Tabla de contenido
1.1 Recorte del valor del rango de ajuste
1. Recorte de todos los parámetros (predeterminado)
2. Recorte parcial de parámetros
1.3 Recorte por norma global L2
2. Modelo de protocolo ONNX de exportación
3. Convierte una imagen dinámica en una imagen estática
3.1 Dos tipos de definiciones de gráficos
3.2 ¿En qué escenarios es necesario convertir las imágenes dinámicas en imágenes estáticas?
3.3 Por qué el modo gráfico dinámico se está volviendo cada vez más popular
4. Despliegue del razonamiento
4.1 Implementación del servidor—Inferencia de Paddle
4.2 Implementación móvil/integrada: Paddle Lite
4.3 Modelo de compresión — PaddleSlim
1. Recorte de degradado
En el módulo de procesamiento de lenguaje natural de PaddlePaddle, el recorte de degradado es una técnica utilizada para controlar el tamaño del degradado. Cuando se entrena una red neuronal, los gradientes pueden volverse muy grandes, lo que lleva a un entrenamiento inestable o gradientes explosivos. Para evitar esto, se puede usar el recorte de degradado para limitar el tamaño del degradado .
1.1 Recorte del valor del rango de ajuste
El recorte de degradado se logra restringiendo la norma del degradado dentro de un umbral predefinido. Específicamente, el recorte de gradiente compara la norma del vector de gradiente x calculado
con un umbral x dado .
Si
,
escale a
, de lo contrario no realice ninguna modificación. Esto asegura que la magnitud del gradiente no supere un umbral
, haciendo que el entrenamiento sea más estable.
1. Recorte de todos los parámetros (predeterminado)
De forma predeterminada, se recortan los gradientes de todos los parámetros del optimizador:
import paddle
linear = paddle.nn.Linear(10, 10)
clip = paddle.nn.ClipGradByValue(min=-1, max=1)
sdg = paddle.optimizer.SGD(learning_rate=0.1, parameters=linear.parameters(), grad_clip=clip)Este código define un modelo de capa lineal
linearcon 10 entradas y 10 salidas utilizando el marco PaddlePaddle. A continuación, se define unaClipGradByValueinstanciaclipque recorta el degradado a un valor mínimo y máximo dado (en este caso, -1 y 1, respectivamente). Finalmente, se define un optimizador de descenso de gradiente estocástico (SGD)sdg, se usa un optimizador con una tasa de aprendizaje de 0.1 y se pasa el clipperclipcomo parámetrograd_clip, lo que indica que se debe usar la técnica de recorte de gradiente al realizar actualizaciones de parámetros.En conjunto, la función de este código es definir un modelo que contenga una capa lineal y utilizar la técnica de recorte de degradado para optimizar los parámetros del modelo. De esta forma, se puede hacer que el modelo sea más estable durante el entrenamiento y evitar problemas como la explosión de gradiente o la desaparición.
2. Recorte parcial de parámetros
Parte del recorte de parámetros necesita establecer el parámetro paddle.ParamAttr , que need_clip por defecto es True, lo que significa que se requiere recorte. Si se establece en False, no se recortará.
Por ejemplo: para recortar solo el gradiente de peso en lineal, debe configurar bias_attr de la siguiente manera al crear una capa lineal:
linear = paddle.nn.Linear(10, 10,bias_attr=paddle.ParamAttr(need_clip=False))1.2 Recorte por norma L2
Recorte por norma L2: El degradado se utiliza como Tensor multidimensional, y se calcula su norma L2, si supera el valor máximo se recortará proporcionalmente, en caso contrario no se recortará.
Cómo se usa: debe crear una instancia de la clase paddle.nn.ClipGradByNorm y luego pasarla al optimizador. El optimizador recortará el gradiente antes de actualizar los parámetros.

1.3 Recorte por norma global L2
El gradiente de todos los parámetros en el optimizador se compone en un vector, y la norma L2 se resuelve para el vector. Si excede el valor máximo, se recortará proporcionalmente, de lo contrario, no se recortará.
Cómo se usa: debe crear una instancia de la clase paddle.nn.ClipGradByGlobalNorm y luego pasarla al optimizador. El optimizador recortará el gradiente antes de actualizar los parámetros.

2. Modelo de protocolo ONNX de exportación
ONNX (Open Neural Network Exchange) es un formato abierto para representar modelos de aprendizaje automático. Está desarrollado conjuntamente por Microsoft y Facebook y cuenta con el apoyo de otras empresas y organizaciones como AWS, Nvidia, etc. El objetivo principal de ONNX es proporcionar un estándar multiplataforma y multimarco que permita una integración e interacción perfectas entre diferentes marcos de aprendizaje profundo.
ONNX utiliza un formato de representación intermedio para representar modelos de aprendizaje profundo, que no depende de ningún marco específico, sino que utiliza un conjunto común de operadores y descriptores de tensor. De esta forma, ONNX puede convertir modelos entre diferentes marcos y ejecutarse en múltiples plataformas de hardware.
Las ventajas de ONNX incluyen:
Multiplataforma: ONNX puede ejecutarse en diferentes hardware y sistemas operativos, lo que hace que el modelo sea más flexible para implementar y aplicar.
Marco cruzado: ONNX es compatible con varios marcos de aprendizaje profundo populares, como PyTorch, TensorFlow, CNTK, etc., lo que facilita la conversión e integración de modelos entre diferentes marcos.
Alto rendimiento: el formato de representación intermedio de ONNX está diseñado como un formato gráfico computacional eficiente, que puede optimizar el rendimiento computacional del modelo.
Abierto: ONNX es un estándar abierto que cualquiera puede usar y extender.
Por lo tanto, ONNX es una tecnología muy útil que puede acelerar el despliegue y la aplicación de modelos de aprendizaje profundo y promover la colaboración y el desarrollo entre diferentes marcos.
ONNX (Open Neural Network Exchange) es un formato de archivo de código abierto diseñado para el aprendizaje automático para almacenar modelos entrenados. Permite que diferentes marcos de IA almacenen modelos en el mismo formato e interactúen . A través del formato ONNX, el modelo Paddle puede usar OpenVINO, ONNX Runtime y otros marcos para la inferencia.
3. Convierte una imagen dinámica en una imagen estática
3.1 Dos tipos de definiciones de gráficos
Dynamic Graph y Static Graph son dos formas de construir modelos en el marco de aprendizaje profundo.
El gráfico estático significa que antes de establecer el modelo, primero se define todo el gráfico de cálculo y luego los datos se ingresan en el gráfico de cálculo para el cálculo. Este método apareció por primera vez en TensorFlow. Los usuarios deben definir primero la estructura del gráfico de cálculo y luego ingresar datos en el gráfico de cálculo para el cálculo. Tiene buen rendimiento y escalabilidad.
Gráfico dinámico significa que el gráfico de cálculo se genera solo cuando el modelo se está ejecutando. Por ejemplo, PyTorch y Chainer son marcos de trabajo de aprendizaje profundo que utilizan gráficos dinámicos. En el gráfico dinámico, los usuarios pueden construir libremente modelos como escribir códigos Python, que tiene una mayor flexibilidad y facilidad de uso, y es adecuado para la experimentación y creación de prototipos rápidos.
Los gráficos estáticos y dinámicos tienen sus propias ventajas y desventajas, por ejemplo:
-
La ventaja del gráfico estático es que puede optimizar previamente el gráfico de cálculo, mejorar la eficiencia operativa y la escalabilidad, y es adecuado para entornos de producción a gran escala.
-
La ventaja de los gráficos dinámicos es que pueden construir modelos de manera más flexible, facilitar la depuración y la experimentación, y son adecuados para las etapas de investigación y desarrollo de prototipos.
En general, los gráficos estáticos y los gráficos dinámicos son dos métodos de modelado diferentes. De acuerdo con las necesidades y los escenarios específicos, puede elegir un marco de aprendizaje profundo y un método de modelado que se adapte a sus necesidades.
3.2 ¿En qué escenarios es necesario convertir las imágenes dinámicas en imágenes estáticas?
Al diseñar el marco de la paleta de mosca, se tienen en cuenta la alta usabilidad de los gráficos dinámicos y las ventajas de alto rendimiento de los gráficos estáticos, y se adopta el esquema de "unidad de dinámico y estático":
- En el desarrollo de modelos, se recomienda la programación de gráficos dinámicos. Se puede obtener una mejor experiencia de programación, una interfaz más fácil de usar y un mecanismo de interacción de depuración más amigable.
- Durante el entrenamiento del modelo o la implementación de inferencia, solo necesita agregar una línea de decorador @to_static para convertir el código de gráfico dinámico en código de gráfico estático y usar automáticamente el ejecutor de gráfico estático para ejecutar en la capa inferior. Se puede obtener un mejor rendimiento del tiempo de ejecución del modelo.
De acuerdo con los diferentes métodos de análisis y ejecución del Operador , la paleta voladora admite los siguientes dos paradigmas de programación:
- Modo gráfico estático (paradigma de programación declarativa) : primero compila y luego ejecuta. Los usuarios deben definir una estructura de red completa por adelantado y luego compilar y optimizar la estructura de red antes de ejecutarla para obtener resultados de cálculo.
- Modo gráfico dinámico (paradigma de programación imperativa) : ejecución analítica . Los usuarios no necesitan definir una estructura de red completa por adelantado y pueden obtener resultados de cálculo al mismo tiempo cada vez que escriben una línea de código de red.
Por ejemplo, suponga que el usuario escribe una línea de código: y = x + 1. En el modo de gráfico estático, ejecutar este código solo insertará un Operador con Tensor más 1 en el gráfico de cálculo. En este momento, el Operador no está realmente ejecutado y no se puede obtener El resultado del cálculo de y. Sin embargo, en el modo gráfico dinámico, todos los operadores se ejecutan inmediatamente.Después de ejecutar este código, el operador se ha ejecutado y el usuario puede obtener directamente el resultado del cálculo de y.
3.3 Por qué el modo gráfico dinámico se está volviendo cada vez más popular
Hay varias razones por las que el modo gráfico dinámico se está volviendo cada vez más popular:
-
Estructura de código más intuitiva: el modo de gráfico dinámico utiliza código Python para crear un gráfico de cálculo, lo que hace que el código sea más intuitivo y fácil de entender. En el modo de gráfico estático, los usuarios deben definir primero la estructura del gráfico de cálculo, lo que hace que la estructura del código sea más complicada y difícil de entender.
-
Mayor flexibilidad: en el modo gráfico dinámico, los usuarios pueden cambiar la estructura del modelo en cualquier momento según sea necesario y agregar o eliminar nodos informáticos para adaptarse a diferentes escenarios de aplicación. Esto hace que el modo Gráfico dinámico sea más adecuado para la creación rápida de prototipos y los experimentos de investigación.
-
Velocidad de iteración más rápida: en el modo de gráfico dinámico, los usuarios pueden iterar y depurar modelos más rápido porque pueden ver directamente la salida del modelo sin construir y ejecutar manualmente el gráfico computacional.
-
Mejor legibilidad y mantenibilidad: la estructura del código en el modo gráfico dinámico es más intuitiva y fácil de entender, lo que hace que el código sea más fácil de mantener y ampliar. Además, el modo gráfico dinámico también proporciona mejores funciones de depuración y resolución de problemas.
-
Soporte más amplio: en la actualidad, muchos marcos de aprendizaje profundo populares admiten el modo gráfico dinámico, como PyTorch, TensorFlow2.0, Chainer, etc. Esto permite a los usuarios cambiar de manera flexible entre múltiples marcos y elegir el método de modelado que más les convenga.
Como resultado, los patrones de gráficos dinámicos están ganando popularidad en el aprendizaje profundo, lo que permite a los desarrolladores e investigadores iterar y crear modelos más rápido y comprender y mantener mejor el código.
3.4 Resumen
Al reescribir un gráfico dinámico en un gráfico estático, existen principalmente las siguientes diferencias:
- Las API utilizadas son diferentes: Paddle proporciona tanto el uso de gráficos dinámicos como el uso de gráficos estáticos. Los dos pueden compartir la mayoría de las API, pero debe tenerse en cuenta que todavía hay una pequeña cantidad de API que necesitan distinguir entre gráficos dinámicos y gráficos estáticos. , como guardar modelos y gráficos estáticos en el ejemplo anterior.API cargada, etc.; además, las declaraciones de flujo de control de Python se pueden usar libremente en gráficos dinámicos, pero en gráficos estáticos, cuando las condiciones de juicio en el flujo de control están relacionadas con data (como el ejemplo while_loop mencionado anteriormente), debe convertirse para usar varias API de flujo de control dedicadas, como while_loop, cond, case, switch_case, etc.
- El proceso de lectura de datos es diferente: aunque la interfaz utilizada es básicamente la misma, el gráfico dinámico lee los datos cuando el programa se está ejecutando, lo que es lo mismo que nuestro hábito habitual de escribir programas como python, pero la red no se está ejecutando realmente. durante la etapa de red de gráficos estáticos, por lo que no se leen los datos, por lo que es necesario usar un "marcador de posición" (paddle.data) para indicar el tipo, la forma y otra información de los datos de entrada para completar la red. Para un uso específico, consulte la documentación de la API de DataLoader en el sitio web oficial de Paddle.
- El período de ejecución es diferente: el gráfico dinámico es el método de ejecución "lo que ves es lo que obtienes", mientras que el gráfico estático se divide en la fase de compilación y el ejecutor. Ya sea entrenamiento o predicción, se requiere que el ejecutor ejecute la red Al llamar al ejecutor, debe inicializarse, especificar los datos de entrada y el valor de retorno que se obtendrá, etc.
4. Despliegue del razonamiento
4.1 Implementación del servidor—Inferencia de Paddle
Diferencia con el marco principal model.predict
El producto de inferencia Paddle inference paddle y Model.predict del marco principal pueden realizar predicciones de inferencia. Paddle Inference es la biblioteca de inferencia nativa de Paddle, que actúa en el servidor y en la nube y proporciona capacidades de razonamiento de alto rendimiento . El objeto Model del marco principal es una red neuronal A con entrenamiento, prueba e inferencia. En comparación con Model.predict, la inferencia puede usar MKLDNN, CUDNN, TensorRT para acelerar la predicción y es compatible con las herramientas X2Paddle de marcos de trabajo de terceros (TensorFlow, Pytorh, Caffe, etc.) y la implementación del modelo destilado . Model.predict es adecuado para la predicción directa de modelos entrenados. La inferencia de Paddle es adecuada para usuarios que tienen requisitos de rendimiento y versatilidad de razonamiento. Se ha adaptado y optimizado profundamente para diferentes escenarios de aplicación en diferentes plataformas para garantizar que el modelo esté entrenado en el lado del servidor Listo para usar, implementación rápida.
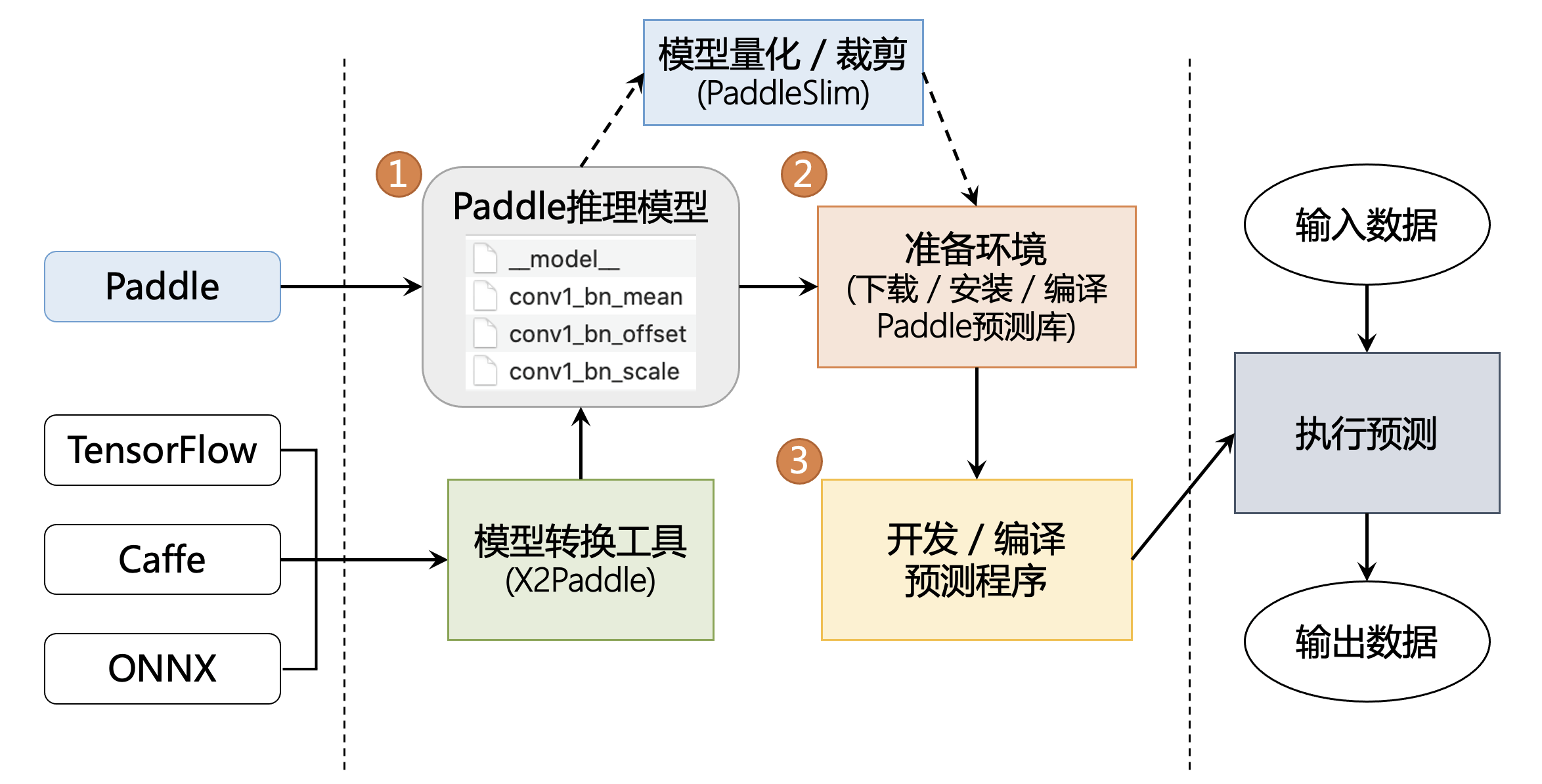
También hay ventajas como la implementación de alto rendimiento, la multiplexación de memoria/memoria de visualización para mejorar el rendimiento del servicio, la integración horizontal y vertical detallada de OP para reducir la cantidad de cálculo y el kernel de CPU/GPU integrado de alto rendimiento .
4.2 Implementación móvil/integrada: Paddle Lite
Paddle-Lite es una versión mejorada de Paddle-Mobile. Es un motor de predicción de aprendizaje profundo ligero y de alto rendimiento que admite la predicción ligera y eficiente de más escenarios, incluidos teléfonos móviles y una gama más amplia de hardware y plataformas. Además de mantener una conexión perfecta con PaddlePaddle, también es compatible con modelos producidos por otros frameworks de entrenamiento.
La documentación de uso completa se encuentra en la documentación de Paddle-Lite .
4.3 Modelo de compresión — PaddleSlim
PaddleSlim es una biblioteca de herramientas de compresión de modelos que incluye una serie de estrategias de compresión de modelos, como el recorte de modelos, la cuantificación de puntos fijos, la destilación de conocimientos, la búsqueda de hiperparámetros y la búsqueda de estructuras de modelos.
Para los usuarios comerciales, PaddleSlim proporciona una solución completa de compresión de modelos, que se puede utilizar en varios tipos de escenarios visuales, como la clasificación, detección y segmentación de imágenes. Al mismo tiempo, también continuamos explorando el esquema de compresión del modelo de dominio NLP. Además, PaddleSlim proporciona y mejora constantemente los puntos de referencia de varias estrategias de compresión en tareas clásicas de código abierto como referencia para los usuarios comerciales.
Para los investigadores o desarrolladores de algoritmos de compresión de modelos, PaddleSlim proporciona la interfaz auxiliar subyacente de varias estrategias de compresión, lo cual es conveniente para que los usuarios reproduzcan, investiguen y utilicen los últimos métodos en papel. PaddleSlim apoyará a los desarrolladores en el trabajo innovador relacionado con las estrategias de compresión de modelos desde la perspectiva de las capacidades subyacentes, la cooperación en consultoría técnica y los escenarios comerciales.