Каталог статей
- 1. Обзор ClickHouse
- 2. Основные функции ClickHouse
-
- 2.1 Полные функции СУБД
- 2.2 Хранение столбцов и сжатие данных
- 2.3 Векторизованный исполнительный механизм
- 2.4 Реляционная модель и SQL-запрос
- 2.5 Разнообразные настольные движки
- 2.6, многопоточность и распределенность
- 2.7, архитектура с несколькими мастерами
- 2.8. Запрос в реальном времени (онлайн-запрос)
- 2.9, фрагментация данных и распределенный запрос
- 3. Дизайн архитектуры ClickHouse
- 4. Почему ClickHouse такой быстрый?
1. Обзор ClickHouse
1.1 Краткое введение
ClickHouseЭто база данных с MPPархитектурой , Она не принимает Hadoopархитектуру ведущий-ведомый в экологии, а использует результат одноранговой сети с несколькими ведущими, Это также ROLAPрешение Адрес документации официального сайта: https://clickhouse.com/docs/en/intro
1.2. Объяснение терминов
1.2.1, архитектура MPP
MMP: Массовая параллельная обработка (Massively Parallel Processing), заключается в параллельном распределении задач по нескольким серверам и узлам.После завершения расчета на каждом узле результаты соответствующих частей агрегируются для получения окончательного результата. База данных, использующая архитектуру MPP, называется базой данных MPP.
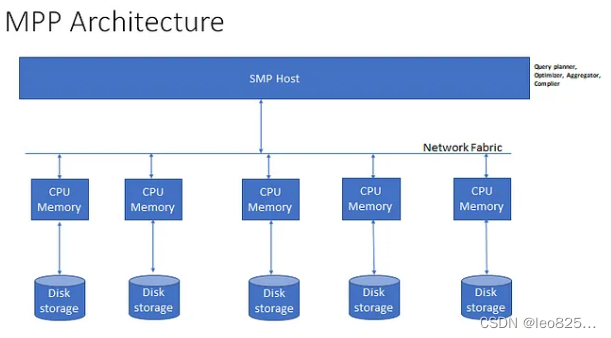
Особенности архитектуры MPP :
- MPP поддерживает распределенную архитектуру без общего доступа.
- В MPP каждый процессор обрабатывает свою часть задачи.
- У каждого процессора свой набор дисков
- Каждый узел отвечает только за обработку строк на своем диске.
- Легко расширяется, просто добавляя узлы
- Горизонтальное разбиение данных, сильная способность сжатия
- Процессоры MPP взаимодействуют друг с другом, используя некоторый интерфейс передачи сообщений.
- В MPP каждый процессор использует свою операционную систему (ОС) и память.
И MPPDB, и Hadoop распределяют вычисления по узлам для независимых вычислений и объединяют результаты (распределенные вычисления), но у них есть свои преимущества, недостатки и область применения из-за различных принятых теорий и технических путей. Сравнение этих двух технологий с традиционными технологиями баз данных выглядит следующим образом:

В целом, конкретные и применимые сценарии технологий Hadoop и MPP:
● Hadoop имеет преимущества при обработке неструктурированных и частично структурированных данных и особенно подходит для таких требований приложений, как обработка больших пакетов данных.
● MPP подходит для замены обработки больших данных в рамках существующей организации реляционных данных и обладает высокой эффективностью.
1.2.2, векторизованный исполнительный механизм
向量化执行引擎(Векторизованный механизм выполнения), для столбцовых данных в памяти один пакет вызывает SIMD-инструкции (вместо вызова по одному разу для каждой строки), что не только уменьшает количество вызовов функций и промахов кэша, но также может полностью использовать параллельные возможности. SIMD-инструкций, что значительно сокращает время вычислений. Движок векторного исполнения обычно может обеспечить увеличение производительности в несколько раз.
Простое понимание состоит в том, чтобы исключить оптимизацию программного цикла, ускорить работу машины с кучей и реализовать векторизованное выполнение, которое требует использования SIMD-инструкций ЦП.
1.2.3 、SIMD
SIMD(Single Instruction Multiple Data), с использованием одного потока инструкций и нескольких потоков данных, то есть одна рабочая инструкция может выполнять несколько потоков данных.Простым примером является сложение и вычитание векторов, что не подходит для сценариев со многими ветвь суждения .
1.2.4 、OLAP
OLTP: Обработка транзакций в режиме онлайн означает обработку транзакций в режиме онлайн. Для успешного и своевременного обновления данных требуется высокая производительность в режиме реального времени и высокая стабильность. С точки зрения базы данных OLTP в основном касается добавления, удаления и изменения данных.
OLAP: On-line Analytical Processing переводится в онлайн-аналитическую обработку. Необходимо централизовать и унифицировать анализ бизнес-данных.Как правило, данные хранятся в хранилище данных для обеспечения унифицированного анализа OLAP. OLAP — это в основном приложение хранилища данных, которое представляет собой запрос данных.

ROLAP: Реляционный OLAP, реляционная онлайн-аналитическая обработка. Как следует из названия, он использует реляционное построение напрямую, а модель данных часто использует схему «звезда» или «схема-снежинка» ( схема-звезда и схема-снежинка ). ROLAP представляет традиционные реляционные базы данных, распределенные базы данных MPP и Spark/Impala на основе Hadoop, которые характеризуются возможностью одновременного подключения подробных и сводных данных, расчета данных в режиме реального времени в соответствии с потребностями пользователей. , и вернуть его пользователю. Из-за используемой технологии вычислений в реальном времени очевидны и недостатки ROLAP — когда количество вычислений достигает определенного уровня или количество параллелизма достигает определенного уровня, обязательно возникают проблемы с производительностью .
Представленные традиционными реляционными базами данных, такими как Teradata, Oracle и т. д., из-за плохой масштабируемости традиционной архитектуры требования к оборудованию очень высоки.Когда объем вычисляемых данных достигнет десятков миллионов, появится вычисление базы данных. Задержка не позволяет пользователям получить своевременный ответ, не говоря уже об увеличении параллелизма.
Распределенная база данных MPP (GreenPlum/GBase/Vertica) частично решает проблему масштабируемости, а также несколько снижены требования к аппаратным устройствам (по-прежнему есть определенные аппаратные требования), а поддерживаемый объем данных (уровень ГБ, ТБ) значительно улучшилась. Когда в кластере сотни или тысячи узлов, возникает узкое место в производительности (независимо от того, сколько узлов добавляется, улучшение производительности не будет очевидным), а затраты на расширение также высоки.
Spark/Impala на основе Hadoop имеет очень низкие требования к оборудованию для развертывания (достаточно обычных серверов, но он в основном использует вычисления в памяти для сокращения времени отклика, поэтому у него высокие требования к памяти), а стоимость расширения узла относительно низкая. Однако, когда количество вычислений достигает определенного уровня или параллелизм достигает определенного уровня, он не может ответить в течение нескольких секунд, и могут возникнуть такие проблемы, как переполнение памяти.
MOLAP: Многомерный OLAP, многомерная онлайн-аналитическая обработка. Анализ MOLAP представлен Cognos, SSAS, Kylin и др. Концепция дизайна заключается в предварительном расчете потребностей заказчика и сохранении их в виде результатов (например, если таблица разбита на 10 измерений и 5 мер, то спрос клиента Будет 2 в 10-й степени возможностей, а затем вычислить и сохранить эти возможности заранее), когда клиент делает запрос, найти соответствующий результат и вернуть его. Особенность заключается в том, что он возвращается очень быстро, когда требование выполняется (поэтому MOLAP очень подходит для распространенных фиксированных сценариев анализа), объем данных, поддерживаемых теми же ресурсами, больше, и параллелизм поддерживается.Недостатком является то, что больше измерений таблица, тем она сложнее . , чем больше требуется дискового пространства для хранения, тем больше времени потребуется для построения куба .
HOLAP: Гибридный OLAP, OLAP с гибридной архитектурой. Эту идею можно понимать как интеграцию ROLAP и MOLAP.
1.3 Сценарии применения
Применимые сценарии :
- Подавляющее большинство запросов на доступ для чтения
- Данные необходимо обновлять большими пакетами (более 1000 строк), а не обновлять одну строку или вообще не выполнять операцию обновления.
- Данные просто добавляются в базу данных, никаких изменений не требуется
- При чтении данных из базы данных извлекается большое количество строк, но используется лишь небольшое количество столбцов.
- Таблица «широкая», то есть содержит большое количество столбцов
- Относительно низкая частота запросов (обычно сотни запросов в секунду или меньше на сервер)
- Для простых запросов допускается задержка около 50 мс.
- Значения столбца — это относительно небольшие числа и короткие строки (например, всего 60 байт на URL)
- Требует высокой пропускной способности (до миллиардов строк в секунду на сервер) при обработке одного запроса.
- транзакция не требуется
- Требования к согласованности данных низкие
- В каждом запросе будет запрашиваться только одна большая таблица. За исключением одного большого стола, остальные столики маленькие.
- Результат запроса значительно меньше источника данных. То есть данные имеют фильтрацию или агрегацию. Возвращаемый результат не превышает размер памяти одного сервера
Неприменимые сценарии :
- Не поддерживает реальную поддержку удаления/обновления, не поддерживает транзакции (с нетерпением жду поддержки в последующих версиях)
- Вторичные индексы не поддерживаются
- Ограниченная поддержка SQL, разные реализации соединения
- Не поддерживает оконные функции
- Управление метаданными требует ручного вмешательства для поддержания
2. Основные функции ClickHouse
2.1 Полные функции СУБД
ClickHouse имеет полные функции управления, а не только базу данных. Как СУБД, она имеет некоторые основные функции.
DDL: Язык определения данных, язык определения данных, может динамически создавать, изменять или удалять базы данных, таблицы и представления без перезапуска службы.
DML: Язык манипулирования данными, язык манипулирования данными, может динамически добавлять, удалять, изменять и запрашивать данные.
权限控制: вы можете установить разрешения для работы с базой данных или таблицами в соответствии с пользовательской степенью детализации, чтобы обеспечить безопасность данных.
数据备份与恢复: Предоставляет механизмы восстановления экспорта и импорта резервных копий данных в соответствии с требованиями производственной среды.
分布式管理: Обеспечьте режим кластера и самостоятельное управление несколькими узлами базы данных.
2.2 Хранение столбцов и сжатие данных
Если вы хотите сделать запрос быстрее, самый простой и эффективный способ — уменьшить диапазон сканирования данных и размер передачи данных.Поколоночное хранение и сжатие данных могут помочь нам достичь двух вышеуказанных пунктов.
Хранилище столбцов : избегайте избыточного сканирования данных при сканировании указанных столбцов.
Сжатие данных : сопоставляйте и сканируйте данные в соответствии с определенным размером шага и выполняйте преобразование кода при обнаружении повторяющихся частей, уменьшая нагрузку на ввод-вывод и хранилище.
Пример:
До сжатия : abcdefghi_bcdefghi
После сжатия : abcdefghi_(9,8)
Суть сжатия заключается в сопоставлении и сканировании данных в соответствии с определенным размером шага, а также в выполнении преобразования кодирования при обнаружении повторяющихся частей. Например, (9,8) в приведенном выше примере означает, что если вы переместитесь вперед на 9 байтов от знака подчеркивания, он будет соответствовать повторяющемуся элементу длиной 8 байтов, то есть bcdefghi.
Конечно, реальный алгоритм сжатия сложнее, чем в нашем примере, 默认使用 LZ4 算法压缩общий коэффициент сжатия данных достигает 8:1 (17ПБ до сжатия и 2ПБ после сжатия). В дополнение к снижению нагрузки на ввод-вывод и хранилище, колоночное хранение также прокладывает путь для векторизованного выполнения.
2.3 Векторизованный исполнительный механизм
Простое понимание векторизованного механизма выполнения состоит в том, чтобы исключить оптимизацию цикла программы, ускорить работу с кучей и параллелизм на уровне данных. Достижение векторизованного выполнения использует SIMD-инструкции ЦП. SIMD 的全称是 Single Instruction Multiple Data,即用单挑指令操作多条数据. В современной концепции компьютерной системы это реализация повышения производительности за счет параллелизма данных (другие включают параллелизм на уровне инструкций и параллелизм на уровне потоков).Его принцип заключается в реализации параллельных операций с данными на уровне регистров ЦП.
В архитектуре компьютерной системы система хранения представляет собой иерархию. Иерархия хранилища для типичного сервера показана на следующей диаграмме:
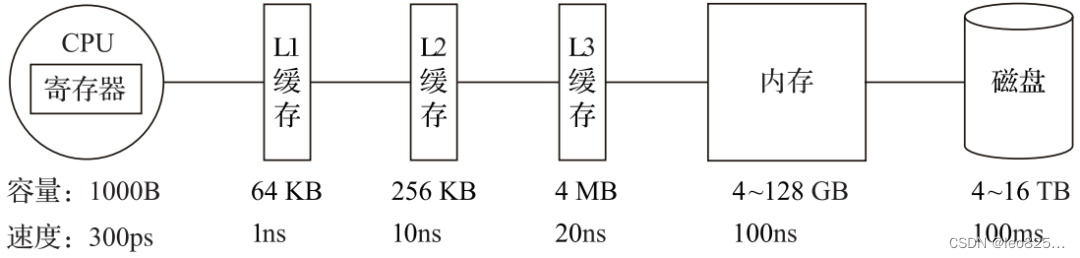
Как видно из рисунка выше, слева направо, чем дальше от ЦП, тем медленнее скорость доступа к данным. Доступ к данным из регистров в 300 раз быстрее, чем доступ к данным из памяти, и в 30 миллионов раз быстрее, чем доступ к данным с диска. Таким образом, использование характеристик векторизованного выполнения ЦП имеет большое значение для повышения производительности программы.
ClinckHouse в настоящее время использует уровень инструкций SSE4.2 для реализации векторизованного выполнения.
2.4 Реляционная модель и SQL-запрос
- По сравнению с другими моделями, такими как документы и пары ключ-значение, реляционная модель ClickHouse обладает лучшими возможностями описания и может более четко выражать отношения между сущностями. В области OLAP большое количество рабочих моделей данных основано на реляционных моделях (модель звезды, модель снежинки и даже модель широкой таблицы). Поэтому стоимость миграции систем, основанных на традиционных реляционных базах данных или хранилищах данных, на ClickHouse очень низкая.
- Полностью используйте SQL в качестве языка запросов (группа поддержки, порядок, объединение, в и большинство стандартных SQL),
SQL 解析方面 ClickHouse 是大小写敏感的семантика, представленная select a и select A, отличается.
2.5 Разнообразные настольные движки
Оригинальная архитектура ClickHouse реализована на базе MySQL, конструкция движка таблиц аналогична MySQL, а движок хранилища представляет собой независимый интерфейс. Есть много типов, и вы можете выбрать в соответствии с бизнес-сценарием. ClickHouse имеет более 20 движков таблиц в 6 категориях, включая дерево слияния, память, файл, интерфейс и другие. Очень гибко поддерживать определенные сценарии с помощью определенных движков таблиц. Для простых сцен можно напрямую использовать простые движки для снижения затрат, а для сложных сцен есть подходящие варианты. (У ClickHouse много табличных движков, и я позже оставлю статью, посвященную знакомству с табличными движками)
2.6, многопоточность и распределенность
- Векторизованное выполнение повышает производительность за счет параллелизма на уровне данных, а многопоточность повышает производительность за счет параллелизма на уровне потоков . По сравнению с векторизованной реализацией SIMD, основанной на базовой аппаратной реализации, параллелизм на уровне потоков обычно контролируется программным уровнем более высокого уровня. Многопоточность (параллелизм на уровне потоков) дополняет векторизованное выполнение (параллелизм на уровне данных).
- Заранее распределите данные по каждому серверу и отправьте запрос данных непосредственно на сервер, на котором они расположены, поскольку перемещение вычислений более рентабельно, чем перемещение данных .
С точки зрения доступа к данным, ClickHouse поддерживает не только партиционирование (вертикальное расширение с использованием принципа многопоточности), но и поддерживает фрагментацию (горизонтальное расширение с использованием принципа распределения), что можно сказать о применении многопоточности и распределенности. технологии до крайности.
2.7, архитектура с несколькими мастерами
Распределенные системы, такие как HDFS, Spark, HBase и Elasticsearch, используют архитектуру Master-Slave master-slave с управляющим узлом, выступающим в роли лидера для координации общей ситуации. С другой стороны, ClickHouse использует архитектуру Multi-Master с несколькими мастерами: каждый узел в кластере имеет одинаковую роль, и клиент может получить доступ к любому узлу, чтобы получить тот же эффект . Он имеет следующие преимущества:
- Одноранговая роль упрощает архитектуру системы, не нужно различать главные узлы управления, узлы данных и вычислительные узлы, и все узлы в кластере выполняют одну и ту же функцию.
- Это естественным образом позволяет избежать проблемы единой точки отказа и очень подходит для сценариев с несколькими центрами обработки данных и удаленными местоположениями.
2.8. Запрос в реальном времени (онлайн-запрос)
- Сходства: по сравнению с другими аналитическими базами данных существует много общего, например, поддержка сценариев массивных запросов, столбцовое хранилище, сегментирование данных, выталкивание вычислений и другие специальные эффекты, указывающие на то, что CK вобрал в себя различные преимущества в своей конструкции.
- С точки зрения цены: другие системы с открытым исходным кодом медленные, а коммерческие системы дорогие. ClickHouse — это быстро и бесплатно.
Некоторые места переведены в онлайн-запрос, мне кажется, правильнее перевести в "запрос в реальном времени". По сравнению с другими аналитическими базами, такими как "Вертика", SparkSQL, Hive, Elasticsearch и т. д., ClickHouse работает быстро и бесплатно. в сценариях анализа больших данных.
2.9, фрагментация данных и распределенный запрос
- ClickHouse имеет локальную таблицу (Local Table) и распределенную таблицу (Distributed Table), локальная таблица эквивалентна части фрагментации данных, а распределенная таблица не хранит данные, а является только прокси доступа к локальной таблице.
- Распределенные таблицы аналогичны промежуточному программному обеспечению подбазы данных, и агенты получают доступ к нескольким сегментам данных для выполнения распределенных запросов.
3. Дизайн архитектуры ClickHouse
В настоящее время информация, которую публикует ClickHouse, относительно скудна, например, трудно найти полную информацию об уровне архитектуры, и нет даже общей схемы архитектуры.
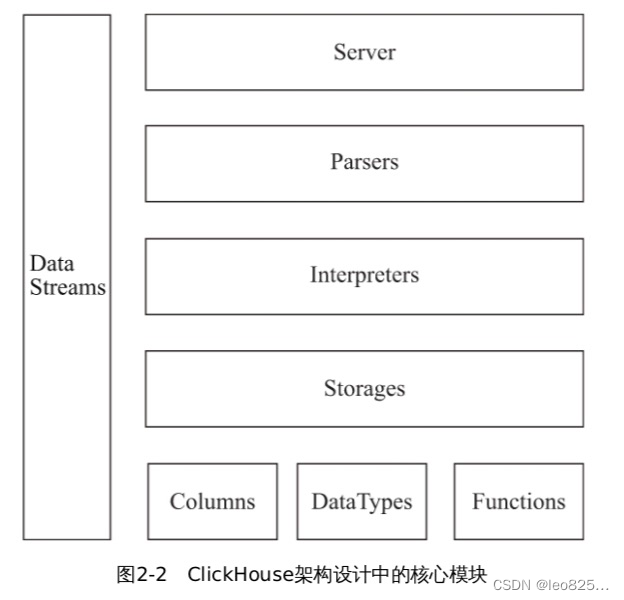
3.1. Столбец и поле
Колонка и поле — самые основные единицы отображения данных ClickHouse . Столбец данных в памяти ClickHouse представлен объектом Column, а строка в столбце (строка данных в одном столбце) представлена объектом Filed.
Объект столбца : он разделен на две части: интерфейс и реализация. Интерфейс IColumn определяет методы для различных реляционных операций с данными; конкретная реализация методов реализуется соответствующими объектами в соответствии с различными типами данных, такими как ColumnString, ColumnArray и ColumnTuple.
Объект поля : используйте шаблон проектирования агрегации. Внутри объекта Field агрегируются 13 типов данных, таких как Null, UInt64, String и Array, и соответствующая логика обработки.
3.2、Тип данных
Он отвечает за сериализацию и десериализацию данных, но напрямую за чтение данных не отвечает, а получается объектами Column или Field . В классе реализации DataType агрегируются объекты Column и объекты Field соответствующих типов данных. Например, DataTypeString будет ссылаться на ColumnString строкового типа, DataTypeArray будет ссылаться на ColumnArray типа Array и так далее.
3.3. Блокировка и блокировка потока
Данные ClickHouse ориентированы на объект Block и используют потоковый метод. Хотя столбец и поле представляют собой базовую единицу сопоставления данных, в них по-прежнему отсутствует некоторая информация, необходимая для фактической работы, например тип данных и имя столбца. Так спроектирован объект Block, и объект Block можно рассматривать как подмножество таблицы данных.
Блок = объект данных (столбец/поле) + DataType + строка имени столбца
Потоковые операции имеют два интерфейса верхнего уровня: IBlockInputStream отвечает за чтение данных и реляционные операции, а IBlockOutputStream отвечает за вывод данных на следующую ссылку.
3.4, Таблица
В базовом дизайне таблицы данных нет так называемого объекта Table, который напрямую использует интерфейс IStorage для ссылки на таблицу данных.
Табличный движок — примечательная особенность ClickHouse.Различные движки таблиц реализуются разными подклассами, такими как IStorageSystemOneBlock (системная таблица), StorageMergeTree (движок таблицы дерева слияния) и StorageTinyLog (движок таблицы журнала).
3.5, Парсер и интерпретатор
Анализатор Parser отвечает за создание объекта AST (Абстрактное синтаксическое дерево, Абстрактное синтаксическое дерево), а интерпретатор Interpreter отвечает за интерпретацию AST и дальнейшее создание конвейера выполнения запроса. Вместе с IStorage они последовательно соединяют весь процесс запроса данных. Анализатор Parser может разобрать инструкцию SQL в синтаксическое дерево AST методом рекурсивного спуска. Различные операторы SQL будут анализироваться с помощью разных классов реализации Parser.
3.6、Функции 与 Агрегатные функции
Обычные функции, такие как четыре арифметических операции, преобразование на сутки вперед, функции извлечения URL-адресов и функции десенсибилизации IP-адресов. Состояние отсутствует, и эффект функции действует на каждую строку данных. В конкретном процессе выполнения функции метод векторизации используется для непосредственного воздействия на весь столбец данных вместо построчного вычисления.
Агрегатная функция с отслеживанием состояния, такая как агрегатная функция COUNT, состояние AggregateFunctionCount записывается с целочисленным типом UInt64. Состояние функции агрегации поддерживает сериализацию и десериализацию, поэтому его можно передавать между распределенными узлами для реализации инкрементных вычислений.
3.7、Репликация кластера
Кластер состоит из осколков, а осколки состоят из реплик. У одной ноды ClickHouse может быть только один шард, для реализации 1 шарда и 1 копии необходимо развернуть как минимум две сервисные ноды . Фрагментация является логической концепцией, а физический носитель осуществляется репликами.
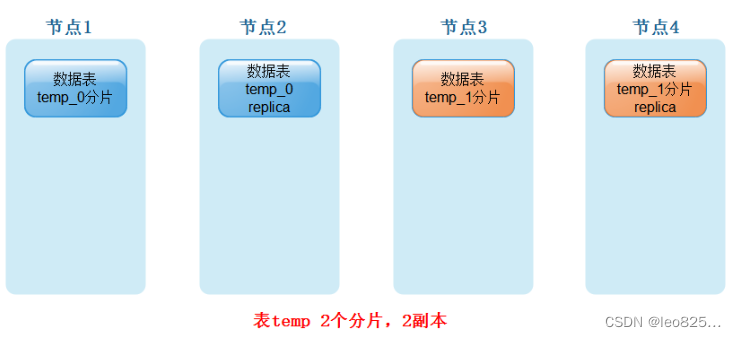
В приведенном выше примере 2 сегмента и 2 копии требуют 4 физических узла.
4. Почему ClickHouse такой быстрый?
- Сосредоточьтесь на аппаратном обеспечении : сосредоточьтесь на аппаратном обеспечении и сможете рассчитать примерную производительность перед его внедрением.
- Алгоритм прежде всего : ClickHouse выбрал разные алгоритмы для разных сценариев использования, и производительность является основным фактором при выборе алгоритма.
- Отважьтесь попробовать что-то новое : осмельтесь попробовать новейший и самый быстрый алгоритм и найдите наиболее подходящую реализацию алгоритма.
- Непрерывное улучшение : постоянное тестирование и непрерывное улучшение во всех аспектах.