Hay muchas herramientas que se pueden usar para el modelado y la predicción de inteligencia artificial, como Python, R, SAS, SPSS, etc. Entre ellas, Python es muy popular debido a sus bibliotecas de ciencia de datos enriquecidas y fáciles de aprender, y libre. fuente abierta. Sin embargo, para los programadores que no están familiarizados con los algoritmos de modelado de datos, todavía es relativamente complicado usar Python para modelar, en muchos casos, no está claro qué hacer con los datos y qué algoritmo elegir. De hecho, SPL también es una buena opción para el análisis de datos y el modelado de datos. Es más simple y fácil de usar que Python, y la velocidad de cálculo es más rápida. La interfaz interactiva es muy amigable para el análisis de datos. También proporciona funciones automáticas de modelado de datos. y Algunas funciones estadísticas y de procesamiento de datos también son muy convenientes de usar.
Tomemos como ejemplo los datos de predicción de incumplimiento de préstamo de un usuario y usemos SPL para llevar a cabo la predicción de modelado de datos.
1. Identificar objetivos y preparar datos
Modelar y pronosticar consiste en extraer patrones de los datos históricos y luego usar los patrones para hacer predicciones sobre lo que puede suceder en el futuro. Esta ley se conoce generalmente como el modelo.
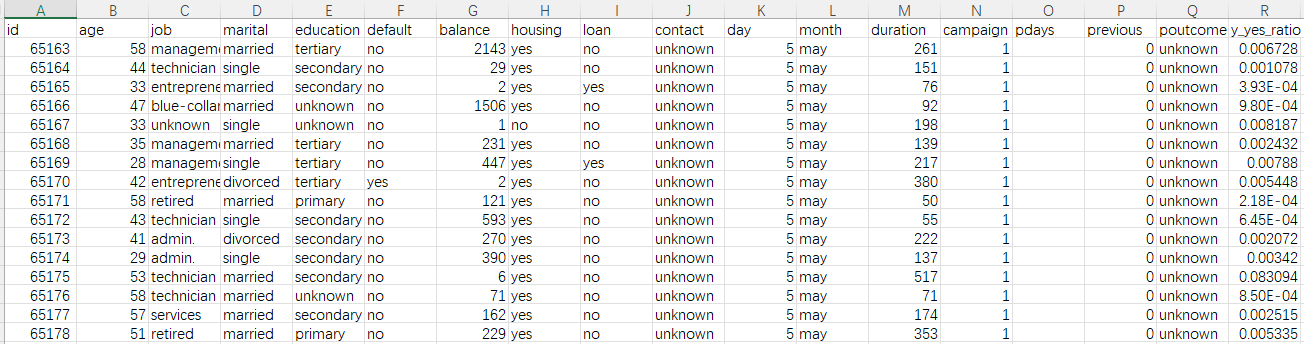
Los datos históricos suelen ser una tabla amplia. Por ejemplo, en el ejemplo de la predicción de incumplimiento de préstamo de usuario, los datos históricos son una tabla de Excel como la siguiente figura: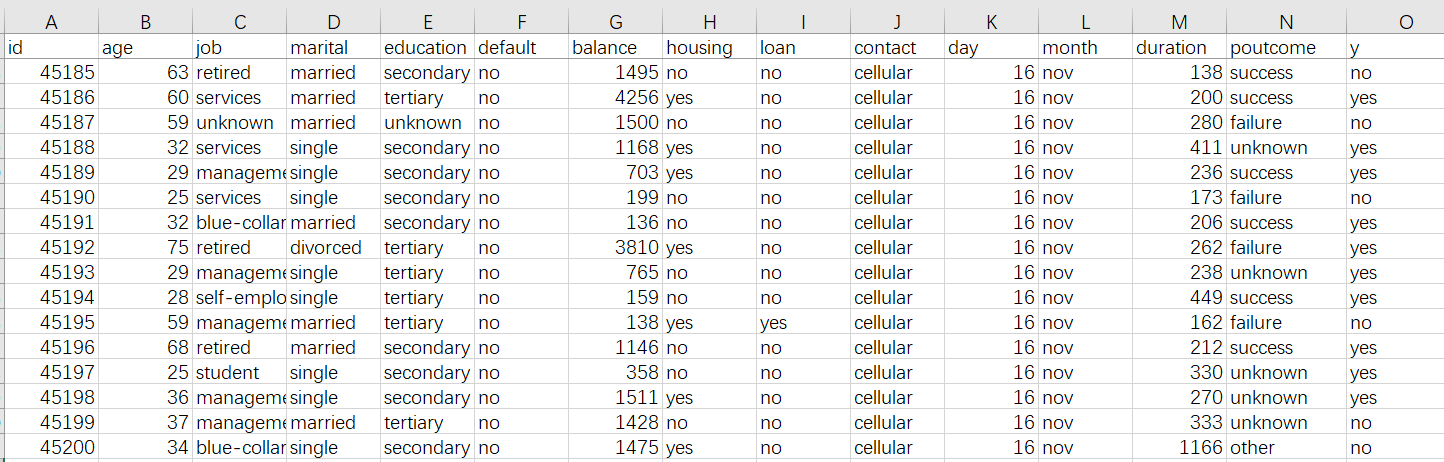
En primer lugar, la tabla ancha debe incluir lo que queremos predecir, que generalmente se denomina objetivo de predicción. El objetivo de predicción en la figura anterior es el comportamiento predeterminado de los usuarios históricos, es decir, la columna y en la figura, sí significa predeterminado, no significa que no hay predeterminado. El objetivo de pronóstico también puede ser un valor numérico, como ventas de productos, precio de venta, etc., o a qué tipo de pronóstico pertenece el pronóstico, como predecir si la calidad del producto es excelente, buena, calificada o deficiente. A veces, el objetivo existe en los datos originales y se puede usar directamente, y otras veces, el objetivo debe etiquetarse manualmente.
Además del objetivo de predicción, aquí se necesita mucha información, como la edad del usuario, el trabajo, los bienes raíces, la situación del préstamo en la tabla..., cada columna aquí se llama una variable, es decir, la información que puede estar relacionado con si el prestamista incumple en el futuro, el principio Cuantas más variables se puedan recopilar, mejor. Por ejemplo, para predecir si un cliente comprará un producto, puede recopilar información sobre el comportamiento del cliente, preferencias de compra e información sobre características del producto, promociones, etc.; para predecir el riesgo de reclamos de seguros de automóviles, necesita datos de pólizas, información del vehículo, hábitos de tráfico del propietario y estado histórico de reclamos, etc., si está pronosticando un seguro de salud, también necesita información sobre los hábitos de vida, las condiciones físicas y el tratamiento médico del asegurado; predecir las ventas de centros comerciales y supermercados requiere órdenes de venta históricas, información del cliente e información de productos básicos; predicción de malos productos, necesidad de producir parámetros de proceso, medio ambiente, materias primas y otros datos. En resumen, cuanta más información relevante se recopile, mejor será la predicción.
Al recopilar datos, generalmente interceptamos datos históricos de un período determinado para hacer una tabla amplia.Por ejemplo, si queremos predecir la situación de incumplimiento de los usuarios en julio, podemos recopilar datos de enero a junio para entrenar y construir un modelo. El intervalo de tiempo de recopilación de datos no es fijo y se puede operar de manera flexible, por ejemplo, puede ser de casi 1 año o casi 3 meses, etc.
La tabla ancha preparada puede estar en formato Excel o csv, la primera fila es el título y cada fila posterior es un registro histórico.
Si la empresa tiene un sistema de información bien construido, puede solicitar estos datos al departamento de TI, y muchas empresas pueden exportar directamente este tipo de datos en el sistema de BI.
2. Descargue el software y configure la biblioteca externa de modelado
SPL puede proporcionar funciones de predicción y modelado completamente automatizadas con la cooperación de la biblioteca externa de modelado de Yiming.
(1) Descargue e instale el software de modelado esProc (SPL) y Yiming
Descarga de esProc:
“http://c.raqsoft.com.cn/article/1595816810031”
Descarga de modelado de Yiming: "http://www.raqsoft.com.cn/download/download-ymodel"
Instale esProc y el software de modelado y registre el directorio de instalación, por ejemplo: C:\Program Files\raqsoft\ymodel
(2) Configurar bibliotecas externas en SPL
(a) Copie los archivos que necesita la biblioteca externa
Busque las carpetas YModelCil y lib en el directorio de instalación de Yiming Modeling
Luego vaya a estas dos carpetas para encontrar los archivos necesarios para modelar la biblioteca externa y cópielos en el directorio esProc ([directorio raíz de instalación]\esProc\extlib\YModelCil), como C:\Program Files\raqsoft\esProc\ extlib \YModelCli.
Los archivos necesarios para modelar bibliotecas externas son:
1>YModelCil en el directorio de modelado de Yiming contiene los siguientes archivos jar y xml
ant-1.8.2.jar
commons-beanutils.jar
commons-lang-2.6.jar
ezmorph-1.0.2.jar
json-lib-1.1-jdk13.jar
raq-ymodel-cli-2.10.jar
userconfig.xml
2> El modelo lib de Yiming contiene los siguientes frascos
commons-io-2.4.jar
esproc-ext-20211104.jar
fastjson-1.2.58.jar
gson-2.8.0.jar
jackson-annotations-2.9.6.jar
jackson-core-2.9.6.jar
jackson-databind- 2.9.6.jar
jackson-databind-2.9.6-sources.jar
jackson-dataformat-msgpack-0.8.14.jar
minería.jar
msgpack-0.6.12.jar
msgpack-core-0.8.16.jar
(b) Establecer los parámetros del archivo userconfig.xml
Establecer parámetros en el archivo userconfig.xml en el archivo esProc\extlib\YModelCil
| nombre | Descripción de parámetros |
| sAppInicio | El directorio de instalación de Yiming Modeling |
| spythonInicio | Ruta de Python del directorio de modelado de Yiming Windows: raqsoft\ymodel\Python37 Linux: raqsoft/ymodel/Python37/bin/python3.7 |
| iPythonServerPort | Puerto de red del servicio de Python |
| Número de proceso de iPython | Número de procesos de Python |
| bAutoDecideImputar | Ya sea para llenar el vacío de manera inteligente |
| iResampleMultiple | número de remuestreo |
Los parámetros que deben configurarse son sAppHome y sPythonHome, otros parámetros pueden usar los valores predeterminados y deben modificarse. Por ejemplo, puede configurar los parámetros de la siguiente manera: la parte en negrita debe configurarse de acuerdo con su propia ruta de instalación.
<?xml version="1.0" encoding="UTF-8"?>
<Config Version="1">
<Options>
<Option Name="sAppHome" Value="C:\Program Files\raqsoft\ymodel"/>
<Option Name="sPythonHome" Value="C:\Program Files\raqsoft\ymodel\Python37\python.exe"/>
<Option Name="iPythonServerPort" Value="8510"/>
<Option Name="iPythonProcessNumber" Value="2"/>
<Option Name="bAutoDecideImpute" Value="true"/>
<Option Name="iResampleMultiple" Value="150"/>
</Options>
</Config>
De hecho, se puede ver a partir de esto que el modelado de Yiming también está escrito en base a Python, pero después de encapsular el algoritmo de Python, el programador no necesita comprender el principio matemático y los detalles de operación del algoritmo.
(c) Configuración del entorno SPL
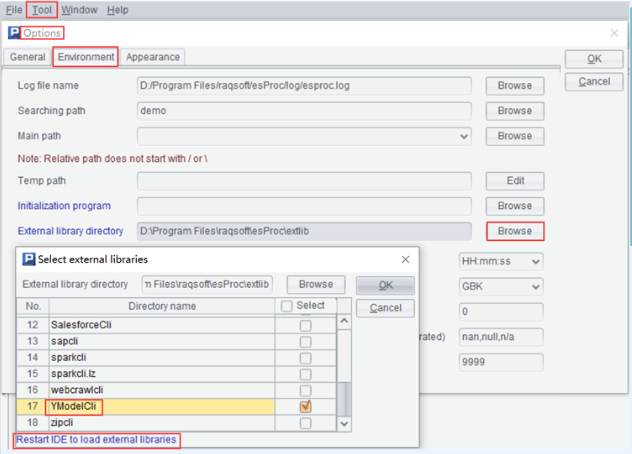
1> Configurar bibliotecas externas
Abra SPL, en el menú de opciones, marque YModelCli en la selección de biblioteca externa para que tenga efecto. La ruta de la biblioteca externa es la ruta de instalación de esProc YModelCli en el paso (1).
En el servidor sin GUI, vaya al archivo esProc\config\raqsoftConfig.xml en el directorio de instalación de esProc para configurar la ruta y el nombre de la biblioteca externa.
<extLibsPath>ruta de la biblioteca externa
<importLibs>Nombre de biblioteca externa (múltiple)
2> Configuración del número de hilo
Si hay una predicción concurrente, también debe establecer el "número paralelo máximo" en SPL, es decir, el número de subprocesos. Cuántos usuarios se pueden configurar según sus necesidades y las condiciones de la máquina.
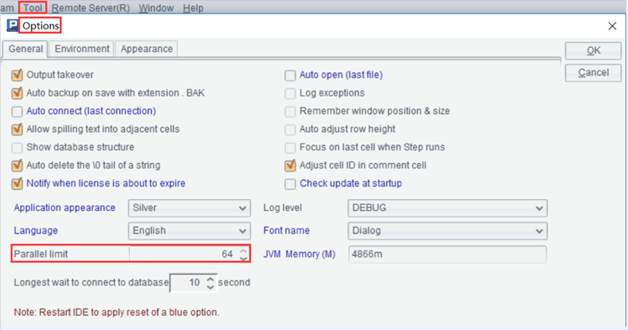
Vaya al archivo esProc\config\raqsoftConfig.xml en el directorio de instalación de esProc para la configuración en el servidor sin GUI.
<parallelNum>Número máximo de paralelos
En este punto, la configuración del entorno está completa.
3. Modelado y pronóstico
(1) Cargar datos
SPL puede admitir datos en csv, excel o base de datos para el modelado. Aquí tomamos csv como ejemplo, otras fuentes de datos son similares.
Dada la siguiente tabla de datos de incumplimiento de préstamo, se necesita un modelo para predecir si los nuevos usuarios incumplirán.
El archivo se llama bank-full.csv;
| A | |
| 1 | =archivo("banco-lleno.csv").import@tc() |
| 2 | =ym_env() |
| 3 | =ym_modelo(A2,A1) |
A1 Importar datos de modelado, leer en la tabla de pedidos

A2 inicializa el entorno.Después de ejecutar A2, el directorio de la tienda y los subdirectorios se generarán en el directorio de instalación de Yiming Modeling para guardar datos y archivos de resultados.
A3 Cargue el archivo de modelado y genere el objeto md
(2) Configuración de variables de destino y estadísticas de variables
Después de cargar los datos, configure la variable de destino
| A | |
| … | … |
| 4 | =ym_objetivo(A3,"y") |
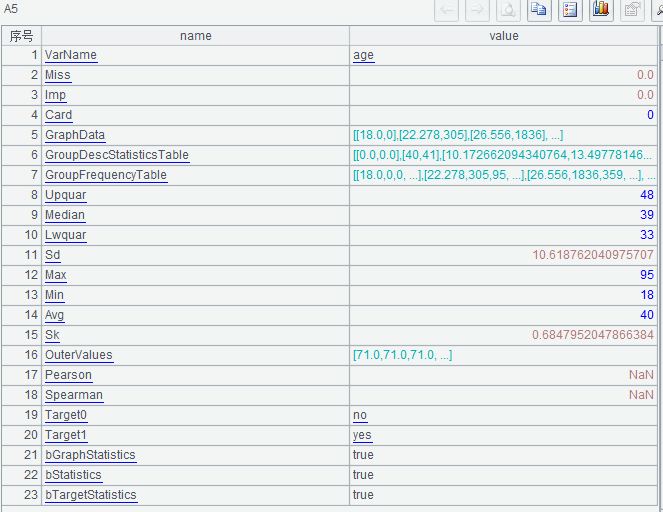
| 5 | =ym_statistics(A3,"edad") |
| 6 | =A1.fname().(ym_statistics(A3,~)) |
A4 significa establecer el campo "y" como la variable de destino, y la variable de destino puede ser una variable binaria o una variable numérica.
A5 Vea los indicadores estadísticos de una variable, como "edad", en el valor devuelto, puede ver parámetros como tasa de faltantes, valores máximos y mínimos, valores atípicos y diagramas de distribución de datos.
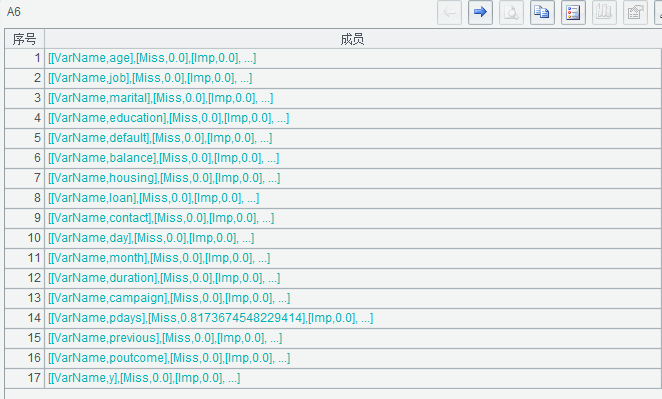
A6 Nombre de variable de bucle Ver las estadísticas de todos los campos y devolver una secuencia secundaria de estadísticas que contiene todos los campos.
(3) Construcción de un modelo y rendimiento del modelo
| A | |
| … | … |
| 7 | =ym_construir_modelo(A3) |
| 8 | =ym_presente(A7) |
| 9 | =ym_rendimiento(A7) |
| 10 | = ym_importance (A7) .sort @ z (Importancia) |
A7 utiliza funciones de modelado para construir un modelo. Después de la ejecución, se realizará un proceso de preprocesamiento y modelado de datos totalmente automatizado en segundo plano. Este proceso llevará algún tiempo, y la duración depende de la cantidad de datos. El resultado devuelve el objeto del modelo pd.
Después de construir el modelo, puede llamar al objeto del modelo pd para ver la información del modelo, la calidad y la importancia del modelo.
A8 devuelve el valor y los parámetros AUC del modelo
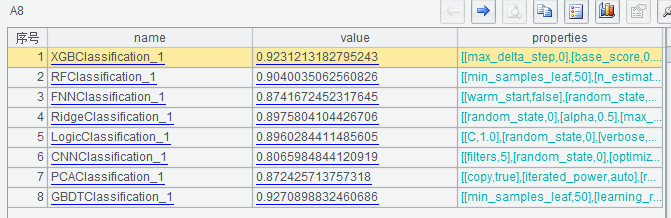
A9 devuelve varias métricas y gráficos del modelo, como AUC, ROC, Lift...

Por ejemplo, haga clic en el valor del sexto registro de A9, luego haga clic en el icono "Vista de gráficos" en la esquina superior derecha y seleccione "Elevación" en el campo de valor para ver la curva de elevación.
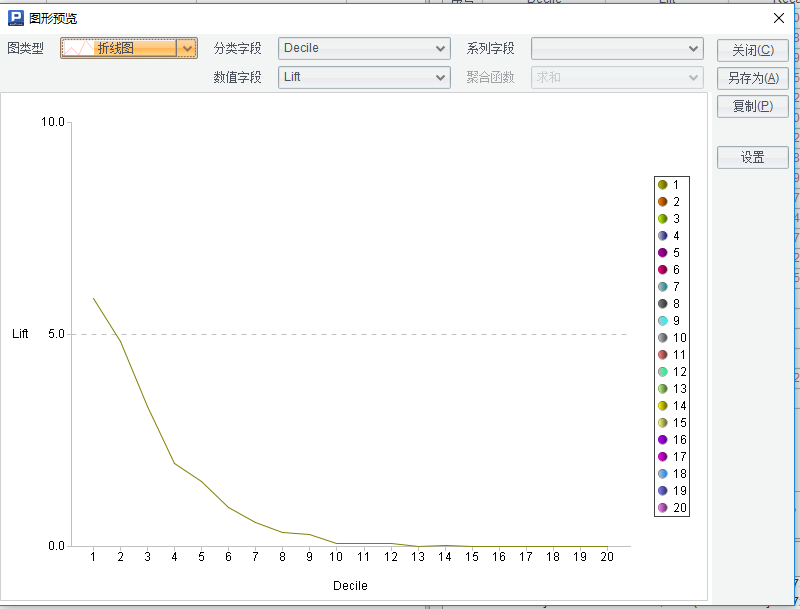
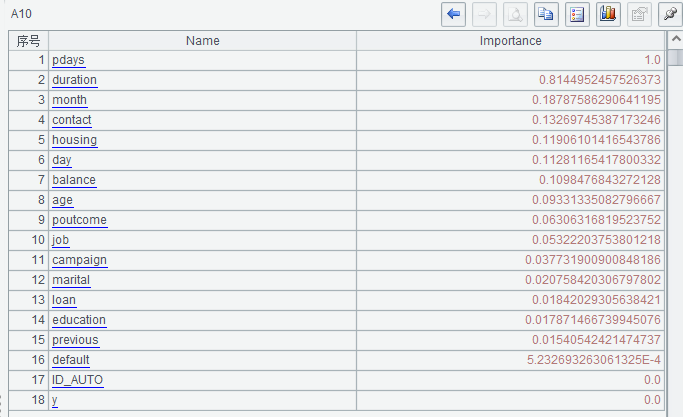
A10 devuelve la influencia de cada variable sobre la variable objetivo en orden descendente de importancia. Cuanto mayor sea el valor, mayor será el impacto en la variable objetivo. Ordenar en orden descendente es más intuitivo de analizar.
(4) Guardar el modelo
| A | |
| … | … |
| 11 | =ym_save_pcf(A7,"bankfull.pcf") |
| 12 | =ym_json(A7) |
| 13 | >ym_cerrar(A2) |
R11 Guarde el modelo como "bankfull.pcf", y la ruta de guardado predeterminada es [sAppHome]/store/predict.
A12 devuelve la información del modelo como una cadena json. Para obtener una explicación detallada del contenido json, consulte el documento en línea "descripción del parámetro json"
A13 Cerrar el entorno y liberar recursos.
(5) Predicción
Se requiere un archivo de modelo pcf y un conjunto de datos de predicción antes de la predicción
| A | |
| 1 | =ym_env() |
| 2 | =ym_load_pcf("bancolleno.pcf") |
| 3 | =archivo("banco-lleno2.csv").import@tc() |
| 4 | =ym_predecir(A2,A3) |
| 5 | =ym_resultado(A3) |
| 6 | =archivo("bank-full_result.csv").export@tc(A4) |
| 7 | >ym_cerrar(A1) |
A1 Inicializar el entorno
A2 Importe el archivo del modelo pcf para generar el objeto del modelo pd.
A3 Importe el conjunto de datos de predicción y lea la tabla de pedidos
A4 Realizar predicciones sobre datos ordinales. Además de la tabla de secuencias, también admite cursores, archivos csv y archivos mtx. Por ejemplo, A4 también se puede escribir directamente como ym_predict(A2, "bankfull2.csv")
A5 Obtener resultados de predicción
A6 deriva el resultado de la predicción, en este caso el resultado de la predicción es la probabilidad de que el usuario incumpla.

A7 Cerrar el entorno y liberar recursos
4. Llamada de integración
SPL también se puede integrar y llamar mediante aplicaciones de capa superior. Por ejemplo, SPL se puede integrar en aplicaciones Java. Para obtener más información, consulte: http://c.raqsoft.com.cn/article/1615765346560
Resumir
Es muy simple usar SPL con Yiming Modeling para realizar el modelado y la predicción de datos. Los programadores no necesitan comprender principios matemáticos esotéricos. Siempre que preparen datos de entrenamiento, pueden completar la tarea de modelado de datos en unos pocos pasos simples. Y con la capacidad de integrar fácilmente esta funcionalidad en las aplicaciones, la IA avanzada ya no es exclusiva de un puñado de científicos de datos.
SPL本来就超强的数据处理能力,能更方便地完成人工智能算法之前的数据准备工作,同时也提供了丰富的数学函数: SPL Math 例程,有些数学基础想自己实现建模过程的同学也可以进一步研究。