Introducción
Este blog habla principalmente sobre cómo usar la GPU en el servidor en la nube para ejecutar el programa, principalmente sobre algunas configuraciones y pasos de operación. Para pasos de capacitación específicos, puede ver mi otro blog.
Puede haber omisiones en los siguientes pasos, o puede haber algunas diferencias con los tuyos. Si tienes alguna pregunta, por favor comenta o envía un mensaje privado.
Permítanme hablar sobre el entorno primero , el sistema operativo de la computadora es win10, la plataforma del servidor en la nube usa Hengyuan Cloud y el IDE usa la versión profesional de Pycharm (versión 2022.1.3, tenga en cuenta que la versión comunitaria no puede usar el servidor en la nube , los estudiantes pueden solicitar la versión profesional de forma gratuita, pasos específicos Otros blogs sobre CSDN describen en detalle), el sistema operativo del servidor es Linux.
plataforma en la nube
Elegí Hengyuan Cloud antes, pero descubrí que la versión revisada se está volviendo cada vez más difícil de usar. Ahora cambié a autodl , y el precio es bastante económico. La certificación del partido estudiantil es miembro. Sin embargo, la documentación de autodl no es tan fácil de usar como la de Hengyuan Cloud.
Operación de la plataforma en la nube
Seleccione la GPU a utilizar
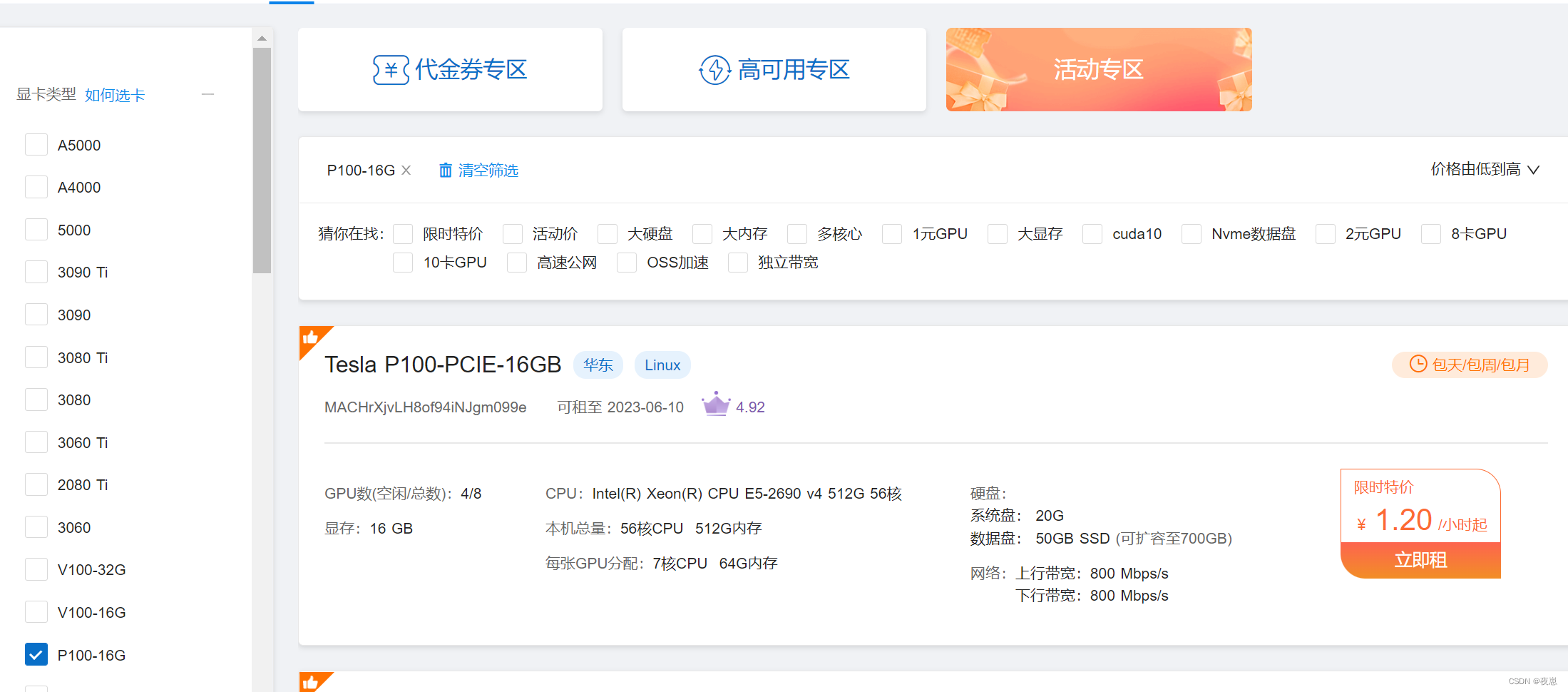
La imagen de arriba es la interfaz del mercado en la nube, el lado izquierdo se puede usar para filtrar los modelos de GPU y el lado derecho son las GPU disponibles. Se divide en vales, alta disponibilidad y actividades, y los dos últimos requieren efectivo.Esta demostración utiliza el área de vales para demostrar.
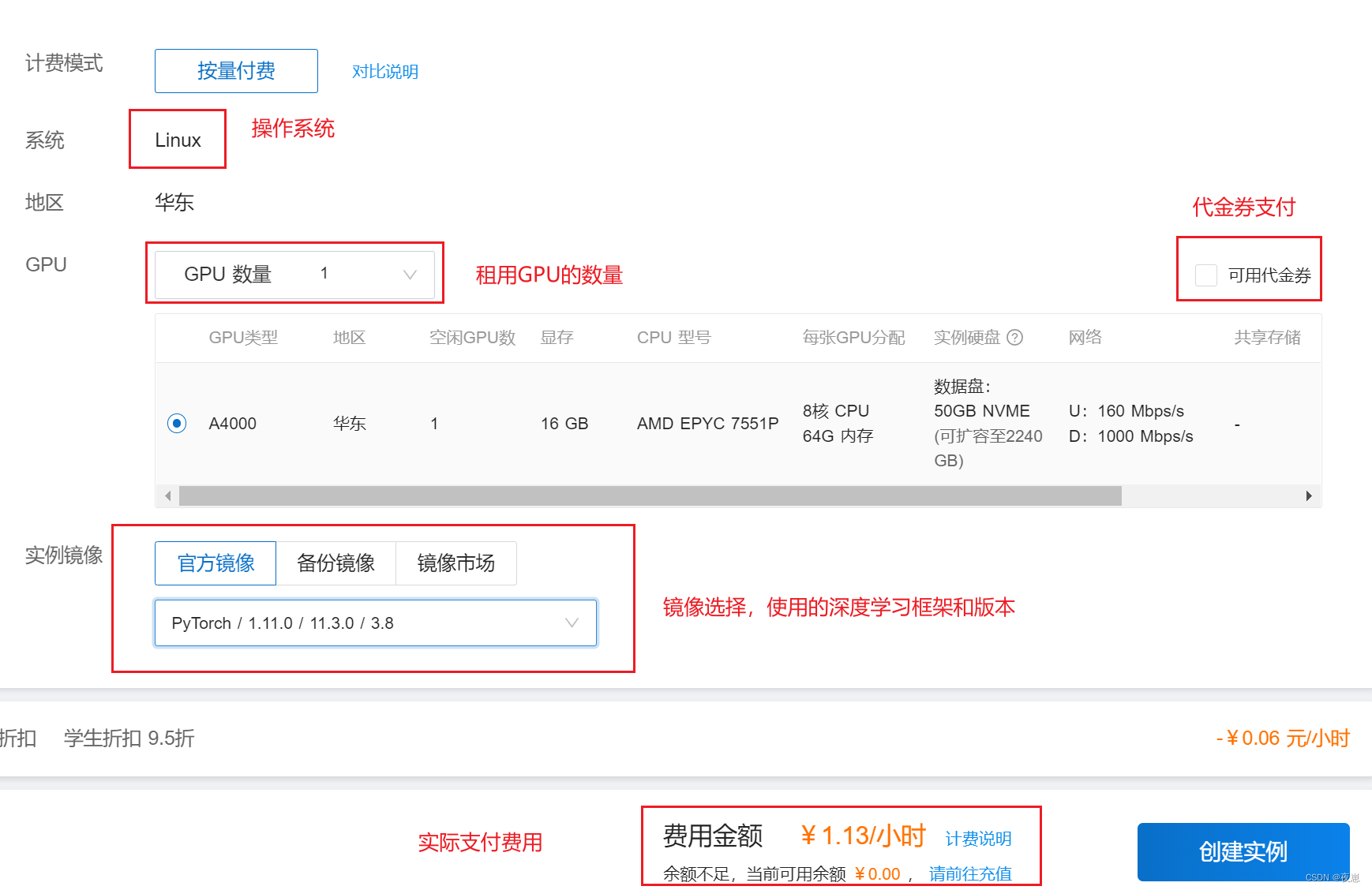
La imagen de arriba es la interfaz después de hacer clic en alquilar, y hay introducciones específicas en la imagen. Cabe señalar que si la imagen es la misma pero la GPU es diferente, el entrenamiento fallará (me he encontrado con este problema, y la razón no está particularmente clara, puede ser un problema con la imagen).
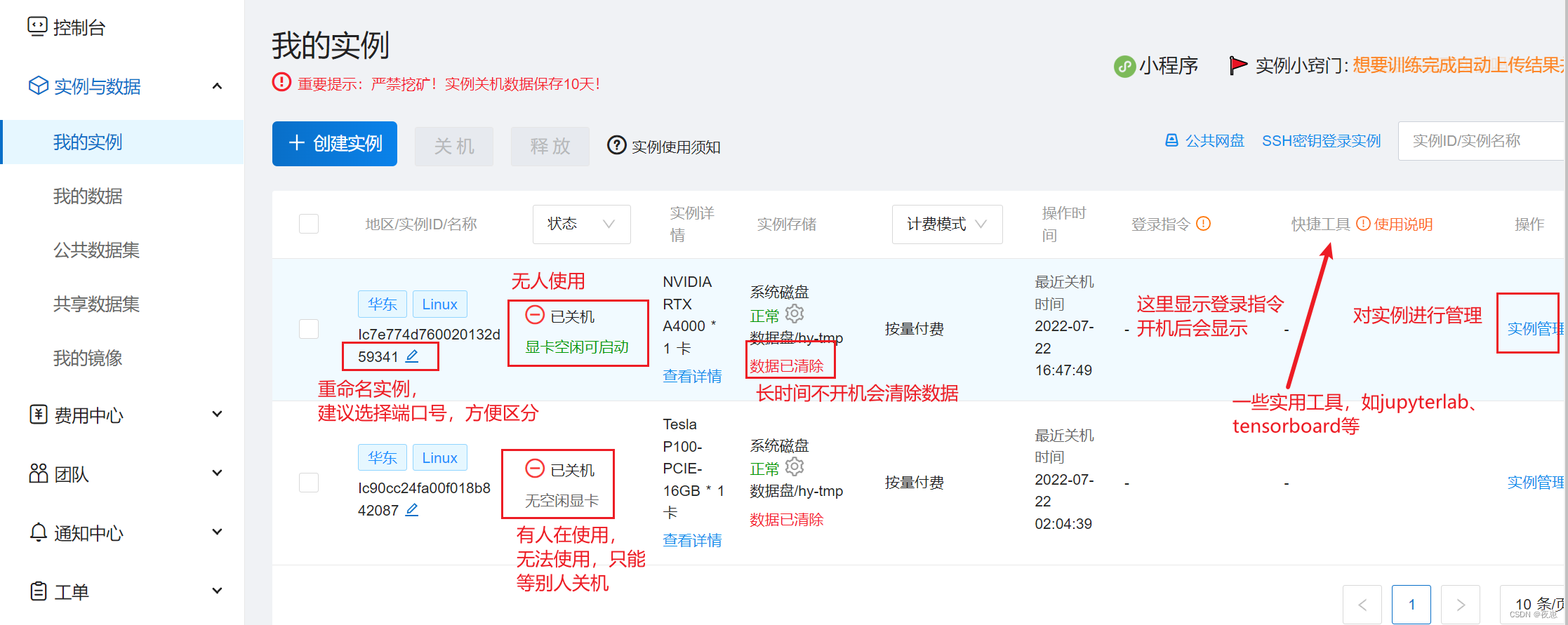
Después de que la instancia se haya creado con éxito, abra mi instancia y podrá ver la siguiente interfaz. Aquí usaré la instancia que creé antes para mostrarla. Se ha marcado cierta información básica en la imagen. El siguiente paso es iniciar la instancia, encenderla a través del botón de administración de instancias y apresurarse.
 ? ? ? Cara de signo de interrogación (no más, no hay dinero, termina aquí)
? ? ? Cara de signo de interrogación (no más, no hay dinero, termina aquí)
Después de mirarlo, de repente se convirtió en que solo puede usar dinero real para pagar. Agregue otra desventaja, que en realidad es similar a la primera desventaja. Los cambios son demasiado frecuentes. Puede usar el cupón por un tiempo y luego puede ' T. Alquilé uno de nuevo.

Ok, el arrendamiento es exitoso, la interfaz es como se muestra arriba después del inicio y luego configure pycharm.
configuración de pycharm

Abra la configuración, haga clic en el intérprete de python y agregue un nuevo intérprete a través del engranaje de la derecha (hay dos formas de agregar un servidor y la otra es operar a través de Herramientas/Herramientas en la barra de menú)
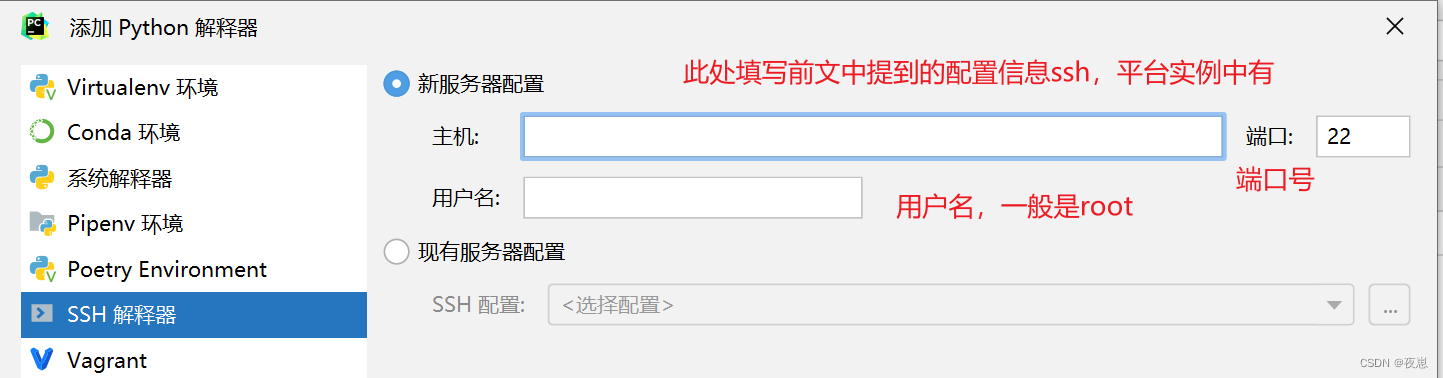
ssh -p 45269 [email protected] El número de puerto es 45269, el nombre de usuario es root, el host es i-2.gpushare.com, complete y haga clic en Aceptar para conectarse.

Complete la contraseña y recuerde guardar la contraseña para la próxima conexión.
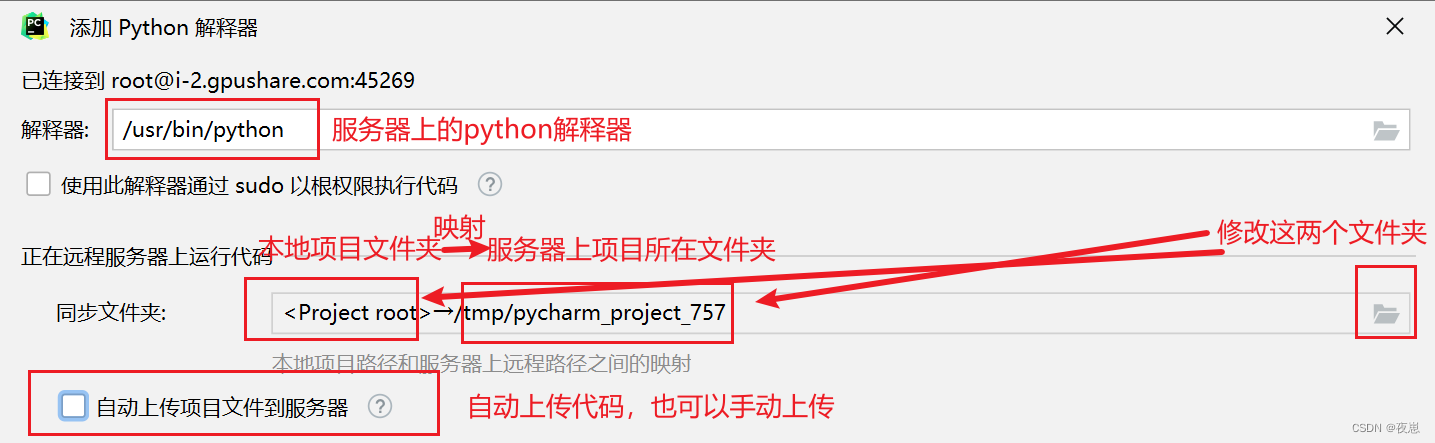
El intérprete de python en el servidor está configurado de forma predeterminada y la ruta remota se modifica de la siguiente manera.
Nota: Se recomienda cargar el proyecto manualmente (se describe a continuación), y es posible que la ruta remota deba modificarse por segunda vez para la carga automática.
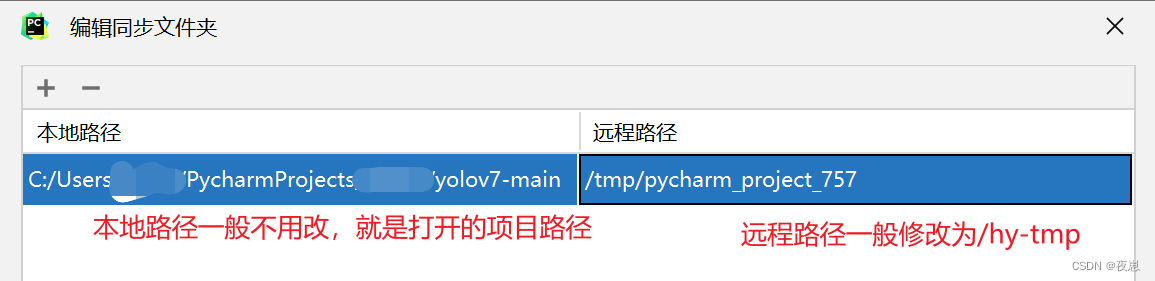
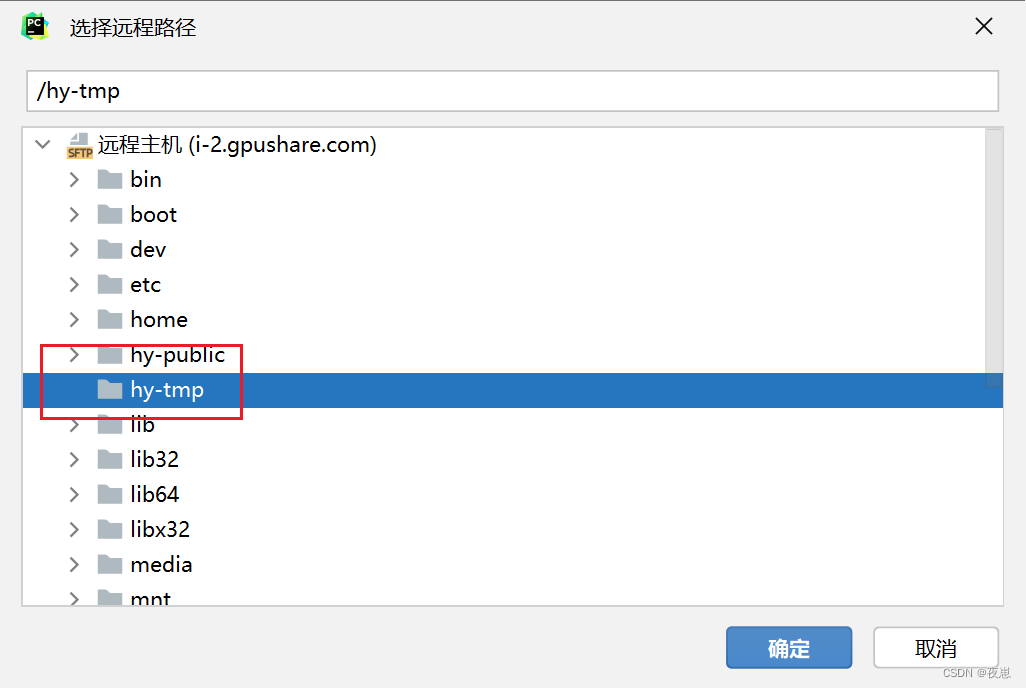
Una vez completada la selección, haga clic en Aceptar y luego vaya al siguiente paso sin pensar.
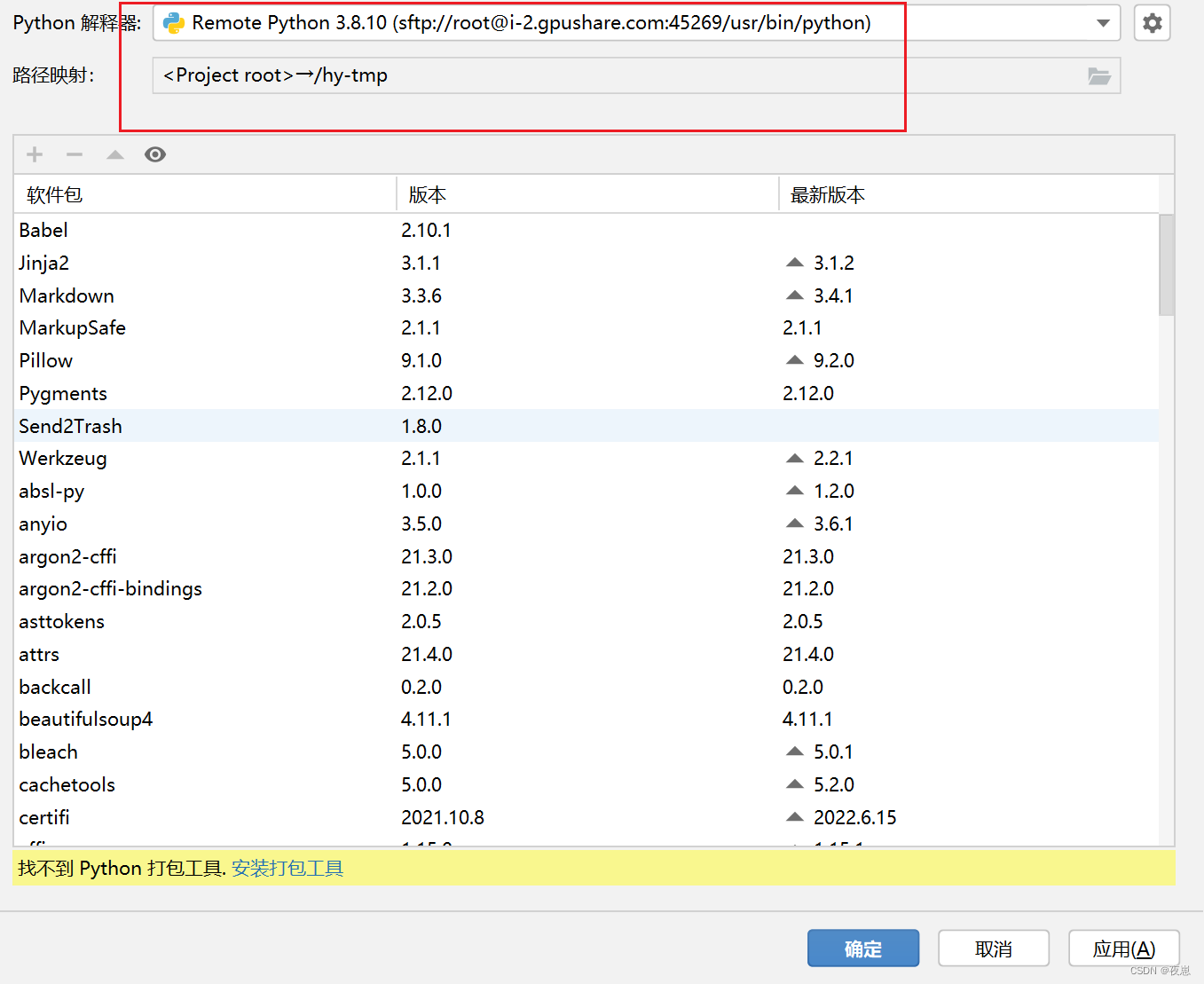
Aparece la interfaz anterior, es decir, la configuración es exitosa, haga clic en Aplicar y confirme.

Después de regresar a la interfaz de pycharm, verá la imagen de arriba en la esquina inferior derecha de la parte inferior. El lado derecho es el intérprete de python remoto configurado, y el lado izquierdo es el servidor. Debe hacer que estos dos sean uno a uno. una correspondencia. Si no corresponden, puede modificar el servidor. Simplemente haga clic en Revisado a 45269.
Una vez que el servidor se haya configurado correctamente, el intérprete y el paquete de software descargado en el servidor se actualizarán en segundo plano. Si se configura la carga automática, el código también se cargará automáticamente (si el conjunto de datos está en el proyecto, se cargará automáticamente). también pueden cargarse juntos, lo que hará que el tiempo de carga sea muy largo, generalmente no se recomienda cargar datos de esta manera, puede cargarlos a través de oss, consulte a continuación)
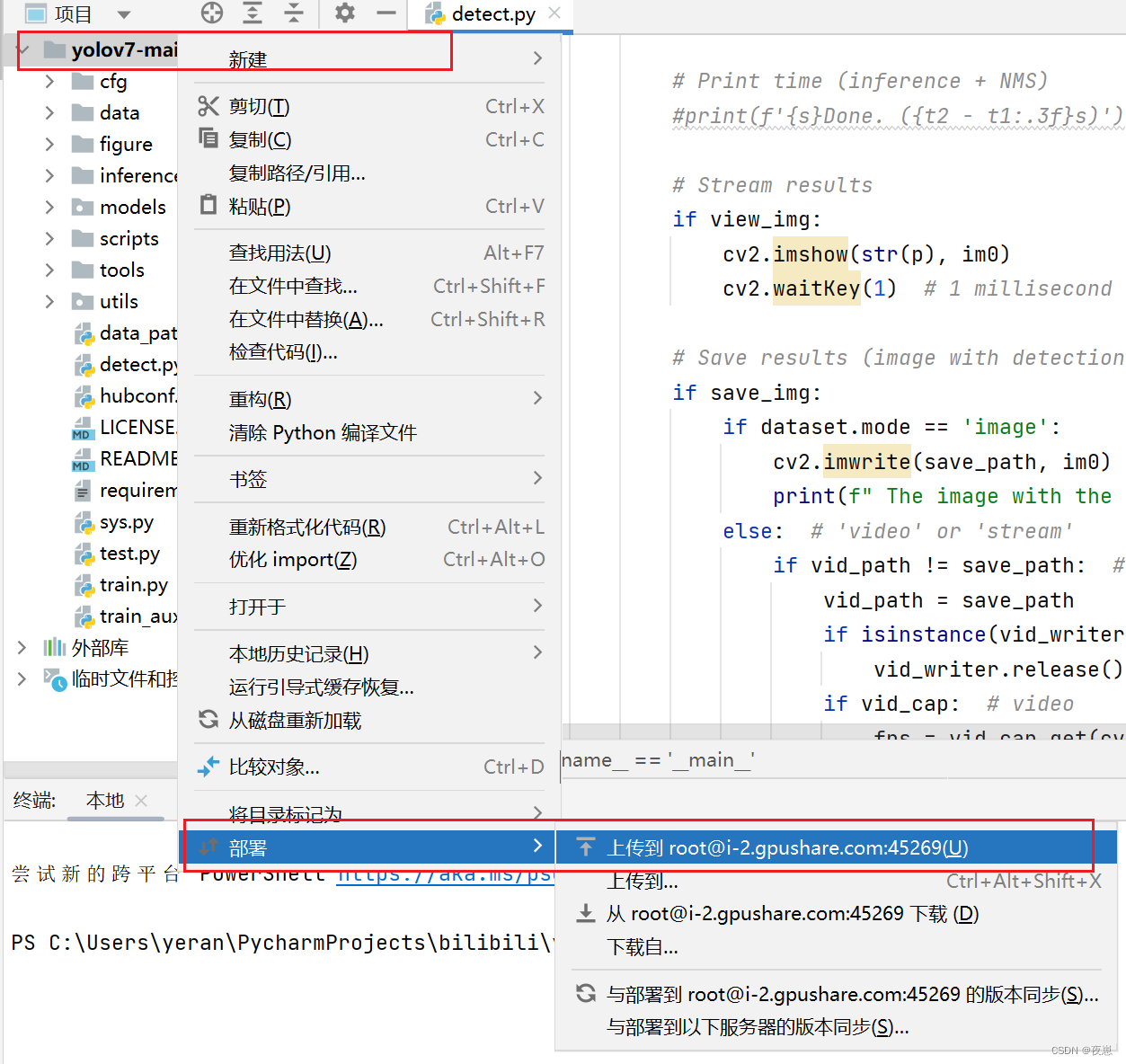
Si la carga automática no está configurada, cargue manualmente los archivos al servidor haciendo clic derecho en el directorio raíz del proyecto, como se muestra arriba. Después de que la carga sea exitosa, puede hacer clic en jupyterlab para ver el archivo a través de la página web de Hengyuan Cloud.
 Puede ver los archivos cargados, porque no hay un conjunto de datos, por lo que la velocidad es muy rápida.
Puede ver los archivos cargados, porque no hay un conjunto de datos, por lo que la velocidad es muy rápida.
En este punto, la configuración de pycharm está básicamente completa.
carga de datos
La carga de datos en la nube de Hengyuan utiliza varios métodos, como os, se recomienda usar os para cargar, primero descargue os en el local.
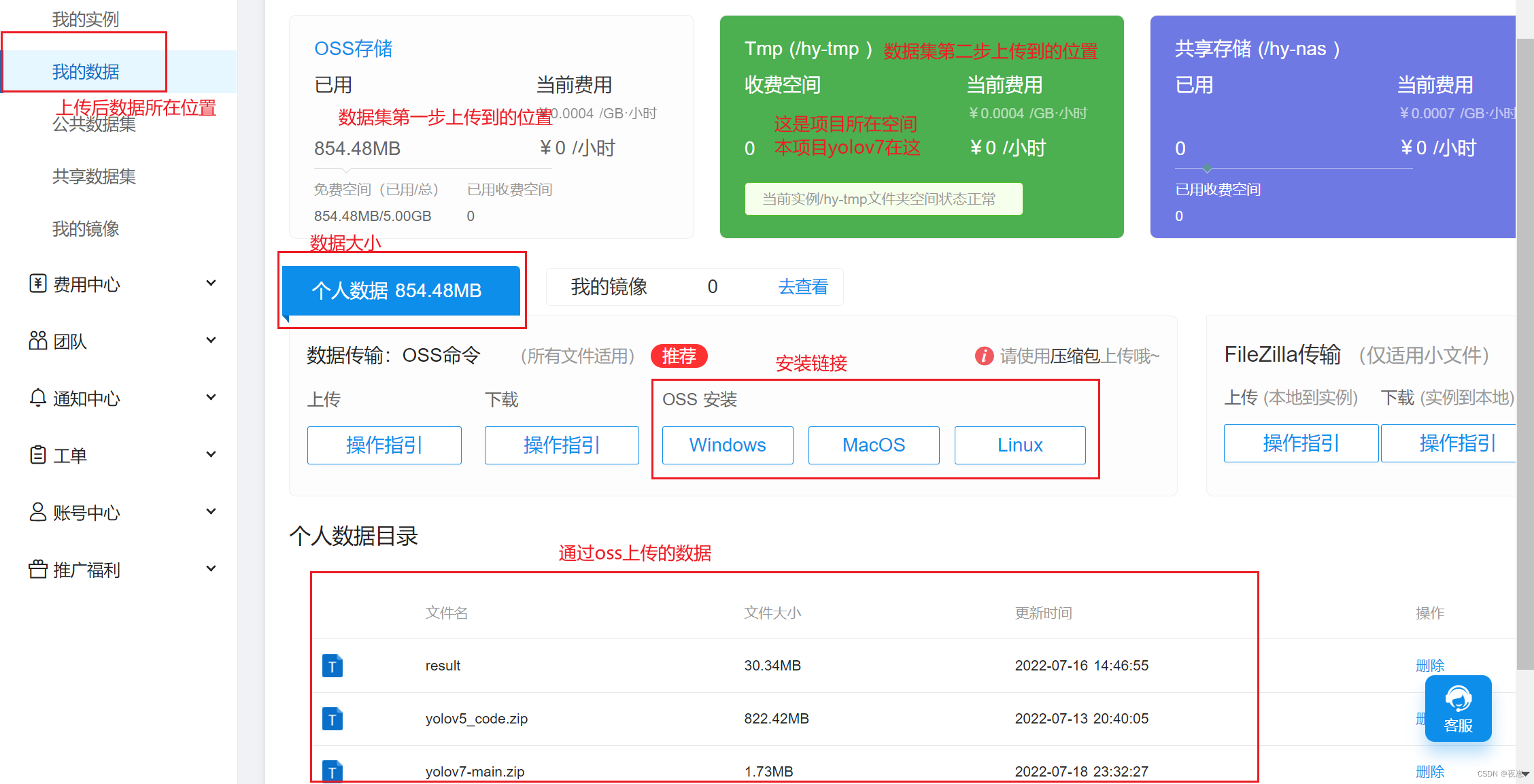
Una vez completada la descarga, abra oss.exe, ingrese el inicio de sesión para iniciar sesión, ingrese el número de cuenta y la contraseña de Hengyuan Cloud, y el inicio de sesión es exitoso
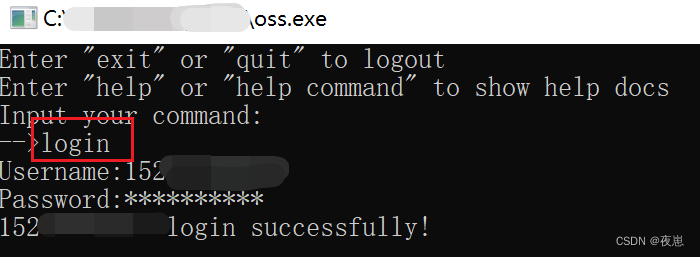
Cargue datos, tenga en cuenta que solo se pueden cargar paquetes comprimidos.
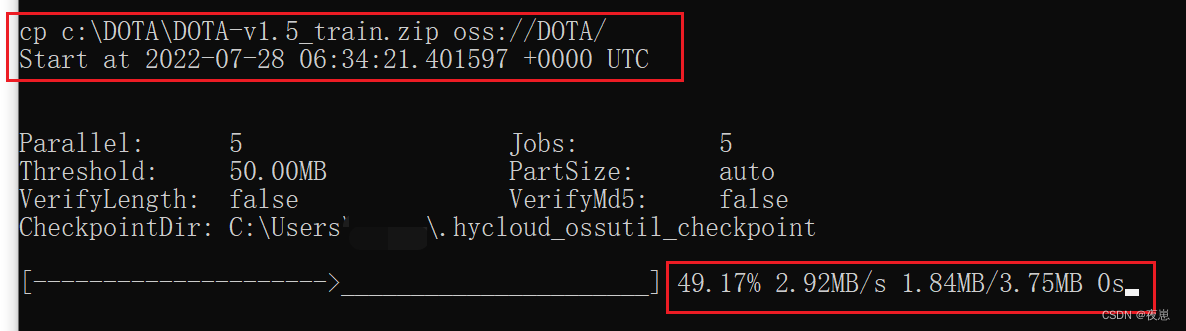
Cargue el archivo de anotación del conjunto de datos DOTA en la unidad c a la carpeta DOTA en oss a través del comando en la figura anterior, como se muestra en la figura a continuación.

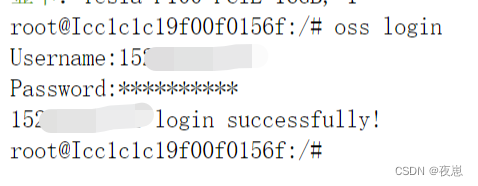
Copie el conjunto de datos en el directorio de datos personales al directorio /hy-tmp, a través de la terminal en pycharm o jupyterlab. Aquí está la implementación de terminal de jupyterlab, primero inicie sesión y luego copie el archivo al directorio hy-tmp a través de la línea de comando, como se muestra en la figura a continuación.
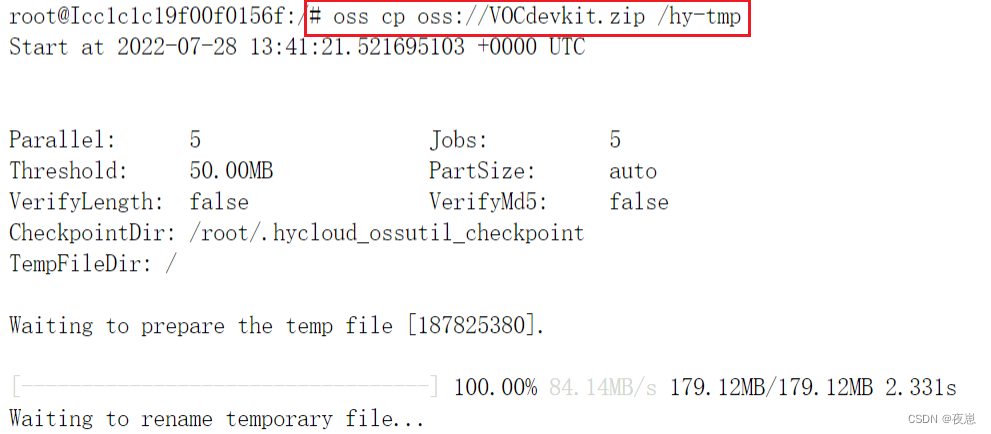
Luego cree un directorio mydata para almacenar los archivos descomprimidos y descomprima el conjunto de datos en la carpeta mydata.

Hasta ahora, pycharm y el servidor están todos configurados. Después de modificar el código y cargarlo en el servidor, puede hacer clic para ejecutarlo en pycharm (tenga en cuenta los requisitos ambientales en requisitos.txt). Si el programa reporta un error, puedes leer mi otro blog, puede ser por alguna configuración o el paquete no está instalado.
Si hay errores en el artículo, por favor hágamelo saber.