1. 제이수프
jsoup는 URL 주소와 HTML 텍스트 콘텐츠를 직접 구문 분석할 수 있는 Java HTML 구문 분석기입니다. DOM, CSS 및 jQuery와 같은 조작 방법을 통해 데이터를 검색하고 조작 할 수 있는 매우 노동 절약적인 API를 제공합니다 .
요구 사항은 특정 웹 사이트에서 순위표 데이터를 가져와 앱 디스플레이로 사용하는 것이므로 Jsoup 프레임워크가 떠오릅니다.
인터넷에 실제로 Jsoup 블로그가 많이 있는데 아주 좋지만 약간의 차이가 있고 일부는 틀릴 것입니다 여전히 공식 웹 사이트에 가서 작고 매우 간단합니다.
URL에서 문서 로드: jsoup Java HTML 파서
html 파일, url 주소, 파일에서 내용을 로드하는 방법에 대해 이야기하고 DOM, CSS 및 jQuery와 유사한 작업 을 통해 데이터를 추출하고 조작하는 방법에 대해 설명합니다. 매우 상세하고 간단합니다. 모두 영어로 되어 있고 읽으십시오 너무 잘 알고 있다면 번역 플러그인을 설치하거나 Google 브라우저에서 벽을 넘기면 그가 직접 번역합니다.
여기서는 자세히 설명하지 않겠습니다. 많은 것들이 매우 복잡하지만 또한 매우 기본적입니다. 예를 들어 2022년 빌보드 목록의 상위 100위 가수 데이터(순위, 표지, 이름)를 가져옵니다.

구현 코드: Kotlin
1. getListData 메서드를 사용하여 가수 정보 목록을 가져옵니다.
2. Dispatchers.IO - 이 디스패처는 기본 스레드 외부에서 디스크 또는 네트워크 I/O를 수행하도록 특별히 최적화되었습니다. 예를 들면 Room 구성요소 사용, 파일에서 데이터 읽기 또는 파일에 데이터 쓰기, 네트워크 작업 실행 등이 있습니다.
3. Jsoup.connect(url).get()은 Document 객체를 가져옵니다.객체를 가져온 후 해당 메서드를 사용하여 원하는 데이터를 가져올 수 있습니다.
fun getListData(result:RequestCallBack<MutableList<ArtistInfo>>): List<ArtistInfo>? {
CoroutineScope(Dispatchers.IO).launch {
val artistList = mutableListOf<ArtistInfo>()
val url = "https://www.billboard.com/charts/year-end/top-artists/"
try {
val document = Jsoup.connect(url).get()
Log.d("TTTT", "jsoup:$document")
val listDoc: Elements =
document.getElementsByClass("o-chart-results-list-row-container")
Log.d("TTTT", "jsoup:size ${listDoc.size}")
val artistSize = if (listDoc.size > 50) 50 else listDoc.size
for (i in 0 until artistSize) {
val sortNum = listDoc[i].select("span").text()
Log.d("TTTT", "jsoup:$sortNum")
val artistName = listDoc[i].select("h3").text()
Log.d("TTTT", "jsoup:$artistName")
val img = listDoc[i].select("img").attr("data-lazy-src").toString()
Log.d("TTTT", "jsoup:$img")
val artistInfo = ArtistInfo().apply {
this.artist = artistName
this.rank = sortNum.toInt()
this.coverOnline = img
}
artistList.add(artistInfo)//加入列表
App.getInstance().getArtistDao().insertOrReplace(artistInfo)//单个歌手数据插入数据库,用的greenDao
}
result.success(artistList)//返回歌手列表数据,UI上展示
} catch (exception: IOException) {
exception.printStackTrace()
}
}
return null
}
물론 웹 페이지의 데이터가 어떤 종류의 레이블과 클래스에 있는지 어떻게 알 수 있습니까?당연히 브라우저 F12로 이동하여 데이터를 봅니다.
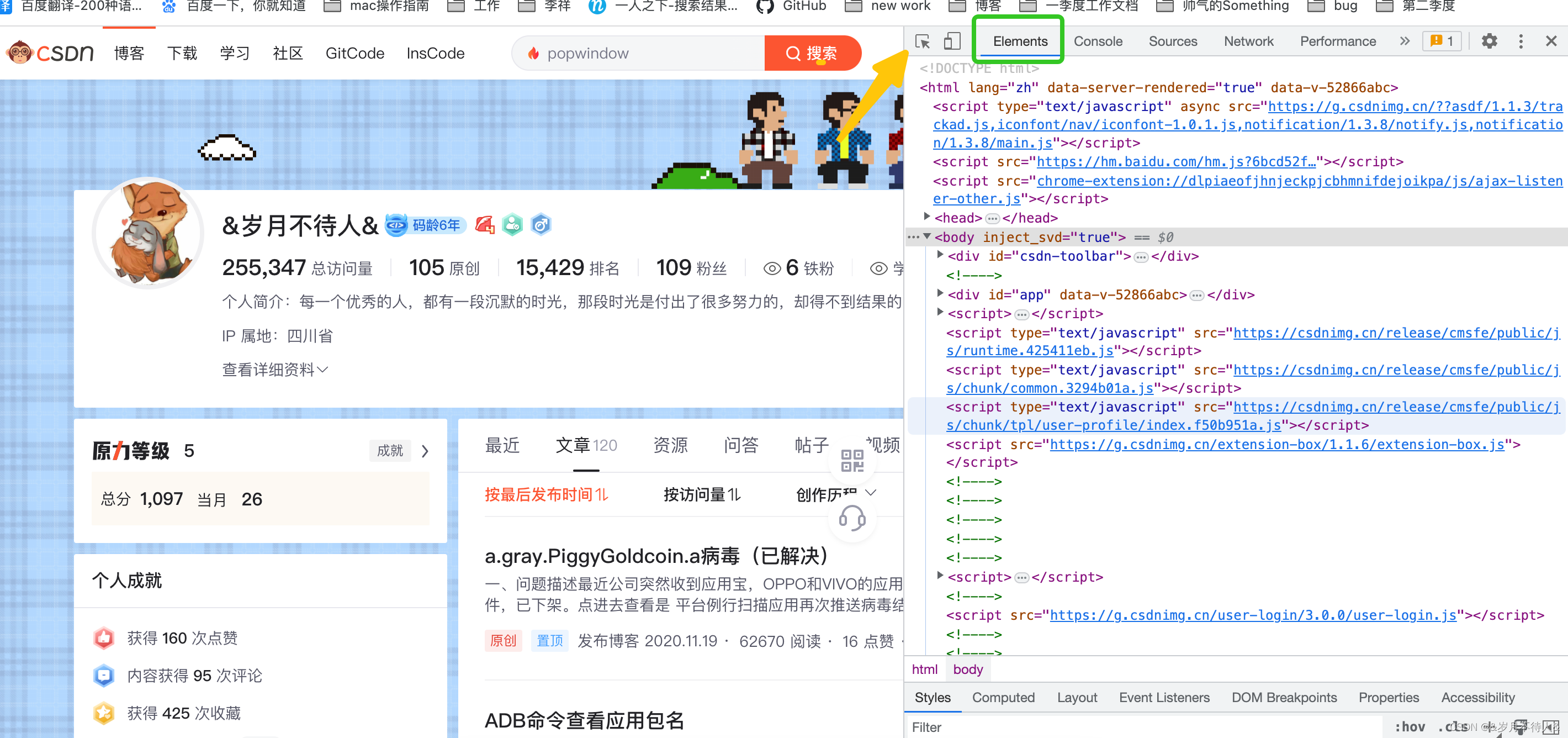
1. 먼저 요소가 있는 현재 웹페이지의 소스코드를 확인하고 옆에 있는 노란색 화살표를 클릭한 후 왼쪽 웹페이지에서 요소를 클릭하면 해당 데이터가 어디에 있는지 알 수 있습니다.
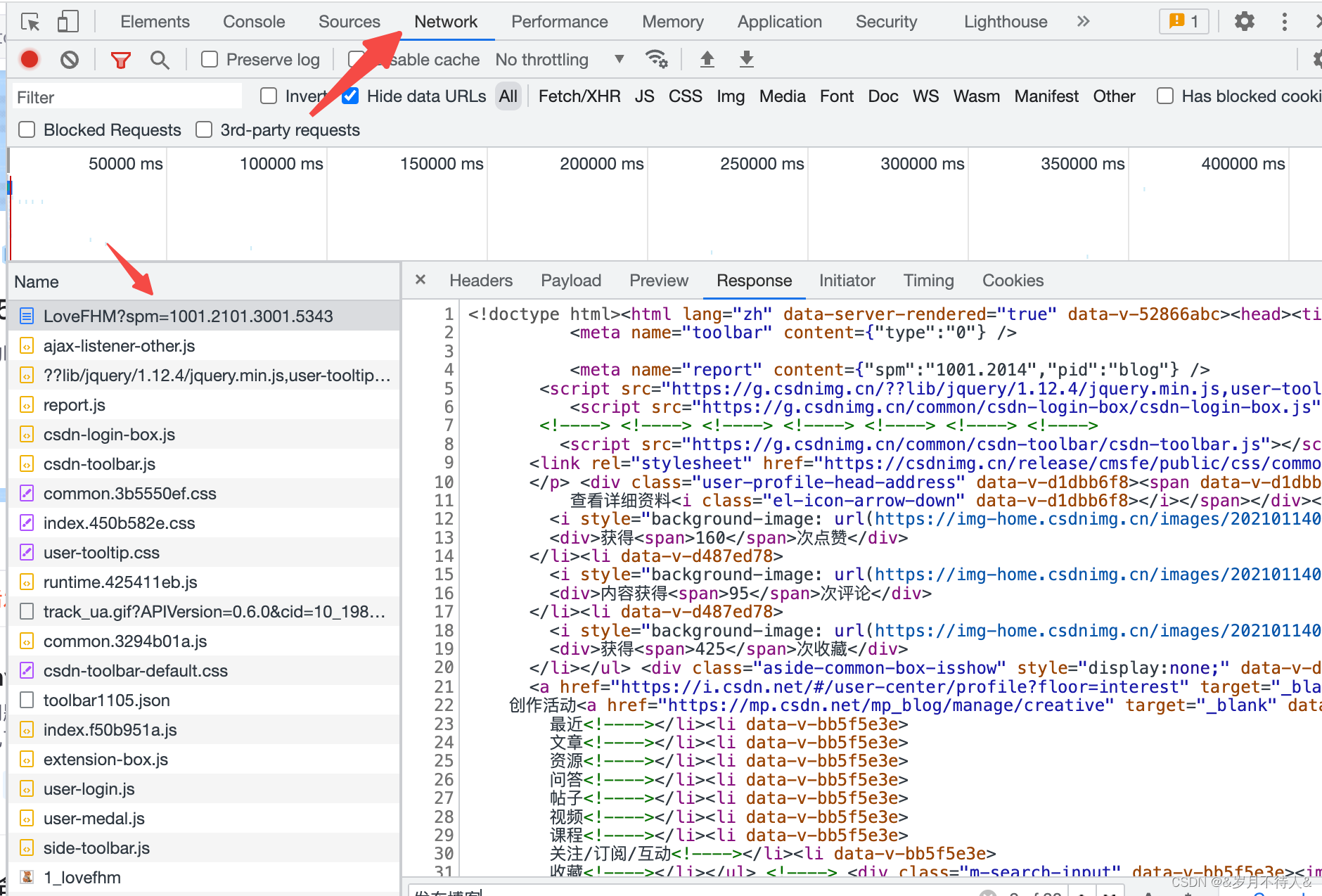
2. 네트워크에서 반환된 데이터를 클릭하고 응답을 선택하면 요청에 의해 반환된 데이터를 볼 수 있으며 데이터 구조를 관찰할 수도 있습니다(js, json 및 기타 데이터 형식이 있음).
이 상자의 옵션은 매우 유용하며 요청 방법, 매개변수, 미리보기 페이지, 반환 데이터 등을 볼 수 있습니다. 
2. 제한사항
Jsoup을 사용하게 되어 매우 기쁩니다.국내 대부분의 사이트를 크롤링하면 대부분의 데이터를 얻을 수 있습니다.
그런데 일부 웹페이지를 크롤링 해보니 일부 데이터를 얻을 수 없었고 한번에 일부 데이터를 얻지 못한 것을 발견했는데 F12를 누르면 많은 양의 데이터를 병렬로 요청한 다음 표시하는 것을 발견했습니다. 그렇다면 Jsoup은 실제로 동적 웹 페이지의 데이터를 가져올 수 있습니까? ? ? Baidu Jsoup에서 동적 웹 페이지를 크롤링 하고 많은 기사를 찾았지만 기사에서 크롤링된 데이터를 한 번에 모두 얻은 것을 보았는데 정말 혼란스러웠습니다. Jsoup에 제한이 있나요?
그래서 저는 개인적으로 Jsoup 크롤러에 특정 제한이 있다고 생각합니다. 즉, jsoup 크롤러를 통해 정적 웹 페이지를 크롤링하는 것이 더 적합하므로 특별한 준비 없이 현재 페이지 데이터의 일부만 크롤링할 수 있습니다. 웹 사이트의 모든 데이터를 크롤링해야 하는 경우 인터페이스를 통해 올바른 매개 변수를 업로드하여 웹 사이트의 적절한 데이터 정보로 크롤링하는 것이 더 쉬울 수 있습니다.
음음, 웹사이트의 음악 데이터를 크롤링할 때, 나는 오랫동안 Jsoup을 사용하지 않았습니다. 마지막으로 F12는 인터페이스를 쿼리하고 매개 변수는 인터페이스에서 얻은 데이터를 사용합니다.
인터페이스를 통해 데이터를 얻는 것은 번거롭지만 웹 사이트가 안티 크롤러를 구현하지 않으면 여전히 데이터를 얻는 데 문제가 없습니다.
팁: Jsoup은 요청 본문(데이터)을 구성하고 헤더를 구성하여 동적 웹 페이지의 데이터를 가져올 수 있지만 개인적으로 약간 번거롭고 크롤링할 페이지가 많아서 선택했습니다. 인터페이스
3. 인터페이스 크롤링 데이터 아이디어
주요 공정:
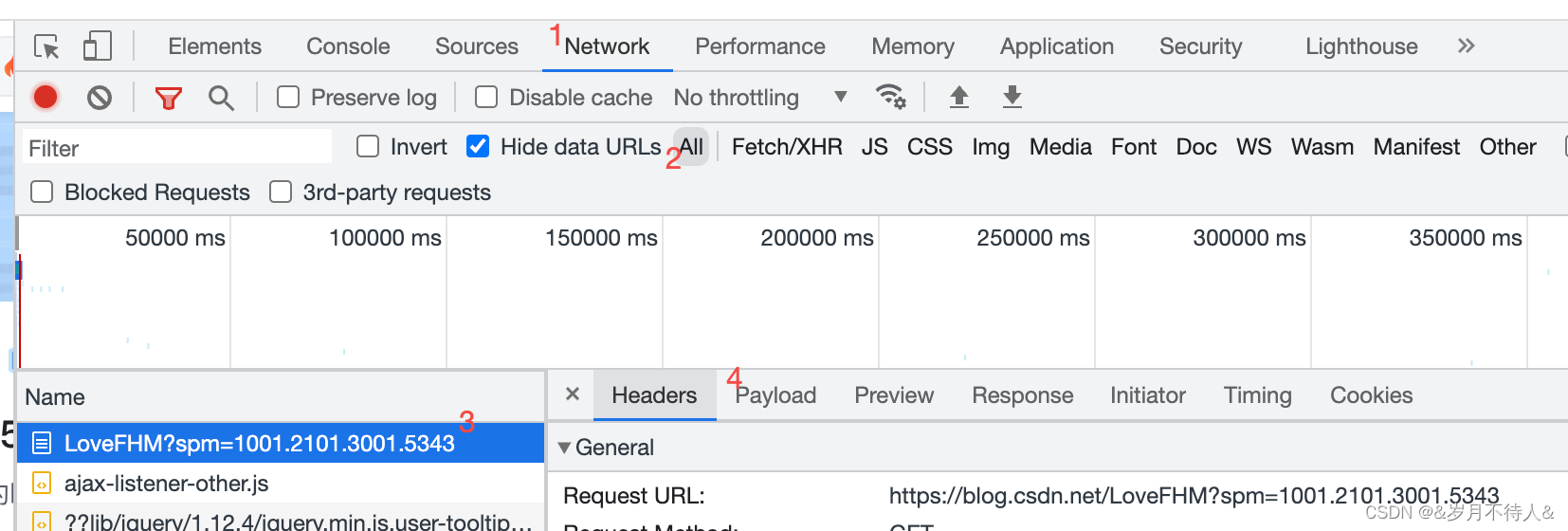
1. 대상 웹 페이지에서 아래 그림을 보고 헤더 등의 데이터를 관찰하고 인터페이스, 필수 매개 변수 등을 얻습니다.
2. 이때 인터페이스에서 반환된 응답의 Json 데이터를 확인할 수 있습니다. 어떻게 보십니까? ? 다음은 매우 유용한 웹사이트입니다.
3. URL이 있더라도 걱정하지 마십시오. 먼저 우편 배달부를 사용하여 데이터 액세스를 시뮬레이션하여 구성한 데이터가 실제로 URL에 액세스하고 원하는 데이터를 얻을 수 있는지 확인하십시오. 우편 배달부에서 얻은 데이터는 URL 인터페이스에서 크롤링한 데이터가 매우 커서 우편 배달부가 관찰하기 쉽지 않기 때문에 위의 URL에 배치하여 데이터 구조를 볼 수도 있습니다.
4. 요청/반환 엔터티 클래스를 만든 다음 Android 네트워크 프레임워크를 사용하여 액세스합니다.
여기서는 특정 구현이 아닌 아이디어만 제공합니다. 아이디어로, 그것은 빨리 끝날 것입니다.
개인 크롤링 데이터는 개인 학습 전용입니다. 베테랑은 스스로 할 것을 기억합니다, 하하하