Directorio de artículos
1. Varias funciones de consulta de Mybatis
1. Si solo hay un resultado de consulta
(1) puede usar el objeto de clase de entidad para recibirlo
(2) también puede usar la lista y la colección de mapas para recibirlo
2. Si hay varios resultados de consulta
(1) use la colección de lista de tipo de clase de entidad para recibirla
(2) Use la colección de lista de tipo de mapa para recibir
(3) Puede agregar la anotación @MapKey al método de la interfaz del mapeador. En este momento, puede usar la colección de mapas como el valor y el valor de un campo único como clave, y ponerlo en la misma colección de mapas
2. Ejecución de SQL especial
1. Consulta difusa
<!--三种方式都可以实现模糊查询,推荐使用方式3-->
<select id="getUserByLike" resultType="com.jd.wds.pojo.User">
<!--select * from user where username like '%${username}%'-->
<!--select * from user where username like concat ('%',#{username},'%')-->
select * from user where username like "%"#{username}"%"
</select>
2. Eliminar lote
<!--批量删除的特殊情况-->
<delete id="deleteMore">
<!--此处只能使用${}的形式,因为#{}的方式会添加引号,而id的字段名是int-->
<!--delete from user where id in (#{id})-->
delete from user where id in (${id})
</delete>
3. Establecer dinámicamente el nombre de la tabla
<select id="getUserByTableName" resultType="com.jd.wds.pojo.User">
<!--此处只能使用${},不能使用#{}-->
<!--select * from #{tableName}-->
select * from ${tableName}
</select>
4. El nombre del campo y el nombre del atributo son inconsistentes.
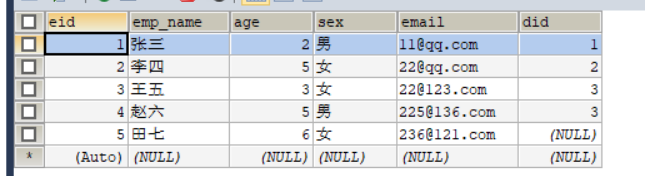
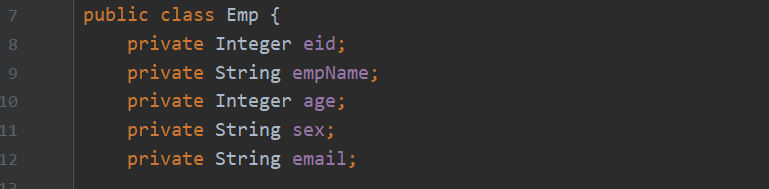
De acuerdo con diferentes especificaciones, al crear una tabla, el campo se nombra con un guión bajo y el nombre del atributo de la clase creada se nombra con una pequeña joroba. En este momento, el campo name y el nombre del atributo no se corresponden exactamente Tres soluciones:
<select id="getAllEmp" resultType="com.jd.wds.pojo.Emp">
<!--方法1:给对应的字段名设置别名-->
select eid,emp_name empName,age,sex,email from t_emp
</select>
<!--mybatis的核心配置文件中配置如下,此时sql语句:select * from t_emp-->
<!--方法2:设置全局配置:驼峰命名转下划线命名-->
<settings>
<setting name="mapUnderscoreToCamelCase" value="true"/>
</settings>
<!--方法3:使用resultmap设置自定义的映射-->
<resultMap id="empResultMap" type="com.jd.wds.pojo.Emp">
<!--id设置的是主键名,result设置的是非主键名,column是属性名-->
<id property="eid" column="eid"></id>
<result property="empName" column="emp_name"></result>
<result property="age" column="age"></result>
<result property="sex" column="sex"></result>
<result property="email" column="email"></result>
</resultMap>
<select id="getAllEmp" resultMap="empResultMap">
<!--解决字段名和属性名方法1:给对应的字段名设置别名-->
select * from t_emp
</select>
5. Relación de mapeo de muchos a uno
Muchos a uno corresponde a objetos y uno a muchos corresponde a colecciones
Tome una castaña: consulte la información de un empleado y la información del departamento (varios empleados corresponden a un departamento, típicamente muchos -a-uno)
método 1: resultMap se procesa a través de asignaciones de propiedades en cascada
<resultMap id="empAndDeptOne" type="com.jd.wds.pojo.Emp">
<id property="eid" column="eid"></id>
<result property="empName" column="emp_name"></result>
<result property="age" column="age"></result>
<result property="sex" column="sex"></result>
<result property="email" column="email"></result>
<!--需要在Emp类中声明dept属性,resultMap通过级联属性赋值-->
<result property="dept.did" column="did"></result>
<result property="dept.deptName" column="dept_name"></result>
</resultMap>
<select id="getEmpAndDept" resultMap="empAndDeptOne">
SELECT * FROM t_emp LEFT JOIN t_dept ON t_emp.did = t_dept.did WHERE t_emp.eid = #{eid}
</select>
Método 2: use la asociación para manejar específicamente las asignaciones de propiedades en cascada
<resultMap id="empAndDeptTwo" type="com.jd.wds.pojo.Emp">
<id property="eid" column="eid"></id>
<result property="empName" column="emp_name"></result>
<result property="age" column="age"></result>
<result property="sex" column="sex"></result>
<result property="email" column="email"></result>
<!--需要在Emp类中声明dept属性,使用association专门处理级联属性赋值
javaType:需要处理的属性的类型;
property:需要处理的属性名-->
<association javaType="com.jd.wds.pojo.Dept" property="dept">
<result property="did" column="did"></result>
<result property="deptName" column="dept_name"></result>
</association>
</resultMap>
<select id="getEmpAndDept" resultMap="empAndDeptTwo">
SELECT * FROM t_emp LEFT JOIN t_dept ON t_emp.did = t_dept.did WHERE t_emp.eid = #{eid}
</select>
Método 3: resolver usando una consulta paso a paso
<!--<mapper resource="com/jd/wds/mapper/EmpMapper.xml"/>-->
<!--分步查询员工所对应的部门信息-->
<!--第一步:查询员工信息-->
<resultMap id="EmpAndDeptByStepOne" type="com.jd.wds.pojo.Emp">
<id property="eid" column="eid"></id>
<result property="empName" column="emp_name"></result>
<result property="age" column="age"></result>
<result property="sex" column="sex"></result>
<result property="email" column="email"></result>
<!--association标签中property:属性名,select:第二步的sql查询语句,column:第二步的查询条件-->
<association property="dept" select="com.jd.wds.mapper.DeptMapper.getEmpAndDeptByStepTwo" column="did"></association>
</resultMap>
<select id="getEmpAndDeptByStepOne" resultMap="EmpAndDeptByStepOne">
select * from t_emp where eid=#{eid}
</select>
<!--<mapper resource="com/jd/wds/mapper/DeptMapper.xml"/>-->
<!--步骤2:根据查询道德did查询t_dept表中的数据-->
<select id="getEmpAndDeptByStepTwo" resultType="com.jd.wds.pojo.Dept">
select * from t_dept where did = #{did}
</select>
Los beneficios de la consulta paso a paso: puede implementar la carga retrasada y mejorar la reutilización de SQL. Debe estar habilitada en el archivo de configuración antes de poder usarse. De forma predeterminada, la carga retrasada no está habilitada.
6. Relación de mapeo de uno a muchos
Muchos a uno corresponde a objetos y uno a muchos corresponde a colecciones
Tome una castaña: consulte un departamento y la información de los empleados en el departamento (un departamento puede tener múltiples empleados, uno a muchos típico) Método
1: use la colección para manejar el mapeo de resultados de uno a muchos
<resultMap id="DeptAndEmp" type="com.jd.wds.pojo.Dept">
<id property="did" column="did"></id>
<result property="deptName" column="dept_name"></result>
<!--collection:处理一对多的结果映射,emps:一对多的集合名,ofType:集合emps所对应的集合类型-->
<collection property="emps" ofType="com.jd.wds.pojo.Emp">
<id property="eid" column="eid"></id>
<result property="empName" column="emp_name"></result>
<result property="age" column="age"></result>
<result property="sex" column="sex"></result>
<result property="email" column="email"></result>
</collection>
</resultMap>
<select id="getDeptAndEmp" resultMap="DeptAndEmp">
select * from t_dept left join t_emp on t_dept.did = t_emp.did where t_dept.did = #{did}
</select>
Enfoque 2: use consultas paso a paso para manejar el mapeo de resultados de uno a muchos
<!--分步查询-->
<!--<mapper resource="com/jd/wds/mapper/DeptMapper.xml"/>-->
<resultMap id="getDeptAndEmpByStep" type="com.jd.wds.pojo.Dept">
<id property="did" column="did" ></id>
<result property="deptName" column="dept_name"></result>
<collection property="emps" select="com.jd.wds.mapper.EmpMapper.getDeptAndEmpByStepTwo" column="did">
</collection>
</resultMap>
<!--第一步:根据did查询所在的部门信息-->
<select id="getDeptAndEmpByStepOne" resultMap="getDeptAndEmpByStep">
select * from t_dept where did = #{did}
</select>
<!--<mapper resource="com/jd/wds/mapper/EmpMapper.xml"/>-->
<!--第二步:根据第一步查询结果的did查询所在的员工信息-->
<select id="getDeptAndEmpByStepTwo" resultType="com.jd.wds.pojo.Emp">
select * from t_emp where did = #{did}
</select>
3. SQL dinámico
1. El elemento <if>
determina si el contenido de la etiqueta debe empalmarse en SQL de acuerdo con la expresión correspondiente al atributo de prueba en la etiqueta.
<!--通过多个条件精确查询某一条数据-->
<select id="getEmpDynamicCondition" resultType="com.jd.wds.pojo.Emp">
select * from t_emp where 1=1
<!--test属性的值是属性名-->
<if test="empName != null and empName !=''">
and emp_name = #{empName}
</if>
<if test="age != null and age !=''">
and age = #{age}
</if>
<if test="sex != null and sex != ''">
and sex = #{sex}
</if>
<if test="email != null and email != ''">
and email = #{email}
</if>
</select>
2. Elemento <where>
Cuando hay contenido en la etiqueta, la palabra clave where se generará automáticamente y el y o antes del contenido se eliminarán, cuando no haya contenido en la etiqueta, donde no tendrá efecto. (y/o informará un error después del contenido)
<select id="getEmpDynamicCondition" resultType="com.jd.wds.pojo.Emp">
select * from t_emp
<where>
<if test="empName != null and empName !=''">
and emp_name = #{empName}
</if>
<if test="age != null and age !=''">
and age = #{age}
</if>
<if test="sex != null and sex != ''">
and sex = #{sex}
</if>
<if test="email != null and email != ''">
and email = #{email}
</if>
</where>
</select>
3. Elemento <trim>
Si hay contenido en la etiqueta:
prefijo/sufijo: agregue el contenido especificado antes o después del contenido en la etiqueta de recorte
suffixoverrides /prefixoverrides: elimine el contenido especificado antes o después del contenido en la etiqueta de recorte
Si hay no hay contenido en la etiqueta, recorte la etiqueta Nada funciona.
<select id="getEmpDynamicCondition" resultType="com.jd.wds.pojo.Emp">
select * from t_emp
<!--此时在内容之前添加where,条件前面加and|or-->
<trim prefix="where" prefixOverrides="and|or">
<if test="empName != null and empName !=''">
and emp_name = #{empName}
</if>
<if test="age != null and age !=''">
and age = #{age}
</if>
<if test="sex != null and sex != ''">
and sex = #{sex}
</if>
<if test="email != null and email != ''">
and email = #{email}
</if>
</trim>
</select>
4.<elegir> <cuando> <de lo contrario>
equivalente a elemento si,si no si,si no,si no
<select id="getEmpDynamicCondition" resultType="com.jd.wds.pojo.Emp">
select * from t_emp where 1=1
<choose>
<when test="empName != null and empName !=''">
and emp_name = #{empName}
</when>
<when test="age != null and age !=''">
and age = #{age}
</when>
<when test="sex != null and sex != ''">
and sex = #{sex}
</when>
<when test="email != null and email != ''">
and email = #{email}
</when>
<otherwise>
did = 1
</otherwise>
</choose>
</select>
5. El elemento < foreach >
foreach se usa para operaciones transversales y, a menudo, se usa para operaciones como la eliminación y adición de lotes.
<!--批量删除操作-->
<delete id="deleteMoreUser">
<!--方法1:使用in集合的方式-->
delete from t_emp where eid in
<foreach collection="eids" open="(" close=")" separator="," item="eid">
#{eid}
</foreach>
<!--方法2:使用or连接条件-->
delete from t_emp where
<foreach collection="eids" item="eid" separator="or">
eid = #{eid}
</foreach>
</delete>
<!--批量插入操作-->
<insert id="insertMoreUser">
insert into t_emp values
<foreach collection="emps" separator="," item="emp">
(null,#{emp.empName},#{emp.age},#{emp.sex},#{emp.email},#{emp.did})
</foreach>
</insert>
6. La etiqueta SQL
se usa para establecer el fragmento SQL, que se puede citar en la posición requerida.
<!--设置sql片段-->
<sql id="columns">eid,emp_name,age,sex,email</sql>
<select id="selectAllUser" resultType="com.jd.wds.pojo.Emp">
<!--使用sql片段-->
select <include refid="colums"></include> from t_emp where eid = #{eid}
</select>
Cuatro, caché de Mybatis
1. Caché de primer nivel de Mybatis
El caché es solo para la función de consulta. El caché de primer nivel está en el nivel SqlSession. Está habilitado de manera predeterminada. Cuando se use el mismo SqlSession para consultar los mismos datos la próxima vez, se obtendrá directamente del caché y no se puede consultar desde la base de datos (la instrucción SQL solo se ejecuta una vez y hay dos resultados iguales).
Hay cuatro situaciones en las que falla la memoria caché de primer nivel:
(1) Diferentes SqlSessions corresponden a la memoria caché de primer nivel
(2) Las condiciones de consulta correspondientes a la misma SqlSession son diferentes
(3) Se realizan operaciones de adición, eliminación y modificación entre dos consultas de la misma SqlSession
(4) Limpiar manualmente la memoria caché entre dos consultas de la misma SqlSesion
//手动清空缓存
sqlSession.clearCache();
2. Caché de segundo nivel de Mybatis
La memoria caché de segundo nivel está en el nivel SqlSessionFactory. Los resultados de la consulta de la SqlSession creada a través de la misma SqlSessionFactory se almacenarán en la memoria caché. Si la misma declaración de consulta se ejecuta más adelante, los resultados se obtendrán de la memoria caché.
(1) Condiciones para habilitar el caché secundario :
① En el archivo de configuración central, configure el atributo de configuración global cacheEnabled="true"
<setting name="cachedEnable" value="true"/>
② Establezca la etiqueta <cache /> en el archivo de asignación.
③ La caché de segundo nivel debe surtir efecto después de que se cierre o envíe SqlSession.
④ El tipo de clase de entidad convertido por los datos consultados debe implementar la
interfaz
de serialización . Cualquier adición, eliminación , y las operaciones de modificación entre consultas invalidarán las cachés principal y secundaria al mismo tiempo.
(3) Configuración relevante de la caché de segundo nivel

(4) Orden de consultas de caché
