Tabla de contenido
5.1 Dividir el conjunto de datos
prefacio
Han pasado tres años desde que comencé a aprender sobre aprendizaje automático y tengo un conocimiento general del proceso de modelado y varios escenarios de uso de modelos. De estos, siento que me falta un artículo realmente introductorio de todos mis artículos de aprendizaje automático. Dar el primer paso de aprender en cualquier situación es más difícil, el costo de aprender es muy alto y los beneficios también son altos en comparación con lo que has aprendido. En particular, el aprendizaje automático es un tema que está fuertemente relacionado con las matemáticas y la lógica. Es difícil comenzar, pero cuando realmente se hace, producirá una sensación de entusiasmo y alegría. Siento que es por eso que participo en Minería de datos El modelado funciona por esta razón. Al escribir este artículo, espero que otros amigos no se preocupen demasiado por sus habilidades cuando quieran comenzar con el aprendizaje automático y traten de dar sus primeros pasos primero. Espero que a todos les guste.
Espero que los lectores puedan cometer errores u opiniones después de leer, y los bloggers mantendrán el blog durante mucho tiempo y lo actualizarán a tiempo.
1. A partir del propósito
Dado que es el primer proyecto, no lo hagamos tan complicado, simplemente mantenga todo simple, y también tenemos una poderosa biblioteca de análisis de aprendizaje automático como Python-sklearn. Entonces, partimos directamente del propósito y usamos la biblioteca Iris Flower para hacer una clasificación, es así de simple.
1. Importar datos
Entonces, primero necesitamos datos, ¿de dónde provienen los datos?
Los datos siempre han sido un problema difícil en el aprendizaje automático. El proceso de construcción de un modelo de aprendizaje automático es entrenar el modelo a través de una gran cantidad de datos históricos para lograr la capacidad de ajustar el valor real. La calidad y la cantidad de datos determinan el límite superior del modelo, desde la recopilación de datos hasta el procesamiento y cálculo de datos. La adquisición involucra sensores en gran medida, los complejos son un poco confusos y sensores multidimensionales, mientras que simplemente obtener información del usuario de la base de datos está bien. El procesamiento de datos lo realiza un equipo o departamento especial de ETL. Los diferentes tipos de datos recopilados deben procesarse en diferentes grados. Por ejemplo, los datos confidenciales deben ser insensibilizados y los datos faltantes deben completarse y eliminarse. En términos de computación, hay más formas. Ahora no solo buscamos la precisión del modelo, sino también la velocidad en los negocios, como el popular marco de computación distribuida de big data y el marco de aprendizaje profundo de redes neuronales. En resumen, no consideramos primero la fuente de los datos, la biblioteca sklearn de aprendizaje automático viene con datos de iris. El conjunto de datos Iris iris contiene 3 categorías: Iris-setosa, Iris-versicolor e Iris-virginica, con un total de registros 150 y datos 50 en cada categoría. Cada registro tiene características 4: longitud del sépalo, anchura del sépalo, longitud del pétalo y longitud del pétalo. ancho.
- longitud del sépalo: longitud del sépalo
- ancho del sépalo: ancho del sépalo
- longitud del pétalo: longitud del pétalo
- ancho de pétalo: ancho de pétalo
Las unidades de las cuatro características anteriores son todos centímetros (cm).
Este conjunto de datos tiene las siguientes características:
- Todos los datos de características son números, no es necesario pensar en cómo importar y procesar los datos.
- Las unidades numéricas de todas las características son las mismas y no se requiere escala.
Luego, instalamos el proceso tradicional de modelado de modelos de máquinas para completar todos los pasos de un proyecto de aprendizaje automático. Seguiremos los siguientes pasos para implementar este proyecto:
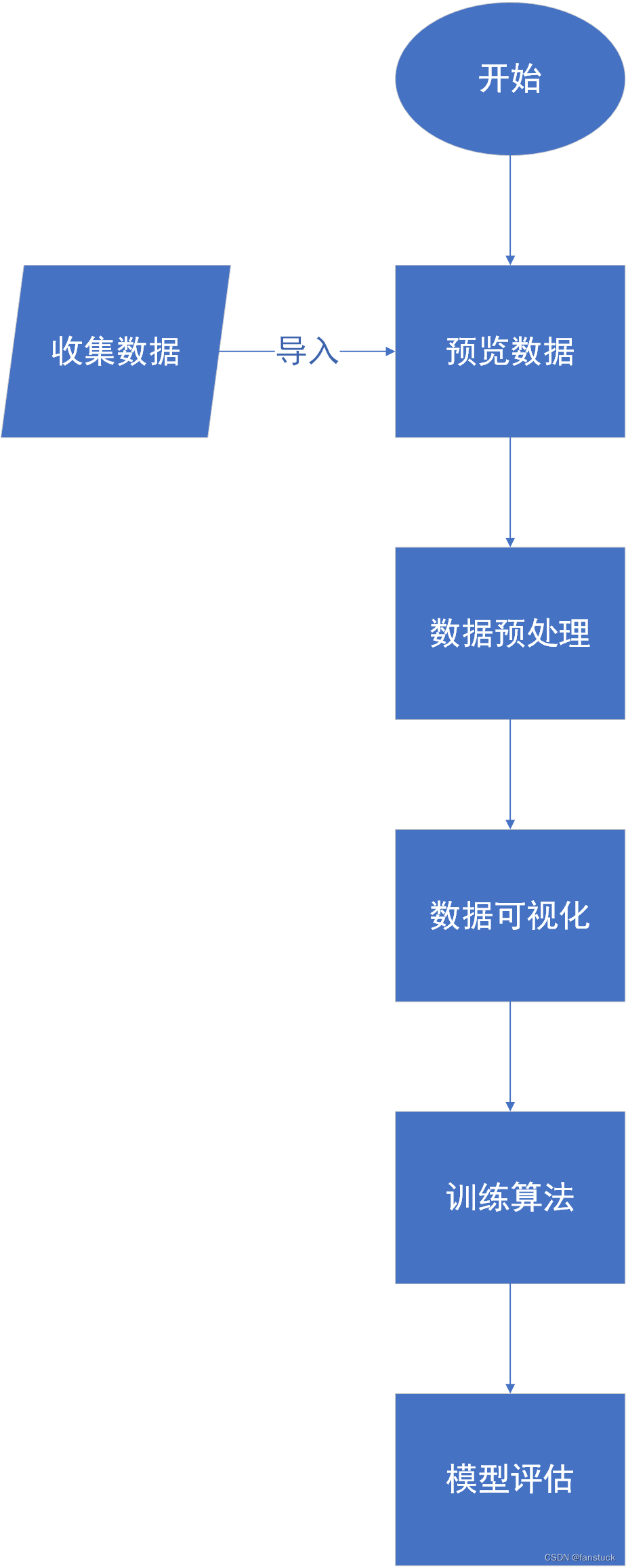
2. Inicio del proyecto
1. Importar datos
Primero necesitamos importar las bibliotecas que usaremos:
from sklearn.datasets import load_iris
import pandas as pdDespués de eso, solo necesitamos iniciar sesión en los datos para ver la forma de los datos:
iris_data = load_iris()
iris_data_feature=list(iris_data.data)
iris_data_df=pd.DataFrame(iris_data_feature,columns=['花萼长度','花萼宽度','花瓣长度','花瓣宽度'])
iris_data_df 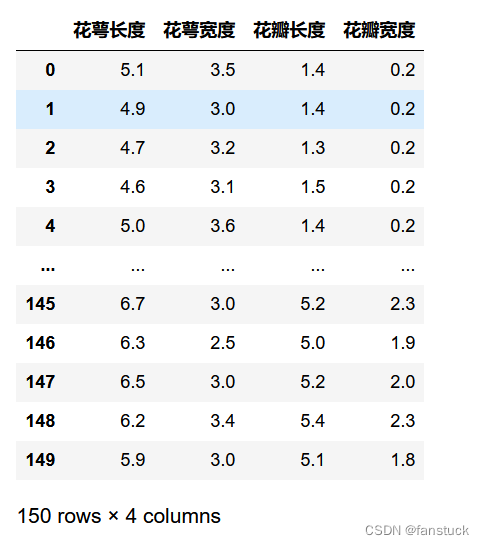
Entre ellos, podemos ver que los datos en iris_data se dividen principalmente en dos partes, una parte son los datos que representan las cuatro dimensiones de 'longitud del cáliz', 'ancho del cáliz', 'longitud del pétalo', 'ancho del pétalo' y la el objetivo son los datos del tipo de flor:
iris_data_class=list(iris_data.target)
iris_class_df=pd.DataFrame(iris_data_class,columns=['花朵类型'])
iris_class_df 

Se puede ver que los datos son muy comunes y tienen una precisión de un decimal. Es muy inconveniente observar un conjunto de datos con una gran cantidad de datos a simple vista. Necesitamos obtener una vista previa de los datos de forma intuitiva.
Al fusionar podemos obtener una tabla de datos de iris completa para dibujar y estadísticas más tarde:
iris_true_df=pd.concat([iris_data_df,iris_class_df],axis=1) 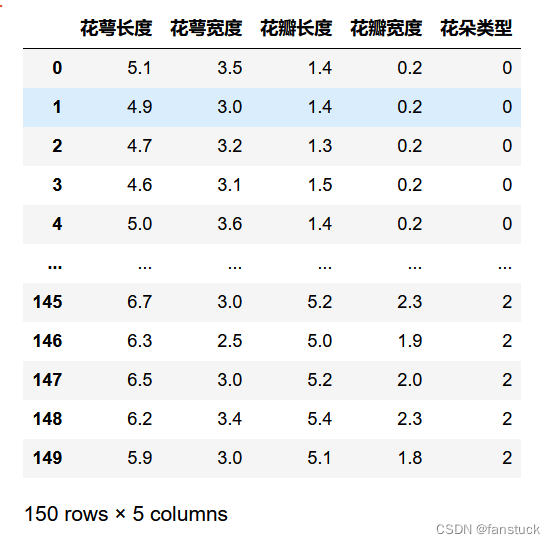
2. Vista previa de datos
Hay muchas formas de obtener una vista previa de los datos, que se pueden obtener a través de la visualización de datos o mediante la descripción estadística de los datos. Aquí podemos presentar las potentes funciones de análisis de datos de nuestros pandas. Pandas tiene muchas funciones de análisis estadístico, que pueden obtener rápidamente parámetros estadísticos comunes:
iris_true_df.describe()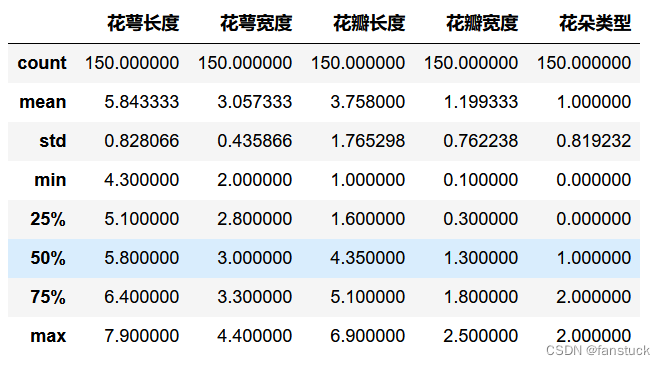
Entre ellas, la descripción de la variable de valor estadístico:
- count: número de estadísticas, cuántos valores válidos hay en esta columna
- unipue: cuantos valores diferentes hay
- estándar: desviación estándar
- min: valor mínimo
- 25%: cuartil
- 50%: medio cuantil
- 75%: cuartil
- máx: valor máximo
- media: media
Podemos agrupar los datos de diferentes tipos de flores por etiqueta y comprobar si la distribución de datos de cada categoría está equilibrada:
iris_true_df.groupby('花朵类型').size() 
Podemos ver que hay 50 datos para las tres especies de iris, y la distribución es equilibrada. Al agrupar, también puede agregar para obtener datos agregados de varias dimensiones de flores de diferentes categorías:
iris_true_gy=iris_true_df.groupby('花朵类型')
for name,group in iris_true_gy:
print(name)
display(group.head()) 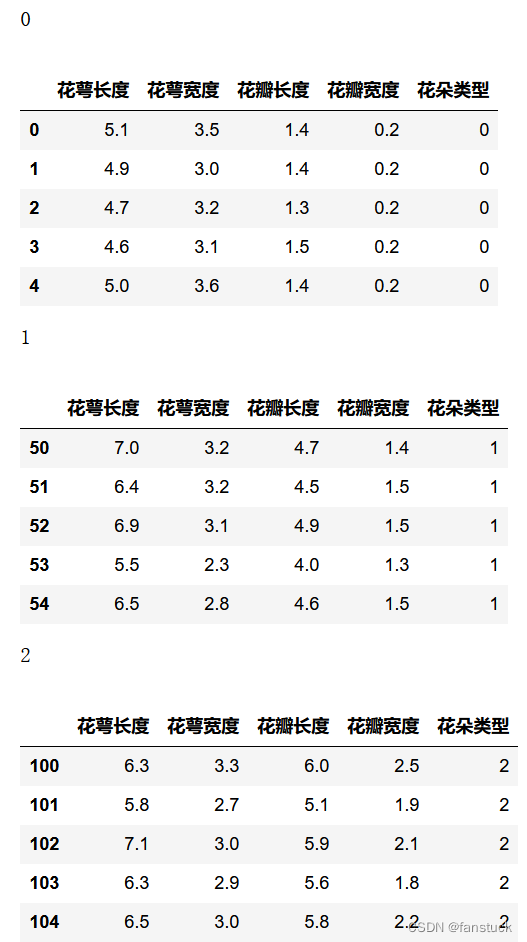
Se pueden lograr estadísticas más refinadas a través de la función de agregación agregada de pandas:
iris_true_gy['花萼长度'].agg(['min','mean','max']) 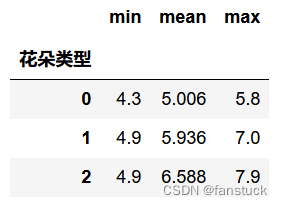
3. Preprocesamiento de datos
Si la distribución de los datos está desequilibrada, puede afectar la precisión del modelo. Por lo tanto, cuando la distribución de datos está desequilibrada, es necesario procesar los datos y ajustar los datos a un estado relativamente equilibrado.
El preprocesamiento de datos, como tema principal en el aprendizaje automático, ha pasado por décadas de experiencia y precipitación tecnológica. Si desea obtener más información, puede leer: Un estudio rápido: explicación detallada del método de preprocesamiento y análisis de categorías de datos de características + código Python - Blog de Fanstuck - Blog de CSDN
En este artículo, el método de procesamiento es:
1. Sobremuestreo
El sobremuestreo también se conoce como sobremuestreo, este método es más adecuado para datos pequeños con distribución desigual. Si la distribución de big data está desequilibrada, expanda los conjuntos de datos pequeños originales con diferentes categorías al mismo tamaño que los conjuntos de datos con diferentes categorías. Al igual que los datos del primer ejemplo, si se realiza un sobremuestreo, se generarán más de 260 000 datos. En comparación con el submuestreo, la relación de peso de cálculo y el tiempo de operación aumentarán considerablemente. Incluso puede causar sobreajuste. Sin embargo, el uso de este método también puede evitar el ajuste insuficiente causado por la escasez de datos.
2. Submuestreo
El submuestreo, también conocido como submuestreo, generalmente reduce una categoría más grande de datos hasta que es comparable a un pequeño conjunto de datos de diferentes tipos. Si submuestreamos los datos del Ejemplo 1, los datos de comportamiento del usuario de 13w se reducirán a 6730 datos y la velocidad de modelado se acelerará considerablemente.
Dado que el preprocesamiento de datos se ha llevado a cabo en este conjunto de datos, este blog no explicará en detalle el caso de la predicción de datos. Los estudiantes interesados pueden consultar los artículos anteriores del blogger sobre modelos de aprendizaje automático.
4. Visualización de datos
Aquí debemos pensar que si dibujamos estos datos como un gráfico, al igual que convertimos los datos de la lista de Excel en un gráfico, python también puede lograr efectos similares, aquí solo necesitamos importar la biblioteca matplotlib:
Podemos elegir la fuente y el tema de matplotlib, así como el color y el método de salida.
import matplotlib.pyplot as plt
from matplotlib import font_manager # 导入字体管理模块
plt.style.use('ggplot')Gráfico univariante
Un gráfico univariante puede mostrar cada atributo de característica individual y, dado que cada atributo de característica es un número, podemos mostrar la velocidad discreta del atributo frente al valor medio al trazarlo en una línea:
Cabe señalar aquí que la fuente china informará un error y debe configurar la fuente predeterminada especificada.
from pylab import mpl
#mpl.rcParams['font.sans-serif'] = ['SimHei']
mpl.rcParams['font.sans-serif'] = ['Microsoft YaHei'] # 指定默认字体:解决plot不能显示中文问题
mpl.rcParams['axes.unicode_minus'] = False # 解决保存图像是负号'-'显示为方块的问题
iris_data_df.plot(kind='box',subplots=True,layout=(2,2))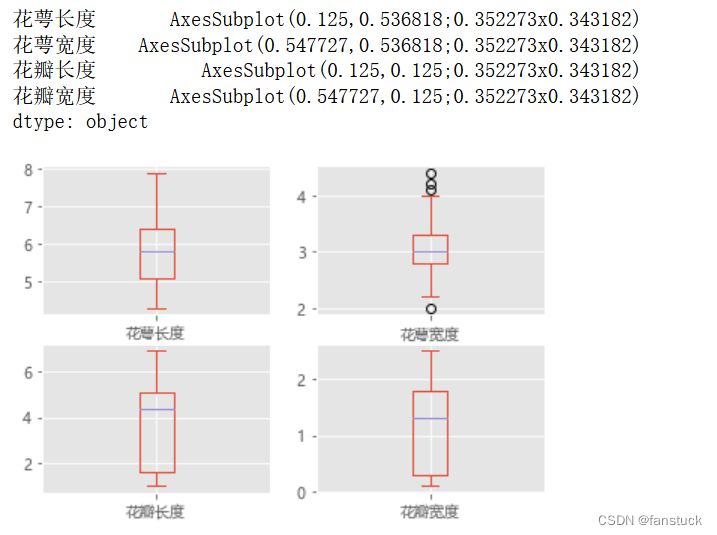
La distribución de cada atributo de característica también se puede mostrar a través de un histograma:
iris_data_df.hist() 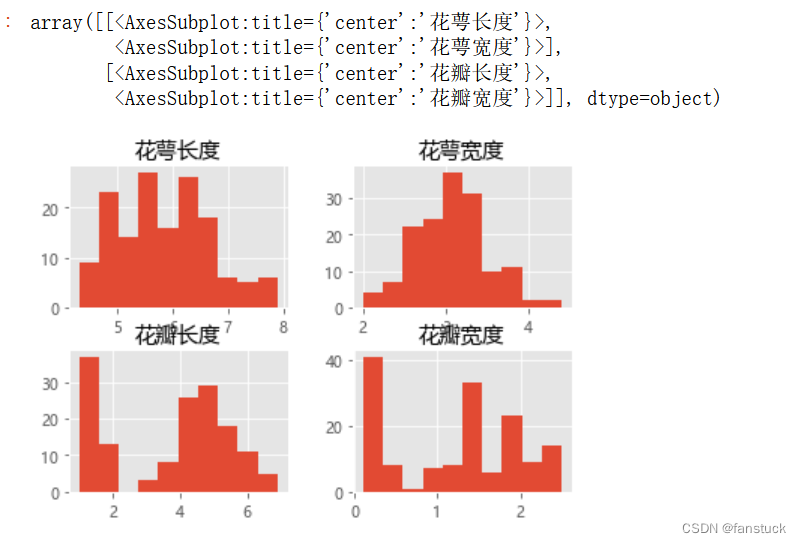
Encontraremos que la longitud del cáliz, el ancho del cáliz y la longitud del pétalo están todos en línea con la distribución gaussiana.
Gráfico multivariante
Los gráficos multivariantes le permiten ver la relación entre diferentes atributos de características. Observamos la relación de influencia entre cada atributo a través de un gráfico de matriz de dispersión.
#散点矩阵图
scatter_matrix(iris_data_df) 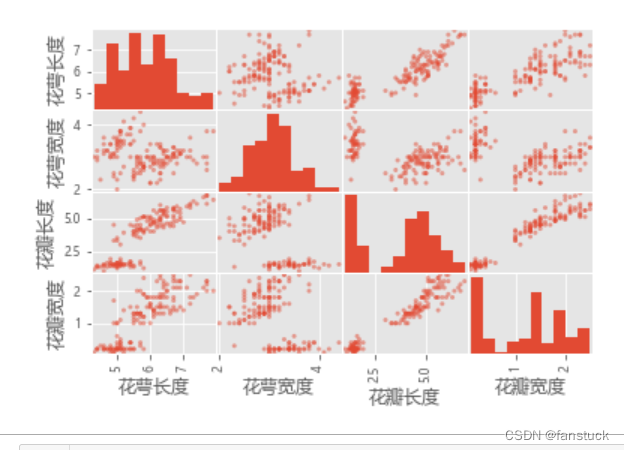
## 第一步,先定义1张空白的大画板
fig=plt.figure(num=1, figsize=(16, 16))
## 增加1个子图,2x2,共4个子图,排第1个
ax1 = fig.add_subplot(221)
ax1.scatter(x=iris_true_df.iloc[:,0:1], y=iris_true_df.iloc[:,4:5],color='k',alpha=0.5)
## 增加1个子图,2x2,共4个子图,排第2个
ax2 = fig.add_subplot(222)
ax2.scatter(x=iris_true_df.iloc[:,1:2], y=iris_true_df.iloc[:,4:5],alpha=0.5)
## 增加1个子图,2x2,共4个子图,排第3个
ax3 = fig.add_subplot(223)
ax3.scatter(x=iris_true_df.iloc[:,2:3], y=iris_true_df.iloc[:,4:5],color='tan',alpha=0.5)
## 增加1个子图,2x2,共4个子图,排第4个
ax4 = fig.add_subplot(224)
ax4.scatter(x=iris_true_df.iloc[:,3:4], y=iris_true_df.iloc[:,4:5],color='c',alpha=0.5)Puede ser un poco complicado para los principiantes ponerse en contacto con matplotlib, pero si lo usa con frecuencia, pronto recordará cómo usar la función:
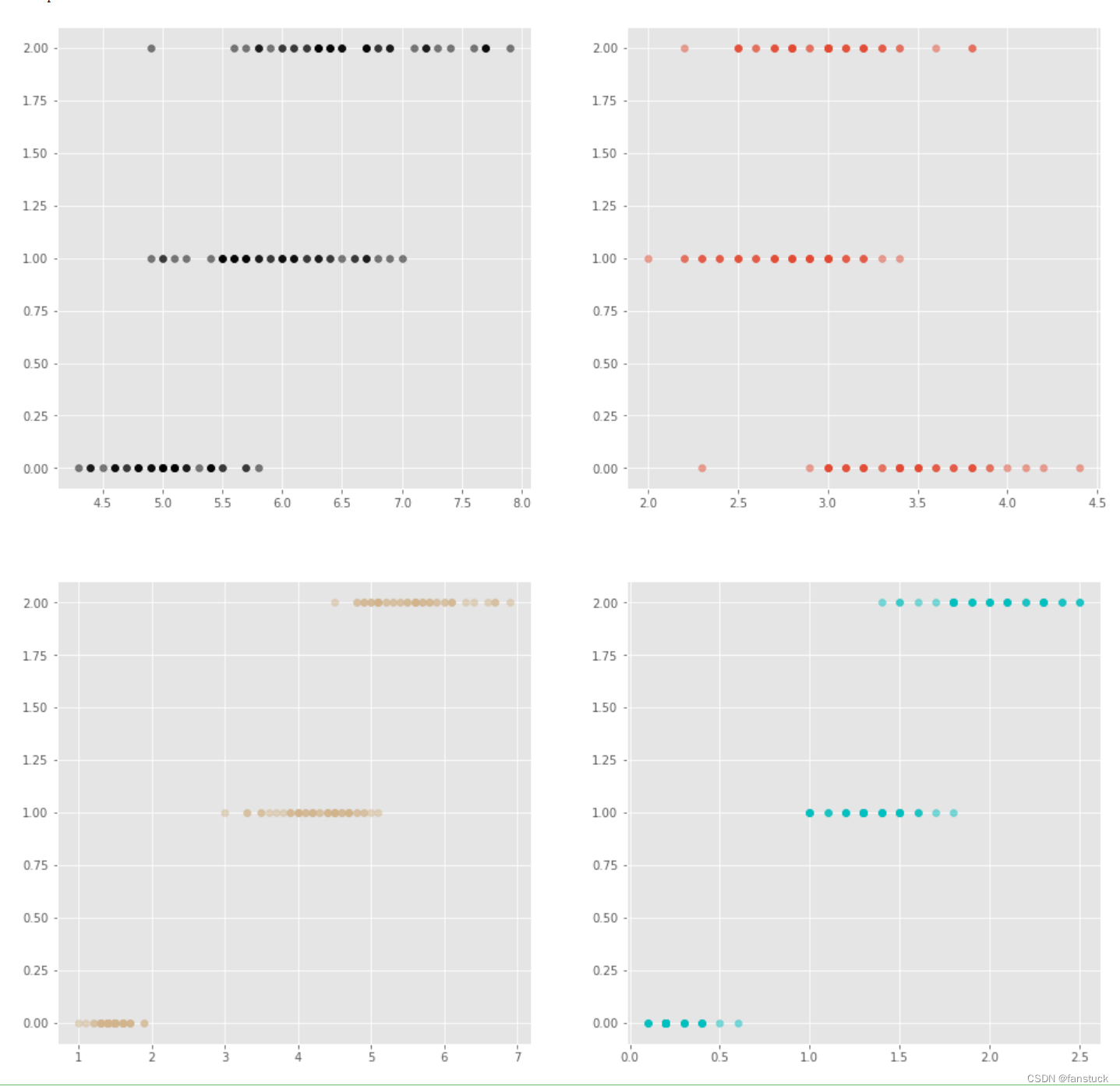
Intuitivamente podemos encontrar que las características de cada dimensión de las flores de cada variedad son claramente distinguibles, y existen grandes diferencias. De esta forma, podemos empezar a construir y entrenar el modelo.
5. Entrena al modelo
Necesitamos parte de los datos para entrenar el modelo y parte de los datos para verificar la precisión del modelo para que podamos encontrar el algoritmo más adecuado.
5.1 Dividir el conjunto de datos
Por lo general, dividimos el conjunto de datos en 2/8, de los cuales el 80 % de los datos se usa para entrenamiento y el 20 % de los datos se usa para validación.
from sklearn.model_selection import train_test_split
iris_array=iris_true_df.values
X=iris_array[:,0:4]
Y=iris_array[:,4]
test_model=0.2
seed=5
X_train,X_test,Y_train,Y_test=train_test_split(X,Y,test_size=test_model,random_state=seed)5.2 Algoritmos de evaluación
Aquí usamos el método de validación cruzada de diez veces para evaluar la precisión del algoritmo. La validación cruzada de diez veces implica dividir aleatoriamente los datos en 10 partes: 9 para entrenar el modelo y 1 para evaluar el algoritmo.
from sklearn.model_selection import KFoldLa validación KFold y K-fold es la misma. Es decir, un conjunto de datos se divide en K partes, una de las cuales se usa para verificación y los k-1 datos restantes se usan para entrenamiento. Por lo tanto, la clase KFold no es difícil de entender y también se usa para la división de datos.
5.3 Establecimiento modelo
Una de las cosas que es muy conveniente para nosotros al usar sklearn es que el modelo solo necesita ser importado, y no necesitamos hacer la lógica de cálculo subyacente. En la etapa inicial del proyecto, puede llamar a varios algoritmos para realizar pruebas, pero si realmente desea comenzar con el aprendizaje automático, debe dominar cada algoritmo ahora para ajustar los parámetros con mayor precisión.
Aquí presentamos seis algoritmos para la evaluación:
from sklearn.linear_model import LogisticRegression
from sklearn.tree import DecisionTreeClassifier
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis
from sklearn.neighbors import KNeighborsClassifier
from sklearn.naive_bayes import GaussianNB
from sklearn.svm import SVCLuego construye seis modelos diferentes:
models={}
models['LR']=LogisticRegression()
models['LDA']=LinearDiscriminantAnalysis()
models['KNN']=KNeighborsClassifier()
models['CART']=DecisionTreeClassifier()
models['NB']=GaussianNB()
models['SVM']=SVC()
Después de eso, necesitamos construir el algoritmo de evaluación del modelo:
results=[]
for key in models:
kfold=KFold(n_splits=10,shuffle=True,random_state=seed)
cv_results=cross_val_score(models[key],X_train,Y_train,cv=kfold,scoring='accuracy')
results.append(cv_results)
print('%s:%f(%f)'%(key,cv_results.mean(),cv_results.std()))
En este punto, sería bueno si pudiéramos usar más los resultados de la visualización de datos:
#箱线图
fig=pyplot.figure()
fig.suptitle('Comparison')
ax = fig.add_subplot(111)
pyplot.boxplot(results)
ax.set_xticklabels(models.keys())
pyplot.show() 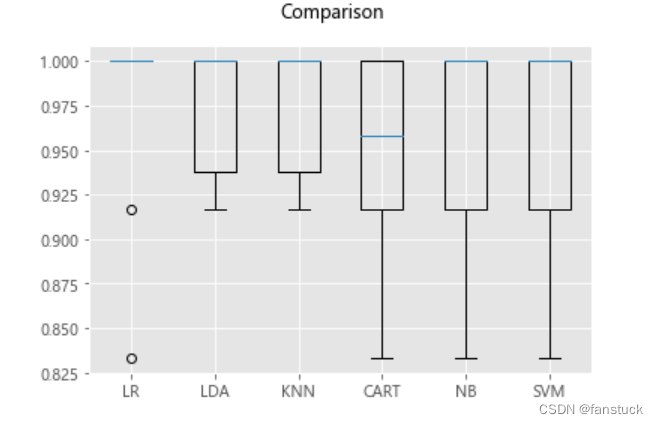
5.4 Modelo de predicción
Nuestra evaluación muestra que el algoritmo de regresión logística LR es el algoritmo más preciso. Luego usamos el conjunto de datos de evaluación reservados para dar un informe de modelo de algoritmo.
LR=LogisticRegression()
LR.fit(X=X_train,y=Y_train)
predictions=LR.predict(X_test)
print(accuracy_score(Y_test,predictions))
print(confusion_matrix(Y_test,predictions))
print(classification_report(Y_test,predictions))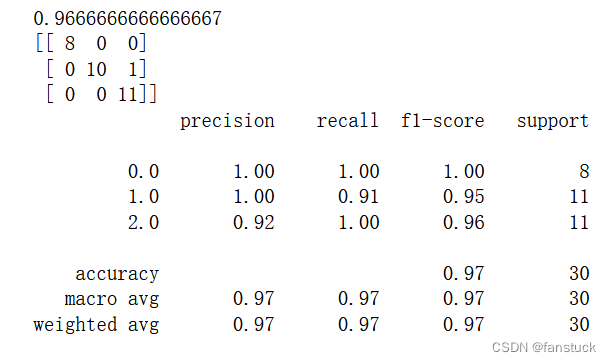
La precisión del algoritmo es del 96,7 % y la precisión de predicción de los proyectos reales es muy baja, lo que significa que los datos son lo suficientemente simples.
confusion_matrix es la matriz de confusión. Classification_report proporciona predicciones, precisión, recuperación y F1 para cada categoría.
Así que ahora hemos completado el primer proyecto de aprendizaje automático, que es un proceso de modelado muy estándar. Desde la importación de datos hasta la visualización de datos, el preprocesamiento de datos hasta el establecimiento y evaluación de modelos, hay mucho conocimiento involucrado en una división de un aspecto. Cada uno de los temas correspondientes es digno de nuestra profunda comprensión y excavación. Y sklearn puede construir rápidamente un modelo, lo que nos facilita el ajuste de parámetros.Puede considerarse como una biblioteca de bloqueo de aprendizaje automático. Sin embargo, para seleccionar el algoritmo con mayor precisión y construir modelos de fusión y más avanzados, es necesario tener una comprensión más clara de todo el modelo de algoritmo de aprendizaje automático.
Preste atención, evite perderse, si hay algún error, deje un mensaje para recibir asesoramiento, muchas gracias.
Eso es todo por este tema. Estoy atascado. Si tiene alguna pregunta, no dude en dejar un mensaje para discutir. Nos vemos en la próxima edición.