Resumen: Cuando el rendimiento del operador o de la red es deficiente, se puede utilizar AOE para la sintonización. Este artículo lo llevará a comprender la herramienta de ajuste automático AOE, para que su modelo pueda ejecutarse de manera eficiente en la plataforma Ascend.
Este artículo se comparte desde Huawei Cloud Community " Herramienta de ajuste automático AOE, permita que su modelo se ejecute de manera eficiente en la plataforma Shengteng ", autor: Shengteng CANN.
¿Qué son los AOE?
AOE (Ascend Optimization Engine) es una herramienta de ajuste automático diseñada para aprovechar al máximo los recursos de hardware limitados y cumplir con los requisitos de rendimiento de los operadores y de toda la red.
AOE itera continuamente a través del mecanismo de retroalimentación de circuito cerrado para generar estrategias de ajuste, compilar y verificar en el entorno operativo, y finalmente obtiene la mejor estrategia de ajuste, para aprovechar al máximo los recursos de hardware y mejorar el rendimiento de la red.
La estructura de AOE es la siguiente.

Capa de aplicación : entrada de ajuste, el soporte es el siguiente.
- AOE: AOE aquí significa el proceso AOE, que es la entrada de ajuste para escenarios de inferencia fuera de línea.
- TFAdapter (adaptador de TensorFlow): la entrada de ajuste para los escenarios de entrenamiento de TensorFlow.
- PyTorchAdapter (adaptador de PyTorch): la entrada de ajuste para los escenarios de entrenamiento de PyTorch.
Capa de sintonización : modo de sintonización, admite los siguientes tipos.
- SGAT (Sintonización automática de subgráficos): sintonización de subgráficos. Una red completa se dividirá en varios subgrafos. Para cada subgráfico, SGAT genera diferentes estrategias de ajuste. El algoritmo de ajuste de SGAT encuentra la estrategia de ajuste óptima al obtener los datos de rendimiento de la estrategia de ajuste de cada iteración, para lograr el rendimiento óptimo del subgráfico correspondiente.
- OPAT (Operator Auto Tuning): sintonización del operador. AOE ingresa una imagen completa a OPAT, y OPAT realiza la fusión de operadores, divide la imagen fusionada en granularidad de operadores y genera diferentes estrategias de optimización de operadores para cada subgráfico de operadores fusionados, a fin de lograr un rendimiento óptimo del operador.
- GDAT (Gradient Auto Tuning): ajuste de gradiente. En el escenario de entrenamiento distribuido, GDAT maximiza el paralelismo del cálculo inverso y la comunicación de agregación de gradientes, acorta el tiempo de espera de la comunicación y mejora el rendimiento del entrenamiento de clúster.
Capa de ejecución : es la capa de ejecución, que admite la compilación (Compiler) y la ejecución en el entorno de tiempo de ejecución (Runner).
Cómo funciona AOE
A continuación, se utiliza el ajuste del operador como ejemplo para presentar el principio de funcionamiento de AOE.
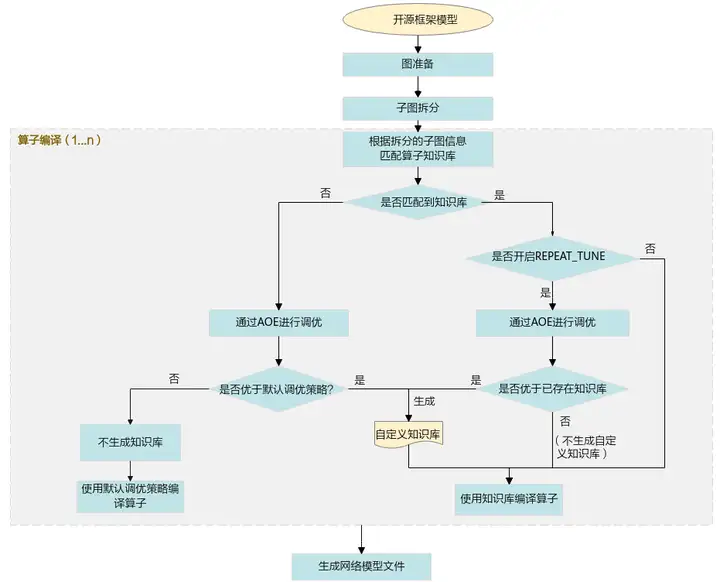
1. Importe el modelo de marco de código abierto original a GE y FE para la preparación de gráficos (InferShape, selección de operadores, etc.) y división de subgráficos.
2. Ingrese a la etapa de compilación del operador y haga coincidir la base de conocimiento de acuerdo con la información del subgráfico dividido.
Si puede coincidir con la base de conocimiento:
- En el escenario donde REPEAT_TUNE no está habilitado, use directamente la estrategia de ajuste en la base de conocimiento existente para compilar el operador.
- Encienda la escena de REPEAT_TUNE y ajústela a través de AOE.
Si el resultado ajustado es mejor que la base de conocimiento existente, el resultado ajustado se almacenará en la base de conocimiento definida por el usuario y el operador se compilará utilizando la estrategia de ajuste en la base de conocimiento personalizada.
Si el resultado del ajuste no es mejor que la base de conocimiento existente, no se generará ninguna base de conocimiento definida por el usuario y la base de conocimiento existente se usará para compilar operadores directamente.
Si no coincide con la base de conocimientos, se ajustará a través de AOE.
- Si el resultado ajustado es mejor que el rendimiento de la estrategia de ajuste predeterminada, el resultado ajustado se escribirá en la base de conocimiento personalizada y el operador se compilará utilizando la estrategia de ajuste en la base de conocimiento personalizada.
- Si el resultado del ajuste no es mejor que el rendimiento de la estrategia de ajuste predeterminada, no se genera una base de conocimientos personalizada y se usa la estrategia de ajuste predeterminada para compilar el operador.
3. En el escenario de inferencia, una vez completada la compilación, se genera un archivo de modelo fuera de línea adaptado al procesador Ascend AI. En el escenario de entrenamiento, una vez completada la compilación, se genera un archivo de modelo de red entrenado.
Escenarios de uso de AOE
Cuando el rendimiento del operador o de la red es deficiente, se puede utilizar AOE para el ajuste. Los escenarios admitidos por el ajuste AOE son los siguientes:
- razonamiento sin conexión
- Entrenamiento TensorFlow
- Entrenamiento PyTorch
- razonamiento en línea
- composición de infrarrojos
¿Cómo usar AOE para afinar?
A continuación se utiliza la optimización del operador de la red Caffe en el escenario de inferencia fuera de línea como ejemplo para presentar cómo realizar la optimización AOE.
1. Prepare el archivo del modelo.
2. Configure las variables de entorno.
Variable de entorno obligatoria
- El paquete CANN proporciona un script de configuración de variables de entorno a nivel de proceso para que los usuarios hagan referencia en el proceso para completar automáticamente la configuración de variables de entorno. Ejecute el comando como referencia de la siguiente manera. Los siguientes ejemplos son las rutas de instalación predeterminadas para usuarios root o no root. Consulte la ruta de instalación real.
# 以root用户安装toolkit包
/usr/local/Ascend/ascend-toolkit/set_env.sh
# 以非root用户安装toolkit包
${HOME}/Ascend/ascend-toolkit/set_env.sh- La herramienta AOE depende de Python. Tomando Python3.7.5 como ejemplo, ejecute los siguientes comandos como el usuario que ejecuta para configurar las variables de entorno relevantes de Python3.7.5.
#用于设置python3.7.5库文件路径
export LD_LIBRARY_PATH=/usr/local/python3.7.5/lib:$LD_LIBRARY_PATH
#如果用户环境存在多个python3版本,则指定使用python3.7.5版本
export PATH=/usr/local/python3.7.5/bin:$PATHvariables de entorno opcionales
export ASCEND_DEVICE_ID=1
export TUNE_BANK_PATH=/home/HwHiAiUser/custom_tune_bank
export TE_PARALLEL_COMPILER=7
export REPEAT_TUNE=True
命令中的参数含义如下。- ASCEND_DEVICE_ID: ID lógico del procesador Ascend AI.
- TUNE_BANK_PATH: la ruta de almacenamiento de la base de conocimientos personalizada después de la optimización.
- TE_PARALLEL_COMPILER: Habilita la función de compilación paralela del operador.
- REPEAT_TUNE: si se reinicia la afinación.
3. Para realizar el ajuste AOE, el comando es el siguiente. Los directorios y archivos utilizados en los comandos son ejemplos, consulte la situación real.
aoe --framework=0 --model=$HOME/module/resnet50.prototxt --weight=$HOME/module/resnet50.caffemodel --job_type=2Los significados de los parámetros en el comando son los siguientes.
- framework: El tipo de framework del modelo de red original. 0 significa Café.
- modelo: ruta del archivo del modelo original y nombre del archivo.
- peso: la ruta del archivo de peso del modelo original y el nombre del archivo.
- job_type: Modo de sintonización, 2 significa sintonización del operador.
4. Si se muestra la siguiente información, significa que se completó el ajuste de AOE.
Aoe process finishedUna vez completada la sintonización, los archivos generados son los siguientes.
- Base de conocimiento personalizada: Si se cumplen las condiciones para generar una base de conocimiento personalizada, se generará una base de conocimiento personalizada.
- archivo de modelo om, la ruta de almacenamiento es:
${WORK_PATH}/aoe_workspace/${model_name}_${timestamp}/tunespace/result/${model_name}_${timestamp}_tune.om
${WORK_PATH}:调优工作目录
${model_name}:模型名称
${timestamp}:时间戳- Archivo de resultados del ajuste del operador: un archivo denominado "aoe_result_opat_{timestamp}_{pid xxx }.json" se genera en tiempo real en el directorio de trabajo donde se realiza el ajuste y registra la información del operador sintonizado durante el ajuste. Los ejemplos son los siguientes.
"basic": {
"tuning_name": "调优任务名",
"tuning_time(s)": 1827
}
"OPAT": {
"model_baseline_performance(ms)": 113.588725,
"model_performance_improvement": "0.31%",
"model_result_performance(ms)": 113.236731,
"opat_tuning_result": "tuning successful",
"repo_modified_operators": {
"add_repo_operators": [
{
"op_name": "strided_slice_10",
"op_type": "stridedsliced",
……
"repo_summary": {
"repo_add_num": 2,
"repo_hit_num": 17,
"repo_reserved_num": 15,
"repo_unsatisfied_num": 0,
"repo_update_num": 2,
"total_num": 19
}5. Una vez completada la optimización, utilice la base de conocimiento personalizada ajustada para volver a razonar y verificar si el rendimiento ha mejorado.
Lo anterior es una breve introducción a AOE. Para obtener más contenido, puede verlo en el Centro de documentación de Shengteng , y también puede estudiar cursos en video en la sección " Curso en línea de la comunidad de Shengteng ". Si tiene alguna pregunta durante el proceso de aprendizaje, puede interactuar y comunicarse en el " Shengteng Community Course". Foro "!
Haga clic para seguir y conocer las nuevas tecnologías de Huawei Cloud por primera vez~