Hola a todos, soy Weixue AI. Hoy les presentaré el modelo de construcción de inteligencia artificial (Pytorch) 5: la construcción del modelo del mecanismo de atención y la aplicación de fusión del modelo GRU. El mecanismo de atención es un modelo de red neuronal que, en tareas de secuencia a secuencia, puede ayudar a resolver el problema de que es difícil obtener información global cuando la secuencia de entrada es larga. El modelo asigna diferentes pesos a diferentes partes de la secuencia de entrada para centrarse mejor en la información que debe procesarse en cada paso de tiempo. En el marco codificador-decodificador (Encoder-Decoder), el codificador mapea la secuencia de entrada en una serie de vectores, mientras que el decodificador genera la secuencia de salida en cada paso de tiempo. Durante este proceso, el decodificador debe prestar " atención " a todos los momentos del codificador para comprender qué entradas son más importantes para el paso de tiempo actual.
En el mecanismo de atención, el decodificador calcula la correlación entre la salida de cada codificador y el estado oculto del decodificador actual, y la convierte en un peso de atención para determinar el impacto de cada salida del codificador en el estado actual del decodificador. Estos pesos se utilizan para sumar los pesos de la salida del codificador, lo que da como resultado un vector de contexto que contiene información importante sobre la secuencia de entrada, lo que ayuda a mejorar el rendimiento y la generalización del modelo.
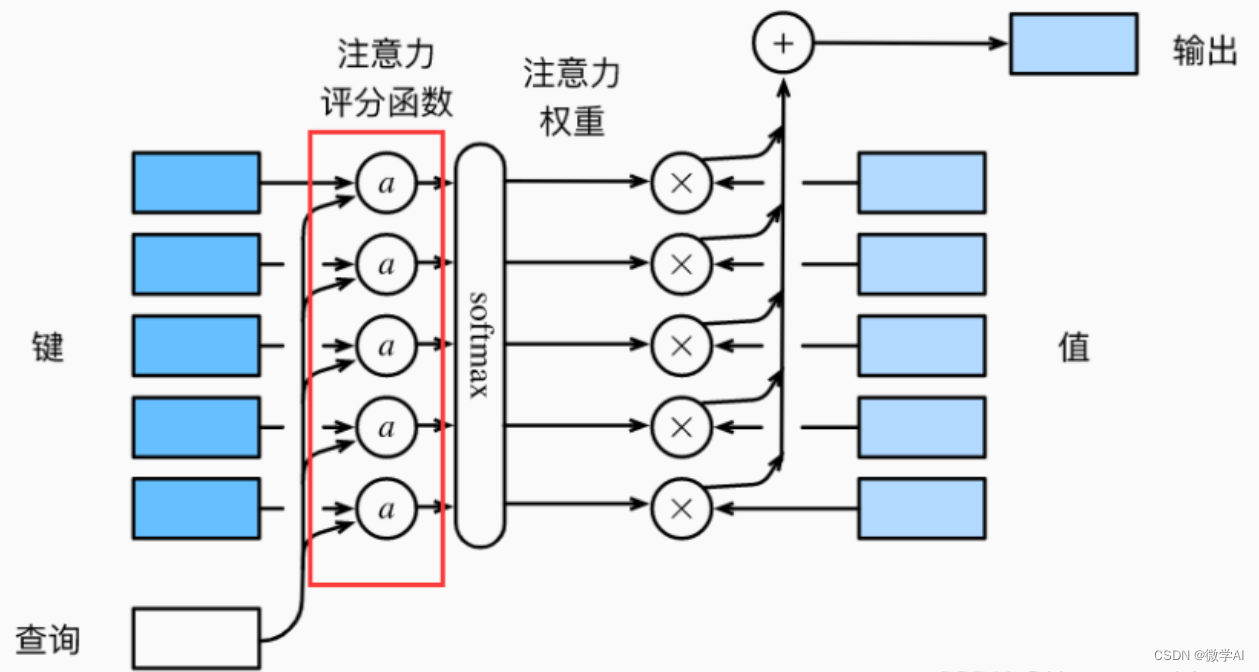
1. Construcción del modelo del mecanismo de atención
# 1. 导入所需库
import torch
import torch.nn as nn
import torch.optim as optim
import numpy as np
from torch.utils.data import Dataset, DataLoader
class Attention(nn.Module):
def __init__(self, hidden_size):
super(Attention, self).__init__()
self.hidden_size = hidden_size
self.attn = nn.Linear(self.hidden_size * 2, hidden_size)
self.v = nn.Linear(hidden_size, 1, bias=False)
def forward(self, hidden, encoder_outputs):
max_len = encoder_outputs.size(1)
repeated_hidden = hidden.unsqueeze(1).repeat(1, max_len, 1)
energy = torch.tanh(self.attn(torch.cat((repeated_hidden, encoder_outputs), dim=2)))
attention_scores = self.v(energy).squeeze(2)
attention_weights = nn.functional.softmax(attention_scores, dim=1)
context_vector = (encoder_outputs * attention_weights.unsqueeze(2)).sum(dim=1)
return context_vector, attention_weightsLa clase Atención anterior es un modelo de red neuronal del mecanismo de atención, que recibe dos parámetros de entrada: estado oculto y salida del codificador . Entre ellos, el estado oculto es la salida del paso de tiempo anterior en el decodificador, y la salida del codificador es la salida después de codificar la secuencia de entrada por el modelo del codificador. La salida del codificador y el estado oculto se utilizan para calcular los vectores de contexto y los pesos de atención . Al concatenar el estado oculto y la salida del codificador, el resultado se procesa a través de una capa lineal y la matriz de energía (energía) se obtiene después de usar la función de activación tanh . A continuación, use otra capa lineal (self.v) para convertir la matriz de energía en puntajes de atención (puntajes de atención) y use la función softmax para convertirla en pesos de atención (pesos de atención). Finalmente, las salidas del codificador se ponderan y combinan de acuerdo con los pesos de atención para obtener el vector de contexto.
Todo el proceso se puede resumir brevemente de la siguiente manera : primero conecte el estado oculto y la salida del codificador, luego use la transformación lineal y la función de activación tanh para calcular la matriz de energía, luego use la transformación lineal y la función softmax para calcular el peso de atención, y finalmente use el peso de atención al codificador Las salidas se ponderan y combinan para obtener el vector de contexto.
2. Construcción del modelo GRU + mecanismo de atención
class GRUModel(nn.Module):
def __init__(self, input_size, hidden_size, output_size, num_layers, dropout=0.5):
super(GRUModel, self).__init__()
self.hidden_size = hidden_size
self.num_layers = num_layers
self.gru = nn.GRU(input_size, hidden_size, num_layers, batch_first=True, dropout=dropout)
self.attention = Attention(hidden_size)
self.fc = nn.Linear(hidden_size, output_size)
self.dropout = nn.Dropout(dropout)
def forward(self, x):
h0 = torch.zeros(self.num_layers, x.size(0), self.hidden_size)
out, hidden = self.gru(x, h0)
out, attention_weights = self.attention(hidden[-1], out)
out = self.dropout(out)
out = self.fc(out)
return outEn el método de inicialización de la clase GRUModel, primero se llama al constructor de la clase principal para inicializar. Luego se define una capa GRU y su salida se pasa a la clase Atención para calcular el vector de contexto y el peso de atención. Finalmente, el vector de contexto se envía a una capa lineal y se agrega la operación de abandono para evitar el sobreajuste, y luego se genera el resultado de la predicción del modelo. Mediante el diseño de este modelo, podemos minimizar el impacto del cambio de longitud de la secuencia de entrada y la secuencia de salida en el rendimiento del modelo, y utilizar el mecanismo de atención para permitir que el modelo se centre mejor en la información importante de la secuencia.
3. Generación y carga de datos
# 3. 准备数据集
class SampleDataset(Dataset):
def __init__(self):
self.sequences = []
self.labels = []
for _ in range(1000):
seq = torch.randn(10, 5)
label = torch.zeros(2)
if seq.sum() > 0:
label[0] = 1
else:
label[1] = 1
self.sequences.append(seq)
self.labels.append(label)
def __len__(self):
return len(self.sequences)
def __getitem__(self, idx):
return self.sequences[idx], self.labels[idx]
train_set_split = int(0.8 * len(SampleDataset()))
train_set, test_set = torch.utils.data.random_split(SampleDataset(),
[train_set_split, len(SampleDataset()) - train_set_split])
train_loader = DataLoader(train_set, batch_size=32, shuffle=True)
test_loader = DataLoader(test_set, batch_size=32, shuffle=False)4. Entrenamiento modelo
# 4. 定义训练过程
def train(model, loader, criterion, optimizer, device):
model.train()
running_loss = 0.0
correct = 0
total = 0
for batch_idx, (inputs, labels) in enumerate(loader):
inputs, labels = inputs.to(device), labels.to(device)
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
running_loss += loss.item()
_, predicted = torch.max(outputs, 1)
_, true_labels = torch.max(labels, 1)
total += true_labels.size(0)
correct += (predicted == true_labels).sum().item()
print("Train Loss: {:.4f}, Acc: {:.2f}%".format(running_loss / (batch_idx + 1), 100 * correct / total))
# 5. 定义评估过程
def evaluate(model, loader, criterion, device):
model.eval()
running_loss = 0.0
correct = 0
total = 0
with torch.no_grad():
for batch_idx, (inputs, labels) in enumerate(loader):
inputs, labels = inputs.to(device), labels.to(device)
outputs = model(inputs)
loss = criterion(outputs, labels)
running_loss += loss.item()
_, predicted = torch.max(outputs, 1)
_, true_labels = torch.max(labels, 1)
total += true_labels.size(0)
correct += (predicted == true_labels).sum().item()
print("Test Loss: {:.4f}, Acc: {:.2f}%".format(running_loss / (batch_idx + 1), 100 * correct / total))
# 6. 训练模型并评估
device = "cuda" if torch.cuda.is_available() else "cpu"
model = GRUModel(input_size=5, hidden_size=10, output_size=2, num_layers=1).to(device)
criterion = nn.BCEWithLogitsLoss()
optimizer = optim.Adam(model.parameters(), lr=1e-3)
num_epochs = 100
for epoch in range(num_epochs):
print("Epoch {}/{}".format(epoch + 1, num_epochs))
train(model, train_loader, criterion, optimizer, device)
evaluate(model, test_loader, criterion, device)
resultado de la operación:
Epoch 97/100
Train Loss: 0.0264, Acc: 99.75%
Test Loss: 0.1267, Acc: 94.50%
Epoch 98/100
Train Loss: 0.0294, Acc: 99.75%
Test Loss: 0.1314, Acc: 95.00%
Epoch 99/100
Train Loss: 0.0286, Acc: 99.75%
Test Loss: 0.1280, Acc: 94.50%
Epoch 100/100
Train Loss: 0.0286, Acc: 99.75%
Test Loss: 0.1324, Acc: 95.50%