Каталог статей
Бинарный поиск и поиск различий
Метод бинарного поиска и метод поиска различий в основном одинаковы, различается только один код, и они объединены для описания
Сначала поговорим о бинарном поиске
обзор
Двоичный поиск также называют бинарным поиском (Binary Search), который является более эффективным методом поиска. Однако бинарный поиск требует, чтобы линейная таблица имела последовательную структуру хранения, а элементы в таблице располагались в порядке согласно ключу .
Энциклопедия Baidu: во-первых, предполагая, что элементы в таблице расположены в порядке возрастания, сравните ключевые слова, записанные в средней позиции таблицы, с ключевыми словами поиска.Если они равны, поиск выполнен успешно, в противном случае используйте записи в средней позиции, чтобы разделить таблицу на переднюю и заднюю подгруппы.таблица, если ключ, записанный в средней позиции, больше ключа поиска, то выполняется дальнейший поиск в предыдущей подтаблице, в противном случае - в последней подтаблице. искал. Повторяйте описанный выше процесс до тех пор, пока не будет найдена запись, соответствующая условию, что сделает поиск успешным, или пока дочерняя таблица не будет существовать, в это время поиск не увенчался успехом.
выполнить
Предпосылка метода бинарного поиска заключается в том, что последовательность упорядочена. Далее
предполагается, что последовательность отсортирована от меньшего к большему. Идея
: используйте рекурсию, чтобы разделить последовательность пополам в соответствии с отношением размера между значением, которое вы ищете. и среднее значение, и рекурсивно, пока искомое значение не будет равно среднему значению, или элементы в массиве рекурсивно потеряны.
Дальнейшие идеи: Во-первых, последовательность, мы находим значение в середине последовательности и используем это значение для сравнения с искомым значением. Если значение больше, то берем последовательность слева от этого значения и выполняем предыдущую операцию (то есть операцию нахождения среднего значения и сравнения его с искомым значением). Если значение мало, возьмите последовательность справа от значения и выполните такую операцию. Если два равны, значит, оно найдено, тогда записываем индекс промежуточного значения, и ищем одно и то же значение с обеих сторон от этого индекса (в это время массив в порядке, и его легко найти, есть ли одно и то же значение). Если это так, также запишите индексы этих значений и верните набор этих индексов. Если он не был найден, то при отсутствии данных в последовательности цикл также завершится.В это время это означает, что общая
идея не была найдена: Напишите метод как тело рекурсивного метода.Этот метод получает четыре параметра, а именно: исходная последовательность (здесь мы используем массив), значения индекса начальной и конечной точек массива в массиве, необходимом для каждой рекурсии, и значение для поиска. Функция значений индексов двух точек состоит в том, чтобы разделить последовательность пополам, Мы делим последовательность пополам на разницу входных значений двух индексов в каждой рекурсии. Начальная и конечная точки определяют, над какой частью последовательности в массиве работает текущая рекурсия.
В теле метода мы сначала получаем индекс среднего значения текущего массива, затем получаем среднее значение, а затем сравниваем размер среднего значения с искомым значением.
Если промежуточное значение велико, введите следующую рекурсию и передайте индекс параметра конечной позиции (индекс промежуточного значения + 1) среди параметров, переданных следующей рекурсией, индекс начальной позиции останется неизменным , и другие параметры также остаются без изменений
Если промежуточное значение мало, то входим в следующую рекурсию В параметрах, передаваемых в следующей рекурсии, передается индекс параметра начальной позиции (индекс промежуточного значения + 1), индекс конечной позиции остается неизменным, остальные параметры также остаются неизменными.
Если они равны, это означает найти положение этого значения в последовательности, записать индекс этого промежуточного значения и искать одно и то же значение от этого индекса в обе стороны (в это время последовательность в порядке, и легко найти не одинаковые значения)
если да, то также запишите индексы этих значений и верните набор этих индексов.
В качестве тела рекурсивного метода мы должны рассматривать рекурсию, поэтому в этом теле метода в начале мы должны судить, достигнуто ли другое условие конца рекурсии, т. е. больше ли начальная позиция, чем исходная. конец рекурсии в это время. Если оно больше позиции,
это означает, что искомые данные не найдены в этом массиве, и сразу возвращается пустой набор. Здесь нужно знать несколько ситуаций: когда начальная позиция равна конечной позиции, это означает, что в данный момент в последовательности есть только одни данные, если больше, то это означает, что данных нет.
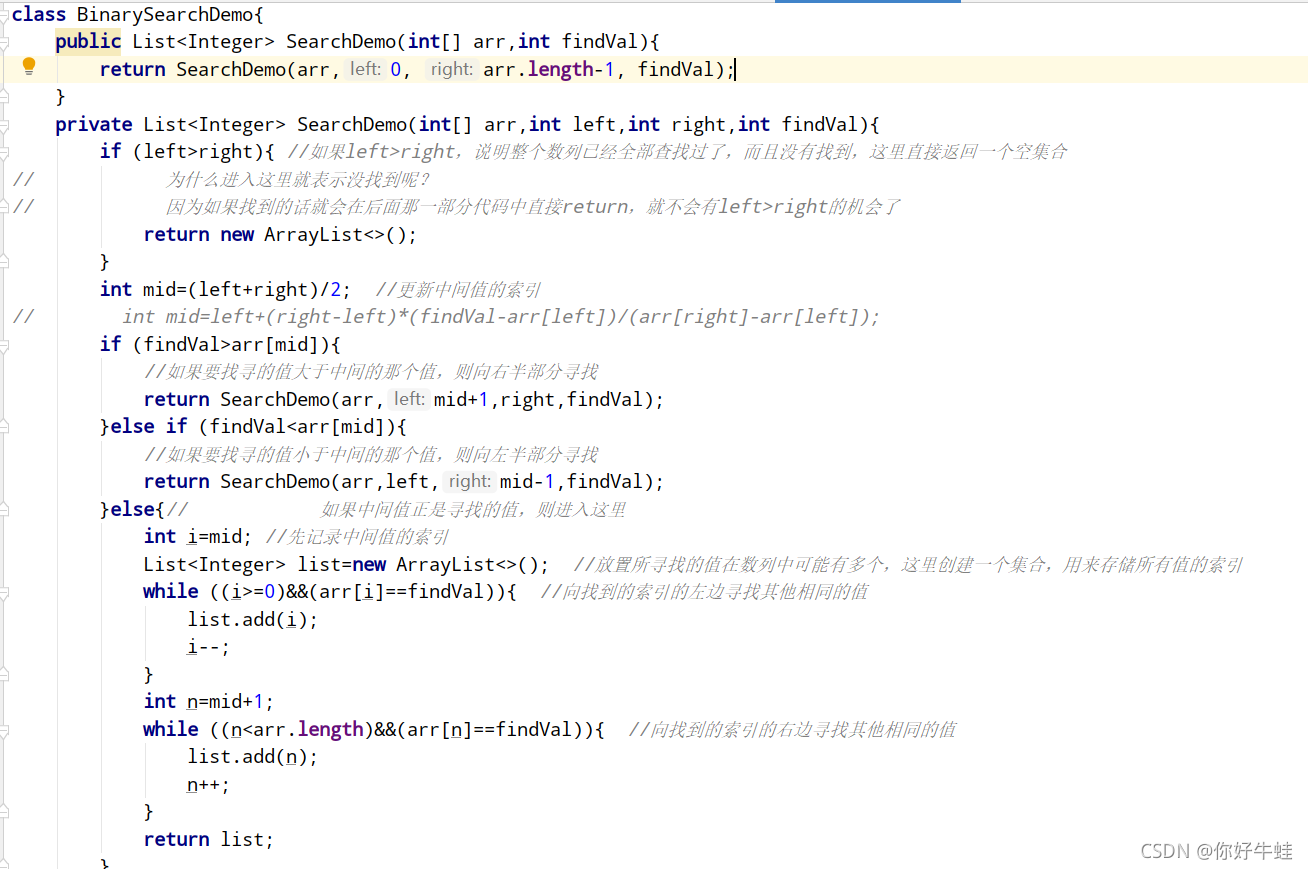
Выше приведен основной код бинарного поиска.
Есть лишь небольшая разница между бинарным поиском и поиском разности, то есть обновить значение промежуточного значения и судить об условиях выхода из рекурсии по
int mid=left+(right-left)*(findVal-arr[left])/(arr[right]-arr[left]);
энциклопедии Baidu: интерполяционный поиск , метод поиска для упорядоченных таблиц. Интерполяционный поиск — это метод поиска, основанный на сравнении ключа поиска с максимальным и минимальным ключами записи в таблице поиска. Интерполяционный поиск основан на бинарном поиске, который улучшает выбор точек поиска до адаптивного выбора и повышает эффективность поиска.
Адаптивный здесь относится к его особому методу обновления среднего значения
В интерполяционном поиске адаптивная формула среднего выглядит так: Не знаю, откуда эта формула, int mid=(left+right)/2;но int mid=left+(right-left)*(findVal-arr[left])/(arr[right]-arr[left]);
она действительно может ускорить поиск
. условное суждение об окончании рекурсии, его нужно изменить:

Еще один левый = правый, это предотвращает arr[right]-arr[left]=исключение деления на 0, вызванное 0.
Позже findVal<arr[0]||findVal>arr[arr.length-1]это означает, что если данные, которые вы ищете, больше, чем самый большой элемент массива или меньше, чем самый маленький элемент массива, он будет возвращен напрямую.Первый может ускорить, но он же и самый важный.Смысл в том,чтобы индекс массива не пересекал границы,потому что данные, которые вы ищете,также участвуют в операции,предотвращая мид от слишком большой из-за больших данных, которые вы ищете, и заставляет индекс массива пересекать границы.
Не знаю почему, но при тестировании я столкнулся с несколькими случаями мертвой рекурсии, и индекс промежуточного значения постоянно зацикливался на числе, или просто зацикливался на числе.
Полный код:
import java.util.ArrayList;
import java.util.List;
public class BinarySearch {
public static void main(String[] args) {
BinarySearchDemo searchDemo=new BinarySearchDemo();
int[] array={
1,2,3,4,5,6,7,8,9,10,11,12};
int Array[]=new int[8000];
for (int i = 0; i < 8000; i++) {
Array[i]= (int) (Math.random()*8000);
}
QuickSortDemo sortDemo=new QuickSortDemo();
sortDemo.SortDemo(Array);
Long time1=System.currentTimeMillis();
System.out.println(searchDemo.SearchDemo(Array, 452));
System.out.println("耗时(毫秒)"+(System.currentTimeMillis()-time1));
}
}
//二分查找方法前提是数列是有序的
//下面假设数列是从小到大排序
//思路:用递归按照所寻找的数值与中间值的大小关系,对数列进行对半分,一直递归到所寻找的数值等于中间值或者数列中的元素给递归没了
//进一步思路:首先一个数列,我们找到数列中间的那个值,用此值和所要寻找的值进行大小比较,若此值更大,则取此值左边的数列再执行前面的操作(即找中间值再和所寻找的值比大小的操作)
//若此值小,则取此值右边的数列进行再进行这样的操作,若两者相等,则表示找到了,则记录此中间值的索引,并从此索引向两边找一下看有没有相同的值(此时数列有序,可很简单的找到是不是有相同值)
//若有,则也记录下这些值的索引然后返回这些索引的集合。若一直没找到,则当数列中没数据了,也结束循环,此时表示未找到
//大致思路:写一个方法,作为递归的方法体,此方法接收四个参数,分别是:原数列(这里我们用数组)、每次递归所需要数列在数组中的起始点和终止点的索引值、要寻找的值
//要两个点的索引值作用就是为了对数列进行中分,我们借由每次递归中,对两点索引传入值的不同来对数列进行对半分。起始终止两点决定了当前的递归是对数组中的那一部分数列进行操作
//在方法体中,我们先获得当前数列的中间值的索引,然后获得中间值,然后用中间值和所要寻找的值进行大小比较,
//若中间值大,则进入下一次递归,下一次的递归传入的参数中,把终止位置的参数索引传入(中间值的索引+1),起始位置索引不变,其他参数也不变
//若中间值小,则进入下一次递归,下一次的递归传入的参数中,把起始位置的参数索引传入(中间值的索引+1),终止位置索引不变,其他参数也不变
//若两者相等,则表示找到此值在数列中的位置,记录下此中间值的索引,并从此索引向两边找一下看有没有相同的值(此时数列有序,可很简单的找到是不是有相同值)
// 若有,则也记录下这些值的索引然后返回这些索引的集合。
//作为一个递归的方法体,我们得为递归进行考虑,所以在此方法体内,一开始,我们得先判断是否达到了递归结束的另一个条件,即是否此时递归中,起始位置是否大于终止位置,
// 若大于则表示在此数组中未找到所要寻找的数据,直接返回一个空集合。这里需要知道几种情况,当起始位置等于终止位置,则表示此时数列中仅有一个数据,若大于,则表示一个数据也没了
class BinarySearchDemo{
public List SearchDemo(int[] arr,int findVal){
return SearchDemo(arr,0, arr.length-1, findVal);
}
private List SearchDemo(int[] arr,int left,int right,int findVal){
if (left>=right||findVal<arr[0]||findVal>arr[arr.length-1]){
//如果left>right,说明整个数列已经全部查找过了,而且没有找到,这里直接返回一个空集合
// 这里需要再加一个=号,为了防止除0异常
return new ArrayList<>();
// 为什么进入这里就表示没找到呢?
// 因为如果找到的话就会在后面那一部分代码中直接return,就不会有left>right的机会了
}
// int mid=(left+right)/2; //更新中间值的索引
int mid=left+(right-left)*(findVal-arr[left])/(arr[right]-arr[left]);
int midValue = arr[mid];
if (findVal>midValue){
//如果要找寻的值大于中间的那个值,则向右半部分寻找
return SearchDemo(arr,mid+1,right,findVal);
}else if (findVal<midValue){
//如果要找寻的值小于中间的那个值,则向左半部分寻找
return SearchDemo(arr,left,mid-1,findVal);
}else{
// 如果中间值正是寻找的值,则进入这里
int i=mid; //先记录中间值的索引
List<Integer> list=new ArrayList<>(); //放置所寻找的值在数列中可能有多个,这里创建一个集合,用来存储所有值的索引
while ((i>=0)&&(arr[i]==findVal)){
//向找到的索引的左边寻找其他相同的值
list.add(i);
i--;
}
int n=mid+1;
while ((n<arr.length)&&(arr[n]==findVal)){
//向找到的索引的右边寻找其他相同的值
list.add(n);
n++;
}
return list;
}
}
}
Кстати, здесь я тестировал скорость поиска, QuickSortDemo sortDemo=new QuickSortDemo(); sortDemo.SortDemo(Array);а это быстрая сортировка, описанная в предыдущей статье.
Поиск Фибоначчи
Я думаю, что поиск Фибоначчи - очень странная вещь. Его также называют поиском золотого сечения. Как следует из названия, поиск Фибоначчи состоит в том, чтобы каждый раз делить последовательность от точки золотого сечения, а в остальном то же самое, что и бинарный поиск. Почему? Нужно ли делить по золотому сечению? ? ? Я действительно не понимаю этого, и во время теста я обнаружил, что скорость кажется еще меньше.В
этом поиске самое главное, как найти точку золотого сечения.Последовательность
Фибоначчи на самом деле очень замечательная последовательность.Чем дальше идет этот ряд, тем отношение предыдущего значения ряда к следующему бесконечно близко к значению золотого сечения, то есть 0,618... Здесь опущено бесконечно много знаков после запятой.
С помощью этой функции мы можем использовать последовательность Фибоначчи в качестве помощи, чтобы легко найти точку золотого сечения последовательности. Итак, это также называется поиском Фибоначчи.
обзор
Важно: этот поиск также должен основываться на упорядоченном массиве.
Энциклопедия Baidu: Поиск Фибоначчи разделен в соответствии с последовательностью Фибоначчи на основе бинарного поиска. Найдите число F[n] в последовательности Фибоначчи, которое немного превышает количество элементов в таблице поиска, и расширьте исходную таблицу поиска до длины F[n] (если вы хотите добавить элементы, добавьте и повторите последний элемент до момента Satisfy F[n] elements), после завершения выполнить сегментацию Фибоначчи, то есть F[n] элементов разделить на первую половину из F[n-1] элементов, а вторую половину из F[n -2] elements, узнайте, в какой части находится искомый элемент, и выполняйте рекурсию, пока не найдете его.
Проще говоря:
Прежде всего, этот метод поиска также является бинарным поиском, но это не среднее разделение.Количество элементов между начальной позицией последовательности и точкой разделения ближе к золотому сечению, чем количество элементов во всей последовательности Значение делится таким образом, чтобы найти точку разделения.Из-за особенностей последовательности Фибоначчи вы можете использовать значение в последовательности Фибоначчи, чтобы найти точку разделения, то есть сначала найти значение в последовательности Фибоначчи требуется, чтобы это значение (то есть F[n]) было больше или равно и ближе всего к количеству элементов в массиве, если F[n] больше, чем количество элементов в массив, затем расширьте исходный массив до длины F[n] , расширенная позиция будет заполнена 0.
Затем, поскольку последовательность Фибоначчи F[n]=F[n-1]+F[n-2] и F[n-1]/F[n] бесконечно близка к 0,618, что является значением золотого сечения , поэтому F
[n-1]-1 — это индекс точки разделения последовательности F[n]. Почему -1? Поскольку F[n-1] представляет длину, она начинается с 1, а индекс начинается с 0.
Поскольку F[n-2] — это значение перед F[n-1], поэтому F[n-1] деление точкой последовательности является F[n-2]-1
и так далее
, но обратите внимание на один момент: мы работаем с массивом, и индекс начальной позиции последовательности, которую нужно искать каждый раз, не обязательно 0, индекс Каждая точка разделения на самом деле起始位置索引+F[n-1]-1
выполнить
Идея реализации: сначала написать функцию для создания последовательности Фибоначчи для последующего использования,
а затем написать тело метода, которое является телом метода для реализации поиска Фибоначчи.Сначала использовать цикл для поиска числа, которое не меньше и ближайшее Значение последовательности Фибоначчи длины последовательности, а затем использовать цикл для расширения исходной последовательности до соответствующего размера,
а затем официально начать поиск, использовать цикл while, условие окончания цикла состоит в том, что есть нет данных в последовательности, то есть когда начальная позиция больше конечной позиции, или когда результат найден,
сначала найти точку разделения, а затем судить о соотношении между размером элемента точки разделения и размером данных, которые вы ищете.Если
точка разделения больше, найдите числовую последовательность слева после разделения и обновите требуемый индекс Фибоначчи значения (используется позже, чтобы найти точку разделения). Как обновить, подробно описано в комментариях к следующему коду.Если
точка разделения меньше, ищем последовательность справа от точки разделения, и обновляем индекс нужного значения Фибоначчи (для последующего поиска точки разделения). точка). Как обновить конкретно в комментариях к следующему коду.Код
выглядит следующим образом:
import java.util.Arrays;
public class FibonacciSearch {
public static void main(String[] args) {
FibonacciSearchDemo searchDemo=new FibonacciSearchDemo();
int[] array={
0,1,3,5,7,8,9,10,11,12,45,78,49};
int Array[]=new int[8000000];
for (int i = 0; i < 8000000; i++) {
Array[i]= (int) (Math.random()*8000000);
}
QuickSortDemo sortDemo=new QuickSortDemo();
sortDemo.SortDemo(Array);
Long time1=System.currentTimeMillis();
System.out.println(searchDemo.SearchDemo(Array, 12));
System.out.println("耗时(毫秒)"+(System.currentTimeMillis()-time1));
}
}
class FibonacciSearchDemo{
public int SearchDemo(int[] arr,int key){
int low=0; //记录数列的起始索引
int high= arr.length-1; //记录数列的终止索引
int[] fib=getFibArr(100); //接收斐波那契数列
int k=0;//用来记录所需的斐波那契数值在斐波那契数列中的索引
int mid;//mid用来记录数列中的中分点
// 在斐波那契数列中寻找一个数值,要求此值不小于数列的长度,且最接近数列的长度
while (high+1>fib[k]-1){
//为什么要加一?因为hight表示的是最大索引值,他和数列的长度差1
// 为什么fib[k]-1,因为我们要找到那个值不小于数列的长度,而且,是最接近数列的长度的那个值
k++;
}
// 数列的原长度可能达不到前面找到的那个数值的大小,这里需要将数列扩增
int[] temp= Arrays.copyOf(arr,fib[k]);//这个方法可以将arr数组增长到fib[k],增加的元素都默认为0
// 我们需要的是用数列的最后一个元素来填充数组,所以需要修改后面的0
for (int i = high+1; i < temp.length; i++) {
temp[i]=arr[high];
}
while (low<=high){
mid=low+fib[k-1]-1;//为啥最后面要减一?因为fib[k-1]在此处表示的是一个数量,即从low索引到中分点间的元素个数,而此处我们想要的mid表示的是一个索引
// 这里为啥是fib[k-1]?因为fib[k]表示的是这个数列的长度,所以这个数列的黄金分割点到数列头的长度就是fib[k]的前一个数值,我们这里需要的就是黄金分割点,所以k-1
if (key<temp[mid]){
//若所寻找的值小于中间值,则进入分割后左边的数列,即F[k-1]的那一部分数列
high=mid-1;
k--;
// 为什么这里k自减?因为进入下次循环的时候,从数列头到这个黄金分割点(即f[k-1])的长度,就是我们下次循环时候数列的总长,
// 而这个数列的黄金分割点正是f[k-1]的前一个数值,所以这里我们需要得到的是斐波那契数列中的前一个数值,即fib[k-1]的前一个数值,所以是k--
}else if (key>temp[mid]){
//若所寻找的值大于中间值,则进入分割后右边的那一部分数列,即F[k-2]的那一部分
low=mid+1;
k-=2;
// 这里为什么是k自减2?因为当数列经过黄金分割之后,如果key>temp[mid],即key在经过黄金分割后的数列的后半部分,
// 则我们下次就需要把后半部分的这个数列进行黄金分割找值,如果要对这个数列黄金分割,我们需要先知道这个数列的长度,这个数列的长度就很明显
// 因为斐波那契数列f(n)=f(n-1)+f(n-2),由因为黄金分割后数列后半部分长度不可能大于前半部分长度,所以后半部分长度就是f(n-2)了,
// f(n-2)的黄金分割点就是这次黄金分割点的上上个数值,即f[k-1]的上上个数值,也就是f[k-1-1-1],所以f[k-1-1]的黄金分割点又是f[k-1-1]的上一个数值
// 所以此处是k自减2
// 明明后面是个减三个1为啥这里只k自减两次?因为,在每次循环开始之前,得到的中间值都是low+fib[k-1]-1,每次用的值不是k而是k-1
}else {
return mid;
}
}
return -1;
}
public int[] getFibArr(int n){
int[] fib=new int[n];
fib[0]=0;
if (n==1){
return fib;
}
fib[1]=1;
if (n==2){
return fib;
}
for (int i = 2; i < n; i++) {
fib[i]=fib[i-1]+fib[i-2];
}
return fib;
}
}
Кстати, вот тест скорости поиска в 8 млн данных, это и QuickSortDemo sortDemo=new QuickSortDemo(); sortDemo.SortDemo(Array);есть быстрая сортировка, написанная в предыдущей статье