Directorio de artículos
Hola a todos, hoy me gustaría compartir con ustedes un pequeño caso en el aprendizaje profundo de TensorFlow2.0.
Contenido del caso: hay 348 datos de muestra de temperatura, cada muestra tiene 8 valores propios y 1 valor objetivo, y se realiza una predicción de regresión para construir un modelo de red neuronal. El código completo y los datos se pueden obtener al final del artículo. Si te gusta, recuerda marcarlo y darle me gusta.
1. Adquisición de datos
Importe los archivos de biblioteca necesarios para obtener datos de temperatura
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import tensorflow as tf
# 使用keras建模方法
from tensorflow.keras import layers
import warnings
warnings.filterwarnings('ignore')
#(1)数据获取
filepath = 'C:\\...\\temps.csv'
features = pd.read_csv(filepath)
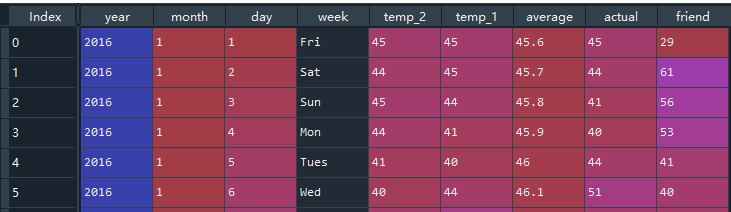
temp_2 representa la temperatura más alta anteayer, temp_1 representa la temperatura más alta ayer y el valor objetivo pronosticado es real
2. Visualización de datos
Para dibujar una curva de fecha y temperatura , primero debemos combinar las características año, mes y día en una cadena y luego convertirla en un tipo de datos de fecha y hora.
# 处理时间数据,将年月日组合在一起
import datetime
# 获取年月日数据
years = features['year']
months = features['month']
days = features['day']
# 将年月日拼接在一起--字符串类型
dates = [] # 用于存放组合后的日期
for year,month,day in zip(years,months,days):
date = str(year)+'-'+str(month)+'-'+str(day) #年月日之间用'-'向连接
dates.append(date)
# 转变成datetime格式
times = []
for date in dates:
time = datetime.datetime.strptime(date,'%Y-%m-%d')
times.append(time)
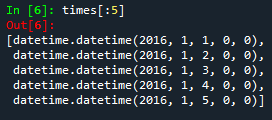
# 看一下前5行
times[:5]
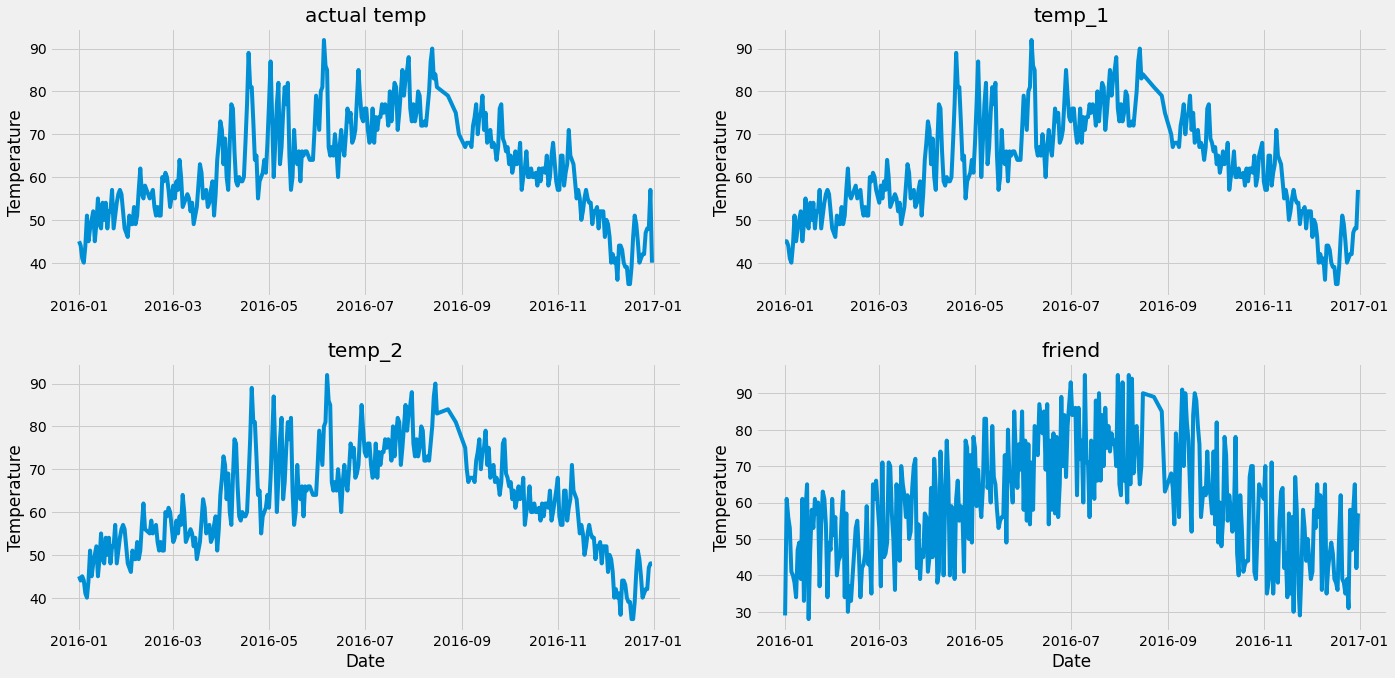
Después de procesar los datos del eje x, ahora dibujemos una curva para varias características
# 可视化,对各个特征绘图
# 指定绘图风格
plt.style.use('fivethirtyeight')
# 设置画布,2行2列的画图窗口,第一行画ax1和ax2,第二行画ax3和ax4
fig,((ax1,ax2),(ax3,ax4)) = plt.subplots(2,2,figsize=(20,10))
# ==1== actual特征列
ax1.plot(times,features['actual'])
# 设置x轴y轴标签和title标题
ax1.set_xlabel('');ax1.set_ylabel('Temperature');ax1.set_title('actual temp')
# ==2== 前一天的温度
ax2.plot(times,features['temp_1'])
# 设置x轴y轴标签和title标题
ax2.set_xlabel('');ax2.set_ylabel('Temperature');ax2.set_title('temp_1')
# ==3== 前2天的温度
ax3.plot(times,features['temp_2'])
# 设置x轴y轴标签和title标题
ax3.set_xlabel('Date');ax3.set_ylabel('Temperature');ax3.set_title('temp_2')
# ==4== friend
ax4.plot(times,features['friend'])
# 设置x轴y轴标签和title标题
ax4.set_xlabel('Date');ax4.set_ylabel('Temperature');ax4.set_title('friend')
# 轻量化布局调整绘图
plt.tight_layout(pad=2)
3. Procesamiento de características
Primero necesitamos dividir los valores propios y los valores objetivo. Extraiga los valores propios y los valores objetivo de los datos originales, y "real" almacena la temperatura más alta del día.
# 获取目标值y,从Series类型变成数组类型
targets = np.array(features['actual'])
# 获取特征值x,即在原数据中去掉目标值列,默认删除行,需要指定轴axis=1指向列
features = features.drop('axtual',axis=1)
# 把features从DateFrame变成数组类型
features = np.array(features)
Dado que hay datos de tipo de cadena en los valores propios, la columna 'semana' son todas las cadenas , por lo que debemos realizar una codificación en caliente en los valores propios para convertir el tipo de cadena en un tipo numérico .
# week列是字符串,重新编码,变成数值型
features = pd.get_dummies(features)

Después de procesar los datos de la cadena, todos los datos se vuelven numéricos. Para evitar el problema de la baja precisión del modelo debido a las diferentes unidades de datos y los intervalos grandes, los datos numéricos están estandarizados.
# 导入标准化方法库
from sklearn import preprocessing
input_features = preprocessing.StandardScaler().fit_transform(features)

En este punto, el procesamiento de los datos originales ha terminado y luego se construye el modelo de red neuronal.
4. Construya un modelo de red
Usamos el método de modelado keras, y los parámetros comúnmente utilizados son los siguientes:
activación: función de activación, generalmente elija relu
kernel_initializer, bias_initializer: el método de inicialización de los parámetros de peso y sesgo , a veces es mejor cambiar el método de inicialización si no converge
kernel_regularizer, bias_regularizer: regularización de pesos y sesgos
entradas: entrada
unidades: el número de neuronas
Referencia para todos los métodos de configuración de parámetros: Módulo: tf | TensorFlow Core v2.7.0 (google.cn)
(1) Construcción de red
Primero, importamos el modelo de secuencia de keras , tf.keras.Sequential() , y agregamos capas de red capa por capa en secuencia. Las capas representan diferentes niveles de implementación.
La cantidad de neuronas en cada capa oculta se puede cambiar a voluntad. Puede probarlo usted mismo. Necesitamos predecir la temperatura más alta aquí, por lo que solo se necesita una neurona en la capa de valor de salida. Los métodos de inicialización de peso son diferentes, puede encontrar el apropiado en el documento anterior.
# 构建层次
model = tf.keras.Sequential()
# 隐含层1设置16层,权重初始化方法设置为随机高斯分布,加入正则化惩罚项
model.add(layers.Dense(16,kernel_initializer='random_normal',kernel_regularizer=tf.keras.regularizers.l2(0.01)))
# 隐含层2设置32层
model.add(layers.Dense(32,kernel_initializer='random_normal',kernel_regularizer=tf.keras.regularizers.l2(0.01)))
# 输出层设置为1,即输出一个预测结果
model.add(layers.Dense(1,kernel_initializer='random_normal',kernel_regularizer=tf.keras.regularizers.l2(0.01)))
(2) Optimizador y función de pérdida
A continuación, debe especificar el optimizador y la función de pérdida model.compile() , donde el optimizador usa el descenso de gradiente y la función de pérdida usa el error cuadrático medio MSE. Todos tienen que elegir según sus propias tareas, y la elección de la función de pérdida tiene un gran impacto en los resultados de la red.
# 优化器和损失函数
model.compile(optimizer=tf.keras.optimizers.SGD(0.001),loss='mean_squared_error')
(3) Capacitación en red
Una vez completada la formulación, se puede iniciar el entrenamiento, la función de entrenamiento de red model.fit() . Valor de característica de entrada input_features, objetivos de valor objetivo, validation_split=0.25 significa que el conjunto de prueba se extrae de los datos de entrada con 0.25 para la prueba, epochs significa que el número de iteraciones es 100 y cada iteración tiene 128 muestras.
# ==3== 网络训练
model.fit(input_features,targets,validation_split=0.25,epochs=100,batch_size=128)
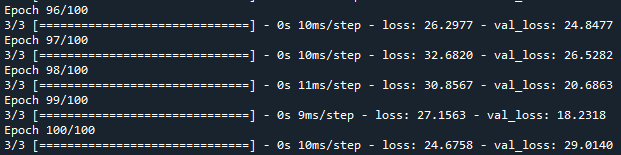
Volviendo a la pérdida de entrenamiento y la pérdida de prueba, se puede ver que después de 100 iteraciones, la pérdida del conjunto de entrenamiento de 24.675 y la pérdida del conjunto de prueba de 29.01 no son muy diferentes, lo que demuestra que no hay un fenómeno de sobreajuste . Si la pérdida del conjunto de entrenamiento es pequeña y la pérdida del conjunto de prueba es muy grande, significa que hay sobreajuste y es necesario ajustar los parámetros.
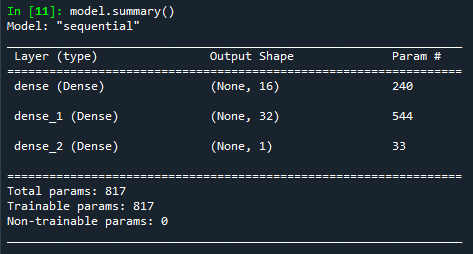
(4) Estructura del modelo de red
También podemos mirar la estructura del modelo de red que construimos, model.summary() , la capa oculta 1 tiene 240 parámetros, ¿cómo se calcula? La forma de la capa de entrada es [348, 14], con 14 características; la forma de la primera capa W totalmente conectada es [14, 16], 16 representa el número de características de la capa oculta 1 y la forma de la el parámetro de sesgo b es [ 1,16], y=Wx+b. Por tanto, el número de parámetros es 14*16+16=240.
(5) Resultados de la predicción
Función de predicción del modelo de red model.predict()
# ==5== 预测模型结果
predict = model.predict(input_features)
Hacemos predicciones para todas las muestras aquí para comparar la diferencia entre los resultados previstos y los resultados reales.
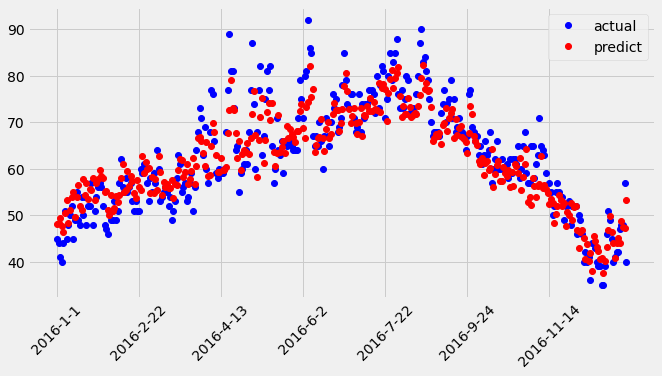
5. Visualización de resultados
Simplemente dibuje un gráfico de dispersión para ver, puede ver que los resultados pronosticados y los resultados reales son aproximadamente los mismos, con una ligera desviación. Los estudiantes interesados pueden realizar aún más la ingeniería de características y ajustar los parámetros para lograr mejores resultados.
# 真实值,蓝色实现
fig = plt.figure(figsize=(10,5))
axes = fig.add_subplot(111)
axes.plot(dates,targets,'bo',label='actual')
# 预测值,红色散点
axes.plot(dates,predict,'ro',label='predict')
axes.set_xticks(dates[::50])
axes.set_xticklabels(dates[::50],rotation=45)
plt.legend()
plt.show()
Código completo y datos
El código completo y los datos se han colocado en segundo plano, solo responda con una palabra clave
Si desea unirse al intercambio técnico, la mejor manera de comentar al agregar es: fuente + dirección de interés, que es conveniente para encontrar amigos de ideas afines
Método ①, Añadir ID de WeChat: dkl88191, Observaciones: de CSDN+ Método de temperatura
②, Número público de búsqueda de WeChat: aprendizaje de Python y extracción de datos, respuesta en segundo plano: temperatura