navegación:
Tabla de contenido
2 Solución de tecnología de transacciones distribuidas
2.1 Revisión de transacciones locales y transacciones distribuidas
2.2 ¿Qué es la teoría de la PAC?
2.3 Esquema de control de transacciones distribuidas
2.3.1 Fuerte consistencia de CP y fuerte disponibilidad de AP
2.3.2 Teoría BASE: Disponibilidad Básica, Estado Blando, Consistencia Final
2.3.3 Métodos de implementación de consistencia fuerte y consistencia eventual
2.4.2 Solución técnica, tabla de mensajes
3 Interfaz de publicación de cursos
3.1 Definición de interfaz, publicar cursos de acuerdo con la identificación del curso
3.3.1 Crear tabla de mensajes y tabla de historial de mensajes
4 [Módulo de mensajes] SDK de procesamiento de mensajes
4.1.1 ¿Por qué extraer el módulo de mensajes?
4.1.3 SDK no necesita proporcionar lógica para ejecutar tareas
4.1.4 ¿Cómo asegurar la idempotencia de las tareas?
4.1.5 ¿Cómo asegurar que las tareas no se repitan?
4.1.6 ¿Cómo prevenir la ejecución repetida de tareas pequeñas en el escenario?
4.2 Realización del servicio de mensajes
4.2.0 Inicializar el módulo sdk de mensajes
4.2.1 Escaneo y finalización de mensajes, consulta y finalización de pequeñas tareas de etapa
4.2.2 Clase abstracta de procesamiento de tareas para facilitar la herencia de clases de tareas
4.3 xxl-job integra el SDK de mensajes para programar la tarea de publicar cursos
4.3.2 [Módulo de contenido] Clase de tarea de publicación de cursos
5.1 ¿Qué es la página estática?
5.2 Prueba estática de la página de vista previa del curso Freemarker
5.3.1 Preparación del entorno, dependencia de carga de varios archivos, clase de configuración
5.3.3 Prueba de llamada remota
5.4 Procesamiento de degradación de fusibles Hystrix
5.4.1 Avalancha, disyuntor, degradación
5.4.2 Procesamiento de degradación de fusibles
5.4 Curso de desarrollo estático
5.4.3 Navegar por la página detallada
1 proceso comercial, almacenamiento + almacenamiento en caché + ES + MinIO para almacenar páginas estáticas
El personal de la institución de enseñanza puede publicar el curso después de que se apruebe la revisión del curso, y el curso se mostrará públicamente en el sitio web para que los estudiantes lo vean, elijan cursos y aprendan.
La visualización de la información del curso en el sitio web debe resolver el problema de rendimiento de la visualización de la información del curso.Si la velocidad es lenta (excluyendo la velocidad de la red), afectará la experiencia del usuario.
¿Cómo buscar cursos rápidamente? ¿Es factible abrir la página de detalles del curso y seguir consultando la base de datos?
Para mejorar la velocidad del sitio web, la información del curso debe almacenarse en caché y la información del curso debe agregarse a la biblioteca de índice de ES para facilitar la búsqueda.
Proceso comercial de publicación de cursos:
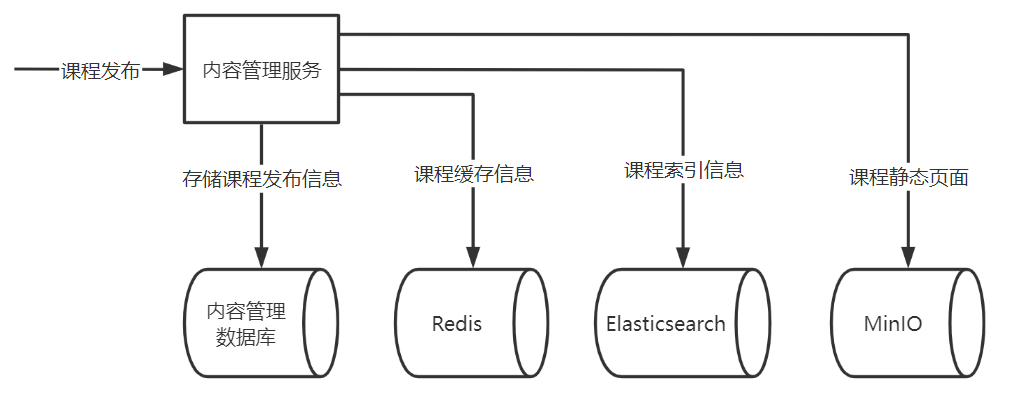
1. Guarde la información de publicación del curso en la tabla de publicación del curso de la base de datos de administración de contenido y actualice el estado de publicación en la tabla de información básica del curso a publicado.
2. Almacene la información de caché del curso en Redis.
3. Almacene la información del índice del curso en Elasticsearch.
4. Estatice la página de vista previa del curso y guárdela en el sistema de archivos minIO para navegar rápidamente por la página de detalles del curso.
Proceso comercial detallado:
1. Inserte un registro en la tabla de publicación del curso Course_publish. El registro proviene de la tabla de prepublicación del curso. Si existe, se actualizará. El estado de publicación es: publicado.
2. Actualice el estado de publicación de este curso en Course_base: Published
3. Elimine el registro correspondiente en la tabla de prelanzamiento del curso .
4. Inserte un mensaje en la tabla de mensajes mq_message , el tipo de mensaje es: publicación_curso, es decir, el mensaje es para procesar la tarea de publicación del curso, "información comercial asociada 1" es la identificación del curso.
5. El mensaje insertado es una tarea de publicación del curso, que almacenará la información de la memoria caché del curso en Redis, almacenará la información del índice del curso en Elasticsearch, hará estática la página de vista previa del curso y la almacenará en el sistema de archivos minIO.
Los datos en la tabla de lanzamiento del curso provienen de la tabla de prelanzamiento del curso y sus estructuras son básicamente las mismas, excepto que el estado en la tabla de lanzamiento del curso es el estado de lanzamiento del curso, como se muestra en la siguiente figura:

La información del caché del curso en redis es para convertir los datos en la tabla de publicación del curso en json para el almacenamiento.
La información del índice del curso en elasticsearch es para indexar y almacenar el nombre del curso, la introducción del curso y otra información de acuerdo con las necesidades de búsqueda.
Los archivos de página estática (páginas web html) de los cursos se almacenan en MinIO, y los detalles del curso se ven a través del sistema de archivos para navegar por la página de detalles del curso.
2 Solución de tecnología de transacciones distribuidas
2.1 Revisión de transacciones locales y transacciones distribuidas
¿Qué son los asuntos locales?
@Anotación transaccional . Por lo general, usamos Spring para controlar las transacciones en el programa usando las características de transacción de la propia base de datos , por lo que se llama transacción de base de datos.Dado que la aplicación se basa principalmente en la base de datos relacional para controlar la transacción, esta base de datos solo pertenece a la aplicación. por lo tanto, en función de la relación de la propia aplicación, las transacciones de bases de datos pequeñas también se denominan transacciones locales.
Las transacciones locales tienen las cuatro características de ACID. Cuando se implementa una transacción de base de datos, todas las operaciones involucradas en una transacción se incorporarán a una unidad de ejecución inseparable. Todas las operaciones en esta unidad de ejecución tendrán éxito o fallarán. Siempre que alguna de ellas falle para ejecutar la operación resultará en la reversión de toda la transacción.
¿Qué es una transacción distribuida?
Una transacción distribuida significa que los participantes de la transacción, el servidor que respalda la transacción, el servidor de recursos y el administrador de transacciones están ubicados respectivamente en diferentes nodos de diferentes sistemas distribuidos .
Escenarios para transacciones distribuidas:
Proceso Cross-JVM: bajo la arquitectura de microservicio, llamada remota

Base de datos cruzada: un solo servicio opera múltiples bases de datos:
Tenga en cuenta que aquí estamos hablando de varias bases de datos, no de varias tablas en la misma base de datos.

Base de datos única multiservicio:

2.2 ¿Qué es la teoría de la PAC ?
CAP es la abreviatura de Consistencia, Disponibilidad y Tolerancia de partición, que representan consistencia, disponibilidad y tolerancia de partición respectivamente.
- Coherencia C: Sincronización de datos
- Disponibilidad A: Se puede acceder al nodo normalmente
- Tolerancia a fallas de partición P: cuando se produce una partición en el clúster, todo el sistema debe continuar brindando servicios externos
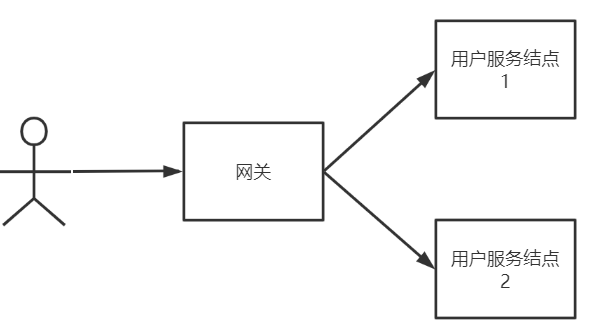
El cliente accede a los dos nodos del servicio de usuario a través de la pasarela:
La consistencia significa que no importa a qué nodo acceda el usuario, los datos obtenidos son los más recientes Por ejemplo, al consultar la información de Xiao Ming, los resultados de las dos consultas no pueden ser diferentes cuando los datos no han cambiado.
Disponibilidad significa que los resultados se pueden consultar en cualquier momento cuando se consulta la información del usuario , pero no se garantiza que se consulten los datos más recientes.
La tolerancia de partición también se denomina tolerancia a fallas de partición.Cuando el sistema adopta una arquitectura distribuida, las solicitudes se interrumpen o los mensajes se pierden debido a una comunicación de red anormal cuando se producen particiones, pero el sistema aún necesita proporcionar servicios externos .
- Partición: debido a fallas en la red u otras razones, algunos nodos en el sistema distribuido pierden la conexión con otros nodos, formando una partición independiente.
- Tolerancia a fallas: cuando se particiona el clúster, todo el sistema debe continuar brindando servicios externos
La teoría CAP enfatiza que es imposible satisfacer estos tres puntos en un sistema distribuido , ya sea para garantizar CP o garantizar AP .
Dado que es un sistema distribuido, se debe cumplir con la tolerancia de partición, ya que inevitablemente se producen anomalías en la red entre los servicios, y todo el sistema no puede dejar de estar disponible debido a anomalías en la red local.
Si se cumple P, entonces C y A no se pueden satisfacer al mismo tiempo:
Por ejemplo, si agregamos la información de un usuario Xiaoming, la información se agrega primero al nodo 1 y luego se sincroniza con el nodo 2, como se muestra en la siguiente figura:
Si desea cumplir con la consistencia C, debe esperar a que se complete la sincronización de la información de Xiaoming antes de que se pueda usar el sistema (de lo contrario, los datos no se consultarán cuando la solicitud llegue al nodo 2, lo que viola la consistencia). El sistema no está disponible durante el proceso de sincronización de la información, por lo que A no puede satisfacerse mientras se satisface C.
Si se va a satisfacer la Disponibilidad, el sistema debe estar siempre disponible sin esperar a que se complete la sincronización de la información. En este momento, no se puede satisfacer la consistencia del sistema.
Por lo tanto, para el control de transacciones distribuidas en un sistema distribuido, se garantiza CP o AP.

2.3 Esquema de control de transacciones distribuidas
El control de transacciones distribuidas requiere una compensación entre C y A. Para garantizar la coherencia, no garantice la disponibilidad y, para garantizar la disponibilidad, no garantice la coherencia. En primer lugar, debe confirmar si desea CP o AP, y debe juzgar de acuerdo con el escenario de aplicación.
2.3.1 Fuerte consistencia de CP y fuerte disponibilidad de AP
Escenario CP: Satisfacer C y abandonar A, enfatizando la consistencia . Aplicable a escenarios con altos requerimientos de puntualidad.
Transferencia interbancaria : una solicitud de transferencia debe esperar a que los sistemas bancarios de ambas partes completen toda la transacción antes de que se considere completa, siempre que uno de ellos falle y la otra parte realice una operación de reversión.
Operación de apertura de cuenta: Al abrir una cuenta en el sistema empresarial, también debe abrir una cuenta con el operador, si alguna de las partes no logra abrir una cuenta, el usuario no podrá usarla, por lo que debe cumplir con el CP.
Escenario AP: Satisfacer A y abandonar C, enfatizando la usabilidad . Aplicable a escenarios con bajos requerimientos de puntualidad.
Reembolso del pedido , el reembolso es exitoso hoy y la cuenta se acreditará mañana, siempre que el usuario pueda aceptar el crédito dentro de un cierto período de tiempo.
Regístrese para enviar puntos, y los puntos se acreditarán en 24 minutos después del registro exitoso.
Para la comunicación por SMS de pago, si el pago es exitoso y se envía el SMS, puede haber un retraso en el envío del SMS, o incluso puede que no se envíe correctamente.
En aplicaciones prácticas, hay muchos escenarios que se ajustan a AP. De hecho, aunque AP abandona la consistencia C, de hecho, los datos finales son consistentes y se satisface la consistencia final. Por lo tanto, la industria define la teoría BASE.
2.3.2 Teoría BASE: Disponibilidad Básica, Estado Blando, Consistencia Final
BASE es un acrónimo de las tres frases Basicly Available (básicamente disponible), Soft state (estado suave) y Eventualmente consistente (consistencia final).
Disponibilidad básica: cuando el sistema no puede cumplir con todos los requisitos disponibles, basta con garantizar que los servicios básicos estén disponibles. Por ejemplo, un sistema para llevar tiene un sistema concurrente alto alrededor de las 12:00 del mediodía. En este momento, es necesario asegurarse de que los servicios involucrados en el proceso de pedido estén disponibles y otros servicios no estén disponibles temporalmente.
Estado suave: significa que puede haber un estado intermedio, como: imprimir sus propias estadísticas de seguridad social, la operación no mostrará el resultado de inmediato, pero le recordará que la impresión está en progreso, verifique después de XXX tiempo. Aunque se dan estados intermedios, el estado final es el correcto.
Consistencia Final: Luego de que la operación de devolución no se realice a tiempo, la cuenta será acreditada después de un cierto período de tiempo, abandonando la consistencia fuerte y satisfaciendo la consistencia final.
2.3.3 Métodos de implementación de consistencia fuerte y consistencia eventual
Darse cuenta de CP es lograr una fuerte consistencia:
Implementación basada en modo AT utilizando el framework Seata
Se implementa en base al modo TCC utilizando el framework Seata .
Para implementar AP, es necesario asegurar la consistencia final de los datos:
Utilice el método de notificación de la cola de mensajes para darse cuenta de que la notificación no se vuelve a intentar automáticamente y se requiere un procesamiento manual para alcanzar el número máximo de fallas ;
Usando el esquema de programación de tareas , inicie la programación de tareas para sincronizar la información del curso desde la base de datos a elasticsearch, MinIO y redis.
2.4 Esquema de control de transacciones para la publicación de cursos: xxl-job logra la consistencia final
2.4.1 Análisis
Reflexión: después de aprender tantas teorías, vuelva a la publicación del curso. Después de realizar la operación de publicación del curso, debe escribir cuatro datos en la base de datos, redis, elasticsearch y MinIO. ¿Qué solución se usa en este escenario?
Conclusión: la publicación del curso garantiza la consistencia final de AP, utilizando la programación de tareas xxl-job
¿Conocer a CP?
Si se cumple el CP, significa que después de la operación de publicación del curso, se escriben cuatro copias de los datos en la base de datos, redis, elasticsearch y MinIO. Mientras una copia falle, todas las demás se revertirán.
¿Conoce a AP?
Después de la operación de publicación del curso, primero actualice el estado de publicación del curso en la base de datos y luego escriba la información del curso en redis, elasticsearch, MinIO después de la actualización, siempre que los datos finalmente se escriban en redis, elasticsearch, MinIO dentro de un cierto período de tiempo .
En la actualidad, ya tenemos la acumulación técnica de la programación de tareas. Aquí elegimos el esquema de programación de tareas para realizar el control de transacciones distribuidas, y la publicación del curso puede cumplir con la consistencia final de AP .
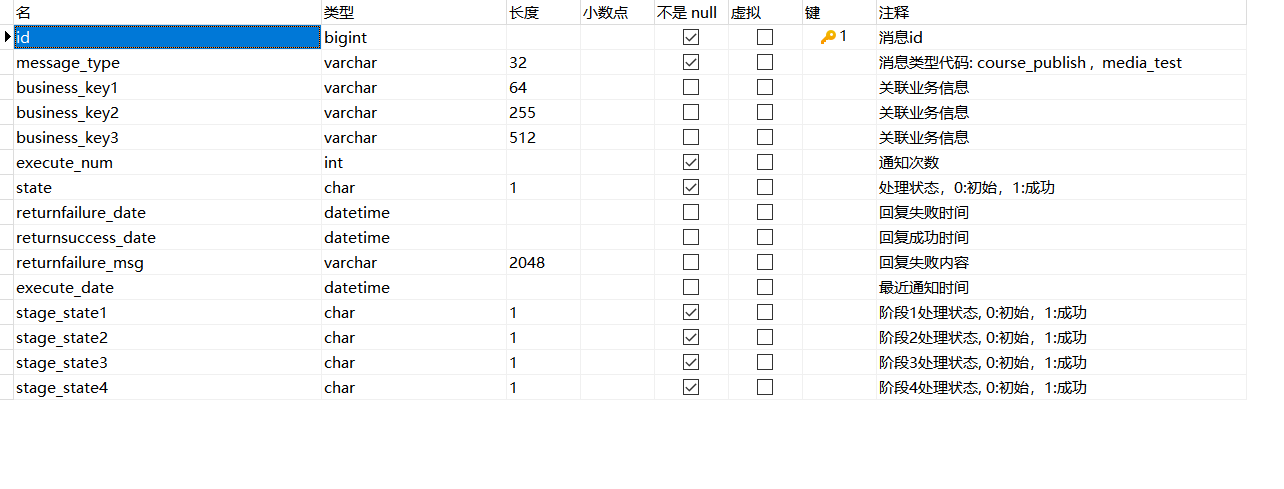
2.4.2 Solución técnica, tabla de mensajes
La siguiente figura es la solución técnica específica:

1. Agregue una tabla de mensajes en la base de datos del servicio de administración de contenido , que se encuentra en la misma base de datos que la tabla de lanzamiento del curso .
2. Haga clic en la publicación del curso para escribir la información de publicación del curso en la tabla de publicación del curso a través de asuntos locales y escriba el mensaje de publicación del curso en la tabla de mensajes al mismo tiempo . Controlado a través de la base de datos, siempre que la tabla de liberación del curso se inserte con éxito en la tabla de mensajes, los datos de la tabla de mensajes registrarán las tareas liberadas por un determinado curso.
3. Inicie el sistema de programación de tareas para programar regularmente el servicio de administración de contenido para escanear los registros de la tabla de mensajes regularmente .
4. Cuando se escanee el mensaje publicado por el curso, se completará la operación de sincronización de datos a redis, elasticsearch y MinIO.
5. Elimine el registro de la tabla de mensajes después de completar la tarea de sincronización de datos.
Tabla de mensajes:
2.4.3 Proceso comercial
La siguiente figura muestra el proceso de la operación de liberación del curso:

1. Ejecute la operación de liberación y agregue una "tarea de liberación del curso" a la tabla de mensajes mientras almacena la tabla de liberación del curso en el servicio de administración de contenido. Aquí, las transacciones locales se utilizan para garantizar que la información de publicación del curso se guarde correctamente y que la tabla de mensajes también se guarde correctamente.
2. El servicio de programación de tareas programa regularmente el servicio de administración de contenido para escanear la tabla de mensajes. Dado que una tarea de publicación del curso se inserta en la tabla de mensajes después de la operación de publicación del curso, se escanea una tarea en este momento.
3. Obtenga la tarea y comience a ejecutarla, y almacene datos en redis, elasticsearch y file system respectivamente.
4. Elimine el registro de la tabla de mensajes después de completar la tarea.
3Interfaz de publicación de cursos
3.1 Definición de interfaz, publicar cursos de acuerdo con la identificación del curso
De acuerdo con el esquema de control de transacciones distribuidas de publicación de cursos, la operación de publicación de cursos primero escribe información de publicación de cursos en la tabla de publicación de cursos a través de transacciones locales e inserta un mensaje en la tabla de mensajes. La interfaz de publicación de cursos definida aquí debe realizar esta función.
Defina la interfaz de publicación del curso en el proyecto de interfaz de administración de contenido.
/**
* @description 课程预览,发布
* @author Mr.M
* @date 2022/9/16 14:48
* @version 1.0
*/
@Api(value = "课程预览发布接口",tags = "课程预览发布接口")
@Controller
public class CoursePublishController {
...
@ApiOperation("课程发布")
@ResponseBody
@PostMapping ("/coursepublish/{courseId}")
public void coursepublish(@PathVariable("courseId") Long courseId){
}3.3 Desarrollo de la interfaz
3.3.1 Crear tabla de mensajes y tabla de historial de mensajes
1. Cree la tabla de mensajes mq_message y la tabla de mensajes del historial de mensajes en la base de datos de administración de contenido (la tabla del historial almacena los mensajes completados).
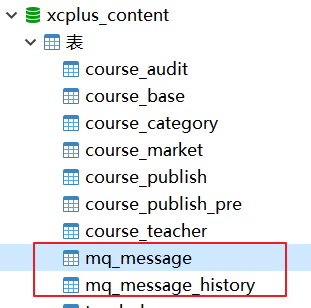
La estructura de la tabla de mensajes es la siguiente:

2. Genere la tabla de mensajes mq_message, la interfaz po y mapper de la tabla de publicación de cursos Course_Publish
Más adelante se desarrollará un componente general de procesamiento de mensajes , por lo que no se generará ningún código aquí.
3.3.2 Proceso de negocio
1. Inserte un registro en la tabla de publicación del curso Course_publish. El registro proviene de la tabla de prepublicación del curso. Si existe, se actualizará. El estado de publicación es: publicado.
2. Actualice el estado de publicación de este curso en Course_base: Published
3. Elimine el registro correspondiente en la tabla de prelanzamiento del curso .
4. Inserte un mensaje en la tabla de mensajes mq_message , el tipo de mensaje es: publicación_curso, es decir, el mensaje es para procesar la tarea de publicación del curso, "información comercial asociada 1" es la identificación del curso.
5. El mensaje insertado es una tarea de publicación del curso, que almacenará la información del caché del curso en Redis, almacenará la información del índice del curso en Elasticsearch, estatizará la página de vista previa del curso html y la almacenará en el sistema de archivos minIO.
restricción:
1. La revisión del curso solo se puede publicar después de aprobar la revisión.
2. Esta institución solo puede publicar cursos de esta institución.
3.3.3 Implementación comercial , publicar cursos de acuerdo con la identificación del curso y la identificación de la institución
CoursePublishServiceImpl
/**
* @description 课程发布接口
* @param companyId 机构id
* @param courseId 课程id
*/
@Transactional
@Override
public void publish(Long companyId, Long courseId) {
//约束校验
//查询课程预发布表
CoursePublishPre coursePublishPre = coursePublishPreMapper.selectById(courseId);
if(coursePublishPre == null){
XueChengPlusException.cast("请先提交课程审核,审核通过才可以发布");
}
//本机构只允许提交本机构的课程
if(!coursePublishPre.getCompanyId().equals(companyId)){
XueChengPlusException.cast("不允许提交其它机构的课程。");
}
//课程审核状态
String auditStatus = coursePublishPre.getStatus();
//审核通过方可发布
if(!"202004".equals(auditStatus)){
XueChengPlusException.cast("操作失败,课程审核通过方可发布。");
}
//保存课程发布信息
saveCoursePublish(courseId);
//保存消息表
saveCoursePublishMessage(courseId);
//删除课程预发布表对应记录
coursePublishPreMapper.deleteById(courseId);
}
/**
* @description 保存课程发布信息
* @param courseId 课程id
*/
private void saveCoursePublish(Long courseId){
//整合课程发布信息
//查询课程预发布表
CoursePublishPre coursePublishPre = coursePublishPreMapper.selectById(courseId);
if(coursePublishPre == null){
XueChengPlusException.cast("课程预发布数据为空");
}
CoursePublish coursePublish = new CoursePublish();
//拷贝到课程发布对象
BeanUtils.copyProperties(coursePublishPre,coursePublish);
coursePublish.setStatus("203002");
CoursePublish coursePublishUpdate = coursePublishMapper.selectById(courseId);
if(coursePublishUpdate == null){
coursePublishMapper.insert(coursePublish);
}else{
coursePublishMapper.updateById(coursePublish);
}
//更新课程基本表的发布状态
CourseBase courseBase = courseBaseMapper.selectById(courseId);
courseBase.setStatus("203002");
courseBaseMapper.updateById(courseBase);
}
/**
* @description 保存消息表记录
* @param courseId 课程id
*/
private void saveCoursePublishMessage(Long courseId) {
//这里是直接注入service,不用远程调用,因为消息sdk是个通用的组件,不是服务
//消息类型为:course_publish,即该消息是处理课程发布任务的;“关联业务信息1”是课程id。
MqMessage mqMessage = mqMessageService.addMessage("course_publish"
, String.valueOf(courseId), null, null);
if (mqMessage == null) {
XueChengPlusException.cast(CommonError.UNKOWN_ERROR);
}
}
}El módulo de mensajes agrega servicios de mensajes:
@Override public MqMessage addMessage(String messageType, String businessKey1, String businessKey2, String businessKey3) { MqMessage mqMessage = new MqMessage(); mqMessage.setMessageType(messageType); mqMessage.setBusinessKey1(businessKey1); mqMessage.setBusinessKey2(businessKey2); mqMessage.setBusinessKey3(businessKey3); int insert = mqMessageMapper.insert(mqMessage); if(insert>0){ return mqMessage; }else{ return null; } }
3.3.3 Interfaz perfecta
@ApiOperation("课程发布")
@ResponseBody
@PostMapping ("/coursepublish/{courseId}")
public void coursepublish(@PathVariable("courseId") Long courseId){
//机构id先用假数据
Long companyId = 1232141425L;
coursePublishService.publish(companyId,courseId);
}3.4 Pruebas
Primero use el método httpclient para probar:
### 课程发布
POST {
{content_host}}/content/coursepublish/2Pruebe las restricciones primero:
1. Realice una prueba de liberación del curso cuando no se envíe la revisión.
2. Publicar cuando el curso no esté aprobado.
Prueba de proceso normal:
1. Enviar el curso de repaso
2. Modifique manualmente el estado de revisión de la tabla previa al lanzamiento del curso y la información básica del curso para aprobar la revisión.
3. Ejecución del lanzamiento del curso
4. Verifique si los registros de la tabla de publicación del curso son normales, los registros de la tabla de publicación previa del curso se han eliminado y el estado de publicación de la tabla de información básica del curso y la tabla de publicación del curso están "publicados".
Use el método de depuración conjunta de front-end y back-end para probar.
4 [Módulo de mensajes] SDK de procesamiento de mensajes
4.1 Análisis
Después de ejecutar la operación de publicación del curso, es necesario escanear los registros de la tabla de mensajes.Las operaciones relacionadas con el procesamiento de mensajes son:
1. Agregar tabla de mensajes
2. Escanee la tabla de mensajes.
3. Actualice la tabla de mensajes.
4. Elimine la tabla de mensajes.

4.1.1 ¿Por qué extraer el módulo de mensajes?
Dado que cada servicio utiliza el mismo conjunto de tablas de mensajes , la extracción del módulo de mensajes puede mejorar la reutilización del código.
analizar
Usar la tabla de mensajes en cada negocio para lograr la consistencia de la transacción final es la misma solución :
Si se implementa en cada lugar un conjunto de lógica para el escaneo de tiempo y el procesamiento de la tabla de mensajes, básicamente se repetirá, y la reutilización del software será demasiado baja y el costo será demasiado alto.
¿Cómo resolver este problema?
Para resolver este problema, es concebible convertir la lógica relacionada con el procesamiento de mensajes en un componente de código común .
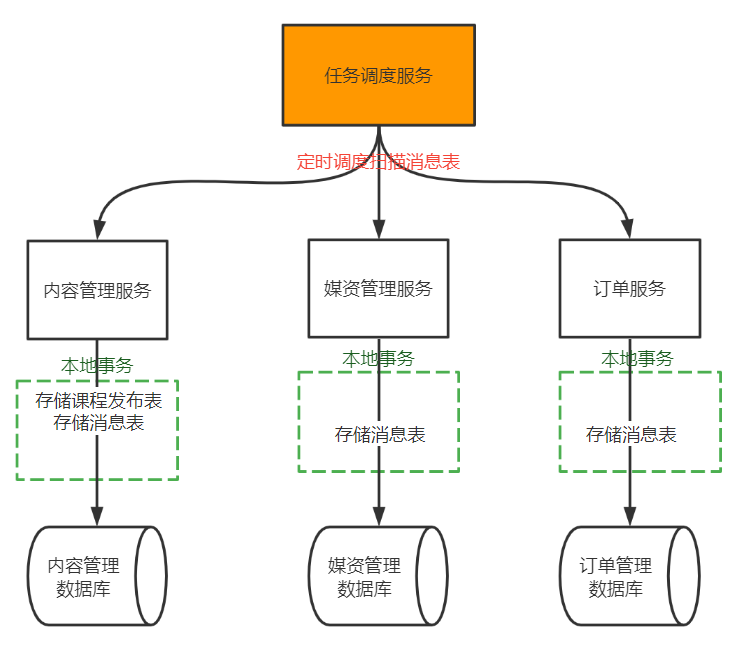
4.1.2 ¿Por qué el módulo de mensajes es un componente de código general en lugar de un servicio general?
Porque no solo es una función independiente, sino que también conecta múltiples bases de datos relacionadas con el servicio.
analizar:
Un servicio común es completar una función independiente común y proporcionar una interfaz de red independiente, como: el servicio de sistema de archivos en el proyecto, que proporciona servicios de almacenamiento distribuido para archivos.
El componente de código también cumple una función independiente común, y generalmente proporciona una API para uso de sistemas externos , como: fastjson, Apache commons toolkit, etc.
Si el procesamiento de mensajes se convierte en un servicio general, el servicio debe conectarse a varias bases de datos , ya que necesita escanear la tabla de mensajes en la base de datos del microservicio y proporcionar una interfaz de red para comunicarse con el microservicio, que solo se desarrolla para las necesidades actuales. el costo es un poco alto.
Si el procesamiento de mensajes se convierte en un kit de herramientas SDK, en comparación con el servicio general, no solo puede resolver el requisito de generalizar el procesamiento de mensajes, sino también reducir el costo.
Por lo tanto, este proyecto determina que el procesamiento relacionado con la tabla de mensajes se convertirá en un componente SDK para uso de varios microservicios, como se muestra en la siguiente figura:
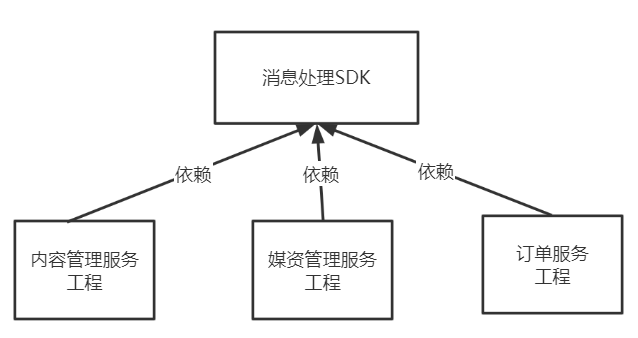
SDK generalmente se refiere a un kit de desarrollo de software. Es la abreviatura de Software Development Kit.
A continuación se describe el contenido de diseño del SDK de mensajes:
4.1.3 SDK no necesita proporcionar lógica para ejecutar tareas
No, use el campo "tipo de mensaje" para distinguir diferentes tareas y use "bussiness_key" para almacenar parámetros.
Tome la tarea de publicación del curso como ejemplo. La ejecución de la tarea de publicación del curso es sincronizar datos con redis, la biblioteca de índices, etc. La lógica de ejecución de otras tareas es diferente, por lo que la tarea de ejecución no necesita implementar la lógica de la tarea en el sdk Solo necesita proporcionar un método abstracto para ser controlado por el Ejecute la tarea específica para lograrlo.
4.1.4 ¿Cómo asegurar la idempotencia de las tareas?
Una vez completada la ejecución de la tarea, el estado del mensaje se establece en "Completado", se elimina de la tabla de mensajes y se almacena en la tabla de mensajes históricos. Si el estado del mensaje está completo o no existe en la tabla de mensajes, no necesita ser ejecutado.
Revisión: en el capítulo de procesamiento de video, el esquema de idempotencia del procesamiento de video es un bloqueo optimista. Habilitar el procesamiento de tareas es modificar el estado de la tarea a "procesamiento" .
Revisión: Cómo garantizar la idempotencia de la tarea
1) Restricciones de la base de datos , tales como: índice único, clave principal. La misma clave principal no se puede insertar correctamente dos veces.
2) Bloqueo optimista (usado). Agregue un campo de versión a la tabla de la base de datos y juzgue si es igual a una determinada versión al actualizar. Por ejemplo, cuando se envía repetidamente, se considera que la base de datos no se enviará si descubre que la versión ha cambiado.
3) Número de serie único de Redis . La clave Redis es la identificación de la tarea y el valor es un uuid serializado aleatorio. Genere un número de serie único antes de la solicitud, lleve el número de serie a la solicitud y registre el número de serie en redis durante la ejecución, lo que indica que la solicitud con este número de serie se ha ejecutado. Si se ejecuta nuevamente el mismo número de serie, significa ejecución repetida.
4.1.5 ¿Cómo asegurar que las tareas no se repitan?
Además de asegurar la idempotencia de las tareas, la programación de tareas utiliza la transmisión de fragmentos para obtener tareas de acuerdo con los parámetros de los fragmentos, y la estrategia de programación de bloqueo es descartar tareas.
Adopte el mismo esquema que el capítulo anterior de procesamiento de video:
https://blog.csdn.net/qq_40991313/article/details/129766117
Nota: Esta es una tarea de sincronización de información . Incluso si la tarea se ejecuta repetidamente, no importa , no hay pérdida, y el método de apropiación de la tarea ya no se usa para garantizar que la tarea no se ejecute repetidamente.
4.1.6 ¿Cómo prevenir la ejecución repetida de tareas pequeñas en el escenario?
Todavía es una idea de bloqueo optimista (el índice único de la base de datos de bloqueo distribuida), y los pequeños campos de estado de tareas de cada etapa están diseñados en la tabla de mensajes .
Otro problema es asegurar la idempotencia de la tarea según exista el registro de la tabla de mensajes o el estado de la tarea en la tabla de mensajes, si una tarea tiene varias tareas pequeñas, por ejemplo: la tarea de publicación del curso necesita realizar tres operaciones de sincronización: almacenar el curso para redis, almacene cursos en la biblioteca de índice y almacene páginas de cursos en el sistema de archivos. Si una de las pequeñas tareas ya se ha completado, no se debe repetir . ¿Cómo debería diseñarse aquí?
Utilice tareas pequeñas como diferentes etapas de la tarea y diseñe el estado de la etapa en la tabla de mensajes.
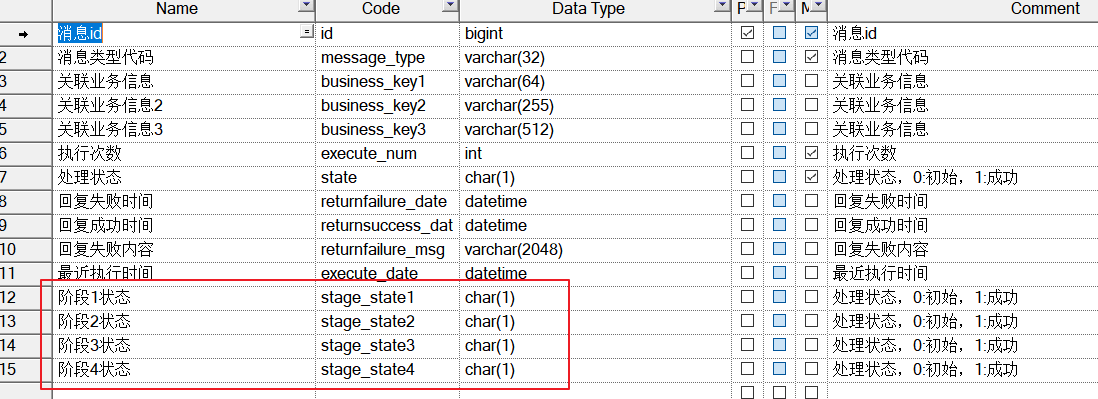
Cada vez que se completa una etapa, la marca de finalización se marca en el campo de estado de la etapa correspondiente. Incluso si la tarea grande no se completa y luego se vuelve a ejecutar, si se completa la tarea de la etapa pequeña, la tarea de una etapa pequeña no se completará. repetido.
4.2 Realización del servicio de mensajes
4.2.0 Inicializar el módulo sdk de mensajes
1. Cree una tabla de mensajes y una tabla de historial de mensajes en la base de datos de administración de contenido
2. Copie xuecheng-plus-message-sdk en los materiales del curso en el directorio del proyecto, como se muestra a continuación:
4.2.1 Escaneo y finalización de mensajes, consulta y finalización de pequeñas tareas de etapa
En resumen, además de la interfaz básica de agregar, eliminar, modificar y verificar la tabla de mensajes, el SDK de mensajes también tiene las siguientes funciones de interfaz:
package com.xuecheng.messagesdk.service;
/**
* <p>
* 服务类
* </p>
*/
public interface MqMessageService extends IService<MqMessage> {
/**
* @description 扫描消息表记录,采用与扫描视频处理表相同的思路
* @param shardIndex xxl-job执行器分片序号
* @param shardTotal 分片总数
* @param count 扫描记录数
* @return java.util.List 消息记录
*/
public List<MqMessage> getMessageList(int shardIndex, int shardTotal, String messageType,int count);
/**
* @description 完成任务
* @param id 消息id
* @return int 更新成功:1
*/
public int completed(long id);
/**
* @description 完成阶段任务
* @param id 消息id
* @return int 更新成功:1
*/
public int completedStageOne(long id);
public int completedStageTwo(long id);
public int completedStageThree(long id);
public int completedStageFour(long id);
/**
* @description 查询阶段状态
* @param id
* @return int
*/
public int getStageOne(long id);
public int getStageTwo(long id);
public int getStageThree(long id);
public int getStageFour(long id);
}Clase de implementación:
@Slf4j @Service public class MqMessageServiceImpl extends ServiceImpl<MqMessageMapper, MqMessage> implements MqMessageService { @Autowired MqMessageMapper mqMessageMapper; @Autowired MqMessageHistoryMapper mqMessageHistoryMapper; @Override public List<MqMessage> getMessageList(int shardIndex, int shardTotal, String messageType,int count) { return mqMessageMapper.selectListByShardIndex(shardTotal,shardIndex,messageType,count); } @Override public MqMessage addMessage(String messageType, String businessKey1, String businessKey2, String businessKey3) { MqMessage mqMessage = new MqMessage(); mqMessage.setMessageType(messageType); mqMessage.setBusinessKey1(businessKey1); mqMessage.setBusinessKey2(businessKey2); mqMessage.setBusinessKey3(businessKey3); int insert = mqMessageMapper.insert(mqMessage); if(insert>0){ return mqMessage; }else{ return null; } } @Transactional @Override public int completed(long id) { MqMessage mqMessage = new MqMessage(); //完成任务 mqMessage.setState("1"); int update = mqMessageMapper.update(mqMessage, new LambdaQueryWrapper<MqMessage>().eq(MqMessage::getId, id)); if(update>0){ mqMessage = mqMessageMapper.selectById(id); //添加到历史表 MqMessageHistory mqMessageHistory = new MqMessageHistory(); BeanUtils.copyProperties(mqMessage,mqMessageHistory); mqMessageHistoryMapper.insert(mqMessageHistory); //删除消息表 mqMessageMapper.deleteById(id); return 1; } return 0; } @Override public int completedStageOne(long id) { MqMessage mqMessage = new MqMessage(); //完成阶段1任务 mqMessage.setStageState1("1"); return mqMessageMapper.update(mqMessage,new LambdaQueryWrapper<MqMessage>().eq(MqMessage::getId,id)); } @Override public int completedStageTwo(long id) { MqMessage mqMessage = new MqMessage(); //完成阶段2任务 mqMessage.setStageState2("1"); return mqMessageMapper.update(mqMessage,new LambdaQueryWrapper<MqMessage>().eq(MqMessage::getId,id)); } @Override public int completedStageThree(long id) { MqMessage mqMessage = new MqMessage(); //完成阶段3任务 mqMessage.setStageState3("1"); return mqMessageMapper.update(mqMessage,new LambdaQueryWrapper<MqMessage>().eq(MqMessage::getId,id)); } @Override public int completedStageFour(long id) { MqMessage mqMessage = new MqMessage(); //完成阶段4任务 mqMessage.setStageState4("1"); return mqMessageMapper.update(mqMessage,new LambdaQueryWrapper<MqMessage>().eq(MqMessage::getId,id)); } @Override public int getStageOne(long id) { return Integer.parseInt(mqMessageMapper.selectById(id).getStageState1()); } @Override public int getStageTwo(long id) { return Integer.parseInt(mqMessageMapper.selectById(id).getStageState2()); } @Override public int getStageThree(long id) { return Integer.parseInt(mqMessageMapper.selectById(id).getStageState3()); } @Override public int getStageFour(long id) { return Integer.parseInt(mqMessageMapper.selectById(id).getStageState4()); } }Dao:
public interface MqMessageMapper extends BaseMapper<MqMessage> { @Select("SELECT t.* FROM mq_message t WHERE t.id % #{shardTotal} = #{shardindex} and t.state='0' and t.message_type=#{messageType} limit #{count}") List<MqMessage> selectListByShardIndex(@Param("shardTotal") int shardTotal, @Param("shardindex") int shardindex, @Param("messageType") String messageType,@Param("count") int count); }
4.2.2 Clase abstracta de procesamiento de tareas para facilitar la herencia de clases de tareas
El SDK de mensajes proporciona una clase abstracta para el procesamiento de mensajes Esta clase abstracta es para que el usuario la herede y la use, de la siguiente manera:
package com.xuecheng.messagesdk.service;
/**
* @description 消息处理抽象类
*/
@Slf4j
@Data
public abstract class MessageProcessAbstract {
@Autowired
MqMessageService mqMessageService;
/**
* @param mqMessage 执行任务内容
* @return boolean true:处理成功,false处理失败
* @description 任务处理
* @author Mr.M
* @date 2022/9/21 19:47
*/
public abstract boolean execute(MqMessage mqMessage);
/**
* @description 扫描消息表多线程执行任务
* @param shardIndex 分片序号
* @param shardTotal 分片总数
* @param messageType 消息类型
* @param count 一次取出任务总数
* @param timeout 预估任务执行时间,到此时间如果任务还没有结束则强制结束 单位秒
* @return void
* @author Mr.M
* @date 2022/9/21 20:35
*/
public void process(int shardIndex, int shardTotal, String messageType,int count,long timeout) {
try {
//扫描消息表获取任务清单
List<MqMessage> messageList = mqMessageService.getMessageList(shardIndex, shardTotal,messageType, count);
//任务个数
int size = messageList.size();
log.debug("取出待处理消息"+size+"条");
if(size<=0){
return ;
}
//创建线程池
ExecutorService threadPool = Executors.newFixedThreadPool(size);
//计数器
CountDownLatch countDownLatch = new CountDownLatch(size);
messageList.forEach(message -> {
threadPool.execute(() -> {
log.debug("开始任务:{}",message);
//处理任务
try {
boolean result = execute(message);
if(result){
log.debug("任务执行成功:{})",message);
//更新任务状态,删除消息表记录,添加到历史表
int completed = mqMessageService.completed(message.getId());
if (completed>0){
log.debug("任务执行成功:{}",message);
}else{
log.debug("任务执行失败:{}",message);
}
}
} catch (Exception e) {
e.printStackTrace();
log.debug("任务出现异常:{},任务:{}",e.getMessage(),message);
}
//计数
countDownLatch.countDown();
log.debug("结束任务:{}",message);
});
});
//等待,给一个充裕的超时时间,防止无限等待,到达超时时间还没有处理完成则结束任务
countDownLatch.await(timeout,TimeUnit.SECONDS);
System.out.println("结束....");
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}4.3 xxl-job integra el SDK de mensajes para programar la tarea de publicar cursos
4.3.1 Preparación del entorno, importación de dependencias + adición de una tabla de mensajes de tipo "publicar curso"
1. Crear una tabla de mensajes y una tabla de historial de mensajes en la base de datos de administración de contenido (completado)
2. Copie xuecheng-plus-message-sdk en los materiales del curso en el directorio del proyecto, como se muestra a continuación:

3. Agregar dependencias SDK al proyecto de servicio de administración de contenido
<dependency>
<groupId>com.xuecheng</groupId>
<artifactId>xuecheng-plus-message-sdk</artifactId>
<version>0.0.1-SNAPSHOT</version>
</dependency>4. Vuelva al método de publicación del curso y agregue una tabla de mensajes:
@Transactional
@Override
public void publish(Long companyId, Long courseId) {
。。。
//保存消息表
saveCoursePublishMessage(courseId);
。。。
}
/**
* @description 保存消息表记录
* @param courseId 课程id
*/
private void saveCoursePublishMessage(Long courseId){
//消息类型为:course_publish,即该消息是处理课程发布任务的;“关联业务信息1”是课程id。
MqMessage mqMessage = mqMessageService.addMessage("course_publish", String.valueOf(courseId), null, null);
if(mqMessage==null){
XueChengPlusException.cast(CommonError.UNKOWN_ERROR);
}
}prueba:
Publique un curso y observe si la tabla de mensajes agrega mensajes normalmente.
Debe modificar manualmente el estado de revisión del curso a Aprobado y ejecutar la operación de publicación.Después de la publicación, puede modificar el estado de publicación para retirarlo del estante y volver a publicarlo para realizar pruebas.
4.3.2 [Módulo de contenido] Clase de tarea de publicación de cursos
Flujo de tareas:
- La clase de tarea implementa la clase MessageProcessAbstract en el SDK
- Establezca la entrada de programación de tareas y llame al método de la clase abstracta para ejecutar la tarea. Consulte la lista de tareas, configure el contador para evitar una espera infinita y recorra el subproceso abierto para ejecutar el método de ejecución reescrito a continuación.
- Anule el método de ejecución:
- Obtener información comercial relacionada con el mensaje
- Almacenar información de caché de cursos en Redis
- Almacene la información del índice del curso en Elasticsearch
- Solicite el sistema de archivos de distribución minIO para almacenar páginas estáticas del curso (es decir, páginas html)
package com.xuecheng.content.service.jobhandler;
@Slf4j
@Component
public class CoursePublishTask extends MessageProcessAbstract {
//任务调度入口
@XxlJob("CoursePublishJobHandler")
public void coursePublishJobHandler() throws Exception {
// 分片参数
int shardIndex = XxlJobHelper.getShardIndex();//执行器的序号,从0开始
int shardTotal = XxlJobHelper.getShardTotal();//执行器总数
//调用抽象类的方法执行任务。查询任务列表、设置计数器防止无限等待,遍历开启线程执行下面重写的execute方法
process(shardIndex,shardTotal, "course_publish",30,60);
}
//课程发布任务处理
@Override
public boolean execute(MqMessage mqMessage) {
//获取消息相关的业务信息
String businessKey1 = mqMessage.getBusinessKey1();
long courseId = Integer.parseInt(businessKey1);
//课程静态化
generateCourseHtml(mqMessage,courseId);
//课程索引
saveCourseIndex(mqMessage,courseId);
//课程缓存
saveCourseCache(mqMessage,courseId);
return true;
}
//生成课程静态化页面并上传至文件系统
public void generateCourseHtml(MqMessage mqMessage,long courseId){
log.debug("开始进行课程静态化,课程id:{}",courseId);
//消息id
Long id = mqMessage.getId();
//消息处理的service
MqMessageService mqMessageService = this.getMqMessageService();
//消息幂等性处理
int stageOne = mqMessageService.getStageOne(id);
if(stageOne >0){
log.debug("课程静态化已处理直接返回,课程id:{}",courseId);
return ;
}
try {
TimeUnit.SECONDS.sleep(10);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
//保存第一阶段状态
mqMessageService.completedStageOne(id);
}
//TODO:将课程信息缓存至redis
public void saveCourseCache(MqMessage mqMessage,long courseId){
log.debug("将课程信息缓存至redis,课程id:{}",courseId);
try {
TimeUnit.SECONDS.sleep(2);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
//TODO:保存课程索引信息
public void saveCourseIndex(MqMessage mqMessage,long courseId){
log.debug("保存课程索引信息,课程id:{}",courseId);
try {
TimeUnit.SECONDS.sleep(2);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
}4.3.3 El centro de programación de trabajos xxl inicia el ejecutor y las tareas, y las ejecuta cada 10 segundos
1. Primero agregue la dependencia xxl-job en el proyecto de servicio de administración de contenido
<dependency>
<groupId>com.xuxueli</groupId>
<artifactId>xxl-job-core</artifactId>
</dependency>2. Configurar el ejecutor
Configurar en content-service-dev.yaml en nacos
xxl:
job:
admin:
addresses: http://192.168.101.65:8088/xxl-job-admin
executor:
appname: coursepublish-job
address:
ip:
port: 8999
logpath: /data/applogs/xxl-job/jobhandler
logretentiondays: 30
accessToken: default_token3. Copie una clase de configuración XxlJobConfig del proyecto de capa de servicio de administración de activos de medios al proyecto de servicio de administración de contenido.
Agregar ejecutor en la consola xxl-job-admin

3. Escribir entrada de programación de tareas
@Slf4j
@Component
public class CoursePublishTask extends MessageProcessAbstract {
//任务调度入口
@XxlJob("CoursePublishJobHandler")
public void coursePublishJobHandler() throws Exception {
// 分片参数
int shardIndex = XxlJobHelper.getShardIndex();
int shardTotal = XxlJobHelper.getShardTotal();
log.debug("shardIndex="+shardIndex+",shardTotal="+shardTotal);
//参数:分片序号、分片总数、消息类型、一次最多取到的任务数量、一次任务调度执行的超时时间
process(shardIndex,shardTotal,"course_publish",30,60);
}
....4. Agregar tareas a xxl-job

La configuración de la tarea es la siguiente:
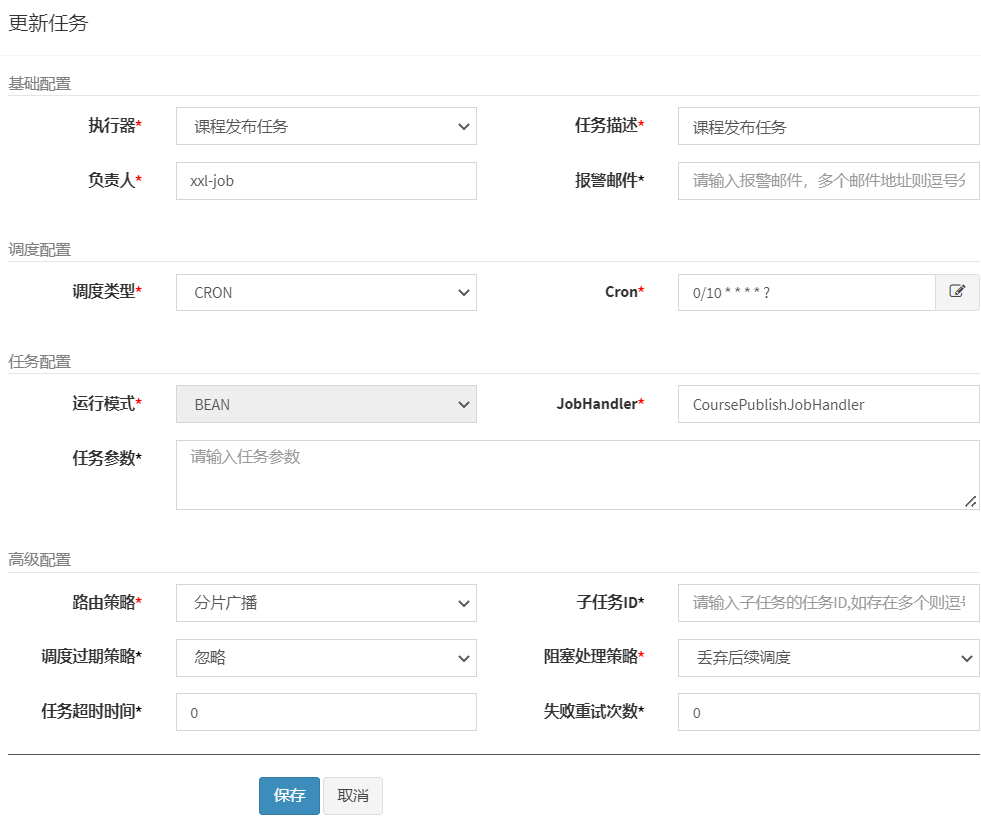
En este punto, el desarrollo y la integración del SDK están completos, y el siguiente paso es agregar tareas como páginas estáticas, almacenamiento en caché del curso e indexación del curso después de que se publique el curso.
4.3.4 Pruebas
Agregue un mensaje de publicación de curso en la tabla de mensajes, el tipo de mensaje es Course_publish y business_key1 es la ID del curso publicado.
1. Pruebe si se puede programar y ejecutar con normalidad.
2. Prueba de idempotencia de la tarea
Rompa el punto en saveCourseCache(mqMessage,courseId); espere a que llegue la ejecución aquí y observe que la marca que se esperaba marcar como 1 se completa en la primera fase de la base de datos.
Termina el proceso, reinícialo y observa que ya no se espera ejecutar las tareas de la primera etapa.
3. Una vez completada la ejecución de la tarea, elimine el registro en la tabla de mensajes, insértelo en la tabla de historial y el campo de estado es 1
5 El motor de plantillas implementa páginas estáticas (la página de vista previa estática del curso se carga en MinIO)
5.1 ¿ Qué es la página estática?
Versión simple: en el pasado, la página se procesaba en una página html después de que se respondía a la solicitud y, después de crearse estáticamente, la página se procesaba y guardaba en el sistema de archivos cuando se creaba o modificaba.
De acuerdo con el proceso de operación de la publicación del curso, después de ejecutar la publicación del curso, la página de información detallada del curso debe estar estática y una página html debe generarse y cargarse en el sistema de archivos .
¿Qué es la página estática?
La función de vista previa del curso utiliza la tecnología del motor de plantilla para completar los datos en la plantilla de página para generar una página html. Este proceso consiste en que cuando el cliente solicita el servidor, el servidor comienza a procesar y generar la página html, y finalmente responde a el navegador La concurrencia de renderizado del lado del servidor es limitada .
La página estática enfatiza que el proceso de generación de páginas html debe ser avanzado, utilizando tecnología de motor de plantillas para generar páginas html con anticipación y solicitando páginas html directamente cuando el cliente lo solicite , porque las páginas estáticas pueden usar servidores web de alto rendimiento como nginx. y apache, el alto rendimiento simultáneo.
¿Cuándo puedo usar la tecnología de página estática?
Cuando los datos cambian con poca frecuencia , una vez que se genera una página estática y rara vez cambia durante mucho tiempo, se puede usar la página estática en este momento. Porque si los datos cambian con frecuencia, la página estática debe regenerarse una vez que cambia, lo que genera una gran carga de trabajo para mantener la página estática.
De acuerdo con los requisitos comerciales de la publicación del curso, aunque la información del curso aún se puede modificar después de que se publique el curso, debe ser revisada por el curso y la frecuencia de modificación no es alta, por lo que es adecuado usar una página estática.
5.2 Prueba estática de la página de vista previa del curso Freemarker
Lo siguiente utiliza tecnología de marcador libre para generar estáticamente páginas html para las páginas.
1. Agregar dependencia de marcador libre en el proyecto de servicio de administración de contenido
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-freemarker</artifactId>
</dependency>2. Escriba el método de prueba
Procesos de negocio:
- El objeto de configuración especifica el directorio y la codificación de la plantilla.
- Preparar los datos de la página de vista previa del curso
- El archivo de plantilla se convierte estáticamente en una cadena html, clase de herramienta de plantilla de marcador libre
- Convierta los caracteres html en flujo de entrada, luego convierta el flujo de salida para escribir en el archivo
La clase de herramienta de plantilla de marcador libre convierte las plantillas en cadenas html:
String FreeMarkerTemplateUtils.processTemplateIntoString(Template template, Object model);
package com.xuecheng.content;
/**
* @description freemarker测试
*/
@SpringBootTest
public class FreemarkerTest {
@Autowired
CoursePublishService coursePublishService;
//测试页面静态化
@Test
public void testGenerateHtmlByTemplate() throws IOException, TemplateException {
//Configuration对象指定模板目录和编码
Configuration configuration = new Configuration(Configuration.getVersion());
//加载模板
//选指定模板路径,classpath下templates下
//得到classpath路径
String classpath = this.getClass().getResource("/").getPath();
configuration.setDirectoryForTemplateLoading(new File(classpath + "/templates/"));
//设置字符编码
configuration.setDefaultEncoding("utf-8");
//指定模板文件名称
Template template = configuration.getTemplate("course_template.ftl");
//准备课程预览页数据
CoursePreviewDto coursePreviewInfo = coursePublishService.getCoursePreviewInfo(2L);
Map<String, Object> map = new HashMap<>();
map.put("model", coursePreviewInfo);
//页面静态化,模板文件转html字符串
//参数1:模板,参数2:数据模型
String content = FreeMarkerTemplateUtils.processTemplateIntoString(template, map);
System.out.println(content);
//将静态化内容输出到文件中
InputStream inputStream = IOUtils.toInputStream(content);
//输出流
FileOutputStream outputStream = new FileOutputStream("D:\\develop\\test.html");
IOUtils.copy(inputStream, outputStream);
}
}prueba:
Ejecute el método de prueba y observe si D:\\develop\\test.html se genera correctamente.


5.3 Subir archivo de prueba
5.3.1 Preparación del entorno, dependencia de carga de varios archivos, clase de configuración
Los archivos generados estáticamente deben cargarse en el sistema de archivos distribuido. De acuerdo con la división de responsabilidades de los microservicios, el servicio de administración de activos de medios es responsable de mantener los archivos en el sistema de archivos, por lo que el servicio de administración de contenido debe llamar a la administración de activos de medios. servicio para generar archivos html de forma estática . Como se muestra abajo:
Inevitablemente habrá llamadas remotas entre microservicios. En Spring Cloud, Feign se puede usar para llamadas remotas.
Feign es un cliente http declarativo, dirección oficial: GitHub - OpenFeign/feign: Feign facilita la escritura de clientes java http
Su función es ayudarnos a implementar elegantemente el envío de solicitudes http y resolver los problemas mencionados anteriormente.

A continuación, prepare primero el entorno de desarrollo de Fingir:
1. Agregue dependencias al proyecto de servicio de contenido de administración de contenido:
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-nacos-discovery</artifactId>
</dependency>
<!-- Spring Cloud 微服务远程调用 -->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-openfeign</artifactId>
</dependency>
<dependency>
<groupId>io.github.openfeign</groupId>
<artifactId>feign-httpclient</artifactId>
</dependency>
<!--feign支持Multipart格式传参-->
<dependency>
<groupId>io.github.openfeign.form</groupId>
<artifactId>feign-form</artifactId>
<version>3.8.0</version>
</dependency>
<dependency>
<groupId>io.github.openfeign.form</groupId>
<artifactId>feign-form-spring</artifactId>
<version>3.8.0</version>
</dependency>2. Configurar fusible en feign-dev.yaml de nacos
feign:
#Hystrix类似于Sentinel,用于微服务保护。隔离、熔断、降级等
hystrix:
enabled: true
#断路器
circuitbreaker:
enabled: true
hystrix:
command:
default:
execution:
isolation:
thread:
timeoutInMilliseconds: 30000 #熔断超时时间
ribbon:
ConnectTimeout: 60000 #连接超时时间
ReadTimeout: 60000 #读超时时间
MaxAutoRetries: 0 #重试次数
MaxAutoRetriesNextServer: 1 #切换实例的重试次数3. Introduzca este archivo de configuración tanto en el proyecto de servicio de administración de contenido como en el proyecto de API de administración de contenido.
shared-configs:
- data-id: feign-${spring.profiles.active}.yaml
group: xuecheng-plus-common
refresh: true4. Clase de configuración de carga de archivos múltiples
Configure fingir para admitir Multipart en el proyecto de servicio de administración de contenido y cree MultipartSupportConfig en el paquete de configuración en el proyecto de servicio de contenido.
@Configuration
public class MultipartSupportConfig {
@Autowired
private ObjectFactory<HttpMessageConverters> messageConverters;
@Bean
@Primary//注入相同类型的bean时优先使用
@Scope("prototype")
public Encoder feignEncoder() {
return new SpringFormEncoder(new SpringEncoder(messageConverters));
}
//将file转为Multipart
public static MultipartFile getMultipartFile(File file) {
FileItem item = new DiskFileItemFactory().createItem("file", MediaType.MULTIPART_FORM_DATA_VALUE, true, file.getName());
try (FileInputStream inputStream = new FileInputStream(file);
OutputStream outputStream = item.getOutputStream();) {
IOUtils.copy(inputStream, outputStream);
} catch (Exception e) {
e.printStackTrace();
}
return new CommonsMultipartFile(item);
}
}5.3.2 [Servicio de activos de medios] Agregue el parámetro "nombre de objeto" a la interfaz de carga de múltiples archivos
Ahora debe cargar el archivo estático del curso en minio y almacenarlo por separado en el directorio del curso. El nombre del objeto del archivo es "ID del curso.html", y la interfaz de carga del archivo original debe agregar un parámetro nombre del objeto.
Expanda la interfaz de carga de archivos del servicio de recursos de medios a continuación
El método de carga de MediaFilesController agrega el parámetro objectName:
@ApiOperation("上传图片")
@RequestMapping(value = "/upload/coursefile",consumes = MediaType.MULTIPART_FORM_DATA_VALUE)
public UploadFileResultDto upload(@RequestPart("filedata")MultipartFile filedata,
@RequestParam(value= "objectName",required=false) String objectName) throws IOException {
//准备上传文件的信息
UploadFileParamsDto uploadFileParamsDto = new UploadFileParamsDto();
//原始文件名称
uploadFileParamsDto.setFilename(filedata.getOriginalFilename());
//文件大小
uploadFileParamsDto.setFileSize(filedata.getSize());
//文件类型
uploadFileParamsDto.setFileType("001001");
//创建一个临时文件
File tempFile = File.createTempFile("minio", ".temp");
filedata.transferTo(tempFile);
Long companyId = 1232141425L;
//文件路径
String localFilePath = tempFile.getAbsolutePath();
//调用service上传图片
UploadFileResultDto uploadFileResultDto = mediaFileService.uploadFile(companyId
, uploadFileParamsDto, localFilePath,objectName);
return uploadFileResultDto;
}
}La interfaz de servicio también agrega el parámetro "nombre de objeto":
/**
* 上传文件
* @param companyId 机构id
* @param uploadFileParamsDto 上传文件信息
* @param localFilePath 文件磁盘路径
* @param objectName 对象名
* @return 文件信息
*/
public UploadFileResultDto uploadFile(Long companyId, UploadFileParamsDto uploadFileParamsDto, String localFilePath,String objectName);Modifique el método uploadFile original, si el objectName está vacío, se adoptará el método de ruta del estilo año-mes-día.

//存储到minio中的对象名(带目录)
if(StringUtils.isEmpty(objectName)){
objectName = defaultFolderPath + fileMd5 + extension;
}
// String objectName = defaultFolderPath + fileMd5 + extension;5.3.3 Prueba de llamada remota
Escriba la interfaz de fingir en el servicio de contenido
package com.xuecheng.content.feignclient;
/**
* @description 媒资管理服务远程接口
*/
@FeignClient(value = "media-api",configuration = MultipartSupportConfig.class)
public interface MediaServiceClient {
@RequestMapping(value = "/media/upload/coursefile",consumes = MediaType.MULTIPART_FORM_DATA_VALUE)
String uploadFile(@RequestPart("filedata") MultipartFile upload,@RequestParam(value = "objectName",required=false) String objectName);
}Agregue la anotación @EnableFeignClients a la clase de inicio
@EnableFeignClients(basePackages={"com.xuecheng.content.feignclient"})método de prueba de escritura
package com.xuecheng.content;
/**
* @description 测试使用feign远程上传文件
*/
@SpringBootTest
public class FeignUploadTest {
@Autowired
MediaServiceClient mediaServiceClient;
//远程调用,上传文件
@Test
public void test() {
MultipartFile multipartFile = MultipartSupportConfig.getMultipartFile(new File("D:\\develop\\test.html"));
mediaServiceClient.uploadFile(multipartFile,"course","test.html");
}
}El siguiente paso es probar, iniciar el servicio de activos de medios, ejecutar el método de prueba, cargar el archivo correctamente, ingresar minIO para ver el archivo

Visite: http://192.168.101.65:9000/mediafiles/course/74b386417bb9f3764009dc94068a5e44.html
Compruebe si se puede acceder normalmente.
5.4 Procesamiento de degradación de fusibles Hystrix
5.4.1 Avalancha, fusible, degradación
Las llamadas remotas entre servicios son inevitables en los microservicios . Por ejemplo, el servicio de administración de contenido llama de forma remota a la interfaz de carga de archivos del servicio de recursos multimedia. Cuando el microservicio no se ejecuta con normalidad , no se puede llamar al microservicio con normalidad
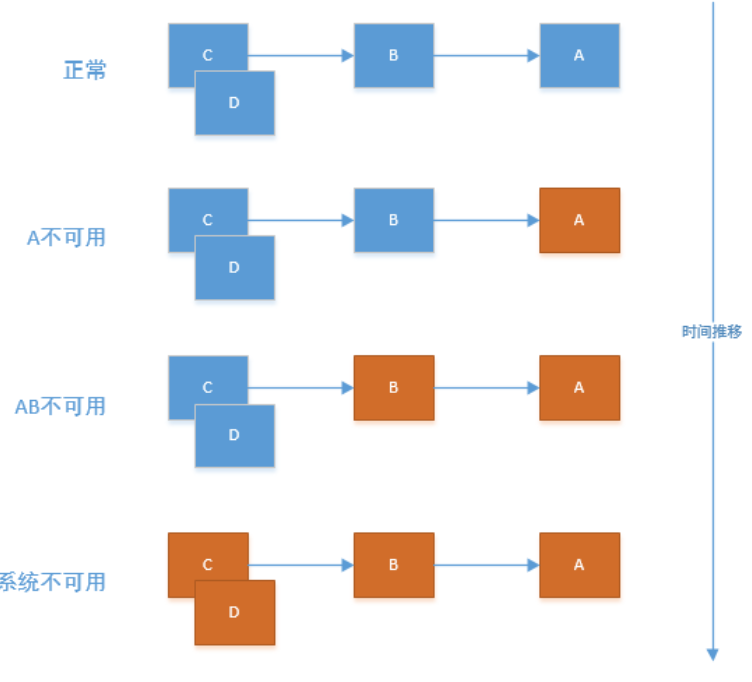
El efecto de avalancha de los microservicios se manifiesta en las llamadas entre servicios. Cuando uno de los servicios no puede proporcionar servicios, otros servicios también pueden morir. Por ejemplo: el servicio B llama al servicio A y el servicio B responde lentamente debido a la excepción del servicio A. Finalmente, B, los servicios como C no están disponibles. Una serie de múltiples servicios causados por un servicio no puede proporcionar servicios, que es el efecto de avalancha de los microservicios, como se muestra en la siguiente figura:
¿Cómo solucionar el efecto avalancha que provocan las excepciones de microservicios?
Se puede resolver fusionando y degradando .
El mismo punto de degradación del fusible es resolver el problema del colapso del sistema de microservicio, pero son dos medios técnicos diferentes y hay una conexión entre los dos.
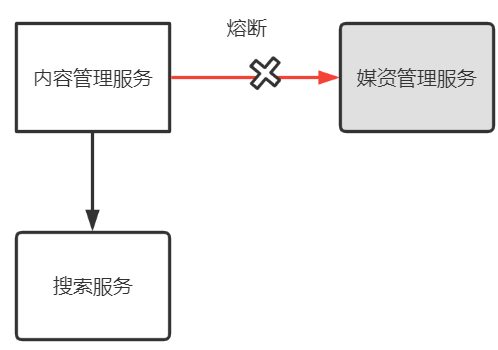
Disyuntor: El servicio aguas abajo llamado activa un disyuntor de manera anormal.
El flujo ascendente llama al flujo descendente. Cuando el servicio descendente es anormal y la interacción con el servicio ascendente se desconecta, es equivalente a un fusible. La anomalía del servicio descendente activa el fusible, para garantizar que el servicio ascendente no se vea afectado.
Degradar:
Cuando la excepción del servicio descendente activa el fusible , el servicio ascendente ya no llama al microservicio anómalo, sino que ejecuta la lógica de procesamiento de degradación Esta lógica de procesamiento de degradación puede ser un método local independiente.
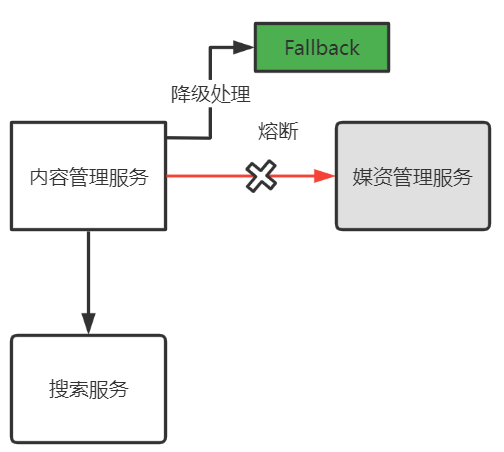
Ambos son para proteger el sistema. La fusión es un medio de proteger el sistema cuando los servicios de bajada son anormales, y la degradación es un método para que los servicios de subida manejen fusión tras fusión.
5.4.2 Procesamiento de degradación de fusibles
El proyecto utiliza el marco Hystrix para implementar el procesamiento de fusión y degradación, que se configura en feign-dev.yaml.
1. Encienda la protección del fusible Fingir
feign:
hystrix:
enabled: true
circuitbreaker:
enabled: true2. Establezca el tiempo de espera del fusible Para evitar que el fusible se active por un tiempo de procesamiento prolongado, también es necesario configurar el tiempo de espera de la solicitud y la conexión, de la siguiente manera:
hystrix:
command:
default:
execution:
isolation:
thread:
timeoutInMilliseconds: 30000 #熔断超时时间
ribbon:
ConnectTimeout: 60000 #连接超时时间
ReadTimeout: 60000 #读超时时间
MaxAutoRetries: 0 #重试次数
MaxAutoRetriesNextServer: 1 #切换实例的重试次数3. Definir la lógica de degradación
Dos métodos:
1) Método 1: respaldo
@FeignClient(value = "media-api",configuration = MultipartSupportConfig.class
,fallback = MediaServiceClientFallback.class)
@RequestMapping("/media")
public interface MediaServiceClient{
...Defina una clase alternativa MediaServiceClientFallback, que implementa la interfaz MediaServiceClient.
El primer método no puede eliminar la excepción lanzada por el fusible y el segundo método puede resolver este problema definiendo MediaServiceClientFallbackFactory.
2) Método 2: fallbackFactory (recomendado, puede eliminar la excepción del fusible)
El segundo método especifica fallbackFactory en FeignClient, de la siguiente manera:
@FeignClient(value = "media-api",configuration = MultipartSupportConfig.class
,fallbackFactory = MediaServiceClientFallbackFactory.class)Defina MediaServiceClientFallbackFactory de la siguiente manera:
@Slf4j
@Component
public class MediaServiceClientFallbackFactory implements FallbackFactory<MediaServiceClient> {
@Override
public MediaServiceClient create(Throwable throwable) {
return new MediaServiceClient(){
@Override
public String uploadFile(MultipartFile upload, String objectName) {
//降级方法
log.debug("调用媒资管理服务上传文件时发生熔断,异常信息:{}",throwable.toString(),throwable);
return null;
}
};
}
}Lógica de procesamiento de degradación:
Se devuelve un objeto nulo y la interfaz de solicitud de servicio ascendente obtiene un valor nulo que indica que se ha realizado el proceso de degradación.
prueba:
Detenga el servicio de administración de activos de medios o cree anomalías artificialmente para observar si se ejecuta la lógica de degradación.
5.4 Curso de desarrollo estático
La página del curso estática y la prueba de carga remota de la página estática pasaron, el siguiente paso es desarrollar la función estática del curso y finalmente usar el SDK de procesamiento de mensajes para programar la ejecución.
5.4.1 Implementación estática
El curso estático incluye dos partes: generar páginas estáticas del curso y cargar páginas estáticas en el sistema de archivos.
Escribir estas dos partes en el servicio publicado por el curso, y finalmente programarlas y ejecutarlas a través de mensajes.
1. Definición de interfaz
/**
* @description 课程静态化
* @param courseId 课程id
* @return File 静态化文件
* @author Mr.M
* @date 2022/9/23 16:59
*/
public File generateCourseHtml(Long courseId);
/**
* @description 上传课程静态化页面
* @param file 静态化文件
* @return void
* @author Mr.M
* @date 2022/9/23 16:59
*/
public void uploadCourseHtml(Long courseId,File file);2. Implementación de la interfaz
Copie el código de prueba estático escrito anteriormente y cargue el código de prueba de archivo estático para usar
@Override
public File generateCourseHtml(Long courseId) {
//静态化文件
File htmlFile = null;
try {
//配置freemarker
Configuration configuration = new Configuration(Configuration.getVersion());
//加载模板
//选指定模板路径,classpath下templates下
//得到classpath路径
String classpath = this.getClass().getResource("/").getPath();
configuration.setDirectoryForTemplateLoading(new File(classpath + "/templates/"));
//设置字符编码
configuration.setDefaultEncoding("utf-8");
//指定模板文件名称
Template template = configuration.getTemplate("course_template.ftl");
//准备数据
CoursePreviewDto coursePreviewInfo = this.getCoursePreviewInfo(courseId);
Map<String, Object> map = new HashMap<>();
map.put("model", coursePreviewInfo);
//静态化
//参数1:模板,参数2:数据模型
String content = FreeMarkerTemplateUtils.processTemplateIntoString(template, map);
// System.out.println(content);
//将静态化内容输出到文件中
InputStream inputStream = IOUtils.toInputStream(content);
//创建静态化文件
htmlFile = File.createTempFile("course",".html");
log.debug("课程静态化,生成静态文件:{}",htmlFile.getAbsolutePath());
//输出流
FileOutputStream outputStream = new FileOutputStream(htmlFile);
IOUtils.copy(inputStream, outputStream);
} catch (Exception e) {
log.error("课程静态化异常:{}",e.toString());
XueChengPlusException.cast("课程静态化异常");
}
return htmlFile;
}
@Override
public void uploadCourseHtml(Long courseId, File file) {
MultipartFile multipartFile = MultipartSupportConfig.getMultipartFile(file);
String course = mediaServiceClient.uploadFile(multipartFile, "course/"+courseId+".html");
if(course==null){
XueChengPlusException.cast("上传静态文件异常");
}
}Mejorar el código de la tarea de publicación de cursos clase CoursePublishTask:
//生成课程静态化页面并上传至文件系统
public void generateCourseHtml(MqMessage mqMessage,long courseId){
log.debug("开始进行课程静态化,课程id:{}",courseId);
//消息id
Long id = mqMessage.getId();
//消息处理的service
MqMessageService mqMessageService = this.getMqMessageService();
//消息幂等性处理
int stageOne = mqMessageService.getStageOne(id);
if(stageOne == 1){
log.debug("课程静态化已处理直接返回,课程id:{}",courseId);
return ;
}
//生成静态化页面
File file = coursePublishService.generateCourseHtml(courseId);
//上传静态化页面
if(file!=null){
coursePublishService.uploadCourseHtml(courseId,file);
}
//保存第一阶段状态
mqMessageService.completedStageOne(id);
}5.4.2 Pruebas
1. Inicie el proyecto de servicio de administración de activos multimedia y de puerta de enlace.
2. Configure FeignClient en la clase de inicio del proyecto API de administración de contenido
@EnableFeignClients(basePackages={"com.xuecheng.content.feignclient"})Referencia fingir-dev.yaml en bootstrap.yml
- data-id: feign-${spring.profiles.active}.yaml
group: xuecheng-plus-common
refresh: true #profiles默认为devInicie el proyecto de interfaz de administración de contenido.
Coloque un punto de interrupción en el método de ejecución de la clase CoursePublishTask.
3. Publique un curso, guarde el procesamiento sin procesar en la tabla de mensajes.
4. Inicie el centro de programación de trabajos xxl, inicie la tarea de publicación del curso y espere la programación programada.

5. Observe el registro de programación de tareas para ver si la tarea se puede procesar normalmente.
6. Ingrese al sistema de archivos después de que se complete el procesamiento y verifique si hay un archivo html con el nombre de la identificación del curso en el depósito de archivos multimedia.
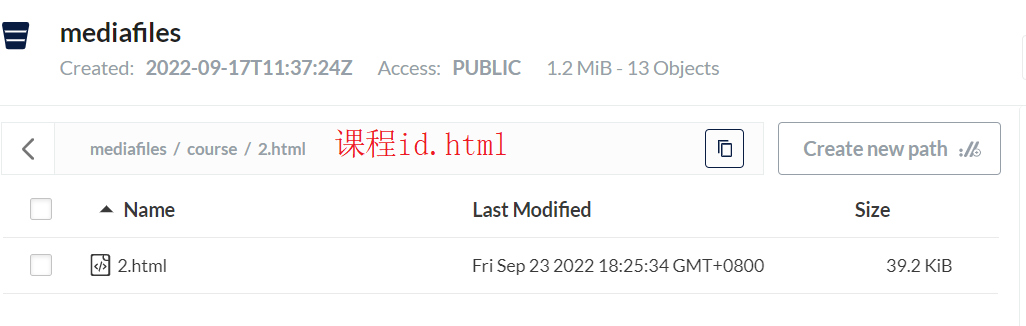
Si no existe, significa que hay un problema con el curso estático y luego verifique cuidadosamente el registro de ejecución para solucionar el problema.
Si existe, significa que el curso es estático y se subió a minio con éxito.
5.4.3 Navegar por la página detallada
Una vez que el curso se ha estatizado con éxito, puede usar un navegador para acceder al archivo html y ver si se puede navegar normalmente. La siguiente figura muestra que se puede navegar normalmente.
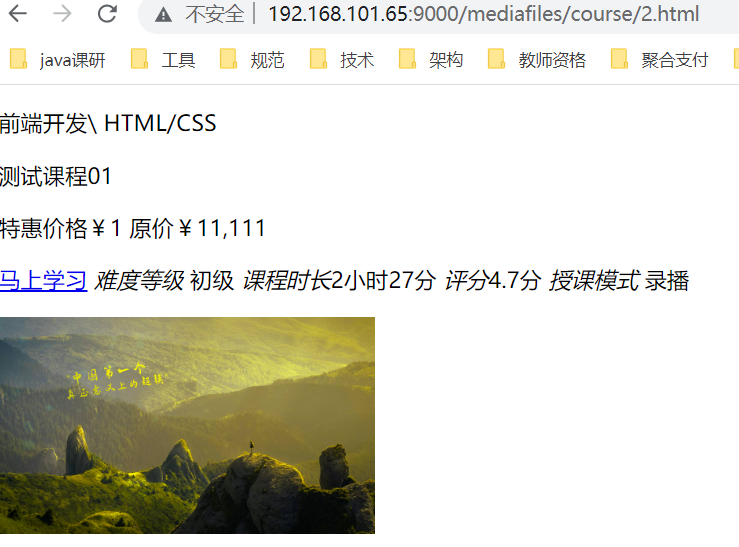
La página aún no tiene estilo, debe configurar el directorio virtual en nginx y configurarlo en www.51xuecheng.cn:
location /course/ {
proxy_pass http://fileserver/mediafiles/course/;
}Cargar archivo de configuración de nginx
Visita: http://www.51xuecheng.cn/course/2.html
2.html es un archivo html que lleva el nombre de la identificación del curso.