Tabla de contenido
1. Efecto de simulación de algoritmo
2. Los algoritmos implican una visión general del conocimiento teórico
4. Archivo de código de algoritmo completo
1. Efecto de simulación de algoritmo
Los resultados de la simulación matlab2022a son los siguientes:
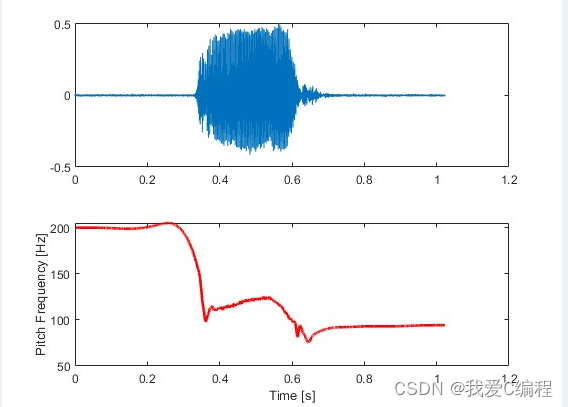

2. Los algoritmos implican una visión general del conocimiento teórico
El tono es el componente de frecuencia básico de la señal de voz, que determina el tono del habla y el tono del sonido. En el procesamiento de señales de voz, la estimación del tono es una tarea importante que se puede utilizar en la síntesis de voz, el reconocimiento de voz, la mejora del habla y otras aplicaciones. El filtro de Kalman extendido (Filtro de Kalman extendido, EKF) es un método de filtrado para sistemas no lineales, que se puede utilizar para la estimación de tono.
En las señales de voz, el componente de vibración periódica se denomina tono. El período de tono se refiere al intervalo de tiempo entre dos formas de onda periódicas adyacentes, también conocido como período de tono. La frecuencia se refiere al número de ciclos de vibración por segundo, y su recíproco se llama ciclo. Para un tono con período T, su frecuencia f = 1/T. El rango de frecuencia del tono suele estar entre 50 Hz y 500 Hz.
Kalman Filter (Kalman Filter, KF) es un método de filtrado para sistemas lineales, que puede inferir el estado del sistema en función del modelo de sistema conocido y el estado inicial en datos de observación con ruido. El filtrado de Kalman extendido es un método de filtrado para sistemas no lineales que se aproxima al sistema no lineal mediante el uso de la linealización local en cada paso de tiempo y utiliza el filtrado de Kalman para la estimación del estado.
El filtrado de Kalman extendido requiere un modelo de sistema que describa la evolución del tono. En la estimación de tono, el modelo del sistema se puede expresar como:
x(k) = A(k-1)x(k-1) + w(k-1)
donde x(k) representa el vector de estado en el tiempo k, A (k-1) representa la matriz de transición de estado y w(k-1) representa el ruido del sistema. En la estimación del tono, el vector de estado se puede expresar como:
x(k) = [p(k), T(k)]
donde p(k) representa el período del tono y T(k) representa la fase del tono. La matriz de transición de estado A(k-1) se puede expresar como:
A(k-1) = [1 0; 0 1]
Esta matriz indica que el período de tono y la fase permanecen sin cambios en cada paso de tiempo. El ruido del sistema w(k-1) se puede expresar como:
w(k-1) = [w1(k-1), w2(k-1)]
donde w1(k-1) y w2(k-1) son respectivamente Ruido que representa el período y la fase del tono.
El filtrado de Kalman extendido también requiere un modelo de observación, que describe la relación entre los datos de observación y los vectores de estado. En la estimación del tono, el modelo de observación se puede expresar como:
y(k) = H(k)x(k) + v(k)
donde y(k) representa el vector de observación en el tiempo k, y H(k) representa el matriz de observación, v(k) representa el ruido de observación. En la estimación del tono, el vector de observación se puede expresar como:
y(k) = [y1(k), y2(k)]
donde y1(k) y y2(k) representan los valores observados del período y la fase del tono, respectivamente. La matriz de observación H(k) se puede expresar como:
H(k) = [1 0; 0 1]
Esta matriz significa que podemos observar directamente el período y la fase del tono. El ruido de observación v(k) se puede expresar como:
v(k) = [v1(k), v2(k)]
donde v1(k) y v2(k) representan el período de tono y el ruido de fase, respectivamente.
El algoritmo de filtro de Kalman extendido se puede dividir en dos pasos: predicción y actualización. En el paso de predicción, usamos el modelo del sistema para predecir el vector de estado y la matriz de covarianza para el siguiente paso de tiempo. En el paso de actualización, usamos el modelo observado para actualizar los valores previstos en función de los datos observados. Los siguientes son los pasos detallados del algoritmo de filtro de Kalman extendido:
Inicialice el vector de estado y la matriz de covarianza:
x(0) = [p(0), T(0)]
P(0) = diag([p_var(0), T_var( 0)])
Para cada paso de tiempo k:
a. Paso de predicción:
De acuerdo con el modelo del sistema, prediga el vector de estado del siguiente paso de tiempo:
x(k|k-1) = A(k-1)x( k-1| k-1)
Según el modelo del sistema, prediga la matriz de covarianza del siguiente paso de tiempo:
P(k|k-1) = A(k-1)P(k-1|k-1)A (k-1)^ T + Q(k-1)
b. Paso de actualización:
Calcular la ganancia de Kalman K(k):
K(k) = P(k|k-1)H(k)^T(H( k)P(k| k-1)H(k)^T + R(k))^(-1)
Según los datos observados, calcule el vector de estado del paso de tiempo actual:
x(k|k) = x(k|k-1) + K (k)(y(k) - H(k)x(k|k-1)) Calcule
la matriz de covarianza del paso de tiempo actual en función de los datos observados:
P(k |k) = (I - K(k)H (k))P(k|k-1)
Entre ellos, Q(k-1) representa la matriz de covarianza del ruido del sistema y R(k) representa la matriz de covarianza del ruido de observación. Para la estimación del tono, podemos establecer Q(k-1) y R(k) como constantes de la siguiente manera: Q(k- 1)
= diag([q1, q2])
R(k) = diag([r1 , r2] )
donde q1 y q2 representan la variación del ruido del período y la fase del tono, respectivamente, y r1 y r2 representan la variación del ruido observada del período y la fase del tono, respectivamente.
3. Programa básico de MATLAB
..............................................................
%pitch tracking
for ii=2:size(datass,2)
%基于先前估计的均值一步预测
One_step_state=F*(state(:,ii-1));
P_OneStep(:,:,ii)=F*P(:,:,ii-1)*F'+C*Q*C';
H=cos((B*One_step_state)'+pha')*G-(G*One_step_state)'*diag(sin(B*One_step_state+pha))*(B);
O_covariance=(H*P_OneStep(:,:,ii)*H'+R);
% Kalman gain
K=P_OneStep(:,:,ii)*H'*O_covariance^(-1);
% 计算一步预测残差
h=(G*One_step_state)'*cos(B*One_step_state+pha);
correction_factor=K*(datass(:,ii)-h);
state(:,ii)= One_step_state+correction_factor;
P(:,:,ii) = P_OneStep(:,:,ii)-K*H*P_OneStep(:,:,ii);
end
%卡尔曼平滑器;
N=size(datass,2);
pitch(:,N) = state(:,N);
P_upS(:,:,N) = P(:,:,N);
for k = (N-1):-1:1
%计算除最后一个步骤外的所有步骤的预测步骤
sgain = (P(:,:,k)*F')/(F*P(:,:,k)*F' + C*Q*C');
pitch(:,k) = state(:,k) + sgain*(pitch(:,k+1) - F*(state(:,k)));
P_upS(:,:,k) = P(:,:,k)+ sgain*(P_upS(:,:,k+1) - P_OneStep(:,:,k+1))*sgain';
end
end
A8664. Archivo de código de algoritmo completo
V