Tabla de contenido
1. El origen del mecanismo de atención
2. Regresión del kernel de Nadaraya-Watson
Con la popularidad del modelo Transformer en los campos de PNL, CV e incluso CG, cada vez más académicos han notado el mecanismo de atención (Mecanismo de atención), y se introduce en varias tareas de aprendizaje profundo para mejorar el rendimiento. El equipo del profesor Hu Shimin de la Universidad de Tsinghua publicó recientemente una revisión de Atención sobre CVM [1], que presentó en detalle el progreso de la investigación relacionada en este campo. Para las aplicaciones de nube de puntos, la introducción de un mecanismo de atención y el diseño de un nuevo modelo de aprendizaje profundo es, naturalmente, un punto crítico de investigación. Este artículo toma el mecanismo de atención como objeto, describe su desarrollo y su aplicación exitosa en el campo de las aplicaciones de nubes de puntos, y proporciona alguna referencia para los estudiantes que esperan lograr avances en esta dirección de investigación.
1. El origen del mecanismo de atención
Consulte el libro de texto de aprendizaje en profundidad del Sr. Li Mu [2] para la introducción del mecanismo de atención Aquí hay una explicación simple del mecanismo de atención. El mecanismo de atención es un mecanismo que simula la percepción visual humana y filtra selectivamente la información para su recepción y procesamiento. Al filtrar información, si no se proporciona un aviso autónomo, es decir, cuando una persona lee un texto, observa una escena o escucha un audio sin pensar, el mecanismo de atención está sesgado hacia información anormal, como una escena en blanco y negro. Una chica de rojo, o un signo de exclamación en un párrafo, etc. Cuando se introducen indicaciones autónomas, como cuando desea leer oraciones relacionadas con un sustantivo determinado o escenas asociadas con varios objetos, el mecanismo de atención presenta esta indicación y aumenta la sensibilidad a esta información cuando se filtra la información. Para modelar matemáticamente el proceso anterior, el mecanismo de atención introduce tres elementos básicos, a saber, consulta, clave y valor. Estos tres elementos juntos constituyen la unidad básica de procesamiento del Módulo de Atención. La clave (Key) y el valor (Value) corresponden a la entrada y salida de información, y la consulta (Query) corresponde al aviso autónomo. La unidad básica de procesamiento del Módulo de Atención se muestra en la siguiente figura.
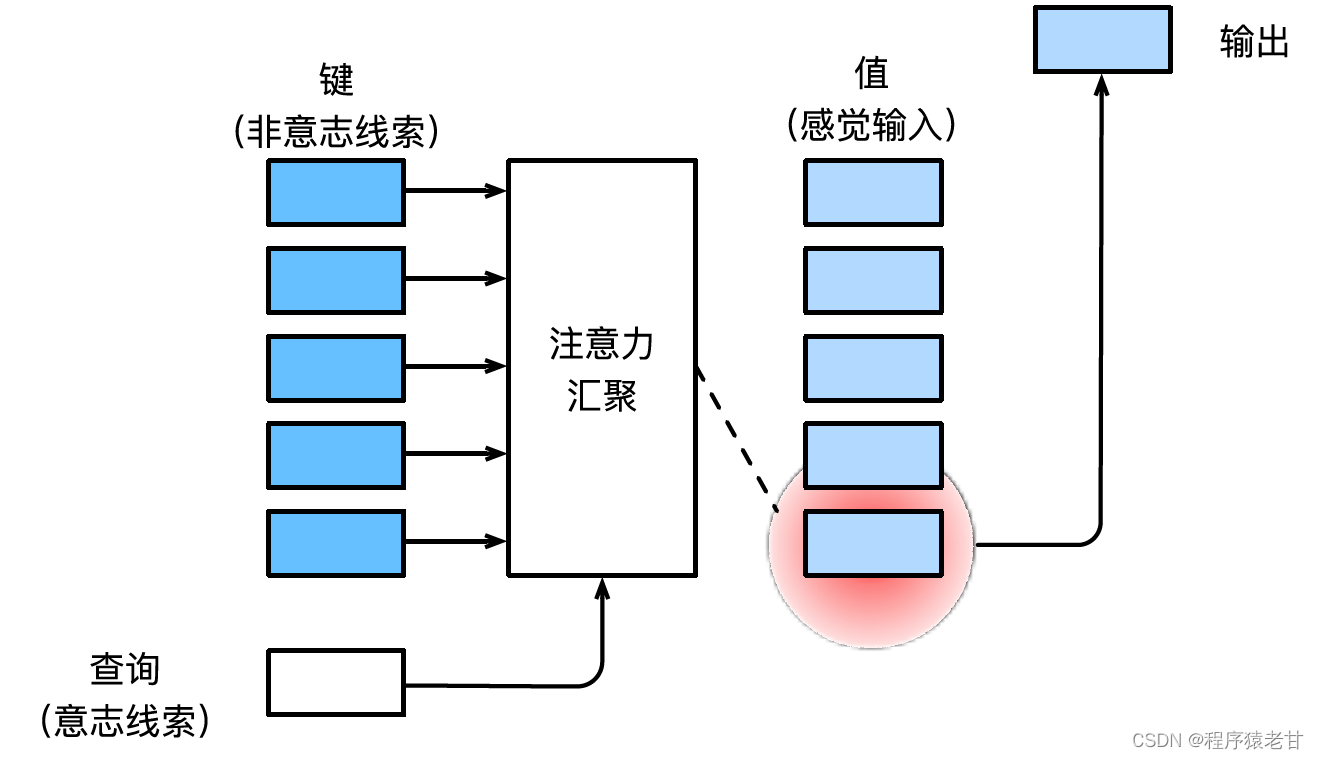
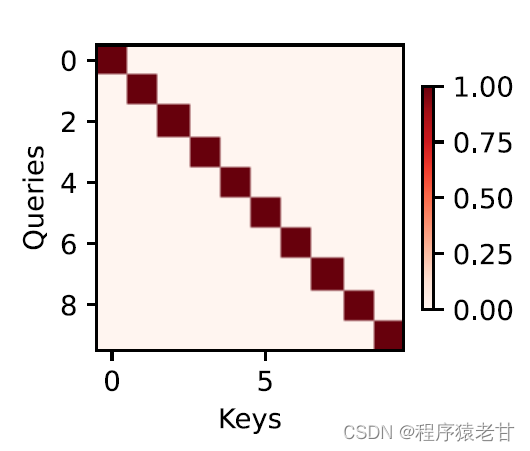
El mecanismo de atención combina la consulta y la clave a través de la agrupación de atención para realizar la tendencia de selección del valor. La clave y el valor están emparejados, al igual que la entrada y la salida en la tarea de entrenamiento, que es una distribución de datos conocida o una correspondencia de categoría. El mecanismo de atención ingresa la consulta en el grupo de atención, establece el código de peso de la consulta a cada clave, obtiene la relación entre la consulta y la clave, y luego guía la salida del valor correspondiente. En resumen, cuando la consulta está más cerca de una clave, la salida de la consulta está más cerca del valor correspondiente a la clave. Este proceso introduce la atención en la correspondencia clave-valor más cerca de la consulta para guiar la salida compatible con la atención. Si se establece una matriz de relación bidimensional correspondiente a la consulta y la clave, cuando los valores son iguales es 1, y cuando son diferentes es 0, y el resultado de la visualización se puede expresar como :
2. Regresión del kernel de Nadaraya-Watson
Aquí hay un modelo de mecanismo de atención clásico, la regresión kernel de Nadaraya-Watson [3] [4], para comprender la lógica operativa básica del mecanismo de atención. Supongamos que tenemos un conjunto de datos de correspondencia clave-valor {(x1,y1),(x2,y2),...(xi,yi)} controlado por una función f, la tarea de aprendizaje es establecer f y guiar la nueva Evaluación de la tecla x. En esta tarea, (xi, yi) corresponde a la clave y el valor, la entrada x representa la consulta y el objetivo es obtener su valor correspondiente. Según el mecanismo de atención, es necesario establecer la predicción de su valor examinando la relación de similitud entre x y cada valor clave en el conjunto de datos de correspondencia de valor clave. Cuando la entrada x está más cerca de cierta tecla xi, el valor de salida está más cerca de yi. El estimador más simple para valores-clave aquí es el promedio:
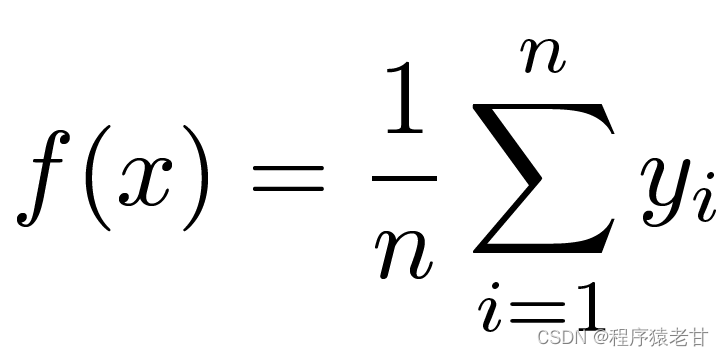
Obviamente, esto no es una buena idea. Porque la agrupación promedio ignora la desviación de la muestra en la distribución de clave-valor. Si la diferencia clave-valor se introduce en el proceso de evaluación, el resultado naturalmente será mejor. La regresión kernel de Nadaraya-Watson utiliza esta idea y propone un método de evaluación ponderado:
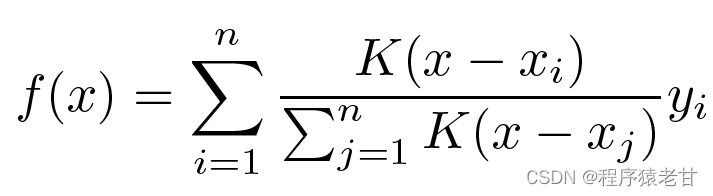
Se considera que K es el núcleo, es decir, se entiende como un peso para medir la desviación de la diferencia. Si la fórmula anterior se reescribe según el peso de la diferencia entre la entrada y la clave, se puede obtener su propia fórmula:
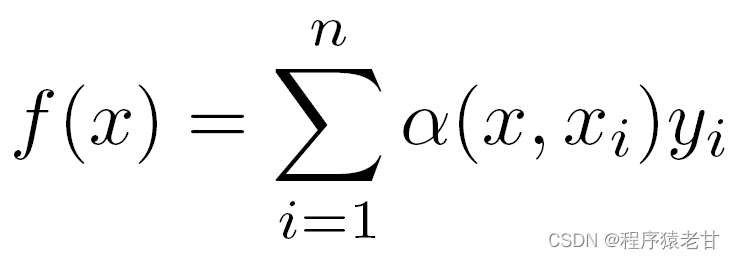
Si los pesos anteriores se reemplazan por un peso gaussiano impulsado por un kernel gaussiano, entonces la función f se puede expresar como:
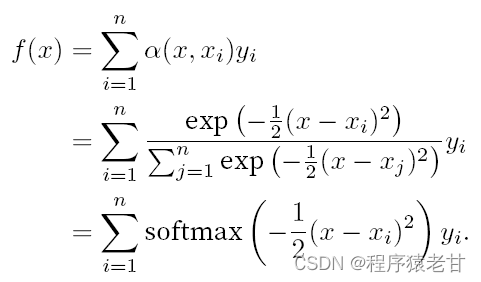
Aquí se proporciona un esquema para comparar el ajuste de diferentes f para muestras de pares clave-valor derivados de la agrupación promedio (panel izquierdo) y la agrupación de atención impulsada por el núcleo gaussiano (panel derecho). Se puede ver que el rendimiento de ajuste de este último es mucho mejor.
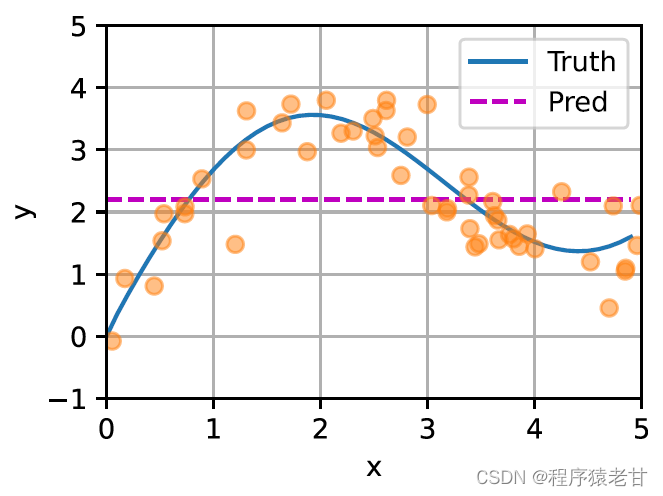
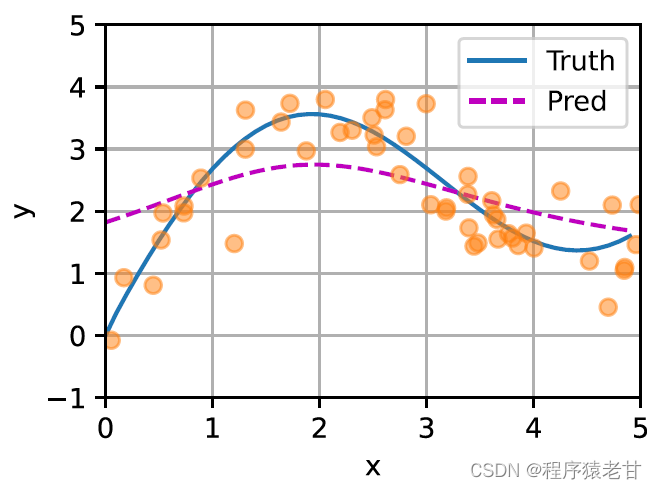
El modelo anterior es un modelo no paramétrico, para el caso de parámetros aprendibles, se recomienda leer el capítulo de mecanismo de atención de [2]. El núcleo gaussiano y su peso gaussiano correspondiente que se usan aquí se usan para describir la relación entre la consulta y la clave. En el mecanismo de atención, la representación cuantitativa de esta relación es el puntaje de atención. El proceso mencionado anteriormente de establecer predicciones para los valores de consulta se puede expresar estableciendo una puntuación basada en pares clave-valor para la consulta y asignando pesos a las puntuaciones para obtener valores de consulta, expresados como:
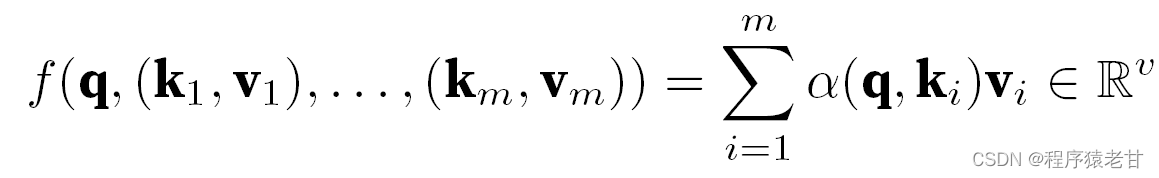
Donde α representa el peso, q representa la consulta y kv representa el par clave-valor. En el libro de texto [2], también se presenta cómo lidiar con el método de procesamiento de atención aditiva de consulta y tiempo de desajuste de longitud de clave y la atención de producto escalar, que se usa para definir la puntuación de atención, y no se detallará aquí.
3. Atención de múltiples cabezas y autoatención.
1) Atención de múltiples cabezas
La atención de múltiples cabezas se utiliza para combinar consultas y representaciones subespaciales con diferentes valores clave, y realizar la organización de diferentes comportamientos basados en el mecanismo de atención para aprender conocimiento estructurado y dependencias de datos. Se aprenden diferentes proyecciones lineales de forma independiente para transformar consultas, claves y valores. Luego, la consulta transformada y el valor clave se envían al grupo de atención en paralelo, y luego las salidas de varios grupos de atención se unen y se transforman mediante otra proyección lineal que se puede aprender, y se genera el resultado final. Este diseño se denomina atención multicabezal [5]. La siguiente figura muestra un modelo de atención de múltiples cabezas que se puede aprender:
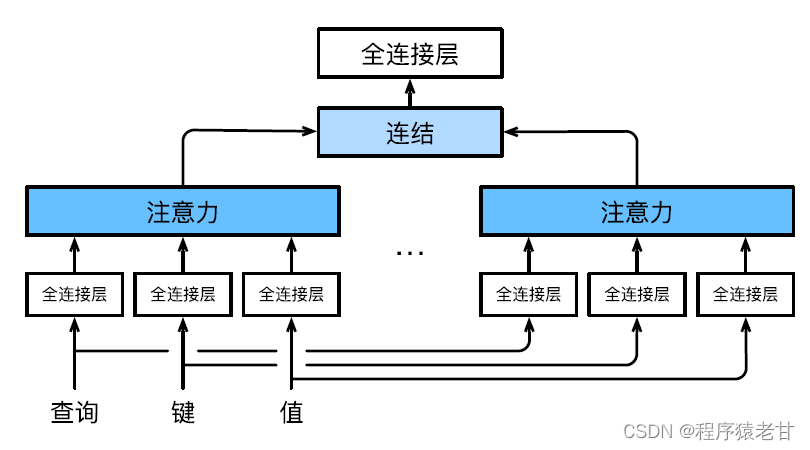
A continuación se da la definición matemática de cada cabeza de atención, dada una consulta q, clave k y valor v, el método de cálculo de cada cabeza de atención h es:
![]()
Aquí f puede ser atención aditiva y atención de producto punto escalado. La salida de la atención de múltiples cabezas sufre otra transformación lineal para concatenar las salidas de múltiples mecanismos de atención para imitar funciones más complejas.
2) Autoatención y codificación de posición
Según el mecanismo de atención, la secuencia léxica en el problema de NLP se ingresa en el grupo de atención, y un grupo de elementos léxicos se utilizan como consultas y valores clave al mismo tiempo. Cada consulta atiende a todos los pares clave-valor y produce una salida de atención. Dado que la consulta y los valores clave provienen todos del mismo conjunto de entradas, se denomina mecanismo de autoatención. Aquí se dará un método de codificación basado en el mecanismo de autoatención.
Dada una secuencia de entrada token x1,x2,...,xn, la salida correspondiente es una secuencia idéntica y1,y2,...,yn. y se expresa como:
![]()
No entendí muy bien esta fórmula al principio. Sin embargo, combinado con la tarea específica de traducción de textos, es fácil de entender. El significado aquí es que un elemento en una determinada posición de un token corresponde a la entrada y salida. Es decir, el valor-clave es el propio elemento. Necesitamos aprender la función que construye la predicción del valor aprendiendo los pesos de cada palabra y todas las palabras en el token.
Cuando se trata de tokens, las operaciones secuenciales se abandonan debido a la necesidad de un cálculo paralelo de autoatención. Para usar información de secuencia, se pueden agregar codificaciones posicionales a la representación de entrada para inyectar información posicional absoluta o relativa. Al agregar una matriz de incrustación de posición de la misma forma a la matriz de entrada para lograr la codificación de posición absoluta , los elementos correspondientes a las filas y columnas se expresan como:
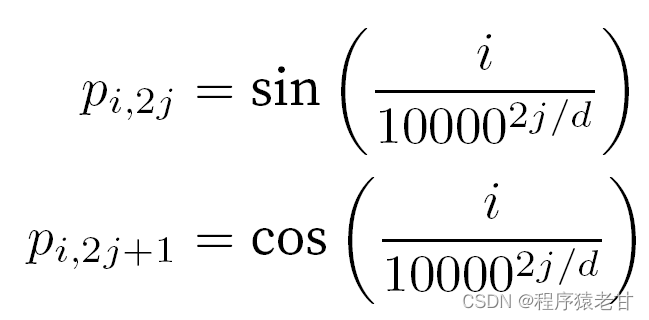
Esta representación basada en trigonometría de la incrustación posicional de los elementos de la matriz no es intuitiva. Solo sabemos que existe una relación entre la dimensión codificada y la frecuencia de las curvas impulsadas por las funciones trigonométricas. Es decir, la información de diferentes dimensiones dentro de cada unidad léxica tiene diferentes frecuencias de curvas de funciones trigonométricas correspondientes, como se muestra en la figura:
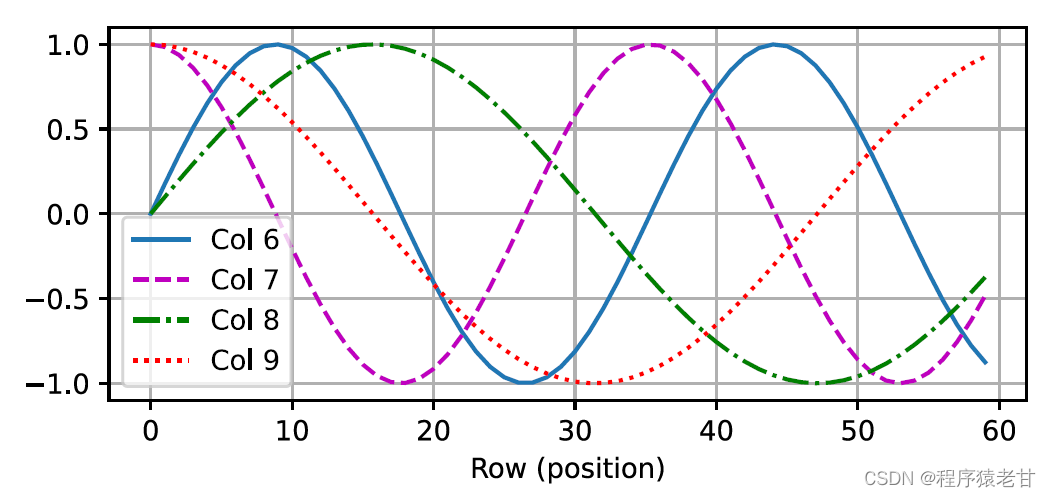
Parece que a medida que aumenta la dimensionalidad de cada lema, disminuye la frecuencia correspondiente a su intervalo. Para aclarar la relación entre este cambio de frecuencia y la posición absoluta, se utiliza aquí un ejemplo para explicar. Esto imprime la representación binaria de 0-7 (el mapa de calor de frecuencia está a la derecha):

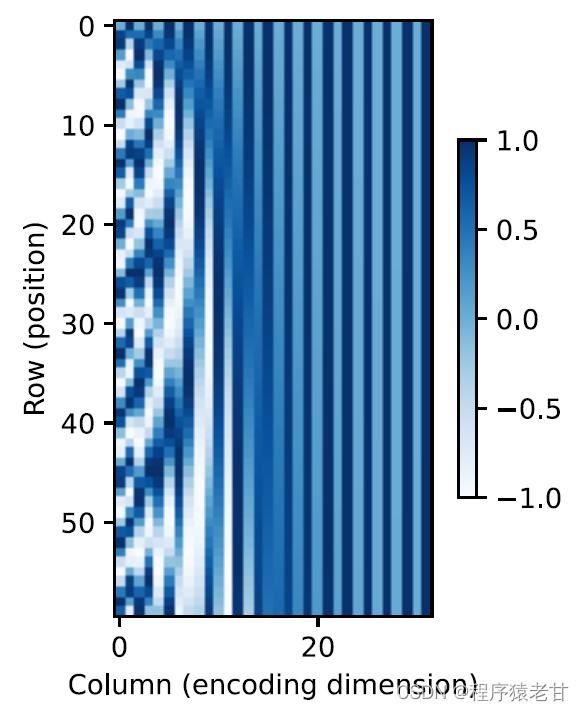
Aquí, los bits más altos se alternan con menos frecuencia que los bits más bajos. Mediante el uso de codificación posicional, se realiza la codificación de diferentes dimensiones de etimología basada en la transformación de frecuencia y luego se realiza la adición de información posicional. La codificación de posición relativa no se describirá en detalle aquí.
4. Modelo de transformador
¡Por fin es hora de emocionarse! Después de comprender el conocimiento anterior, hemos sentado las bases para aprender Transformer. En comparación con el modelo de autoatención anterior que todavía se basa en la red neuronal cíclica para realizar la representación de entrada, el modelo de Transformador se basa completamente en el mecanismo de autoatención sin ninguna capa convolucional o capa de red neuronal cíclica.
El modelo Transformer es una arquitectura de códec y el diagrama de arquitectura general es el siguiente:
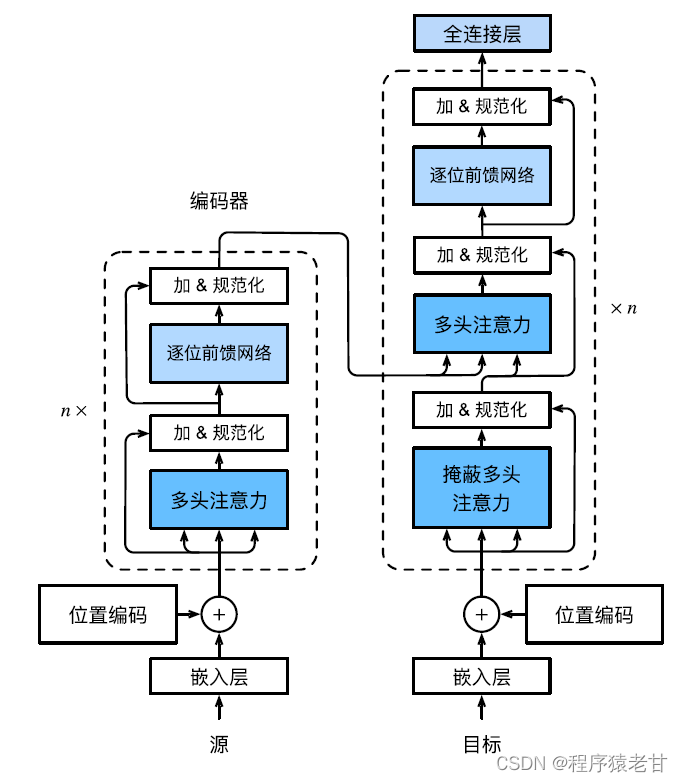
El transformador se compone de un codificador y un decodificador. Está construido sobre la base de un módulo de autoatención. La secuencia de origen (entrada) y la representación de incrustación de la secuencia de destino (salida) se agregarán con codificación posicional y luego se ingresarán al codificador y decodificador respectivamente. El codificador se construye apilando múltiples capas idénticas, cada una con dos subcapas. La primera subcapa es una agrupación de autoatención de varios cabezales, y la segunda subcapa es una red de realimentación basada en la posición. Las consultas, claves y valores calculados por la capa del codificador provienen de la salida de la capa anterior. Cada subcapa utiliza conexiones residuales. Al igual que el codificador , el decodificador también se compone de varias capas idénticas y utiliza conexiones residuales y normalización de capas. Además de las dos subcapas descritas en el codificador, el decodificador agrega una subcapa intermedia denominada capa de atención del codificador-decodificador. Las consultas en esta capa provienen de la salida de la capa del decodificador anterior, mientras que las claves y los valores provienen de la salida de todo el codificador. En la autoatención del decodificador, las consultas, las claves y los valores se derivan de la salida de la capa del decodificador anterior. Cada posición en el decodificador solo puede considerar todas las posiciones anteriores. Esta atención enmascarada conserva las propiedades autorregresivas, lo que garantiza que las predicciones solo dependan de los tokens de salida que se hayan generado. La implementación específica de diferentes módulos no se describirá en detalle.
Nota: La explicación del término anterior, la introducción del principio y la fórmula sobre el mecanismo de atención se refieren principalmente al libro de texto del maestro Li Mu [2].
Basado en el principio del mecanismo de atención mencionado anteriormente, se propone un modelo de aprendizaje profundo del mecanismo de atención para tareas de procesamiento de nubes de puntos. Presentaremos el trabajo relacionado en detalle en el próximo blog, bienvenido a seguir prestando atención a mi blog.
Referencia
[1] MH. Guo, TX, Xu, JJ. Liu, et al. Mecanismos de atención en visión artificial: una encuesta [J]. Medios visuales computacionales, 2022, 8(3): 331-368.
[2] A. Zhang, ZC. Lipton, M. Li y AJ. Smola. Inmersión en el aprendizaje profundo [B]. https://zh-v2.d2l.ai/d2l-zh-pytorch.pdf .
[3] EE. Nadaraya. Sobre la estimación de la regresión[J]. Teoría de la probabilidad y sus aplicaciones, 1964, 9(1): 141-142.
[4] SG. Watson. Análisis de regresión suave. Sankhyā: The Indian Journal of Statistics, serie A, págs. 359-372.
[5] A. Vaswani, N. Shazeer, N. Parmar, et al. La atención es todo lo que necesitas. Avances en los sistemas de procesamiento de información neuronal, 2017,5998-6008.