Enlace de video de demostración : ¡Puedes hacer clic para verlo!
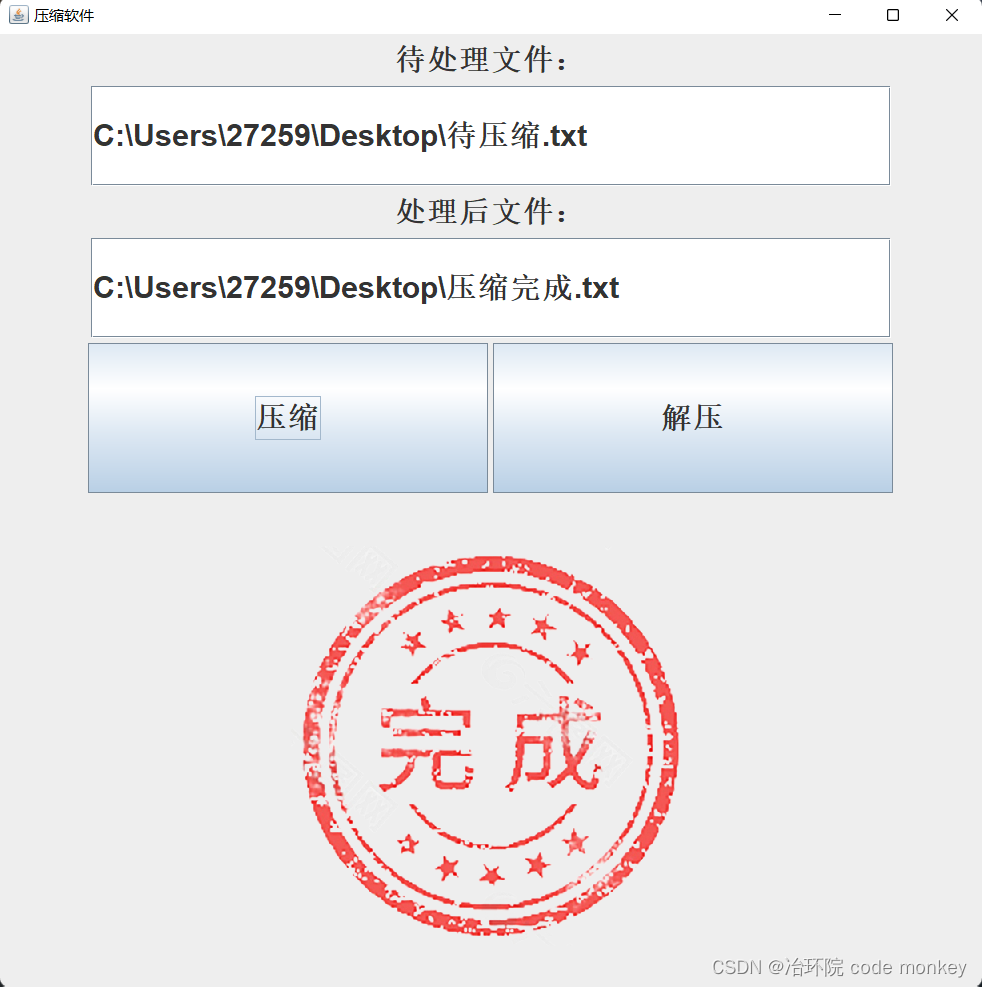
Software de compresión zip para completar la idea.
- principio:
- lograr:
-
- Método de compresión:
-
- 1. Lea el documento y cree hashMap<>:
- 2. Toma el árbol de Huffman:
- 3. Obtenga el código de carácter y guárdelo en hashMap<código, carácter>:
- 4. Decodifique de acuerdo con hashMap<Character, String> para obtener una cadena 0/1:
- 5. (0/1 cadena -> byte[]) escriba en el documento (tenga en cuenta que se escribe hashMap<encoding, character>):
- Método de descompresión:
- diseño de interfaz:
- mejoramiento
- Empaquetado en un archivo jar: *como se muestra*
- Código fuente (con todo el código):
principio:
Según el método de codificación UTF-8, los caracteres suelen ocupar varios bytes, si los representamos en bits binarios (y también se pueden decodificar con la ayuda de bits binarios), se ahorrará mucho espacio.
Y debido a que usamos el número de ocurrencias para construir un árbol de Huffman para obtener el código binario representativo (puede pensarlo un poco, ¿cómo obtenerlo?), cuanto mayor sea la frecuencia de ocurrencia, más corto será el código binario representativo, haciendo el efecto de compresión más superior
| puntos de conocimiento | Fundamental |
|---|---|
| entrada y salida de archivos | Use el flujo de entrada y salida para completar (OutputStream/InputStream), operaciones de lectura y escritura por byte, y cómo escribir y leer |
| tabla de picadillo | Use la clave para encontrar una matriz de valores de lista vinculada, puede leer el artículo que escribí: hashMap |
| árbol de huffman | Construya un árbol según el peso de cada dato, es decir, los dos valores con el peso más pequeño se fusionan en un árbol cuyo nodo raíz es la suma de pesos, y luego el peso del nodo padre se pone en el restante. datos, y el ciclo continúa hasta que solo hay un número |
| concatenación de cadenas | La lógica subyacente es que cada vez que se empalma, se debe crear un objeto StringBuilder, y luego se asigna el método Copiar (que atraviesa la cadena) al objeto y, después del empalme, devuelve el valor a la cadena. |
lograr:
Método de compresión:
1. Lea el documento y cree hashMap<>:
Vale la pena señalar que siempre que queramos usar los flujos de entrada y salida, tenga cuidado de lanzar una excepción.
Al mismo tiempo, el texto se puede obtener por el método escrito en el segmento de código.
Finalmente, el uso de hashMap también es muy simple, solo necesita recorrer primero la matriz de caracteres de la cadena, verificar si el carácter (clave) existe y luego modificar el peso (número de ocurrencias) para almacenarlo. Después de depositar, use Set para mapear y crear nuestro nodo inicial
//读取待压缩文件
private String readWaitCop(File wait) throws IOException {
//读取文件内容
FileInputStream fip = new FileInputStream(wait);
byte[] buf = new byte[fip.available()];
//**重中之重,一定要先读文本内容,填充这个byte数组,不然出大乱子——————大冤种的劝告 ~_~。
/**
* 在文件读写里:string 和 byte 可以互换,达到input/output都成为可阅读文本
* 写文件:fop.write(String.getBytes());
* 读文件: fip.read(bytes[]);
* new String(bytes[])
*/
fip.read(buf);
return new String(buf);
}
//获取权值和内容,构建初始节点
private String initSet(File wait) throws IOException {
String str = readWaitCop(wait);
HashMap<Character,Integer> hashMap = new HashMap<Character,Integer>();
char[] chars = str.toCharArray();
for (char cc:chars) {
String sinStr = String.valueOf(cc);
if(hashMap.containsKey(cc)){
hashMap.put(cc, hashMap.get(cc) + 1);
}else{
hashMap.put(cc,1);
}
}
Set<Map.Entry<Character, Integer>> entrys = hashMap.entrySet();
for(Map.Entry<Character, Integer> entry:entrys) {
Node node = new Node(null,null, entry.getKey(), entry.getValue(), null);
arrayList.add(node);
}
return str;
2. Toma el árbol de Huffman:
En primer lugar, debemos comprender el establecimiento de los nodos: puede echar un vistazo a mi clase de Nodo interno: los
nodos izquierdo y derecho son convenientes para construir árboles, los pesos se usan para comparar, el camino puede registrar la codificación realizada y contenido registra el contenido del carácter
//内部节点类
public class Node{
private Node left;
private Node right;
//出现频率(权值)
private int num;
//记载路径
private String road;
//记载内容
private char content;
public Node(Node left, Node right,char content, int num,String road) {
this.left = left;
this.right = right;
this.content = content;
this.num = num;
this.road = null;
}
}
La idea es la misma que el árbol de Huffman en el principio. Puedes ver cómo me di cuenta. Vale la pena
señalar que cada vez que se encuentra el peso mínimo, el nodo debe eliminarse para evitar comparaciones repetidas. Al
mismo tiempo, cuando quede el último nodo, el árbol se ha construido, registre el nodo raíz.
Dado que siempre se usa el ArrayList de este nodo, recuerde borrar el último nodo.
//搭建树
private void setTree(){
while(arrayList.size() != 1){
//最小权值结点
Node bro1 = Min();
Node bro2 = Min();
Node father = new Node(bro1,bro2,'0',bro1.num + bro2.num,null);
arrayList.add(father);
}
root = arrayList.get(0);
arrayList.remove(0);
}
//找到最小权值
private Node Min(){
int minIndex = 0;
for (int i = 0; i < arrayList.size(); i++) {
if(arrayList.get(minIndex).num > arrayList.get(i).num){
minIndex = i;
}
}
Node node = arrayList.get(minIndex);
arrayList.remove(minIndex);
return node;
}
3. Obtenga el código de carácter y guárdelo en hashMap<código, carácter>:
La codificación de caracteres mencionada aquí es el camino del nodo ¿Cómo realizarlo?
De hecho, podemos atravesar el árbol de Huffman. Ir a la izquierda es '0', e ir a la derecha es '1', lo que resuelve la codificación, y el peso que usamos antes hace que algunas capas de datos de uso común sean más Less, entonces la codificación es más corta para lograr el efecto de compresión
El siguiente código está codificado:
el nodo que almacena los datos reales es en realidad un nodo hoja, es decir, el nodo no tiene nodos secundarios. Puede pensar en el motivo de esto.
El árbol transversal en realidad tiene una variedad de métodos, como el recorrido previo al pedido y el recorrido posterior al pedido, pero lo que escribí usa el recorrido transversal por orden de capas, que puede evitar la recursividad y simplificar el pensamiento.
Pero vale la pena señalar que la cola Queue está escrita por mí mismo, por lo que puede ser diferente de la normal.

Puede explicar el recorrido del orden jerárquico: dado que el árbol de Huffman es un árbol binario perfecto, cada nodo tiene dos o ningún nodo secundario, por lo que podemos usar la estructura de datos de cola para abrir un nodo, empujar dos nodos y luego Debido a la Mecanismo FIFO, se consigue el efecto transversal.
Entonces, en cuanto a por qué se almacena en hashMap, es importantepresagiando, seguido de una explicación.
//得到路径
private void setRoad() throws IOException {
Queue<Node> queue = new Queue<>();
queue.enqueue(root);
root.road = "";
while (!queue.isEmpty()){
if(queue.peak().left != null) {
queue.enqueue(queue.peak().left);
queue.peak().left.road = queue.peak().road + '0';
}
if(queue.peak().right != null){
queue.enqueue(queue.peak().right);
queue.peak().right.road = queue.peak().road + '1';
}else{
arrayList.add(queue.peak());
}
queue.dequeue();
}
//得到readMap
for (int i = 0; i < arrayList.size(); i++) {
readMap.put(arrayList.get(i).road,arrayList.get(i).content);
}
}
4. Decodifique de acuerdo con hashMap<Character, String> para obtener una cadena 0/1:
Aquí es relativamente simple, recorrer el texto que leemos, reemplazar los caracteres con sus códigos 0/1 correspondientes según el hashMap, y obtener una nueva cadena, pero debes entender que como 1 byte = 8 bits, necesitamos Complementar a un múltiplo de 8, de lo contrario habrá un error cuando se convierta a byte y se escriba en el archivo Al mismo tiempo, después de completar, se debe agregar el número de dígitos adicionales al encabezado de la cadena.
//存入内容
char[] chars = comContent.toCharArray();
//先将comContent清空,得到有效位数+二进制字符串
/**
* 这是压缩时最耗时间的部分,可以考虑换成string来算,因为这个比char的hashcode算的快,
* 因为算hashCode从map取值,重复过多了
*/
//注意清空啊,嘚吧!
comContent = "";
StringBuilder builder = new StringBuilder();
for (char cc:chars) {
//hashMap.get可查看源码,返回值为V;
builder.append(hashMap.get(cc));
}
//存入补足编码
int num = 8 - builder.length() % 8;
for (int i = 0; i < num; i++) {
builder.append('0');
}
//存入补的位数,直接存数字,eg:……+"num"。
byte b = (byte) num;
//运用 StringBuilder ,出现了heap溢出
builder.insert(0,String.valueOf(b));
comContent = builder.toString();
Vale la pena señalar: comContent se obtiene por medio de initSet (esperar) [inicializar el nodo de construcción], y recuerde convertirlo en una matriz char [], y recuerde borrarlo para obtener la cadena codificada
5. (0/1 cadena -> byte[]) escriba en el documento (tenga en cuenta que se escribe hashMap<encoding, character>):
Aquí hablamos principalmente sobre el método de convertir cadenas 0/1 en bytes. Cuando se lee '0', el byte se desplaza a la izquierda, y cuando se lee '1', el byte se desplaza a la izquierda, y + 1 , leído ocho veces Puede formar un valor btye y escribirlo en byte 【】.
Y el primer bit de nuestro byte[] almacena los bits 0/1 efectivos del último byte, lo cual es conveniente para el proceso de descompresión, por lo que
convertimos el texto en una matriz byte[], que cumple con los requisitos para escribir archivos.
//写入到文件的具体方法
private void outputStream(String comContent,File after) throws IOException {
//得到要写入字符串的字符
char[] chars = comContent.toCharArray();
//得到需要写多少byte,初始位置存num
byte[] bytes = new byte[(chars.length - 1) / 8 + 1];
//得到最后一个字节中的几位有效
int num = 8 - ((int) chars[0] - 48);
//(byte)转型,可以得到int num的最后一个字节
bytes[0] = (byte) (num & 255);
//第一位是存储需要丢弃几个数字,所以可以从下标1开始
for (int i = 1; i < bytes.length; i++) {
byte b = 0;
int bb = i - 1;
for (int j = 1; j <= 8; j++) {
if(chars[bb * 8 + j] == '0'){
b = (byte) (b << 1);
}else{
b = (byte) (b <<1 + 1);
}
bytes[i] = b;
}
}
//开写开写
FileOutputStream fop = new FileOutputStream(after);
/**
* 可以去仔细研究:::
* 写入readMap,只能用ObjectInputStream,写入任何类型
* 但要注意,该类型要实现java.io.Serializable,使其“序列化”
*/
ObjectOutputStream foop = new ObjectOutputStream(fop);
//写入任何类型
foop.writeObject(readMap);
fop.write(bytes);
}
Aquí necesitamos enfatizar el 3. pasopresagiandoSí, porque las reglas de codificación son diferentes, por lo que para descomprimirlo y leerlo, necesitamos una tabla de decodificación como referencia, que es el hashMap que guardamos en ese momento. Si falta esta forma, uno puede imaginar que después de que el telegrama fue interceptado durante la Segunda Guerra Mundial, la expresión de su rostro era desconcertada, como si hubiera sido abolida, y no supiera qué decir. La tabla de decodificación se escribe con la ayuda de ObjectOutputStream (ambos basados en File I/O Stream), que es potente y se puede escribir en cualquier tipo que implemente la interfaz Serializable.
Si tienes curiosidad al respecto, puedes echarle un vistazo.
Método de descompresión:
1. (byte[]->0/1 cadena) proceso:
Tenga en cuenta que el cambio se cambia continuamente de 7->0, por lo que la cadena 0/1 se puede obtener en orden, puede pensarlo usted mismo.
for (int i = 1; i < bytes.length; i++) {
//将byte转换为字符串
for (int j = 7; j >= 0 ; j--) {
int num = bytes[i];
if(((num >> j) & 1) == 0){
codeBulider.append('0');
}
else{
codeBulider.append('1');
}
}
}
2. De acuerdo con la lectura hashMap<código, carácter>, (0/1 cadena -> Cadena), obtenga la cadena de contenido real
Lea nuestra tabla de decodificación hashMap<encoding, character>
FileInputStream fip = new FileInputStream(wait);
// Object的输入输出流都是基于file输入输出流
ObjectInputStream fiop = new ObjectInputStream(fip);
Comience a decodificar, use sinBuilder (carácter único) para empalmar un 0/1, y luego averigüe si existe la clave (código), y repita hasta que exista el código, luego use contentBuilder para empalmar hashMap a través de la clave para averiguar el valor
( carácter), la navegación se completa y hemos completado la decodificación.在这里插入代码片
for (char cc:chars) {
sinBuilder.append(cc);
if(readMap.containsKey(sinBuilder.toString())){
contentBuilder.append(readMap.get(sinBuilder.toString()));
sinBuilder.delete(0, sinBuilder.length());
}
}
content = contentBuilder.toString();
3. Escriba en el archivo descomprimido:
Recuerde usar el método String.getBytes() cuando escriba en un String.
FileOutputStream fop = new FileOutputStream(after);
fop.write(content.getBytes());
diseño de interfaz:
Diseño de apariencia:
No es más que crear un formulario y luego unos componentes, el código está en el código fuente, que es muy sencillo.
Crear ActionListener
Podemos pasar la clase de escucha interna, de modo que podamos llamar a los datos requeridos a voluntad, sin intentar pasarlos.
Por ejemplo, aquí podemos usar directamente el texto del cuadro de texto, sin obtener primero su dirección antes de poder operar.
Nota: Hay un punto y coma al final de la clase de escucha interna, que puede entenderse como una declaración larga.
ActionListener ac = new ActionListener() {
@Override
public void actionPerformed(ActionEvent e) {
Color tuWhite = new Color(238,238,238);
g.setColor(tuWhite);
g.fillRect(300,550,400,400);
g.drawImage(starBuf,300,550,400,400,null);
long start = System.currentTimeMillis();
String btname = e.getActionCommand();
File wait = new File(jt1.getText());
File after = new File(jt2.getText());
if(btname.equals("压缩")){
try {
hf.copCode(wait,after);
} catch (IOException ex) {
ex.printStackTrace();
}
}else{
try {
hf.unPack(wait,after);
} catch (IOException ex) {
ex.printStackTrace();
} catch (ClassNotFoundException ex) {
ex.printStackTrace();
}
}
long end = System.currentTimeMillis();
double time = (end - start) / 1000;
System.out.println(btname + ": "+ time + " S");
g.setColor(tuWhite);
g.fillRect(300,550,400,400);
g.drawImage(finBuf,300,550,400,400,null);
}
};
Agregar logotipo de imagen en ejecución
Cuando se hace clic en el botón, podemos dibujar nuestra imagen de barra de carga y dibujar la imagen de éxito del sello después del final Estos códigos están todos arriba.
mejoramiento
Velocidad de impulso
Si usa el proceso de empalme de cuerdas original, encontrará que es extremadamente lento y ha llegado a un punto insoportable.Aquí propongo mi propia solución.
1. Encuentra el peso mínimo:
Solución: si está utilizando una clasificación de bajo nivel, como la clasificación de burbujas, su eficiencia es baja y, obviamente, no es aplicable cuando hay muchos caracteres. Puede usar la ordenación rápida o, como yo, encontrar directamente el subíndice del valor mínimo, lo que puede mejorar en gran medida la velocidad.
2. Empalme de cuerdas que requiere mucho tiempo:
Solución: si usa directamente el "+" de la cadena para empalmar, de acuerdo con su principio subyacente, podemos pensar en cuánto tiempo se pierde. Cada conexión debe atravesarse y copiarse, y luego empalmarse, [la complejidad del tiempo es (n^2)]. Por lo tanto, solo necesitamos crear un objeto StringBuilder, que empalma todo el contenido y luego lo convierte en un tipo String.
El efecto es muy notable, en aquella época tardaba más de 200 segundos para un archivo de menos de 1M, pero ahora solo tarda unos 6 segundos para un archivo de 100M.
Si está interesado, puede echar un vistazo al método de adición de String.
aumentar la capacidad
StringBuilder tiene un límite
Cuando se utiliza la compresión de texto de 300 M, se informará una excepción de desbordamiento del montón.Después de consultar el código fuente de StringBuilder, se encuentra que su capa inferior es una matriz char[], y su longitud está limitada al tipo int, por lo que cuando hay demasiados textos , acumulará desbordamiento de memoria
Solución: podemos crear una matriz de StringBuilder【】, especificar cuántos caracteres conectar, luego ir al siguiente StringBuilder y finalmente empalmar, para que la capacidad se pueda expandir.
Esta es solo una idea personal y aún no se ha completado. Espero que las personas con ideales elevados puedan operarla.
Empaquetado en un archivo jar: como se muestra en la figura

Código fuente (con todo el código):
1. Interfaz
package fcj1028;
import javax.imageio.ImageIO;
import javax.swing.*;
import java.awt.*;
import java.awt.event.ActionEvent;
import java.awt.event.ActionListener;
import java.awt.image.BufferedImage;
import java.io.File;
import java.io.IOException;
public class Ui extends JFrame {
public void ui() throws IOException {
Huffman_Compress hf = new Huffman_Compress();
this.setTitle("压缩软件");
this.setSize(1000,1000);
this.setDefaultCloseOperation(WindowConstants.EXIT_ON_CLOSE);
this.setLocationRelativeTo(null);
JLabel jl1 = new JLabel("待处理文件:");
jl1.setFont(new java.awt.Font("Dialog", 1, 30));
JLabel jl2 = new JLabel("处理后文件:");
jl2.setFont(new java.awt.Font("Dialog", 1, 30));
JTextField jt1 = new JTextField();
Dimension dim1 = new Dimension(800,100);
Dimension dim2 = new Dimension(400,150);
jt1.setFont(new java.awt.Font("Dialog", 1, 30));
JTextField jt2 = new JTextField();
jt2.setFont(new java.awt.Font("Dialog", 1, 30));
JButton jb1 = new JButton("压缩");
jb1.setFont(new java.awt.Font("Dialog", 1, 30));
JButton jb2 = new JButton("解压");
jb2.setFont(new java.awt.Font("Dialog", 1, 30));
jt1.setPreferredSize(dim1);
jt2.setPreferredSize(dim1);
jb1.setPreferredSize(dim2);
jb2.setPreferredSize(dim2);
this.add(jl1);
this.add(jt1);
this.add(jl2);
this.add(jt2);
this.add(jb1);
this.add(jb2);
this.setLayout(new FlowLayout());
this.setVisible(true);
//先可视化,再得到画笔
Graphics g = this.getGraphics();
File starPic = new File("C:\\Users\\27259\\Pictures\\java_pic\\9df86687_E848203_9ea3a43f-removebg-preview.png");
BufferedImage starBuf = ImageIO.read(starPic);
File finPic = new File("C:\\Users\\27259\\Pictures\\java_pic\\R-C-removebg-preview(1).png");
BufferedImage finBuf = ImageIO.read(finPic);
ActionListener ac = new ActionListener() {
@Override
public void actionPerformed(ActionEvent e) {
Color tuWhite = new Color(238,238,238);
g.setColor(tuWhite);
g.fillRect(300,550,400,400);
g.drawImage(starBuf,300,550,400,400,null);
long start = System.currentTimeMillis();
String btname = e.getActionCommand();
File wait = new File(jt1.getText());
File after = new File(jt2.getText());
if(btname.equals("压缩")){
try {
hf.copCode(wait,after);
} catch (IOException ex) {
ex.printStackTrace();
}
}else{
try {
hf.unPack(wait,after);
} catch (IOException ex) {
ex.printStackTrace();
} catch (ClassNotFoundException ex) {
ex.printStackTrace();
}
}
long end = System.currentTimeMillis();
double time = (end - start) / 1000;
System.out.println(btname + ": "+ time + " S");
g.setColor(tuWhite);
g.fillRect(300,550,400,400);
g.drawImage(finBuf,300,550,400,400,null);
}
};
jb1.addActionListener(ac);
jb2.addActionListener(ac);
}
public static void main(String[] args) throws IOException {
new Ui().ui();
}
}
```java
```java
```java
2. Software de compresión
package fcj1028;
import Algorithm.Linear.Queue;
import java.io.*;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.Map;
import java.util.Set;
public class Huffman_Compress {
//写到压缩文件里,方便之后,文件读出内容(避免程序结束,所存hashMap消失)
private HashMap<String,Character> readMap = new HashMap<>();
//根节点,便于寻找
private Node root;
/**哈夫曼树:a.先对节点排序保存到List中
b.取出List中最小的两个节点,让它们的权值累加,保存新的父节点中
c.让最小两个节点作为左右子树,把父节点添加到List中重新排序
d.直到List只有一个节点
3.设置叶子节点的编码,往左编码为1 往右编码为0
统计每个叶子节点对应的编码
*/
//用途:节省空间存储内容
//原理:使用路径编码即可代表字符,而且越常用字符编码越少
//用来存节点
private ArrayList<Node> arrayList = new ArrayList<Node>();
//内部节点类
public class Node{
private Node left;
private Node right;
//出现频率(权值)
private int num;
//记载路径
private String road;
//记载内容
private char content;
public Node(Node left, Node right,char content, int num,String road) {
this.left = left;
this.right = right;
this.content = content;
this.num = num;
this.road = null;
}
}
//获取权值和内容,构建初始节点
private String initSet(File wait) throws IOException {
String str = readWaitCop(wait);
HashMap<Character,Integer> hashMap = new HashMap<Character,Integer>();
char[] chars = str.toCharArray();
for (char cc:chars) {
String sinStr = String.valueOf(cc);
if(hashMap.containsKey(cc)){
hashMap.put(cc, hashMap.get(cc) + 1);
}else{
hashMap.put(cc,1);
}
}
Set<Map.Entry<Character, Integer>> entrys = hashMap.entrySet();
for(Map.Entry<Character, Integer> entry:entrys) {
Node node = new Node(null,null, entry.getKey(), entry.getValue(), null);
arrayList.add(node);
}
return str;
}
//读取待压缩文件
private String readWaitCop(File wait) throws IOException {
//读取文件内容
FileInputStream fip = new FileInputStream(wait);
/**
* V1.0:一开始的想法是,得到的是byte【】数组,转换为字符串
* 其中借用了fip.available(),可以返回文件的字节数
* 但是问题在于,这样的话byte[]数组并不能转换成字符串内容,反而得到的是其长度
* 原因:当时也忘记了用fip.read(bytes)存放内容,所以读出长度十分正常
* 故,我们的想法可以是用将每个字节转换为char。
* V2.0:由于数字和中文编码并不一样,所以这个方法也要淘汰
* V3.0:在得到bytes[]后,可以使用String()方法,规定好长度自动会帮我们转型
* 值得注意的是:String.valueOf()会得到乱码
*/
byte[] buf = new byte[fip.available()];
//**重中之重,一定要先读文本内容,填充这个byte数组,不然出大乱子——————大冤种的劝告 ~_~。
/**
* 在文件读写里:string 和 byte 可以互换,达到input/output都成为可阅读文本
* 写文件:fop.write(String.getBytes());
* 读文件: fip.read(bytes[]);
* new String(bytes[])
*/
fip.read(buf);
return new String(buf);
}
//搭建树
private void setTree(){
while(arrayList.size() != 1){
//最小权值结点
Node bro1 = Min();
Node bro2 = Min();
Node father = new Node(bro1,bro2,'0',bro1.num + bro2.num,null);
arrayList.add(father);
}
root = arrayList.get(0);
arrayList.remove(0);
}
//找到最小权值
private Node Min(){
int minIndex = 0;
for (int i = 0; i < arrayList.size(); i++) {
if(arrayList.get(minIndex).num > arrayList.get(i).num){
minIndex = i;
}
}
Node node = arrayList.get(minIndex);
arrayList.remove(minIndex);
return node;
}
//得到路径
/**
* 首先表扬一下自己,通过不断输出语句还是找到了bug
* 这里的问题并非是树连接失败,而是我(nt)的忘了把队列里的节点叉出去,导致死循环
*/
private void setRoad() throws IOException {
Queue<Node> queue = new Queue<>();
queue.enqueue(root);
root.road = "";
while (!queue.isEmpty()){
if(queue.peak().left != null) {
queue.enqueue(queue.peak().left);
queue.peak().left.road = queue.peak().road + '0';
}
if(queue.peak().right != null){
queue.enqueue(queue.peak().right);
queue.peak().right.road = queue.peak().road + '1';
}else{
arrayList.add(queue.peak());
}
queue.dequeue();
}
//得到readMap
for (int i = 0; i < arrayList.size(); i++) {
readMap.put(arrayList.get(i).road,arrayList.get(i).content);
}
}
//写入到文件的具体方法
private void outputStream(String comContent,File after) throws IOException {
//得到要写入字符串的字符
char[] chars = comContent.toCharArray();
//得到需要写多少byte,初始位置存num
byte[] bytes = new byte[(chars.length - 1) / 8 + 1];
//得到最后一个字节中的几位有效
int num = 8 - ((int) chars[0] - 48);
//(byte)转型,可以得到int num的最后一个字节
bytes[0] = (byte) (num & 255);
//第一位是存储需要丢弃几个数字,所以可以从下标1开始
for (int i = 1; i < bytes.length; i++) {
byte b = 0;
/**
* V1.0:使用byte存储,思路是想用位运算使得效率更高,但是发现不是想要的效果,存入的都是0
* 原因:暂时还不清楚,可去看这篇文章
* https://blog.csdn.net/weixin_39775428/article/details/114176698
* 所以,现在还是用 * 2.
*/
int bb = i - 1;
for (int j = 1; j <= 8; j++) {
if(chars[bb * 8 + j] == '0'){
b = (byte) (b * 2);
}else{
b = (byte) (b * 2 + 1);
}
/**
* 值得注意:byte表示范围为 -128~127,一旦超出127,会自动转换
* 但是读取时就需要主要判断正负,得到第一位了,问题在于补码中的0,存在 10000000,00000000两种情况,需要特殊判断
*/
bytes[i] = b;
}
}
//开写开写
FileOutputStream fop = new FileOutputStream(after);
/**
* 可以去仔细研究:::
* 写入readMap,只能用ObjectInputStream,写入任何类型
* 但要注意,该类型要实现java.io.Serializable,使其“序列化”
*/
ObjectOutputStream foop = new ObjectOutputStream(fop);
//写入任何类型
foop.writeObject(readMap);
fop.write(bytes);
}
//得到压缩后的编码(除了补足八位,构成byte存入),还需要记录补了几个),并写入到文件
public void copCode(File wait,File after) throws IOException {
String comContent = initSet(wait);
setTree();
setRoad();
//利用HashMap存好字符的数据编码,即路径
HashMap<Character,String> hashMap = new HashMap<>();
for (Node node:arrayList) {
hashMap.put(node.content, node.road);
}
//存入内容
char[] chars = comContent.toCharArray();
//先将comContent清空,得到有效位数+二进制字符串
/**
* 这是压缩时最耗时间的部分,可以考虑换成string来算,因为这个比char的hashcode算的快,
* 因为算hashCode从map取值,重复过多了
*/
//注意清空啊,嘚吧!
comContent = "";
/**
* 神之一手 ———— 郝为高
* 由于每次字符串的连接,都会先创建 StringBuilder builder对象,浪费大量时间,不如直接一步到位,先创建出来
*/
StringBuilder builder = new StringBuilder();
for (char cc:chars) {
//hashMap.get可查看源码,返回值为V;
builder.append(hashMap.get(cc));
}
//存入补足编码
int num = 8 - builder.length() % 8;
for (int i = 0; i < num; i++) {
builder.append('0');
}
//存入补的位数,直接存数字,eg:……+"num"。
byte b = (byte) num;
//运用 StringBuilder ,出现了heap溢出
builder.insert(0,String.valueOf(b));
comContent = builder.toString();
builder.delete(0,builder.length());
outputStream(comContent,after);
}
//解压压缩后的文本
public void unPack(File wait,File after) throws IOException, ClassNotFoundException {
//开始读出readMap(sb,你自己要注意你是用的那个文件啊啊啊啊啊!!!!!)
FileInputStream fip = new FileInputStream(wait);
// Object的输入输出流都是基于file输入输出流
ObjectInputStream fiop = new ObjectInputStream(fip);
HashMap<String,Character> readMap = (HashMap<String, Character>) fiop.readObject();
//将内容都写到byte[]数组里
byte[] bytes = new byte[fip.available()];
fip.read(bytes);
/**
* 神之一手 ———— 郝为高
* 由于每次字符串的连接,都会先创建 StringBuilder builder对象,浪费大量时间,不如直接一步到位,先创建出来
*/
//存储编码后的0/1串
String copCode = "";
StringBuilder codeBulider = new StringBuilder();
for (int i = 1; i < bytes.length; i++) {
//将byte转换为字符串
for (int j = 7; j >= 0 ; j--) {
int num = bytes[i];
if(((num >> j) & 1) == 0){
codeBulider.append('0');
}
else{
codeBulider.append('1');
}
}
}
copCode = codeBulider.toString();
//删除补足‘0’字符串
copCode = copCode.substring(0,copCode.length() - bytes[0] - 1);
//为了提高效率的到str的char[]数组
char[] chars = copCode.toCharArray();
//得到全体字符
String content = "";
/**
* 神之一手 ———— 郝为高
* 由于每次字符串的连接,都会先创建 StringBuilder builder对象,浪费大量时间,不如直接一步到位,先创建出来
*/
StringBuilder sinBuilder = new StringBuilder();
StringBuilder contentBuilder = new StringBuilder();
for (char cc:chars) {
sinBuilder.append(cc);
if(readMap.containsKey(sinBuilder.toString())){
contentBuilder.append(readMap.get(sinBuilder.toString()));
sinBuilder.delete(0, sinBuilder.length());
}
}
content = contentBuilder.toString();
FileOutputStream fop = new FileOutputStream(after);
fop.write(content.getBytes());
}
}