Este artículo son las notas de lectura del Capítulo 5 Gestión y mantenimiento de la información basada en el tiempo de Oracle 19c VLDB y la Guía de partición.
Oracle Database proporciona políticas para administrar y mantener datos en función del tiempo.
Este capítulo analiza los componentes de la base de datos Oracle que permiten crear estrategias basadas en el tiempo para gestionar y mantener los datos.
Aunque la mayoría de las organizaciones han considerado durante mucho tiempo que su almacenamiento de datos es uno de sus activos corporativos más valiosos, la forma en que se administran y mantienen estos datos varía de una compañía a otra. Inicialmente, los datos se usaban para ayudar a alcanzar los objetivos operativos, administrar el negocio y ayudar a determinar la dirección y el éxito futuros de la empresa.
Sin embargo, las nuevas regulaciones y pautas gubernamentales son factores clave de cómo y por qué se conservan los datos. Las regulaciones actuales exigen que las organizaciones retengan y controlen la información durante largos períodos de tiempo. Como resultado, los gerentes de tecnología de la información (TI) de hoy se esfuerzan por alcanzar otras metas:
- Almacene grandes cantidades de datos al menor costo posible
- Cumpla con los nuevos requisitos reglamentarios para la retención y protección de datos
- Aumente las oportunidades comerciales a través de mejores análisis basados en más datos
5.1 Gestión de datos en Oracle Database con ILM
Con la Gestión del ciclo de vida de la información (ILM), puede gestionar datos en una base de datos de Oracle utilizando las normas y reglamentos que se aplican a esos datos.
La información actual viene en muchos tipos, como mensajes de correo electrónico, fotos o pedidos en un sistema de procesamiento de transacciones en línea (OLTP). Una vez que comprenda los tipos de datos y cómo se utilizan, podrá comprender cómo evolucionan y cómo se eliminan en última instancia.
Un desafío para cada organización es comprender cómo evolucionan y crecen sus datos, monitorear cómo cambia su uso con el tiempo y decidir cuánto tiempo deben conservarse, mientras se cumplen todas las reglas y regulaciones que ahora se aplican a esos datos . La gestión del ciclo de vida de la información (ILM) tiene como objetivo abordar estos problemas a través de una combinación de procesos, políticas, software y hardware para que se pueda utilizar la tecnología adecuada en cada etapa del ciclo de vida de los datos .
5.1.1 Acerca de la base de datos Oracle para ILM
Oracle Database proporciona una plataforma ideal para implementar soluciones ILM.
La plataforma Oracle Database proporciona las siguientes capacidades:
-
Transparencia de la aplicación
La transparencia de la aplicación es muy importante en ILM porque significa que no hay necesidad de personalizar la aplicación y que se pueden realizar varios cambios en los datos sin ningún impacto en las aplicaciones que usan los datos. Los datos se pueden mover fácilmente a través de diferentes etapas de su ciclo de vida y el acceso a los datos se puede optimizar utilizando la base de datos. Otro beneficio importante es que la transparencia de las aplicaciones brinda la flexibilidad necesaria para adaptarse rápidamente a cualquier requisito normativo nuevo, nuevamente sin ningún impacto en las aplicaciones existentes. -
Datos detallados
Oracle puede ver datos en un nivel muy detallado y agrupar datos relacionados, mientras que los dispositivos de almacenamiento solo ven bytes y bloques. -
Almacenamiento de bajo costo
Con tantos datos retenidos, el uso de almacenamiento de bajo costo es un factor clave en la implementación de ILM. Debido a que Oracle puede aprovechar muchos tipos de dispositivos de almacenamiento, puede almacenar la mayor cantidad de datos al menor costo posible. -
Políticas de cumplimiento exigibles
Cuando la información se retiene por motivos de cumplimiento, se debe mostrar a los reguladores que los datos se retienen y administran de acuerdo con las reglamentaciones. En Oracle Database, puede definir políticas de seguridad y auditoría que aplican y registran todos los accesos a los datos.
5.1.1.1 Oracle Database gestiona todo tipo de datos
La gestión del ciclo de vida de la información afecta a todos los datos de una organización.
Estos datos incluyen no solo datos estructurados, como pedidos en un sistema OLTP o historial de ventas en un almacén de datos, sino también datos no estructurados, como correos electrónicos, documentos e imágenes. Oracle Database admite BLOB y Oracle SecureFiles para almacenar datos no estructurados, y un sofisticado sistema de gestión de documentos está disponible en Oracle Text.
Si toda la información de su organización está contenida en una base de datos de Oracle, puede aprovechar las características y capacidades que proporciona la base de datos para administrar y mover la evolución de los datos a lo largo de su ciclo de vida sin tener que administrar múltiples tipos de almacenes de datos .
5.1.1.2 Requisitos reglamentarios
Muchas organizaciones deben conservar datos específicos durante un período de tiempo específico. El incumplimiento de estas normas puede resultar en que las organizaciones tengan que pagar multas sustanciales.
Varios requisitos normativos en todo el mundo, como Sarbanes-Oxley, HIPAA, DOD5015.2-STD en los EE. UU. y la Directiva europea de privacidad de datos en la UE, están cambiando la forma en que las organizaciones administran sus datos. Estas normas dictan qué datos se deben conservar, si se pueden modificar y durante cuánto tiempo se deben conservar , que pueden ser 30 años o más.
Estas reglamentaciones a menudo exigen que los datos electrónicos estén protegidos contra el acceso y la alteración no autorizados, y que se mantenga un registro de auditoría de todos los cambios en los datos y por parte de quién . Oracle Database puede retener grandes cantidades de datos sin afectar el rendimiento de la aplicación . También incluye las funciones necesarias para restringir el acceso y evitar cambios no autorizados en los datos, y se puede mejorar aún más con Oracle Audit Vault y Database Firewall. Oracle Database también proporciona funciones criptográficas que pueden probar que un usuario privilegiado no modificó los datos intencionalmente. Con la tecnología Flashback Data, puede almacenar todas las versiones de una fila durante su vida útil en un archivo histórico a prueba de manipulaciones.
5.1.1.3 Los beneficios de un archivo en línea
Hay muchos beneficios de archivar en línea .
Durante el ciclo de vida de los datos, por lo general llega un punto en el que ya no se accede a ellos con regularidad y se los considera aptos para el archivo. Tradicionalmente, los datos se eliminan de la base de datos y se almacenan en cinta, donde puede almacenar grandes cantidades de información a un costo muy bajo. Hoy en día, en lugar de archivar estos datos en una cinta, se pueden guardar en la base de datos o transferir a una base de datos de archivo central en línea. Toda esta información se puede almacenar usando dispositivos de almacenamiento de bajo costo que cuestan muy cerca de una cinta por gigabyte.
Hay muchos beneficios de mantener todos los datos en una base de datos de Oracle para archivar. El beneficio más importante es que los datos siempre están disponibles de inmediato . Por lo tanto, no se pierde tiempo buscando cintas para datos archivados y determinando si las cintas son legibles y todavía están en un formato que se puede cargar en la base de datos.
Si los datos se han archivado durante muchos años, es posible que también se requiera tiempo de desarrollo para escribir el programa para volver a cargar los datos del archivo de cinta en la base de datos. Esto puede resultar costoso y llevar mucho tiempo, especialmente si los datos son muy antiguos. Si los datos se mantienen en la base de datos, esto no es un problema, ya que está en línea y en el formato de base de datos más reciente.
Mantener los datos históricos en la base de datos ya no afecta el tiempo necesario para realizar la copia de seguridad de la base de datos ni el tamaño de la copia de seguridad. Cuando se usa RMAN para hacer una copia de seguridad de una base de datos, solo incluye los datos modificados en la copia de seguridad. Debido a que es poco probable que los datos históricos cambien, los datos respaldados no se volverán a respaldar .
Otro factor importante a considerar es cómo se eliminan físicamente los datos de la base de datos , especialmente si los datos se transfieren desde un sistema de producción a un archivo de base de datos central. Oracle brinda la capacidad de mover estos datos rápidamente entre bases de datos mediante el uso de particiones o espacios de tablas transportables , que mueven los datos como una unidad completa.
Cuando necesite eliminar datos de la base de datos, la forma más rápida es eliminar un conjunto de datos. Esto se logra manteniendo los datos en su propia partición. Las particiones se pueden eliminar, lo cual es una operación muy rápida. Sin embargo, si no se puede usar este método porque se deben mantener las relaciones de datos, se debe emitir una declaración de eliminación de SQL regular. No debe subestimar el tiempo que lleva emitir una declaración de eliminación.
Si es necesario eliminar datos de la base de datos y es posible que sea necesario devolver datos a la base de datos en el futuro, considere eliminar datos en un formato de base de datos, como tablespace transportable, o usar la capacidad de XML Oracle Database para extraer información. en un formato abierto.
Considere archivar sus datos en línea en una base de datos de Oracle por las siguientes razones:
- El costo del disco es similar al costo de la cinta, por lo que se ahorra el tiempo de encontrar la cinta que contiene los datos y el costo de recuperar esos datos.
- Los datos permanecen en línea cuando se necesitan, lo que le brinda un acceso más rápido para satisfacer las necesidades comerciales
- Los datos en línea significan acceso instantáneo , por lo que es menos probable que los reguladores sean multados por no proporcionar datos
- Se puede acceder a los datos utilizando las aplicaciones actuales , por lo que no necesita desperdiciar recursos creando nuevas aplicaciones.
5.1.2 Implementación de ILM mediante la base de datos Oracle
Crear una solución de gestión del ciclo de vida de la información con Oracle Database es sencillo.
Una solución ILM se puede lograr en cuatro pasos simples, aunque el paso 4 es opcional si no se implementa ILM para el cumplimiento:
- Paso 1: Definir la clase de datos
- Paso 2: Cree una capa de almacenamiento para la clase de datos
- Paso 3: crear políticas de migración y acceso a datos
- Paso 4: Definir y hacer cumplir una política de cumplimiento
5.1.2.1 Paso 1: Definir las clases de datos
Para utilizar de forma eficaz la gestión del ciclo de vida de la información, empiece por examinar todos los datos de su organización antes de implementar una solución de gestión del ciclo de vida de la información.
Después de revisar los datos, determina lo siguiente:
- Qué datos son importantes, dónde se almacenan y qué se debe conservar
- Cómo fluyen estos datos dentro de la organización
- ¿Cómo cambiarán estos datos con el tiempo y si todavía son necesarios?
- Disponibilidad de datos requeridos y grado de protección
- Retención de datos para requisitos legales y comerciales
Una vez que comprenda el propósito de los datos, puede clasificar los datos sobre esta base. Los tipos de clasificación más comunes son por año o fecha, pero son posibles otros tipos, como por producto o privacidad. También hay disponibles clasificaciones mixtas, como por privacidad y año.
Para tratar las clases de datos de manera diferente, los datos deben estar separados físicamente . Cuando la información se crea inicialmente, por lo general se accede a ella con frecuencia, pero con el tiempo puede ser menos referenciada. Por ejemplo, cuando un cliente realiza un pedido, verifica periódicamente el pedido para ver su estado y si se ha enviado. Una vez que llega un pedido, es posible que nunca vuelvan a consultarlo. Este pedido también se incluirá en los informes periódicos que se ejecutan para ver qué artículos se están ordenando, pero no aparecerá en ningún informe a lo largo del tiempo y solo se hará referencia en el futuro si alguien hace un análisis detallado al respecto. Por ejemplo, los pedidos se pueden categorizar por trimestres fiscales Q1, Q2, Q3 y Q4, o pedidos históricos.
La ventaja de usar este enfoque es que cuando los datos se agrupan en el nivel de fila por categoría, en este caso, la fecha del pedido, todos los pedidos del primer trimestre se pueden administrar como una sola unidad , mientras que los pedidos del segundo trimestre residirán en una clase diferente. Esto se puede lograr mediante el uso de particiones. Dado que la partición es transparente para la aplicación , los datos se separan físicamente, pero la aplicación aún puede encontrar todos los pedidos.
5.1.2.1.1 Particionamiento para ILM
La partición implica colocar datos físicamente en función de su valor, y una técnica utilizada con frecuencia es dividir la información por fecha.
La Figura 5-1 ilustra un escenario en el que los pedidos para el primer trimestre, el segundo trimestre, el tercer trimestre y el cuarto trimestre se almacenan en particiones separadas, mientras que los pedidos de años anteriores se almacenan en otras particiones.
Figura 5-1 Asignación de clases de datos a particiones
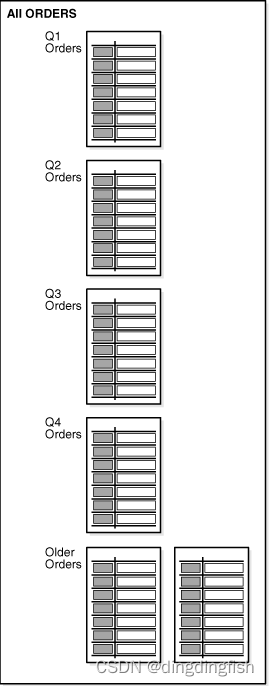
Oracle proporciona varios métodos de partición diferentes. La partición de rango es un método de partición común en ILM. Las particiones de intervalo y de referencia también son especialmente adecuadas para su uso en entornos ILM.
La partición de datos tiene muchos beneficios. El particionamiento proporciona una manera fácil de distribuir datos entre los dispositivos de almacenamiento apropiados en función de su uso, al mismo tiempo que mantiene los datos en línea y almacenados en el dispositivo más rentable . Debido a que la partición es transparente para cualquier persona que acceda a los datos, no se requieren cambios en la aplicación , por lo que la partición se puede implementar en cualquier momento. Cuando se necesitan nuevas particiones, simplemente se agregan mediante la cláusula ADD PARTITION o, si se usa la partición por intervalos, se crean automáticamente.
Entre otros beneficios, cada partición puede tener su propio índice local. Cuando el optimizador utiliza la eliminación de particiones, las consultas solo acceden a las particiones relevantes en lugar de a todas las particiones, lo que mejora el tiempo de respuesta de las consultas.
5.1.2.1.2 El ciclo de vida de los datos
Un análisis de sus datos puede revelar que inicialmente se accede a ellos y se actualizan con mucha frecuencia. A medida que los datos envejecen, su frecuencia de acceso disminuye hasta ser insignificante (si es que lo es).
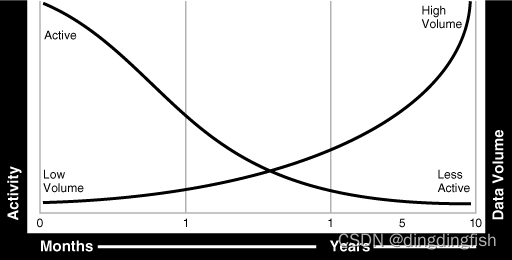
La mayoría de las organizaciones se encuentran en una situación en la que muchos usuarios acceden a los datos actuales y muy pocos acceden a los datos heredados, como se muestra en la Figura 5-2. Se consideran datos: activos, menos activos, históricos o listos para archivar .
Dado que se guardan tantos datos, se deben mover a diferentes ubicaciones físicas durante su vida útil . Dependiendo de dónde se encuentren los datos en su ciclo de vida, deben estar en el dispositivo de almacenamiento más adecuado.
Figura 5-2 Uso de datos a lo largo del tiempo
5.1.2.2 Paso 2: Crear niveles de almacenamiento para las clases de datos
Dado que Oracle Database puede aprovechar muchas opciones de almacenamiento diferentes, el segundo paso para implementar una solución de gestión del ciclo de vida de la información es establecer los niveles de almacenamiento necesarios.
Aunque puede crear tantos niveles de almacenamiento como desee, se recomienda comenzar con los siguientes niveles:
-
Alto rendimiento
El nivel de almacenamiento de alto rendimiento almacena todos los datos importantes ya los que se accede con frecuencia , como las particiones que contienen nuestros pedidos del primer trimestre. Esta capa utiliza discos más pequeños y rápidos en dispositivos de almacenamiento de alto rendimiento. -
Bajo costo
El nivel de almacenamiento de bajo costo almacena datos a los que se accede con poca frecuencia, como particiones que contienen pedidos del segundo, tercer y cuarto trimestre. Este nivel se crea con discos de alta capacidad, como los de las matrices de almacenamiento modular o los discos ATA de bajo costo, que brindan la máxima cantidad de almacenamiento económico. -
Archivo en línea
El nivel de almacenamiento de Archivo en línea es donde se almacenan todos los datos a los que rara vez se accede o se modifican. Esta capa de almacenamiento puede ser muy grande y almacena la mayor cantidad de datos. Puede utilizar varias técnicas para comprimir datos. Los datos almacenados en dispositivos de almacenamiento de bajo costo, como unidades ATA, permanecen en línea y disponibles a un costo ligeramente superior al de almacenar esta información en cinta, sin las desventajas que conlleva archivar datos en cinta. Si el nivel de almacenamiento del archivo en línea está marcado como de solo lectura, es imposible cambiar los datos y no se requieren copias de seguridad posteriores después de la copia de seguridad inicial de la base de datos. -
Archivo sin conexión (opcional)
El nivel de almacenamiento de archivo sin conexión es un nivel opcional porque solo se usa cuando es necesario eliminar los datos de la base de datos y almacenarlos en otro formato, como XML en cinta.
La figura 5-2 ilustra cómo se utilizan los datos dentro de un intervalo de tiempo. Con esta información, se puede determinar que para retener toda esta información, se requieren múltiples niveles de almacenamiento para almacenar todos los datos, lo que también tiene la ventaja de reducir significativamente los costos generales de almacenamiento.
Después de crear el nivel de almacenamiento, las clases de datos identificadas en el Paso 1: Definir clases de datos se implementarán físicamente dentro de la base de datos mediante particiones. Este enfoque proporciona una manera fácil de distribuir datos a través de dispositivos de almacenamiento apropiados en función de su uso, al mismo tiempo que mantiene los datos en línea y fácilmente disponibles, y almacenados en el dispositivo más rentable.
También puede usar Oracle Automatic Storage Management (Oracle ASM) para administrar datos en todos los niveles de almacenamiento. Oracle ASM es una solución de almacenamiento de archivos de alto rendimiento y fácil de administrar para Oracle Database. Oracle ASM es un administrador de volúmenes que proporciona un sistema de archivos diseñado para el uso de bases de datos. Para utilizar Oracle ASM, debe asignar discos particionados para la base de datos de Oracle, dando prioridad a la creación de bandas y la duplicación. Oracle ASM administra el espacio en disco y distribuye la carga de E/S entre todos los recursos disponibles para optimizar el rendimiento y eliminar la necesidad de ajuste manual de E/S. Por ejemplo, puede aumentar el tamaño del disco de una base de datos o mover parte de una base de datos a un nuevo dispositivo sin cerrar la base de datos.
5.1.2.2.1 Asignación de clases a niveles de almacenamiento
Una vez que se definen los niveles de almacenamiento, las clases de datos (particiones) identificadas en el Paso 1 se pueden asignar a los niveles de almacenamiento apropiados.
Esta asignación proporciona una forma sencilla de distribuir datos entre los dispositivos de almacenamiento apropiados en función de su uso, manteniendo los datos en línea y disponibles, y almacenados en el dispositivo más rentable. En la Figura 5-3, los datos identificados como activos, inactivos, históricos o listos para archivar se asignan al nivel de alto rendimiento, al nivel de almacenamiento de bajo costo, al nivel de almacenamiento de archivo en línea y al archivo fuera de línea, respectivamente. Con este enfoque, no se requieren cambios en la aplicación, ya que los datos aún son visibles.
Figura 5-3 Ciclo de vida de los datos
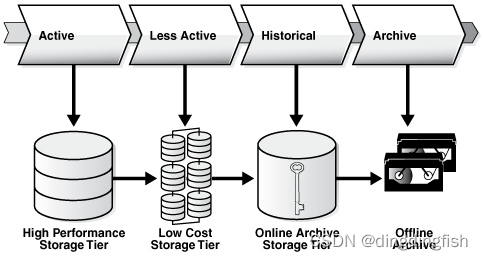
5.1.2.2.2 Ahorro de costos al usar almacenamiento en niveles
Uno de los beneficios de implementar una estrategia ILM es el ahorro de costos que se puede lograr mediante el uso de múltiples niveles de almacenamiento.
Suponga que desea almacenar 3 TB de datos, con 200 GB para alto rendimiento, 800 GB para bajo costo y 2 TB para archivado en línea. Suponga un costo por GB de $72 para el nivel de alto rendimiento, $14 para el nivel de bajo costo y $7 para el nivel de archivo en línea.
La Tabla 5-1 ilustra los posibles ahorros de costos de usar almacenamiento en niveles en lugar de almacenar todos los datos en un tipo de almacenamiento. Como puede ver, los ahorros de costos son sustanciales y se pueden lograr más ahorros si los datos son adecuados para la compresión de bases de datos OLTP y HCC.
Tabla 5-1 Ahorro de costos mediante almacenamiento en niveles
| capa de almacenamiento | Todos usan discos de alto rendimiento | varios niveles de almacenamiento | Múltiples niveles de almacenamiento + compresión |
|---|---|---|---|
| Alto rendimiento (200 GB) | $14,400 | $14,400 | $14,400 |
| Bajo costo (800 GB) | $57,600 | $11,200 | $11,200 |
| Archivo en línea (2 TB) | $144,000 | $14,000 | $5,600 |
| total por columna | $216,000 | $39,600 | $31,200 |
5.1.2.3 Paso 3: Crear políticas de acceso y migración de datos
El tercer paso en la implementación de una solución de gestión del ciclo de vida de la información es garantizar que solo los usuarios autorizados puedan acceder a los datos y especificar cómo se mueven los datos a lo largo de su ciclo de vida.
Existen varias técnicas para migrar datos entre niveles de almacenamiento a medida que envejecen.
5.1.2.3.1 Control del acceso a los datos
La seguridad de los datos es otra parte muy importante de la gestión del ciclo de vida de la información, ya que los derechos de acceso a los datos pueden cambiar durante su vida útil.
Además, puede haber requisitos reglamentarios que impongan requisitos estrictos sobre cómo se accede a los datos.
Los datos en una base de datos de Oracle se pueden proteger utilizando funciones de base de datos como:
- seguridad de la base de datos
- vista
- Base de datos privada virtual (VPD)
Una base de datos privada virtual (VPD) define un nivel muy detallado de acceso a la base de datos. Las políticas de seguridad determinan qué filas se pueden ver y qué columnas están visibles. Se pueden definir múltiples políticas para que diferentes usuarios y aplicaciones vean diferentes vistas de los mismos datos. Por ejemplo, la mayoría de los usuarios pueden ver información del primer trimestre, segundo trimestre, tercer trimestre y cuarto trimestre, mientras que solo los usuarios autorizados pueden ver datos históricos.
Las políticas de seguridad se definen a nivel de la base de datos y se aplican de forma transparente a todos los usuarios de la base de datos. El beneficio de este enfoque es que proporciona un entorno seguro y controlado para acceder a datos que no se pueden anular y se pueden aplicar sin necesidad de realizar cambios en la aplicación. Además, se pueden definir espacios de tabla de solo lectura para garantizar que los datos no cambien.
5.1.2.3.2 Mover datos usando particiones
Durante su vida útil, los datos deben moverse y la partición es una técnica que se puede utilizar.
Los datos móviles pueden ocurrir debido a las siguientes razones:
- Por motivos de rendimiento, solo se guarda un número limitado de pedidos en discos de alto rendimiento
- Ya no se accede a los datos con frecuencia y se utiliza un valioso almacenamiento de alto rendimiento, por lo que deben trasladarse a un almacenamiento de bajo costo.
- La ley exige que la información esté siempre disponible durante un intervalo de tiempo determinado y debe mantenerse de forma segura al menor costo posible
Hay varias formas de mover datos físicamente dentro de una base de datos de Oracle para aprovechar los diferentes niveles de almacenamiento. Por ejemplo, si los datos están particionados, la partición que contiene los pedidos del segundo trimestre se puede mover en línea desde el nivel de almacenamiento de alto rendimiento al nivel de almacenamiento de bajo costo. Debido a que los datos se mueven dentro de la base de datos, se pueden mover físicamente sin afectar las aplicaciones que los necesitan ni causar interrupciones a los usuarios habituales.
A veces, se deben mover elementos de datos individuales, en lugar de un grupo de datos. Por ejemplo, supongamos que los datos se clasifican según el nivel de privacidad y un informe previamente confidencial ahora se pone a disposición del público. Si la clasificación cambia de secreto a público y los datos se dividen según su clasificación de privacidad, la fila se moverá automáticamente a la partición que contiene los datos públicos.
Siempre que los datos se trasladen de su fuente original, es importante asegurarse de que el proceso elegido cumpla con los requisitos reglamentarios, como que los datos no se puedan alterar, proteger del acceso no autorizado, leer fácilmente y almacenar en una ubicación aprobada.
5.1.2.4 Paso 4: Definir y hacer cumplir las políticas de cumplimiento
El cuarto paso en una solución de gestión del ciclo de vida de la información es crear una política de cumplimiento.
Cuando los datos están fragmentados y distribuidos, las políticas de cumplimiento deben definirse y aplicarse en cada ubicación de datos, lo que puede conducir fácilmente a que se pasen por alto las políticas de cumplimiento. Sin embargo, el uso de una base de datos de Oracle para proporcionar una ubicación central para almacenar datos significa que las políticas de cumplimiento se pueden aplicar muy fácilmente porque todas se administran y se aplican desde una ubicación central .
Al definir una política de cumplimiento, tenga en cuenta lo siguiente:
- retención de datos
- invariancia
- privacidad
- auditoría
- Venció
5.1.2.4.1 Retención de datos
Una política de retención describe cómo se retienen los datos, cuánto tiempo se deben retener y qué sucede con los datos después de su vida útil.
Un ejemplo de una política de retención es que los registros deben almacenarse en su forma original, no se permiten modificaciones, deben conservarse durante siete años y luego pueden eliminarse. Con Oracle Database Security, puede asegurarse de que los datos permanezcan intactos y que solo los procesos autorizados puedan eliminarlos en el momento adecuado. Las políticas de retención también se pueden definir a través de definiciones de ciclo de vida en ILM Assistant.
5.1.2.4.2 Inmutabilidad
La inmutabilidad implica demostrar a partes externas que los datos están completos y no han sido modificados.
Oracle Database puede generar una contraseña o firma digital y mantenerla dentro o fuera de la base de datos para mostrar que los datos no se han modificado.
5.1.2.4.3 Privacidad
Oracle Database proporciona varios métodos para garantizar la privacidad de los datos.
El acceso a los datos se puede controlar estrictamente mediante políticas de seguridad definidas con una base de datos privada virtual (VPD). Además, las columnas individuales se pueden cifrar para que cualquier persona que vea los datos sin procesar no pueda ver su contenido.
5.1.2.4.4 Auditoría
Oracle Database realiza un seguimiento de todos los accesos y cambios en los datos.
Estas capacidades de auditoría se pueden definir en el nivel de la tabla o mediante una auditoría detallada, que especifica criterios para cuándo se generan los registros de auditoría. La auditoría se puede mejorar aún más con Oracle Audit Vault y Database Firewall.
5.1.2.4.5 Caducidad
Eventualmente, los datos pueden caducar por razones comerciales o reglamentarias y deben eliminarse de la base de datos.
Oracle Database puede eliminar datos de manera muy rápida y eficiente simplemente eliminando la partición que contiene la información que se eliminará.
5.2 Implementando una estrategia ILM con mapa de calor y ADO
Para implementar una estrategia de administración del ciclo de vida de la información (ILM) para el movimiento de datos en la base de datos, puede usar las funciones de mapa de calor y optimización automática de datos (ADO).
Nota: Los mapas de calor y ADO son compatibles con los entornos multiinquilino de Oracle Database 12c versión 2. Estas dos funciones solo se admiten después de 12c.
5.2.1 Uso del mapa de calor
Para implementar su estrategia ILM, puede usar mapas de calor en Oracle Database para rastrear el acceso y la modificación de datos.
Los mapas de calor proporcionan un seguimiento del acceso a los datos a nivel de segmento , así como un seguimiento de la modificación de datos a nivel de segmento y fila . Puede habilitar esta función con el parámetro de inicialización HEAT_MAP.
Los datos del mapa de calor pueden ayudar a la optimización automática de datos (ADO) a administrar el contenido del almacén de columnas en memoria (almacén de columnas IM) mediante la estrategia ADO. Utilizando datos de mapas de calor que incluyen estadísticas de columnas y otras estadísticas relevantes, el almacén de columnas de IM puede determinar cuándo está casi lleno (bajo presión de memoria). Si se determina que está casi lleno, los segmentos inactivos se pueden desalojar si hay segmentos a los que se accede con más frecuencia que se beneficiarían de la población en el almacén de columnas IM.
5.2.1.1 Activación y desactivación del mapa de calor
Puede habilitar y deshabilitar el seguimiento del mapa de calor a nivel del sistema o de la sesión con la declaración ALTER SYSTEM o ALTER SESSION utilizando la cláusula HEAT_MAP.
Por ejemplo, la siguiente instrucción SQL habilita el seguimiento del mapa de calor para una instancia de base de datos.
ALTER SYSTEM SET HEAT_MAP = ON;
Cuando el mapa de calor está habilitado, todas las visitas son rastreadas por el módulo de seguimiento de actividad en memoria. Los objetos en los tablespaces SYSTEM y SYSAUX no se rastrean .
La siguiente instrucción SQL deshabilita el seguimiento del mapa de calor.
ALTER SYSTEM SET HEAT_MAP = OFF;
Cuando el mapa de calor está deshabilitado, el módulo de seguimiento de actividad en memoria no realiza un seguimiento de las visitas. El valor predeterminado del parámetro de inicialización HEAT_MAP es OFF .
El parámetro de inicialización HEAT_MAP también activa y desactiva la optimización automática de datos (ADO). Para ADO, los mapas de calor deben estar habilitados a nivel del sistema .
5.2.1.2 Visualización de datos de seguimiento de mapas de calor con vistas
Vea los datos de seguimiento del mapa de calor utilizando las vistas de mapa de calor V$ , ALL , DBA* y USER*.
El ejemplo 5-1 muestra un ejemplo de la información proporcionada por la vista de mapa de calor. La vista V$HEAT_MAP_SEGMENT muestra información de acceso al segmento en tiempo real. Las vistas ALL_, DBA_ y USER_HEAT_MAP_SEGMENT muestran el último tiempo de acceso al segmento para todos los segmentos visibles para el usuario. Las vistas ALL_, DBA_ y USER_HEAT_MAP_SEG_HISTOGRAM muestran información de acceso al segmento para todos los segmentos visibles para el usuario. La vista DBA_HEATMAP_TOP_OBJECTS muestra información del mapa de calor para los objetos más activos. La vista DBA_HEATMAP_TOP_TABLESPACES muestra información del mapa de calor para los tablespaces más activos.
Ejemplo 5-1 Vista de mapa de calor
/* enable heat map tracking if necessary*/
SELECT SUBSTR(OBJECT_NAME,1,20), SUBSTR(SUBOBJECT_NAME,1,20), TRACK_TIME, SEGMENT_WRITE,
FULL_SCAN, LOOKUP_SCAN FROM V$HEAT_MAP_SEGMENT;
SUBSTR(OBJECT_NAME,1 SUBSTR(SUBOBJECT_NAM TRACK_TIM SEG FUL LOO
-------------------- -------------------- --------- --- --- ---
SALES SALES_Q1_1998 01-NOV-12 NO NO NO
SALES SALES_Q3_1998 01-NOV-12 NO NO NO
SALES SALES_Q2_2000 01-NOV-12 NO NO NO
SALES SALES_Q3_1999 01-NOV-12 NO NO NO
SALES SALES_Q2_1998 01-NOV-12 NO NO NO
SALES SALES_Q2_1999 01-NOV-12 NO NO NO
SALES SALES_Q4_2001 01-NOV-12 NO NO NO
SALES SALES_Q1_1999 01-NOV-12 NO NO NO
SALES SALES_Q4_1998 01-NOV-12 NO NO NO
SALES SALES_Q1_2000 01-NOV-12 NO NO NO
SALES SALES_Q1_2001 01-NOV-12 NO NO NO
SALES SALES_Q2_2001 01-NOV-12 NO NO NO
SALES SALES_Q3_2000 01-NOV-12 NO NO NO
SALES SALES_Q4_2000 01-NOV-12 NO NO NO
EMPLOYEES 01-NOV-12 NO NO NO
...
SELECT SUBSTR(OBJECT_NAME,1,20), SUBSTR(SUBOBJECT_NAME,1,20), SEGMENT_WRITE_TIME,
SEGMENT_READ_TIME, FULL_SCAN, LOOKUP_SCAN FROM USER_HEAT_MAP_SEGMENT;
SUBSTR(OBJECT_NAME,1 SUBSTR(SUBOBJECT_NAM SEGMENT_W SEGMENT_R FULL_SCAN LOOKUP_SC
-------------------- -------------------- --------- --------- --------- ---------
SALES SALES_Q1_1998 30-OCT-12 01-NOV-12
SALES SALES_Q1_1998 30-OCT-12 01-NOV-12
SALES SALES_Q1_1998 30-OCT-12 01-NOV-12
SALES SALES_Q1_1998 30-OCT-12 01-NOV-12
SALES SALES_Q1_1998 30-OCT-12 01-NOV-12
SALES SALES_Q1_1998 30-OCT-12 01-NOV-12
...
SELECT SUBSTR(OBJECT_NAME,1,20), SUBSTR(SUBOBJECT_NAME,1,20), TRACK_TIME, SEGMENT_WRITE, FULL_SCAN,
LOOKUP_SCAN FROM USER_HEAT_MAP_SEG_HISTOGRAM;
SUBSTR(OBJECT_NAME,1 SUBSTR(SUBOBJECT_NAM TRACK_TIM SEG FUL LOO
-------------------- -------------------- --------- --- --- ---
SALES SALES_Q1_1998 31-OCT-12 NO NO YES
SALES SALES_Q1_1998 01-NOV-12 NO NO YES
SALES SALES_Q1_1998 30-OCT-12 NO YES YES
SALES SALES_Q2_1998 01-NOV-12 NO NO YES
SALES SALES_Q2_1998 31-OCT-12 NO NO YES
SALES SALES_Q2_1998 30-OCT-12 NO YES YES
SALES SALES_Q3_1998 01-NOV-12 NO NO YES
SALES SALES_Q3_1998 30-OCT-12 NO YES YES
SALES SALES_Q3_1998 31-OCT-12 NO NO YES
SALES SALES_Q4_1998 01-NOV-12 NO NO YES
SALES SALES_Q4_1998 31-OCT-12 NO NO YES
SALES SALES_Q4_1998 30-OCT-12 NO YES YES
SALES SALES_Q1_1999 01-NOV-12 NO NO YES
SALES SALES_Q1_1999 31-OCT-12 NO NO YES
...
SELECT SUBSTR(OWNER,1,20), SUBSTR(OBJECT_NAME,1,20), OBJECT_TYPE, SUBSTR(TABLESPACE_NAME,1,20),
SEGMENT_COUNT FROM DBA_HEATMAP_TOP_OBJECTS ORDER BY SEGMENT_COUNT DESC;
SUBSTR(OWNER,1,20) SUBSTR(OBJECT_NAME,1 OBJECT_TYPE SUBSTR(TABLESPACE_NA SEGMENT_COUNT
-------------------- -------------------- ------------------ -------------------- -------------
SH SALES TABLE EXAMPLE 96
SH COSTS TABLE EXAMPLE 48
PM ONLINE_MEDIA TABLE EXAMPLE 22
OE PURCHASEORDER TABLE EXAMPLE 18
PM PRINT_MEDIA TABLE EXAMPLE 15
OE CUSTOMERS TABLE EXAMPLE 10
OE WAREHOUSES TABLE EXAMPLE 9
HR EMPLOYEES TABLE EXAMPLE 7
OE LINEITEM_TABLE TABLE EXAMPLE 6
IX STREAMS_QUEUE_TABLE TABLE EXAMPLE 6
SH FWEEK_PSCAT_SALES_MV TABLE EXAMPLE 5
SH CUSTOMERS TABLE EXAMPLE 5
HR LOCATIONS TABLE EXAMPLE 5
HR JOB_HISTORY TABLE EXAMPLE 5
SH PRODUCTS TABLE EXAMPLE 5
...
SELECT SUBSTR(TABLESPACE_NAME,1,20), SEGMENT_COUNT
FROM DBA_HEATMAP_TOP_TABLESPACES ORDER BY SEGMENT_COUNT DESC;
SUBSTR(TABLESPACE_NA SEGMENT_COUNT
-------------------- -------------
EXAMPLE 351
USERS 11
SELECT COUNT(*) FROM DBA_HEATMAP_TOP_OBJECTS;
COUNT(*)
----------
64
SELECT COUNT(*) FROM DBA_HEATMAP_TOP_TABLESPACES;
COUNT(*)
----------
2
5.2.1.3 Gestión de datos de mapas de calor con subprogramas DBMS_HEAT_MAP
El paquete DBMS_HEAT_MAP brinda flexibilidad adicional para mostrar datos de mapas de calor mediante la subrutina DBMS_HEAT_MAP.
DBMS_HEAT_MAP incluye un conjunto de API que externalizan mapas de calor en diferentes niveles de almacenamiento, como bloque, extensión, segmento, objeto y espacio de tabla; un segundo conjunto de API externaliza mapas de calor materializados por procesos en segundo plano para espacios de tabla de nivel superior.
El ejemplo 5-2 muestra un ejemplo del uso de la subrutina del paquete DBMS_HEAT_MAP.
Ejemplo 5-2 Uso de la subrutina del paquete DBMS_HEAT_MAP
SELECT SUBSTR(segment_name,1,10) Segment, min_writetime, min_ftstime
FROM TABLE(DBMS_HEAT_MAP.OBJECT_HEAT_MAP('SH','SALES'));
SELECT SUBSTR(tablespace_name,1,16) Tblspace, min_writetime, min_ftstime
FROM TABLE(DBMS_HEAT_MAP.TABLESPACE_HEAT_MAP('EXAMPLE'));
SELECT relative_fno, block_id, blocks, TO_CHAR(min_writetime, 'mm-dd-yy hh-mi-ss') Mintime,
TO_CHAR(max_writetime, 'mm-dd-yy hh-mi-ss') Maxtime,
TO_CHAR(avg_writetime, 'mm-dd-yy hh-mi-ss') Avgtime
FROM TABLE(DBMS_HEAT_MAP.EXTENT_HEAT_MAP('SH','SALES')) WHERE ROWNUM < 10;
SELECT SUBSTR(owner,1,10) Owner, SUBSTR(segment_name,1,10) Segment,
SUBSTR(partition_name,1,16) Partition, SUBSTR(tablespace_name,1,16) Tblspace,
segment_type, segment_size FROM TABLE(DBMS_HEAT_MAP.OBJECT_HEAT_MAP('SH','SALES'));
OWNER SEGMENT PARTITION TBLSPACE SEGMENT_TYPE SEGMENT_SIZE
---------- ---------- ---------------- ---------------- -------------------- ------------
SH SALES SALES_Q1_1998 EXAMPLE TABLE PARTITION 8388608
SH SALES SALES_Q2_1998 EXAMPLE TABLE PARTITION 8388608
SH SALES SALES_Q3_1998 EXAMPLE TABLE PARTITION 8388608
SH SALES SALES_Q4_1998 EXAMPLE TABLE PARTITION 8388608
SH SALES SALES_Q1_1999 EXAMPLE TABLE PARTITION 8388608
...
5.2.2 Uso de la optimización automática de datos
Para implementar su estrategia ILM, puede utilizar la Optimización automática de datos (ADO) para comprimir y mover datos automáticamente entre diferentes niveles de almacenamiento en su base de datos.
Esta capacidad incluye la posibilidad de crear políticas que especifiquen diferentes niveles de compresión para cada capa, así como controlar cuándo se produce el movimiento de datos.
Para usar la optimización automática de datos, debe habilitar los mapas de calor a nivel del sistema. Puede habilitar esta función con el parámetro de inicialización HEAT_MAP.
5.2.2.1 Gestión de políticas para la optimización automática de datos
Puede especificar políticas para ADO en los niveles de granularidad de filas, segmentos y espacios de tablas al usar sentencias SQL para crear y modificar tablas. Además, las estrategias ADO pueden realizar operaciones en índices.
Al especificar políticas para ADO, puede automatizar el movimiento de datos entre diferentes niveles de almacenamiento en la base de datos . Estas políticas también le permiten especificar diferentes niveles de compresión para cada nivel y controlar cuándo se produce el movimiento de datos .
Estrategias ADO para tablas
La cláusula ILM de las sentencias SQL CREATE y ALTER TABLE le permite crear, descartar, habilitar o deshabilitar estrategias ADO. Las cláusulas de la política de ILM determinan la política de niveles de almacenamiento o compresión y contienen otras cláusulas, como las cláusulas AFTER y ON, para especificar las condiciones bajo las cuales deben ocurrir las acciones de la política. Se pueden agregar nuevas políticas para ADO cuando se crea una tabla. Puede modificar esta tabla para agregar más políticas o para habilitar, deshabilitar o eliminar políticas existentes. Puede agregar políticas a una tabla completa o a particiones de una tabla. Al agregar una política ADO a una tabla o partición de una tabla, puede especificar solo un tipo de condición para la cláusula AFTER. Las políticas ILM ADO reciben un nombre generado por el sistema, como P1, P2, etc. hasta Pn.
Las políticas a nivel de segmento se ejecutan solo una vez. Una vez que una política se ha ejecutado correctamente, se desactiva y no se volverá a evaluar. Sin embargo, puede volver a habilitar explícitamente la política. Las políticas de nivel de fila continúan ejecutándose y no se deshabilitan después de una ejecución exitosa.
El ámbito de una política ADO se puede especificar para un grupo de objetos relacionados o en el nivel de fila o segmento mediante las palabras clave GRUPO, FILA o SEGMENTO.
Los mapas de compresión predeterminados que se pueden aplicar a la directiva de grupo son:
- COMPRESS ADVANCED en tablas de almacenamiento dinámico se asigna a compresión estándar para índices y LOW para segmentos LOB.
- COMPRESS FOR QUERY LOW/QUERY HIGH en tablas de almacenamiento dinámico se asigna a compresión estándar para índices y MEDIUM para segmentos LOB.
- COMPRESS FOR ARCHIVE LOW/ARCHIVE HIGH en tablas de almacenamiento dinámico se asigna a compresión estándar para índices y HIGH para segmentos LOB.
En resumen, se utiliza compresión estándar para índices y diferentes niveles de compresión para segmentos LOB.
No se puede cambiar el mapa de compresión. GRUPO solo se puede aplicar a políticas de nivel de segmento. Las políticas de niveles de almacenamiento solo están disponibles a nivel de segmento y no se pueden especificar a nivel de fila.
Estrategias de ADO para almacenamiento de columnas en memoria
La optimización automática de datos (ADO) admite almacenamientos de columnas en memoria (almacenes de columnas IM) con los tipos de política INMEMORY, INMEMORY MECOMPRESS y NO INMEMORY.
- Para habilitar el llenado de objetos en un almacén de columnas en memoria , incluya INMEMORY en la cláusula ADD POLICY.
- Para aumentar el nivel de compresión de los objetos en el almacén de columnas IM , incluya INMEMORY MEMCOMPRESS en la cláusula ADD POLICY.
- Para desalojar explícitamente los objetos que se beneficiarían menos del almacenamiento de columnas IM, incluya NO INMEMORY en la cláusula ADD POLICY. Por ejemplo:
A continuación se muestra un ejemplo del uso de la cláusula NO INMEMORY para desalojar un objeto del almacén de columnas IM.
ALTER TABLE sales_2015 ILM ADD POLICY NO INMEMORY
AFTER 7 DAYS OF NO ACCESS;
Las políticas de ADO con la cláusula In-Memory Column Store solo pueden ser políticas de nivel de sección. Las vistas USER/DBA_ILMDATAMOVEMENTPOLICIES y V$HEAT_MAP_SEGMENT incluyen información sobre políticas ADO para almacenes de columnas en memoria.
Estrategias personalizadas de ADO
Puede personalizar estrategias utilizando la opción ON PL/SQL_function, que proporciona la capacidad de determinar cuándo ejecutar la estrategia. La opción ON PL/SQL_function solo se aplica a las políticas de nivel de sección. Por ejemplo:
CREATE OR REPLACE FUNCTION my_custom_ado_rules (objn IN NUMBER) RETURN BOOLEAN;
ALTER TABLE sales_custom ILM ADD POLICY COMPRESS ADVANCED SEGMENT
ON my_custom_ado_rules;
5.2.2.2 Creación de una tabla con una política ADO de ILM
Utilice la cláusula ILM ADD POLICY con la declaración CREATE TABLE para crear una tabla con una política ILM ADO.
La instrucción SQL del Ejemplo 5-3 crea una tabla y agrega una política ILM.
Ejemplo 5-3 Crear una tabla usando la estrategia ILM ADO
/* Create an example table with an ILM ADO policy */
CREATE TABLE sales_ado
(PROD_ID NUMBER NOT NULL,
CUST_ID NUMBER NOT NULL,
TIME_ID DATE NOT NULL,
CHANNEL_ID NUMBER NOT NULL,
PROMO_ID NUMBER NOT NULL,
QUANTITY_SOLD NUMBER(10,2) NOT NULL,
AMOUNT_SOLD NUMBER(10,2) NOT NULL )
PARTITION BY RANGE (time_id)
( PARTITION sales_q1_2012 VALUES LESS THAN (TO_DATE('01-APR-2012','dd-MON-yyyy')),
PARTITION sales_q2_2012 VALUES LESS THAN (TO_DATE('01-JUL-2012','dd-MON-yyyy')),
PARTITION sales_q3_2012 VALUES LESS THAN (TO_DATE('01-OCT-2012','dd-MON-yyyy')),
PARTITION sales_q4_2012 VALUES LESS THAN (TO_DATE('01-JAN-2013','dd-MON-yyyy')) )
ILM ADD POLICY COMPRESS FOR ARCHIVE HIGH SEGMENT
AFTER 12 MONTHS OF NO ACCESS;
/* View the existing ILM ADO polices */
SELECT SUBSTR(policy_name,1,24) POLICY_NAME, policy_type, enabled
FROM USER_ILMPOLICIES;
POLICY_NAME POLICY_TYPE ENABLE
------------------------ ------------- ------
P1 DATA MOVEMENT YES
¿Cuáles son los otros tipos de póliza?
5.2.2.3 Adición de políticas ADO de ILM
Agregue la política ILM ADO a la tabla mediante la cláusula ILM ADD POLICY con la instrucción ALTER TABLE.
La instrucción SQL del ejemplo 5-4 proporciona un ejemplo de cómo agregar una política ILM a una partición de la tabla de ventas.
Ejemplo 5-4 Adición de una política ADO de ILM
/* Add a row-level compression policy after 30 days of no modifications */
ALTER TABLE sales MODIFY PARTITION sales_q1_2002
ILM ADD POLICY ROW STORE COMPRESS ADVANCED ROW
AFTER 30 DAYS OF NO MODIFICATION;
/* Add a segment level compression policy for data after 6 months of no modifications */
ALTER TABLE sales MODIFY PARTITION sales_q1_2001
ILM ADD POLICY COMPRESS FOR ARCHIVE HIGH SEGMENT
AFTER 6 MONTHS OF NO MODIFICATION;
/* Add a segment level compression policy for data after 12 months of no access */
ALTER TABLE sales MODIFY PARTITION sales_q1_2000
ILM ADD POLICY COMPRESS FOR ARCHIVE HIGH SEGMENT
AFTER 12 MONTHS OF NO ACCESS;
/* Add storage tier policy to move old data to a different tablespace */
/* that is on low cost storage media */
ALTER TABLE sales MODIFY PARTITION sales_q1_1999
ILM ADD POLICY
TIER TO my_low_cost_sales_tablespace;
/* View the existing polices */
SELECT SUBSTR(policy_name,1,24) POLICY_NAME, policy_type, enabled
FROM USER_ILMPOLICIES;
POLICY_NAME POLICY_TYPE ENABLE
------------------------ ------------- ------
P1 DATA MOVEMENT YES
P2 DATA MOVEMENT YES
P3 DATA MOVEMENT YES
P4 DATA MOVEMENT YES
P5 DATA MOVEMENT YES
5.2.2.4 Inhabilitación y eliminación de políticas ADO de ILM
Utilice la cláusula ILM DISABLE POLICY o ILM DELETE POLICY con la instrucción ALTER TABLE para inhabilitar o eliminar la política ILM ADO.
Puede deshabilitar o eliminar la estrategia ILM de ADO, como se muestra en la instrucción SQL en el Ejemplo 5-5. Ocasionalmente, es posible que deba eliminar las políticas de ILM existentes si entran en conflicto con las nuevas políticas que está agregando.
Ejemplo 5-5 Inhabilitación y eliminación de una política ADO de ILM
/* You can disable or delete an ADO policy in a table with the following */
ALTER TABLE sales_ado ILM DISABLE POLICY P1;
ALTER TABLE sales_ado ILM DELETE POLICY P1;
/* You can disable or delete all ADO policies in a table with the following */
ALTER TABLE sales_ado ILM DISABLE_ALL;
ALTER TABLE sales_ado ILM DELETE_ALL;
/* You can disable or delete an ADO policy in a partition with the following */
ALTER TABLE sales MODIFY PARTITION sales_q1_2002 ILM DISABLE POLICY P2;
ALTER TABLE sales MODIFY PARTITION sales_q1_2002 ILM DELETE POLICY P2;
/* You can disable or delete all ADO policies in a partition with the following */
ALTER TABLE sales MODIFY PARTITION sales_q1_2000 ILM DISABLE_ALL;
ALTER TABLE sales MODIFY PARTITION sales_q1_2000 ILM DELETE_ALL;
5.2.2.5 Especificación de niveles de almacenamiento y compresión a nivel de segmento con ADO
Puede especificar la compresión a nivel de segmento dentro de una tabla utilizando políticas de niveles de compresión a nivel de segmento.
Combinado con estrategias de nivelación de compresión a nivel de fila, tiene un control detallado sobre cómo se almacenan y administran los datos en la base de datos.
El ejemplo 5-6 ilustra cómo crear una política para que ADO aplique compresión y niveles de almacenamiento en la tabla sales_ado, reflejando los siguientes requisitos comerciales:
- datos de carga masiva
- Ejecute cargas de trabajo OLTP
- Archivo comprimido alto después de seis meses sin actualizaciones
- Mover al almacenamiento de bajo costo
Ejemplo 5-6 Uso de compresión a nivel de segmento y almacenamiento en niveles
/* Add a segment level compression policy after 6 months of no changes */
ALTER TABLE sales_ado ILM ADD POLICY
COMPRESS FOR ARCHIVE HIGH SEGMENT
AFTER 6 MONTHS OF NO MODIFICATION;
Table altered.
/* Add storage tier policy */
ALTER TABLE sales_ado ILM ADD POLICY
TIER TO my_low_cost_tablespace;
SELECT SUBSTR(policy_name,1,24) POLICY_NAME, policy_type, enabled
FROM USER_ILMPOLICIES;
POLICY_NAME POLICY_TYPE ENABLED
------------------------ ------------- -------
...
P6 DATA MOVEMENT YES
P7 DATA MOVEMENT YES
5.2.2.6 Especificación de niveles de compresión a nivel de fila con ADO
Además de la compresión básica y avanzada, las políticas de optimización automática de datos (ADO) también admiten la compresión de columna híbrida (HCC).
Las políticas de nivel de fila de HCC se pueden definir en cualquier tabla, independientemente del tipo de compresión de la tabla . HCC se puede usar para comprimir filas de bloques fríos cuando hay actividad DML en otras partes del segmento.
Para las políticas de HCC en tablas que no son de HCC, el movimiento de filas puede ocurrir durante una actualización si la fila reside en una unidad de compresión (CU) de HCC. Además, de manera similar a otros casos de uso para el movimiento de filas, el mantenimiento del índice es necesario para actualizar las entradas del índice que hacen referencia a las filas movidas.
Oracle Database 12c versión 1 (12.1) admite políticas de nivel de fila: sin embargo, la base de datos debe ser compatible con 12.2 o posterior para usar la política de compresión de nivel de fila de HCC.
Ejemplo 5-7 Creación de una política ADO mediante compresión columnar híbrida de nivel de fila
La instrucción SQL del ejemplo 5-7 usa HCC para crear una política en las filas de la tabla employee_ilm.
ALTER TABLE employees_ilm
ILM ADD POLICY COLUMN STORE COMPRESS FOR QUERY ROW
AFTER 30 DAYS OF NO MODIFICATION;
Ejemplo 5-8 Creación de una política ADO mediante compresión avanzada de nivel de fila
La instrucción SQL del Ejemplo 5-8 crea una política que usa compresión avanzada para las filas de la tabla sales_ado.
ALTER TABLE sales_ado
ILM ADD POLICY ROW STORE COMPRESS ADVANCED ROW
AFTER 60 DAYS OF NO MODIFICATION;
SELECT policy_name, policy_type, enabled
FROM USER_ILMPOLICIES;
POLICY_NAME POLICY_TYPE ENABLE
------------------------ ------------- -------
...
P8 DATA MOVEMENT YES
5.2.2.7 Gestión de parámetros ADO de ILM
Puede personalizar el entorno ADO usando los parámetros ILM ADO establecidos usando el procedimiento CUSTOMIZE_ILM en el paquete DBMS_ILM_ADMIN PL/SQL.
Los diversos parámetros ILM ADO se describen en la Tabla 5-2.
Tabla 5-2 Parámetros ADO de ILM
| nombre | describir |
|---|---|
| LÍMITE ABSOLUTO DE TRABAJOS | Limita el número absoluto de trabajos ADO simultáneos. |
| GRADO DE PARALELISMO | Determina el grado de paralelismo con el que ejecutar trabajos de estrategia ADO. |
| ACTIVADO | Controla la evaluación y ejecución en segundo plano de ADO. Habilitado por defecto (VERDADERO o 1). La configuración de ENABLED y el parámetro de inicialización HEAT_MAP interactúan de la siguiente manera: - Si el parámetro de inicialización HEAT_MAP se establece en ON y el parámetro ENABLED se establece en FALSE (0), las estadísticas del mapa de calor se recopilan, pero ADO no opera automáticamente en las estadísticas. . - Si el parámetro de inicialización HEAT_MAP se establece en OFF y el parámetro ENABLED se establece en TRUE (1), no se recopilan estadísticas de mapa de calor y ADO no hace nada porque ADO no puede confiar en las estadísticas de mapa de calor. ADO se comporta como si HABILITADO estuviera establecido en FALSO. |
| MODO DE EJECUCIÓN | Controla si ADO se ejecuta en modo en línea o fuera de línea. El valor predeterminado es en línea (2). |
| INTERVALO DE EJECUCIÓN | Determina la frecuencia con la que ADO inicia la evaluación en segundo plano. El valor predeterminado es 15 minutos . |
| LÍMITE DE TRABAJO | Controla el número máximo de trabajos ADO en cualquier momento. El número máximo de trabajos ADO simultáneos se calcula como (LÍMITE DE TRABAJO) x (número de instancias) x (número de CPU por instancia). El valor predeterminado es 2. |
| TIEMPO DE LA POLÍTICA | Determina si la política ADO se especifica en segundos o días. Los valores son 1 segundo o 0 días (predeterminado). |
| TIEMPO DE RETENCIÓN | Especifica el tiempo que se retienen los datos de las tareas ADO completadas antes de ser purgados. El valor predeterminado es 30 días. |
| TBS PORCENTAJE UTILIZADO | Especifica el porcentaje de la cuota del tablespace cuando el tablespace se considera lleno. El valor predeterminado es 85% . |
| TBS PORCENTAJE LIBRE | El valor del parámetro TBS_PERCENT_FREE especifica el porcentaje libre de destino para el espacio de tabla. El valor predeterminado es 25% . |
Para los valores de los parámetros TBS_PERCENT*, ADO hará todo lo posible, pero no está garantizado . Cuando el porcentaje de la cuota del espacio de tablas alcanza el valor de TBS_PERCENT_USED, ADO comienza a mover datos para que el porcentaje libre de la cuota del espacio de tablas se acerque al valor de TBS_PERCENT_FREE. Por ejemplo, suponga que TBS_PERCENT_USED se establece en 85, TBS_PERCENT_FREE se establece en 25 y el tablespace está lleno en un 90 %. Luego, ADO inicia la operación para mover los datos de modo que la cuota del tablespace esté libre al menos en un 25 %, lo que también puede interpretarse como que el uso de la cuota del tablespace está por debajo del 75 %.
Puede mostrar parámetros utilizando la vista DBA_ILMPARAMETERS. Por ejemplo, la siguiente consulta muestra los valores de los parámetros relacionados con ADO.
SQL> SELECT NAME, VALUE FROM DBA_ILMPARAMETERS;
---------------------------------------------------------------- ----------
ENABLED 1
RETENTION TIME 30
JOB LIMIT 2
EXECUTION MODE 2
EXECUTION INTERVAL 15
TBS PERCENT USED 85
TBS PERCENT FREE 25
POLICY TIME 0
ABSOLUTE JOB LIMIT 10
DEGREE OF PARALLELISM 4
...
5.2.2.8 Uso de funciones PL/SQL para la gestión de políticas
Puede usar los paquetes PL/SQL DBMS_ILM y DBMS_ILM_ADMIN para la administración y personalización de políticas avanzadas para implementar escenarios ADO más complejos y controlar cuándo las políticas mueven y comprimen datos activamente.
Con los paquetes PL/SQL DBMS_ILM y DBMS_ILM_ADMIN, puede administrar las actividades de ILM de ADO para que no afecten negativamente las cargas de trabajo de producción críticas. La compatibilidad de la base de datos debe establecerse en al menos 12.0 para usar estos paquetes.
El procedimiento EXECUTE_ILM del paquete DBMS_ILM crea y programa trabajos para ejecutar estrategias ADO. El procedimiento EXECUTE_ILM() proporciona esta funcionalidad independientemente de cualquier trabajo ILM programado previamente. Todos los trabajos se crean y programan para ejecutarse inmediatamente ; sin embargo, si se ejecutan inmediatamente depende de cuántos trabajos haya en cola el programador.
El procedimiento EXECUTE_ILM se puede utilizar si desea tener más control sobre la ejecución de sus trabajos ILM y no desea esperar hasta la próxima ventana de mantenimiento .
El procedimiento STOP_ILM del paquete DBMS_ILM detiene todos los trabajos, todos los trabajos en ejecución, los trabajos basados en el ID de la tarea o trabajos específicos.
El procedimiento CUSTOMIZE_ILM del paquete DBMS_ILM_ADMIN PL/SQL le permite personalizar la configuración de ADO, como se muestra en el Ejemplo 5-9.
Por ejemplo, puede configurar los valores de los parámetros TBS_PERCENT_USED y TBS_PERCENT_FREE ILM o configurar el parámetro ABS_JOBLIMIT ILM. TBS_PERCENT_USED y TBS_PERCENT_FREE determinan cuándo se mueven los datos de acuerdo con las cuotas de espacios de tabla y ABS_JOBLIMIT establece el número absoluto de trabajos ADO simultáneos.
También puede usar el paquete DBMS_METADATA PL/SQL para recrear objetos que contienen políticas.
Ejemplo 5-9 Personalización de la configuración de ADO mediante CUSTOMIZE_ILM
SQL> BEGIN
2 DBMS_ILM_ADMIN.CUSTOMIZE_ILM(DBMS_ILM_ADMIN.TBS_PERCENT_USED, 85);
3 DBMS_ILM_ADMIN.CUSTOMIZE_ILM(DBMS_ILM_ADMIN.TBS_PERCENT_FREE, 25);
4 END;
5 /
SQL> BEGIN
2 DBMS_ILM_ADMIN.CUSTOMIZE_ILM(DBMS_ILM_ADMIN.ABS_JOBLIMIT, 10);
3 END;
4 /
5.2.2.9 Uso de vistas para monitorear políticas para ADO
Puede usar las vistas DBA_ILM* y USER_ILM* para ver y monitorear las políticas de ADO asociadas con los objetos de su base de datos, lo que facilita el cambio de políticas según sea necesario.
- La vista DBA/USER_ILMDATAMOVEMENTPOLICIES muestra información sobre las propiedades relacionadas con el movimiento de datos para políticas de ILM específicas de ADO.
- La vista DBA/USER_ILMTASKS muestra los ID de tareas para el procedimiento EXECUTE_ILM. Cada vez que el usuario llama al procedimiento EXECUTE_ILM, se devuelve un ID de tarea para realizar un seguimiento de esta llamada en particular. También se genera un ID de tarea para realizar un seguimiento de las tareas ILM internas recurrentes para la base de datos. Esta vista contiene información sobre todas las tareas de ILM para ADO.
- La vista DBA/USER_ILMEVALUATIONDETAILS muestra información detallada sobre las estrategias consideradas para una tarea en particular. Si se selecciona una política para evaluación, también muestra el nombre del trabajo que ejecutó la política. Si la política no se aplica, esta vista también proporciona el motivo.
- La vista DBA/USER_ILMOBJECTS muestra todos los objetos y estrategias de ADO en la base de datos. Muchos objetos heredan la política a través de su objeto principal o porque se crearon en un tablespace específico. Esta vista proporciona una asignación entre políticas y objetos. En el caso de políticas heredadas, esta vista también indica el nivel de políticas heredadas.
- La vista DBA/USER_ILMPOLICIES muestra información detallada sobre todas las políticas de ADO en la base de datos.
- La vista DBA/USER_ILMRESULTS muestra información sobre los trabajos relacionados con el movimiento de datos de ADO en la base de datos.
- La vista DBA_ILMPARAMETERS muestra información sobre los parámetros relacionados con ADO.
5.2.3 Limitaciones y Restricciones con ADO y Mapa de Calor
Este tema analiza las limitaciones y las limitaciones relacionadas con ADO y los mapas de calor.
Las limitaciones y restricciones relacionadas con ADO y los mapas de calor incluyen:
- La validez de tiempo admite ADO y compresión de nivel de partición, con la excepción de las políticas de ADO de nivel de fila, que comprimen filas más allá de su tiempo válido (acceso o modificación).
- ADO a nivel de partición y la compresión admiten el archivado en la base de datos si se particiona en una columna ORA_ARCHIVE_STATE.
- Las políticas personalizadas de ADO (funciones definidas por el usuario) no se admiten si la política está predeterminada en el nivel de tablespace.
- Cuando se utiliza el almacenamiento en niveles, ADO no verifica el espacio de almacenamiento en el tablespace de destino .
- ADO no es compatible con tablas con tipos de objetos o vistas materializadas.
- ADO no es compatible con tablas o clústeres organizados por índices.
- La simultaneidad de ADO (la cantidad de trabajos de política simultáneos para ADO) depende de la simultaneidad del planificador de Oracle. Si un trabajo de política para ADO falla más de dos veces, el trabajo se marcará como deshabilitado y deberá habilitarse manualmente más tarde.
- ADO tiene limitaciones relacionadas con el movimiento de tablas y particiones de tablas.
5.3 Control de la validez y visibilidad de los datos en la base de datos Oracle
Puede utilizar el archivado en base de datos y la validación de tiempo para controlar la validez y la visibilidad de los datos en Oracle Database.
5.3.1 Uso del archivado en la base de datos
El archivado en base de datos le permite archivar filas en una tabla marcándolas como inactivas.
Estas filas inactivas están en la base de datos y se pueden optimizar mediante compresión, pero son invisibles para la aplicación . Los datos de estas filas se pueden utilizar con fines de cumplimiento mediante el establecimiento de parámetros de sesión si se desea.
Con el archivado en la base de datos, puede almacenar más datos en una sola base de datos durante períodos de tiempo más largos sin afectar el rendimiento de la aplicación . Los datos de archivo se pueden comprimir para ayudar a mejorar el rendimiento de la copia de seguridad, y las actualizaciones de los datos de archivo se pueden diferir durante las actualizaciones de la aplicación para mejorar el rendimiento de la actualización.
Para administrar el archivado en la base de datos para una tabla, debe habilitar ROW ARCHIVAL para la tabla y manipular la columna oculta ORA_ARCHIVE_STATE de la tabla. Como alternativa, puede especificar ACTIVO o . PERMITIR VISIBILIDAD DE ARCHIVO
Por ejemplo, puede usar instrucciones SQL similares a las del Ejemplo 5-10 para ocultar o mostrar filas en una tabla. La intención es mostrar solo los datos activos en la mayoría de los casos, pero en casos específicos es necesario mantener todos los datos.
Live SQL: vea y ejecute ejemplos relacionados en Oracle Live SQL en Oracle Live SQL: cómo trabajar con ejemplos de archivos en la base de datos .
Ejemplo 5-10 Uso de archivado en base de datos
/* Set visibility to ACTIVE to display only active rows of a table.*/
ALTER SESSION SET ROW ARCHIVAL VISIBILITY = ACTIVE;
CREATE TABLE employees_indbarch
(employee_id NUMBER(6) NOT NULL,
first_name VARCHAR2(20), last_name VARCHAR2(25) NOT NULL,
email VARCHAR2(25) NOT NULL, phone_number VARCHAR2(20),
hire_date DATE NOT NULL, job_id VARCHAR2(10) NOT NULL, salary NUMBER(8,2),
commission_pct NUMBER(2,2), manager_id NUMBER(6), department_id NUMBER(4)) ROW ARCHIVAL;
/* Show all the columns in the table, including hidden columns */
SELECT SUBSTR(COLUMN_NAME,1,22) NAME, SUBSTR(DATA_TYPE,1,20) DATA_TYPE, COLUMN_ID AS COL_ID,
SEGMENT_COLUMN_ID AS SEG_COL_ID, INTERNAL_COLUMN_ID AS INT_COL_ID, HIDDEN_COLUMN, CHAR_LENGTH
FROM USER_TAB_COLS WHERE TABLE_NAME='EMPLOYEES_INDBARCH';
NAME DATA_TYPE COL_ID SEG_COL_ID INT_COL_ID HID CHAR_LENGTH
---------------------- -------------------- ---------- ---------- ---------- --- -----------
ORA_ARCHIVE_STATE VARCHAR2 1 1 YES 4000
EMPLOYEE_ID NUMBER 1 2 2 NO 0
FIRST_NAME VARCHAR2 2 3 3 NO 20
LAST_NAME VARCHAR2 3 4 4 NO 25
EMAIL VARCHAR2 4 5 5 NO 25
PHONE_NUMBER VARCHAR2 5 6 6 NO 20
HIRE_DATE DATE 6 7 7 NO 0
JOB_ID VARCHAR2 7 8 8 NO 10
SALARY NUMBER 8 9 9 NO 0
COMMISSION_PCT NUMBER 9 10 10 NO 0
MANAGER_ID NUMBER 10 11 11 NO 0
DEPARTMENT_ID NUMBER 11 12 12 NO 0
/* Insert some data into the table */
INSERT INTO employees_indbarch(employee_id, first_name, last_name, email,
hire_date, job_id, salary, manager_id, department_id)
VALUES (251, 'Scott', 'Tiger', '[email protected]', '21-MAY-2009',
'IT_PROG', 50000, 103, 60);
INSERT INTO employees_indbarch(employee_id, first_name, last_name, email,
hire_date, job_id, salary, manager_id, department_id)
VALUES (252, 'Jane', 'Lion', '[email protected]', '11-JUN-2009',
'IT_PROG', 50000, 103, 60);
/* Decrease the ORA_ARCHIVE_STATE column size to improve formatting in queries */
COLUMN ORA_ARCHIVE_STATE FORMAT a18;
/* The default value for ORA_ARCHIVE_STATE is '0', which means active */
SELECT employee_id, ORA_ARCHIVE_STATE FROM employees_indbarch;
EMPLOYEE_ID ORA_ARCHIVE_STATE
----------- ------------------
251 0
252 0
/* Insert a value into ORA_ARCHIVE_STATE to set the record to inactive status*/
UPDATE employees_indbarch SET ORA_ARCHIVE_STATE = '1' WHERE employee_id = 252;
/* Only active records are in the following query */
SELECT employee_id, ORA_ARCHIVE_STATE FROM employees_indbarch;
EMPLOYEE_ID ORA_ARCHIVE_STATE
----------- ------------------
251 0
/* Set visibility to ALL to display all records */
ALTER SESSION SET ROW ARCHIVAL VISIBILITY = ALL;
SELECT employee_id, ORA_ARCHIVE_STATE FROM employees_indbarch;
EMPLOYEE_ID ORA_ARCHIVE_STATE
----------- ------------------
251 0
252 1
Tanto el ejemplo anterior como el ejemplo en LiveSQL solo demuestran la visibilidad de los datos, pero no dicen cómo no afectar el rendimiento.
5.3.2 Uso de la Validez Temporal
La validez de tiempo le permite realizar un seguimiento de los períodos de tiempo de validez en el mundo real. El usuario y el programa de aplicación pueden configurar el tiempo efectivo de los datos, y los datos se pueden seleccionar de acuerdo con el tiempo efectivo especificado o el rango de tiempo efectivo.
Las aplicaciones suelen registrar la validez (o validez) de los hechos registrados en una base de datos, junto con sellos de fecha y hora relevantes para la gestión empresarial. Por ejemplo, la fecha de contratación de un empleado en una aplicación de recursos humanos (HR) determina la fecha de vigencia de la cobertura de seguro, que es una fecha de vigencia. Esta fecha se contrasta con la fecha u hora en que se ingresó el registro del empleado en la base de datos. El atributo temporal del primero (fecha de contratación) se denomina tiempo efectivo (VT), mientras que el segundo (fecha de ingreso a la base de datos) se denomina tiempo de transacción (TT). Los tiempos válidos generalmente son controlados por el usuario, mientras que los tiempos de transacción son administrados por el sistema. Presta atención al concepto y diferencia entre VT y TT
La finitud del tiempo utiliza el concepto de VT.
Para ILM, el atributo de tiempo de validez puede representar cuándo un hecho es válido y cuándo no lo es en el mundo empresarial. Con el atributo Tiempo en validez, las consultas pueden mostrar solo filas actualmente válidas y no filas que contengan datos actualmente no válidos, como pedidos cerrados o futuras contrataciones.
Los conceptos integrales para el modelado temporal de tiempo eficiente incluyen:
-
Hora válida
Esta es una representación de tiempo definida por el usuario. Los ejemplos de tiempos efectivos incluyen las fechas de inicio y finalización del proyecto, y las fechas de contratación y finalización de los empleados. -
Tablas con semántica de tiempo eficiente
Estas tablas tienen una o más dimensiones de tiempo definidas por el usuario, cada una con un inicio y un final. -
Consulta Flashback de tiempo efectivo
Esta es la capacidad de realizar consultas de fecha y versión utilizando la dimensión de tiempo efectivo.
Un período de tiempo válido consta de las dos columnas de fecha y hora especificadas en la definición de la tabla. Puede agregar períodos de tiempo válidos agregando la columna explícitamente o crear la columna automáticamente. Se puede agregar un período de tiempo válido durante el proceso de creación o modificación de la tabla.
Para admitir el control de visibilidad a nivel de sesión para consultas de tablas temporales, el paquete DBMS_FLASHBACK_ARCHIVEPL/SQL proporciona el procedimiento ENABLE_AT_VALID_TIME. Para ejecutar el procedimiento, necesita los privilegios de sistema y objeto requeridos.
El siguiente procedimiento PL/SQL establece la visibilidad de tiempo efectivo para un tiempo determinado.
SQL> EXECUTE DBMS_FLASHBACK_ARCHIVE.enable_at_valid_time
('ASOF', '31-DEC-12 12.00.01 PM');
El siguiente procedimiento PL/SQL establece la visibilidad de los datos temporales a nivel de sesión a los datos válidos actualmente para el período de tiempo válido.
SQL> EXECUTE DBMS_FLASHBACK_ARCHIVE.enable_at_valid_time('CURRENT');
El siguiente procedimiento establece la visibilidad de los datos temporales en la tabla completa, que es la visibilidad predeterminada de la tabla temporal.
SQL> EXECUTE DBMS_FLASHBACK_ARCHIVE.enable_at_valid_time('ALL');
5.3.3 Creación de una tabla con validez temporal
Los ejemplos de este tema muestran cómo crear tablas de tiempo efectivo.
El ejemplo 5-11 muestra el uso de la validez de tiempo.
Live SQL: vea y ejecute ejemplos relacionados en Oracle Live SQL en Oracle Live SQL: creación de tablas eficientes en el tiempo .
Ejemplo 5-11 Crear una tabla con validez de tiempo
-- PERIOD FOR即时间有效性的关键字
/* Create a time with an employee tracking timestamp */
/* using the specified columns*/
CREATE TABLE employees_temp (
employee_id NUMBER(6) NOT NULL, first_name VARCHAR2(20), last_name VARCHAR2(25) NOT NULL,
email VARCHAR2(25) NOT NULL, phone_number VARCHAR2(20), hire_date DATE NOT NULL,
job_id VARCHAR2(10) NOT NULL, salary NUMBER(8,2), commission_pct NUMBER(2,2),
manager_id NUMBER(6), department_id NUMBER(4),
PERIOD FOR emp_track_time);
DESCRIBE employees_temp
Name Null? Type
------------------------------------------------------- -------- ---------------
EMPLOYEE_ID NOT NULL NUMBER(6)
FIRST_NAME VARCHAR2(20)
LAST_NAME NOT NULL VARCHAR2(25)
EMAIL NOT NULL VARCHAR2(25)
PHONE_NUMBER VARCHAR2(20)
HIRE_DATE NOT NULL DATE
JOB_ID NOT NULL VARCHAR2(10)
SALARY NUMBER(8,2)
COMMISSION_PCT NUMBER(2,2)
MANAGER_ID NUMBER(6)
DEPARTMENT_ID NUMBER(4)
SQL> SELECT SUBSTR(COLUMN_NAME,1,22) NAME, SUBSTR(DATA_TYPE,1,28) DATA_TYPE, COLUMN_ID AS COL_ID,
SEGMENT_COLUMN_ID AS SEG_COL_ID, INTERNAL_COLUMN_ID AS INT_COL_ID, HIDDEN_COLUMN
FROM USER_TAB_COLS WHERE TABLE_NAME='EMPLOYEES_TEMP';
NAME DATA_TYPE COL_ID SEG_COL_ID INT_COL_ID HID
---------------------- ---------------------------- ------ ---------- ---------- ---
EMP_TRACK_TIME_START TIMESTAMP(6) WITH TIME ZONE 1 1 YES
EMP_TRACK_TIME_END TIMESTAMP(6) WITH TIME ZONE 2 2 YES
EMP_TRACK_TIME NUMBER 3 YES
EMPLOYEE_ID NUMBER 1 3 4 NO
FIRST_NAME VARCHAR2 2 4 5 NO
LAST_NAME VARCHAR2 3 5 6 NO
EMAIL VARCHAR2 4 6 7 NO
PHONE_NUMBER VARCHAR2 5 7 8 NO
HIRE_DATE DATE 6 8 9 NO
JOB_ID VARCHAR2 7 9 10 NO
SALARY NUMBER 8 10 11 NO
COMMISSION_PCT NUMBER 9 11 12 NO
MANAGER_ID NUMBER 10 12 13 NO
DEPARTMENT_ID NUMBER 11 13 14 NO
/* Insert/update/delete with specified values for time columns */
INSERT INTO employees_temp(emp_track_time_start, emp_track_time_end, employee_id, first_name,
last_name, email, hire_date, job_id, salary, manager_id, department_id)
VALUES (TIMESTAMP '2009-06-01 12:00:01 Europe/Paris',
TIMESTAMP '2012-11-30 12:00:01 Europe/Paris', 251, 'Scott', 'Tiger',
'[email protected]', DATE '2009-05-21', 'IT_PROG', 50000, 103, 60);
INSERT INTO employees_temp(emp_track_time_start, emp_track_time_end, employee_id, first_name,
last_name, email, hire_date, job_id, salary, manager_id, department_id)
VALUES (TIMESTAMP '2009-06-01 12:00:01 Europe/Paris',
TIMESTAMP '2012-12-31 12:00:01 Europe/Paris', 252, 'Jane', 'Lion',
'[email protected]', DATE '2009-06-11', 'IT_PROG', 50000, 103, 60);
UPDATE employees_temp set salary = salary + salary * .05
WHERE emp_track_time_start <= TIMESTAMP '2009-06-01 12:00:01 Europe/Paris';
SELECT employee_id, SALARY FROM employees_temp;
EMPLOYEE_ID SALARY
----------- ----------
251 52500
252 52500
/* No rows are deleted for the following statement because no records */
/* are in the specified track time. */
DELETE employees_temp WHERE emp_track_time_end < TIMESTAMP '2001-12-31 12:00:01 Europe/Paris';
0 rows deleted.
/* Show rows that are in a specified time period */
SELECT employee_id FROM employees_temp
WHERE emp_track_time_start > TIMESTAMP '2009-05-31 12:00:01 Europe/Paris' AND
emp_track_time_end < TIMESTAMP '2012-12-01 12:00:01 Europe/Paris';
EMPLOYEE_ID
-----------
251
/* Show rows that are in a specified time period */
SELECT employee_id FROM employees_temp AS OF PERIOD FOR
emp_track_time TIMESTAMP '2012-12-01 12:00:01 Europe/Paris';
EMPLOYEE_ID
-----------
252
5.3.4 Limitaciones y restricciones con el archivado en base de datos y la validez temporal
Este tema enumera las limitaciones y limitaciones relacionadas con el archivado en la base de datos y la validez de tiempo.
Las limitaciones y restricciones incluyen:
- ILM no admite la compresión de tablas OLTP eficiente en el tiempo. La ILM y la compresión a nivel de segmento son compatibles si la partición se realiza en la columna de hora de finalización.
- La compresión de tablas OLTP para el archivado en la base de datos no es compatible con ILM. ORA_ARCHIVE_STATE admite ILM y compresión a nivel de segmento si se particiona en la columna.
referencia:
- https://oracle-base.com/articles/12c/temporal-validity-12cr1
- https://connor-mcdonald.com/2021/09/17/es-mi-mesa-temporal/
- https://www.researchgate.net/publication/282835771_Checking_and_Verifying_Temporal_Data_Validity_Using_Valid_Time_Temporal_Dimension_and_Queries_in_Oracle_12C
5.4 Implementación manual de un sistema ILM mediante particiones
Puede implementar manualmente un sistema de gestión del ciclo de vida de la información (ILM) mediante particiones.
El ejemplo 5-12 ilustra cómo crear manualmente niveles de almacenamiento y tablas de partición en esos niveles de almacenamiento, luego establecer una política de base de datos privada virtual (VPD) en esa base de datos para restringir el acceso a los datos del nivel de archivo en línea.
Ejemplo 5-12 Implementación manual de un sistema ILM
REM Setup the tablespaces for the data
REM These tablespaces would be placed on a High Performance Tier
CREATE SMALLFILE TABLESPACE q1_orders DATAFILE 'q1_orders'
SIZE 2M AUTOEXTEND ON NEXT 1M MAXSIZE UNLIMITED LOGGING
EXTENT MANAGEMENT LOCAL SEGMENT SPACE MANAGEMENT AUTO ;
CREATE SMALLFILE TABLESPACE q2_orders DATAFILE 'q2_orders'
SIZE 2M AUTOEXTEND ON NEXT 1M MAXSIZE UNLIMITED LOGGING
EXTENT MANAGEMENT LOCAL SEGMENT SPACE MANAGEMENT AUTO ;
CREATE SMALLFILE TABLESPACE q3_orders DATAFILE 'q3_orders'
SIZE 2M AUTOEXTEND ON NEXT 1M MAXSIZE UNLIMITED LOGGING
EXTENT MANAGEMENT LOCAL SEGMENT SPACE MANAGEMENT AUTO ;
CREATE SMALLFILE TABLESPACE q4_orders DATAFILE 'q4_orders'
SIZE 2M AUTOEXTEND ON NEXT 1M MAXSIZE UNLIMITED LOGGING
EXTENT MANAGEMENT LOCAL SEGMENT SPACE MANAGEMENT AUTO ;
REM These tablespaces would be placed on a Low Cost Tier
CREATE SMALLFILE TABLESPACE "2006_ORDERS" DATAFILE '2006_orders'
SIZE 5M AUTOEXTEND ON NEXT 10M MAXSIZE UNLIMITED LOGGING
EXTENT MANAGEMENT LOCAL SEGMENT SPACE MANAGEMENT AUTO ;
CREATE SMALLFILE TABLESPACE "2005_ORDERS" DATAFILE '2005_orders'
SIZE 5M AUTOEXTEND ON NEXT 10M MAXSIZE UNLIMITED LOGGING
EXTENT MANAGEMENT LOCAL SEGMENT SPACE MANAGEMENT AUTO ;
REM These tablespaces would be placed on the Online Archive Tier
CREATE SMALLFILE TABLESPACE "2004_ORDERS" DATAFILE '2004_orders'
SIZE 5M AUTOEXTEND ON NEXT 10M MAXSIZE UNLIMITED LOGGING
EXTENT MANAGEMENT LOCAL SEGMENT SPACE MANAGEMENT AUTO ;
CREATE SMALLFILE TABLESPACE old_orders DATAFILE 'old_orders'
SIZE 15M AUTOEXTEND ON NEXT 10M MAXSIZE UNLIMITED LOGGING
EXTENT MANAGEMENT LOCAL SEGMENT SPACE MANAGEMENT AUTO ;
REM Now create the Partitioned Table
CREATE TABLE allorders (
prod_id NUMBER NOT NULL,
cust_id NUMBER NOT NULL,
time_id DATE NOT NULL,
channel_id NUMBER NOT NULL,
promo_id NUMBER NOT NULL,
quantity_sold NUMBER(10,2) NOT NULL,
amount_sold NUMBER(10,2) NOT NULL)
--
-- table wide physical specs
--
PCTFREE 5 NOLOGGING
--
-- partitions
--
PARTITION BY RANGE (time_id)
( partition allorders_pre_2004 VALUES LESS THAN
(TO_DATE('2004-01-01 00:00:00'
,'SYYYY-MM-DD HH24:MI:SS'
,'NLS_CALENDAR=GREGORIAN'
)) TABLESPACE old_orders,
partition allorders_2004 VALUES LESS THAN
(TO_DATE('2005-01-01 00:00:00'
,'SYYYY-MM-DD HH24:MI:SS'
,'NLS_CALENDAR=GREGORIAN'
)) TABLESPACE "2004_ORDERS",
partition allorders_2005 VALUES LESS THAN
(TO_DATE('2006-01-01 00:00:00'
,'SYYYY-MM-DD HH24:MI:SS'
,'NLS_CALENDAR=GREGORIAN'
)) TABLESPACE "2005_ORDERS",
partition allorders_2006 VALUES LESS THAN
(TO_DATE('2007-01-01 00:00:00'
,'SYYYY-MM-DD HH24:MI:SS'
,'NLS_CALENDAR=GREGORIAN'
)) TABLESPACE "2006_ORDERS",
partition allorders_q1_2007 VALUES LESS THAN
(TO_DATE('2007-04-01 00:00:00'
,'SYYYY-MM-DD HH24:MI:SS'
,'NLS_CALENDAR=GREGORIAN'
)) TABLESPACE q1_orders,
partition allorders_q2_2007 VALUES LESS THAN
(TO_DATE('2007-07-01 00:00:00'
,'SYYYY-MM-DD HH24:MI:SS'
,'NLS_CALENDAR=GREGORIAN'
)) TABLESPACE q2_orders,
partition allorders_q3_2007 VALUES LESS THAN
(TO_DATE('2007-10-01 00:00:00'
,'SYYYY-MM-DD HH24:MI:SS'
,'NLS_CALENDAR=GREGORIAN'
)) TABLESPACE q3_orders,
partition allorders_q4_2007 VALUES LESS THAN
(TO_DATE('2008-01-01 00:00:00'
,'SYYYY-MM-DD HH24:MI:SS'
,'NLS_CALENDAR=GREGORIAN'
)) TABLESPACE q4_orders);
ALTER TABLE allorders ENABLE ROW MOVEMENT;
REM Here is another example using INTERVAL partitioning
REM These tablespaces would be placed on a High Performance Tier
CREATE SMALLFILE TABLESPACE cc_this_month DATAFILE 'cc_this_month'
SIZE 2M AUTOEXTEND ON NEXT 1M MAXSIZE UNLIMITED LOGGING
EXTENT MANAGEMENT LOCAL SEGMENT SPACE MANAGEMENT AUTO ;
CREATE SMALLFILE TABLESPACE cc_prev_month DATAFILE 'cc_prev_month'
SIZE 2M AUTOEXTEND ON NEXT 1M MAXSIZE UNLIMITED LOGGING
EXTENT MANAGEMENT LOCAL SEGMENT SPACE MANAGEMENT AUTO ;
REM These tablespaces would be placed on a Low Cost Tier
CREATE SMALLFILE TABLESPACE cc_prev_12mth DATAFILE 'cc_prev_12'
SIZE 2M AUTOEXTEND ON NEXT 1M MAXSIZE UNLIMITED LOGGING
EXTENT MANAGEMENT LOCAL SEGMENT SPACE MANAGEMENT AUTO ;
REM These tablespaces would be placed on the Online Archive Tier
CREATE SMALLFILE TABLESPACE cc_old_tran DATAFILE 'cc_old_tran'
SIZE 2M AUTOEXTEND ON NEXT 1M MAXSIZE UNLIMITED LOGGING
EXTENT MANAGEMENT LOCAL SEGMENT SPACE MANAGEMENT AUTO ;
REM Credit Card Transactions where new partitions
REM are automatically placed on the high performance tier
CREATE TABLE cc_tran (
cc_no VARCHAR2(16) NOT NULL,
tran_dt DATE NOT NULL,
entry_dt DATE NOT NULL,
ref_no NUMBER NOT NULL,
description VARCHAR2(30) NOT NULL,
tran_amt NUMBER(10,2) NOT NULL)
--
-- table wide physical specs
--
PCTFREE 5 NOLOGGING
--
-- partitions
--
PARTITION BY RANGE (tran_dt)
INTERVAL (NUMTOYMINTERVAL(1,'month') ) STORE IN (cc_this_month )
( partition very_old_cc_trans VALUES LESS THAN
(TO_DATE('1999-07-01 00:00:00'
,'SYYYY-MM-DD HH24:MI:SS'
,'NLS_CALENDAR=GREGORIAN'
)) TABLESPACE cc_old_tran ,
partition old_cc_trans VALUES LESS THAN
(TO_DATE('2006-07-01 00:00:00'
,'SYYYY-MM-DD HH24:MI:SS'
,'NLS_CALENDAR=GREGORIAN'
)) TABLESPACE cc_old_tran ,
partition last_12_mths VALUES LESS THAN
(TO_DATE('2007-06-01 00:00:00'
,'SYYYY-MM-DD HH24:MI:SS'
,'NLS_CALENDAR=GREGORIAN'
)) TABLESPACE cc_prev_12mth,
partition recent_cc_trans VALUES LESS THAN
(TO_DATE('2007-07-01 00:00:00'
,'SYYYY-MM-DD HH24:MI:SS'
,'NLS_CALENDAR=GREGORIAN'
)) TABLESPACE cc_prev_month,
partition new_cc_tran VALUES LESS THAN
(TO_DATE('2007-08-01 00:00:00'
,'SYYYY-MM-DD HH24:MI:SS'
,'NLS_CALENDAR=GREGORIAN'
)) TABLESPACE cc_this_month);
REM Create a Security Policy to allow user SH to see all credit card data,
REM PM only sees this years data,
REM and all other uses cannot see the credit card data
CREATE OR REPLACE FUNCTION ilm_seehist
(oowner IN VARCHAR2, ojname IN VARCHAR2)
RETURN VARCHAR2 AS con VARCHAR2 (200);
BEGIN
IF SYS_CONTEXT('USERENV','CLIENT_INFO') = 'SH'
THEN -- sees all data
con:= '1=1';
ELSIF SYS_CONTEXT('USERENV','CLIENT_INFO') = 'PM'
THEN -- sees only data for 2007
con := 'time_id > ''31-Dec-2006''';
ELSE
-- others nothing
con:= '1=2';
END IF;
RETURN (con);
END ilm_seehist;
/
El ejemplo anterior incluye tres partes: la primera parte es un ejemplo de partición de rango, la segunda parte es un ejemplo de partición de intervalo y la tercera parte es la creación de una política de seguridad de nivel de fila, donde con significa condición, es decir, donde condición . CLIENT_INFO es la información de sesión almacenada por la aplicación.
5.5 Gestión del mapa de calor de ILM y ADO con Oracle Enterprise Manager
Puede usar Oracle Enterprise Manager Cloud Control para administrar mapas de calor y optimización automática de datos.