1. Breve introducción del artículo
1. Primer autor: Philipp Schroppel
2. Año de publicación: 2022
3. Revista publicada: 3DV
4. Palabras clave: MVS, estimación de profundidad, punto de referencia, modelo de referencia
5. Motivación de exploración: sin embargo, los métodos de aprendizaje profundo actuales generalmente solo se evalúan en datos similares a su dominio de entrenamiento.
Sin embargo, los enfoques a menudo se evalúan solo con datos similares a su dominio de entrenamiento. Además, la evaluación se realiza predominantemente solo hasta una escala de escena relativa: en la profundidad del video, las predicciones se alinean con las profundidades reales del terreno en función de los valores medianos; en estéreo multivista, los modelos se suministran con valores de profundidad mínimos y máximos y predicen valores relativos dentro de este rango.
6. Objetivo de trabajo: resolver los problemas anteriores.
7. Idea central:
Se han utilizado métodos recientes de aprendizaje profundo para la estimación de profundidad de vista múltiple para obtener configuraciones estéreo de profundidad o vista múltiple de videos. A pesar de las diferentes configuraciones, estos métodos son técnicamente similares: asocian múltiples vistas de origen con una vista clave para estimar el mapa de profundidad de la vista clave. El artículo presenta el Robust Multi-View Depth Benchmark, que se basa en un conjunto de conjuntos de datos públicos y permite la evaluación de datos en diferentes campos bajo estas dos configuraciones. Los autores evalúan métodos recientes y encuentran que el rendimiento en todos los dominios es desigual. Además, se considera un tercer caso, donde la pose de la cámara está disponible y el objetivo es estimar el mapa de profundidad correspondiente a la escala correcta. Indica que, en este caso, los métodos recientes no son generales en diferentes conjuntos de datos. Esto se debe a que sus salidas de volumen de costo están fuera de distribución. Con este fin, se propone el modelo Robust MVD Baseline para la estimación de profundidad de vista múltiple, que se basa en componentes existentes pero emplea un nuevo enfoque de escala aumentada. Se puede aplicar a una estimación robusta de profundidad de vista múltiple independiente de los datos del objetivo.
8. Descarga de papel:
https://github.com/lmb-freiburg/robustmvd
https://arxiv.org/pdf/2209.06681.pdf
2. Traducción de tesis
1. Introducción
Desde los primeros días de la visión artificial, la profundidad se ha reconstruido mediante el paralaje de movimiento entre múltiples vistas. El principio de paralaje de movimiento es general. Es igual en todos los campos, al igual que la física es igual en cualquier parte del mundo. Por lo tanto, los métodos clásicos basados en geometría no se limitan a la distribución de entrenamiento, sino que son independientes de los datos de diferentes dominios.
En los últimos años, han surgido métodos de estimación de profundidad multivista basados en aprendizaje profundo. Se utilizan en configuraciones de profundidad de video, donde las imágenes provienen de video con movimiento de cámara pequeño e incremental pero desconocido, o en configuraciones estéreo de vista múltiple con colecciones de imágenes no estructuradas pero calibradas. Por lo general, el núcleo de estos métodos es una red profunda que asocia características aprendidas de múltiples imágenes y aprende a decodificar el volumen de costos obtenido en un mapa de profundidad estimado. En principio, este diseño permite que la red realice estimaciones en función del paralaje de movimiento, lo que debería permitir una buena generalización entre dominios y predicciones coherentes en diferentes escalas de escena. Sin embargo, los métodos generalmente solo se evalúan en datos similares a su dominio de entrenamiento. Además, la evaluación se realiza principalmente solo a escalas de escena relativas: en vídeo profundo, las predicciones se alinean con la profundidad real basada en la mediana; en geometría estéreo multivista, el modelo proporciona valores de profundidad mínimos y máximos, y dentro de este rango Predecir valores relativos.
En este trabajo, presentamos un punto de referencia basado en conjuntos de datos existentes para evaluar modelos profundos de múltiples vistas que se generalizan en todos los dominios. Además, dado que los casos específicos como el movimiento de cámara pequeño, las oclusiones o las áreas sin textura son potencialmente problemáticos, sería beneficioso que el modelo viniera con una medida de su incertidumbre, que debería estar relacionada con la alineación del error de predicción de profundidad. Específicamente, un punto de referencia robusto de profundidad de vista múltiple (1) evalúa los mapas de profundidad estimados a partir de datos de diferentes dominios de una manera cero y (2) evalúa la incertidumbre utilizando el área bajo la métrica de la curva de error dispersa. Además, (3) incluye evaluaciones en la configuración absoluta, donde se utilizan poses de cámara reales para el modelado, y las evaluaciones se realizan en su escala correcta en relación con las profundidades reales del terreno. Dado que la escala se proporciona a través de la pose, la evaluación se realiza sin un rango de profundidad dado y sin alineación. Esta configuración es relevante en la práctica, por ejemplo, en robótica o configuraciones multicámara donde se conocen las poses de la cámara.
Evaluamos modelos recientes para la estimación de la profundidad y la incertidumbre en la profundidad de video relativa original o la configuración estéreo multivista, así como en la configuración de estimación de profundidad absoluta anterior. Encontramos que (1) casi todos los modelos tienen un rendimiento desequilibrado en todos los dominios: (2) la incertidumbre solo tiene un acuerdo limitado con el error de predicción; (3) los modelos en su mayoría funcionan bien en escalas relativas, pero no se pueden aplicar directamente Estimación de profundidad de escala correcta en conjuntos de datos. Atribuimos el problema a escala absoluta a estadísticas fuera de distribución en el volumen de costo relevante: el aprendizaje de profundidad del modelo a partir del video usa solo la fracción del volumen de costo correspondiente al valor de profundidad absoluto visto durante el entrenamiento; en un mínimo dado y Dentro de el valor de profundidad máxima, el modelo estéreo de vista múltiple sobreajusta la distribución de volumen de costo, por lo que se necesita conocer un rango de profundidad suficientemente preciso.
El problema de la estimación de la profundidad a escalas absolutas del mundo real limita las aplicaciones prácticas. Para abordar este problema, construimos un modelo de línea de base simple para una estimación de profundidad de vista múltiple robusta de dominio cruzado e independiente de la escala. El modelo se basa principalmente en componentes existentes, como la estructura DispNet, y está entrenado en el conjunto de datos BlendedMVS y la versión estática del conjunto de datos FlyingThings3D. Durante el entrenamiento, solo agregamos aumento de escala como un nuevo componente para aleatorizar entre escalas. Esta línea de base simple cumple la promesa de usar el paralaje de movimiento: se generaliza a través de dominios y escalas.
2. Métodos y puntos de referencia anteriores
Profundidad del video . En Depth from Video, se estima un mapa de profundidad a partir de imágenes consecutivas de un video. Por lo general, se supone que se conocen los parámetros internos de la cámara, pero se desconoce el movimiento de la cámara. Por lo tanto, la tarea generalmente también incluye estimar el movimiento de la cámara entre imágenes. DeMoN es el primer enfoque basado en el aprendizaje profundo para esta tarea. DeMoN consta de una sola red que estima conjuntamente la profundidad y el movimiento de la cámara a partir de un par de imágenes consecutivas. Los métodos posteriores son DeepTAM y DeepV2D, los cuales procesan más de dos cuadros y utilizan alternativamente módulos de mapeo y seguimiento respectivamente para estimar la profundidad y el movimiento de la cámara. En este enfoque, los módulos de mapeo y seguimiento generalmente se ajustan demasiado a la escala de la escena vista durante el entrenamiento. Aplicar modelos a escenas en diferentes escalas requiere alinear predicciones a escalas de escena basadas en información adicional. Además, los estudios han demostrado que el módulo de mapeo de este método no se puede generalizar a través de escalas, es decir, generalmente es imposible ingresar poses de cámara reales a escalas del mundo real y obtener una profundidad absoluta. Vemos esto como una deficiencia, ya que la noción de mapear el paralaje del movimiento a la profundidad para un movimiento de cámara dado es independiente de la escala.
Geometría sólida multivista. En la geometría estéreo multivista, la tarea consiste en estimar la geometría 3D de la escena observada a partir de un conjunto de imágenes de varios fotogramas sin estructura con parámetros intrínsecos conocidos y poses de cámara. Aquí nos centramos en los mapas de profundidad como representaciones geométricas en 3D. DeepMVS es el primer método basado en redes profundas para esta tarea. DeepMVS asigna vistas clave a vistas de origen a través de capas de correlación que muestrean bloques de imágenes de origen en función de los valores de profundidad candidatos y los comparan con bloques en imágenes clave. Las características de coincidencia de vistas resultantes se fusionan mediante la agrupación máxima. MVSNet adopta un enfoque similar, pero compara las vistas clave y de origen en el espacio de características aprendidas y fusiona la información de varias vistas en función de la variación entre las vistas de origen. Muchos trabajos posteriores se basan en este concepto. R-MVSNet reduce el consumo de memoria mediante bucles. CVP-MVSNet y CAS-MVSNet se asocian de manera gruesa a fina para reducir las restricciones computacionales y lograr una mayor resolución de salida. Vis-MVSNet utiliza una estrategia de fusión tardía basada en la incertidumbre de predicción para mejorar la fusión de información de vistas múltiples. Para diferentes escalas de escena, todos estos métodos requieren los valores de profundidad mínimos y máximos de la escena observada como entrada y predicen la profundidad relativa a este rango. La investigación muestra que estos métodos tienen problemas en el entorno más general donde se desconoce el rango de profundidad de la escena observada, dada la verdadera pose.
Puntos de referencia y conjuntos de datos. Los métodos profundos de video aprendidos se evalúan principalmente en KITTI y scannet. KITTI es un conjunto de referencia para tareas clave en la conducción autónoma basada en visión, incluida la estimación de profundidad. ScanNet es un conjunto de datos para la comprensión de escenas 3D con videos RGB-D anotados de escenas de interiores adquiridos a escala con un marco de captura bien diseñado. El método de geometría estéreo multivista aprendido se evalúa principalmente en DTU, ETH3D y Tanks and Temples. La DTU consta de 80 escenas, cada una de las cuales muestra un objeto de mesa capturado por una cámara y un escáner de luz estructurada montado en un brazo robótico. Tanques y templos consisten en escenas del mundo real filmadas tanto en interiores como en exteriores con cámaras de alta resolución y escáneres láser industriales. Del mismo modo, el punto de referencia de geometría estéreo de vista múltiple de alta resolución ETH3D consta de imágenes de varias escenas interiores y exteriores adquiridas con cámaras DSLR de alta resolución y escáneres láser industriales. El entrenamiento generalmente se realiza en el mismo conjunto de datos, es decir, en KITTI, ScanNet y DTU. Además, algunos métodos se entrenan en BlendedMVS, que está especialmente diseñado para la diversidad para mejorar la generalización. En este trabajo, también entrenamos en el conjunto de datos FlyingThings3D, que se ha demostrado que se generaliza bien a otras tareas basadas en coincidencias, como la estimación de disparidad y flujo óptico.
3. Robusto punto de referencia de profundidad de múltiples vistas
El factor clave. En este trabajo, nuestro objetivo es evaluar la estimación de profundidad robusta de modelos de profundidad de vista múltiple en datos reales arbitrarios. Para reflejar esto, proponemos un punto de referencia robusto de profundidad de vista múltiple (MVD) basado en los siguientes cuatro factores clave:
- El rendimiento de la estimación de profundidad debe ser independiente del dominio objetivo. Como proxy, los puntos de referencia definen conjuntos de prueba de diferentes conjuntos de datos existentes. El conjunto de entrenamiento no está definido, pero debe ser diferente del conjunto de datos de prueba. La evaluación se realiza en una configuración de conjunto de datos cruzados de tiro cero sin ajuste fino. Esto modela la solidez de datos arbitrarios, posiblemente invisibles, del mundo real.
- El punto de referencia debe ser aplicable a diferentes configuraciones de estimación de profundidad de vista múltiple. Con este fin, el punto de referencia permite diferentes modalidades de entrada y una alineación opcional entre las profundidades previstas y las reales.
- La medida de incertidumbre de la estimación debe ser consistente con el error de estimación de profundidad. Esto se evalúa usando el área bajo la métrica de la curva de error de dispersión.
- La evaluación no debe verse afectada por la selección de la vista de origen. Para esto, se utiliza un procedimiento para encontrar y evaluar un conjunto cuasi-óptimo de vistas fuente.
Relación con los puntos de referencia existentes. Para la geometría estéreo multivista, existen varios puntos de referencia establecidos, como DTU, ETH3D y Tanks and Temples. Consideramos que los puntos de referencia propuestos son complementarios a estos puntos de referencia. Los puntos de referencia de geometría estéreo multivista existentes evalúan el rendimiento de la reconstrucción 3D basada en nubes de puntos fusionados. Además, el punto de referencia propuesto evalúa la capacidad de generalización de un modelo aprendido en función de sus resultados brutos típicos (es decir, mapas de profundidad e incertidumbres). Alentamos el trabajo futuro para evaluar el rendimiento de la reconstrucción 3D en los puntos de referencia existentes, pero también evaluar las capacidades de generalización en puntos de referencia sólidos de MVD. Los modelos profundos de video generalmente se entrenan y evalúan en conjuntos de datos existentes como KITTI o ScanNet. Por lo general, el conjunto de prueba es menos diverso que la línea de base propuesta. Por lo tanto, alentamos la investigación futura sobre la profundidad del video para evaluar la capacidad de generalización en puntos de referencia sólidos de MVD. Las estimaciones de profundidad a escalas absolutas generalmente no se calculan. Sin embargo, creemos que esta configuración es relevante en la práctica y alentamos el trabajo futuro en puntos de referencia sólidos de MVD evaluados en esta configuración.
3.1 Configuración
equipo de prueba. Los conjuntos de prueba del sólido punto de referencia MVD se basan en los conjuntos de datos KITTI, ScanNet, ETH3D, DTU y Tanks and Temples, ya que son conjuntos de datos de uso común para la evaluación de profundidad de video y geometría estéreo de múltiples vistas, que cubren diferentes dominios y escalas de escena.

Cada conjunto de prueba es un conjunto de muestras del conjunto de datos respectivo. Cada muestra tiene una vista de entrada V = (V0,··,Vk), incluida la vista clave V0 y las vistas de origen V1,...,Vk y un valor de profundidad de verdad del terreno (posiblemente escaso) z* para la vista clave. Cada vista Vi consta de una imagen Ii, su pose relativa a la vista clave y los parámetros intrínsecos Ki. La tarea es estimar un mapa de profundidad denso Z para una vista clave V0 a partir de los datos de entrada. Los conjuntos de prueba se eligen de modo que sean lo más comparables posible con las divisiones de datos existentes. El conjunto de prueba es intencionalmente pequeño para acelerar la evaluación, pero las muestras elegidas cubren una gran diversidad.
Conjunto de entrenamiento. El punto de referencia no define un conjunto de entrenamiento, ya que el objetivo es la solidez de los datos arbitrarios del mundo real, sin depender de un entorno de entrenamiento específico. Sin embargo, debe especificarse en los casos en que los datos de entrenamiento se superponen con el conjunto de datos de prueba del punto de referencia.
Configuraciones de evaluación. El punto de referencia permite la evaluación con diferentes modalidades de entrada proporcionadas al modelo, con una opción para alinear entre las profundidades predichas y reales. La modalidad de entrada proporcionada siempre incluye una imagen Ii y un Ki intrínseco para cada vista, y opcionalmente incluye una pose i OT y un rango de profundidad real del suelo (zmin∗; Zmax∗) con valores mínimos y máximos de profundidad real del suelo. Para resolver la ambigüedad de escala de algunos modelos, existe una opción para alinear el mapa de profundidad pronosticado con el mapa de profundidad real antes de calcular una métrica, por ejemplo, en función de la relación entre la profundidad real mediana y la profundidad pronosticada mediana.
En la literatura, los modelos de profundidad de los videos generalmente se aplican sin pose y rango de profundidad real y se evalúan por alineación. La geometría estéreo multivista a menudo se aplica junto con los rangos de profundidad de pose y verdad del suelo, y se evalúa sin alineación. Ambas configuraciones evalúan las estimaciones de profundidad en una escala relativa, es decir, hasta un factor de escala desconocido o dentro de un rango de profundidad determinado. Por el contrario, los puntos de referencia también evalúan la estimación de la profundidad en una escala absoluta. Aquí, el modelo tiene una pose pero no un rango de profundidad, y la tarea es estimar un mapa de profundidad a una escala absoluta del mundo real. La evaluación se realiza sin alineación.
Métrica de estimación de profundidad. Los resultados se informan para cada conjunto de pruebas de error relativo absoluto (rel) y relación interior (τ), con un umbral de 1,03:
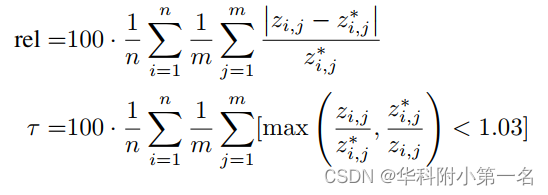
donde j indexa m píxeles con profundidades reales efectivas, I indexa n muestras en el conjunto de prueba y [.] denota corchetes de Iverson (1 si se cumple la condición dentro de los corchetes, 0 si no). El error relativo absoluto representa la desviación relativa promedio del valor de profundidad pronosticado del valor de profundidad real, expresado como porcentaje. La relación interior representa el porcentaje de píxeles con una predicción correcta, donde una predicción se considera correcta si el error es inferior al 3 %. Las métricas promedio y los tiempos de ejecución del modelo se informan en todos los conjuntos de pruebas, excepto los resultados de un único conjunto de pruebas.
El mapa de profundidad estimado se muestrea a resolución completa antes de calcular las métricas. Además, para eliminar el efecto de valores atípicos inverosímiles, las estimaciones de profundidad están restringidas a un rango de 0,1 m a 100 m. Especulamos que este es un rango razonable para aplicaciones del mundo real.
Medida de estimación de la incertidumbre. Los resultados informan la curva de error de dispersión utilizada comúnmente y el área bajo la curva de error de dispersión (AUSE). Para la curva de error dispersa, una métrica de error basada en el error de píxel real (incertidumbre de Oracle) y la incertidumbre de píxel estimada excluye progresivamente los píxeles más erróneos. La curva de error escaso es la diferencia entre la reducción de errores basada en Oracle y la basada en incertidumbre. AUSE es el área bajo la curva de error de dispersión. Un AUSE de 0 es óptimo, lo que indica un acuerdo perfecto entre la incertidumbre estimada y el error real.
Selección de vista de fuente. Para analizar el impacto de la elección de las vistas de origen en el rendimiento del modelo, el punto de referencia encuentra y evalúa un conjunto de vistas de origen casi óptimas para cada modelo. Para una muestra determinada, se almacenan las vistas clave del modelo para todos los pares (V0;Vi) y una vista de fuente única y el error relativo absoluto resultante. Luego, el error relativo absoluto del conjunto de vistas de origen se incrementa gradualmente agregando vistas de origen en el orden almacenado. Informe el error de resultado para el conjunto de vistas de origen con los valores relativos absolutos más bajos. Además, el error relativo absoluto se traza frente al tamaño del conjunto de vistas de origen.
3.2 Resultados robustos de referencia de MVD
Evalúa el modelo. En este trabajo, evaluamos los modelos COLMAP, DeMoN, DeepTAM, DeepV2D, MVSNet, CVP-MVSNet, VisMVSNet, PatchmatchNet, Fast-MVSNet, MVS2D en el benchmark propuesto. Esta selección refleja el trabajo fundamental que formó la base para mejoras posteriores, además de representar el mejor trabajo actual. Para todos los modelos, usamos el código y los pesos proporcionados originalmente, excepto para MVSNet, usamos la implementación de PyTorch, ya que proporciona un mejor rendimiento que la versión original de Tensorflow. Además, también evaluamos nuestra MVSNet reentrenada utilizando muestreo de exploración planar en el espacio de profundidad inversa. Para DeepV2D, evaluamos los modelos KITTI y ScanNet. Para MVS2D, evaluamos los modelos ScanNet y DTU. Tenga en cuenta que intencionalmente no volvemos a entrenar el modelo en un conjunto de datos unificado específico, ya que el objetivo del punto de referencia es la generalización en diferentes conjuntos de prueba, independientemente de los datos de entrenamiento.
resultado. En la siguiente tabla, informamos los resultados de la evaluación de nuestros modelos en el robusto punto de referencia MVD propuesto. Informamos la escala relativa, así como los resultados de la escala absoluta para la profundidad de video típica y la configuración de geometría estéreo de vista múltiple.
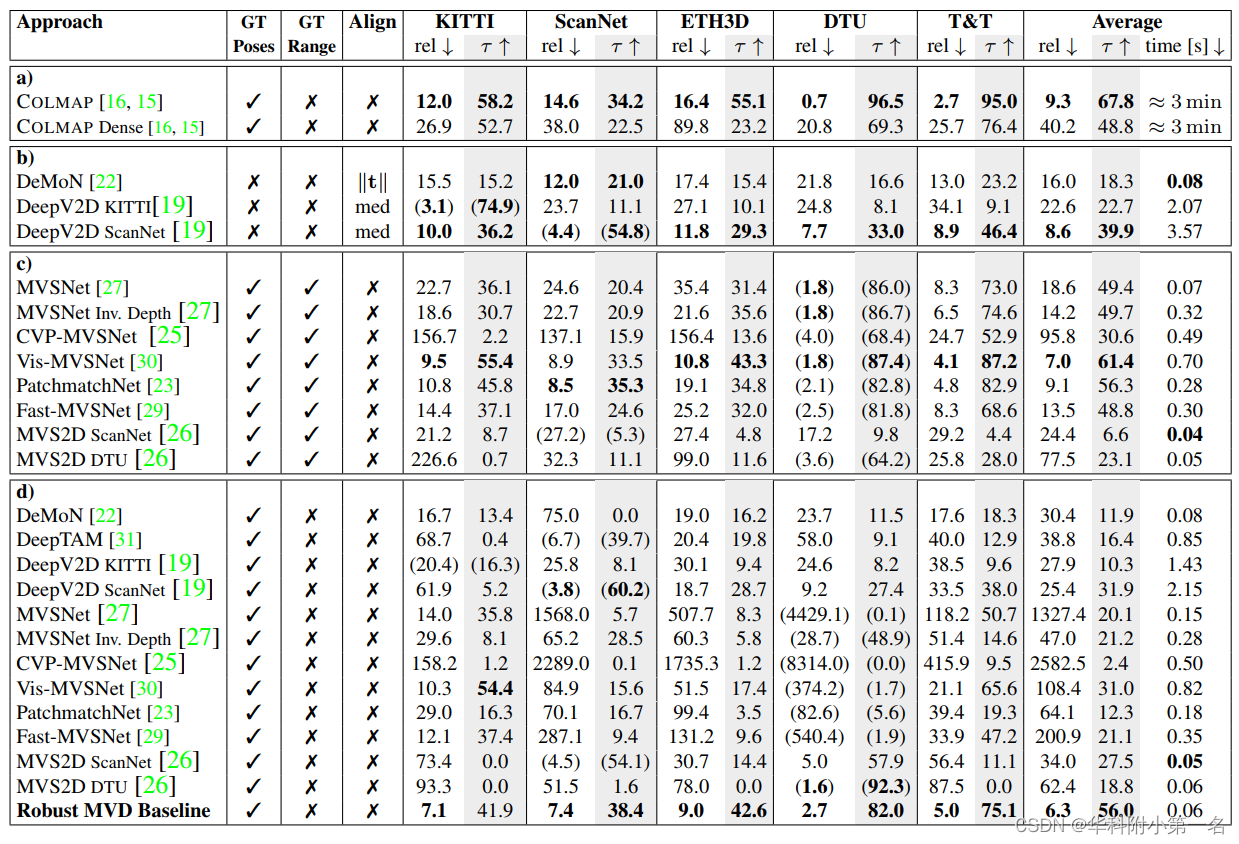
método clásico. Para la comparación con los métodos clásicos, en la Tabla a informamos los resultados de COLMAP en los puntos de referencia. Los resultados de aplicar COLMAP con parámetros predeterminados no se pueden comparar directamente con los del modelo aprendido, porque COLMAP estima el mapa de profundidad con una densidad más baja (54 % en promedio) y solo calculamos métricas para píxeles con predicciones válidas. Agregamos que COLMAP informa los resultados sin filtrar, lo que conduce a predicciones densas, pero con menor precisión.
Evaluación de Escalas Relativas. En las Tablas b y c, informamos los resultados de la profundidad de video típica y las escalas relativas para la configuración de geometría estéreo de vista múltiple. Los resultados muestran que todos los modelos funcionan significativamente mejor en el dominio de entrenamiento.
Evaluación de la escala absoluta. En la Tabla d, presentamos los resultados de evaluar el modelo bajo la configuración de estimación de profundidad de escala absoluta. Para DeepV2D y DeepTAM, solo usamos el módulo de mapeo y las poses reales de entrada. Para los modelos que requieren un rango de profundidad dado, asumimos que el rango de profundidad es desconocido y proporcionamos un rango predeterminado de 0,2 m a 100 m. Esto cubre la gama completa del conjunto de prueba y simula aplicaciones del mundo real sin más información que la pose.
En este entorno, todos los modelos evaluados se desempeñaron significativamente peor. Los modelos de profundidad de video funcionan peor que los datos de entrenamiento en conjuntos de datos con diferentes rangos de profundidad (por ejemplo, DeepV2D-ScanNet en KITTI). Los modelos estéreo multivista funcionan mal en conjuntos de datos con profundidades distintas al rango de profundidad predeterminado dado (por ejemplo, MVSNet en DTU). La mayoría de los modelos de evaluación construyen y decodifican internamente un volumen de costos que asocia una vista de origen con una vista externa específica en un estilo estéreo de exploración planar con un valor de profundidad específico (inverso). Atribuimos la caída del rendimiento a las estadísticas de volumen de costos fuera de distribución. El aprendizaje profundo del modelo de video utiliza solo la fracción de los volúmenes de costos correspondientes a los valores de profundidad absolutos vistos durante el entrenamiento. En el rango de profundidad proporcionado, el modelo estéreo de vistas múltiples supera la distribución de volumen de costos.
En la práctica, esto significa que los modelos de profundidad de video existentes a menudo no se pueden usar para poses de cámara reales conocidas. A su vez, los modelos estéreo de vista múltiple requieren un rango suficientemente preciso de profundidades de escena observadas. Aunque este rango de profundidad se puede
obtener con la estructura a partir del movimiento, tiene el costo de un mayor tiempo de ejecución y complejidad.
El sólido modelo de referencia de MVD propuesto exhibe un rendimiento constante en todos los conjuntos de prueba. Conjeturamos que el modelo aprende a explotar señales de múltiples vistas, lo que permite la generalización en todos los dominios. Además, el aumento de escala propuesto hace que la estimación de profundidad de escala absoluta sea independiente de la escala de la escena.
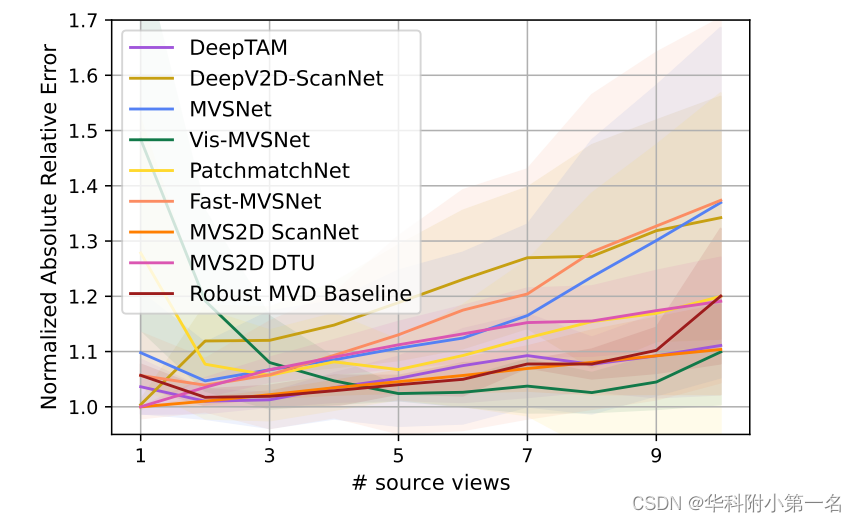
Depende del rendimiento de la vista de origen. En la siguiente figura, trazamos el rendimiento de diferentes números de vistas de origen. Para todos los modelos, trazamos los resultados en sus respectivas configuraciones, dando los mejores resultados promedio de acuerdo con la tabla a continuación. En una curva ideal, el error disminuye cuando hay más vistas de origen y converge al mínimo cuando más vistas no contienen información adicional. Los resultados muestran que la estrategia de fusión de vistas múltiples es subóptima para la mayoría de los modelos.
En la Fig. 3, trazamos las curvas de error dispersas para nuestro modelo estimado de incertidumbre de predicción de profundidad prevista. En la Tabla 3, informamos las métricas correspondientes de la curva de error de dispersión por debajo del área. Asimismo, informamos los resultados de cada modelo en sus respectivas configuraciones para brindar el mejor rendimiento promedio. Los resultados de los modelos anteriores muestran una alineación subóptima entre la incertidumbre y el error estimados, mientras que
los modelos de referencia sólidos de MVD brindan mejores incertidumbres.

Figura 2. El efecto del número de vistas de origen en la evaluación del rendimiento del modelo. Cada gráfico muestra el error relativo absoluto medio para el rendimiento casi óptimo de cada modelo en todos los conjuntos de prueba. El área sombreada representa la desviación estándar entre los conjuntos de prueba.
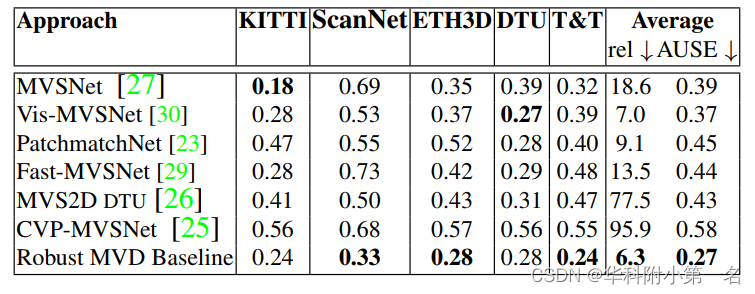
Tabla 3. El área bajo la curva de error de dispersión (AUSE) estima las incertidumbres de las estimaciones. Un AUSE de 0 significa la mejor alineación de incertidumbre y error.
4. Línea de base robusta de MVD
A continuación, describimos la línea de base robusta de MVD, que está específicamente diseñada como una línea de base para una estimación de profundidad sólida a través de escalas de dominio y escena, que puede servir como línea de base contra la cual se evalúan los puntos de referencia propuestos. El modelo se basa en gran medida en los componentes existentes y proporcionamos estudios de ablación de componentes individuales en la Tabla 4.
4.1 Estructura del modelo
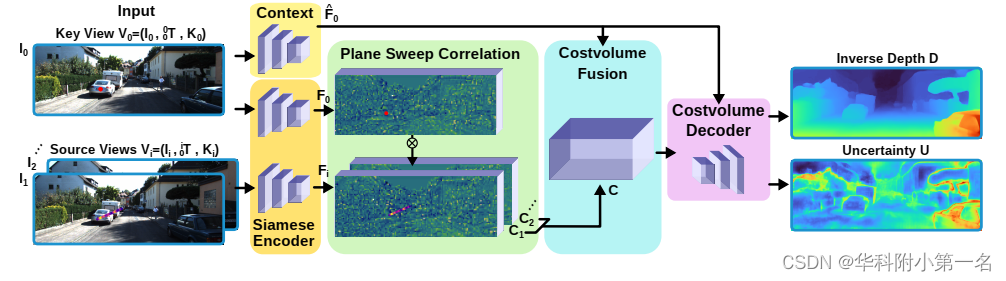
El sólido modelo de referencia de MVD se basa en la estructura de red DispNet simple, pero se adapta a una configuración de vista múltiple dada con imágenes no rectificadas. Más específicamente, como se muestra en la Fig. 4, y utilizando la notación definida en la Sección 3.1, el modelo está estructurado de la siguiente manera: (1) Una red codificadora siamesa fθ que asigna la imagen de entrada Ii al mapa de características, Fi = fθ(Ii ), ( 2) Una capa de correlación que asocia la función gráfica clave f0 con la función de vista de origen Fi de forma plana, lo que da como resultado un volumen de costo orientado a la vista C1,...,k, (3) mapeando la imagen clave a las funciones utilizadas para decodificar el volumen de costos F^0 = hσ (I0) red de codificador de contexto hσ, (4) un módulo de fusión gρ, que fusiona los cuerpos de costos de múltiples vistas de origen en una representación de fusión C = gρ(C1, . .., k, F^0), (5) red decodificadora de volumen de costo convolucional bidimensional (D, U) = kφ(C; F^0), que asigna el volumen de costo de fusión al mapa de profundidad inversa de salida D, gráfico no determinista U. El mapa de profundidad inversa D contiene el valor de profundidad inversa predicho d = 1/z para cada píxel de imagen clave.
En el primer experimento, aplicamos el modelo base en modo de vista dual, utilizando solo una vista de fuente única. Este factor excluye el efecto de la fusión de volumen de costo de vista múltiple y permite una evaluación independiente de los efectos del aumento de datos, el conjunto de datos de entrenamiento, la arquitectura del modelo y la estimación de la incertidumbre. Sobre esta base, evaluamos diferentes estrategias de fusión de información multivista. En la Tabla 4c, comparamos la arquitectura disnet y la arquitectura MVSNet.
4.2 Aumento de datos
Se aplican mejoras fotométricas y espaciales estándar a todas las vistas. Además, para evitar que el modelo sobreajuste la distribución de profundidad de los datos de entrenamiento, presentamos una nueva estrategia de aumento de datos, que llamamos aumento de escala. Durante el entrenamiento, el aumento de escala vuelve a escalar la transformación de verdad en el terreno i0t antes de introducirla en el modelo . Del mismo modo, el mapa de profundidad inverso D* de la realidad del terreno se escala con un factor de escala inverso. Los valores de profundidad inversa fuera del rango (0,009 m−1, 2,75 m−1 se configuran como máscara. Para seleccionar el factor de escala, el histograma de los valores de profundidad vistos durante la etiqueta de profundidad del contenedor de histograma con el valor más bajo el conteo y la muestra actual El valor medio de la profundidad real del terreno de . La Figura 6 muestra el efecto del aumento de datos en una muestra ejemplar. Como se muestra en los resultados de la Tabla 4a, el aumento de escala es un componente clave que permite que el modelo se generalice a través de diferentes escalas de escena

Figura 6. Datos de entrenamiento y aumento: (a) una imagen de vista clave de muestra de entrenamiento StaticThings3D I0, (b) imagen de vista clave aumentada, (c) profundidad inversa de la verdad del terreno D*, (d) factor de escala muestreado aleatoriamente 3.27 El d* expandido . Convierta 0t a la vista de origen escalada usando el mismo factor.

Tabla 4. Estudio de ablación del modelo basal robusto de MVD. Todos los resultados son para la configuración de estimación de profundidad de escala absoluta (Tabla 2d). a) El aumento de escala es crucial para la generalización a través de escalas de escena. b) El entrenamiento conjunto en StaticThings3D y BlendedMVS proporciona el mejor rendimiento. c) La estructura DispNet funciona mejor que la estructura MVSNet. d) Predecir los parámetros de la distribución de Laplace en lugar de estimaciones puntuales mejora el rendimiento. e) La fusión de vistas múltiples con un promedio ponderado utilizando los pesos aprendidos es ligeramente mejor que un promedio simple. El último modelo es el modelo robusto de referencia MVD.
4.3 Datos de entrenamiento
El sólido modelo de referencia de MVD se entrena conjuntamente en la versión estática del conjunto de datos FlyingThings3D existente y el conjunto de datos BlendedMVS existente. Lo llamamos StaticThings3D (ver Figura 6). StaticThings3D es similar a FlyingThings3D: contiene 2250 secuencias de entrenamiento y 600 de prueba de 10 fotogramas cada una, que muestran objetos ShapeNet colocados aleatoriamente frente a un fondo aleatorio de Flickr. Sin embargo, en StaticThings3D, todos los objetos son estáticos, solo se mueve la cámara. La ventaja de utilizar un conjunto de datos sintéticos aleatorios de este tipo es que reduce la posibilidad de que el modelo sobreajuste los datos previos específicos del dominio. En la Tabla 4b, comparamos StaticThings3D y BlendedMVS con el entrenamiento en un único conjunto de datos. El entrenamiento conjunto funciona cuantitativamente comparable al entrenamiento en BlendedMVS solo, pero los resultados son más precisos en los límites de los objetos.
4.4 Estimación de la incertidumbre
El robusto modelo de línea base MVD no predice estimaciones puntuales del mapa de profundidad inversa, sino parámetros de la distribución de Laplace, como en [7] y [30]. Con este fin, se agrega un canal de salida adicional a la red de manera que un canal codifica el parámetro de posición previsto y el otro codifica el parámetro de escala previsto. Luego, el entrenamiento se realiza minimizando la probabilidad logarítmica negativa. El impacto en el rendimiento de la predicción de profundidad se evalúa en la Tabla 4d. La incertidumbre de las predicciones se evalúa en la Tabla 3 y se muestra cualitativamente en la Figura 8.

Figura 8. Estimación de la incertidumbre: la primera fila muestra la imagen del fotograma clave, la segunda fila muestra el mapa de profundidad inversa pronosticado y la tercera fila muestra el mapa de incertidumbre pronosticado (el rojo indica incertidumbre). El modelo genera una alta incertidumbre para casos problemáticos, como (a) objetos en movimiento, (b) regiones sin textura, (c) ventanas o (d) estructuras finas.
4.5 Fusión multivista
Evaluamos dos estrategias para la fusión de múltiples vistas, promediando los volúmenes de costos de múltiples vistas de origen y promediando ponderados utilizando ponderaciones aprendidas. Para el promedio ponderado, se aplica una red con dos capas de pesos compartidos de volumen 2D pequeños a todos los volúmenes de costos orientados a la vista y genera pesos por píxel para cada vista. Usamos el aumento de datos de borrado para el entrenamiento de múltiples vistas, donde las regiones en la vista de origen se reemplazan aleatoriamente con un color promedio. La Tabla 4e presenta los resultados de dos estrategias de fusión de vistas múltiples. Un modelo con pesos aprendidos se denomina modelo de línea de base MVD robusto.
5. Conclusión
Proponemos el punto de referencia robusto de MVD para evaluar la solidez de los modelos de estimación de profundidad de vista múltiple en diferentes dominios de datos. El punto de referencia admite diferentes configuraciones de evaluación, es decir, diferentes modalidades de entrada y alineación opcional entre las profundidades reales predichas y del terreno. Descubrimos que los métodos existentes tienen un rendimiento desequilibrado en diferentes dominios y no se pueden aplicar directamente a escenas arbitrarias del mundo real para estimar la profundidad en la escala correcta desde una pose de cámara determinada. También demostramos que esto se puede solucionar con las técnicas existentes. Junto con el punto de referencia, proporcionamos un método de referencia sólido que puede servir como base para el trabajo futuro.