[Práctica de aprendizaje automático] Uso de la biblioteca de optimización BayesOpt para optimizar los hiperparámetros del conjunto de datos de precios de la vivienda
1. Pasos para la optimización de hiperparámetros usando BayseOpt
Definir la función objetivo
Definir espacio de parámetros
Definir la función objetivo de optimización
definir la función de validación (opcional)
Ejecutar el proceso de optimización real
2. Hay tres reglas en la biblioteca BayseOpt que afectan la definición de la función objetivo
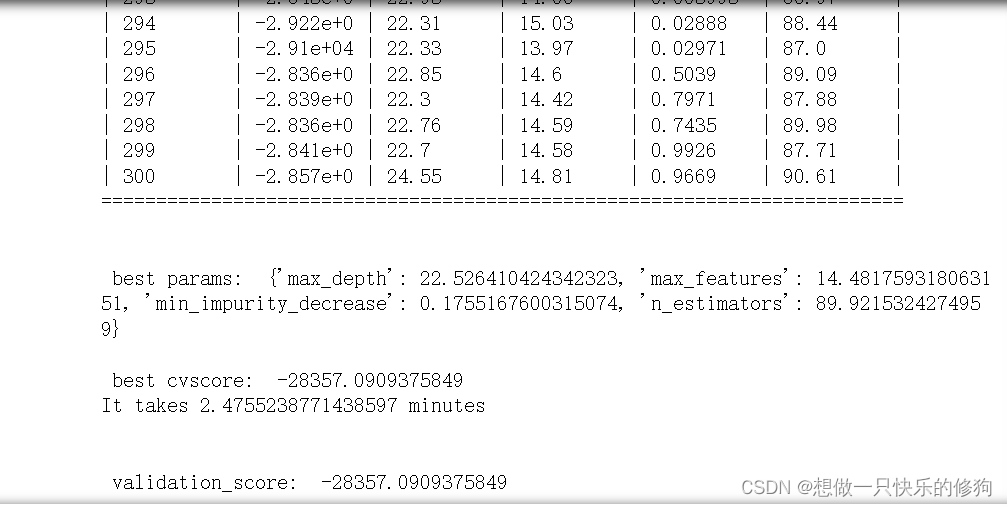
3. Código
3.1 Importar biblioteca y datos
#基本工具
import numpy as np
import pandas as pd
import time
import os #修改环境设置
#算法/损失/评估指标等
import sklearn
from sklearn.ensemble import RandomForestRegressor asRFR
from sklearn.model_selection import KFold, cross_validate
#优化器
from bayes_opt import BayesianOptimization
data = pd.read_csv(r"C:\work-file\pythonProject\Demo练习\贝叶斯优化\train_encode.csv",index_col=0)X= data.iloc[:,:-1]
y = data.iloc[:,-1]
Debido a que esta biblioteca no puede garantizar el mismo resultado de salida cada vez a través de la semilla de números aleatorios, los resultados reproducidos por diferentes personas pueden ser diferentes.