Grupo de intercambio | Ingrese "grupo de sensores/grupo de chasis de monopatín", agregue WeChat ID: xsh041388
Grupo de intercambio | Ingrese al "Grupo de software básico automotriz", agregue la cuenta de WeChat: Faye_chloe
Observaciones: nombre del grupo + nombre real, empresa, puesto
El autor ha tenido curiosidad sobre muchos puntos de conocimiento en la simulación de conducción autónoma (el número uno es "simulación con datos reales de la carretera") durante más de dos años, pero nunca antes había tenido la oportunidad de aprenderlo. Durante la epidemia de abril del año pasado, ocasionalmente tuve la oportunidad de conversar con el fundador de una empresa de simulación, y el autor aprovechó la oportunidad para hacerle muchas preguntas.
Desde entonces, para la validación cruzada, el autor ha consultado sucesivamente a casi 20 expertos en la primera línea del negocio de simulación de conducción autónoma.
Los expertos que brindan apoyo para esta serie de notas de estudio incluyen, entre otros, An Hongwei, director ejecutivo de Zhixing Zhongwei, Yang Zijiang, fundador de Shenxin Kechuang, Li Yue, director de tecnología de Zhixing Zhongwei, Bao Shiqiang, director de tecnología de 51 World y simulaciones. de Momo Zhixing, Qingzhou Zhihang y Cheyou Intelligent expertos, etc. Gracias por esto.
Pregunta 1: Fuente de la escena: de datos sintéticos a datos de carreteras reales
Según Li Manman, el autor de la cuenta pública "Che Lu Slowly", y Li Yue, CTO de Zhixing Zhongwei, generalmente hay dos formas de pensar sobre el origen de la escena de la prueba de simulación:
La primera idea es un sistema de tres capas de escenarios funcionales-escenarios lógicos-escenarios específicos propuestos por el proyecto alemán PEGASUS: 1) Obtener diferentes tipos de escenarios (es decir, escenarios funcionales) a través de la recopilación de datos de carreteras reales y el análisis teórico; 2) , y luego analice los parámetros clave en estos diferentes tipos de escena, y obtenga el rango de distribución de estos parámetros clave (es decir, escenas lógicas) a través de métodos como estadísticas de datos reales y análisis teórico; 3), y finalmente seleccione el valor de un grupo de parámetros como escenarios de prueba (es decir, escenarios concretos).
Como se muestra abajo:
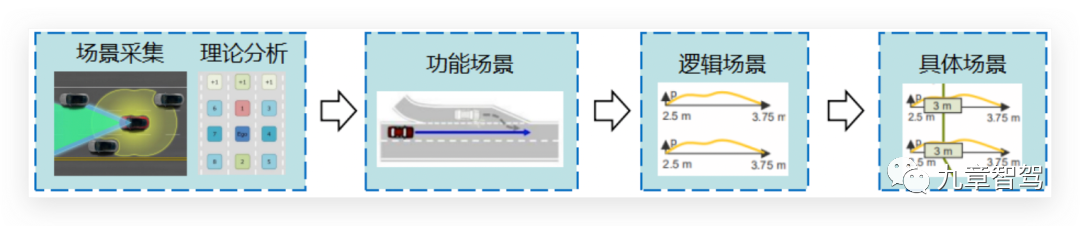
Por ejemplo, el escenario funcional se puede describir como "el vehículo autónomo (vehículo bajo prueba) está circulando en el carril actual, hay un vehículo delante del vehículo autónomo acelerando y el vehículo autónomo sigue al vehículo precedente". ." La escena lógica extrae los parámetros clave de la escena y le da a los parámetros de la escena un rango de valores específico. Por ejemplo, en la escena descrita anteriormente, parámetros como la velocidad del vehículo de enfrente, la velocidad y la aceleración del vehículo de enfrente , y se puede extraer la distancia entre el vehículo de delante y el vehículo de delante. Cada parámetro tiene un cierto rango de valores y características de distribución. También puede haber dependencias entre parámetros. Para una escena específica, los valores de parámetros de escena específicos deben seleccionarse para formar un vector de parámetros de escena y expresarse en un lenguaje de escena específico.
Esta es en realidad la llamada "escena generada por algoritmo/construcción virtual". Aunque la comprensión de la escena aún proviene de la escena real de la carretera, en la práctica, se basa más en esta comprensión para "dibujar artificialmente" una escena en el software Trayectoria de conducción, un conjunto de escenas, por lo tanto, los datos detrás de esta escena también se denominan "datos sintéticos".
En la práctica, el principal desafío con este enfoque es si el ingeniero de simulación tiene una comprensión lo suficientemente profunda de los escenarios de conducción normales del vehículo. Si el ingeniero no entiende la escena y deliberadamente "dibuja" una escena, por supuesto que no se puede usar.
La segunda forma de pensar es: recopilar datos de flujo de tráfico en el área de trabajo predeterminada del vehículo de conducción autónoma e ingresar estos datos en la herramienta de simulación de tráfico para generar flujo de tráfico y utilizar este flujo de tráfico como el "vehículo de tráfico circundante". del vehículo de conducción autónoma para realizar la prueba Generación automática de escenas.
Según Yang Zijiang, el fundador de Shenxin Kechuang, para garantizar un "valor real" más preciso, por lo general, la configuración del sensor en el vehículo de recopilación de ingeniería es mucho más alta que la de los automóviles autónomos comunes. Por ejemplo, el posicionamiento El sistema utilizará equipos de más de 20 W y el lidar de haz alto producirá datos más precisos.
Se dice que Waabi, una empresa de simulación fundada por Raquel Urtasun, exjefa científica de UberACT, utiliza los datos recopilados por la cámara para simular sin necesidad de sensores de alta precisión como lidar.
La mayor ventaja de utilizar datos de carreteras reales para la simulación es que la diversidad de escenarios no estará limitada por la falta de comprensión de los ingenieros de los escenarios, por lo que es más fácil "salvar" esos escenarios desconocidos que "nadie puede pensar en ".
Además, el responsable de la simulación de una empresa de conducción autónoma dijo: Para mejorar el realismo de la simulación, utilizaremos la menor cantidad posible de datos sintéticos y utilizaremos más datos reales de la carretera. De hecho, la simulación actual ya se está desarrollando en esta dirección: cada vez hay más datos y módulos reales.
Sin embargo, los ingenieros con práctica de simulación de primera línea generalmente reflejan que esta idea es demasiado idealista. Específicamente, el uso de datos de carreteras reales para la simulación tiene las siguientes limitaciones:
1. Los datos deben verificarse manualmente
De hecho, los datos recopilados por el sensor no se pueden usar directamente para la simulación: el tipo de datos y el formato deben convertirse, hay una gran cantidad de datos no válidos que deben limpiarse y las escenas válidas deben identificarse a partir de ellos, y algunos elementos específicos necesitan ser marcados Diferentes sensores Los datos entre necesitan ser sincronizados y fusionados en tiempo real, etc.
En circunstancias normales, los datos de percepción de los vehículos de conducción autónoma no necesitan verificarse manualmente, sino que se entregan directamente al algoritmo de toma de decisiones. Sin embargo, si se trata de una simulación, la verificación manual de los datos de percepción es un paso esencial.
2. El proceso inverso es más difícil de realizar que el proceso directo.
Un ingeniero de simulación de una empresa de camiones no tripulados dijo: La simulación con datos sintéticos es un proceso positivo, es decir, primero sabes qué pruebas debes hacer y luego tomas la iniciativa para diseñar tal escena; la simulación con datos reales es un proceso positivo proceso Un proceso inverso, es decir, primero encuentra un problema y luego lo resuelve. Comparando los dos, el último es mucho más difícil.
3. Incapaz de resolver el problema de interacción
Jame Zhang, jefe de Furui Microelectronics, mencionó en un intercambio público que WorldSim (que usa datos virtuales para la simulación) es como jugar un juego, mientras que LogoSim (que usa datos de carreteras reales para la simulación) es más como una película, solo puede mirar, Incapaz para participar, por lo tanto, LogoSim naturalmente no puede resolver el problema de la interactividad.
4. No se puede hacer un ciclo cerrado
Jame Zhang, director de Furui Microelectronics, también mencionó otra diferencia entre los dos métodos de simulación: al usar datos de carreteras reales para la reproducción, los fragmentos que se pueden recopilar siempre son limitados y, a menudo, cuando comienza la recopilación, es posible que ya se haya producido un peligro. un tiempo, y es difícil obtener los datos anteriores, pero si usa datos virtuales (datos sintéticos), no tiene que enfrentar este problema.
El responsable de la simulación de un OEM dijo: "Los expertos antes mencionados describieron el proceso de adquisición. En efecto, considerando la capacidad del equipo de adquisición y la definición de escenarios efectivos, los escenarios de adquisición y gestión tienen longitudes, generalmente antes y después de la activación de la función. El tiempo, especialmente el caché antes de la activación no será particularmente largo. Por otro lado, cuando los datos se recopilan y se utilizan para recargar, solo la escena anterior a la activación de la función es válida, pero la escena real después de la activación. el activador de la función no es válido".
El experto en OEM dijo: Es posible usar datos de carreteras reales para entrenar el algoritmo de percepción, pero para probar todo el enlace del algoritmo, todavía tiene que depender de datos sintéticos de la escena.
Sin embargo, el director de simulación de la fábrica principal de motores también enfatizó al final: "El llamado 'lazo cerrado no se puede lograr' también es relativo. Ya hay proveedores que pueden completar la parametrización de los elementos en las escenas recopiladas, por lo que que se puede lograr el circuito cerrado. Pero el precio de dicho equipo es muy caro".
5. La autenticidad de los datos sigue siendo difícil de garantizar
Simulación con datos reales de flujo de tráfico, también conocida como "recarga".
Según Yang Zijiang, el fundador de Shenxin Kechuang, hay dos tecnologías principales que deben usarse para "recargar": una es restaurar la estructura de la red de carreteras de los datos de minería de carreteras en el entorno de simulación, y la otra es integrar los participantes dinámicos del tráfico en los datos de minería de carreteras (peatones, vehículos, etc.) La información de posición en diferentes sistemas de coordenadas se asigna al sistema de coordenadas global bajo la red de carreteras mundial simulada.
Las herramientas que deben usarse en este proceso son SUMO o openScenario, que se utilizan para leer la información de ubicación de los participantes del tráfico.
Un experto en simulación de un OEM dijo: "La recarga de los datos originales no puede garantizar el 100% de autenticidad, porque después de que los datos originales se inyectan en la plataforma de simulación, se debe agregar la simulación de la dinámica del vehículo. Pero de esta manera, si la escena sigue siendo la igual que en la carretera real. Las escenas son las mismas, por lo que es difícil de decir”.
La razón es que el software de simulación de flujo de tráfico existente a menudo todavía tiene los siguientes defectos principales:
El flujo de tráfico generado no es lo suficientemente fiel, a menudo solo admite la importación de trayectorias de vehículos, y la interacción bidireccional entre vehículos no es lo suficientemente realista;
La interfaz de transmisión de datos entre el módulo de simulación (vehículo propio) y el módulo de flujo de tráfico (otros participantes de la carretera) es limitada (por ejemplo, el formato de la red de carreteras es diferente y se requiere la coincidencia de la red de carreteras), y la operabilidad de terceros es limitada. limitado;
El modelo de flujo de tráfico basado en reglas está orientado a la evaluación de la eficiencia del tráfico, y puede haber problemas de simplificación excesiva (a menudo se utilizan modelos unidimensionales, asumiendo que el establecimiento se conduce a lo largo de la línea central, y el impacto lateral se considera menos ), y es difícil cumplir con los requisitos de evaluación de seguridad interactiva.
Un ingeniero de simulación de nivel 1 dijo que es bastante difícil usar datos de flujo de tráfico real para generar escenarios de simulación, cómo elegir un modelo de flujo de tráfico (como definir el modelo de seguimiento de automóviles y el modelo de cambio de carril) y cómo definir la interfaz del módulo de simulación de flujo de tráfico. Al mismo tiempo, cómo sincronizar los datos del propio vehículo con los datos de otros usuarios de la vía también será un gran problema.
6. La universalidad de los datos es baja y la generalización es difícil
Tanto An Hongwei, CEO de Zhixing Zhongwei, como Li Yue, CTO, mencionaron específicamente la "universalidad" de los datos de simulación. La llamada versatilidad de datos significa que se pueden ajustar los parámetros del vehículo y la escena. Por ejemplo, cuando los datos son recopilados por un automóvil, el ángulo de visión de la cámara es muy bajo, pero después de que se convierte en una escena de simulación, el ángulo de visión de la cámara se puede ajustar más alto y este conjunto de datos se puede utilizado para la prueba del modelo de camión.
Si la escena es una construcción virtual/generada por un algoritmo, cada parámetro se puede ajustar arbitrariamente según las necesidades; entonces, ¿qué pasa si la escena se basa en datos reales de la carretera?
El encargado de la simulación de una empresa de cadena de herramientas dijo que en el caso de utilizar datos reales de la carretera para la simulación, una vez que se cambie la posición o modelo del sensor, el valor de este conjunto de datos se reducirá, o incluso " obsoleto".
Los expertos en simulación de Qingzhou Zhihang dijeron que la red neuronal también se puede usar para ajustar los parámetros de los datos de carreteras reales. Este tipo de ajuste de parámetros será más inteligente, pero la capacidad de control será más débil.
El uso de datos de flujo de tráfico real para la simulación, también conocida como "recarga", y la recarga se puede dividir en dos tipos, recarga directa y recarga modelo:
La llamada "recarga directa" se refiere a alimentar directamente los datos del sensor al algoritmo sin procesar. En este modo, los parámetros del vehículo y la escena no se pueden ajustar. Los datos recopilados por un determinado modelo solo se pueden usar para el mismo vehículo La prueba de simulación del modelo;
El "relleno del modelo" se refiere a abstraer y modelar primero los datos de la escena y expresarlos con un conjunto de fórmulas matemáticas. En esta fórmula matemática, los parámetros del vehículo y la escena son ajustables.
Según Li Yue, la recarga directa no requiere el uso de modelos matemáticos. "Es relativamente simple. Básicamente, siempre que haya una gran capacidad de datos, se puede hacer". La trayectoria y la velocidad del vehículo se realizan a través de fórmulas matemáticas.
El umbral técnico de recarga del modelo es muy alto y el costo no es bajo. Un ingeniero de simulación dijo: "Es muy difícil convertir los datos registrados por el sensor en datos de simulación. Por lo tanto, en la actualidad, esta tecnología se queda principalmente en PR En la práctica, las pruebas de simulación de cada empresa se basan en escenarios generados por algoritmos, complementados con escenarios de carreteras reales”.
El responsable de la simulación de una empresa de conducción autónoma dijo: "Todavía es una tecnología muy avanzada usar datos reales de flujo de tráfico para la simulación. Es muy difícil ajustar los parámetros de estos datos (los parámetros solo se pueden ajustar dentro de un rango pequeño). Debido a que la minería de carreteras es un montón de registros y registros uno por uno, registra cómo funciona el automóvil en el primer segundo y segundo, a diferencia de algunas escenas editadas por humanos, que se componen de una serie de fórmulas.
El experto en simulación dijo que el mayor desafío del relleno de modelos es que en el caso de escenarios complejos, es extremadamente difícil formular los escenarios, este proceso se puede realizar de forma automatizada, pero al final es si la escena puede ser utilizado es también una pregunta.
Waymo anunció en 2020 que "al generar directamente información de imagen realista a partir de los datos recopilados por el sensor para la simulación", ChauffeurNet en realidad está utilizando una red neuronal en la nube para convertir los datos originales de la carretera en un modelo matemático y luego rellenar el modelo. Pero un experto en simulación que ha estado en Silicon Valley durante muchos años dijo que esto todavía está en la etapa experimental y que aún falta algo de tiempo antes de que se convierta en un producto real.
Más significativo que la realimentación, dijo el experto en simulación, es la introducción del aprendizaje automático o aprendizaje por refuerzo. Específicamente, el sistema de simulación entrena parte de su propia lógica sobre la base del aprendizaje completo de los hábitos de comportamiento de varios participantes del tráfico, formula estas lógicas y luego ajusta los parámetros en estas fórmulas.
Sin embargo, según Li Yue, CTO de Zhixing Zhongwei, y Feng Zonglei, subdirector general, ya han podido realizar la recarga de modelos.
Feng Zonglei cree que si una empresa de simulación tiene la capacidad de volver a llenar el modelo depende principalmente de las herramientas que utilizan y sus capacidades de gestión de escenas.
"En la gestión de escenas, el corte es una parte muy importante; no todos los datos son válidos. Por ejemplo, en 1 hora de datos, los datos efectivos reales pueden ser menos de 5 minutos. Al realizar la gestión de escenas, la empresa de simulación necesita la parte efectiva. ser cortado, y este proceso se llama 'rebanar'.
"Después de completar el corte, la empresa de simulación necesita crear un entorno de gestión correspondiente con información semántica (como quién es un peatón y cuál es una intersección) para facilitar la siguiente evaluación. Específicamente, primero es necesario clasificar los segmentos de datos. , y luego refinar la lista de objetivos dinámicos, y luego importarla al modelo del entorno de simulación. De esta manera, el modelo tiene la información semántica correspondiente. Con la información semántica, puede ajustar los parámetros y luego, los datos. se puede reutilizar
"La razón por la que la mayoría de las empresas no pueden ajustar los parámetros en función de los datos de flujo de tráfico real es porque no han hecho un buen trabajo en la gestión de la escena".
Yang Zijiang, el fundador de Shenxin Kechuang, dijo: "Si desea generalizar los datos de minería de carreteras y mantener la autenticidad de los datos, puede reproducir los datos de minería de carreteras en la inicialización de la escena y la etapa inicial, y en un cierto Punto en el que el modelo smart-npc se hará cargo de la carretera Los vehículos de fondo en el sistema evitarán que los vehículos de fondo funcionen de acuerdo con los datos de muestreo de la carretera. Después de que el smart-npc se haga cargo, registra las escenas generalizadas para que las escenas clave generalizadas se puede reproducir”.
Un ingeniero de simulación de un OEM cree que aunque la recarga del modelo suena "poco clara", en realidad "no es necesaria". La razón es: modelar los datos no coincide con la intención original de rellenar: la intención original de rellenar es querer datos reales, pero dado que el modelo está modelado y los parámetros son ajustables, no es lo más real; requiere mucho tiempo y laborioso, conversión de formato de datos Muy problemático y desagradecido.
El ingeniero dijo: "Ya que desea más escenarios, puede usar directamente el simulador para generar escenarios generalizados a gran escala. No tiene que tomar el camino de modelar datos reales".
En respuesta, Feng Zonglei respondió:
"Usar algoritmos para generar escenas directamente no es un problema, por supuesto, en las primeras etapas de desarrollo, pero las limitaciones también son obvias: ¿qué pasa con esas escenas que los ingenieros 'inesperaron'? Las condiciones reales del tráfico cambian constantemente y su imaginación no puede ser limitado Darlo todo.
"Más importante aún, en la escena imaginada por el ingeniero, la relación de interacción entre los objetos a menudo no es natural. Por ejemplo, si hay un vehículo frente a ti, ¿en qué ángulo se inserta? Cuando está a 10 metros de ti. , todavía está a 5 metros de distancia. ¿Inserción de tiempo? En la práctica del uso de algoritmos para generar escenas, la formulación de los parámetros de la escena suele ser muy subjetiva y arbitraria. Los ingenieros tomaron su cerebro y crearon un conjunto de modelos de inyección de parámetros, pero ¿Este conjunto de parámetros es representativo?
Feng Zonglei cree que cuando la conducción no tripulada todavía está en la etapa de demostración, las escenas virtuales generadas por algoritmos pueden satisfacer las necesidades, pero en la era de la producción en masa preinstalada, la generalización de la escena se basa en datos de conducción natural a gran escala (flujo de tráfico real). datos) Sigue siendo muy necesario.
Según una persona que ha tenido contacto con Momenta: "Momenta ya tiene la capacidad de usar datos de carreteras reales para la generalización de escenas (ajuste de parámetros), pero su tecnología es solo para su propio uso y no para el mundo exterior".
Bao Shiqiang, jefe de simulación de vehículos en 51 World, cree que la generalización de los datos de conducción natural todavía es relativamente prospectiva, pero definitivamente se convertirá en una dirección muy importante en el futuro, por lo que también están explorando.
Resumen: Las dos rutas se penetran y los límites se vuelven cada vez más borrosos.
James Zhang, la persona a cargo de Furui Micro-simulation, mencionó en un intercambio hace algún tiempo que hay dos métodos de simulación de Tesla: la escena es completamente virtual (generada por un algoritmo) llamada WorldSim, y la reproducción de datos reales se llama LogSim. para que el algoritmo vea "Sin embargo, la red de carreteras en WorldSim también se genera sobre la base de la estandarización automática de datos de carreteras reales. Por lo tanto, los límites entre WorldSim y LogSim son cada vez más borrosos".
El experto en simulación de Qingzhou Zhihang dijo: "Después de que los datos de la escena real se conviertan en datos con formato estándar, se pueden desgeneralizar a través de reglas, generando así escenarios de simulación más valiosos".
Bao Shiqiang, jefe del negocio de simulación en vehículos de 51 World, también cree que la tendencia futura es que las dos rutas de simulación que utilizan datos de carreteras reales y la simulación que utiliza datos generados por algoritmos se interpenetrarán.
Bao Shiqiang dijo: "Por un lado, el uso de algoritmos para generar escenas también depende de la comprensión del ingeniero de las escenas de carreteras reales. Cuanto más profunda sea la comprensión de las escenas reales, más cerca puede estar el modelado de la realidad. Por otro lado, usar datos de carreteras reales como escenas. También es necesario dividir y extraer los datos (descartar la parte efectiva), luego establecer parámetros, desencadenar reglas y luego realizar una clasificación refinada, y luego pueden ser lógicos y formulados ".
Pregunta 2: Generalización de escenas y extracción de escenas
El "ajuste de parámetros" de los datos de la escena mencionado repetidamente en los párrafos anteriores también se denomina "generalización de la escena"; por lo general, se refiere principalmente a la generalización de las escenas virtuales. En palabras de un ingeniero de sistemas de un OEM, la ventaja de la generalización de escenas es que podemos "crear" algunas escenas que nunca se han visto en el mundo real.
Cuanto más fuerte sea la capacidad de generalización de escenas de una empresa de simulación, más escenas disponibles se pueden obtener después de ajustar los parámetros de una determinada escena. Por lo tanto, la capacidad de generalización de escenas también es una competitividad clave de una empresa de simulación.
Sin embargo, los expertos en algoritmos de Qingzhou Zhihang dijeron que la generalización de la escena se puede lograr a través de modelos matemáticos, aprendizaje automático y otros métodos, pero la cuestión clave es cómo garantizar que la escena generalizada sea real y más valiosa.
¿Cuáles son los factores clave que determinan si la capacidad de generalización de la escena de una empresa es fuerte o débil?
Yang Zijiang, el fundador de Shenxin Kechuang, cree que una gran dificultad en la generalización de escenas es cómo abstraer la trayectoria en una semántica de nivel superior y expresarla en un lenguaje de descripción formal.
Un ingeniero de simulación de nivel 1 dijo: Depende principalmente del lenguaje (como openscenario) que utilice la herramienta de simulación utilizada por la empresa para describir diferentes escenarios de tráfico (detalles, mientras que es escalable).
Existen lenguajes de escenarios correspondientes a escenarios funcionales, escenarios lógicos y escenarios específicos: Para los dos primeros, existen lenguajes de escenarios avanzados como M-SDL; para los últimos, existen OpenSCENARIO, GeoScenario, etc.
Otro nivel puede ser la simulación de conductas de interferencia, el grado de generalización de diversas conductas de conducción y la "personalidad" de conducción.
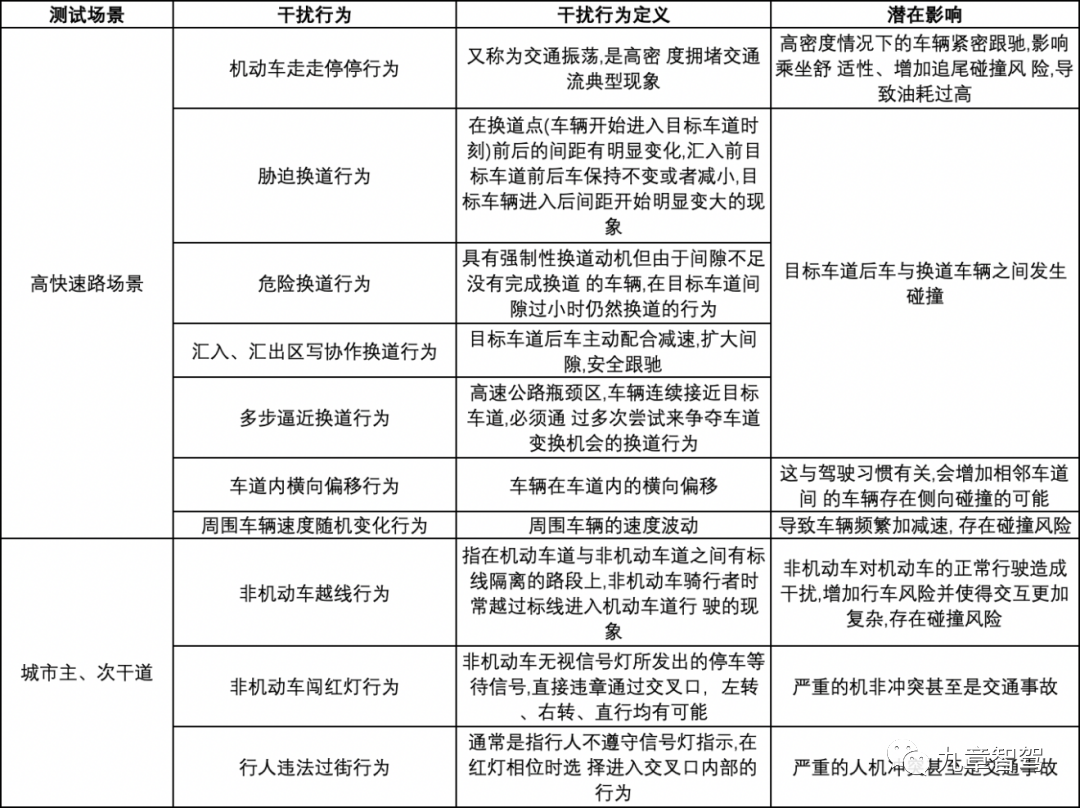
△El gráfico está tomado del libro "Teoría y método de evaluación de la prueba de simulación virtual de conducción autónoma" de Sun Jian, Tian Ye y Yu Rongjie
Yang Zijiang, fundador de Shenxin Technology, dijo: "Según la generalización del flujo de tráfico y la inteligencia de los conductores, si el modelo es lo suficientemente bueno, debido a la existencia de factores aleatorios, ejecutar la escena 10 veces es equivalente a generalizar 10". veces."
Sin embargo, Li Yue, CTO de Zhixing Zhongwei, cree que la generalización no se puede hacer por el bien de la generalización. "Debemos tener una comprensión profunda de la función bajo prueba, y luego diseñar un plan de generalización, no la generalización por el bien de la generalización, y mucho menos la generalización sin límites. Aunque la generalización de la escena es virtual, también debemos respetar la Realidad".
Otro experto en simulación también dijo: "Al final del día, la simulación debe servir para probar. Ya nos encontramos con un problema en el camino y luego veremos cómo resolverlo a través de la simulación, en lugar de decir que tengo una tecnología de simulación". primero, y luego vamos a ver para qué se usa?"
Un experto en simulación mencionado anteriormente dijo que hasta donde él sabe, no hay muchas empresas que realmente puedan lograr la generalización de escenarios, en la mayoría de los casos, el ajuste de parámetros se realiza manualmente. "La capacidad de generalización de la escena es muy importante, pero en esta etapa, ninguna empresa puede hacerlo realmente bien".
Bao Shiqiang, jefe del negocio de simulación de vehículos en 51 World, cree que lo más importante para la generalización de escenas es tener una comprensión profunda de qué tipo de escenarios se necesitan para las pruebas de simulación de conducción autónoma. De hecho, el problema ahora no es que haya muy pocos escenarios generados, sino demasiados, y muchos de ellos no sucederán realmente, por lo que no se consideran escenarios de prueba efectivos, debido a la falta de comprensión de los requisitos.
Según algunos expertos, el mayor desafío al que se enfrentan las empresas de simulación de terceros es que no conocen bien qué tipo de simulación se requiere para la conducción autónoma porque no han participado personalmente en la conducción autónoma.
Y aquellas empresas de conducción autónoma L4 que son capaces y tienen un conocimiento profundo de los requisitos de simulación no tienen suficiente motivación para generalizar la escena con mucha profundidad. Debido a que Robotaxi generalmente solo se ejecuta en un área pequeña de una ciudad determinada, solo necesitan recopilar los datos de la escena de esta área para entrenar y probar, no hay mucha necesidad de generalizar muchos de ellos durante mucho tiempo Escenas que no uno tocará.
Bao Shiqiang cree que los fabricantes de equipos originales como Wei Xiaoli tienen una gran cantidad de datos de carreteras reales y no existe una gran demanda de generalización de la escena. Por el contrario, para estas empresas más urgente que la generalización de escenarios es afinar la clasificación y gestión de escenarios y descartar los escenarios realmente efectivos.
Los expertos en simulación de Qingzhou Zhihang también creen que con el aumento del tamaño de la flota y la rápida expansión de los datos de las carreteras reales, para las empresas de simulación, la forma de extraer escenarios completamente efectivos en estos datos es mucho más importante que la generalización de la escena. "Podemos explorar un método de generalización más inteligente, que puede realizar una verificación a gran escala del algoritmo más rápido".
Yang Zijiang dijo: "Apuntando a la generalización a nivel de parámetros, como la cantidad de carriles, la cantidad de tipos de participantes del tráfico, el clima y parámetros clave como la velocidad y el TTC, la capacidad de cada empresa para generar escenarios generalizados es similar, pero el núcleo de la capacidad de generalización de la escena radica en cómo identificar escenas válidas y filtrar escenas no válidas (incluidas las repetidas e irrazonables); y la dificultad del reconocimiento de escenas es que las escenas complejas necesitan identificar la relación entre múltiples objetos. "
La "identificación de escenas válidas y filtrado de escenas no válidas" mencionada anteriormente también se denomina "extracción de escenas".
La premisa de la extracción de escenas es averiguar primero qué es una "escena válida". Según varios expertos en simulación, además de los escenarios que deben probarse de acuerdo con la ley, los escenarios efectivos también incluyen los siguientes dos tipos: al hacer el diseño avanzado del sistema, los escenarios definidos por los ingenieros de acuerdo con los requisitos de desarrollo. del algoritmo; No puedo hacerlo bien".
Por supuesto, la efectividad y la ineficiencia son relativas, lo que está relacionado con la etapa de desarrollo de la empresa y la etapa de madurez del algoritmo; en principio, a medida que el algoritmo madura y el problema se resuelve, muchos escenarios efectivos originales se convertirán en escenarios inválidos.
Entonces, ¿cómo filtrar de manera eficiente los escenarios efectivos?
Hay una idea en la comunidad académica: establecer algunos valores de entropía en el algoritmo de percepción, y cuando la complejidad de la escena supere estos valores, el algoritmo de percepción marcará la escena cambiada como una escena válida. Pero cómo establecer este valor de entropía es un gran desafío.
Una empresa de simulación adopta el "método de eliminación", es decir, si un algoritmo que originalmente funcionó muy bien tiene "problemas frecuentes" en algunos escenarios de generalización, entonces este escenario tiene una alta probabilidad de ser un "escenario no válido" y se puede descartar. .
Un ingeniero de sistemas de un OEM dijo: "Actualmente, no existe un buen método para la detección de escenas. Si no está seguro, colóquelo en la simulación en la nube para calcular. Después de todo, puede calcular estos escenarios extremos y luego usar estas condiciones extremas en su propia Si la verificación se realiza en el banco HIL o banco VIL, la eficiencia será mucho mayor.”
Pregunta 3: ¿Dónde está la dificultad en la simulación?
En el proceso de comunicación con expertos de muchas empresas de simulación y sus usuarios intermedios, aprendimos que uno de los aspectos más difíciles de la simulación de conducción autónoma es el modelado de sensores.
Según Li Yue, CTO de Zhixing Zhongwei, el modelado de sensores se puede dividir en modelado de nivel de información funcional, modelado de nivel de información de fenómeno/nivel de información estadística y modelado de nivel físico completo. La diferencia entre estos conceptos es la siguiente:
El modelado de nivel de información funcional simplemente describe las funciones específicas de la imagen de salida de la cámara y el radar de ondas milimétricas que detecta objetivos dentro de un cierto rango. El objetivo principal es probar y verificar el algoritmo de percepción, pero no presta atención al rendimiento del sensor en sí;
El modelado de nivel de información estadística y de información de fenómenos es un modelado de nivel intermedio híbrido que incluye modelado de nivel de información funcional parcial y modelado de nivel físico parcial;
El modelado de nivel físico completo se refiere a la simulación de todo el enlace físico del trabajo del sensor. El objetivo es probar el rendimiento físico del sensor en sí, como la capacidad de filtrado del radar de ondas milimétricas.
El modelado de sensores en un sentido estricto se refiere al modelado en el nivel físico completo. Este tipo de modelado, pocas empresas pueden hacerlo bien, las razones específicas son las siguientes:
1. La eficiencia de la representación de imágenes no es lo suficientemente alta
Desde la perspectiva de los principios de imágenes de gráficos por computadora, la simulación de sensores incluye luz (simulación de entrada y salida), geometría, simulación de materiales, representación de imágenes y otras simulaciones, y la diferencia en las capacidades de representación y la eficiencia afectará la autenticidad de la simulación.
2. Demasiados tipos de sensores y el "triángulo imposible" de precisión, eficiencia y versatilidad del modelo
No es suficiente tener un solo sensor con alta precisión, también necesita que todos los sensores alcancen un estado ideal al mismo tiempo, lo que requiere una amplia cobertura de modelado, pero bajo la presión del costo, obviamente es imposible para el El equipo de simulación Radar hace 10 o 20 versiones de modelado, ¿verdad? Por otro lado, es difícil usar un modelo general para expresar varios sensores de diferentes estilos.
La precisión, la eficiencia y la versatilidad del modelo son una relación de "triángulo imposible". Puede mejorar un lado o dos esquinas, pero es difícil para usted mejorar continuamente las tres dimensiones al mismo tiempo. Cuando la eficiencia es lo suficientemente alta, la precisión del modelo debe disminuir.
El experto en simulación de Cheyou Intelligence dijo: "No importa cuán complicado sea el modelo matemático, solo puede simular el sensor real con un 99% de similitud, y el 1% restante puede ser el factor que causará problemas fatales".
3. El modelado del sensor está sujeto a los parámetros del objetivo.
La simulación del sensor requiere datos externos, es decir, los datos del entorno externo están fuertemente acoplados con el sensor.Sin embargo, el modelado del entorno externo es bastante complicado y el costo no es bajo.
Hay demasiados edificios en las escenas urbanas, lo que consumirá seriamente los recursos informáticos para la representación de imágenes. Algunos edificios bloquearán el flujo de tráfico, los peatones y otros objetos objetivo en la carretera, pero si están bloqueados o no, la cantidad de cálculo es completamente diferente.
Además, la reflectividad y el material del objetivo son difíciles de determinar a través del modelado de sensores. Por ejemplo, se puede decir que un objetivo tiene la forma de un barril, pero es difícil expresar claramente a través del modelado si es un barril de hierro o un barril de plástico; incluso si se puede expresar claramente, es otro problema. para ajustar estos parámetros en el modelo de simulación Super gran proyecto.
Si la información física, como el material del objeto de destino, no está clara, es difícil elegir un simulador para la simulación.
4. Es difícil determinar cuánto ruido se agrega al sensor
Un ingeniero de simulación de nivel 1 dijo: "El reconocimiento de objetos mediante algoritmos de aprendizaje profundo es un proceso que va desde la recopilación de datos de sensores del mundo real hasta la eliminación de ruido de señales. Por el contrario, el modelado de sensores se basa en un modelo físico ideal. Agregue ruido y el la dificultad radica en cómo agregar ruido para estar lo suficientemente cerca del mundo real, de modo que pueda ser reconocido por el modelo de aprendizaje profundo y mejorar efectivamente la generalización del reconocimiento del modelo”.
La implicación es que la señal del sensor generada por la simulación debe ser "suficientemente similar" a la señal del sensor en el mundo real (puede identificar el objeto correspondiente), pero no "demasiado similar" (simular el caso de la esquina permite que el modelo de percepción logre reconocimiento en más situaciones — — generalización). Sin embargo, el problema es que en el mundo real, el ruido del sensor es aleatorio en muchos casos, lo que significa que cómo simular estos ruidos en el sistema de simulación es un gran desafío.
Desde la perspectiva del principio del sensor, el proceso de modelado de la cámara también necesita desenfocar la cámara (primero generar un modelo ideal y luego agregar ruido), simulación de distorsión, simulación de viñetas, conversión de color, procesamiento de efecto de ojo de pez, etc. El modelo puede también se puede dividir en un modelo de nube de puntos ideal (los pasos incluyen recorte de escena, juicio de visibilidad, juicio de oclusión y cálculo de posición), modelo de atenuación de potencia (que incluye potencia de láser de aceptación, potencia de láser reflejada, ganancia de antena de reflexión, sección transversal de dispersión del objetivo, apertura de interfaz , distancia objetivo, coeficiente de transmisión atmosférica, coeficiente de transmisión óptica, etc.) y modelos físicos considerando el ruido meteorológico, etc.
5. Limitaciones de recursos
An Hongwei, director ejecutivo de Zhixing Zhongwei, mencionó la limitación de recursos en la simulación virtual de percepción: "Necesitamos hacer un modelado completo del nivel físico del sensor, como los parámetros ópticos y físicos de la cámara, etc., y también necesitamos Para conocer el objetivo (objeto detectable) Materiales, reflectividad y otros datos, la cantidad de este proyecto es enorme: con suficiente mano de obra, el período de construcción de una escena de un kilómetro lleva aproximadamente un mes. Incluso si se puede construir, la complejidad del modelo es extremadamente alto y es difícil ejecutarlo en una máquina física (demasiada potencia informática)".
"En el futuro, todas las simulaciones irán a la nube. Parece que el poder de cómputo de la nube es 'infinito', pero cuando se asigna a un solo modelo de un solo nodo, es posible que el poder de cómputo de la nube no sea tan bueno como el de una máquina física—y, en Cuando se realiza una simulación en una máquina física, si los recursos informáticos de una máquina no son suficientes, se pueden instalar tres máquinas, una es responsable del modelo del sensor, una es responsable de la dinámica , y uno es responsable de la regulación y el control, pero la ejecución de la simulación en la nube se puede usar en una sola escena. El poder de cómputo en un solo modelo no es infinito, por lo que esto limita la complejidad de nuestro modelo".
6. Es difícil para las empresas de simulación obtener los datos subyacentes de los sensores.
El modelado de nivel físico completo necesita construir varias actuaciones de sensores con modelos matemáticos. Por ejemplo, un rendimiento específico del receptor de la señal, la ruta de propagación (influenciada por el aire en el medio, todo el enlace de reflexión y refracción) se expresa en fórmulas matemáticas. Sin embargo, en la etapa en que el software y el hardware no se han desacoplado realmente, el algoritmo de percepción dentro del sensor es una caja negra y la empresa de simulación no puede entender cómo se ve el algoritmo.
El modelado físico completo necesita obtener los parámetros subyacentes de los componentes del sensor (como chips CMOS, ISP) y modelar estos parámetros. Además, también es necesario conocer los principios físicos subyacentes de los sensores y analizar las ondas láser de lidar y radares de ondas milimétricas Modelado de ondas electromagnéticas.
Al respecto, un experto en simulación dijo: "Para hacer un buen trabajo en el modelado de sensores, debe tener una comprensión profunda del conocimiento del hardware subyacente del sensor, que es básicamente equivalente a saber cómo diseñar un sensor".
Sin embargo, los proveedores de sensores generalmente son reacios a abrir los datos subyacentes.
Li Yue, CTO de Zhixing Zhongwei, dijo: "Si obtiene estos parámetros subyacentes y los usa para hacer modelos, entonces básicamente puede hacer este sensor".
An Hongwei, CEO de Zhixing Zhongwei, dijo: "Por lo general, cuando los OEM tratan con proveedores de sensores, no es fácil obtener el protocolo de interfaz, sin mencionar los detalles de los parámetros físicos del material. Si el OEM es lo suficientemente fuerte, los proveedores de sensores son también cooperando activamente, y pueden obtener protocolos de interfaz, pero no todos. Es aún más difícil para los OEM obtener cosas que son difíciles para las empresas de simulación".
De hecho, la simulación a nivel físico de los sensores solo puede ser realizada por los propios fabricantes de sensores. Muchos fabricantes de sensores domésticos utilizan chips externos y otros componentes para la integración, por lo que en realidad son los proveedores aguas arriba, como TI y NXP, los que pueden simular el nivel físico de los sensores.
Un ingeniero de simulación de una empresa de conducción no tripulada de vehículos comerciales dijo: "La simulación de sensores es difícil, lo que hace que el proceso de selección de sensores sea muy complicado. Cuando queremos seleccionar sensores, básicamente la empresa de sensores me envía las muestras primero, y luego instalamos "Varios tipos en el automóvil para la prueba. Si los fabricantes de sensores pueden cooperar con las empresas de simulación, pueden conectar todas las interfaces y proporcionar un modelo de sensor preciso. Conocer la información del sensor reducirá en gran medida la carga de trabajo de la selección del sensor".
Sin embargo, Bao Shiqiang, CTO de 51 World, dijo: "La simulación perceptual aún está en su infancia, y está lejos de llegar a la etapa en la que el modelado dentro del sensor debe hacerse con tanta precisión. Desarmo el interior del sensor y modelar esas cosas. Se siente sin sentido".
Además, según el responsable de la simulación de una empresa de conducción no tripulada, la imposibilidad de hacer simulación de sensores no significa que la simulación de percepción no se pueda hacer en absoluto.
Por ejemplo, el hardware-in-the-loop (HIL) se puede conectar a sensores reales (sensores y controladores de dominio, ambos son reales) para realizar pruebas. La conexión al sensor real no solo puede probar el algoritmo de percepción, sino también la función y el rendimiento del sensor en sí. En este modo, el sensor es real y la precisión de la simulación es mayor que la simulación del sensor.
Sin embargo, debido a que involucra hardware de soporte, es complicado de integrar, y este método aún requiere un modelo de sensor para controlar la generación de señales ambientales, y el costo es mayor, por lo tanto, este método rara vez se usa en la práctica.
Adjunto: dos etapas de la prueba de simulación de conducción autónoma

(Extracto del artículo "Introducción a la Prueba de Simulación Virtual de Conducción Autónoma" publicado por la cuenta oficial "Car Road Slowly" el 26 de marzo de 2021)
Teniendo en cuenta la situación real reciente, la simulación de conducción autónoma se puede dividir aproximadamente en dos etapas de desarrollo (por supuesto, estas dos etapas pueden no tener un límite de tiempo claro).
(1) Etapa 1:
El módulo de percepción e identificación del sensor se prueba en el laboratorio y el campo de prueba cerrado, y el módulo de control de toma de decisiones se prueba en el entorno de simulación virtual.El entorno de simulación proporciona directamente la lista de objetivos al módulo de control de toma de decisiones.
Esto se debe principalmente a que el modelado actual de sensores tiene muchas limitaciones que impiden simulaciones eficientes (o incluso correctas). Por ejemplo, las imágenes emitidas por la cámara son más fáciles de simular, pero la simulación de características tales como manchas y luz fuerte es más difícil; y para el radar de ondas milimétricas, si se establece un modelo con alta precisión, la velocidad de cálculo es lenta. , que no puede satisfacer las necesidades de las pruebas de simulación.
El control completo y el registro de datos del entorno de prueba se pueden llevar a cabo en el laboratorio y en el campo de prueba cerrado. Por ejemplo, organice peatones y vehículos de diferentes categorías, posiciones y velocidades, e incluso simule elementos ambientales como lluvia, nieve, niebla y luz fuerte, y compare la salida de la lista de objetivos mediante el procesamiento del sensor con el entorno real, para dar la percepción reconocimiento Módulo de evaluación de resultados y recomendaciones de mejora.
La ventaja de esto es que, en el caso de muchas limitaciones en el modelado de sensores, el módulo de control de toma de decisiones aún puede probarse en un entorno de simulación y disfrutar de las ventajas de las pruebas de simulación por adelantado.
(2) Etapa dos:
Realice modelos de sensores de alta precisión en un entorno de simulación virtual para probar algoritmos completos de conducción autónoma.
De esta manera, no solo se pueden realizar las pruebas en el mismo entorno, lo que mejora la eficiencia de las pruebas, la cobertura y la complejidad de los escenarios de prueba, sino que también se pueden realizar pruebas de extremo a extremo en algunos algoritmos basados en IA.
La dificultad en esta etapa es, por un lado, el modelado del sensor que cumple con los requisitos de prueba mencionados anteriormente y, por otro lado, las interfaces para la interacción directa entre diferentes fabricantes de sensores y fabricantes OEM pueden ser inconsistentes (en algunos casos, puede no existir).
Pregunta 4: ¿Cuáles son las diferencias entre los niveles inferior y superior de las pruebas de simulación de conducción autónoma?
Para la etapa de conducción autónoma de bajo nivel, la simulación es solo un medio auxiliar, pero cuando se trata de conducción autónoma de alto nivel, la simulación se convierte en una barrera de entrada: L3 necesita hacer suficientes simulaciones de kilometraje para ponerse en camino.
Un experto en simulación de un OEM dijo: Por lo general, las empresas de conducción autónoma son más capaces de realizar simulaciones L4, mientras que las empresas de simulación de terceros se centran principalmente en la simulación L2. Entonces, ¿cuáles son las diferencias específicas entre las dos fases de la simulación?
1. Límites funcionales
Experto en simulación de Qingzhou Zhihang: "La definición de producto de L2 es madura y los límites funcionales son claros. Por lo tanto, los servicios proporcionados por los proveedores de servicios de simulación a varios OEM son muy versátiles; y donde están los límites funcionales de L4, todos todavía están explorando, por lo tanto, los clientes tienen un alto grado de personalización para las necesidades de simulación”.
2. Escala de la biblioteca de escenas
Yang Zijiang, fundador de Kechuang: "Desde la perspectiva de los escenarios de prueba, debido a la mayor complejidad de ODD en L4, el orden de magnitud de la biblioteca de escenas es mucho mayor que el de L2".
3. Requisitos para la reproducibilidad de la escena
Un experto en simulación de un OEM dijo: "La simulación L4 tiene requisitos más altos para la reproducibilidad de la escena, es decir, si un problema que se encuentra en la carretera se puede reproducir en el entorno de simulación; pero muchas empresas que hacen simulación L2 no han pensado en esta pregunta. ."
4. Atención a las capacidades de minería de datos
Para la simulación de conducción autónoma de bajo nivel, todos luchan principalmente por la autenticidad de la escena, mientras que la conducción autónoma de alto nivel presta más atención a la extracción de datos.
5. Composición de datos
Bao Shiqiang, persona a cargo del negocio de simulación de vehículos en 51 WORLD: "L2 tiene una definición de funciones relativamente clara, y la simulación puede basarse principalmente en datos sintéticos, complementados con datos de carreteras reales; y en la etapa L4, la importancia de impulsado por datos será más alto. Por lo tanto, es necesario basarse principalmente en datos de carreteras reales, complementados con datos generados por algoritmos".
6. Percepción
Los vehículos autónomos de alto nivel tienen una gran cantidad de cámaras y muchos píxeles, lo que plantea requisitos más altos para la capacidad de representación de imágenes, la capacidad de sincronización de datos y la estabilidad del motor de simulación del sistema de simulación.
7. mapa de alta definición
Li Yue, CTO de Zhixing Zhongwei: "Básicamente, la conducción autónoma de bajo nivel no requiere mapas de alta precisión, pero la conducción autónoma de alto nivel depende en gran medida de mapas de alta precisión en la etapa actual, que es una de las razones por las que es necesario construir un gemelo digital al construir una escena, en comparación con el mundo real”.
8. Toma de decisiones
Li Yue, CTO de Zhixing Zhongwei: "El plan L2 presta más atención a la lógica estratégica de la toma de decisiones y la prueba de la agencia ejecutiva, pero no se enfoca en el algoritmo de planificación. Sin embargo, en el plan L4, cómo evitar obstáculos y cómo eludir Hay más consideraciones en los algoritmos de planificación de rutas, como las carreteras".
9. ¿Se requiere un modelo de controlador?
Para la conducción automática de bajo nivel, el sistema no controlará completamente el comportamiento del vehículo, sino que solo desempeñará un papel auxiliar. Por lo tanto, las empresas de simulación necesitan diseñar muchos modelos de conductor al diseñar la escena; dijo que el control del vehículo se realiza a través de la conducción automática. Por lo tanto, no es necesario diseñar un modelo de controlador en el diseño de la escena de simulación.
10. Si configurar el proceso de prueba por adelantado
Con respecto a esta lógica, la cuenta pública "Car Road Slowly" explicó con más detalle en un artículo:
La complejidad y el rango de condiciones de trabajo que enfrenta la conducción automática de nivel inferior son relativamente pequeños, o debido a que el comportamiento de conducción es principalmente responsable de los conductores humanos, el sistema de conducción automática solo necesita lidiar con un número limitado de condiciones de trabajo definidas; El comportamiento de conducción de conducción automática de alto nivel está principalmente a cargo del sistema de conducción automática, y la complejidad y el rango de condiciones de trabajo que maneja son muy grandes, y ni siquiera se pueden predecir de antemano.
En función de esta diferencia entre los dos, la conducción autónoma de nivel inferior se puede probar mejor utilizando métodos de prueba basados en casos de uso, mientras que la conducción autónoma de nivel superior requiere métodos de prueba basados en escenarios.
El método de prueba basado en el caso de uso es preestablecer la entrada de prueba y el proceso de prueba, y evaluar si se pasa la prueba comprobando si el algoritmo probado logra la función esperada. Por ejemplo, en la prueba de ACC, se preestablece la velocidad inicial del vehículo bajo prueba y el vehículo en frente, así como el tiempo de desaceleración y la desaceleración del vehículo en frente, y verifique si el vehículo bajo prueba puede seguir la desaceleración para detener.
El método de prueba basado en escenarios es para preestablecer la entrada de prueba , pero no preestablece el proceso de prueba, solo establece el comportamiento de los vehículos de tráfico, le da al algoritmo probado un mayor grado de libertad y verifica si el algoritmo probado logra lo esperado. objetivo Evaluar si pasar la prueba . Por ejemplo, en la prueba de conducción en carretera recta, se preestablecen la velocidad inicial del vehículo bajo prueba y el vehículo de delante, así como el tiempo de desaceleración y la desaceleración del vehículo de delante, pero no está limitado si el vehículo bajo test evita la colisión con el vehículo de delante desacelerando o cambiando de carril.
Una de las razones para usar diferentes métodos de prueba para diferentes niveles de funciones de conducción automática es que la conducción automática de bajo nivel generalmente se puede descomponer en funciones simples e independientes, y una sola función puede usarse como objeto de prueba; mientras que la conducción automática de alto nivel la conducción es más difícil Difícil de descomponer en funciones simples e independientes, por lo que todo el sistema automático de conducción o una parte relativamente grande del mismo debe tomarse como el objeto bajo prueba.
11. Ecología industrial
Yang Zijiang, fundador de Kechuang: "Desde la perspectiva de la ecología industrial, para L2, las empresas automotrices básicamente no desarrollarán su propia investigación, sino que adoptarán directamente soluciones de subcontratación, y la prueba se basará en HIL o incluso en pruebas de carretera; para el simulación de L4, muchas empresas de automóviles tenderán a iniciar su propia investigación a partir del SIL".
Pregunta 5: ¿Cómo entender los "miles de kilómetros por día" en la simulación?
De manera similar a la prueba en carretera real, algunas empresas de simulación también enfatizan el "kilometraje de conducción", por ejemplo, "cientos de miles de kilómetros por día", entonces, ¿cuál es el significado real detrás de este número? ¿Cómo se compara con el kilometraje en carreteras reales?
El kilometraje virtual se refiere a la suma del kilometraje de una plataforma de simulación masiva en nodos de simulación paralelos por unidad de tiempo. El kilometraje de la simulación por unidad de tiempo depende de la cantidad de nodos admitidos por la potencia de cómputo de toda la plataforma y el índice de súper tiempo real bajo la complejidad de la escena de simulación diferente.
En pocas palabras, un nodo de simulación es un vehículo, es decir, cuántos "vehículos de prueba" puede soportar la plataforma de simulación funcionando en paralelo al mismo tiempo.
Según An Hongwei, director ejecutivo de Zhixing Zhongwei, explicó: En pocas palabras, si una plataforma de simulación tiene la potencia de cómputo de 100 servidores GPU y cada uno implementa 8 instancias de simulación, entonces la plataforma de simulación tiene la capacidad de paralelizar 800 simulaciones al mismo tiempo. Mismo tiempo. El kilometraje de la simulación depende del kilometraje diario de cada instancia.
La cantidad de instancias que se pueden ejecutar en un servidor GPU depende del rendimiento de la GPU y de si el solucionador de simulación se puede simular en paralelo en un servidor .
An Hongwei dijo: "Los nodos de simulación de nuestra plataforma de simulación en la nube han realizado una variedad de métodos de implementación, que pueden cumplir de manera flexible las condiciones de varios recursos en la nube de los clientes y pueden lograr una implementación de nodos flexible y a gran escala. Actualmente estamos construyendo en Xiangcheng, Suzhou. Su plataforma de simulación en la nube ha logrado el despliegue de más de 400 nodos".
Combinado con el kilometraje diario de cada instancia, el kilometraje de simulación diario total en la plataforma de simulación se puede calcular aproximadamente. Si una instancia (automóvil virtual) corre un promedio de 120 kilómetros por hora y funciona las 24 horas del día, entonces son casi 3.000 kilómetros por día. Si hay 33 instancias, entonces hay casi 100.000 kilómetros por día en este servidor.
Sin embargo, según An Hongwei, la simulación "miles de miles de kilómetros por día" a la que suele referirse la industria no es muy rigurosa. " Debe estar respaldado por un plan de prueba de simulación razonable y una gran cantidad de escenarios, y la cobertura y efectividad de los escenarios debe expandirse continuamente. Finalmente, los escenarios efectivos que se pueden ejecutar son fundamentales " .
Pregunta 6: Súper simulación en tiempo real
Durante la entrevista, el autor hizo una pregunta repetidamente: ¿Los autos que se ejecutan en la plataforma de simulación están en la misma dimensión de tiempo que los autos en el mundo real? Dicho de otra manera: ¿1 hora en la plataforma de simulación es igual a 1 hora en el mundo real? ¿Habrá una situación de "un año en la tierra, diez años en el cielo"?
La respuesta es: puede ser igual a (simulación en tiempo real), o no igual a (simulación en tiempo súper real). La simulación en tiempo ultra real se puede dividir en dos casos de "aceleración del tiempo" y "desaceleración del tiempo": la aceleración del tiempo significa que el tiempo en la plataforma de simulación es más rápido que el tiempo en el mundo real, y la desaceleración del tiempo significa que el tiempo en la plataforma de simulación es más lento que en el mundo real.
La simulación es más rápida que el tiempo del mundo real para la eficiencia, entonces , ¿por qué es más lenta que el tiempo del mundo real ?
La explicación de Hongwei es: "Por ejemplo, algunas pruebas de simulación requieren una precisión muy alta en la representación de imágenes. Para lograr la precisión, es posible que la representación de una imagen de un solo cuadro no se complete en tiempo real. Este tipo de simulación es más lenta que la real". tiempo, en lugar de hacer pruebas de circuito cerrado en tiempo real, está haciendo pruebas fuera de línea”.
Específicamente, en la simulación en tiempo real, después de generar la imagen, se envía directamente al algoritmo para su reconocimiento. Este proceso puede completarse en 100 milisegundos, pero en la simulación fuera de línea, la imagen se guarda primero después de la generación y se envía al algoritmo en condiciones fuera de línea.
Según la explicación de An Hongwei, se deben cumplir los siguientes dos requisitos previos para la simulación en tiempo ultra real en la plataforma de simulación: los recursos informáticos del servidor son lo suficientemente potentes; el algoritmo bajo prueba puede recibir tiempo virtual.
Los algoritmos pueden aceptar el tiempo virtual, ¿cómo entiendes esto? La explicación de Hongwei es que algunos algoritmos pueden necesitar leer el servicio de tiempo en el hardware o el servicio de tiempo de la red bajo la condición de combinar la plataforma de ejecución del hardware, pero no pueden leer el tiempo virtual proporcionado por el sistema de simulación.
Un experto en simulación de nivel 1 dijo: Se puede lograr una alineación y sincronización de tiempo precisas en el marco de ingeniería del sistema de simulación, PoseidonOS, y luego el algoritmo se puede implementar en servidores de clúster, de modo que el tiempo en el espacio de simulación se pueda desacoplar del tiempo. en el mundo físico real Una vez que lo desatas, puedes "acelerar a voluntad".
Entonces, al hacer la aceleración del tiempo, ¿puede acelerarse 2 o 3 veces? ¿De qué depende este factor de aceleración?
La respuesta de Hongwei es: los recursos informáticos del servidor, la complejidad del escenario de prueba, la complejidad del algoritmo y la eficiencia operativa del algoritmo. Es decir, en teoría, bajo las condiciones de la misma complejidad de escena y el mismo algoritmo, cuanto más potentes sean los recursos de cómputo del servidor, más tiempos de aceleración posibles se pueden lograr.
¿Cuál es el límite superior del múltiplo de aceleración del tiempo? Tenemos que combinar el principio de la aceleración del tiempo para responder a esta pregunta.
Según el responsable de la simulación de una empresa de conducción autónoma, debido a la inconsistencia de la complejidad del algoritmo y otras razones, la velocidad de cálculo del módulo de entrenamiento, el módulo de control del vehículo y otros módulos es diferente, y el método más convencional de súper tiempo real es usar el cálculo de cada módulo involucrado en el cálculo. Hacer programación unificada. La llamada aceleración significa que el módulo con una mayor velocidad de cálculo "cancela el tiempo de espera" -no importa si no ha terminado de calcular otro módulo, sincronizaré cuando se acabe el tiempo.
Si la diferencia de periodo de cálculo entre módulos es demasiado pequeña, el tiempo de espera para la cancelación es muy pequeño, por lo que el factor de aceleración será muy bajo; por el contrario, si la diferencia de periodo de cálculo de cada módulo es especialmente grande, por ejemplo , tarda 1 segundo, y el otro tarda 100 segundos, por lo que no hay forma de "cancelar la espera".
Por lo tanto, el múltiplo de la aceleración del tiempo a menudo es limitado: 2-3 veces se considera muy alto.
Incluso, muchos expertos dijeron que en la práctica es difícil realmente acelerar el tiempo.
Yang Zijiang, el fundador de Shenxin Kechuang, dijo que si el algoritmo del sistema de conducción automática ha sido compilado e implementado en el controlador de dominio o computadora industrial (este es el caso en la etapa HIL), solo puede ejecutarse en tiempo real en el sistema de simulación: en este momento, la simulación en tiempo súper real no es factible.
An Hongwei también dijo: "Hardware-in-the-loop (HIL, simulación de hardware-in-the-loop) en sí mismo debe ser una simulación en tiempo real. No existe el concepto de 'supertiempo real', y los términos ' simulación paralela' o 'aceleración del tiempo' no son aplicables".
Bao Shiqiang dijo: "La premisa de la aceleración del tiempo es el control preciso del tiempo y la sincronización del tiempo. Es difícil acelerar la percepción porque las frecuencias de los diferentes sensores son diferentes. La cámara puede ser de 30 Hz y el lidar es de 10 Hz, similar a esto, ¿cómo te aseguras de que las señales de diferentes sensores puedan estar fuertemente sincronizadas?"
Además, un experto en simulación que ha trabajado en Silicon Valley durante muchos años cree que ninguna empresa puede realmente lograr una simulación en tiempo ultra real. En opinión de este experto, para mejorar la eficiencia de la simulación, la simulación paralela masiva es una solución más deseable.
An Hongwei cree que la capacidad de aceleración del tiempo depende del nivel de súper tiempo real de cada instancia, el número total de instancias y la calidad de la escena. "En realidad, para la simulación de potencia de computación en la nube, el nivel de tiempo ultra real en una sola instancia no es muy importante. El núcleo es centrarse en la calidad de la simulación en esta instancia".
Los expertos en simulación de Qingzhou Zhihang incluso creen que el término "múltiplo de aceleración" en realidad no es cierto. Porque, entre el tiempo en la simulación y el tiempo en el mundo real, no hay una relación múltiple simple, ni siquiera tienen una relación. En la práctica, se utilizan medios más técnicos para reducir la ocupación de la potencia informática y mejorar la eficiencia de la programación de tiempo para lograr la mejora del tiempo informático.
En la prueba de carretera real, el vehículo conduce continuamente. No diría que este es un caso de esquina. Lo ejecutaré. No es un caso de esquina. Caso de esquina; en la plataforma de simulación, los ingenieros generalmente solo capturan los fragmentos relacionados con el caso de la esquina (es decir, "escenas efectivas"). Después de procesar este asunto, el reloj saltará al siguiente período de tiempo sin necesidad de perder tiempo en la escena.
Por lo tanto, cuando se realiza una simulación, la forma de descartar de manera eficiente los escenarios efectivos es más importante que el factor de aceleración del tiempo.
Hablando de esto, podemos encontrar que aunque la aceleración del tiempo no parece ser obvia, pero para aumentar el kilometraje virtual en la plataforma de simulación, de hecho, no podemos confiar principalmente en la aceleración del tiempo. La clave es confiar en "simultaneidad de instancias múltiples", que en realidad consiste en realizar una simulación de potencia de computación en la nube y aumentar la cantidad de servidores e instancias de simulación .
Pregunta 7: Pruebas simultáneas a gran escala
¿Puede admitir una alta concurrencia en la nube y qué escala de concurrencia admite? ¿Dónde está la dificultad? ¿Es suficiente confiar solo en los servidores de almacenamiento dinámico?
Suena bien, pero el problema es que cada aumento de orden de magnitud en el tamaño del servidor trae nuevos problemas :
(1) El costo de los servidores es bastante alto. Cada servidor es de cientos de miles. Si hay 100 servidores, el costo directo es de decenas de millones. La solución ideal es ir a la nube pública, pero los OEM nacionales aún deben aceptar la nube pública un período de tiempo;
(2) En el caso de concurrencia a gran escala, los datos sin procesar del sensor son extremadamente grandes. El costo de almacenamiento de estos datos es muy alto y la transmisión también es difícil: la sincronización de datos en diferentes servidores causará demoras, lo que afectará la eficiencia de Zhixing;
(3) Lo que se ejecuta en cada vía no es una escena de flujo de tráfico continuo, sino un segmento muy corto, tal vez de solo 30 segundos, pero por lo general miles de vías se ejecutan en paralelo, si 1000 vías tienen 1000 algoritmos que se ejecutan en 1000 escenas, lo que plantea una serio desafío para el diseño de la arquitectura de la plataforma de simulación. (CEO de una empresa de simulación)
Sin embargo, con respecto al último elemento anterior, An Hongwei dijo: Este es un requisito básico para la simulación de potencia de computación en la nube, y no es un desafío para nosotros. La plataforma de simulación en la nube en el distrito de Xiangcheng, Suzhou, resolvió este problema ya en 2019. Además, las escenas que se ejecutan en la plataforma de simulación en la nube también tendrán varios kilómetros de escenas complejas/combinadas continuas.El sistema de evaluación de simulación Robo-X de Xiangcheng incluye tales escenas (grupales). En base a tales escenarios, se puede realizar una prueba de "toma de control" bajo simulación virtual.
Pregunta 8: ¿Cuál es el indicador más crítico para medir la solidez de las capacidades de simulación de una empresa?
En la etapa actual, las simulaciones de diferentes empresas son bastante diferentes desde la cadena de herramientas hasta los datos de la escena utilizados, desde la metodología hasta la fuente de los datos. Todo el mundo habla de "simulación", pero no necesariamente del mismo concepto. Entonces, ¿cuáles son los indicadores más críticos para medir la solidez de las capacidades de simulación de una empresa? Después de esta ronda de entrevistas, obtuvimos las siguientes respuestas:
1. Reproducibilidad
Es decir, si los problemas encontrados en la prueba de carretera real pueden reproducirse en el entorno de simulación. (Navegación inteligente con barcos ligeros, viaje inteligente al final del día)
Este tema se discutirá con más detalle en la segunda mitad de este artículo.
2. Capacidad de definición de escena
Es decir, si el escenario de simulación definido por la empresa realmente puede ayudar a mejorar la capacidad real de adelantamiento de la conducción autónoma.
3. Capacidad de adquisición de datos de escena
Adquisición de datos de escena, capacidad de producción, versatilidad de datos y reutilización.
4. Calidad y cantidad de datos de escena
Es decir, qué tan cerca está la escena de simulación de la escena real, la precisión, la confianza y la actualización de los datos de la escena, y la cantidad de escenas válidas, y si hay suficientes datos masivos de la escena de simulación para soportar la simulación paralela de varias instancias.
5. Eficiencia de simulación
Es decir, cómo automatizar y hacer eficientemente la minería de datos para generar el modelo de entorno requerido para la simulación, para encontrar rápidamente problemas reales.
6. Arquitectura Técnica
Es decir, si existe un sistema técnico completo de circuito cerrado adecuado a las necesidades del objeto ensayado. (AIE Zhixing Zhongwei Li Yue)
7. Si tiene la capacidad de realizar pruebas simultáneas a gran escala
Solo en una prueba a gran escala (la cantidad de instancias y escenarios es lo suficientemente grande), una empresa puede crear un sistema de evaluación para la precisión del modelo, la estabilidad del sistema, etc., que prueba la gestión de datos, la extracción de datos, la programación de recursos y otros de una empresa. capacidades. (QingzhouZhihang)
8. Precisión de la simulación
La simulación orientada a la regulación y la simulación orientada a la percepción tienen diferentes requisitos de precisión: la primera puede depender del modelo de dinámica del vehículo, qué niveles de abstracción existen y la granularidad del comportamiento de interferencia en el flujo de tráfico; la última puede depender de diferentes sensores basados en el ruido. agregado por diferentes principios de imagen, etc.
Por lo general, debido a consideraciones de costo, los usuarios esperan que la arquitectura técnica se pueda usar universalmente. Sin embargo, una solución demasiado general sacrificará la precisión en algunos aspectos: la precisión del modelo, la eficiencia del modelo y la versatilidad del modelo son una relación triangular.
Cuando se trata de la autenticidad de los datos de simulación, debemos agregar otra pregunta: MANA ha introducido escenarios de flujo de tráfico real en el sistema de simulación. El flujo de tráfico real en cada momento se registra y luego se importa al motor de simulación a través de log2world. Después de agregar el modelo de controlador, se puede usar para depurar y verificar la escena de la intersección. Entonces, ¿cómo garantizar la exactitud de este tipo de datos?
Al respecto, el experto en simulación de Momo dijo: "En la actualidad, este tipo de datos se utilizan principalmente para el desarrollo y prueba de módulos cognitivos, por lo que lo que necesitamos es un comportamiento dinámico del tráfico lo más realista posible. Los datos en sí están discretizados para el mundo continuo. , siempre que la frecuencia de recolección satisfaga las necesidades de los cálculos de algoritmos cognitivos, no necesitamos comparar estos datos con el valor verdadero (y no hay forma de obtener el valor de verdad absoluto). perseguimos es la racionalidad de la acción y la variedad, no la precisión".
9. Consistencia entre la prueba de simulación y la prueba del vehículo real
Un ingeniero de simulación de una empresa de conducción no tripulada de vehículos comerciales dijo que a menudo encontraron que los resultados de la prueba SIL eran opuestos a los de la prueba en carretera real: no hubo problemas en la prueba en carretera real, pero hubo problemas en el SIL. ; y hubo problemas en la prueba de carretera real Problema escenario, pero ningún problema en SIL.
Una persona a cargo de la simulación de conducción autónoma de un OEM dijo que cuando estaban haciendo pruebas HIL, encontraron que el desempeño del vehículo en la escena de la simulación era más o menos diferente de su desempeño en la carretera real. Las razones de esta diferencia pueden ser: (1) el sensor virtual, EPS, etc. no son completamente consistentes con el vehículo real; (2) la escena virtual no es completamente consistente con la escena real; (3) el estándar de dinámica del vehículo No puedo hacerlo bien.
10. El papel de la simulación en el sistema de I+D de la empresa
La tasa de penetración de la simulación en el negocio real, es decir, la proporción de datos de simulación en la totalidad de los datos de uso comercial en el proceso de I+D, y si la simulación se utiliza como herramienta básica para I+D y pruebas. (Experto en simulación milimétrica)
1 1. Ya sea para formar un circuito cerrado comercial
Un experto en simulación de una empresa de conducción autónoma dijo: "Para una empresa de simulación, es más importante tomar la iniciativa en la construcción de un circuito cerrado comercial que las ventajas de la tecnología en sí".
Bao Shiqiang, jefe de simulación de vehículos en 51 World, dijo que los puntos principales a los que los clientes prestan atención cuando eligen un proveedor de simulación son: A. ¿El módulo de simulación es lo suficientemente completo? B. ¿Qué tipo de cadena de herramientas puede proporcionarle? C. La apertura de la plataforma de simulación.
Hablando de apertura, Bao Shiqiang dijo: "La tendencia general es que los usuarios no quieren comprar directamente un software para resolver un problema específico, sino que quieren construir su propia plataforma. Por lo tanto, prefieren simular los módulos técnicos del proveedor. Puede empoderarlos para construir sus propias plataformas de simulación. Por lo tanto, los proveedores de simulación deben considerar cómo diseñar interfaces API, cómo integrarse con los módulos existentes de los clientes e incluso abrir parte del código a los clientes".
Adjunto: Cómo mejorar la reproducibilidad de la escena
Empresas como Qingzhou Zhihang consideran que "si un problema que se encuentra en la carretera se puede reproducir en el entorno de simulación" es uno de los indicadores más críticos para medir la solidez de las capacidades de simulación de una empresa. Entonces, ¿qué factores afectarán la reproducibilidad de la escena?
Con esta pregunta en mente, el autor interrogó repetidamente a muchos expertos y obtuvo las siguientes respuestas:
1. El modelo del vehículo, el modelo del sensor, el modelo de la carretera y el modelo meteorológico pueden diferir de la situación real.
2. Los criterios de evaluación de la nube y el coche pueden no ser los mismos.
3. El tiempo de comunicación y el tiempo de programación en el sistema de simulación son inconsistentes con el tiempo en el vehículo real. Por ejemplo, al recibir un mensaje, si accidentalmente recibe un marco temprano o un marco tarde, y finalmente bajo el efecto mariposa, la diferencia será muy grande.
4. Los parámetros de control del vehículo en el sistema de simulación son inconsistentes con el vehículo real. En la prueba real del vehículo, el acelerador, el freno, el volante y las llantas existen en forma física, pero no existen tales componentes físicos en el sistema de simulación, por lo que solo se pueden usar métodos de simulación. manejado bien, el realismo de la simulación se verá comprometido.
5. Los datos de la escena en el sistema de simulación están incompletos. Al hacer la simulación, es posible que solo capturemos un segmento determinado de la escena, como que los datos de unos segundos antes y después del semáforo no estén disponibles.
6. El problema puede estar cubierto por el lenguaje lógico que describe el entorno, y el nivel y la cobertura de la definición del lenguaje pueden no ser perfectos.
7. La adaptabilidad del software de simulación en sí mismo a varios escenarios no es lo suficientemente buena, el cambio entre idiomas no es fluido y es difícil admitir la operación de múltiples nodos a gran escala.
8. Los datos en el camino real tienen muchas variables. Al hacer la simulación, para encontrar problemas lo antes posible, los ingenieros deben "asumir" que ciertos parámetros permanecen sin cambios para reducir la interferencia en una variable clave.
9. La secuencia de cálculo entre la percepción, la predicción, el posicionamiento y otros módulos de conducción autónoma puede ser diferente en la nube y en el lado del automóvil, o es posible que el lado del automóvil no registre cierta información estrictamente, siempre que haya un marco Las diferencias pueden conducir a problemas con un resultado.
10. Si es un problema a nivel de percepción, la reproducción de la escena debe lograr una mejor generación inversa de la escena 3D y luego aumentar los datos a través de la generalización y la transformación de la perspectiva.Cada paso aquí es un poco difícil. Si es un problema a nivel regulatorio, para reproducir con precisión la escena, es necesario identificar el comportamiento de interacción y los parámetros clave de la escena, para generar y activar la escena con precisión. (Creo firmemente en Yang Zijiang, el fundador de Kechuang)
El escenario desencadenante se refiere a si se realiza el contenido que este escenario quiere probar. Por ejemplo, si un peatón cruza repentinamente la carretera frente al automóvil principal, si el automóvil principal pasa junto al peatón antes de irse, no se logrará el efecto de prueba, es decir, la escena no se activará. Por ejemplo, si un peatón cruza la calle y luego da la vuelta, la velocidad a la que camina, el tiempo para dar la vuelta y la velocidad del vehículo principal son críticos. Se trata de una sola persona en bicicleta. Los participantes de tráfico múltiple son mucho más complicados y la relación entre ellos está acoplada. Incluso si un parámetro se desvía ligeramente, el efecto de la simulación se reducirá considerablemente.
Al escribir este artículo, se citó una gran cantidad de conocimientos sobre productos secos de la cuenta pública de WeChat "Car Road Slowly". El autor de la cuenta oficial, Li Slowly, es un ingeniero de simulación. Esta cuenta se enfoca en clasificar la experiencia en simulación y recomienda amigos que estén interesados en esta pista para seguir.

Referencias:
Una revisión súper completa de la simulación de conducción autónoma: desde escenarios de simulación, sistemas hasta evaluación
https://zhuanlan.zhihu.com/p/321771761
Lectura recomendada:
escribir al final
Acerca de la contribución
Si está interesado en contribuir a "Conducción inteligente de nueve capítulos" (artículos de tipo "acumulación y clasificación de conocimientos"), escanee el código QR a la derecha y agregue el WeChat del personal.

Nota: asegúrese de anotar su nombre real, empresa y puesto actual al agregar WeChat
Y la información sobre la posición de interés, ¡gracias!
Requisitos de calidad para manuscritos de "acumulación de conocimiento":
R: La densidad de la información es más alta que la mayoría de los informes de la mayoría de las casas de bolsa, y no más baja que el nivel promedio de "Conducción inteligente de nueve capítulos";
B: La información tiene que ser muy escasa, más del 80% de la información tiene que ser invisible en otros medios, si se basa en información pública tiene que tener un punto de vista especialmente potente y exclusivo. Gracias por su comprensión y apoyo.
Lectura recomendada:
◆ Nueve capítulos: una colección de artículos en 2022
◆Dedicado a "la primera ciudad de conducción autónoma" - un "movimiento de la capital"
◆ El radar de ondas milimétricas 4D se explica claramente en el texto extenso de 4D
◆ Aplicación de algoritmo de aprendizaje profundo en regulación y control de conducción automática
◆ Desafíos y comienzo del cambio de control de cables a producción en masa y uso comercial