Autor: JD Logística Wang Beiyong Yao Zaiyi
1. Antecedentes
En el proceso de desarrollo diario, especialmente en el proceso DDD, a menudo se encuentra la conversión mutua de modelos de dominio como VO/MODEL/PO. En este punto, realizaremos set|get settings campo por campo. Utilice herramientas para realizar copias violentas de atributos. En el proceso de copia violenta de atributos, una buena herramienta puede mejorar la eficiencia de ejecución del programa, de lo contrario, provocará situaciones extremas como bajo rendimiento y configuración de detalles ocultos OOM.
2 Tecnología existente
- Direct set|get method: está bien cuando hay pocos campos, pero cuando los campos son muy grandes, la carga de trabajo es enorme y las operaciones repetidas requieren mucho tiempo y mano de obra.
- Realice el mapeo de valor a través de la reflexión + la introspección: por ejemplo, muchas clases de herramientas apache-common, spring y hutool de código abierto proporcionan dichas herramientas de implementación. La desventaja de este método es el bajo rendimiento y la copia de propiedades de caja negra. El procesamiento de diferentes clases de herramientas es diferente: la copia de propiedad de Spring ignorará la conversión de tipos pero no informará un error, hutool realizará automáticamente la conversión de tipos y algunas configuraciones de herramientas arrojarán excepciones, etc. Hay problemas de producción y el posicionamiento es difícil.
- mapstruct: antes de usarlo, debe definir manualmente la interfaz del convertidor y generar automáticamente la clase de implementación de acuerdo con la anotación de la clase de interfaz y la anotación del método. La lógica de conversión de atributos es clara, pero las diferentes conversiones de objetos de dominio deben escribir una capa separada de interfaz de conversión o agregar un método de conversión.
3 Diseño extendido
3.1 Introducción a la estructura de mapa
Este componente de extensión se amplía en función de mapstruct e introduce brevemente el principio de implementación de mapstruct.
mapstruct se implementa en base a JSR 269, que es una especificación introducida por JDK. Con él, es posible procesar anotaciones en tiempo de compilación y leer, modificar y agregar contenido en el árbol de sintaxis abstracta. JSR 269 utiliza Annotation Processor para procesar anotaciones durante la compilación.Annotation Processor es equivalente a un complemento del compilador, por lo que también se denomina procesamiento de anotaciones de complemento.
Sabemos que el mecanismo de carga de clases de Java necesita pasar el tiempo de compilación y el tiempo de ejecución. Como se muestra abajo

mapstruct está en el proceso de compilar el código fuente durante el período de compilación anterior y, en segundo lugar, genera un código de bytes modificando el árbol de sintaxis, como se muestra en la figura a continuación.
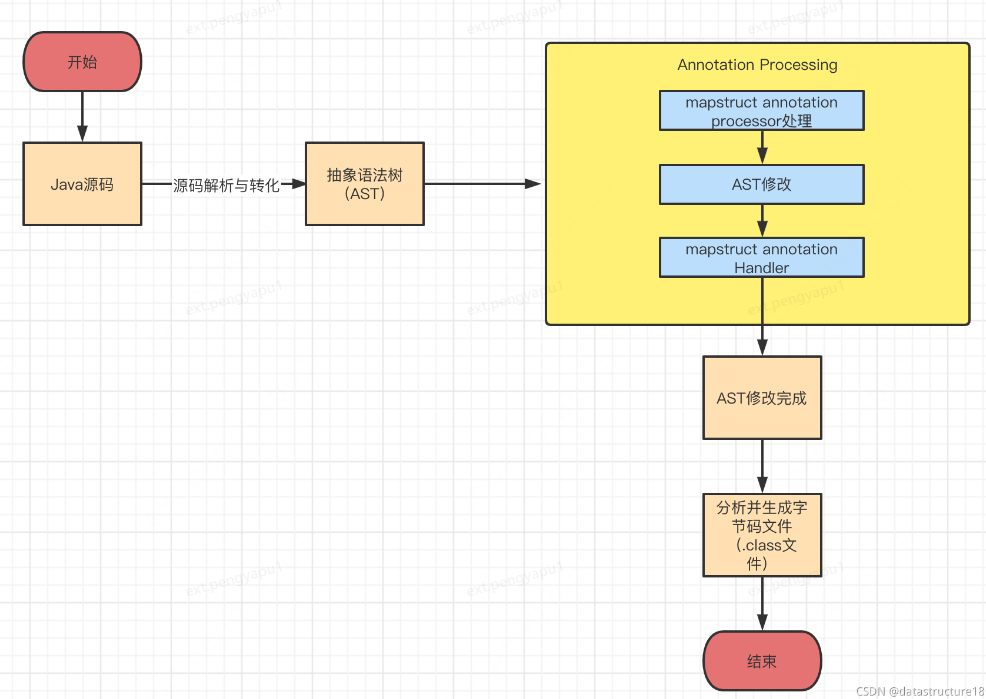
Los pasos anteriores se pueden resumir de la siguiente manera:
1. Genere un árbol de sintaxis abstracta. El compilador de Java compila el código fuente de Java y genera un árbol de sintaxis abstracta (Abstract Syntax Tree, AST).
2. Llame al programa que implementa la API JSR 269. Siempre que el programa implemente la API JSR 269, el procesador de anotaciones implementado se invocará durante la compilación.
3. Modifique el árbol de sintaxis abstracta. En el programa que implementa la API JSR 269, puede modificar el árbol de sintaxis abstracta e insertar su propia lógica de implementación.
4. Generar código de bytes. Después de modificar el árbol de sintaxis abstracta, el compilador de Java generará un archivo de código de bytes correspondiente al árbol de sintaxis abstracta modificado.
Desde la perspectiva del principio de implementación de mapstruct, encontramos que la lógica de conversión de atributos de mapstruct es clara y tiene buena escalabilidad. El problema es que es necesario escribir una interfaz de conversión separada o agregar un método de conversión. ¿Se puede ampliar automáticamente la interfaz o el método de conversión?
3.2 Plan de mejora
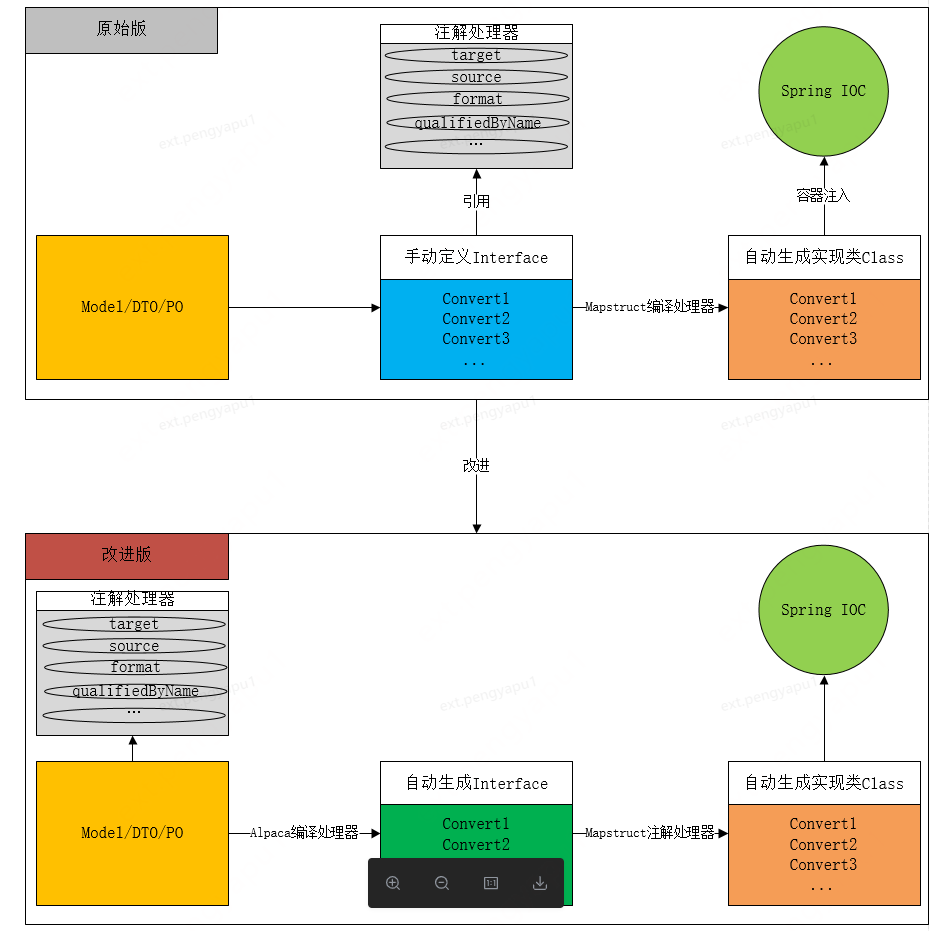
El esquema mapstruct mencionado anteriormente tiene un inconveniente. Es decir, si hay una nueva conversión de modelo de dominio, tenemos que escribir manualmente una capa de interfaz de conversión.Si hay una conversión entre modelos A/B, generalmente es necesario definir cuatro métodos: A->B, B- >A, Lista<A >->Lista<B>, Lista<B>->Lista<A>
En vista de esto, esta solución define el mapstruct original en la anotación de la clase de interfaz de conversión y la anotación del método de conversión, y forma una nueva anotación de empaquetado a través del mapeo. Defina esta anotación directamente en la clase o el campo del modelo, y luego genere la interfaz de conversión directamente en el momento de la compilación de acuerdo con la anotación personalizada en el modelo, y luego mapstruct genera la clase de implementación de conversión específica nuevamente de acuerdo con la interfaz generada automáticamente.
Nota: Las anotaciones de las clases y métodos en la interfaz generada automáticamente son las anotaciones del mapstruct original, por lo que las funciones originales del mapstruct no se pierden. El ajuste detallado es el siguiente:
4 realización
4.1 Dependencia tecnológica
- Procesador de anotaciones en tiempo de compilación AbstractProcessor: Annotation Processor es equivalente a un complemento del compilador, por lo que también se denomina procesamiento de anotaciones de complementos. Para lograr JSR 269, existen principalmente los siguientes pasos .
1) Herede la clase AbstractProcessor, reescriba el método de proceso e implemente su propia lógica de procesamiento de anotaciones en el método de proceso.
2) Cree un archivo javax.annotation.processing.Processor en el directorio META-INF/services para registrar su propia implementación
2. Google AutoService: AutoService es una biblioteca de código abierto creada por Google para facilitar la generación de una biblioteca de código abierto que cumpla con la especificación ServiceLoader, es muy fácil de usar. Solo necesita agregar anotaciones para generar automáticamente archivos de restricciones de especificación.
Punto de conocimiento: la ventaja de usar AutoService es que nos ayuda a no mantener manualmente el directorio de archivos META-INF y el contenido del archivo requerido por Annotation Processor. Se producirá automáticamente para nosotros, y el método de uso es muy simple, simplemente agregue las siguientes anotaciones a la clase de procesador de anotaciones personalizada @AutoService (Processor.class)
- mapstruct: ayude a implementar la interfaz de conversión generada automáticamente por el complemento personalizado e inyéctela en el contenedor de primavera (descrito en la solución existente).
- javapoet: JavaPoet es una biblioteca de código abierto para generar código de forma dinámica. Ayúdenos a generar archivos de clase java de manera fácil y rápida. Las características principales son las siguientes:
1) JavaPoet es una dependencia de terceros que puede generar automáticamente archivos Java.
2) API simple y fácil de entender, fácil de usar.
3) Genere automáticamente archivos Java complejos y repetitivos para mejorar la eficiencia del trabajo y simplificar el proceso.
4.2 Pasos de implementación
- Paso 1: Genere automáticamente la enumeración requerida para convertir la clase de interfaz, anote respectivamente la clase AlpacaMap y el campo AlpacaMapField.
1) AlpacaMap: definido en la clase, el atributo target especifica el modelo de destino que se convertirá; el atributo uses especifica los objetos externos de los que depende el proceso de conversión de Alpaca.
2) AlpacaMapField: realice un ajuste de alias para todas las anotaciones admitidas por el mapstruct original y use la anotación AliasFor proporcionada por Spring.
Puntos de conocimiento: @AliasFor es una anotación del marco Spring, que se usa para declarar el alias del atributo de anotación. Tiene dos escenarios de aplicación diferentes:
Alias en anotaciones
Alias de metadatos
La principal diferencia entre los dos es si están en la misma anotación.
- Paso 2: Implementación de AlpacaMapMapperDescriptor. La función principal de esta clase es cargar todas las clases del modelo que usan el primer paso para definir la enumeración y luego guardar la información de la clase y la información del campo de la clase para su uso directo más adelante. La lógica del fragmento es la siguiente:
AutoMapFieldDescriptor descriptor = nuevo AutoMapFieldDescriptor();
descriptor.target = fillString(alpacaMapField.target());
descriptor.dateFormat = fillString(alpacaMapField.dateFormat());
descriptor.numberFormat = fillString(alpacaMapField.numberFormat());
descriptor.constant = fillString(alpacaMapField.constant());
descriptor.expression = fillString(alpacaMapField.expression());
descriptor.defaultExpression = fillString(alpacaMapField.defaultExpression());
descriptor.ignorar = alpacaMapField.ignorar();
..........
- Paso 3: la clase AlpacaMapMapperGenerator genera principalmente información de clase correspondiente, anotaciones de clase, métodos de clase e información de anotación sobre métodos a través de JavaPoet
Información de clase generada: TypeSpec createTypeSpec(AlpacaMapMapperDescriptor descriptor)
Información de anotación de clase generada AnnotationSpec buildGeneratedMapperConfigAnnotationSpec(AlpacaMapMapperDescriptor descriptor) {
Información de método de clase generada: MethodSpec buildMappingMethods(AlpacaMapMapperDescriptor descriptor)
Información de anotación de método generada: List<AnnotationSpec> buildMethodMapperMapperDescriptorAnnotation(AlpacaMap descriptor)
En el proceso de realización de la información de clase generada, es necesario especificar la clase de interfaz AlpacaBaseAutoAssembler de la clase generada.Esta clase define principalmente cuatro métodos de la siguiente manera:
interfaz pública AlpacaBaseAutoAssembler<S,T>{
Copia T (fuente S);
por defecto List<T> copyL(List<S> source){
return sources.stream().map(c->copy(c)).collect(Collectors.toList());
}
@InheritInverseConfiguration(nombre = "copiar")
S reverseCopy(T fuente);
por defecto List<S> reverseCopyL(List<T> source){
return sources.stream().map(c->reverseCopy(c)).collect(Collectors.toList());
}
}
- Paso 4: porque el convertidor de clase generado se inyecta en el contenedor de primavera. Por lo tanto, es necesario agregar una anotación que genere específicamente la inyección de mapstruct en el contenedor de primavera. Esta anotación se genera automáticamente a través de la clase AlpacaMapSpringConfigGenerator. El código central es el siguiente
private AnnotationSpec buildGeneratedMapperConfigAnnotationSpec() {
return AnnotationSpec.builder(ClassName.get("org.mapstruct", "MapperConfig"))
.addMember("componentModel", "$S", "spring")
.build();
}
- Paso 5: a través de los pasos anteriores, hemos definido clases relacionadas, métodos de clases relacionadas, anotaciones de clases relacionadas y anotaciones de métodos de clases relacionadas. En este momento, únalos para generar la salida del archivo de clase a través del Procesador de anotaciones. El método principal es el siguiente
private void writeAutoMapperClassFile(AlpacaMapMapperDescriptor descriptor){
System.out.println("开始生成接口:"+descriptor.sourcePackageName() + "."+ descriptor.mapperName());
pruebe (final Writer outputWriter =
procesamientoEnv
.getFiler()
.createSourceFile( descriptor.sourcePackageName() + "."+ descriptor.mapperName())
.openWriter()) {
alpacaMapMapperGenerator.write(descriptor, outputWriter);
} captura (IOException e) {
procesamientoEnv
.getMessager()
.printMessage( ERROR, "Error al abrir "+ descriptor.mapperName() + " archivo de salida:
}
}
Puntos de conocimiento: en javapoet, la clase principal primero tiene unas pocas clases, a las que se puede hacer referencia de la siguiente manera:
JavaFile se usa para construir y generar un archivo Java que contiene una clase de nivel superior, que es una definición abstracta de un archivo .java
TypeSpec TypeSpec es el tipo abstracto de una clase/interfaz/enumeración
MethodSpec MethodSpec es una definición abstracta de un método/constructor
FieldSpec FieldSpec es una definición abstracta de una variable/campo miembro
ParameterSpec ParameterSpec se utiliza para crear parámetros de método
AnnotationSpec AnnotationSpec se utiliza para crear anotaciones de marcador
5 práctica
El siguiente es un ejemplo para ilustrar cómo usarlo. Aquí definimos un modelo Persona y un modelo Estudiante, que involucran cadenas ordinarias, enumeraciones, formato de tiempo y reemplazo de tipo complejo de conversiones de campo. Los pasos específicos son los siguientes.
5.1 Introducción de dependencias
El código se ha subido a la base de código. Si necesita requisitos específicos, puede volver a extraer la rama y empaquetarla para su uso.
<dependencia>
<groupId>com.jdl</groupId>
<artifactId>alpaca-mapstruct-processor</artifactId>
<version>1.1-SNAPSHOT</version>
</dependency>
5.2 Definición de objetos
El método uses debe ser un bean en un contenedor Spring normal. Este bean proporciona un método de anotación @Named para anotaciones de campo de clase. El atributo addedByName en AlpacaMapField se puede especificar como una cadena, como se muestra en la figura a continuación.
@Data
@AlpacaMap(targetType = Student.class,uses = {Person.class})
@Service
public class Person {
private String make;
tipo SexType privado;
@AlpacaMapField(objetivo = "edad")
private Integer sax;
@AlpacaMapField(target="dateStr" ,dateFormat = "yyyy-MM-dd")
private Fecha fecha;
@AlpacaMapField(target = "brandTypeName",qualifiedByName ="convertBrandTypeName")
private Integer brandType;
@Named("convertBrandTypeName")
public String convertBrandTypeName(Integer brandType){
return BrandTypeEnum.getDescByValue(brandType);
}
@Nombrado("
public Integer convertBrandType(String brandTypeName){
return BrandTypeEnum.getValueByDesc(brandTypeName);
}
}
5.3 Generación de resultados
Use maven para empaquetar o compilar y observar. En este momento, se generan dos archivos PersonToStudentAssembler y PersonToStudentAssemblerImpl en el directorio target/generated-source/annotatins
El anotador personalizado genera automáticamente el archivo de clase PersonToStudentAssembler, el contenido es el siguiente
@Mapper(
config = AutoMapSpringConfig.class,
uses = {Person.class}
)
public interface PersonToStudentAssembler extends AlpacaBaseAutoAssembler<Persona, Estudiante> {
@Override
@Mapping(
destino = "edad",
fuente = "sax",
ignorar = falso
)
@ Mapping(
target = "dateStr",
dateFormat = "yyyy-MM-dd",
source = "date",
ignore = false
)
@Mapping(
target = "brandTypeName",
source = "brandType",
ignore = false,
qualifiedByName = " convertirNombreTipoMarca"
)
Copia del estudiante (fuente de la persona final);
}
Mapstruct genera automáticamente PersonToStudentAssemblerImpl de acuerdo con el anotador de la interfaz PersonToStudentAssembler, el contenido es el siguiente
@Component
public class PersonToStudentAssemblerImpl implements PersonToStudentAssembler {
@Autowired
private Person person;
@Override
public Person reverseCopy(Estudiante arg0) {
if ( arg0 == null ) {
return null;
}
Persona persona = nueva Persona();
persona.setSax( arg0.getEdad() );
pruebe {
if ( arg0.getDateStr() != null ) {
person.setDate( new SimpleDateFormat( "yyyy-MM-dd" ).parse( arg0.getDateStr() ) );
}
} catch ( ParseException e ) {
throw new RuntimeException ( e );
}
persona.setBrandType( persona.convertBrandType( arg0.getBrandTypeName() ) );
persona.setMake( arg0.getMake() );
persona.setType( arg0.getType() );
persona de retorno;
}
@Override
public Student copy(Person source) {
if ( source == null ) {
return null;
}
Estudiante estudiante = nuevo Estudiante();
estudiante.setEdad( fuente.getSax() );
if ( source.getDate() != null ) {
estudiante.setDateStr( new SimpleDateFormat( "yyyy-MM-dd" ).format( source.getDate() ) );
}
estudiante.setBrandTypeName( person.convertBrandTypeName( source.getBrandType() ) );
estudiante.setMake( fuente.getMake() );
estudiante.setType( fuente.getType() );
estudiante de regreso;
}
}
5.4 Referencia del contenedor de resorte
En este momento, en nuestro contenedor de primavera, @Autowired puede introducir directamente la instancia de interfaz PersonToStudentAssembler para realizar cuatro tipos de conversión de datos de mantenimiento
AnnotationConfigApplicationContext applicationContext = new AnnotationConfigApplicationContext();
applicationContext.scan("com.jdl.alpaca.mapstruct");
applicationContext.refresh();
PersonToStudentAssembler personToStudentAssembler = applicationContext.getBean(PersonToStudentAssembler.class);
Persona persona = nueva Persona();
persona.setMake("hacer");
persona.setType(SexType.BOY);
persona.setSax(100);
persona.setDate(nueva Fecha());
persona.setBrandType(1);
Estudiante estudiante = personToStudentAssembler.copy(person);
System.out.println(estudiante);
System.out.println(personToStudentAssembler.reverseCopy(estudiante));
List<Person> personList = Lists.newArrayList();
listaPersonas.add(persona);
System.out.println(personToStudentAssembler.copyL(personList));
System.out.println(personToStudentAssembler.reverseCopyL(personToStudentAssembler.copyL(personList)));
Impresiones de la consola:
personToStudentStudent(make=make, type=BOY, age=100, dateStr=2022-11-09, brandTypeName=集团KA) studentToPersonPerson(make=make, type=BOY, sax=100, date=Wed Nov 09 00:00: 00 CST 2022, brandType=1) personListToStudentList[Student(make=make, type=BOY, age=100, dateStr=2022-11-09, brandTypeName=集团KA)] studentListToPersonList[Persona(make=make, type=BOY, sax=100, fecha=miércoles 09 de noviembre 00:00:00 CST 2022, brandType=1)]
Darse cuenta:
- El atributo de anotaciónqualifiedByName no es fácil de usar.Si se usa este atributo, se debe definir una función de conversión de tipo de inversión. Debido a que la interfaz abstracta AlpacaBaseAutoAssembler que definimos anteriormente tiene una anotación como se muestra en la figura a continuación, el mapeo inverso del objeto de destino al objeto de origen, debido a la sobrecarga de Java, el mismo nombre y diferentes referencias no son el mismo método, por lo que cuando S se transfiere a T, se recuperará. Este método no está disponible. Por lo tanto, debe definir su propia función de conversión.
@InheritInverseConfiguration(nombre = "copiar")
Por ejemplo, al convertir de S a T, se utilizará el primer método. Al convertir de T a S, se debe definir un método con la misma anotación Named.
@Named("convertBrandTypeName")
public String convertBrandTypeName(Integer brandType){
return BrandTypeEnum.getDescByValue(brandType);
}
@Named("convertBrandTypeName")
public Integer convertBrandType(String brandTypeName){
return BrandTypeEnum.getValueByDesc(brandTypeName);
}
- Cuando se usa la anotaciónqualifiedByName, el método de anotación Named especificado debe definirse como un objeto que puede ser administrado por el contenedor Spring, y esta clase de objeto debe introducirse a través del atributo de anotación de clase de modelo utilizado
Puntos de conocimiento:
InheritInverseConfiguration es muy poderoso y se puede mapear inversamente. Del PersonToStudentAssemblerImpl anterior, podemos ver que el atributo anterior sax se puede mapear a sex, y el mapeo inverso se puede mapear automáticamente de sex a sax. Pero la @Mapping#expression, #defaultExpression, #defaultValue y #constant que se están mapeando serán ignoradas por el mapeo inverso. Además, el mapeo inverso de un campo puede anularse mediante ignorar, expresión o constante.
6. Conclusión
Documentos de referencia:
https://github.com/google/auto/tree/master/servicio
https://github.com/square/javapoet