Hay tres problemas principales en la programación concurrente:
atomicidad, orden y visibilidad.
problema de atomicidad
public class Demo {
int i = 0;
public void incr(){
i++;
}
public static void main(String[] args) {
Demo demo = new Demo();
Thread thread1 = new Thread(() -> {
for (int j = 0; j < 1000; j++) {
demo.incr();
}
});
Thread thread2 = new Thread(() -> {
for (int j = 0; j < 1000; j++) {
demo.incr();
}
});
thread1.start();
thread2.start();
System.out.println(demo.i);
}
}
i++En el código Java, es una instrucción, pero esta instrucción puede eventualmente consistir en múltiples instrucciones de la CPU. Por ejemplo, i++al final se generarán 3 instrucciones .
Podemos javap -v Demo.classverificar
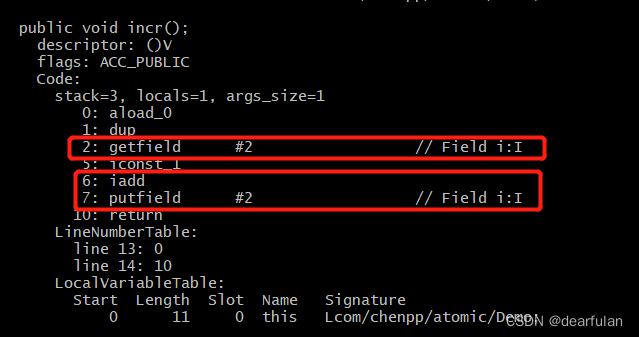
los comandos anteriores en secuencia:
getfield access variable i
iconst_1 put integer constant 1 en la pila de operandos
iadd : inserte la constante 1 en la pila de operandos y agréguela, y coloque el resultado de la suma en la pila de operandos
putfield : asigne el resultado de la operación anterior a la variable Demo.i
Si se va a satisfacer la atomicidad, se requiere que el subproceso no sea perturbado por otros subprocesos al ejecutar el comando i++
Para asegurar la atomicidad, podemos usar el bloqueo de sincronización Synchronized
Uso básico de Sincronizado
Hay tres formas de bloqueo sincronizado:
- Método de instancia modificada, que actúa sobre la instancia actual y obtiene el bloqueo de la instancia actual antes de ingresar el código de sincronización
- Método estático, que actúa sobre el objeto de clase actual, antes de ingresar el código de sincronización, se debe obtener el bloqueo del objeto de clase actual
- Bloque de código modificado, el usuario puede especificar el objeto de bloqueo y se debe obtener el bloqueo del objeto dado antes de ingresar el código de sincronización
El principio de Sincronizado
public class MarkwordDemo {
public static void main(String[] args){
MarkwordDemo markwordDemo = new MarkwordDemo();
synchronized (markwordDemo){
System.out.println("抢到锁,执行代码 ...");
System.out.println("释放锁..");
}
}
}
Descompilar el código anterior en bytecodejavap -c MarkwordDemo.class
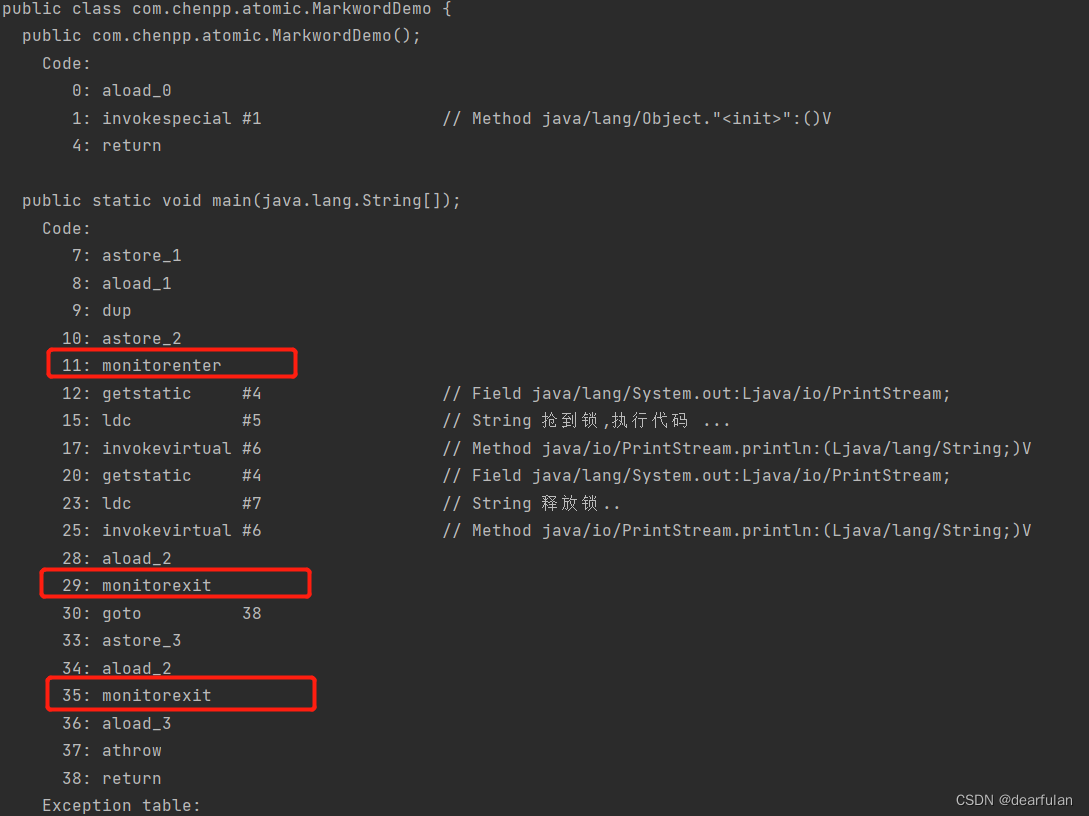
Monitor:
- El comando monitorenter se entiende como bloqueo, y monitorexit se entiende como liberación del bloqueo.
- Cada objeto mantiene un contador que registra el número de bloqueos
- Después de ejecutar monitorenter, el contador se incrementa en 1, y después de ejecutar monitorexit, el contador se reduce en 1 (reentrante)
- cuando el contador es 0. El bloqueo se liberará y otros subprocesos pueden adquirir el bloqueo.
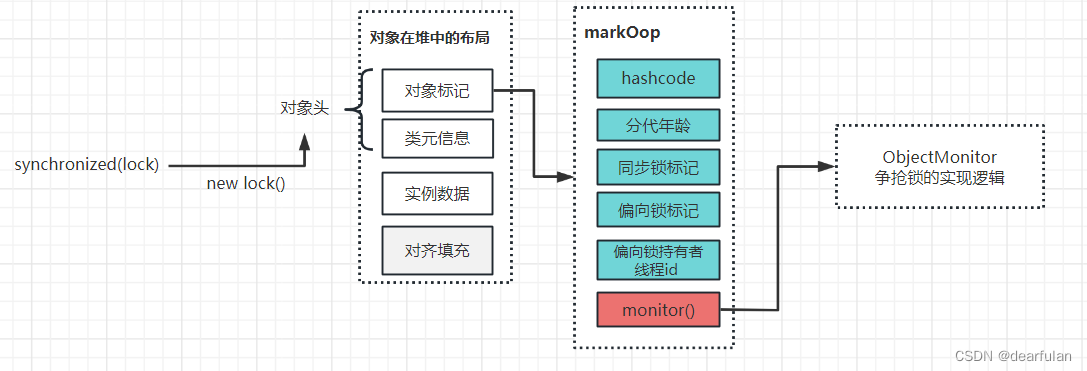
Todos los objetos se pueden usar como el objeto de bloqueo del bloqueo de sincronización sincronizado. El subproceso A toma el bloqueo. Si el subproceso B quiere saber que el bloqueo actual ha sido tomado, debe haber un lugar para almacenar la marca de evento. Este lugar es en la cabecera del objeto Java.Markword.(synchronized es el monitor para obtener el objeto al ejecutar el bloque de código de sincronización, es decir, para operar la Markword en la cabecera del objeto Java)
El encabezado del objeto Markword, simplemente entendido, es el diseño o la forma de almacenamiento de un objeto en la memoria JVM.
Encabezado de objeto Markword
jdk8u: markOop.hpp
En la máquina virtual Hotspot, el diseño de almacenamiento de objetos en la memoria se puede dividir en tres áreas: encabezado de objeto (Encabezado, incluida la marca de objeto Markword y el puntero de tipo), datos de instancia (Datos de instancia), relleno de alineación ( Relleno ) .
Marca de objeto (marca-palabra) :
en un sistema de 64 bits, la marca de objeto ocupa 8 bytes, y la marca de objeto incluye el código hash, la antigüedad del GC y la marca de bloqueo.
Se muestra la estructura de la palabra de marca de 64 bits en diferentes estados de bloqueo. en la figura a continuación, y el análisis de diferentes estados de bloqueo se explicará a continuación:
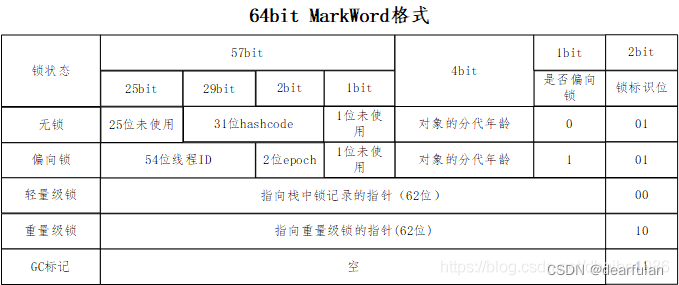
1) hashCode : cuando el objeto está bloqueado (parcial, ligero, pesado), los bytes de MarkWord no tienen suficiente espacio para guardar el hashCode, por lo que el valor se moverá al monitor.
2) Edad generacional , la edad de 4 dígitos que no se ha recopilado y acumulado cada vez que se registra GC aquí, y el valor predeterminado es ingresar la edad avanzada cuando llega a 15 veces (-XX: MaxTenuringThreshold puede modificar el umbral para ingresar el edad a través de esta configuración, porque la generación La edad es de solo 4 dígitos, por lo que el valor máximo es 15
3) Si es un bloqueo sesgado o no 1 dígito
4) Los 2 dígitos del indicador de bloqueo pueden representar 4 estados diferentes, y la bandera de bloqueo correspondiente a cada estado se introducirá más adelante
Puntero Klass: el puntero de tipo del objeto Clase.Jdk1.8 tiene un valor predeterminado de 4 bytes después de habilitar la compresión del puntero y 8 bytes después de deshabilitar la compresión del puntero (-XX:-UseCompressedOops). La ubicación a la que apunta es la dirección de memoria del objeto Class (su objeto de metadatos correspondiente) correspondiente al objeto.
Datos de instancia: incluidas todas las variables miembro del objeto, el tamaño lo determina cada variable miembro, por ejemplo: byte ocupa 1 byte de 8 bits, int ocupa 4 bytes de 32 bits.
Relleno de alineación : No es necesario completar el último espacio, solo se usa como marcador de posición. Dado que el sistema de administración de memoria de la máquina virtual HotSpot requiere que la dirección inicial del objeto sea un múltiplo entero de 8 bytes, el encabezado del objeto es exactamente un múltiplo de 8 bytes. Por lo tanto, cuando la parte de datos de la instancia del objeto no está alineada, debe completarse con el relleno de alineación.
Actualización de bloqueo sincronizado
Los bloqueos sincronizados existen principalmente en cuatro estados, que son: estado sin bloqueo, estado de bloqueo parcial, estado de bloqueo ligero y estado de bloqueo pesado . La razón por la que se diseñan tantos bloqueos diferentes es para minimizar la sobrecarga de las operaciones de bloqueo, especialmente los bloqueos pesados, que necesitan cambiar entre el modo de usuario y el modo kernel, lo que consume una gran cantidad de recursos.
Estos estados escalarán gradualmente con la situación de la competencia. Los bloqueos se pueden actualizar pero no degradar, lo que significa que después de que un bloqueo sesgado se actualice a un bloqueo liviano, no se puede degradar a un bloqueo sesgado. El propósito de esta estrategia de actualización de bloqueo, pero no de degradación, es mejorar la eficiencia de adquirir y liberar bloqueos.
Bloqueo de polarización
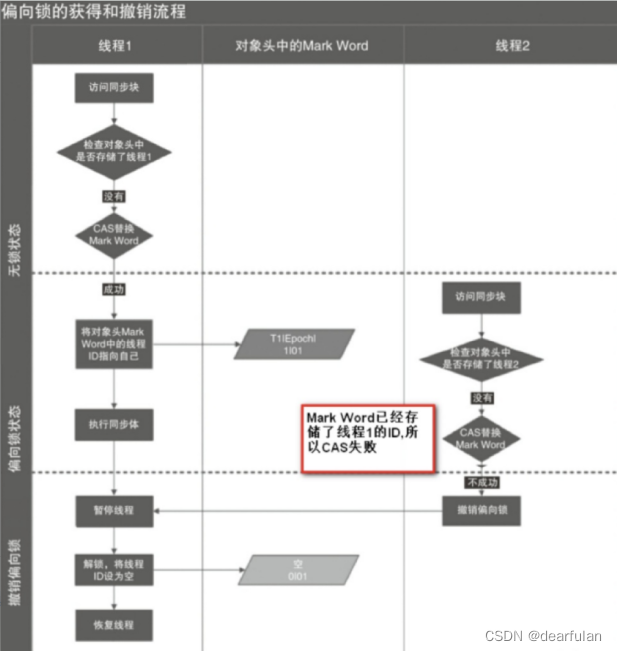
En la mayoría de los casos, el bloqueo no solo no tiene competencia multihilo, sino que siempre es adquirido por el mismo hilo varias veces.Para que el hilo adquiera el bloqueo a un costo menor, se introduce un bloqueo sesgado.
- De forma predeterminada, el bloqueo sesgado está habilitado y la identificación del subproceso sesgado es 0 (esto significa que ningún subproceso posee el bloqueo)
Cuando un subproceso accede al bloque de sincronización y adquiere el bloqueo, almacenará la identificación del subproceso con polarización de bloqueo en el encabezado del objeto y el registro de bloqueo en el marco de la pila . En el futuro, el subproceso no necesita bloquearse y desbloquearse a través del CAS operación al entrar y salir del bloque de sincronización, simplemente juzgue si hay un bloqueo de polarización que apunte al hilo actual almacenado en la palabra de marca del encabezado del objeto. Si almacena su propia identificación de subproceso, significa que el subproceso ha adquirido el bloqueo. De lo contrario, debe juzgar si el objeto de bloqueo está configurado para usar un bloqueo parcial (si el indicador de bloqueo parcial en Mark Word es 1), si no está configurado, entonces compita por el bloqueo a través de CAS; si está configurado, intente pasar el encabezado del objeto a través de CAS El bloqueo sesgado apunta a su propio hilo.
Proceso de adquisición y revocación de bloqueo sesgado
candado ligero
Debido a que la mayoría de los subprocesos liberarán el bloqueo en un corto período de tiempo después de adquirir el bloqueo, para evitar cambiar entre el modo de usuario y el modo kernel y reducir la sobrecarga de recursos, los subprocesos nuevos intentarán adquirir el bloqueo girando
Antes de que el subproceso ejecute el bloque de sincronización, la JVM primero creará un espacio (LockRecord) para almacenar el registro de bloqueo en el marco de la pila del subproceso actual y copiará Mark Word en el encabezado del objeto al registro de bloqueo, que se llama oficialmente Palabra de marca desplazada. Luego, el subproceso que compite por el bloqueo intentará usar CAS para reemplazar Mark Word en el encabezado del objeto con un puntero a su propio registro de bloqueo de subproceso. Si tiene éxito, el subproceso actual adquiere el bloqueo. Si falla, significa que otros subprocesos compiten por el bloqueo, y el subproceso actual intenta usar spin para adquirir el bloqueo.
Desbloqueo de candado ligero
Cuando se desbloquea el candado ligero, se utilizará una operación CAS atómica para reemplazar la palabra de marca desplazada de nuevo en el encabezado del objeto. Si tiene éxito, significa que no hay competencia. Si falla, significa que el candado actual está compitiendo y el candado se expandirá a un candado de peso pesado. La siguiente figura es un diagrama de flujo de dos subprocesos que compiten por los bloqueos al mismo tiempo, lo que da como resultado la expansión del bloqueo.
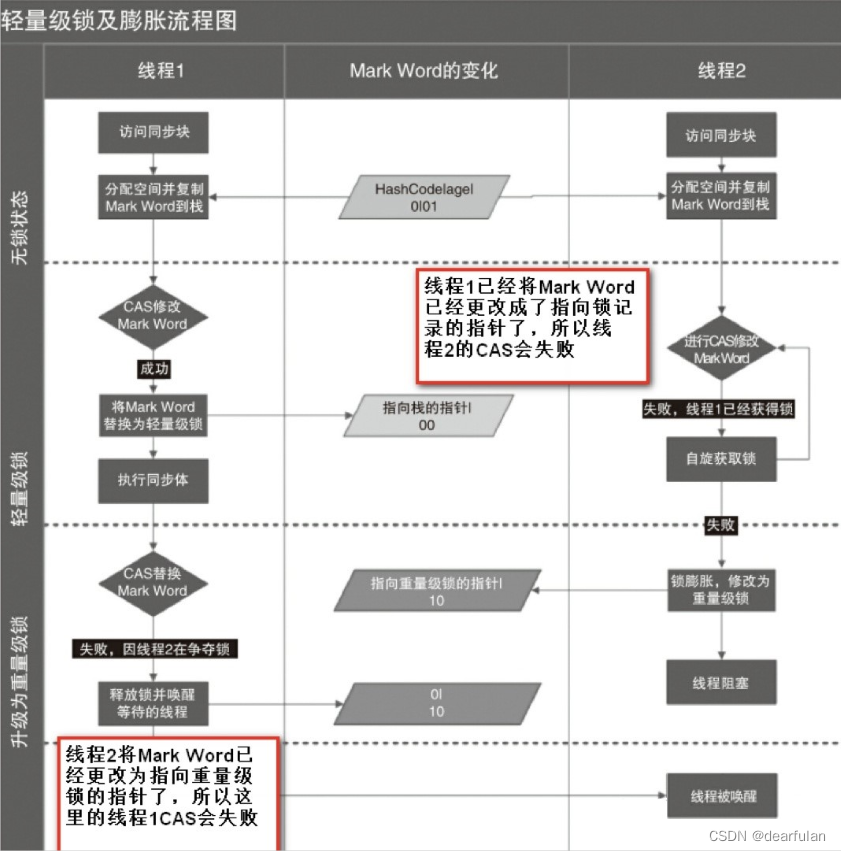
Debido a que el giro consumirá CPU, para evitar giros inútiles (por ejemplo, el hilo que adquiere el bloqueo se bloquea), se establecerá un límite superior para el número de giros, -XX: Configuración del parámetro PreBlockSpin, cuando el número de
hilos los giros exceden este límite superior El bloqueo se actualizará a un bloqueo de peso pesado (después de 1.6, se agrega Adaptive Self Spinning. JVM controlará automáticamente el tiempo de giro de acuerdo con la última situación de competencia).
Una vez que el candado se actualice a un candado pesado, no volverá al estado de candado ligero. Cuando el bloqueo está bajo un bloqueo pesado, otros subprocesos se bloquearán cuando intenten adquirir el bloqueo. Cuando el subproceso que sostiene el bloqueo lo libera, estos subprocesos se despertarán y el subproceso despierto tomará el bloqueo nuevamente.
cerradura de peso pesado
El bloqueo de peso pesado sincronizado se implementa a través del bloqueo del monitor (Monitor) dentro del objeto. Pero la esencia del bloqueo del monitor se implementa confiando en el bloqueo Mutex del sistema operativo subyacente. El sistema operativo necesita cambiar del estado de usuario al estado central para cambiar entre subprocesos. Este costo es muy alto y la transición entre estados lleva un tiempo relativamente largo. Al mismo tiempo, el subproceso actual se suspenderá y entrará en la cola de espera. . .
Esta es la razón por la que la JVM tiene que hacer tantas optimizaciones en el estado de bloqueo sincronizado.
Combate real sincronizado, ver la información del encabezado del objeto Markword en diferentes estados de bloqueo
Imprimir encabezado de objeto por ClassLayout
Podemos ver el diseño de memoria del objeto a través de jol
<dependency>
<groupId>org.openjdk.jol</groupId>
<artifactId>jol-core</artifactId>
<version>0.9</version>
</dependency>
Primero verifiquemos la información de jvm.
public static void main(String[] args) {
//查看字节序
System.out.println(ByteOrder.nativeOrder());
//打印当前jvm信息
System.out.println("======================================");
System.out.println(VM.current().details());
}

Del resultado anterior, podemos ver: Los objetos están alineados en 8 bytes, lo que significa que los bytes asignados por todos los objetos son múltiplos enteros de 8.
A partir del LITTLE_ENDIAN anterior, se puede determinar que el orden de los bytes en la memoria utiliza el modo little endian.
Big-endian: el byte de orden superior viene primero y luego el byte de orden inferior.Esta es la forma en que los humanos leemos y escribimos valores.
Little-endian: byte de orden inferior primero, byte de orden superior al final.
El circuito de la computadora procesa primero los bytes de orden inferior, lo que es más eficiente porque el cálculo comienza con los bytes de orden inferior. Por lo tanto, el procesamiento interno de la computadora es little-endian.
El siguiente es el diseño de memoria de un objeto en un estado sin bloqueo
public class MarkwordDemo {
private Integer age = 1;
private Long number = 1L;
public static void main(String[] args){
MarkwordDemo markwordDemo = new MarkwordDemo();
System.out.println(ClassLayout.parseInstance(markwordDemo).toPrintable());
}
}
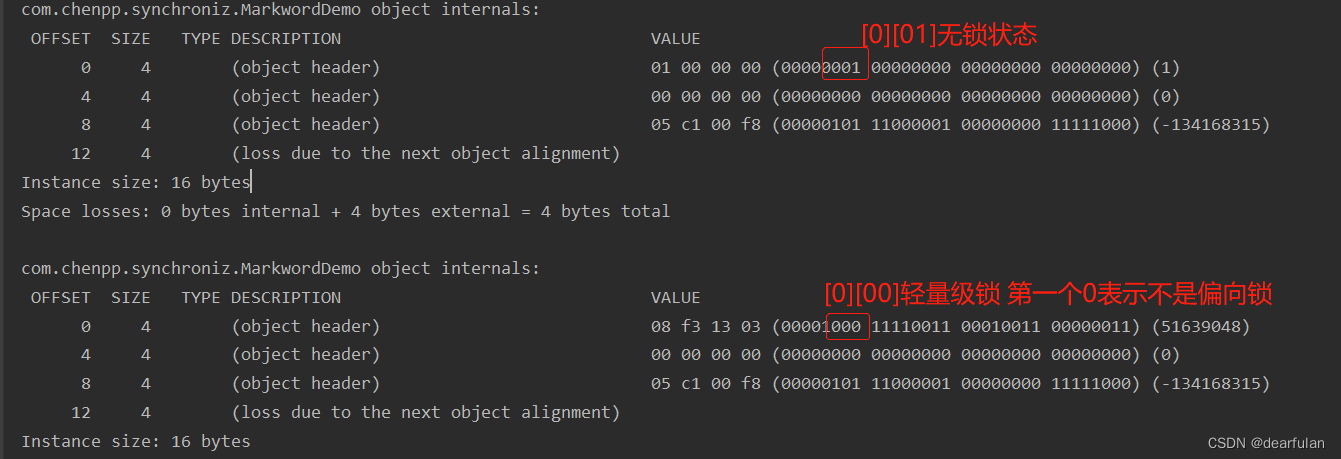
OFFSET SIZE TYPE DESCRIPTION VALUE
## 对象标记
0 4 (object header) 01 00 00 00 (00000001 00000000 00000000 00000000) (1)
4 4 (object header) 00 00 00 00 (00000000 00000000 00000000 00000000) (0)
## 类型指针
8 4 (object header) 05 c1 00 f8 (00000101 11000001 00000000 11111000) (-134168315)
## 对齐填充
12 4 (loss due to the next object alignment)
Instance size: 16 bytes
Space losses: 0 bytes internal + 4 bytes external = 4 bytes total
Como se mencionó anteriormente, jvm adopta el modo little-endian, y el byte alto de los datos se almacena en la parte posterior y el byte bajo se almacena en el frente. Cabe señalar que cada salida aquí es de 4 bytes, y dentro de cada byte, jol ya ha realizado el procesamiento por nosotros. Así que ahora parece que los últimos tres bits del primer byte de la primera línea son el indicador de bloqueo sesgado + el bit de estado de bloqueo (0|01 en el estado libre de bloqueo) al que debemos prestar atención.
Bits de estado en estado de bloqueo ligero
public static void main(String[] args){
MarkwordDemo markwordDemo = new MarkwordDemo();
System.out.println(ClassLayout.parseInstance(markwordDemo).toPrintable());
synchronized (markwordDemo){
System.out.println(ClassLayout.parseInstance(markwordDemo).toPrintable());
System.out.println("抢到锁,执行代码 ...");
}
}
De acuerdo con la declaración anterior sobre la escalada de bloqueo, cuando no hay otros subprocesos que compitan por el bloqueo, el tipo de bloqueo debe ser un bloqueo sesgado. ¿Por qué es inconsistente con el diseño de memoria real del objeto?
Ajustes de retardo predeterminados para bloqueos sesgados
Por defecto, hay un retraso en la apertura de la cerradura sesgada, que es de 4 segundos por defecto.
Esto se debe a que la propia máquina virtual JVM tiene algunos subprocesos que se inician de forma predeterminada. Hay muchos bloques de código sincronizados en estos subprocesos. Cuando se inician estos códigos, se activará la competencia. Si se utilizan bloqueos sesgados, los bloqueos sesgados se bloquearán continuamente. Actualizar y revocar son menos eficientes, por lo que la JVM establece un tiempo de retraso predeterminado para la apertura de bloqueos de polarización.
El tiempo de retraso se puede establecer en 0 mediante el siguiente parámetro de JVM.
-XX:BiasedLockingStartupDelay=0
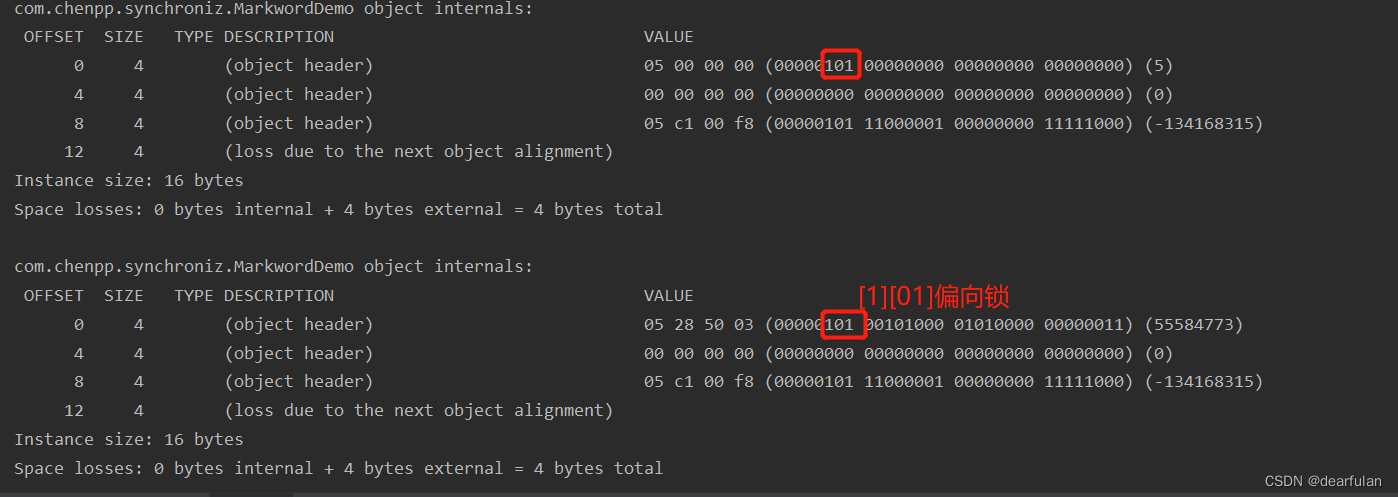
El estado de bloqueo impreso dos veces aquí es 101 (bloqueo sesgado), porque cuando el retardo de bloqueo sesgado está desactivado de forma predeterminada, habrá objetos anónimos configurados para obtener el bloqueo sesgado.
Bits de estado en el estado de bloqueo pesado
public static void main(String[] args){
MarkwordDemo markwordDemo = new MarkwordDemo();
Thread thread1 = new Thread(() -> {
synchronized (markwordDemo){
System.out.println(ClassLayout.parseInstance(markwordDemo).toPrintable());
}
});
thread1.start();
synchronized (markwordDemo){
System.out.println(ClassLayout.parseInstance(markwordDemo).toPrintable());
}
}
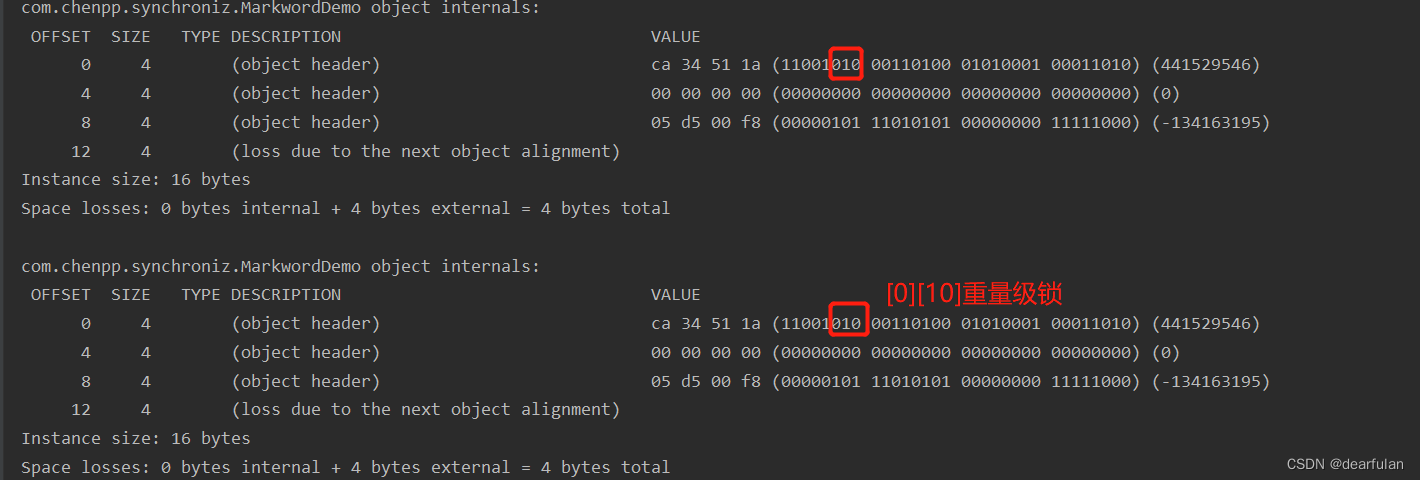
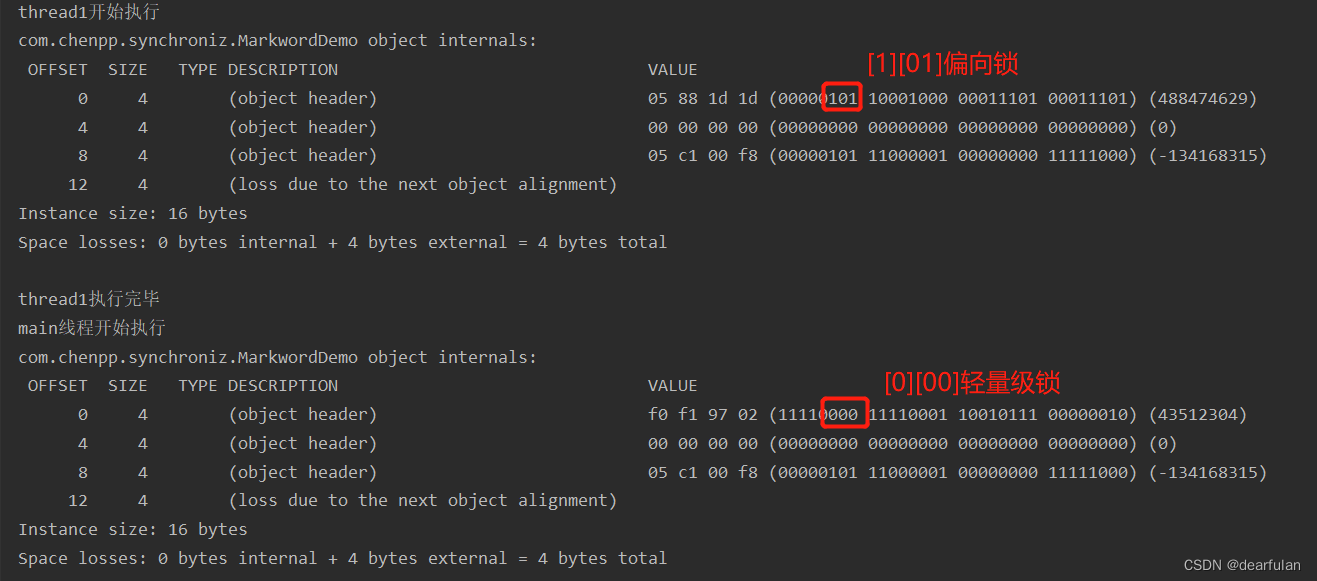
Veamos un ejemplo de actualización de un bloqueo sesgado a un bloqueo ligero. El subproceso 1 adquiere el bloqueo primero. En este momento, ningún otro subproceso compite con él, por lo que es un bloqueo sesgado. El subproceso principal comienza a ejecutarse después de que el subproceso 1 libera el bloqueo. La identificación del subproceso de subproceso1 se almacena en él, CAS falla, por lo que actualizará el bloqueo ligero
public static void main(String[] args) throws InterruptedException {
MarkwordDemo markwordDemo = new MarkwordDemo();
Thread thread1 = new Thread(() -> {
synchronized (markwordDemo){
System.out.println("thread1开始执行");
System.out.println(ClassLayout.parseInstance(markwordDemo).toPrintable());
System.out.println("thread1执行完毕");
}
});
thread1.start();
Thread.sleep(15000);
synchronized (markwordDemo){
System.out.println("main线程开始执行");
System.out.println(ClassLayout.parseInstance(markwordDemo).toPrintable());
}
}