El enfoque de este artículo es Robusto, lo que significa que los métodos propuestos por el autor conducen a la estabilidad de la red y la reducción de errores. La arquitectura de la tarea VSR se divide en alineación y fusión SR. En la parte de alineación, el autor propuso la red de alineación espacialRed alineada en el tiempo; En la parte de fusión SR, el autor proponeRed adaptativa espacialred neuronal adaptativa temporal。
Enlace original: RVSR: Robust Video Super-Resolution With Learned Temporal Dynamics【2017 ICCV】
Artículo de referencia: Robust VSR with Learned Temporal Dynamics
RVSR: Súper resolución de video robusta con dinámica temporal aprendida
Abstracto
La tarea SISR hace un uso completo de la información espacial de una sola imagen, y la tarea VSR, debido a que hay múltiples fotogramas adyacentes en el tiempo, la información temporal entre fotogramas también es muy importante. El movimiento muy complejo es difícil de modelar y el manejo inadecuado puede afectar negativamente la reconstrucción de la imagen. Cómo usar la información de tiempo entre fotogramas de manera razonable y eficiente es muy importante. Por ello, el autor propone ideas desde dos vertientes:
- se le ocurrióRed neuronal adaptativa espacialred neuronal adaptativa temporal. Es posible determinar adaptativamente la escala dependiente del tiempo óptima (fusionando varios fotogramas consecutivos), utilizando filtros de diferentes escalas de tiempo en la fusión.
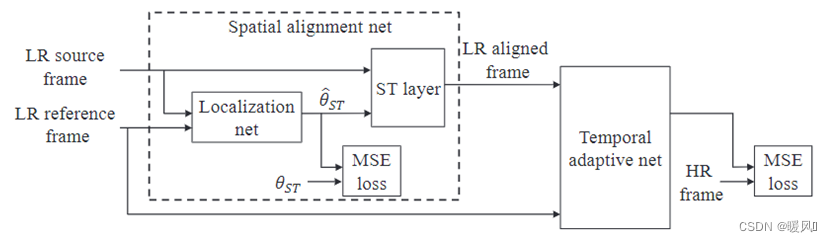
- se le ocurrióRed alineada en el tiempored de alineación espacial. Para reducir la complejidad del movimiento entre fotogramas adyacentes. Reduzca el impacto de los errores de compensación de movimiento en el entrenamiento posterior de la red, logrando así una mayor estabilidad y robustez.
- La red alineada en el tiempo y la red de fusión adaptable al espacio están conectadas en serie, de modo que toda la red se convierte en unde extremo a extremored entrenada.
1. Introducción
Con el fin de mejorar el rendimiento de la red 稳定性, el autor propone dos métodos para mejorar el problema de la estimación imprecisa del flujo óptico con el fin de reducir el error de la red. La red general se divide en dos partes: una red espacialmente alineada y una red temporalmente adaptable en serie.
El módulo de alineación depende en gran medida de la precisión de la estimación de movimiento en los métodos basados en el flujo óptico . Los movimientos suaves y diminutos son muy fáciles de capturar y restaurar. Si se producen movimientos complejos y de gran escala, es probable que se produzcan grandes errores durante la estimación del movimiento (durante el proceso de grandes movimientos, es difícil adivinar qué tipo de trayectoria es) . Una estimación de movimiento inexacta puede afectar seriamente el rendimiento de SR.
-
A partir de este problema, el autor proponeRed adaptable al tiempo, que puede manejar de manera estable varios tipos de movimiento y seleccionar de forma adaptativa el mejor rango dependiente del tiempo para mitigar los efectos adversos de la estimación de movimiento errónea entre fotogramas consecutivos. La red toma como entrada múltiples cuadros LR alineados que han sido compensados por movimiento y aplica filtros de diferentes tamaños temporales para generar múltiples imágenes de estimación de cuadros HR . Al mismo tiempo , múltiples estimaciones de HR generadas se agregan de forma adaptativa de acuerdo con la confianza de compensación de movimiento inferida por otra rama en la red . (Inspirado en el módulo Inception de GoogLeNet) Mejoras en la calidad del flujo óptico: ① DBLP con un alto costo computacional ② Solo extrae información de movimiento de una única escala de tiempo fija VSRCNN . El modelo logra robustez aprendiendo a encontrar un equilibrio en la compensación de movimiento imperfecto a través de la red.
-
Además de modelar la información de movimiento en el dominio temporal, el movimiento también se puede compensar en el dominio espacial, lo que facilita el modelado en el dominio temporal. Los autores descubrieron que los métodos basados en el flujo óptico complejo pueden no ser óptimos, ya que los errores de estimación de los movimientos complejos pueden afectar negativamente a la SR posterior. Por lo tanto, solo se requiere estimación
少量的空间变换参数, lo que reduce la complejidad del movimiento y proporciona un método más estable para alinear diferentes fotogramas. Propuso unRed de alineación espacial, obtenga transformaciones espaciales adecuadas entre marcos y genere marcos de soporte alineados. Este método requiere poco tiempo y se puede conectar en cascada con la red adaptativa en el dominio del tiempo para el entrenamiento conjunto.
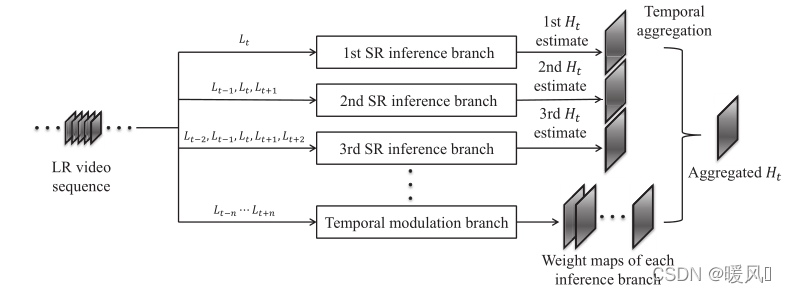
2 Red neuronal adaptativa temporal
Para VSR, lo más importante es cómo usar la información de tiempo para lidiar con varios tipos de movimiento. Los autores diseñan una escala de tiempo óptima de aprendizaje adaptativo. Se divide principalmente en dos partes: múltiples ramas de reconstrucción de SR y ramas de modulación de tiempo. Use N tipos de filtros de tiempo para superresolver la imagen SR H ti H_t^iHtyo; La rama de modulación de tiempo obtiene los pesos de atención de las N ramas anteriores; usa el peso para fusionar las N imágenes SR anteriores H ti H_t^iHtyoObtenga la salida final H t H_tHt。
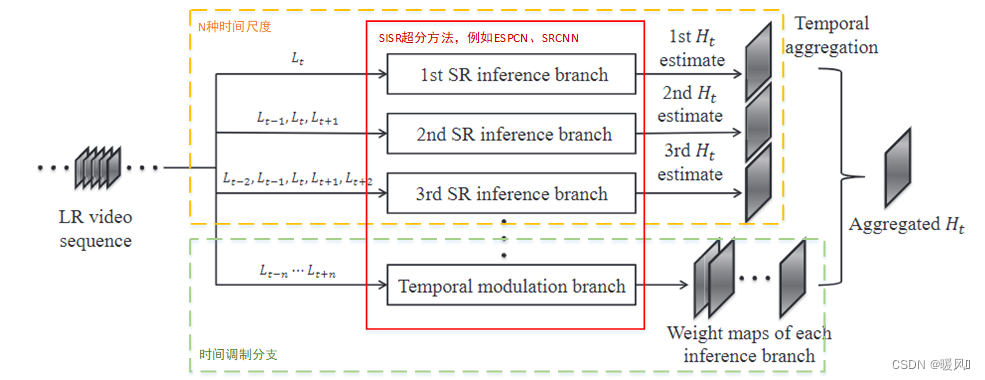
Rama delantera SR:
Hay un total de N ramas { B i } i = 1 N \{B_i\}^N_{i=1}{
Byo}yo = 1norte(N tipos de escalas de tiempo), cada uno utiliza un número diferente de filtros de tiempo, cada uno completa de forma independiente el trabajo de reconstrucción de SR y obtiene diferentes imágenes reconstruidas H ti H_t^iHtyo. yo _Artículo i rama y rama B i BiB i , la entrada es2 i − 1 2i-12i_ _−1 cuadro adyacente, utilizando el par de fusión temprana más simple2i − 1 2i-12i_ _−Se empalma 1 fotograma adyacente y el formato de entrada en este método de fusión es ( Lote , ( 2 i − 1 ) ∗ c , H , W ) (Lote, (2i-1)*c, H, W)( Lote , _ _ _ _( 2i _−1 )∗c ,H ,W ) , donde c es el número de canales por trama. Luego ingrese la red SR. En este artículo, se usa ESPCN, y también se pueden usar otras estructuras, como SRCNN.
Rama de modulación de tiempo:
se utiliza para seleccionar la escala de tiempo óptima (aquí se trata de seleccionar la distribución de peso de la escala de tiempo óptima, no para elegir 1 de N), que es el nivel de píxeles. Tiene la misma estructura de red que la rama directa SR. A diferencia de la rama directa SR, la entrada de esta rama es la secuencia de tiempo más larga en la rama directa, es decir, 2 N − 1 2N-12N _−1 cuadro continuo, esto se hace para cubrir de manera más completa todas las situaciones de entrada de la rama hacia adelante. La salida de esta ramaes NNN张权重图W i W_iWyo, cada mapa de peso y la salida de la rama anterior H ti H_t^iHtyoMultiplica los elementos y finalmente suma los N resultados para obtener el resultado final H t H_tHt。H t = ∑ yo W yo ⊙ H eso , yo ∈ { 1 , ⋯ , norte } H_t = \sum_i W_i\odot H_i^t, i\in\{1,\cdots,N\}Ht=i∑Wyo⊙Hit,i∈{
1 ,⋯,n }
PÉRDIDA:
La función de pérdida de la red adaptable en el tiempo usa L2LOSS:
min Θ ∑ j ∣ ∣ F ( y ( j ) ; Θ ) − x ( j ) ∣ ∣ 2 2 . (1) \min_{\Theta} \sum_j | |F(y^{(j)};\Theta) - x^{(j)}||_2^2.\tag{1}elminutoj∑∣ ∣ F ( y( j ) ;yo )−X( j ) ∣∣22.( 1 )
dondex ( j ) x^{(j)}X( j ) es eljjésimoImágenes HR correspondientes a j marcos de referencia, a saber, Ground Truth; y ( j ) y^{(j)}y( j ) representajjthTodos los marcos de alineación centrados en el marco de referencia del marco j , por lo que F ( y ( j ) ; Θ ) F(y^{(j)};\Theta)F ( y( j ) ;Θ ) representa la salida H tde toda la red adaptativa de tiempoHt.
Refinamiento adicional:
min θ w , { θ segundo yo } yo = 1 norte ∑ j ∣ ∣ ∑ yo = 1 NW yo ( y ( j ) ; θ w ) ⊙ FB yo ( y ( j ) ; θ segundo yo ) − x ( j ) ∣ ∣ 2 2 . (2) \min_{\theta_w,\{\theta_{B_i}\}_{i=1}^N} \sum_j ||\sum^N_{i =1}W_i (y^{(j)};\theta_w)\odot F_{B_i}(y^{(j)};\theta_{B_i}) - x^{(j)}||^2_2. \tag{2 }iw, {
yoByo}yo = 1norteminutoj∑∣ ∣yo = 1∑norteWyo( y( j ) ;iw)⊙FByo( y( j ) ;iByo)−X( j ) ∣∣22.( 2 )
Entre ellosWi W_iWyoRepresenta el mapa de peso de la salida de la red de modulación de tiempo en diferentes escalas de tiempo, θ w \theta_wiwRepresenta los parámetros de la red de modulación temporal, FB i ( y ( j ) ; θ B i ) F_{B_i}(y^{(j)};\theta_{B_i})FByo( y( j ) ;iByo) significaB i B_iByoLa salida H ti H_t^i de la rama delantera SRHtyo, número de referencia θ B yo \theta_{B_i}iByoIndica que B i B_iByoParámetros de red de ramas directas de SR; ⊙ \odot⊙ representa la multiplicación a nivel de elemento.
Durante el entrenamiento, 独立primero se entrenan ramas directas N SR y se obtienen redes N ESPCN con estructuras similares; luego, los parámetros entrenados se usan como parámetros de inicialización de la red adaptativa de tiempo, y la rama de modulación de tiempo se entrena usando la fórmula (2) y cada SR Ajuste fino en la rama delantera. Este método puede acelerar la convergencia de la red.
3 métodos de alineación espacial
En las tareas de VSR, la correlación espacial suele aumentar mediante la alineación temporal de fotogramas consecutivos, y se ha demostrado que la alineación de imágenes como paso de preprocesamiento mejora el rendimiento de las tareas de VSR.
3.1 Alineación de flujo óptico rectificado
El movimiento complejo es difícil de modelar. El método de flujo óptico se basa en la alineación de la imagen. Una estimación de movimiento inexacta introducirá artefactos, lo que afectará la calidad de la reconstrucción SR posterior. El autor trata de simplificar el movimiento a nivel de parche para obtener un desplazamiento de número entero para evitar el aliasing o el desenfoque causado por la interpolación. El autor proponeAlineación de flujo óptico corregidamétodo.
Alineación de flujo óptico correcta:
ingrese un parche, calcule la información de flujo óptico entre el marco de referencia y el marco de soporte en el parche, calcule el valor promedio del desplazamiento horizontal y el desplazamiento vertical de todos los píxeles en la dirección horizontal y dirección vertical, y redondee a un entero. Como la información de flujo óptico promedio de este parche . Obtenga el desplazamiento entero en dos direcciones del parche : θ ST x , θ ST y \theta_{ST}^x, \theta_{ST}^yiST _xyo _ST _tu. Todos los flujos ópticos promedio enteros se pueden obtener atravesando todos los parches del marco de referencia y el marco de soporte. Suponga que hay M parches en un cuadro, cada parche genera 2 parámetros de transformación y se obtiene un total de 2M parámetros de transformación . (Usando estos vectores de movimiento en el marco de soporte se puede obtener un valor estimado del marco de soporte, pero lo que se usa no es el valor estimado, sino la información de flujo óptico entero 2M obtenida en el proceso θ ST x , θ ST y \ theta_ { ST}^x, \theta_{ST}^yiST _xyo _ST _tu)。
3.2 Red de alineación espacial
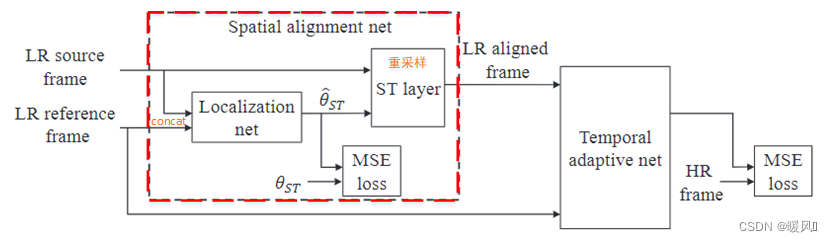
La entrada de la red de alineación espacial es generalmente 2 marcos adyacentes, uno de los cuales es un marco de referencia fijo I t I_tIt, y el otro es el marco de soporte dentro de la ventana de tiempo de la red adaptativa temporal antes mencionada, y el resultado final es la estimación de alineación del marco de soporte. Encuentre 2 N − 1 2N-12N _−Después de 1 marco de soporte continuamente alineado, se ingresa a la siguiente red adaptativa temporal para reconstruir la imagen de alta resolución del marco de referencia.
- Obtenga el parámetro de transformación de regresión θ ^ ST \hat{\theta}_{ST}i^ST _:
Primero, se ingresan 2 fotogramas de imágenes adyacentes a la red de localización a través de la fusión temprana (es decir, la profundidad es 2 × c 2\times c2×c ), devuelve el parámetro de transformaciónθ ^ ST \hat{\theta}_{ST}i^ST _, emiten respectivamente la transformación en dirección horizontal y la transformación en dirección vertical. Los parámetros devueltos por la regresión y las etiquetas de parámetros generadas por la alineación de flujo óptico rectificado se utilizan como pérdida de MSE para ayudar a optimizar los parámetros de transformación de la red de localización . Dado que la alineación de flujo óptico rectificado (ROF) se basa en parches, nuestra red de localización también se basa en parches.
La estructura de red de localización específica es: convolución + agrupación máxima + convolución + agrupación máxima + conexión completa + conexión completa.
Los parámetros son: C onv ( 2 c , 32 , 9 ) − Max P ool ( 2 , 2 ) − C onv ( 32 , 32 , 9 ) − Max P ool ( 1 , 2 ) − FCN ( 32 , 100 ) − FCN ( 100 , 2 ) Conv(2c,32,9)-MaxPool(2,2) - Conv(32,32,9) - MaxPool(1,2) - FCN(32,100) - FCN(100,2)Conv ( 2 c , _ _ _3 2 ,9 )−M a x P o o l ( 2 ,2 )−Conv ( 3 2 , _ _ _3 2 ,9 )−M a x P o o l ( 1 ,2 )−F C N ( 3 2 ,1 0 0 )−F C N ( 1 0 0 ,2 )
C onv ( canal de entrada , canal de salida , tamaño del núcleo ) , M ax P oo ( tamaño del núcleo , zancada ) , FCN ( número de entrada , número de salida ) Conv(entrada\_canal,salida\_canal, núcleo\_tamaño), MaxPoo(núcleo\_tamaño,paso),FCN(entrada\_números, salida\_números)Conv ( entrada_canal , _ _ _ _ _ _ _ _ _ _ _ _ _ _ _salida del canal , _ _ _ _ _ _ _ _tamaño_del_núcleo ) , _ _ _ _ _ _ _ _ _ _M a x P o o ( k e r n e l _ s i z e ,zancada ) , _ _ _ _ _F C N ( entrada _ n u m s , _ _ _ _salida p u t _ n u m s ) _ _
- Capa ST remuestreada
Aquí 和VESPCN中的重采样一样, los puntos de la cuadrícula (xs, ys) (x^s,y^s) del marco de soporte alineado (valor estimado del marco de soporte )( Xs ,ys )(xm, ym)en el marco de soporte a través de la transformación( Xm ,ym ), a través de la interpolación bilineal para obtener el valor de píxel correspondiente como el punto de cuadrícula de salida( xs , ys ) (x^s,y^s)( Xs ,ys )en el valor del píxel. Dado que la interpolación bilineal puede hacer que toda la red sea derivable, toda la red de alineación temporal se puede entrenar de extremo a extremo con la red de SR de fusión posterior.
Rango equivalente de esquemas SR:
min { Θ , θ L } ∑ j ∣ ∣ F ( y ( j ) ; Θ ) − x ( j ) ∣ ∣ 2 2 ⏟ Red adaptativa temporal + λ ∑ j ∑ k ∈ N j ∣ ∣ θ ^ ST ( k ) − θ ST ( k ) ∣ ∣ 2 2 ⏟ Red de alineación espacial . (3) \min_{\{\Theta,\theta_L\}} \underbrace{\sum_j ||F(y^{(j)};\Theta)-x^{(j)}||_2^2} _Red\;adaptativa\;temporal} + \lambda \underbrace{\sum_j\sum_{k\in \mathcal{N}_j}||\hat{\theta}_{ST}^{(k)}- \theta_{ST}^{(k)}||^2_2}_{Red de alineación espacial}.\tag{3}{
Θ , ΘL}minutoT e m p o r a la d a p t i v ered _ _ _ _ _ _
j∑∣ ∣ F ( y( j ) ;yo )−X( j ) ∣∣22+yoespacial _ _ _ _ _ _alineación _ _ _ _ _ _ _ _red _ _ _ _ _ _
j∑k ∈ nortej∑∣ ∣i^ST _( k )−iST _( k )∣ ∣22.( 3 )
donde N j \mathcal{N}_jnortejIndica el jjthTodoLR LR en j muestrasL R marco de referencia, par de entrada del marco de soporte;λ \lambdaλ se utiliza para equilibrar la pérdida de las dos partes.
La red de alineación espacial introduce una alineación de flujo óptico rectificado como el objetivo de los parámetros de salida de la red de localización en STN. Este proceso de agregar pérdida adicional en el proceso intermedio es un poco como el clasificador auxiliar en Inception-v2. La pérdida de la la red de alineamiento es solo acerca de la localización Pérdida de MSE de red. La salida STN es el vector de movimiento de imagen Δ \DeltaΔ . La red de localización produce 2 elementos, a( 2 , ) (2,)( 2 ,) formato tensor 1D.
4 experimentos
Conjunto de entrenamiento: base de datos de evaluación de calidad de video LIVE, base de datos MCL-V, conjunto de datos TUM 1080p.
Conjunto de prueba: 6 escenas clásicas : calendario, ciudad, follaje, pingüino, templo, caminata; y conjunto de video 4k: base de datos de Ultra Video Group .
Todos los datos de LR se obtienen por interpolación bicúbica de las imágenes de HR en el conjunto de datos anterior.
Todos los experimentos se basan en el espacio de color YCbCr y solo 亮度(Y)se procesan los canales que contiene, es decir, c=1.
La relación de zoom SR r = 4, porque esta relación puede reflejar la capacidad del algoritmo en VSR.
La entrada de la red adaptable al tiempo es 5 × 30 × 30 5\times 30\times 305×3 0×3 0 , es decir连续的5帧(esto indica el número máximo de fotogramas consecutivos), cada fotograma es un30 × 30 30\times 303 0×3 0 parches.
Técnicas de autointegración: rotación, espejo, escalado.
Batchsize=64, se entrenan un total de 500 W iteraciones.
Además de los parámetros de convolución de la primera capa de cada rama, los parámetros iniciales de la red de rama directa SR utilizan los parámetros del modelo SISR; en cuanto a la primera capa, se pueden copiar los mismos parámetros en el SISR para cada dimensión de tiempo . Esta estrategia de inicialización puede acelerar la convergencia. Además, los parámetros después de cada entrenamiento de bifurcación directa pueden continuar utilizándose como parámetros de inicialización de toda la red adaptativa temporal. Por lo tanto, hay dos procesos de inicialización de parámetros en total.
El proceso experimental específico se puede ver en este VSR súper robusto con dinámica temporal aprendida
5 Conclusiones
La estructura principal de este artículo consta de dos partes: red de alineación espacial y red adaptativa temporal.
- Red de alineación espacial, basado en el método STN, usando ROF como objetivo para optimizar los parámetros de transformación, agregando una pérdida adicional que solo optimiza los parámetros de la red de alineación.
- Red adaptativa temporal, introduce un mecanismo de autoatención, usa N ramas directas SR paralelas y ramas de modulación de tiempo para generar la escala de tiempo óptima para la selección automática, y reconstruye los fotogramas de video continuos alineados por la red anterior en imágenes HR.
- El defecto de esta red es principalmente la red de alineación de tiempo: por un lado, su esencia es un método basado en flujo.
高度依赖于光流估计的准确性Una vez que la estimación de movimiento es incorrecta, hará que aparezca una gran cantidad de artefactos y afectará directamente a la siguiente. Fusión de red SR. El segundo aspecto es大运动la falta de capacidad para enfrentarlo, que también se puede ver en el experimento.
Finalmente, les deseo a todos éxito en la investigación científica, buena salud y éxito en todo ~