prefacio
Recientemente, estoy tratando de usar Python para rastrear datos de información de listados de viviendas de segunda mano. Aquí, proporcionaré el código para aquellos que lo necesiten y daré algunos consejos.
En primer lugar, antes de rastrear, debe pretender ser un navegador tanto como sea posible sin ser reconocido como un rastreador. Lo básico es agregar un encabezado de solicitud, pero habrá muchas personas rastreando datos de texto sin formato, por lo que necesitamos para considerar cambiar la IP del proxy y el reemplazo aleatorio El método del encabezado de solicitud se usa para rastrear los datos del precio de la vivienda.
Antes de escribir el código del rastreador cada vez, nuestro primer y más importante paso es analizar nuestras páginas web.
En nuestro ejemplo, esta vez, necesitamos obtener el enlace de cada listado específico en cada página, luego ingresar a la página web de segundo nivel para obtener información detallada y luego regresar a la página web de nivel superior para repetir el proceso.
A través del análisis, descubrimos que la velocidad de rastreo es relativamente lenta durante el proceso de rastreo, por lo que también podemos mejorar la velocidad de rastreo de los rastreadores al deshabilitar las imágenes del navegador de Google, JavaScript, etc.
herramientas de desarrollo
Versión de Python: 3.8
Módulos relacionados:
módulo de solicitudes
módulo analizador
Construcción del entorno
Instale Python y agréguelo a la variable de entorno, y pip instala los módulos relacionados necesarios.
Análisis de ideas
La página rastreada se muestra en la siguiente figura:
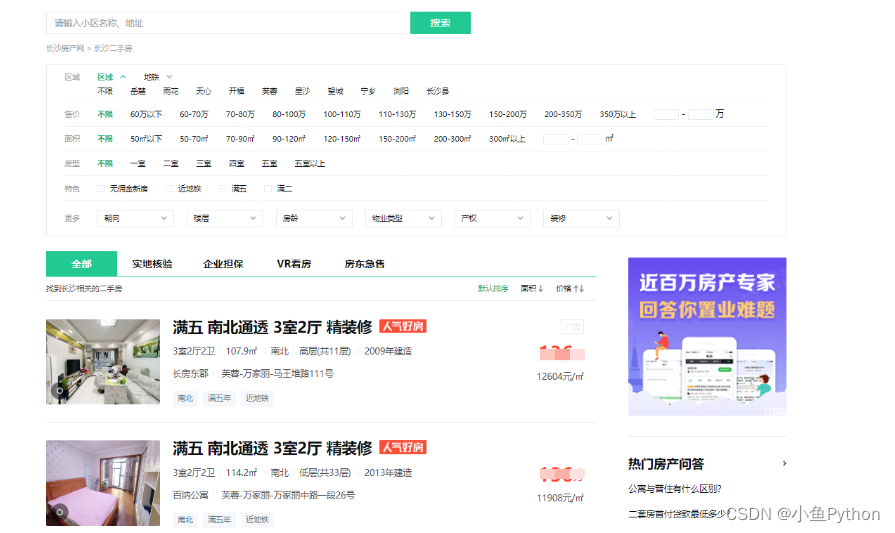
Extraer datos de la página
Abra la página que queremos rastrear en el navegador
y presione F12 para ingresar a la herramienta de desarrollo para ver dónde están los datos que queremos aquí.
Solo necesitamos los datos de la página de listado.
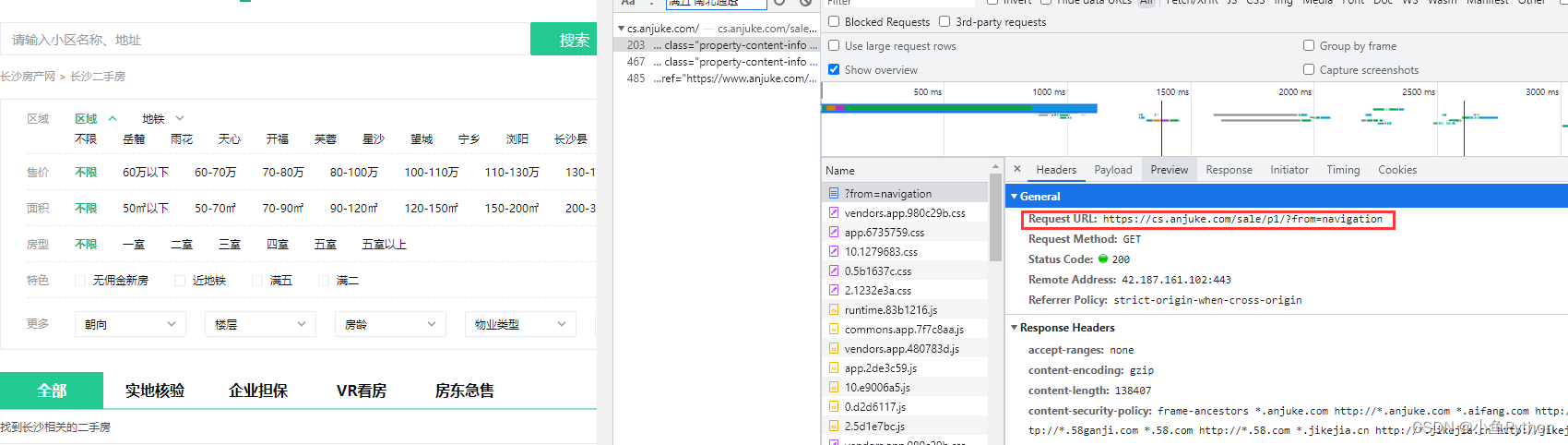
Código
# 伪装
headers = {
'cookie': 'aQQ_ajkguid=B7A0A0B5-30EC-7A66-7500-D8055BFFE0FA; ctid=27; id58=CpQCJ2Lbhlm+lyRwdY5QAg==; _ga=GA1.2.2086942850.1658553946; wmda_new_uuid=1; wmda_uuid=009620ee2a2138d3bd861c92362a5d28; wmda_visited_projects=%3B6289197098934; 58tj_uuid=8fd994c2-35cc-405f-b671-2c1e51aa100c; als=0; ajk-appVersion=; sessid=8D76CC93-E1C8-4792-9703-F864FF755D63; xxzl_cid=2e5a66fa054e4134a15bc3f5b47ba3ab; xzuid=e60596c8-8985-4ab3-a5df-90a202b196a3; fzq_h=4c8d83ace17a19ee94e55d91124e7439_1666957662955_85c23dcb9b084efdbc4ac519c0276b68_2936029006; fzq_js_anjuke_ershoufang_pc=75684287c0be96cac08d04f4d6cc6d09_1666957664522_25; twe=2; xxzl_cid=2e5a66fa054e4134a15bc3f5b47ba3ab; xxzl_deviceid=OOpJsA5XrQMdJFfv71dg+l+he0O1OKPQgRAQcFPbeRAyhjZ4/7gS3Gj4DfiLjxfc; isp=true; obtain_by=2; new_session=1; init_refer=https%253A%252F%252Fcs.anjuke.com%252F; new_uv=3',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/106.0.0.0 Safari/537.36'
}
1.发送请求
response = requests.get(url=url, headers=headers)
2.获取数据
html_data = response.text
3.解析数据
select = parsel.Selector(html_data)
divs = select.css('.property-content')
for div in divs:
# .property-content-title-name 标题
标题 = is_null(div.css('.property-content-title-name::text').get())
# .property-content-info:nth-child(1) .property-content-info-text:nth-child(1) span 户型
户型s = div.css('.property-content-info:nth-child(1) .property-content-info-text:nth-child(1) span::text').getall()
户型 = ' '.join(户型s)
# .property-content-info:nth-child(1) .property-content-info-text:nth-child(2) 面积
面积 = is_null(div.css('.property-content-info:nth-child(1) .property-content-info-text:nth-child(2)::text').get())
# .property-content-info:nth-child(1) .property-content-info-text:nth-child(3) 朝向
朝向 = is_null(div.css('.property-content-info:nth-child(1) .property-content-info-text:nth-child(3)::text').get())
# .property-content-info:nth-child(1) .property-content-info-text:nth-child(4) 楼层
楼层 = is_null(div.css('.property-content-info:nth-child(1) .property-content-info-text:nth-child(4)::text').get())
# .property-content-info:nth-child(1) .property-content-info-text:nth-child(5) 年份
年份 = is_null(div.css('.property-content-info:nth-child(1) .property-content-info-text:nth-child(5)::text').get())
# .property-content-info:nth-child(2) .property-content-info-comm-name 小区名称
小区名称 = is_null(div.css('.property-content-info:nth-child(2) .property-content-info-comm-name::text').get())
# .property-content-info:nth-child(2) .property-content-info-comm-address 小区地址
小区地址 = is_null(div.css('.property-content-info:nth-child(2) .property-content-info-comm-address::text').get())
# .property-content-info:nth-child(3) span 小区标签
小区标签s = div.css('.property-content-info:nth-child(3) span::text').getall()
小区标签 = ' '.join(小区标签s)
# .property-price .property-price-total .property-price-total-num 总价
总价 = is_null(div.css('.property-price .property-price-total .property-price-total-num::text').get())
# .property-price .property-price-average 每平方米的价格
单价 = is_null(div.css('.property-price .property-price-average::text').get())
print(标题, 户型, 面积, 朝向, 楼层, 年份, 小区名称, 小区地址, 小区标签, 总价, 单价)
4.保存数据
with open('安居客.csv', mode='a', encoding='utf-8', newline='') as f:
csv_writer = csv.writer(f)
csv_writer.writerow([标题, 户型, 面积, 朝向, 楼层, 年份, 小区名称, 小区地址, 小区标签, 总价, 单价])
Visualización de resultados
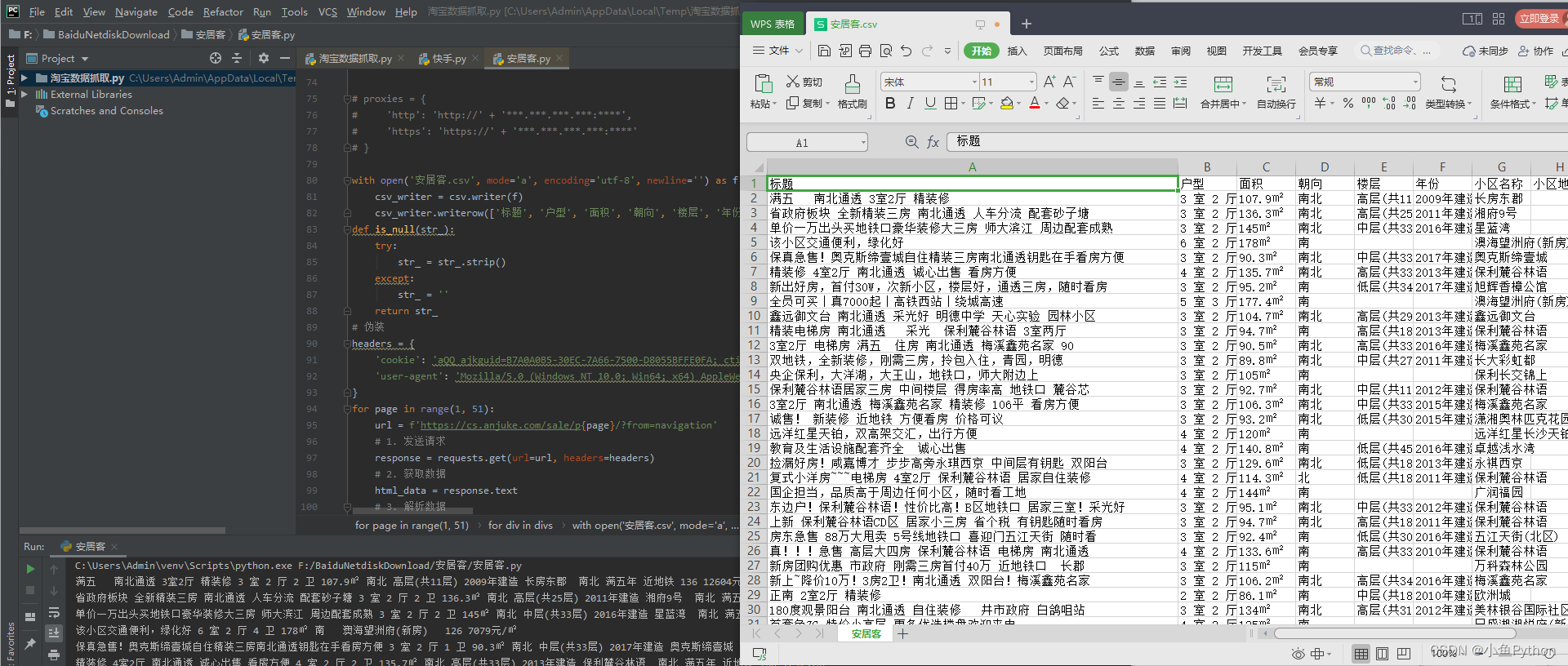
pd: las imágenes son solo para referencia
por fin
El intercambio de hoy está aquí, y los amigos interesados también pueden probarlo.
Si tiene alguna pregunta sobre el artículo, o tiene otras preguntas sobre python, puede dejar un mensaje en el área de comentarios o enviarme un mensaje privado
Si crees que el artículo que compartí es bueno, puedes seguirme o darle me gusta al artículo (/≧▽≦)/