Directorio de artículos
prefacio
Estoy comenzando a ingresar a la vida de posgrado ~ La dirección que quiero estudiar es la dirección del aprendizaje profundo de gráficos. Ahora tengo una comprensión correspondiente de la red neuronal convolucional gráfica GCN. Este artículo es un documento de conferencia sobre "Clasificación semisupervisada con redes convolucionales gráficas" publicado en ICLR en 2017. Este es un artículo clásico y es un buen comienzo para los investigadores que son nuevos en GCN.
1. El artículo pretende resolver problemas e ideas.
El documento "Clasificación semisupervisada con redes convolucionales de gráficos" está inspirado en la aproximación local de primer orden de la convolución de gráficos espectrales que se puede utilizar para codificar la estructura del gráfico local y las características de los nodos para determinar la estructura de la red convolucional. convoluciones gráficas extendidas para el aprendizaje semisupervisado con datos estructurados en gráficos.
dos, el texto
1. Concepto de logotipo
En primer lugar, es necesario tener una comprensión correspondiente de los conceptos básicos involucrados en la tesis.
A (matriz de adyacencia) representa la matriz de adyacencia del gráfico. Una matriz que representa la relación de adyacencia entre vértices. El método de cálculo para agregar una línea horizontal sobre A es A + I , lo que significa una matriz de adyacencia con un bucle propio.
D (Matriz de Grados) representa la matriz de grados del gráfico. es una matriz diagonal, y los elementos de la diagonal son los grados de cada vértice. El grado de un vértice vi representa el número de aristas asociadas con el vértice. (Los gráficos no dirigidos generalmente registran grados de entrada o de salida puros)
L (matriz laplaciana) representa la matriz laplaciana del gráfico. Es una matriz semidefinida positiva y su regla de operación es DA .
Lsym (Matriz Laplaciana Normalizada Simétrica) representa una matriz Laplaciana normalizada simétrica. Expresado como L multiplicado por -1/2 potencia de D a la izquierda , y luego multiplicado por -1/2 potencia de D a la derecha; también se puede expresar como restar L de la izquierda multiplicado por -1/ 2 potencia de D con la matriz unitaria, y a la derechaluego D a la potencia de -1/2. La fórmula es la siguiente: Esta matriz también tiene un método de cálculo:
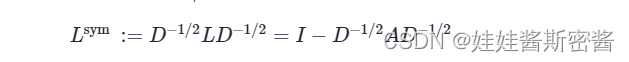
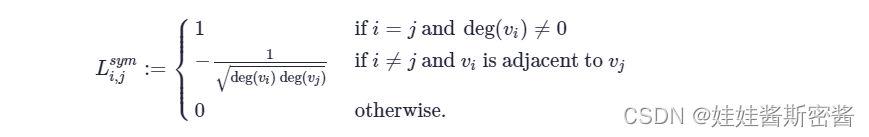
2. Convolución rápida
En primer lugar, debe comprender el concepto de convolución: este lugar se entiende principalmente como: voltear -> deslizar -> superposición -> deslizar -> superposición... En casos continuos, la superposición se
refiere al producto de productos, y en casos discretos casos, es una suma ponderada.
En un gráfico, podemos saber que cada nodo tiene su propia información de características e información estructural. GCN es un método que puede realizar un aprendizaje profundo en los datos del gráfico. El algoritmo de convolución de gráficos se puede entender a través de los siguientes tres pasos:
1. Transmisión: cada nodo envía su propia información característica a los nodos vecinos después de la transformación. Esto es para extraer y transformar la información de características del nodo.
2. Recepción: cada nodo recopila la información de características de sus nodos vecinos. Esto es para fusionar la información de la estructura local de los nodos.
3. Transformación: Después de recopilar la información anterior, haz una transformación no lineal para aumentar la capacidad expresiva del modelo.
El modelo de red neuronal f(X, A) mencionado en el documento se basa en el entrenamiento de pérdida supervisada para todos los nodos etiquetados. Donde X son los datos de entrada y A es la matriz de adyacencia del gráfico.
f (⋅) representa una operación o representa una función de red neuronal, lo que permite que el modelo asigne información de gradiente de la pérdida supervisada L0 y puede aprender todos los nodos, incluidas las representaciones etiquetadas y no etiquetadas.
En este documento, las reglas de la red convolucional de gráficos multicapa se proponen en términos de convolución rápida.La fórmula es la siguiente: W (l
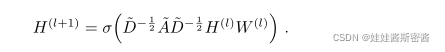
) involucrado en la fórmula anterior se expresa como una matriz de peso entrenable de capa específica. Vale la pena señalar que en un GCN multicapa, la matriz de adyacencia con bucles automáticos es fija y depende de la construcción del gráfico topológico al principio, solo necesitamos aprender los parámetros de la matriz de peso. Aquí hay algunas preguntas:
P: ¿Por qué necesita agregar un bucle automático?
R: Si no agrega bucles automáticos, al recopilar información de vecinos, sin importar si usa el método promedio o el método de promedio ponderado, las características de sus propios nodos se ignoran. Por lo tanto, al actualizar sus propios nodos, generalmente es necesario agregar un bucle automático para actualizar los nodos combinando sus propias características y las características de los vecinos.
P: ¿Por qué usar la normalización simétrica?
R: En un gráfico, los diferentes nodos tienen diferentes números de aristas y pesos. Por ejemplo, algunos nodos tienen muchas aristas, lo que lleva al hecho de que los valores propios de los nodos con muchas aristas o pesos pesados después de la agregación son mucho mayores. que aquellos con pocos bordes o nodos con pequeños pesos de borde. Esto puede dar lugar a problemas de explosión o desaparición de gradientes durante el entrenamiento de la red. Por lo tanto, antes de que el nodo se actualice, es necesario normalizar la información de los vecinos (incluida la información de bucle propio) y la información propagada por los nodos vecinos para eliminar tales problemas. En resumen, la matriz normalizada puede considerarse como una normalización horizontal y vertical de la matriz de adyacencia.
P: ¿Por qué se introduce la matriz laplaciana?
R: Debido a que la matriz laplaciana es una matriz simétrica, se puede realizar una descomposición propia. Para estudiar gráficos en el dominio espectral, es necesario realizar una transformada de Fourier en el gráfico para proyectar el gráfico en el dominio de Fourier. La razón por la que un dominio se denomina "dominio" debe contener al menos un conjunto de bases ortogonales, de modo que cada posición o estado del dominio pueda representarse mediante una combinación lineal de este conjunto de bases ortogonales. Los vectores propios de la matriz laplaciana pueden formar un conjunto de bases ortogonales, por lo que la transformada de Fourier del gráfico se puede expresar en forma de matriz.
P: ¿Por qué necesita realizar una descomposición propia en la matriz de Laplacian?
R: El cálculo de la convolución en el dominio de Fourier es relativamente simple, por lo que necesitamos transformar la gráfica del dominio espacial al dominio espectral, y en esta transformación, necesitamos encontrar la base ortogonal continua de la gráfica para que corresponda a la base de la transformada de Fourier, por lo que es necesario utilizar los vectores propios de la matriz laplaciana.
El propósito de introducir la función de activación: si la función de activación no se introduce en la red neuronal, entonces en la red, la salida de cada capa es una función lineal de la entrada de la capa anterior, sin importar cuántas capas tenga la red neuronal final. red tiene, la salida es la entrada La combinación lineal de, por lo que la red más profunda no tiene significado de existencia y no puede aprovechar los problemas no lineales. Por lo tanto, la función de activación se agrega para introducir factores no lineales y la capacidad de expresión no lineal, lo que no solo amplía el ámbito de aplicación de la red neuronal, sino que también mejora la solidez del modelo, alivia el problema de la desaparición del gradiente y mapea la función. entrada a un nuevo espacio de características. , Acelerar la convergencia del modelo.
2.1 Convolución espectral
Usar la teoría de grafos para realizar la operación de convolución en el grafo topológico es también usar los valores propios y los vectores propios de la matriz laplaciana del grafo para estudiar las propiedades del grafo.
La primera fórmula de convolución es la siguiente:
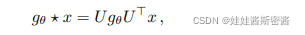
donde x representa el vector propio del nodo del gráfico; gθ=diag(θ) es el kernel de convolución, donde θ es el parámetro; U es la matriz de vectores propios de la matriz laplaciana L del gráfico.
Se menciona en el artículo que el cálculo de esta fórmula es demasiado complicado y la selección del kernel de convolución no es adecuada, por lo que se propone el siguiente contenido.
La segunda fórmula de convolución:
aquí se propone un método de diseño del núcleo de convolución, es decir, gθ(Λ) puede aproximarse mediante la expansión truncada del polinomio de Chebyshev T k(x) a la K-ésima generación.
El polinomio de Chebyshev (Chebyshev) del primer tipo se obtiene mediante la siguiente recursión:
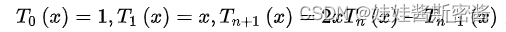
por lo que el nuevo núcleo de convolución se expresa como:
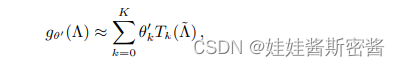
donde Λ horizontal = 2Λ / λmax - In, λmax es el mayor valor propio de L
Luego, la fórmula de convolución se obtiene de la siguiente manera:
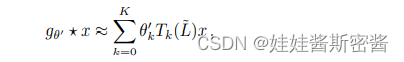
El método de cálculo de la horizontal L es el mismo que el método de cálculo de la horizontal Λ anterior.
Tenga en cuenta que esta fórmula es un polinomio de orden K en el operador laplaciano, que solo depende del nodo con los K pasos más grandes desde el nodo central.
La segunda fórmula de convolución simplifica los parámetros a K, ya no necesita realizar la descomposición propia y usa directamente L para la transformación, lo que resuelve el paso que consume más tiempo. El uso de polinomios de Chebyshev para ajustar el método del kernel de convolución reduce la complejidad.
P: ¿Por qué introducir los polinomios de Chebyshev?
R: Porque los polinomios de Chebyshev se pueden usar para aproximar funciones.
2.2 Modelo lineal
GCN puede considerarse como una simplificación adicional de ChebNet.Cuando la operación de convolución K = 1, es lineal con respecto a L , por lo que hay una función lineal en el espectro laplaciano. Sobre esta base, suponiendo que λmax ≈ 2, se puede predecir que los parámetros de GCN pueden adaptarse a tales cambios durante el proceso de entrenamiento. Cuando ChebNet se aproxima en primer orden, entonces la fórmula de convolución de ChebNet se simplifica y se aproxima como la siguiente fórmula : donde esta fórmula contiene
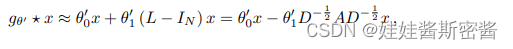
dos parámetros libres θ0' y θ1', los parámetros del filtro pueden ser compartidos por toda la imagen.
El uso continuo de esta forma de filtro convoluciona efectivamente la vecindad de nodos de orden K, donde K es el número de operaciones de filtrado continuo o capas convolucionales en el modelo.
Para limitar el número de parámetros para resolver el sobreajuste y minimizar la operación de cálculo de cada capa, 1-st ChebNet asume que la definición de convolución del gráfico es aproximada (modelo simple de primer orden), en la práctica, usamos la siguiente operación de simplificación :
Hacemos θ = θ0' = - θ1', luego podemos obtener la siguiente fórmula:
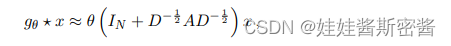
mientras que el rango de valores propios es [0,2], el uso repetido de este operador en la red neuronal profunda conducirá a la desaparición numérica o problemas de explosión (El problema de la explosión o desaparición del gradiente). Por lo tanto, se introduce la técnica de normalización (truco de renormalización), es decir, el gráfico topológico más el bucle automático: por lo que la fórmula de convolución rápida en el artículo es: ¿dónde está el
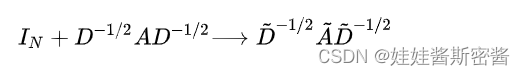
parámetro

? matriz, que es el vector propio del nodo.El cálculo es complicado también se reduce en gran medida.
Los símbolos de identificación mencionados anteriormente se han introducido anteriormente en este artículo y no se repetirán aquí.
Cuando esta definición se extiende a una señal X con canales de entrada C y filtros F, la fórmula del mapa de características es la siguiente: donde Θ es la
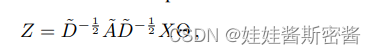
matriz de parámetros del filtro y Z es la matriz de la señal después de la convolución.
3. Clasificación de nodos semisupervisados
Después de resolver el problema de que el modelo f ( X , A ) puede propagar información en el gráfico de manera efectiva, volvemos al problema de la clasificación de nodos semisupervisados. En la siguiente figura se muestra un modelo general de GCN semisupervisado de varias capas: 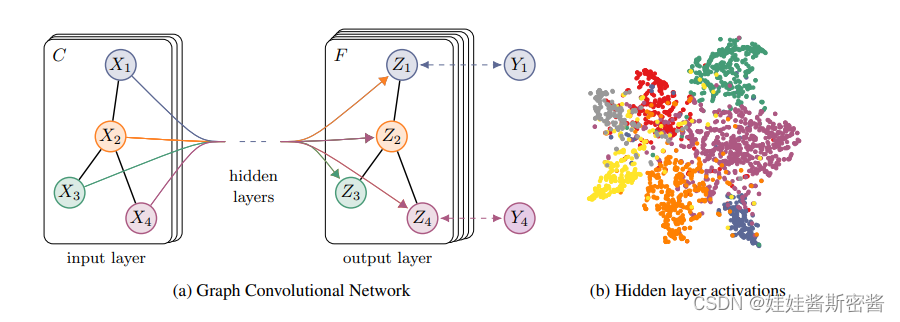
la figura de la izquierda (a) es un diagrama esquemático de una red GCN, la capa de entrada tiene canales C, la del medio contiene varias capas ocultas y la capa de salida tiene mapas de características F. La estructura del gráfico Compartido entre capas, las etiquetas se denotan por Yi.
La imagen de la derecha (b) es una representación visual del valor de activación de la capa oculta obtenida por un GCN de dos capas entrenado en el conjunto de datos de Cora, y el color representa la categoría del documento.
El preprocesamiento de A horizontal puede hacer que el modelo sea más conciso:
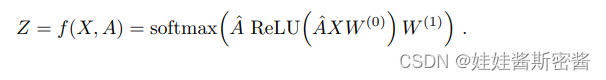
donde W(0) es la matriz de ponderación desde la capa de entrada hasta la capa oculta, W(1) es la matriz de ponderación desde la capa oculta hasta la capa de entrada. La función softmax es
: la función softmax puede convertir el valor de salida de la clasificación múltiple en una distribución de probabilidad que va de [0, 1] a 1. Después de actuar en cada fila, es necesario evaluar

el error de entropía cruzada de todas las etiquetas marcadas La función de pérdida de entropía cruzada describe la probabilidad de salida real y la expectativa La similitud entre las probabilidades de salida, si el valor de la entropía cruzada es menor, más cercanas son las dos distribuciones de probabilidad. La fórmula se muestra en la siguiente figura:
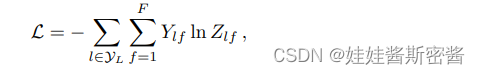
Yl es el conjunto de índices de todos los nodos etiquetados, Y es la etiqueta real y Z es la salida de la red. Pasar la etiqueta a la entropía cruzada permite que la red aprenda y, después del entrenamiento, se puede obtener la etiqueta del nodo sin etiqueta.
Finalmente, el algoritmo de descenso de gradiente se usa para entrenar los pesos W (0) y W (1) en la red, y el algoritmo de descenso de gradiente por lotes se realiza en cada conjunto de datos completo.
4. Experimenta
Se menciona en el documento que el modelo ha sido probado en experimentos, incluyendo principalmente clasificación de documentos semi-supervisada en la red de citas y clasificación de entidades semi-supervisada para extraer gráficos bipartitos de gráficos de conocimiento.
El conjunto de datos utilizado se muestra en la siguiente tabla:
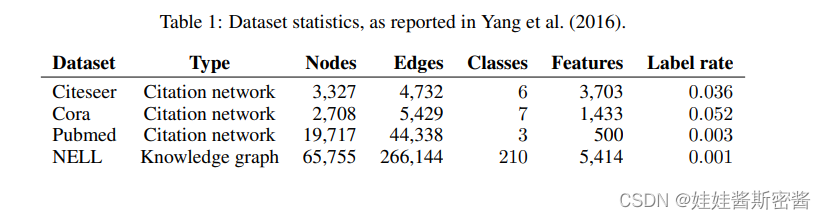
simplemente analice el conjunto de datos cora: el conjunto de datos tiene un total de 2708 puntos de muestra, cada punto de muestra es un artículo científico y todos los puntos de muestra se dividen en 7 categorías. Cada papel está representado por un vector de palabra de 1433 dimensiones, por lo que cada punto de muestra tiene 1433 características. Cada elemento del vector de palabras corresponde a una palabra, y este elemento tiene solo dos valores de 0 o 1. Tome 0 para indicar que la palabra correspondiente al elemento no está en el papel y tome 1 para indicar que está en el papel. Todas las palabras se derivan de un diccionario con 1433 palabras.
Cada artículo ha citado al menos otro artículo, o ha sido citado por otros artículos, es decir, existe una conexión entre los puntos de muestra y ningún punto de muestra está completamente desconectado de otros puntos de muestra. Si los puntos de muestra se consideran como puntos en el gráfico, entonces este es un gráfico conectado y no hay puntos aislados.
5. Resultados
Los resultados experimentales se muestran en la siguiente tabla:
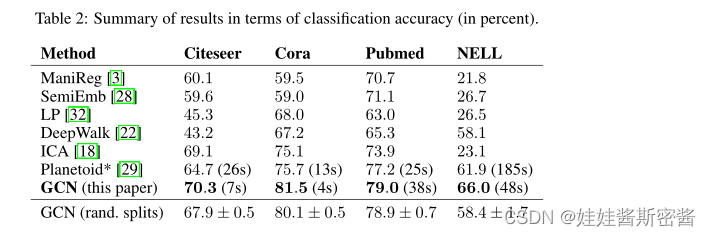
En comparación con los resultados experimentales realizados por otros métodos en el documento, se puede ver que el método de convolución de gráfico en este documento tiene mayor precisión.
Resumir
Me tomó algún tiempo leer y comprender intensamente y, de hecho, he ganado mucho. Dediqué mucho tiempo a la revisión y comprensión de los conceptos básicos y las fórmulas de cálculo. Por supuesto, la primera lectura no lo comprenderá completamente, y se requieren múltiples lecturas cuidadosas para aplicar completamente la teoría en la práctica. Sigue adelante. Si hay nuevos descubrimientos y ganancias, continuaré recuperando ~