В этой статье в основном используются некоторые стратегии обучения 知识蒸馏для повышения скорости обучения и производительности модели.
Исходная текстовая ссылка: Обучение преобразователям изображений с эффективным использованием данных и дистилляция с помощью внимания
Адрес исходного кода: https://github.com/facebookresearch/deit
Хорошая статья написана: Преобразовательное обучение (4) -
Дистилляция знаний DeiT может просто прочитать это введение: Знания Дистилляция (Знание Дистилляция) классика, бумажные заметки
Обучение преобразователям изображений и дистилляции с эффективным использованием данных с помощью внимания[PMLR2021]
Абстрактный
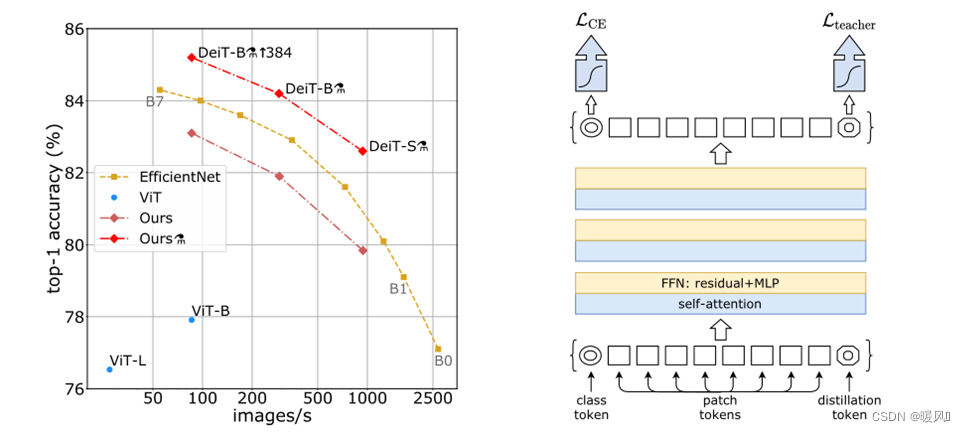
Хотя ViT имеет очень высокую производительность в задачах классификации, он использует большую инфраструктуру для предварительной подготовки сотен миллионов изображений для получения текущего эффекта Эти два условия ограничивают его применение.
Поэтому автор предлагает метод 新的训练策略, который использует только один компьютер для обучения конкурентоспособного преобразователя без свертки в ImageNet менее чем за 3 дня. Без внешних данных самая высокая точность 83,1% ((86M параметров)) достигается на ImageNet.
Во-вторых, автор предлагает 基于知识蒸馏的策略. Полагаясь на токен дистилляции, чтобы гарантировать, что модель ученика учится у модели учителя посредством внимания, обычно модель учителя основана на свертке. Обученный Transformer конкурентоспособен с самым современным на ImageNet (85,2%).
1. Введение
В последнее время возрастает интерес к архитектурам, использующим механизм внимания в консетях, предлагая гибридные архитектуры, которые переносят компоненты преобразователя в конвнеты для решения задач машинного зрения. В этой статье автор использует чистую структуру Transformer, но в стратегии дистилляции знаний сеть convnet используется в качестве сети учителя для обучения, которая может наследовать индуктивный уклон в convnet.
Модель ViT использует большой набор данных изображений с частной маркировкой, содержащий 300 миллионов изображений, для достижения наилучших результатов, и также делается вывод, что она не может хорошо обобщать при обучении на недостаточном количестве данных.
В этой статье авторы обучают Vision Transformer за два-три дня (53 часа предварительной подготовки и дополнительно 20 часов тонкой настройки) на узле 8GPU, что сравнимо с ConvNet с аналогичным количеством параметры и эффективность. Используйте Imagenet в качестве единственного обучающего набора .
Автор также использовал стратегию дистилляции на основе токенов при извлечении модели, в которой ⚗ используется в качестве символа дистилляции.
Подводя итоги, можно сделать следующие взносы:
- В сети
不包含卷积层конкурентоспособные результаты по сравнению с современным уровнем техники могут быть достигнуты на ImageNet без внешних данных. Два новых варианта модели, DeiT-S и DeiT-Ti, имеют меньше параметров и могут рассматриваться как аналоги ResNet-50 и ResNet-18. - Вводится новый процесс дистилляции, основанный на дистиллированных токенах, который играет ту же роль, что и токены класса, за исключением того, что его целью является воспроизведение сети учителя
估计标签. Эти две лексемы взаимодействуют в преобразователе посредством внимания. - Модели, предварительно изученные на Imagenet,
转移到不同的下游任务конкурентоспособны на уровне .
2 Метод
Стратегия обучения:
обучение с более низким разрешением и точная настройка сети с более высоким разрешением, что ускоряет полное обучение и повышает точность в основных схемах увеличения данных.
При увеличении разрешения входного изображения размер патча сохраняется постоянным, поэтому количество N входных патчей изменяется. Благодаря архитектуре блоков-преобразователей и токенов классов нет необходимости модифицировать модель и классификатор для обработки большего количества токенов. Вместо этого необходимо настроить позиционные вложения, поскольку существует N позиционных вложений, по одному на каждый патч.
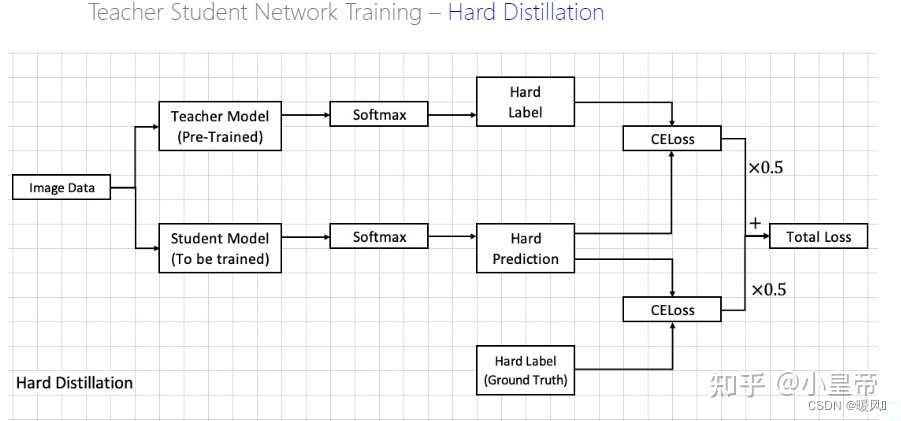
Дистилляция: сначала мы предполагаем, что мощный классификатор изображений можно использовать в качестве модели учителя. Это может быть коннет или смесь классификаторов. В этом разделе представлены: жесткая дистилляция и мягкая дистилляция, а также символическая дистилляция.
Прежде всего, позаимствуйте изображение Маленького императора Чжиху . Модель учителя - это известная модель с большим объемом и превосходным эффектом. В процессе дистилляции модель учителя не обучается, она используется только в качестве ориентира для направления изображения. найти учителя Параметры в модели соответствуют нашим потребностям. На самом деле мы просто используем другую информацию, полученную в процессе отображения модели учителя. При обучении обычной модели классификации единственная информация, которая у нас есть, это изображение и метка классификации , Если это класс этого класса, это 1, а если нет, то это 0. Однако в процессе обучения модели учителя вероятность различных категорий получается через функцию softmax.Это распределение вероятности мы используем для обучения модели ученика.Помимо положительных выборок, отрицательные выборки также содержат много информации, но Ground Truth не может предоставить эту часть информации.Распределение вероятностей модели учителя эквивалентно добавлению некоторой новой информации о метках во время обучения модели ученика. Для более подробного содержания вы можете увидеть эту ссылку: Дистилляция знаний
1. Мягкая дистилляция:
минимизировать расхождение Кульбака-Лейблера между softmax модели учителя и softmax модели ученика . Предположим, Zt — логиты модели учителя, а Zs — логиты модели ученика. Пусть τ обозначает температуру дистилляции, λ обозначает коэффициенты потерь на расхождение Кульбака-Лейблера (KL) и кросс-энтропию (LCE) на сбалансированной наземной метке истинности y, а ψ обозначает функцию softmax. Цель перегонки : расчет нормальной потери части у, а второй половины - дивергенция.
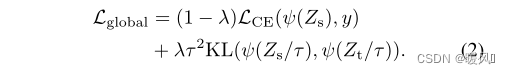
2. Вариант жесткой перегонки:
вывести предсказание модели Учителя yt = argmaxc Z t ( c ) y_t = argmax_cZ_t(c)ут"="а р г м а хвZт( c ) В качестве истинной метки для данного изображения используется жесткая меткаyt y_t,утМожет варьироваться в зависимости от добавления конкретных данных. Этот вариант превосходит традиционный, но не содержит параметров и концептуально проще: учитель предсказывает yt y_tутИграет ту же роль, что и настоящая метка y. Цель перегонки:
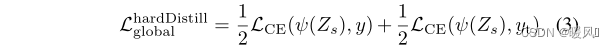
3. Перегонный жетон:
В начальное встраивание (патч и токен класса) добавляется новый токен, токен дистилляции . Токен дистилляции аналогичен токену класса: он взаимодействует с другими вложениями через самовнимание и выводится сетью после последнего слоя. Дистиллированные вложения позволяют модели изучать прогнозируемый результат модели учителя, который не только изучает предварительные знания модели учителя, но также дополняет вложение класса.
Стратегия дистилляции:
微调:Наземные метки истины и прогнозы учителей используются на этапе тонкой настройки с более высоким разрешением. Используя модель учителя с тем же целевым разрешением, на этапе тестирования используются только истинные метки.联合分类器. Во время тестирования класс или дистиллированные вложения, сгенерированные преобразователем, связаны с линейным классификатором и могут выводить метки изображений. Эти две независимые головки объединяются на более позднем этапе, и для прогнозирования добавляются выходные данные softmax двух классификаторов.
Сравнение результатов различных методов дистилляции написано в экспериментальной части.
3 Заключение
Эта статья не улучшает саму модель ViT , но использует некоторые стратегии обучения, чтобы упростить обучение и повысить производительность модели.
Суть этой статьи заключается в использовании стратегии дистилляции знаний , которая увеличивает прогностическую информацию отрицательных выборок в процессе обучения модели и наследует индуктивный уклон в модели учителя (эффект коннета лучше, чем у Трансформера), что на самом деле является своего рода информацией на этикетке.
Напоследок желаю всем успехов в научных исследованиях, крепкого здоровья и успехов во всем~