptionTwo() {
throw new BusinessException("业务异常", 0001);
}
11.3 No utilice e.printStackTrace() en el entorno de producción
public void wrong(){
try {
readFile();
} catch (IOException e) {
//生产环境别用它
e.printStackTrace();
}
}
Debido a que ocupa demasiada memoria, provoca interbloqueos y los registros se intercalan y se mezclan, lo que no es fácil de leer. El uso correcto es el siguiente:
log.error("método normal de impresión de registros", e);
11.4 ¿Qué debo hacer si ocurre una excepción durante el envío del grupo de subprocesos?
public class ThreadExceptionTest {
public static void main(String[] args) {
ExecutorService executorService = Executors.newFixedThreadPool(10);
IntStream.rangeClosed(1, 10).forEach(i -> executorService.submit(()-> {
if (i == 5) {
System.out.println("发生异常啦");
throw new RuntimeException("error");
}
System.out.println("当前执行第几:" + Thread.currentThread().getName() );
}
));
executorService.shutdown();
}
}
resultado de la operación:
当前执行第几:pool-1-thread-1
当前执行第几:pool-1-thread-2
当前执行第几:pool-1-thread-3
当前执行第几:pool-1-thread-4
发生异常啦
当前执行第几:pool-1-thread-6
当前执行第几:pool-1-thread-7
当前执行第几:pool-1-thread-8
当前执行第几:pool-1-thread-9
当前执行第几:pool-1-thread-10
Se puede encontrar que si la tarea asíncrona se envía al grupo de subprocesos utilizando el método de envío, la excepción se tragará. Por lo tanto, en el descubrimiento diario, si hay una excepción previsible, puede tomar las siguientes soluciones:
- Detectar excepciones en el código de tarea try/catch
- Reciba la excepción lanzada a través del método get del objeto Future y luego procéselo
- Establezca UncaughtExceptionHandler para el subproceso de trabajo y maneje la excepción en el método uncaughtException
- Vuelva a escribir el método afterExecute de ThreadPoolExecutor para manejar la referencia de excepción pasada
11.5 También se debe prestar atención a la excepción de que finalmente se vuelven a lanzar
public void wrong() {
try {
log.info("try");
//异常丢失
throw new RuntimeException("try");
} finally {
log.info("finally");
throw new RuntimeException("finally");
}
}
Un método no tiene dos excepciones, por lo que la excepción de "finalmente" "sobrescribirá" la excepción de prueba. La forma correcta de usarlo debería ser que el bloque de código finalmente sea "responsable de su propia captura y manejo de excepciones".
public void right() {
try {
log.info("try");
throw new RuntimeException("try");
} finally {
log.info("finally");
try {
throw new RuntimeException("finally");
} catch (Exception ex) {
log.error("finally", ex);
}
}
}
12. Serialización JSON, ¡el tipo largo se convierte en tipo entero!
public class JSONTest {
public static void main(String[] args) {
Long idValue = 3000L;
Map<String, Object> data = new HashMap<>(2);
data.put("id", idValue);
data.put("name", "测试的");
Assert.assertEquals(idValue, (Long) data.get("id"));
String jsonString = JSON.toJSONString(data);
// 反序列化时Long被转为了Integer
Map map = JSON.parseObject(jsonString, Map.class);
Object idObj = map.get("id");
System.out.println("反序列化的类型是否为Integer:"+(idObj instanceof Integer));
Assert.assertEquals(idValue, (Long) idObj);
}
}
"resultado de la operación:"
Exception in thread "main" 反序列化的类型是否为Integer:true
java.lang.ClassCastException: java.lang.Integer cannot be cast to java.lang.Long
at object.JSONTest.main(JSONTest.java:24)
"Atención", después de serializarse en una cadena Json, la cadena Json no tiene un tipo Long. Y si Object también recibe la deserialización, si el número es menor que el valor máximo de Integer, ¡se convertirá a Integer!
Trece, use Ejecutores para declarar el grupo de subprocesos, el problema OOM de newFixedThreadPool
ExecutorService executor = Executors.newFixedThreadPool(10);
for (int i = 0; i < Integer.MAX_VALUE; i++) {
executor.execute(() -> {
try {
Thread.sleep(10000);
} catch (InterruptedException e) {
//do nothing
}
});
}
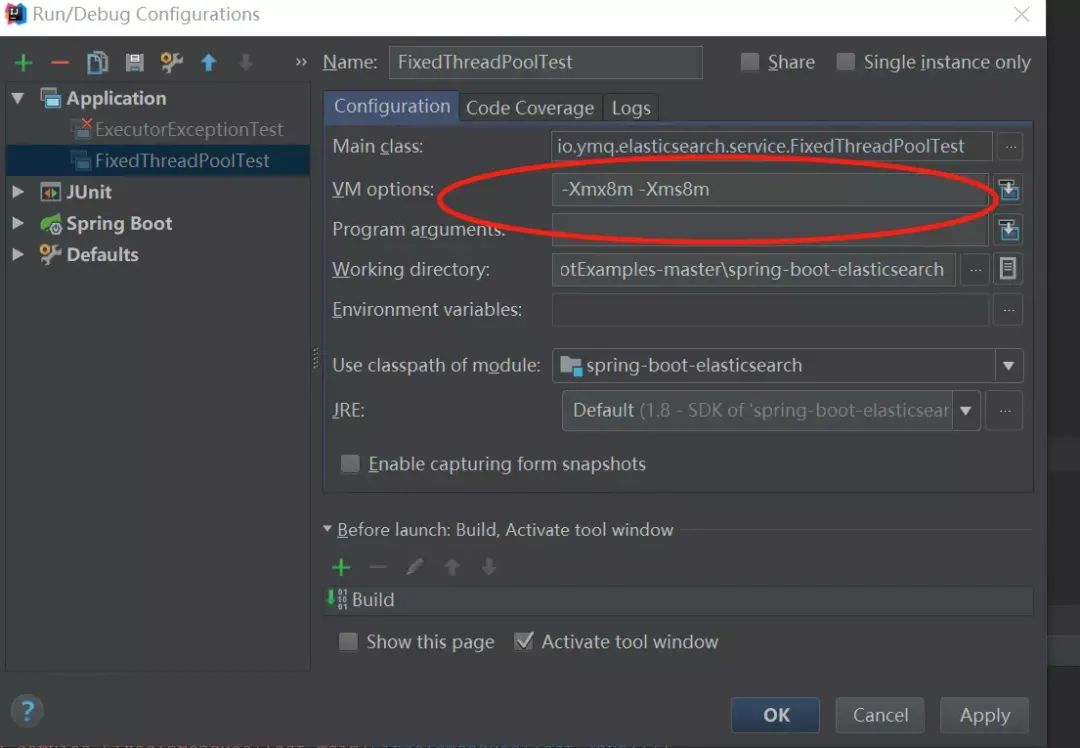
"IDE especifica los parámetros de JVM: -Xmx8m -Xms8m:"
resultado de la operación:
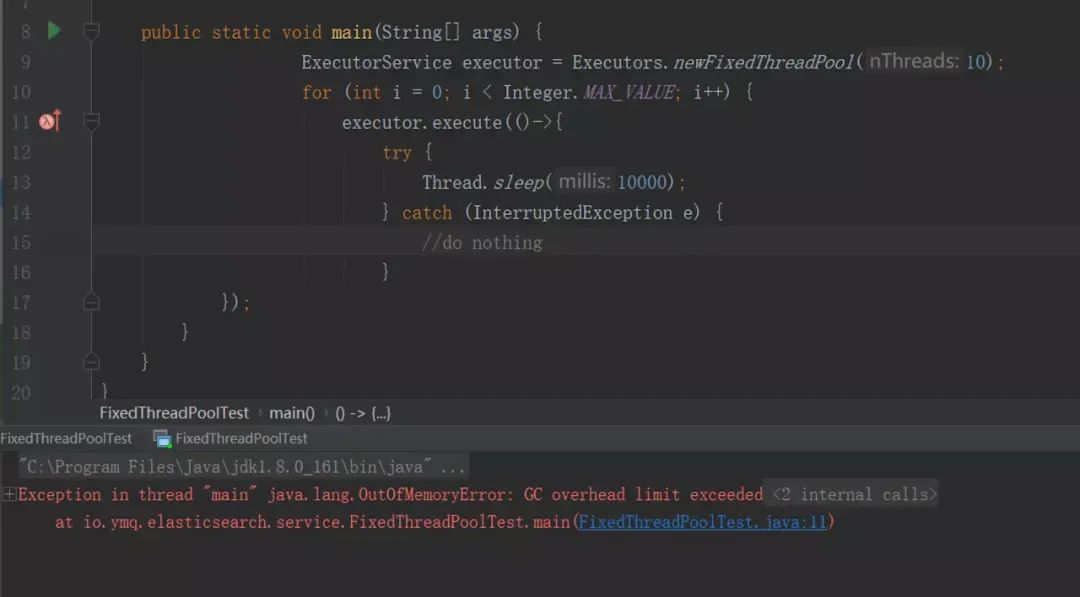
Veamos el código fuente. De hecho, newFixedThreadPool usa una cola ilimitada.
public static ExecutorService newFixedThreadPool(int nThreads) {
return new ThreadPoolExecutor(nThreads, nThreads,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>());
}
public class LinkedBlockingQueue<E> extends AbstractQueue<E>
implements BlockingQueue<E>, java.io.Serializable {
...
/**
* Creates a {@code LinkedBlockingQueue} with a capacity of
* {@link Integer#MAX_VALUE}.
*/
public LinkedBlockingQueue() {
this(Integer.MAX_VALUE);
}
...
}
El número de subprocesos principales en el grupo de subprocesos newFixedThreadPool es fijo y utiliza una cola de bloqueo LinkedBlockingQueue casi ilimitada. Cuando se agoten los subprocesos principales, las tareas se pondrán en cola en la cola de bloqueo. Si el tiempo de ejecución de la tarea es relativamente largo y no se libera, se acumularán cada vez más tareas en la cola de bloqueo y, finalmente, el uso de memoria de la máquina. continuará aumentando Causa JVM OOM.
14. Dirigir archivos grandes o leer demasiados datos de la base de datos a la memoria al mismo tiempo puede causar problemas de OOM
Si demasiados datos de un archivo grande o una base de datos llegan a la memoria al mismo tiempo, causará OOM. Por lo tanto, generalmente se recomienda consultar la base de datos DB en lotes.
Cuando se lee un archivo, generalmente se pide que el archivo no sea demasiado grande, por lo que se utiliza Files.readAllLines(). ¿por qué? Debido a que lee directamente todos los archivos en la memoria, se estima que no será OOM usar esto, puede ver su código fuente:
public static List<String> readAllLines(Path path, Charset cs) throws IOException {
try (BufferedReader reader = newBufferedReader(path, cs)) {
List<String> result = new ArrayList<>();
for (;;) {
String line = reader.readLine();
if (line == null)
break;
result.add(line);
}
return result;
}
}
Si el archivo es demasiado grande, puede usar Files.line() para leerlo a pedido. En ese momento, al leer archivos, generalmente necesita "cerrar el flujo de recursos" después de usarlos.
15. Consulta primero, luego actualiza/elimina el problema de consistencia concurrente
En el desarrollo diario, este tipo de implementación de código se ve a menudo: primero verifique si quedan boletos disponibles y luego actualice los boletos restantes.
if(selectIsAvailable(ticketId){
1、deleteTicketById(ticketId)
2、给现金增加操作
}else{
return “没有可用现金券”
}
Si se ejecuta simultáneamente, puede haber un problema y se debe usar la atomicidad de la actualización/eliminación de la base de datos.La solución correcta es la siguiente:
if(deleteAvailableTicketById(ticketId) == 1){
1、给现金增加操作
}else{
return “没有可用现金券”
}
16. La base de datos se almacena en utf-8 y se inserta el hoyo con expresión anormal
La codificación utf8 admitida por la versión inferior de MySQL tiene una longitud máxima de caracteres de 3 bytes, pero se requieren 4 bytes para almacenar emoticones, por lo que si se usa utf8 para almacenar emoticones, se informará, por lo que la codificación utf8mb4 generalmente se usa para almacenar emoticonos SQLException: Incorrect string value: '\xF0\x9F\x98\x84' for column_
17. El tajo donde no se ha producido la transacción
En el desarrollo comercial diario, a menudo nos ocupamos de las transacciones. La "falla de la transacción" tiene principalmente los siguientes escenarios:
- El motor de base de datos subyacente no admite transacciones
- Uso en métodos modificados no públicos
- El atributo rollbackFor está configurado incorrectamente
- Este método de clase se llama directamente
- Try...catch consume la excepción, lo que hace que la transacción falle.
Entre ellos, los pits que son más fáciles de pisar son los dos últimos, "el método de transacción anotado es llamado directamente por este método de clase", el pseudocódigo es el siguiente:
public class TransactionTest{
public void A(){
//插入一条数据
//调用方法B (本地的类调用,事务失效了)
B();
}
@Transactional
public void B(){
//插入数据
}
}
Si se detecta la excepción, "Entonces la transacción también fallará" ~, el pseudocódigo es el siguiente:
@Transactional
public void method(){
try{
//插入一条数据
insertA();
//更改一条数据
updateB();
}catch(Exception e){
logger.error("异常被捕获了,那你的事务就失效咯",e);
}
}
18. Cuando la reflexión se encuentra con el pozo de la sobrecarga de métodos
/**
* 反射demo
*/
public class ReflectionTest {
private void score(int score) {
System.out.println("int grade =" + score);
}
private void score(Integer score) {
System.out.println("Integer grade =" + score);
}
public static void main(String[] args) throws Exception {
ReflectionTest reflectionTest = new ReflectionTest();
reflectionTest.score(100);
reflectionTest.score(Integer.valueOf(100));
reflectionTest.getClass().getDeclaredMethod("score", Integer.TYPE).invoke(reflectionTest, Integer.valueOf("60"));
reflectionTest.getClass().getDeclaredMethod("score", Integer.class).invoke(reflectionTest, Integer.valueOf("60"));
}
}
resultado de la operación:
int grade =100
Integer grade =100
int grade =60
Integer grade =60
Si "no a través de la reflexión", pase Integer.valueOf(100) y tome la sobrecarga de Integer. Sin embargo, la reflexión no determina la sobrecarga del método en función del tipo de parámetro de entrada, sino que "determina por el nombre del método y el tipo de parámetro pasado cuando el método se obtiene por reflexión".
getClass().getDeclaredMethod("score", Integer.class)
getClass().getDeclaredMethod("score", Integer.TYPE)
Diecinueve, mysql time timestamp pit
Cuando hay una declaración de actualización, la marca de tiempo puede actualizarse automáticamente a la hora actual, vea una demostración
CREATE TABLE `t` (
`a` int(11) DEFAULT NULL,
`b` timestamp NOT NULL,
`c` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP
) ENGINE=InnoDB DEFAULT CHARSET=utf8
Podemos encontrar que la "columna c" tiene CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP, por lo que la columna c se "actualizará a la hora actual" a medida que se actualice el registro. Sin embargo, la columna b también se "actualizará a la hora actual" a medida que se actualicen los registros.
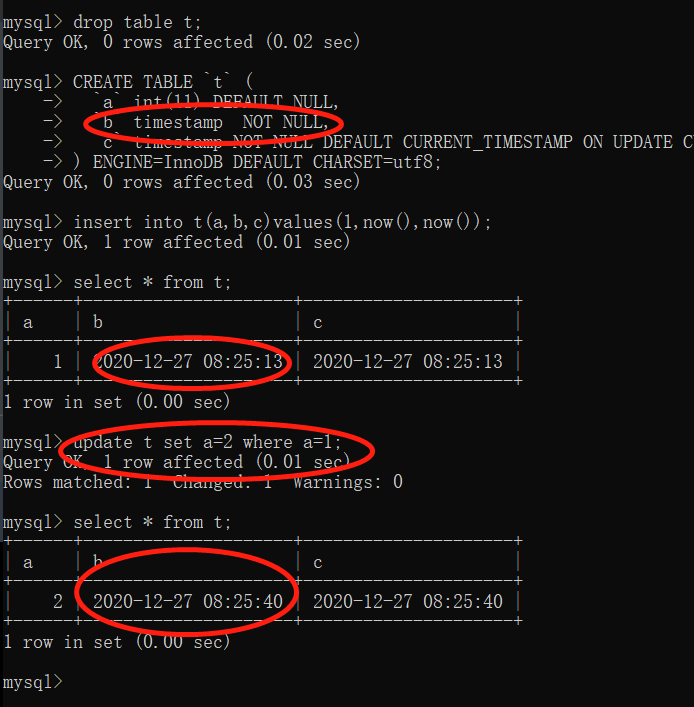
Puede usar datetime en su lugar, y si necesita actualizarlo a la hora actual, asigne el valor a now(), o modifique el parámetro explicit_defaults_for_timestamp de mysql.
20. La zona horaria de la base de datos mysql8
Antes de actualizar la base de datos mysql, la nueva versión es 8.0.12. Pero después de la actualización, descubrí que la hora obtenida por la función now() es 8 horas más tarde que la hora de Beijing.Resulta que mysql8 tiene por defecto la hora de los Estados Unidos, y es necesario especificar la zona horaria.
jdbc:mysql://localhost:3306/test?useUnicode=true&characterEncoding=UTF-8&
serverTimezone=Asia/Shanghai
referencia y gracias
[1] 100 errores comunes en el desarrollo empresarial de Java:
https://time.geekbang.org/column/article/220230