prefacio
Artículos de la serie Coroutine:
- ¿Una historia corta para explicar la relación entre procesos, subprocesos y corrutinas de Kotlin?
- Chico, ¿sabes cómo se veían las corrutinas de Kotlin en primer lugar?
- En serio, la suspensión/reanudación de la rutina de Kotlin no es tan misteriosa (historia)
- Para ser honesto, la suspensión/reanudación de las rutinas de Kotlin no es tan misteriosa (principio)
- Es hora de desentrañar la verdad sobre la programación de rutinas de Kotlin y el cambio de subprocesos
- Recorrido de exploración del conjunto de subprocesos de Kotlin Coroutine (PK con conjunto de subprocesos de Java)
- Recorrido de exploración de cancelación y manejo de excepciones de Kotlin Coroutine (Parte 1)
- Recorrido de exploración de cancelación y manejo de excepciones de Kotlin Coroutine (Parte 2)
- Vamos, sígueme Kotlin runBlocking/launch/join/async/delay principio y uso
- Vamos, juguemos conmigo Zona de aguas profundas del canal Kotlin
- Kotlin coroutine Select: mira cómo multiplexo
- Kotlin Sequence es hora de ser útil
- La contrapresión de Kotlin Flow y el cambio de hilo son muy similares
- Kotlin Flow, ¿adónde vas?
- ¿Qué tan caliente es el flujo caliente de Kotlin SharedFlow y StateFlow?
El análisis anterior tiene que ver con el flujo frío, y el calor y el frío se corresponden. Si hay frío, hay calor. Este artículo se centrará en el análisis del uso y el principio del flujo caliente SharedFlow&StateFlow, y explorará su "calor".
A través de este artículo, aprenderá:
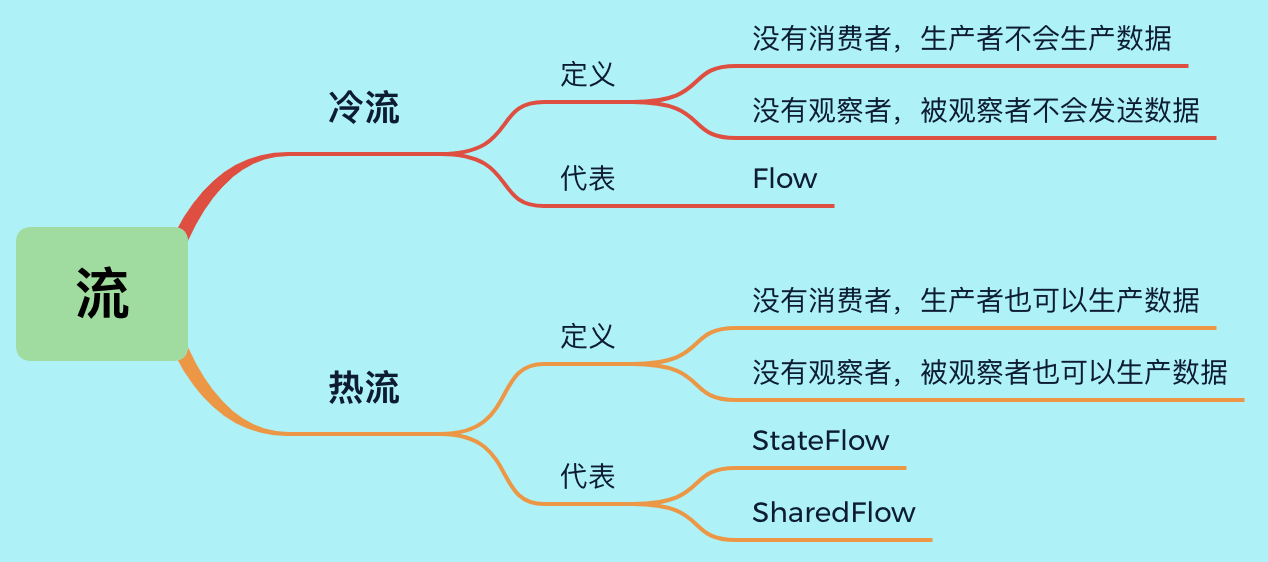
- La diferencia entre flujo frío y flujo caliente
- Escenarios de aplicación y uso de SharedFlow
- Análisis del principio de SharedFlow desde diferentes ángulos
- Escenarios de uso y aplicación de StateFlow
- El principio de StateFlow se puede ver de un vistazo
- Diferencias y aplicaciones de StateFlow/SharedFlow/LiveData
1. La diferencia entre flujo frío y flujo caliente
2. Escenarios de aplicación y uso de SharedFlow
Cómo utilizar
Los dos extremos de la transmisión son consumidores (observador/suscriptor) y productores (observado/suscrito), por lo que solo debe prestar atención al comportamiento de ambos extremos.
1. El productor envía los datos primero
fun test1() {
runBlocking {
//构造热流
val flow = MutableSharedFlow<String>()
//发送数据(生产者)
flow.emit("hello world")
//开启协程
GlobalScope.launch {
//接收数据(消费者)
flow.collect {
println("collect: $it")
}
}
}
}
P: ¿Adivina el resultado primero?
R: No se imprime nada.
Suponemos: el productor envió los datos primero, porque el consumidor no había tenido tiempo de recibirlos en ese momento, por lo que los datos se descartaron.
2. El productor retrasa el envío de datos
Podemos pensar fácilmente en cambiar el tiempo y dejar que el consumidor se registre y espere primero:
fun test2() {
runBlocking {
//构造热流
val flow = MutableSharedFlow<String>()
//开启协程
GlobalScope.launch {
//接收数据(消费者)
flow.collect {
println("collect: $it")
}
}
//发送数据(生产者)
delay(200)//保证消费者已经注册上
flow.emit("hello world")
}
}
En este momento, el consumidor imprime correctamente los datos.
3. Retención (repetición) de datos históricos
Aunque el método 2 conecta a productores y consumidores, todavía te preocupa la falla del 1: sientes que SharedFlow es un poco débil y las restricciones son un poco duras Cada vez que llega un nuevo observador en LiveData puede recibir los datos actuales, pero SharedFlow no.
De hecho, SharedFlow es más poderoso que LiveData en la reproducción de datos históricos. LiveData siempre tiene un solo valor, es decir, solo se reproduce un valor a la vez, mientras que SharedFlow se puede configurar para reproducir cualquier valor (por supuesto, no puede exceder el rango de Int).
Cambia tu postura:
fun test3() {
runBlocking {
//构造热流
val flow = MutableSharedFlow<String>(1)
//发送数据(生产者)
flow.emit("hello world")
//开启协程
GlobalScope.launch {
//接收数据(消费者)
flow.collect {
println("collect: $it")
}
}
}
}
El efecto logrado en este momento es consistente con 2. MutableSharedFlow(1) significa que el productor reserva 1 valor, y cuando llega un nuevo consumidor, obtendrá el valor reservado.
Por supuesto, también es posible mantener más valores:
fun test3() {
runBlocking {
//构造热流
val flow = MutableSharedFlow<String>(4)
//发送数据(生产者)
flow.emit("hello world1")
flow.emit("hello world2")
flow.emit("hello world3")
flow.emit("hello world4")
//开启协程
GlobalScope.launch {
//接收数据(消费者)
flow.collect {
println("collect: $it")
}
}
}
}
En este momento, el consumidor imprimirá "hell world1~hello world4", que también muestra que el productor ha producido datos sin importar si hay un consumidor o no, por lo que muestra:
SharedFlow es flujo caliente
4. Collect es una función de suspensión.
En 2, abrimos la corrutina para ejecutar la lógica del consumidor: flow.collect. ¿Qué sucede si no abrimos la corrutina por separado?
fun test4() {
runBlocking {
//构造热流
val flow = MutableSharedFlow<String>()
//接收数据(消费者)
flow.collect {
println("collect: $it")
}
println("start emit")//①
flow.emit("hello world")
}
}
Finalmente, se encontró que ① no se imprimió, porque recopilar es una función de suspensión. En este momento, debido a que el productor no ha tenido tiempo de producir datos, cuando el consumidor llama a recopilar y descubre que no hay datos, suspende el corrutina
Por lo tanto, el productor y el consumidor deben estar en diferentes rutinas.
5. emit es una función de suspensión.
El consumidor tiene que esperar a que el productor produzca datos, por lo que recopilar está diseñado como una función de suspensión. Por el contrario, ¿el productor tiene que esperar a que el consumidor consuma los datos antes de proceder a emitir el siguiente ¿tiempo?
fun test5() {
runBlocking {
//构造热流
val flow = MutableSharedFlow<String>()
//开启协程
GlobalScope.launch {
//接收数据(消费者)
flow.collect {
delay(2000)
println("collect: $it")
}
}
//发送数据(生产者)
delay(200)//保证消费者先执行
println("emit 1 ${
System.currentTimeMillis()}")
flow.emit("hello world1")
println("emit 2 ${
System.currentTimeMillis()}")
flow.emit("hello world2")
println("emit 3 ${
System.currentTimeMillis()}")
flow.emit("hello world3")
println("emit 4 ${
System.currentTimeMillis()}")
flow.emit("hello world4")
}
}
Se puede ver en la impresión que el productor debe esperar a que el consumidor complete el consumo antes de emitir la próxima vez.
6. Configuración de caché
En el análisis anterior de Flow, mencioné el problema de la contrapresión de Flow y usé Buffer para resolverlo. De manera similar, también existe el concepto de caché en SharedFlow.
fun test6() {
runBlocking {
//构造热流
val flow = MutableSharedFlow<String>(0, 10)
//开启协程
GlobalScope.launch {
//接收数据(消费者)
flow.collect {
delay(2000)
println("collect: $it")
}
}
//发送数据(生产者)
delay(200)//保证消费者先执行
println("emit 1 ${
System.currentTimeMillis()}")
flow.emit("hello world1")
println("emit 2 ${
System.currentTimeMillis()}")
flow.emit("hello world2")
println("emit 3 ${
System.currentTimeMillis()}")
flow.emit("hello world3")
println("emit 4 ${
System.currentTimeMillis()}")
flow.emit("hello world4")
}
}
MutableSharedFlow(0, 10) El segundo parámetro 10 significa que el tamaño de caché adicional es 10. El productor primero coloca los datos en el caché a través de emisión, y en este momento no se ve arrastrado por la velocidad del consumidor.
7. Reproducción y búferes adicionales
public fun <T> MutableSharedFlow(
replay: Int = 0,//重放个数
extraBufferCapacity: Int = 0,//额外的缓存个数
onBufferOverflow: BufferOverflow = BufferOverflow.SUSPEND
):
La reproducción se utiliza principalmente para reproducir una cantidad específica de datos históricos para nuevos consumidores, y la cantidad adicional de cachés es para tratar el problema de la contrapresión. La cantidad total de cachés = la cantidad de repeticiones + la cantidad de cachés adicionales.
Escenario de aplicación
Si tiene los siguientes requisitos, puede usar SharedFlow
- Necesidad de reproducir datos históricos
- Almacenamiento en caché configurable
- Necesidad de transmitir/recibir repetidamente el mismo valor
3. Análisis desde diferentes perspectivas de los principios de SharedFlow
Encuentra respuestas con preguntas
El enfoque no es más que las funciones de emisión y recopilación, las cuales son funciones de suspensión, y si se suspenden depende de si se cumplen las condiciones. Al mismo tiempo, el momento del surgimiento de productores y consumidores también afectará esta condición, así que solo enumere el momento del surgimiento de productores y consumidores.
solo productores
Cuando solo hay productores y no consumidores, ¿la llamada del productor suspenderá la rutina? Si no, ¿qué condiciones colgarían?
Comience con el código fuente de la función de emisión:
override suspend fun emit(value: T) {
//如果发射成功,则直接退出函数
if (tryEmit(value)) return // fast-path
//否则挂起协程
emitSuspend(value)
}
Primer vistazo a tryEmit(xx):
override fun tryEmit(value: T): Boolean {
var resumes: Array<Continuation<Unit>?> = EMPTY_RESUMES
val emitted = kotlinx.coroutines.internal.synchronized(this) {
//尝试emit
if (tryEmitLocked(value)) {
//遍历所有消费者,找到需要唤醒的消费者协程
resumes = findSlotsToResumeLocked(resumes)
true
} else {
false
}
}
//恢复消费者协程
for (cont in resumes) cont?.resume(Unit)
//emitted==true表示发射成功
return emitted
}
private fun tryEmitLocked(value: T): Boolean {
//nCollectors 表示消费者个数,若是没有消费者则无论如何都会发射成功
if (nCollectors == 0) return tryEmitNoCollectorsLocked(value) // always returns true
if (bufferSize >= bufferCapacity && minCollectorIndex <= replayIndex) {
//如果缓存已经满并且有消费者没有消费最旧的数据(replayIndex),则进入此处
when (onBufferOverflow) {
//挂起生产者
BufferOverflow.SUSPEND -> return false // will suspend
//直接丢弃最新数据,认为发射成功
BufferOverflow.DROP_LATEST -> return true // just drop incoming
//丢弃最旧的数据
BufferOverflow.DROP_OLDEST -> {
} // force enqueue & drop oldest instead
}
}
//将数据加入到缓存队列里
enqueueLocked(value)
//缓存数据队列长度
bufferSize++ // value was added to buffer
// drop oldest from the buffer if it became more than bufferCapacity
if (bufferSize > bufferCapacity) dropOldestLocked()
// keep replaySize not larger that needed
if (replaySize > replay) {
// increment replayIndex by one
updateBufferLocked(replayIndex + 1, minCollectorIndex, bufferEndIndex, queueEndIndex)
}
return true
}
private fun tryEmitNoCollectorsLocked(value: T): Boolean {
kotlinx.coroutines.assert {
nCollectors == 0 }
//没有设置重放,则直接退出,丢弃发射的值
if (replay == 0) return true // no need to replay, just forget it now
//加入到缓存里
enqueueLocked(value) // enqueue to replayCache
bufferSize++ // value was added to buffer
// drop oldest from the buffer if it became more than replay
//若是超出了重放个数,则丢弃最旧的值
if (bufferSize > replay) dropOldestLocked()
minCollectorIndex = head + bufferSize // a default value (max allowed)
//发射成功
return true
}
Mire emitSuspend (valor) nuevamente:
private suspend fun emitSuspend(value: T) = suspendCancellableCoroutine<Unit> sc@{ cont ->
var resumes: Array<Continuation<Unit>?> = EMPTY_RESUMES
val emitter = kotlinx.coroutines.internal.synchronized(this) lock@{
...
//构造为Emitter,加入到buffer里
SharedFlowImpl.Emitter(this, head + totalSize, value, cont).also {
enqueueLocked(it)
//单独记录挂起的emit
queueSize++ // added to queue of waiting emitters
// synchronous shared flow might rendezvous with waiting emitter
if (bufferCapacity == 0) resumes = findSlotsToResumeLocked(resumes)
}
}
}
Use un diagrama para representar todo el proceso de emisión:
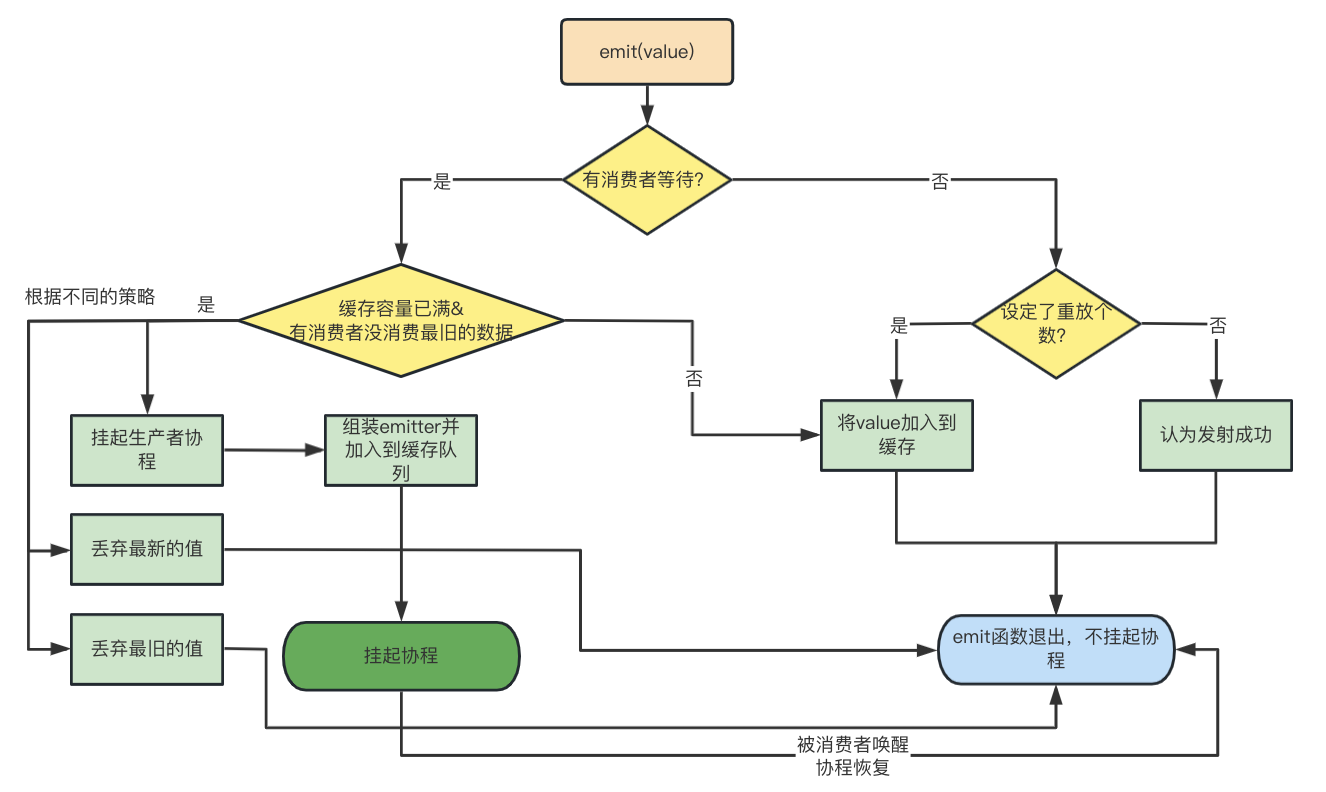
Ahora podemos volver a la pregunta anterior.
- Si no hay consumidores, el productor que llama a la función de emisión nunca se colgará.
- Si un consumidor está registrado y la capacidad de caché está llena y los datos más antiguos no se han consumido, la función de emisión del productor tiene la posibilidad de suspenderse. Si se establece el modo de suspensión, se suspenderá
Los datos más antiguos se analizarán a continuación.
solo consumidores
¿Se suspenderá la llamada por cobrar al consumidor cuando haya un solo consumidor?
Comience con el código fuente de la función de recopilación.
override suspend fun collect(collector: FlowCollector<T>) {
//分配slot
val slot = allocateSlot()//①
try {
if (collector is SubscribedFlowCollector) collector.onSubscription()
val collectorJob = currentCoroutineContext()[Job]
while (true) {
//死循环
var newValue: Any?
while (true) {
//尝试获取值 ②
newValue = tryTakeValue(slot) // attempt no-suspend fast path first
if (newValue !== NO_VALUE)
break//拿到值,退出内层循环
//没拿到值,挂起等待 ③
awaitValue(slot) // await signal that the new value is available
}
collectorJob?.ensureActive()
//拿到值,消费数据
collector.emit(newValue as T)
}
} finally {
freeSlot(slot)
}
}
Concéntrese en tres puntos:
① allocateSlot()
primero mire la estructura de datos de la ranura:
private class SharedFlowSlot : AbstractSharedFlowSlot<SharedFlowImpl<*>>() {
//消费者当前应该消费的数据在生产者缓存里的索引
var index = -1L // current "to-be-emitted" index, -1 means the slot is free now
//挂起的消费者协程体
var cont: Continuation<Unit>? = null // collector waiting for new value
}
Cada llamada a recopilar generará un objeto AbstractSharedFlowSlot para ella, que se almacena en la matriz de objetos AbstractSharedFlowSlot: ranuras
allocateSlot() tiene dos funciones:
- Expanda la matriz de ranuras
- Almacene el objeto AbstractSharedFlowSlot en la matriz de ranuras
② tryTakeValue(slot)
Después de crear el slot, puede tomar el valor
private fun tryTakeValue(slot: SharedFlowSlot): Any? {
var resumes: Array<Continuation<Unit>?> = EMPTY_RESUMES
val value = kotlinx.coroutines.internal.synchronized(this) {
//找到slot对应的buffer里的数据索引
val index = tryPeekLocked(slot)
if (index < 0) {
//没找到
NO_VALUE
} else {
//找到
val oldIndex = slot.index
//根据索引,从buffer里获取值
val newValue = getPeekedValueLockedAt(index)
//slot索引增加,指向buffer里的下个数据
slot.index = index + 1 // points to the next index after peeked one
//更新游标等信息,并返回挂起的生产者协程
resumes = updateCollectorIndexLocked(oldIndex)
newValue
}
}
//如果可以,则唤起生产者协程
for (resume in resumes) resume?.resume(Unit)
return value
}
La función puede o no obtener un valor.
③ awaitValue
private suspend fun awaitValue(slot: kotlinx.coroutines.flow.SharedFlowSlot): Unit = suspendCancellableCoroutine {
cont ->
kotlinx.coroutines.internal.synchronized(this) lock@{
//再次尝试获取
val index = tryPeekLocked(slot) // recheck under this lock
if (index < 0) {
//说明没数据可取,此时记录当前协程,后续恢复时才能找到
slot.cont = cont // Ok -- suspending
} else {
//有数据了,则唤醒
cont.resume(Unit) // has value, no need to suspend
return@lock
}
slot.cont = cont // suspend, waiting
}
}

Al comparar los procesos de emisión del productor y de recopilación del consumidor, está claro que el proceso de recopilación es mucho más simple que el proceso de emisión.
Ahora podemos volver a la pregunta anterior.
Independientemente de que existan o no productores, mientras no se obtengan datos, se suspenderá la recolección.
búfer de ranura
Lo anterior analiza los procesos emit y collect respectivamente, sabemos que emit puede estar suspendido y puede ser despertado por collect después de ser suspendido, el mismo collect también puede ser suspendido y puede ser despertado por emit después de ser suspendido.
El punto clave es cómo los dos intercambian datos, es decir, ¿cómo se relacionan los objetos de ranura y los búferes?

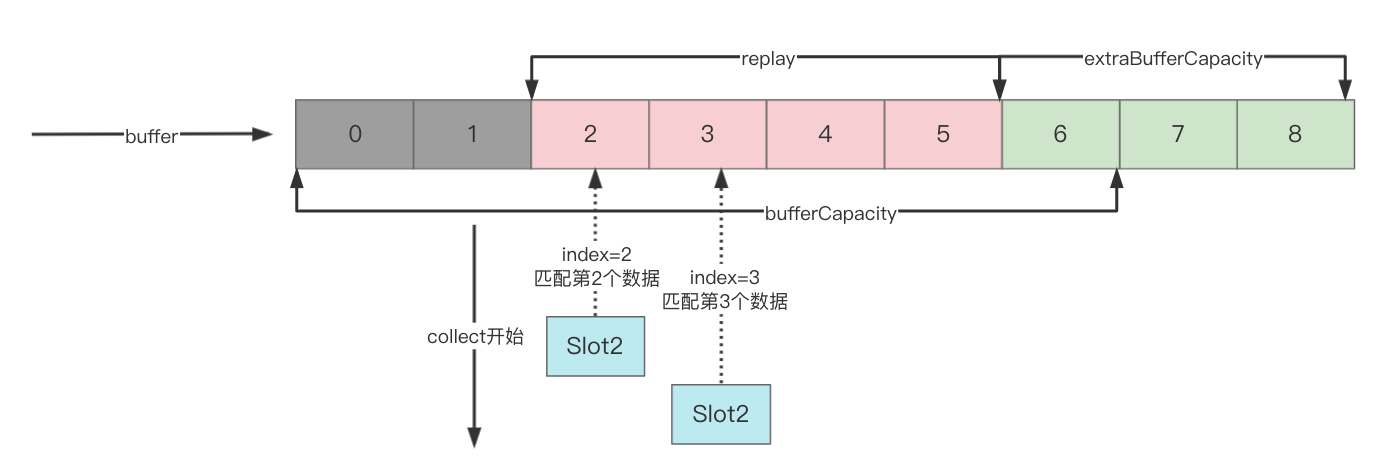
Como se muestra arriba, el proceso se presenta brevemente:
- SharedFlow establece el número de repeticiones en 4, la capacidad adicional en 3 y la capacidad total en 4+3=7
- El productor apila los datos en el búfer y el consumidor no ha comenzado a recopilarlos en este momento.
- El consumidor comienza a recolectar, porque el número de repeticiones está establecido, por lo que al construir el objeto Slot, slot.index=0, y el elemento con el subíndice 0 del búfer encontrado según el índice es el elemento que se puede consumir.
- Después de obtener los datos No. 0, slot.index=1, busque el elemento con el subíndice de búfer 1
- index++, repita el paso 4
Debido a que la recopilación consume datos, emit puede continuar agregando nuevos datos, y se agrega una nueva recopilación en este momento:
- Construya un objeto Slot cuando el consumidor recién agregado recopile, porque el valor más antiguo del búfer en este momento es el subíndice 2 del búfer, por lo que Slot inicializa Slot.index = 2 y toma los segundos datos
- Del mismo modo, continúe tomando el valor más tarde.
En este momento, hay 2 consumidores, suponiendo que la velocidad de consumo del consumidor 2 es muy lenta, se mantiene en el índice = 3, y la velocidad de consumo del consumidor 1 es rápida, lo que se convierte en la siguiente figura:
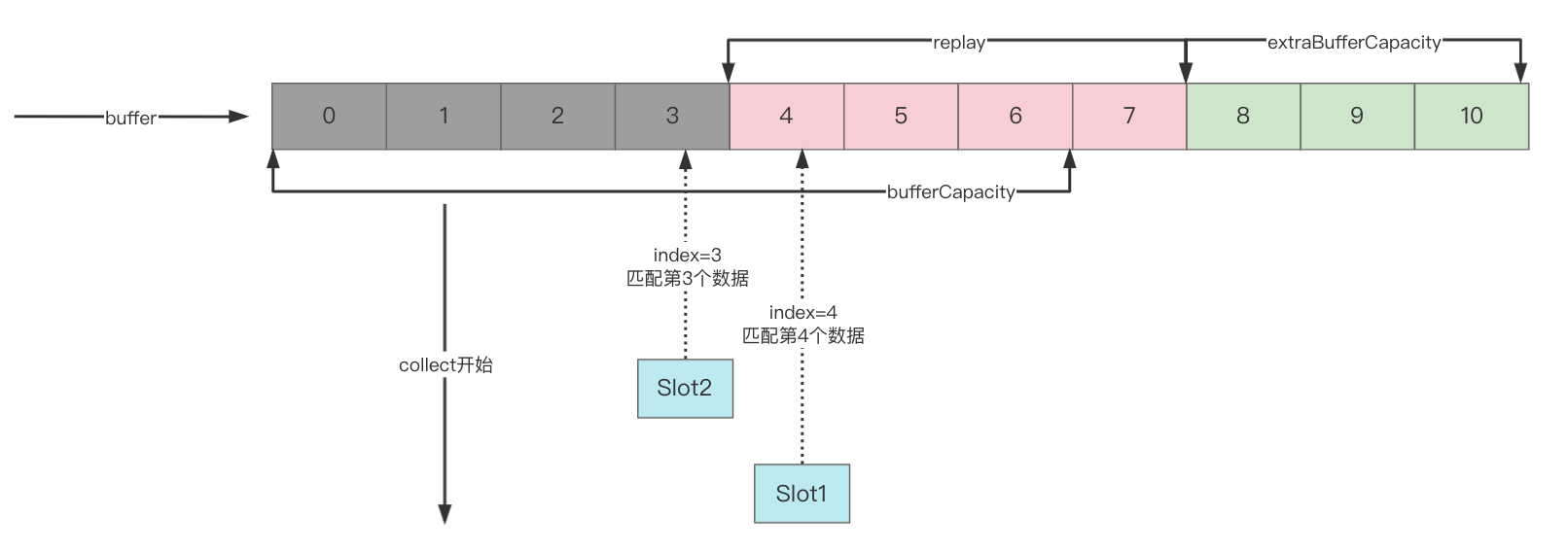
- El consumidor 1 toma el valor de index=4 (puede continuar consumiendo datos más tarde), el consumidor 2 toma el valor de index=3
- El productor ha llenado el búfer en este momento y el valor más antiguo en el búfer es índice = 4. Para garantizar que el consumidor 2 pueda obtener el valor de índice = 4, ya no puede emitir nuevos datos en este momento, por lo que el productor esta bloqueado cuelga
- Cuando el consumidor 2 consuma el valor de index=4, despertará al productor suspendido para continuar produciendo datos.
Esto lleva a una conclusión:
La emisión de SharedFlow puede ser arrastrada hacia abajo por la recopilación y suspensión más lentas.
Este fenómeno es más intuitivo para ver e imprimir con código:
fun test7() {
runBlocking {
//构造热流
val flow = MutableSharedFlow<String>(4, 3)
//开启协程
GlobalScope.launch {
//接收数据(消费者1)
flow.collect {
println("collect1: $it")
}
}
GlobalScope.launch {
//接收数据(消费者2)
flow.collect {
//模拟消费慢
delay(10000)
println("collect2: $it")
}
}
//发送数据(生产者)
delay(200)//保证消费者先执行
var count = 0
while (true) {
flow.emit("emit:${
count++}")
}
}
}
4. Escenarios de uso y aplicación de StateFlow
Cómo utilizar
1. Función de reproducción
Se ha dedicado mucho espacio al análisis de SharedFlow arriba, y StateFlow es un caso especial de SharedFlow. Veamos primero su uso simple.
fun test8() {
runBlocking {
//构造热流
val flow = MutableStateFlow("")
flow.emit("hello world")
flow.collect {
//消费者
println(it)
}
}
}
Descubrimos que la reproducción no está configurada para Flow, y los consumidores aún pueden consumir datos en este momento, lo que indica que StateFlow admite la reproducción de datos históricos de forma predeterminada.
2. Número de repeticiones
¿Cuántos valores se pueden reproducir?
fun test10() {
runBlocking {
//构造热流
val flow = MutableStateFlow("")
flow.emit("hello world")
flow.emit("hello world1")
flow.emit("hello world2")
flow.emit("hello world3")
flow.emit("hello world4")
flow.collect {
//消费者
println(it)
}
}
}
Finalmente, se encuentra que el consumidor solo imprime una vez, lo que indica que StateFlow solo reproduce una vez y es el último valor.
3. Antivibración
fun test9() {
runBlocking {
//构造热流
val flow = MutableStateFlow("")
flow.emit("hello world")
GlobalScope.launch {
flow.collect {
//消费者
println(it)
}
}
//再发送
delay(1000)
flow.emit("hello world")
// flow.emit("hello world1")
}
}
El productor envió los datos dos veces, ¿adivina cuántas veces ha impreso el consumidor en este momento?
La respuesta es solo una vez, porque StateFlow está diseñado con antivibración. Al emitir, verificará si el valor actual es consistente con el valor anterior. Si son consistentes, los datos actuales se descartarán sin ningún procesamiento. Por supuesto, recoger no recibirá el valor. Si soltamos el comentario, habrá 2 impresiones.
Escenario de aplicación
StateFlow es muy similar a LiveData en que solo mantienen un valor, y el valor anterior sobrescribirá el valor nuevo cuando llegue.
Aplicable al escenario de notificación de cambios de estado, como el progreso de la descarga. Útil para cambios que solo se enfocan en el valor más reciente.
Si está familiarizado con LiveData, puede comprender que StateFlow básicamente puede reemplazar la función LiveData.
5. El principio de StateFlow se puede ver de un vistazo
Si comprende el principio de SharedFlow, entonces la comprensión del principio de StateFlow no es un problema.
proceso de emisión
override suspend fun emit(value: T) {
//value 为StateFlow维护的值,每次emit都会修改它
this.value = value
}
public override var value: T
get() = NULL.unbox(_state.value)//从state取出
set(value) { updateState(null, value ?: NULL) }
private fun updateState(expectedState: Any?, newState: Any): Boolean {
var curSequence = 0
var curSlots: Array<StateFlowSlot?>? = this.slots // benign race, we will not use it
kotlinx.coroutines.internal.synchronized(this) {
val oldState = _state.value
if (expectedState != null && oldState != expectedState) return false // CAS support
//新旧值一致,则无需更新
if (oldState == newState) return true // Don't do anything if value is not changing, but CAS -> true
//更新到state里
_state.value = newState
curSequence = sequence
//...
curSlots = slots // read current reference to collectors under lock
}
while (true) {
curSlots?.forEach {
//遍历消费者,修改状态或是将挂起的消费者唤醒
it?.makePending()
}
...
}
}
El proceso de emisión es el proceso de modificar el valor del valor. Independientemente de si la modificación es exitosa o no, la función de emisión saldrá y no se suspenderá.
proceso de recogida
override suspend fun collect(collector: FlowCollector<T>) {
//分配slot
val slot = allocateSlot()
try {
if (collector is SubscribedFlowCollector) collector.onSubscription()
val collectorJob = currentCoroutineContext()[Job]
var oldState: Any? = null // previously emitted T!! | NULL (null -- nothing emitted yet)
while (true) {
val newState = _state.value
collectorJob?.ensureActive()
//值不相同才调用collect闭包
if (oldState == null || oldState != newState) {
collector.emit(NULL.unbox(newState))
oldState = newState
}
if (!slot.takePending()) {
// try fast-path without suspending first
//挂起协程
slot.awaitPending() // only suspend for new values when needed
}
}
} finally {
freeSlot(slot)
}
}
StateFlow también tiene una ranura, llamada StateFlowSlot, que es mucho más simple que SharedFlowSlot, porque solo se debe mantener un valor en todo momento, por lo que no se necesita un índice. Hay una variable miembro _state, que puede ser el estado actual de la corrutina del consumidor o el cuerpo de la corrutina.
Cuando se expresa como un cuerpo de rutina, significa que el consumidor está suspendido en este momento y espera hasta que el productor despierte la rutina a través de la emisión.

6. Diferencias y aplicaciones de StateFlow/SharedFlow/LiveData
- StateFlow es un caso especial de SharedFlow
- SharedFlow se usa principalmente para la notificación de eventos, y StateFlow/LiveData se usa principalmente para cambios de estado
- StateFlow tiene un valor predeterminado, LiveData no, el cierre de StateFlow.collect se puede ejecutar en subprocesos, LiveData.observe debe monitorearse en el subproceso principal, StateFlow no está asociado con un ciclo de vida, LiveData está asociado con un ciclo de vida , StateFlow es antivibración, LiveData no es antivibración, etc.
Con el final de este artículo, la serie de rutinas de Kotlin ha llegado a su fin, y el enfoque estará en la práctica de la arquitectura de ingeniería de rutinas, así que permanezca atento.
Lo anterior es el contenido completo de la contrapresión de flujo y el cambio de rosca. La siguiente parte analizará el flujo de calor de flujo.
Este artículo se basa en Kotlin 1.5.3, haga clic para ver la demostración completa en el artículo
Si te gusta, dale me gusta, sigue y marca, tu aliento es mi motivación.
Actualización continua, sistema paso a paso conmigo, estudio en profundidad de Android/Kotlin
1. El pasado y el presente de los diversos contextos de Android
2. Android DecorView debe saber y saber
3. Cosas que debe saber Window/WindowManager
4. View Measure/Layout/Draw realmente entiende
5. Distribución de eventos de Android conjunto completo de servicios
6. Android invalida /postInvalidate /requestLayout completamente aclarado
7. Cómo determinar el tamaño de la ventana de Android/la razón de múltiples ejecuciones de onMeasure()
8. Análisis de controlador-mensaje-Looper basado en eventos de Android
9. El teclado de Android se puede hacer con un truco
10. Las diversas coordenadas de Android se entienden completamente
11. Actividad de Android/Ventana/Fondo de vista
12. Actividad de Android creada para ver mostrada
13. Serie IPC de Android
14. Serie de almacenamiento de Android
15. Serie de concurrencia de Java No más dudas
16. Serie de grupos de subprocesos de Java
17. Serie prebásica de Android Jetpack
18. Serie fácil de aprender y comprender de Android Jetpack
19. Serie de entrada fácil de Kotlin
20. Interpretación integral de la serie de rutinas de Kotlin