Autor: Un pequeño retoño anhela convertirse en un árbol imponente
Declaración del autor: Escribe cada blog con cuidado
Autor gitee: Si
te gustan los artículos del autor, ¡presta atención al autor!

tipo de inserción
prefacio
Hoy presentaremos la clasificación por inserción. La clasificación por inserción se divide en dos tipos, una es la clasificación por inserción directa y la otra es la clasificación Hill. Estas dos clasificaciones tienen similitudes, así que vamos a presentar estas dos clasificaciones a continuación. (explicado en orden ascendente)
1. Clasificación por inserción directa
Primero, echemos un vistazo a la demostración de la animación:
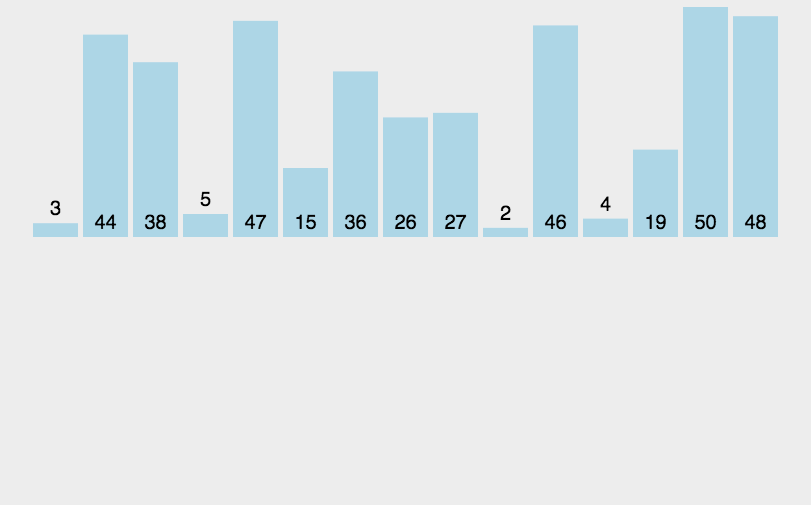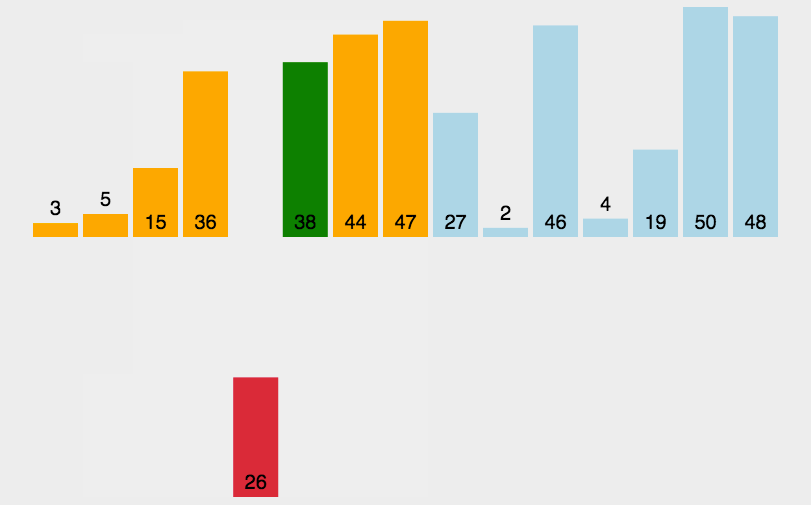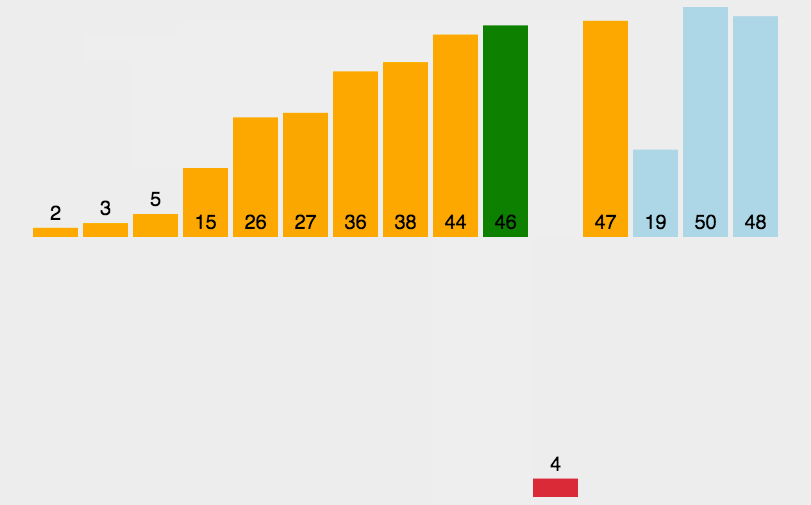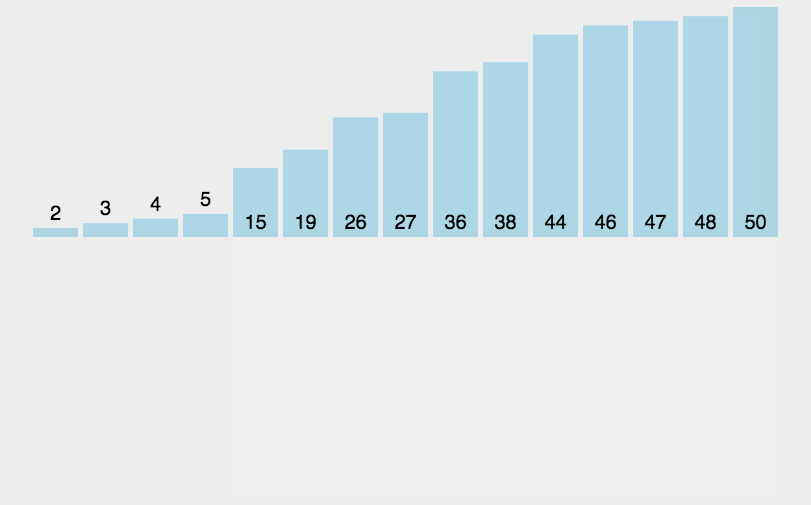
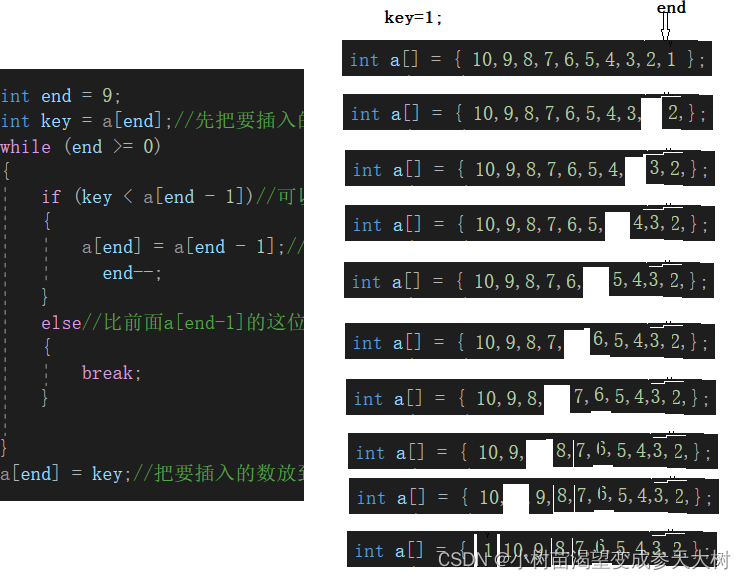
estamos caminando hacia atrás paso a paso, moviéndose un poco hacia atrás cuando encontramos uno grande e insertando datos en la parte posterior del pequeño cuando sabemos que hemos encontrado uno pequeño. uno. Echemos un vistazo a la ordenación de un solo paso primero:
int end = 9;
int key = a[end];//先把要插入的数据保存起来,方便和其他数进行比较
while (end >= 0)
{
if (key < a[end - 1])//可以小于前面的数,就把数往后面移一位
{
a[end] = a[end - 1];//
end--;
}
else//比前面a[end-1]的这位大就退出,把数据放到它后面,就是a[end]的位置
{
break;
}
}
a[end] = key;//把要插入的数放到这个位置
Resultados de clasificación de un solo paso:
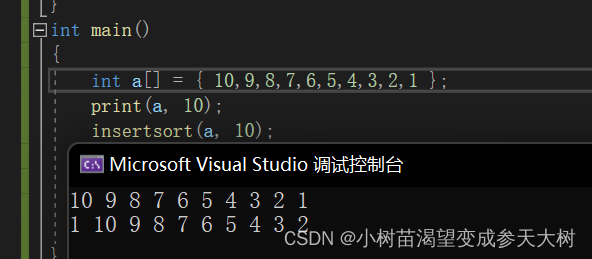
Veamos el dibujo:
En la ordenación real, cuando se empieza a ordenar el último dígito, el anverso debe estar en orden.Seleccionaremos la tecla de adelante hacia atrás para insertar, pero la idea de cada viaje es la misma.
Echemos un vistazo a la clasificación completa:
void insertsort(int* a, int n)
{
for (int i = 1; i <= n-1; i++)//i从1开始就可以了,没必要从0开始
{
int end = i;
int key = a[end];//先把要插入的数据保存起来,方便和其他数进行比较
while (end > 0)//因为都是和前面的数进行,加等于就跳到前面的位置,越界了,
{
if (key < a[end - 1])//可以小于前面的数,就把数往后面移一位
{
a[end] = a[end - 1];//把前面大的数移到后一位
end--;
}
else//比前面a[end-1]的这位大就退出,把数据放到它后面,就是a[end]的位置
{
break;
}
}
a[end] = key;//把要插入的数放到这个位置
}
}
Después de que todos hayan dominado esta idea, comenzaremos a explicar la clasificación de Hill
2. Clasificación de colinas
La clasificación por colinas se basa en la clasificación por inserción directa, primero la agrupación, luego la clasificación previa, la adición de agrupación, la clasificación y finalmente la clasificación exitosa, echemos un vistazo a la imagen: clasificación por inserción directa de elementos agrupados, comencé con Tres son un grupo
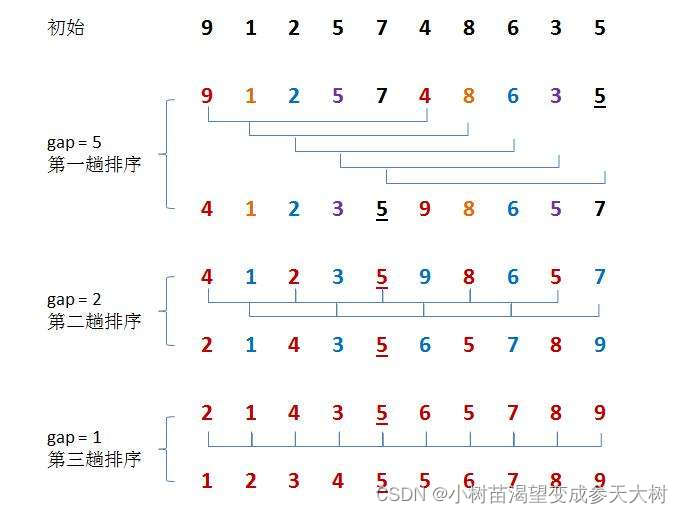
de espacios con una distancia de dos para que todos hagan un dibujo para demostrarlo. Es más intuitivo.
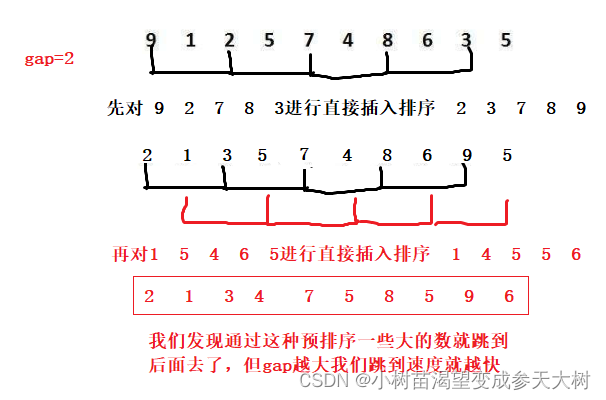
Esta es la clasificación unidireccional de Hill, pero el código real va hacia atrás uno por uno. Sé que la distancia es un espacio. Que todos ver más intuitivamente, echemos un vistazo al código para esta clasificación y luego veamos el conjunto:
int gap = 2;
for (int i = gap; i <=n - gap; i++)
{
int end = i;
int key = a[end];
while (end > 0)
{
if (key < a[end - gap])
{
a[end] = a[end - gap];
end -= gap;
}
else
{
break;
}
}
a[end] = key;
}
Solo hicimos un pequeño cambio para la clasificación por inserción directa, cambiar el espacio a 1 es una clasificación por inserción directa.
El resultado de la clasificación de un solo paso:
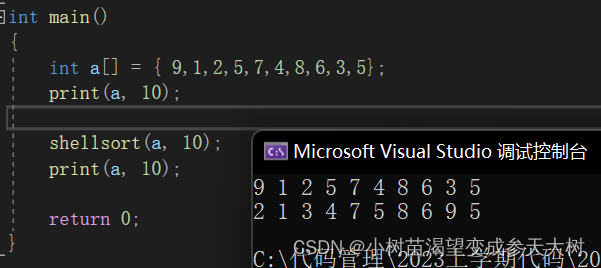
Solo necesitamos asegurarnos de que el último gap=1 sea suficiente, por lo que tenemos otra forma de escribir
gap=gap/3+1;
así es como damos el valor inicial de gap
void shellsort(int* a, int n)
{
int gap=n;
while (gap > 0)
{
gap = gap/2;
gap=gap/3+1;
for (int i = gap; i <= n - gap; i++)
{
int end = i;
int key = a[end];
while (end > 0)//因为都是和前面的数进行,加等于就跳到前面的位置,越界了,
{
if (key < a[end - gap])
{
a[end] = a[end - gap];
end -= gap;
}
else
{
break;
}
}
a[end] = key;
}
gap/=2;
}
}
Para la clasificación Hill, ¿por qué la eficiencia es mejor que la clasificación por inserción directa? La razón es que cuando gap> 1, todos están preclasificados y el propósito es hacer que la matriz esté más cerca del orden. Cuando gap == 1, la matriz ya está cerca del orden, por lo que será muy rápido. De esta manera, se puede lograr el efecto de optimización general.
La complejidad temporal de la clasificación Hill no es fácil de calcular, porque hay muchas formas de valorar la brecha, lo que dificulta el cálculo, por lo que la complejidad temporal de la clasificación Hill dada en muchos árboles no es fija.
Echemos un vistazo a cómo otros libros presentan la complejidad temporal de la clasificación Hill:
"Estructura de datos (edición en lenguaje C)" - Yan Weimin

"Estructura de datos - Método orientado a objetos y descripción de C++" - Yin Renkun Es

mejor que recordemos la conclusión, pero está bien si no podemos. Sí, los dibujos se pueden dominar muy rápidamente.
3. Resumen
Los dos tipos de los que hablo hoy pertenecen a la familia de tipos de inserción. Hay similitudes y diferencias entre los dos. Hay una brecha de rendimiento entre los dos. Actualizaré todos los artículos de clasificación antes de probar. Entonces, la clasificación de hoy es Detengámonos aquí primero, todos, vengan y hagan un dibujo para que lo entiendan ustedes mismos. En el próximo artículo, hablaremos sobre la selección y clasificación de la familia.
