1. Conceptos de TP, FP, TN y FN
Al predecir datos, a menudo existen los siguientes conceptos: TP , FP, TN, FN.
¿Qué significa eso? Es decir, la relación entre si la situación pronosticada (Positiva o Negativa) realmente refleja la situación real: ¡

lee el siguiente análisis y lo entenderás!
TP: True Positive, la predicción es una muestra positiva y la predicción es correcta .
FP: Falso positivo, la predicción es una muestra positiva, pero la predicción incorrecta. Es decir, la detección falsa de
TN: True Negative, la predicción es una muestra negativa y la predicción es correcta.
FN: falso negativo, las muestras negativas se pronostican, pero se pronostican incorrectamente. detección perdida
Extensión:
TP+FN: la suma de muestras positivas, muestras positivas detectadas correctamente + detecciones perdidas.
FP+TN: La suma de muestras negativas, el número de muestras negativas detectadas correctamente + falsos positivos.
TP+TN: suma de clasificación correcta, detección correcta de muestras positivas + detección correcta de muestras negativas
Precisión: tasa de precisión, es decir, la precisión de la predicción,
Precisión = (TP + TN) / (TP + FP + TN +FN)
Es decir, el número de predicciones correctas/número total de muestras. Pero la precisión no se usa a menudo, porque cuando hacemos predicciones de objetivos, a menudo solo nos preocupamos por las muestras positivas, no si las muestras negativas se predicen correctamente.
2. Precisión de detección de cuadro objetivo y tasa de recuperación
El cuadro de salida de detección de objetivos es un cuadro de predicción, y hay detección correcta (TP) y detección falsa (FP) en el cuadro de predicción , así como detección perdida (FN)
1. Percisión: tasa de precisión , la probabilidad de una predicción precisa entre todas las muestras de predicción. Debido a que solo se pronostican muestras positivas, todas las muestras que se consideran pronosticadas son positivas.
Percisión = TP / (TP + FP)
2. Recall: Recall rate , la probabilidad de que se pronostique correctamente entre todas las muestras positivas y positivas.
Recuperar = TP / (TP + FN)
¿Cómo es la predicción correcta en la detección de objetivos? Generalmente, IOU se utiliza para la coincidencia.Cuando el valor de IOU entre el cuadro predicho y el cuadro real es mayor que un cierto umbral, como 0.5, se considera que la muestra real se predijo correctamente.
Ahora que existe una tasa cuasi-llamada, ¿por qué necesitamos AP?
2, PA, MAPA
Supongamos que predecimos una determinada categoría (como una persona), cada cuadro de predicción tiene una puntuación de confianza y si la etiqueta es correcta. Después de ordenar por puntuación, queda de la siguiente manera:

AP:Precisión promedio
Suponiendo que hay M muestras positivas verdaderas, pasamos de Top-1 a Top-N, y cada predicción acumulada corresponderá a un recuerdo y una precisión. Puede haber M valores de recuperación desde Top-1 hasta Top-N. Respectivamente (1/M, 2/M,...,M/M), para cada recuperación, tome el valor máximo de la precisión correspondiente como la precisión correspondiente a la recuperación actual y encuentre el promedio de M precisión para obtener AP .
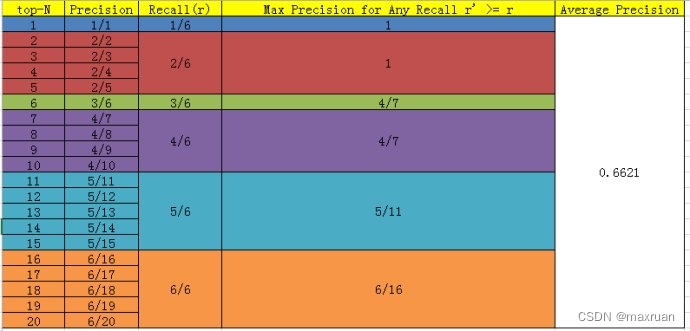
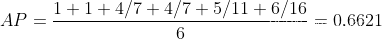
AP indica qué tan bueno es el modelo entrenado en la categoría actual .
mAP: AP
medio Simplemente promedie los AP de todas las categorías.
3. Dibujo de la curva PR
Para calcular AP, primero debe dibujar la curva PR.
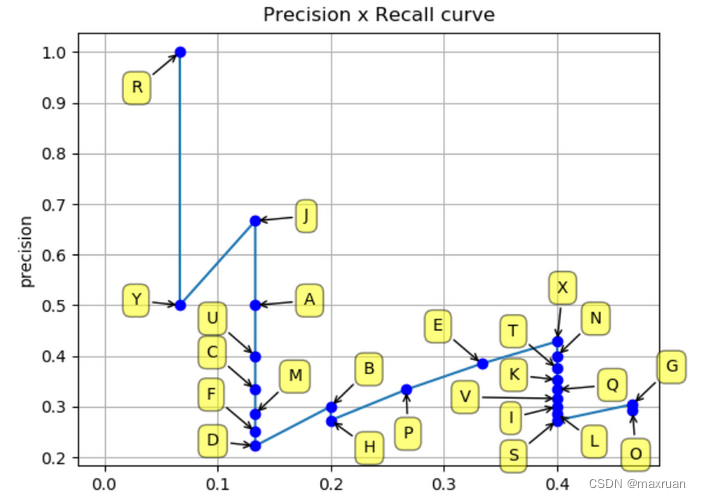
1. Dibuje el gráfico de recuperación de precisión mediante el método de seguimiento de puntos
2. Método de interpolación de todos los puntos (interpolación realizada en todos los puntos)
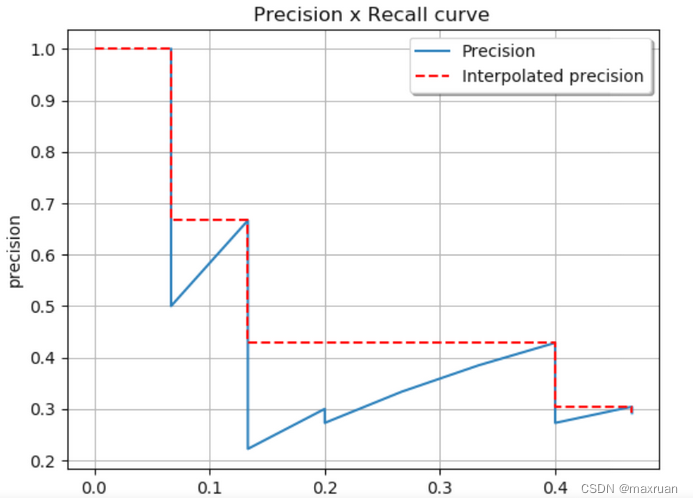
Después de la interpolación, el área de los M rectángulos es el valor AP.
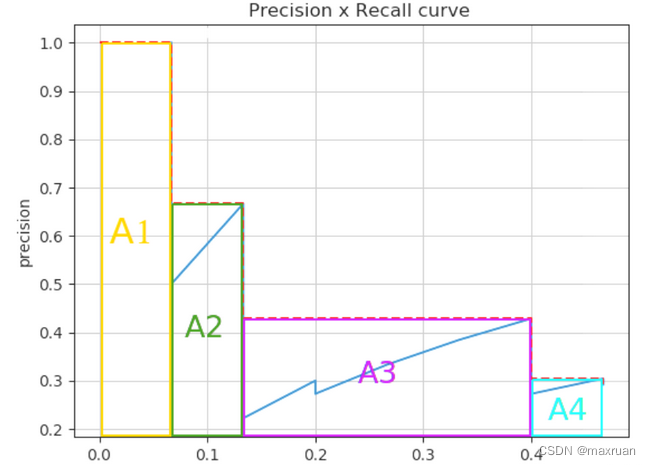
El AP original se define como:
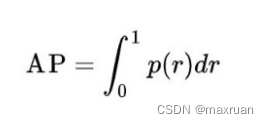 De hecho, todos usamos interpolación rectangular para cálculos aproximados.
De hecho, todos usamos interpolación rectangular para cálculos aproximados.
el código se muestra a continuación:
import os
import numpy as np
import json
import cv2 as cv
def xyhw2xyxy(xyhw):
x1 = xyhw[0] - xyhw[2] / 2
y1 = xyhw[1] - xyhw[3] / 2
x2 = xyhw[0] + xyhw[2] / 2
y2 = xyhw[1] + xyhw[3] / 2
return [x1, y1, x2, y2]
def load_pt(json_file):
# load pt from json files,
# get N x 6, 0:4 bbox, 4:conf 5:class
content = json.load(open(json_file, 'r', encoding="utf-8"))
if content is None:
return None
targes = content['targets']
tar_len = len(targes)
targets_pt = []
for i in range(tar_len):
# print(targes[i])
classid = []
conf = []
conf.append(targes[i]['conf'])
classid.append(targes[i]['classid'])
x1y1x2y2 = xyhw2xyxy(targes[i]['rect'])
targets_pt.append(x1y1x2y2 + conf + classid)
return np.array(targets_pt)
def load_gt(txt_file, H, W):
# load gt from txt files, yolo format,
# get N x 5, 0: label 1:5 bbox
f = open(txt_file)
lines = f.readlines()
targets = []
for line in lines:
contents = line.strip(" ").strip("\n").split(" ")
contents = [float(x) for x in contents]
# print(contents)
class_id = contents[0]
cx = contents[1] * W
cy = contents[2] * H
pw = contents[3] * W
ph = contents[4] * H
x1y1x2y2 = xyhw2xyxy([cx, cy, pw, ph])
targets.append([class_id, x1y1x2y2[0], x1y1x2y2[1], x1y1x2y2[2], x1y1x2y2[3]])
return np.array(targets)
def calc_iou(bbox1, bbox2):
if not isinstance(bbox1, np.ndarray):
bbox1 = np.array(bbox1)
if not isinstance(bbox2, np.ndarray):
bbox2 = np.array(bbox2)
xmin1, ymin1, xmax1, ymax1, = np.split(bbox1, 4, axis=-1)
xmin2, ymin2, xmax2, ymax2, = np.split(bbox2, 4, axis=-1)
area1 = (xmax1 - xmin1) * (ymax1 - ymin1)
area2 = (xmax2 - xmin2) * (ymax2 - ymin2)
ymin = np.maximum(ymin1, np.squeeze(ymin2, axis=-1))
xmin = np.maximum(xmin1, np.squeeze(xmin2, axis=-1))
ymax = np.minimum(ymax1, np.squeeze(ymax2, axis=-1))
xmax = np.minimum(xmax1, np.squeeze(xmax2, axis=-1))
h = np.maximum(ymax - ymin, 0)
w = np.maximum(xmax - xmin, 0)
intersect = h * w
union = area1 + np.squeeze(area2, axis=-1) - intersect
return intersect / union
def ap_per_class(tp, conf, pred_cls, target_cls, plot=False, save_dir='.', names=()):
# Sort by objectness
i = np.argsort(-conf)
tp, conf, pred_cls = tp[i], conf[i], pred_cls[i]
# Find unique classes
unique_classes = np.unique(target_cls)
nc = unique_classes.shape[0] # number of classes, number of detections
# Create Precision-Recall curve and compute AP for each class
px, py = np.linspace(0, 1, 1000), [] # for plotting
ap, p, r = np.zeros((nc, tp.shape[1])), np.zeros((nc, 1000)), np.zeros((nc, 1000))
for ci, c in enumerate(unique_classes):
i = pred_cls == c
# print(" pred_cls = ", pred_cls)
n_l = (target_cls == c).sum() # number of labels
n_p = i.sum() # number of predictions
if n_p == 0 or n_l == 0:
continue
else:
# Accumulate FPs and TPs
fpc = (1 - tp[i]).cumsum(0)
tpc = tp[i].cumsum(0)
# Recall
recall = tpc / (n_l + 1e-16) # recall curve
# print(" recall = ", recall)
r[ci] = np.interp(-px, -conf[i], recall[:, 0], left=0) # negative x, xp because xp decreases
# Precision
precision = tpc / (tpc + fpc) # precision curve
p[ci] = np.interp(-px, -conf[i], precision[:, 0], left=1) # p at pr_score
# AP from recall-precision curve
for j in range(tp.shape[1]):
ap[ci, j], mpre, mrec = compute_ap(recall[:, j], precision[:, j])
if plot and j == 0:
py.append(np.interp(px, mrec, mpre)) # precision at [email protected]
# Compute F1 (harmonic mean of precision and recall)
f1 = 2 * p * r / (p + r + 1e-16)
i = f1.mean(0).argmax() # max F1 index
return p[:, i], r[:, i], ap, f1[:, i], unique_classes.astype('int32')
def compute_ap(recall, precision):
# Append sentinel values to beginning and end
mrec = np.concatenate(([0.], recall, [recall[-1] + 0.01]))
mpre = np.concatenate(([1.], precision, [0.]))
# Compute the precision envelope
mpre = np.flip(np.maximum.accumulate(np.flip(mpre)))
# Integrate area under curve
method = 'interp' # methods: 'continuous', 'interp'
if method == 'interp':
x = np.linspace(0, 1, 101) # 101-point interp (COCO)
ap = np.trapz(np.interp(x, mrec, mpre), x) # integrate
else: # 'continuous'
i = np.where(mrec[1:] != mrec[:-1])[0] # points where x axis (recall) changes
ap = np.sum((mrec[i + 1] - mrec[i]) * mpre[i + 1]) # area under curve
return ap, mpre, mrec
## 评测一张图片
def value_one(pts, gts):
iouv = np.linspace(0.5, 0.95, 10) # iou vector for [email protected]:0.95
niou = iouv.shape[0]
correct = np.zeros((pts.shape[0], niou), dtype=np.bool)
nl = len(gts)
tcls_tensor = gts[:, 0]
tcls = gts[:, 0].tolist() if nl else [] # target class
for cls in np.unique(tcls_tensor):
ti = (cls == (gts[:, 0]).astype(np.uint8)).nonzero()[0] # prediction indices
pi = (cls == (pts[:, 5]).astype(np.uint8)).nonzero()[0] # target indices
if len(pi > 0):
IOUS = calc_iou(pts[pi, :4], gts[ti, 1:5])
ious = IOUS.max(1)
iid = IOUS.argmax(1)
detected = []
detected_set = set()
for j in ((ious > iouv[0]).nonzero()[0]):
d = ti[iid[j]]
if d.item() not in detected_set:
detected_set.add(d.item())
detected.append(d)
correct[pi[j]] = ious[j] > iouv # iou_thres is 1xn
if len(detected) == nl: # all targets already located in image
break
return correct, pts[:, 4], pts[:, 5], tcls
if __name__ == "__main__":
img_dir = "../images/"
predict_dir = "../jsons/"
target_dir = "../labels/"
img_H = 540
img_W = 960
colors = {
0: (255, 0, 0), 1: (0, 255, 0), 2: (0, 0, 255), 3: (255, 255, 0),
4: (255, 0, 255), 5: (0, 255, 255), 6: (255, 255, 255)}
types = {
0: 'person', 1: 'bike', 2: 'car', 3: 'motor', 4: 'bus', 5: 'truck'}
predict_list = os.listdir(predict_dir)
jdict, stats, ap, ap_class, wandb_images = [], [], [], [], []
n = 0
# value all images
for predict_name in predict_list:
predict_path = os.path.join(predict_dir, predict_name)
target_path = os.path.join(target_dir, predict_name).replace(".json", ".txt")
if not os.path.exists(target_path):
print("error : ", target_path)
continue
pts = load_pt(predict_path) # 加载predict
if pts is None:
continue
gts = load_gt(target_path, img_H, img_W) # 加载target
if gts.shape[0] == 0:
continue
# img_path = os.path.join(img_dir, predict_name).replace(".json", ".jpg")
# img = cv.imread(img_path)
# for pt in pts:
# type1 = int(pt[5])
# #图片, 左上角, 右下角, 颜色, 线条粗细, 线条类型,点类型
# cv.rectangle(img, (int(pt[0]), int(pt[1])), (int(pt[2]),int(pt[3])), colors[type1], 1, 4, 0)
# for gt in gts:
# type2 = int(gt[0])
# #cv.rectangle(img, (int(gt[0]), int(gt[1])), (int(gt[2]), int(gt[3])), colors[type2], 1, 4, 0)
# cv.imshow("img", img)
# cv.waitKey(0)
# Append statistics (correct, conf, pcls, tcls)
correct, conf, pcls, tcls = value_one(pts, gts) # value one
stats.append((correct, conf, pcls, tcls)) # add value one result
n += 1
#### after load all images ####
print(" n = ", n)
stats = [np.concatenate(x, 0) for x in zip(*stats)] # to numpy
if len(stats) and stats[0].any():
print(" res : ")
p, r, ap, f1, ap_class = ap_per_class(*stats, plot=False, save_dir="./", names="hello")
print("p = ", p)
print("r = ", r)
print("ap = ", ap)
ap50, ap = ap[:, 0], ap.mean(1) # [email protected], [email protected]:0.95
mp, mr, map50, map = p.mean(), r.mean(), ap50.mean(), ap.mean()
print("mp = ", mp)
print("mr = ", mr)
print("map50 = ", map50)
print("map = ", map)