Explicación: Este es un proyecto práctico de aprendizaje automático (con datos + código + documentación + explicación en video). Si necesita datos + código + documentación + explicación en video, puede ir directamente al final del artículo para obtenerlo.

1. Antecedentes del proyecto
En 2019, Heidari et al., propusieron Harris Hawk Optimization (HHO), que tiene una fuerte capacidad de búsqueda global y tiene la ventaja de requerir menos parámetros para ajustar.
Este proyecto utiliza el algoritmo de optimización HHO Harris Eagle para encontrar los valores de parámetros óptimos para optimizar el modelo de regresión CATBOOST.
2. Adquisición de datos
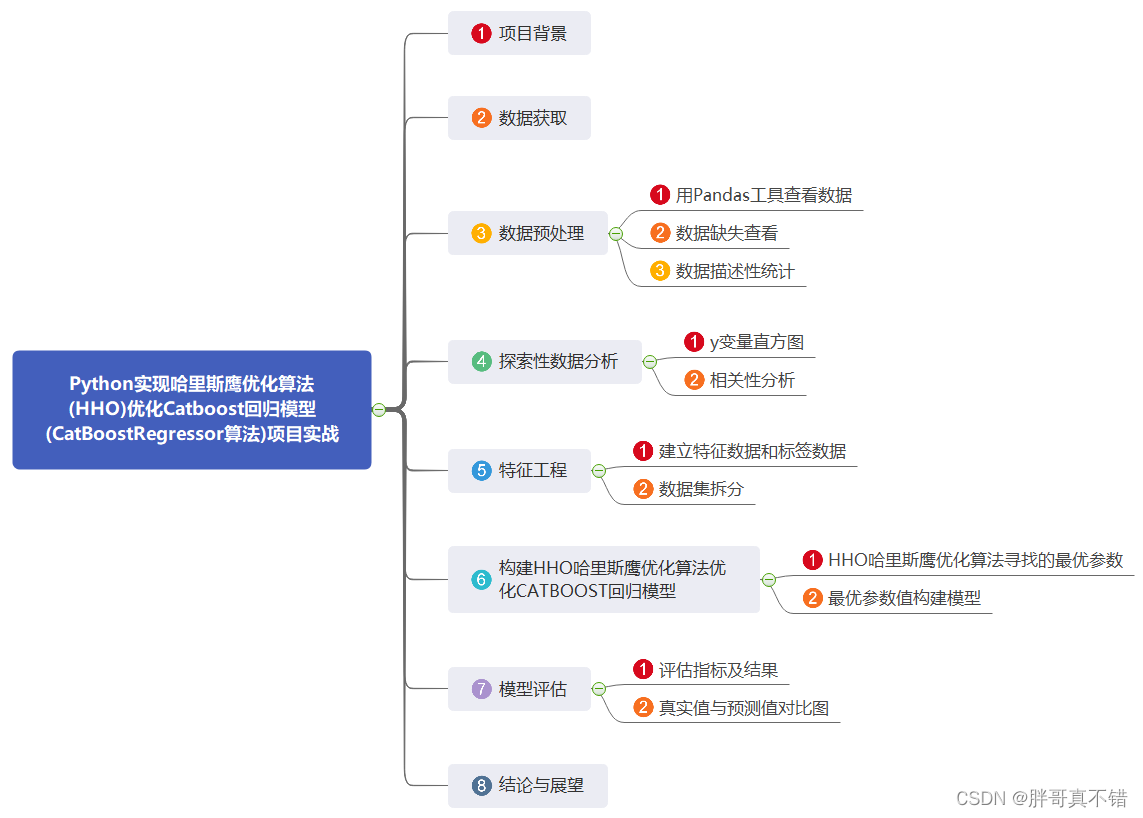
Los datos de modelado para este tiempo provienen de Internet (compilados por el autor de este proyecto), y las estadísticas de los elementos de datos son las siguientes:
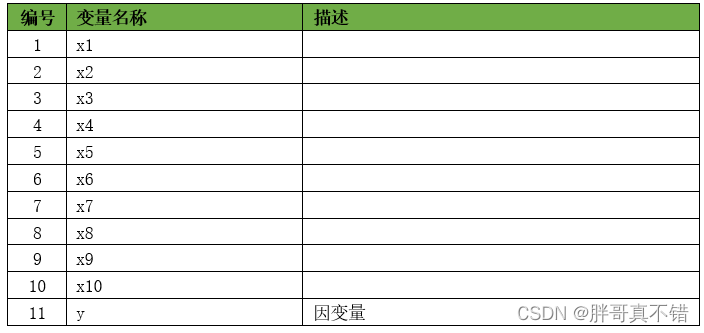
Los detalles de los datos son los siguientes (visualización parcial):
3. Preprocesamiento de datos
3.1 Ver datos con las herramientas de Pandas
Use el método head() de la herramienta Pandas para ver las primeras cinco filas de datos:
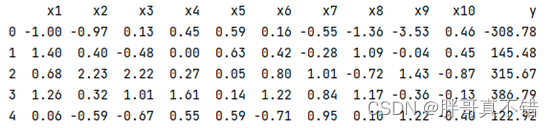
clave:

3.2 Vista de datos faltantes
Use el método info() de la herramienta Pandas para ver la información de los datos:
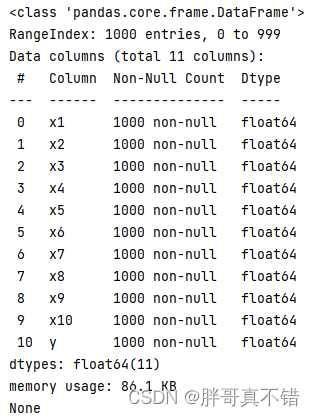
Como se puede ver en la figura anterior, hay un total de 11 variables y no faltan valores en los datos, con un total de 1000 datos.
clave:

3.3 Estadísticas descriptivas de datos
Utilice el método describe() de la herramienta Pandas para ver la media, la desviación estándar, el mínimo, el cuantil y el máximo de los datos.
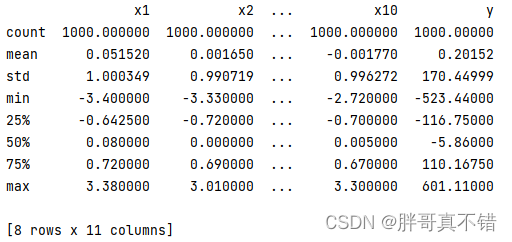
El código clave es el siguiente:

4. Análisis de datos exploratorios
4.1 Histograma de y variables
Utilice el método hist() de la herramienta Matplotlib para dibujar un histograma:
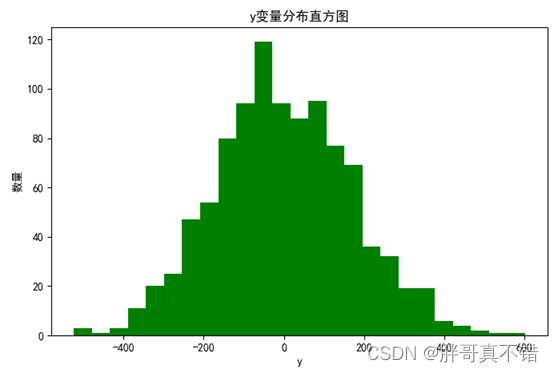
Como puede verse en la figura anterior, la variable y se concentra principalmente entre -400 y 400.
4.2 Análisis de correlación
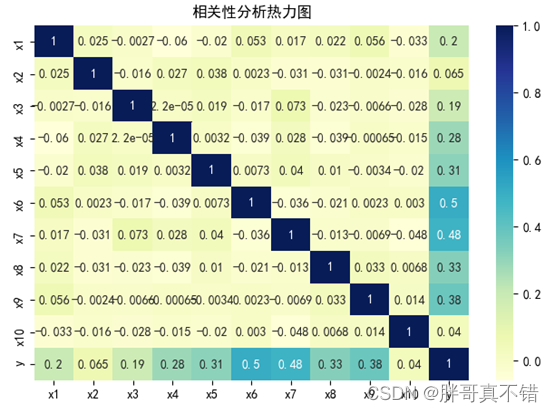
Como se puede ver en la figura anterior, cuanto mayor sea el valor, más fuerte será la correlación.Un valor positivo es una correlación positiva y un valor negativo es una correlación negativa.
5. Ingeniería de características
5.1 Establecer datos de características y datos de etiquetas
El código clave es el siguiente:
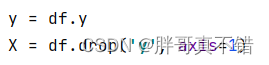
5.2 División de conjuntos de datos
Use el método train_test_split() para dividir de acuerdo con el 80 % del conjunto de entrenamiento y el 20 % del conjunto de prueba. El código clave es el siguiente:
![]()
6. Construya el algoritmo de optimización HHO Harris Eagle para optimizar el modelo de regresión CATBOOST
Utilice principalmente el algoritmo de optimización HHO Harris Eagle para optimizar el algoritmo de regresión CatBoostRegressor para la regresión objetivo.
6.1 Parámetros óptimos buscados por el algoritmo de optimización HHO Harris Eagle
clave:

Procesar datos para cada iteración:
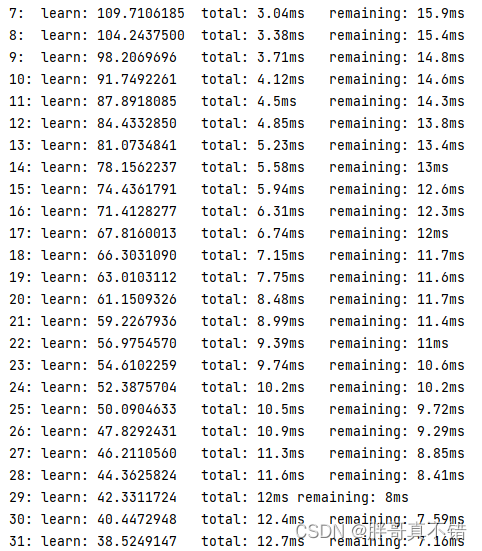
Parámetros óptimos:
| ---------------- El algoritmo de optimización HHO Harris Eagle optimiza el modelo de regresión Catboost - visualización de resultados óptima ----------------- La mejor profundidad es 8 La mejor tasa de aprendizaje es 0.01 |
6.2 Modelo de construcción de valor de parámetro óptimo

7. Evaluación del modelo
7.1 Indicadores y resultados de la evaluación
Los indicadores de evaluación incluyen principalmente valor de varianza explicable, error absoluto medio, error cuadrático medio, valor R cuadrado, etc.
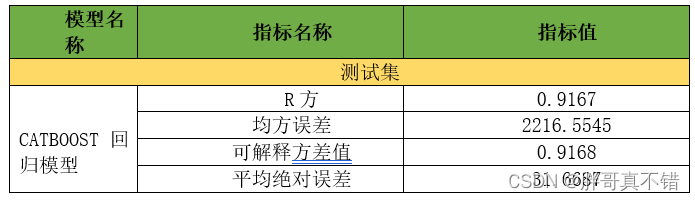
En la tabla anterior se puede ver que el R cuadrado es 0,9167, lo que significa que el modelo funciona bien.
El código clave es el siguiente:

7.2 Cuadro de comparación del valor real y el valor predicho
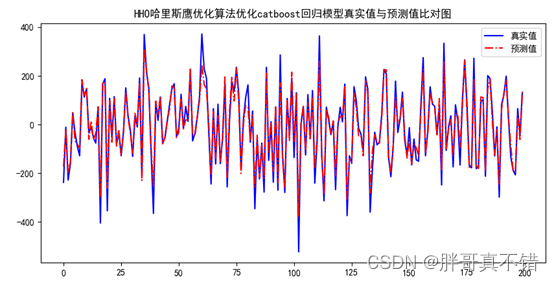
De la figura anterior, se puede ver que las fluctuaciones del valor real y el valor predicho son básicamente las mismas, y el efecto de ajuste del modelo es bueno.
8. Conclusión y perspectiva
En resumen, este artículo utiliza el algoritmo de optimización HHO Harris Eagle para encontrar los valores óptimos de los parámetros del algoritmo de regresión CATBOOST para construir un modelo de regresión, lo que finalmente demuestra que el modelo que propusimos funciona bien. Este modelo se puede utilizar para pronosticar productos cotidianos.
#!/usr/bin/env python
# coding: utf-8
# 定义初始化位置函数
def init_position(lb, ub, N, dim):
X = np.zeros([N, dim], dtype='float') # 位置初始化为0
for i in range(N): # 循环
for d in range(dim): # 循环
X[i, d] = lb[0, d] + (ub[0, d] - lb[0, d]) * rand() # 位置随机初始化
return X # 返回位置数据
# ******************************************************************************
# 本次机器学习项目实战所需的资料,项目资源如下:
# 项目说明:
# 链接:https://pan.baidu.com/s/1c6mQ_1YaDINFEttQymp2UQ
# 提取码:thgk
# ******************************************************************************
if abs(x[0]) > 0: # 判断取值
depth = int(abs(x[0])) + 3 # 赋值
else:
depth = int(abs(x[0])) + 5 # 赋值
if abs(x[1]) > 0: # 判断取值
learning_rate = (int(abs(x[1]))+1) / 10 # 赋值
else:
learning_rate = (int(abs(x[1]))+1) / 10 # 赋值Para obtener más prácticas de proyectos, consulte la lista de colecciones de prácticas de proyectos de aprendizaje automático:
Lista de colecciones de combate reales de proyectos de aprendizaje automático