arXiv - CS - Aprendizaje automático Fecha de publicación: 2021-06-10 , DOI: arxiv-2106.06047
Liangqiong Qu, Yuyin Zhou, Paul Pu Liang, Yingda Xia, Feifei Wang, Li Fei-Fei, Ehsan Adeli, Daniel Rubin
Resumen:
Problemas abordados: falta de fusión y posible olvido catastrófico en dispositivos heterogéneos del mundo real.
Mejora: las arquitecturas basadas en autoatención (Transformers) se muestran más robustas a los cambios de distribución, mejorando el aprendizaje federado en datos heterogéneos. El primer estudio empírico riguroso de diferentes arquitecturas neuronales en una gama de algoritmos conjuntos, puntos de referencia del mundo real y divisiones de datos heterogéneas.
Conclusión: Reemplazar ConvNets con Transformers puede reducir en gran medida el olvido catastrófico de dispositivos anteriores, acelerar la convergencia y lograr mejores modelos globales, especialmente cuando se trata de datos heterogéneos.
1. Introducción
El problema de aprender un solo modelo global a través de dispositivos que no son IID:
(1) Convergencia no garantizada y divergencia del peso del modelo de métodos FL paralelos
(2) Problema grave de olvido catastrófico del método serial FL
La premisa del punto de partida del artículo: aportar una nueva perspectiva repensando la elección de la arquitectura en el modelo federado.
Supongamos que la arquitectura Transformer es especialmente adecuada para la distribución heterogénea de datos.
Razón hipotética:
porque son sorprendentemente robustos a los cambios de distribución. Esta propiedad ha llevado a la popularidad de los transformadores en el aprendizaje autosupervisado, donde la heterogeneidad se manifiesta a través de cambios de distribución entre los datos previos al entrenamiento sin etiquetar y los datos de prueba etiquetados, y en modalidades de entrada heterogéneas básicas como imágenes y texto.Aprendizaje multimodal.
proceso:
Para investigar esta hipótesis, se realiza la primera evaluación comparativa empírica a gran escala de varias arquitecturas neuronales a través de un conjunto de algoritmos conjuntos, evaluaciones comparativas del mundo real y divisiones de datos heterogéneas. Para representar la red Transformer, utilizamos la implementación estándar de Vision Transformers en tareas de imágenes que abarcan la clasificación de imágenes y la clasificación de imágenes médicas.
resultado:
VIT-FL (aprendizaje federado con transformadores visuales) funciona particularmente bien en entornos con divisiones de dispositivos en su mayoría heterogéneas, con la brecha entre VIT-FL y FL con ResNets cada vez más grande a medida que aumenta la heterogeneidad. Para comprender estos resultados, descubrimos que la principal fuente de mejora radica en la robustez mejorada del modelo Transformer para datos heterogéneos, lo que reduce el olvido catastrófico de dispositivos anteriores cuando se entrena con dispositivos nuevos completamente diferentes. Los transformadores juntos convergen más rápido y alcanzan un mejor modelo global adecuado para la mayoría de los dispositivos. Al comparar con los métodos FL especialmente diseñados para hacer frente a datos heterogéneos, se encuentra que VIT-FL proporciona una mejora instantánea sin usar heurísticas de entrenamiento, ajuste de hiperparámetros adicionales o entrenamiento adicional. Además, VIT-FL es ortogonal a los métodos FL basados en optimización existentes y se puede aplicar fácilmente para mejorar su rendimiento. Con este fin, concluimos que en futuros estudios, los Transformadores deben ser considerados como un punto de partida natural para el problema FL.
3, Transformadores en Aprendizaje Federado
Combinando FedAvd con CWT como algoritmo de entrenamiento:
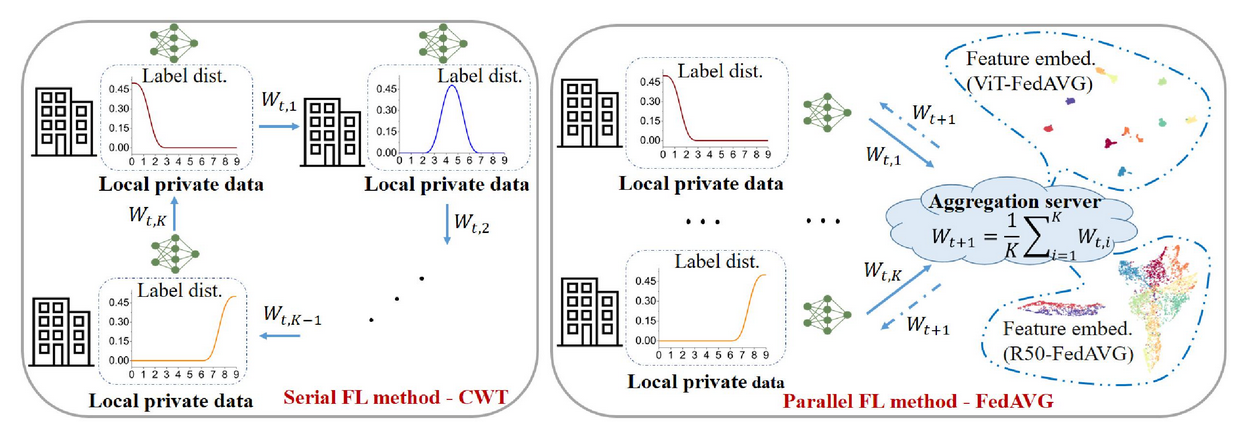
Fig. 2. Diagrama esquemático simplificado del método FL serial típico CWT [7] y el método FL paralelo FedAVG [46] en la partición de datos no IID de CIFAR-10 [31] con asimetría de distribución de etiquetas. Wt,i denota el peso del modelo para el cliente i durante la ronda t de entrenamiento (están involucrados un total de K clientes). A la derecha, mostramos visualizaciones de incorporación de características para ViT(S)-FedAVG y ResNet(50)-FedAVG mediante UMAP [45]. Encontramos que las características aprendidas por ViT(S)-FedAVG están más claramente separadas que las aprendidas por ResNet(50)-FedAVG. Nuestros experimentos (Sección 4.2) respaldan la ventaja de VIT-FL en datos heterogéneos y proporcionamos análisis que explican su eficacia (Sección 4.3).
FedAVG combina el descenso de gradiente estocástico local (SGD) en cada cliente con el promedio iterativo del modelo [47]. Específicamente, una pequeña cantidad de clientes locales se muestrean aleatoriamente en cada ronda de comunicación y el servidor envía el modelo global actual a cada uno de estos clientes. Luego, cada cliente seleccionado realiza rondas E de SGD locales en sus datos de entrenamiento locales y envía gradientes locales de regreso al servidor central para la agregación sincrónica. Luego, el servidor aplica el gradiente promedio para actualizar su modelo global y el proceso se repite.
Transferencia de peso cíclica. A diferencia de FedAVG, que capacita a cada cliente local de manera síncrona y paralela, los clientes locales en CWT se capacitan de manera serial y por turnos. En cada ronda de entrenamiento, CWT entrena un modelo global en un cliente local con sus datos locales para un número de épocas E, y luego transfiere este modelo global al siguiente cliente para entrenamiento hasta que todos los clientes locales estén entrenados. Entrena una vez [7] Luego, el proceso de capacitación se repite repetidamente en el lado del cliente hasta que el modelo converge o alcanza un número predeterminado de rondas de comunicación.
Para ser honesto, la descripción del tercer capítulo me confunde, ¿es tan corto?
4. Experimenta
Aborda las siguientes cinco preguntas:
(1) ¿Pueden los Transformers aprender un mejor modelo global en la configuración de FL en comparación con las CNN como método real para las tareas de FL? (Sección 4.2)
(2) ¿Los Transformers son particularmente capaces de manejar particiones de datos heterogéneas? (Sección 4.3.1)
(3) Comparado con CNN, ¿Transformer reduce el costo de comunicación (Sección 4.3.2)?
(4) ¿Se pueden aplicar los transformadores para mejorar aún más los métodos FL basados en la optimización existentes (Sección 4.4)?
(5) ¿Qué consejos prácticos ayudan a los profesionales a implementar Transformers en FL (Sección 4.5)?
Conjuntos de datos: el aprendizaje de FL se evalúa en el conjunto de datos de competencia de retinopatía diabética de Kaggle (representado como Retina), el conjunto de datos CIFAR-10 con particiones de datos simuladas y el conjunto de datos CelebA del mundo real.
Utilice un programador de calentamiento y decaimiento de tasa de aprendizaje lineal para VIT-FL. El planificador de tasa de aprendizaje para FL con CNN se elige entre calentamiento lineal y decaimiento o decaimiento escalonado. Aplique recorte de gradiente (norma global 1) para estabilizar el entrenamiento. Establecimos la época de entrenamiento local E en 1 en todos los métodos FL (a menos que se indique lo contrario), y el número total de rondas de comunicación en 100 para Retina y CIFAR-10, y 30 para CelebA. Para una comparación justa, todos los modelos utilizados en este documento están previamente entrenados en ImageNet-1K.
4.2 Resultados
Comparación de FL con diferentes arquitecturas neuronales y entrenamiento centralizado (ideal):
Independientemente de la arquitectura aplicada, CWT y FedAVG logran resultados comparables en la configuración de IID con los modelos entrenados en datos alojados centralmente (indicados como Central) (Fig. 3). Sin embargo, observamos una precisión de prueba significativamente menor de las CNN en particiones de datos heterogéneas de CWT y FedAVG, utilizando CNN y transformadores en el conjunto de datos Retina (primera fila) y el conjunto de datos CIFAR-10 (segunda fila) respectivamente como Precisión de predicción (%) para CWT y FedAVG de la red de referencia. Los Vision Transformers (ViT y Swin) muestran un rendimiento consistentemente fuerte, especialmente en particiones de datos que no son IID.
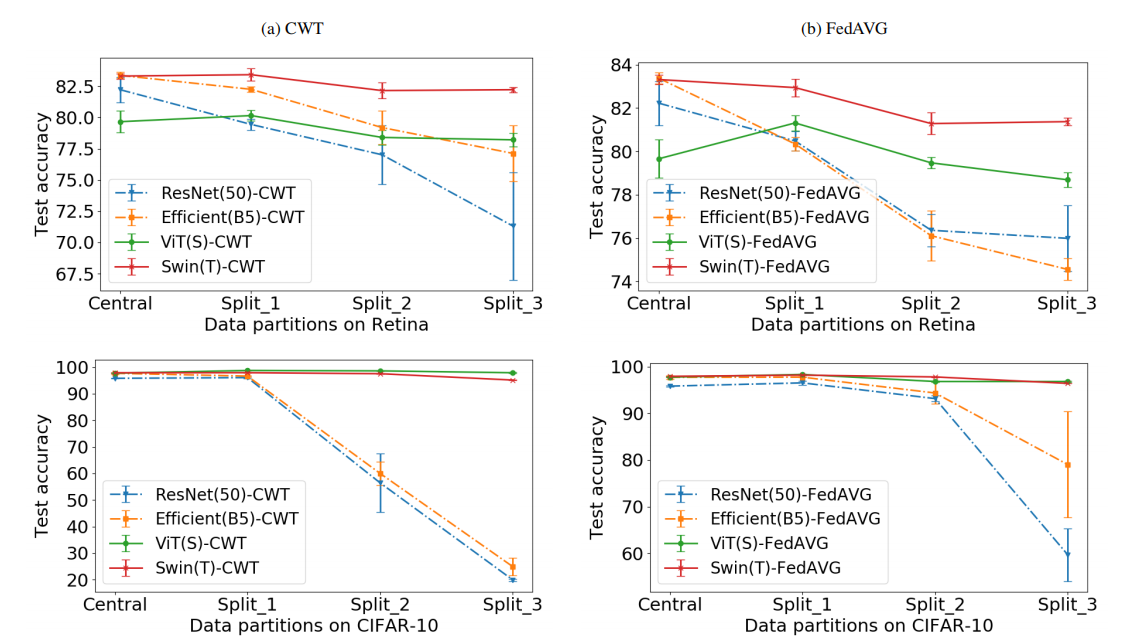
图3:以cnn和transformer为基线网络的CWT和FedAVG分别在Retina数据集(第一行)和CIFAR-10数据集(第二行)上的预测准确率(%)。Vision transformer(包括ViT和Swin)始终表现出强大的性能,特别是在非iid数据分区中。
在极其异构的数据分区上(Split 3,CIFAR-10 的 KS-1)(图 3 和图 1)。通过简单地将 CNN 替换为 ViT,CWT 和 FedAVG 即使在高度异构的非 IID 设置中也能成功保持模型准确性。ViT(S)-CWT 和 ViT(S)-FedAVG 在高度异构的 Split-3、KS-1 上相对于 ResNet(50)-CWT 和 ResNet(50)-FedAVG 提高了 77.70% 和 37.34% 的测试精度CIFAR-10 数据集。因此,VIT特别适用于异构数据。
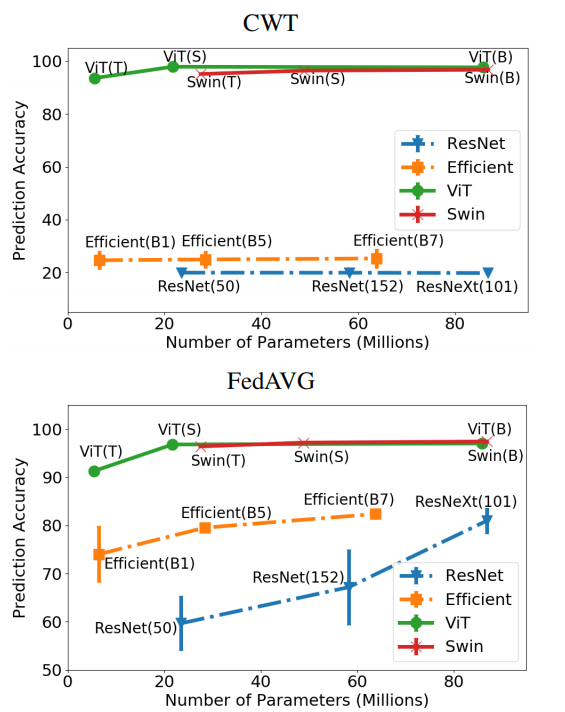
图1:CIFAR-10数据集高度异构数据分区(Split-3)与模型大小1的预测测试精度。在高度异构的数据分区上,Vision transformer (ViTs和Swin transformer)的性能明显优于cnn (ResNets和EfficientNets)。
与现有 FL 方法的比较:
将 VIT-FL 与两种最先进的基于优化的 FL 方法进行比较:FedProx 和 FedAVG-Share 在 Retina 和 CIFAR-10 上。我们使用 ResNet(50) 作为其他比较方法的主干网络,并使用 ViT(S) 作为我们方法的主干网络。我们使用网格搜索在 Split-2 数据集上调整最佳参数(FedProx 近端项中的惩罚常数 µ),并将相同的参数应用于所有剩余的数据分区。我们允许每个客户为 FedAVGShare 在彼此之间共享 5% 的数据。如图 4 所示,VIT-FL 在非 IID 数据分区中优于所有其他 FL 方法,尤其是在高度异构的非 IID 设置上。尽管仔细调整了优化参数,FedProx [37] 在高度异构的数据分区上仍遭受严重的性能下降。 FedAVG-Share 在高度异构的数据分区 Split-3 上也会出现性能下降,即使 5% 的本地数据在所有客户端之间共享(CIFAR-10 数据集上的 Split-3 为 94.4%,而 Split 上为 97%) -1).我们得出结论,简单地使用 Transformers 优于最近为 FL 设计的几种方法,这些方法通常需要仔细调整优化参数。VIT 的使用与现有的优化方法是正交的,两者的结合可以产生更强的性能(详见第 4.4 节)。
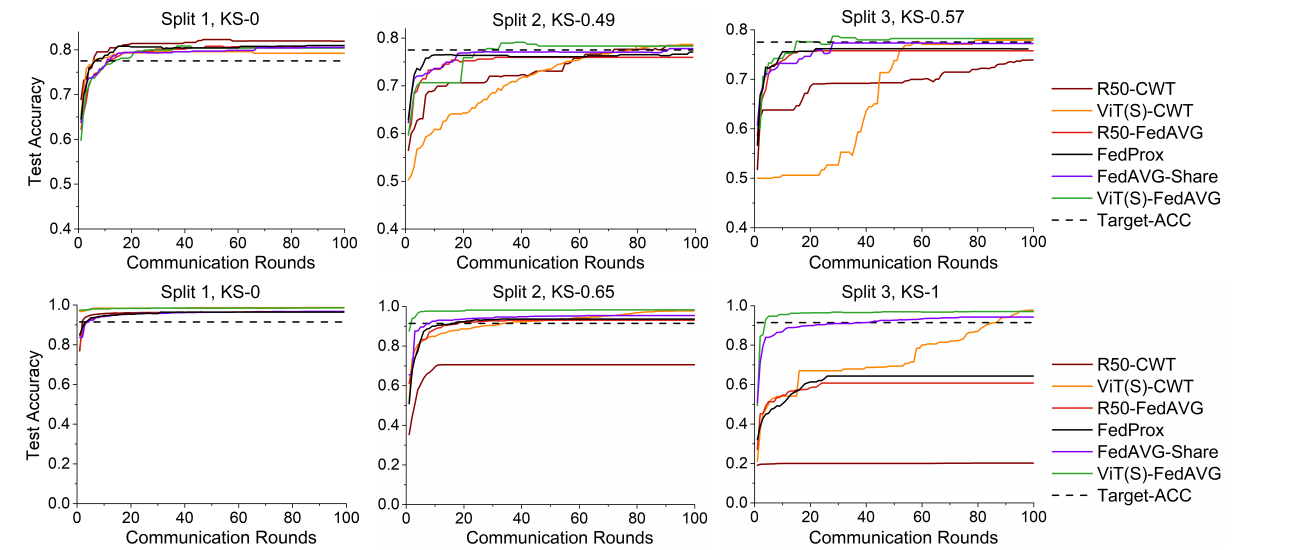
图4。在视网膜数据集(第一行)和CIFAR-10数据集(第二行)上使用不同的数据分区测试集精度与通信轮的关系。黑色虚线显示表3中使用的目标性能(target - acc)。视觉变形器收敛速度快,通信轮数少,特别适用于通信效率高的FL。

表3:达到目标性能(最佳和次优)所需的#传输消息大小(#通信轮× #模型参数(M))。ViT(S)和ResNet(50)的#模型参数分别为21.7M和23.5M。vit收敛速度更快,特别是在异构数据分割上,并且可以与基于优化的方法(FedProx和FedAVG-Share)结合使用,从而实现更快的收敛。
4.3、分析Transformers的有效性
4.3.1 Transformers 在非 IID 设置中泛化得更好
FL 的分布式特性意味着跨客户端的数据分布可能存在很大的异质性。先前的研究表明,使用 FedAVG 或 CWT 训练 FL 模型分别会导致权重发散和灾难性遗忘等问题 [30、57]。我们认为,CNN 中使用的局部卷积已被证明更多地依赖于局部高频模式 [13、26、63],可能对异构设备特别敏感。由于不同的医学成像协议 [16,55] 以及自然数据拆分,不同机构捕获的输入图像在局部模式(强度、对比度等)上可能存在显着差异,因此这个问题在 FL 中比医疗保健数据尤为普遍由于用户在说话 [33]、打字 [17] 和写作 [28] 方面的特质。另一方面,ViTs 使用自注意力来学习全局交互 [53],并且与 CNN 相比,已被证明对局部模式的偏见较小。此属性可能有助于它们对分布图 5 的惊人稳健性。左图:随着越来越多的客户端参与 CWT 学习,客户端 3 的验证数据集的预测准确性的演变。我们使用 CIFAR-10 数据集的 Split 3(最异构的数据拆分)并比较使用 ResNet(50)(图中的 R50)、ResNet(50)-EWC [30] 和 ViT(S) 模型训练的 CWT。右:放大左图中的红色矩形。还显示了不同客户端的训练顺序。ResNet(50)-CWT 的顺序训练策略会在高度异构的数据分布下对先前的客户端造成灾难性的遗忘。ResNet(50)-EWC-CWT [30] 勉强解决了灾难性遗忘问题。ViT(S)-CWT 由于其强大的泛化能力和对异构数据的鲁棒性,有助于缓解这个问题。
进一步分析 Transformer 跨异构数据的泛化能力,设计了以下实验:
1. 跨异构设备的灾难性遗忘:
CNN 在分布外数据上的表现通常更差。这种现象在串行 FL 方法 CWT 中尤为严重。由于其顺序和串行训练策略,在 CWT 范例中训练 CNN 通常会导致对非 IID 数据分区的灾难性遗忘:在具有不同数据分布的新客户端上进行几次更新后,模型在先前客户端上的性能突然下降。这会导致更差和更慢的收敛,这在 FL 中是不希望的。在迁移学习文献中也发现了类似的遗忘问题。
在 CIFAR-10 数据集的 Split-3 上评估 CWT,以说明这种灾难性的遗忘现象。在图 5 中,我们绘制了随着越来越多的客户端参与 CWT 学习,Client-3 的验证数据集(与训练数据集共享相同的数据分布)的预测准确性的演变。将 Client-3 上训练有素的模型转移到 Client-4 时,先前 Client-3 验证数据集的预测准确度突然急剧下降(从 > 98% 到 < 1% 准确度)。然而,以 ViT 作为骨干训练的模型 (ViT(S)-CWT) 能够将知识从 Client-3 转移到 Client-4,同时仅丢失少量关于 Client-3 的信息(保持 98% 的准确率)。因此,ViT 可以更好地泛化到新的数据分布,而不会忘记旧数据分布。
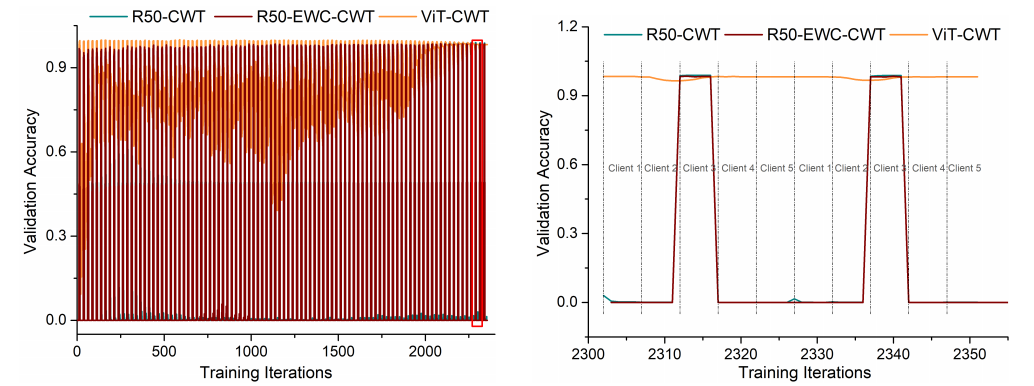
图5。左:随着更多的客户端参与CWT学习,客户端3验证数据集上预测精度的演变。我们使用CIFAR-10数据集的Split 3(异构数据最多的Split),并将训练好的CWT与ResNet(50)(图中的R50)、ResNet(50)-EWC[30]和ViT(S)模型进行比较。右:放大左图中的红色矩形。并给出了不同客户端的训练顺序。ResNet(50)-CWT的序列训练策略在高度异构的数据分布下会对之前的客户端产生灾难性的遗忘。ResNet(50)-EWC-CWT[30]勉强解决了灾难性遗忘问题。ViT(S)-CWT具有较强的泛化能力和对异构数据的鲁棒性,有助于缓解这一问题。
将 ViT(S)-CWT 与专门设计用于减轻灾难性遗忘的优化方法 EWC [30](使用 [23] 中的实现)进行比较。CWT 在 CIFAR-10 的 Split-3 上的串行训练可以被视为增量类学习任务,其中每个客户端都包含数据集中的类的独占子集。每个客户端模型共享相同的分类器到标准化联合标签空间 [23]。然而,从图 5 来看,EWC 几乎没有解决高度异构数据分区上的灾难性遗忘问题,这也与 [23] 中报告的结果相符。该实验进一步证明了 ViT 超越为 FL 设计的优化方法的有效性。
2. VIT-FL 在真实世界联邦数据集上的泛化:
一个训练有素的联邦模型应该在其他看不见的客户端的分布外测试数据集上表现良好。为了测试 Transformers 的通用性,我们使用图 6。测试集精度与 ViT(S)-FedAVG 上的通信回合及其与现有 FL 方法 FedProx [37] 和 FedAVG-Share [68] 的组合。Vision Transformers 可以与现有的基于优化的 FL 方法结合使用,以进一步提高收敛速度并以更少的通信次数达到目标性能。
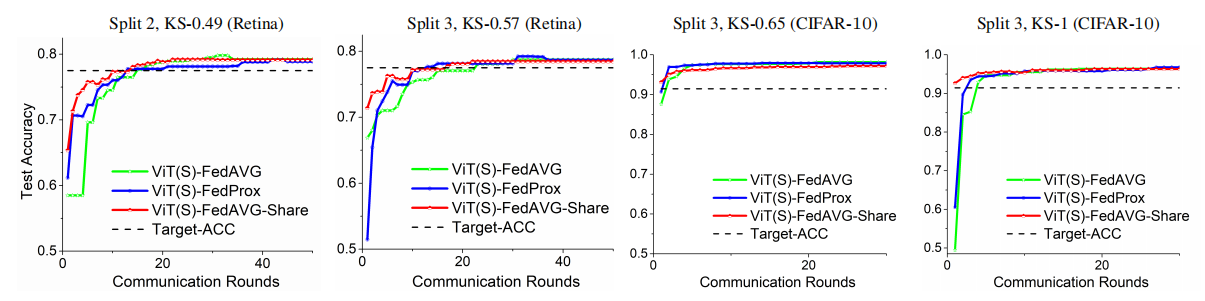
图6:ViT(S)-FedAVG及其与现有FL方法FedProx[37]和FedAVG-Share组合的通信轮的测试集精度[68]。视觉变形器可以与现有的基于优化的FL方法结合使用,进一步提高收敛速度,以更少的通信次数达到目标性能。
Split 2, KS-0.49 (Retina) Split 3, KS-0.57 (Retina) 将其应用于真实世界的联合 CelebA 数据集 [42],并将其与 ResNet 对应物 FedProx [37] 和 FedAVG-Share [68] 进行比较].我们在表 1 中报告了使用不同 FL 方法训练的模型对来自所有本地客户端的测试数据的联合的测试精度。我们的 VIT-FL 方法优于最先进的 FL 方法,并且还减少了方差。这表明 Transformer 学习到的全局模型比 CNN 模型更好。

表1:对CelebA数据集的预测准确率(%)。Vision transformer的性能优于ResNet(50)(表中的R50),也优于以ResNet(50)为骨干网络的基于优化的FL方法(FedProx和FedAVG-Share)。
3. VIT-FL 在极端大规模设置上的泛化:
为了验证 VIT-FL 在涉及数千个客户端的更大规模的真实世界分布式学习环境中的有效性,我们进一步将不同的 FL 方法应用到一个极端Retina 和 CIFAR-10 数据集上的边缘情况。这里的边缘情况被定义为一个客户只持有一个数据样本,这在医疗保健中很常见,患者只持有一个属于自己的数据样本。这导致了大量的异构客户端:Retina 有 6, 000 个,CIFAR-10 有 45, 000 个。从表 2 中,ViTs 仍然在这种极端异构的边缘案例设置上学习了一个有前途的全局模型,明显优于 ResNet 模型(在 Retina 上从 50% 到 80%,在 CIFAR-10 上从 30% 到 90%)。

表2。在有数千个客户参与训练的大规模边缘情况下(Retina和CIFAR-10分别为6,000和45,000个客户,每个客户包含一个数据样本)的预测精度(%)。在这种边缘情况下,视觉变形金刚的表现明显优于ResNet。
4.3.2 Transformer收敛得更快,更优(通信成本)
计算了达到集中训练的 ResNet(50) 预测准确度的 95% 的预定义目标测试集准确度所需的通信轮数。具体来说,我们将 Retina 和 CIFAR-10 数据集的目标准确率分别设置为 77.5% 和 91.5%。我们将串行 CWT 方法的一轮通信定义为所有联合本地客户端的一个完整训练周期。
从图 4 和表 3 可以看出,所有经过评估的 FL 方法都可以在同类数据分区上快速收敛到目标测试性能。然而,ResNet(50)-FedAVG 和 ResNet(50)-CWT 的收敛速度随着异质性的增加而降低,甚至在高度异质的数据分区上达到稳定状态(永远达不到目标精度)。相比之下,VIT-FL 在异构数据上仍然可以快速收敛。例如,ResNet(50)-CWT 由于在 CIFAR-10 上对异构数据分区 Split-2 和 Split-3 的严重灾难性遗忘而完全发散,而 ViT(S)-CWT 在 34 和 85 轮通信后达到目标性能。

表3达到目标性能(最佳和次优)所需的#传输消息大小(#通信轮× #模型参数(M))。ViT(S)和ResNet(50)的#模型参数分别为21.7M和23.5M。vit收敛速度更快,特别是在异构数据分割上,并且可以与基于优化的方法(FedProx和FedAVG-Share)结合使用,从而实现更快的收敛。
4.4.结合现有方法
由于我们对架构选择的调查在很大程度上与现有的基于优化的 FL 方法正交,我们的发现可以很容易地与后者结合使用。我们将 Vision Transformers 与基于优化的方法(FedProx [37] 和 FedAVG-Share [68])相结合,并将其应用于 Retina 和 CIFAR-10 数据集。从表 3 和图 6 可以看出,当应用于现有的 FL 优化方法时,VIT 进一步提升了异构数据客户端的性能。
4.5.实际使用要点
局部训练时期:
标准使用 E 表示局部模型在其局部数据集上经过的轮数。已知 E 会强烈影响 FedAVG [47] 和 CWT [7] 的性能。我们对局部训练时期 E 对 VITFL 的影响进行了实验研究。我们考虑将E=1,5,10 用于 ViT(B)-FedAVG,将E=1,5用于 ViT(B)-CWT。从图 7 中,我们发现 ViT 显示出与它们的 CNN 对应物相似的现象,即较大的 E 加速了 ViT(B)-FedAVG 在同质数据分区上的收敛,但可能导致异构数据分区上的最终性能恶化。类似地,ViT(B)-CWT 也有利于每个客户端之间的频繁传输速率,就像 ResNet(50)-CWT [7] 在非 IID 数据分区上一样。因此,我们建议用户对同质数据应用大 E 以减少通信,但对高度异构的情况应用小 E(VIT-FedAVG 的E小于等于5和和 VIT-CWT 的E=1)
预训练对 VIT-FL 的影响:
有证据表明,从头开始训练时,VIT 通常需要大量训练数据才能比 CNN 表现更好 [12]。我们进行实验以研究预训练对 VIT-FL 的影响。我们应用 FedAVG 作为训练算法,使用 Swin(T) [41] 作为骨干网络,并在 CIFAR-10 上进行测试。我们在训练期间应用与 [41] 相同的增强和正则化策略,并将最大通信轮数设置为 300。如表 4 所示,对于理想的集中托管和 FL 设置,从头开始训练时 Swin(T) 的性能都会下降。尽管如此,从头开始训练时,它在高度异构数据分区 Split-3 上的性能 (64.50%) 比使用更多数量级的数据进行预训练时的 ResNet(50)-FedAVG(图 3 中的 59.68%)要好得多。在实际应用中,建议用户将 VIT 作为他们的第一选择,因为在应用预训练模型时,VIT-FL 始终优于 CNN 对应物(图 1 和图 3)。如果没有大规模的预训练数据集,自我监督的预训练 [6, 18] 可能是一种替代方法。其他训练tips: FL中VIT的训练策略可以直接继承VIT训练,比如使用linear warm-up和learning rate decay,以及gradient clipping。相对较小的学习率和梯度范数剪辑对于稳定 CWT 中 VIT 的训练是必要的,特别是在高度异构的数据分区中。梯度范数剪辑还有助于跨异构数据使用 CNN 训练 FL,因为它已被证明可以减少局部更新和当前全局模型之间的权重差异 [37]。请参阅附录 B.1 了解更多一般提示和实验分析。
5、结论
尽管 FL 最近取得了进展,但在处理异构数据时仍然存在收敛和遗忘方面的挑战。与以前改进优化的方法不同,我们通过重新思考 FL 中的架构设计提供了一个新的视角。利用 Transformer 对异构数据和分布变化的稳健性,我们进行了广泛的分析,并证明了 Transformers 在减轻灾难性遗忘、加速收敛以及为并行和串行 FL 方法达到更好的优化方面的优势。我们发布我们的代码和模型,以鼓励在优化方面努力的同时开发健壮的架构。