1. The purpose of master-slave replication
The built-in replication function of MySQL is the basis for building large-scale and high-performance applications based on MySQL. The purpose of the replication function is to build high-performance applications, and it is also the work of high availability, scalability, disaster recovery, backup, and data warehousing. The basics. The more common uses are:
Data distribution: backup specific databases
Load balancing: read and write separation
High availability and failover: the presence of slave libraries can reduce downtime
MySQL upgrade test: Use a higher version of MySQL as the standby database to ensure that queries can be performed as expected in the standby database before upgrading all instances
Second, the principle and steps of master-slave replication
Simply put, the master writes the database changes to the binary log binary log, which records all SQL statements that modify the database (insert, update, delete, grant, etc.), and the slave synchronizes these binary logs, and based on these binary logs Log data operation, in fact, is to copy the binary log on the master server to the slave server for execution, so that the data on the slave server is the same as the data on the master server.
In general, master-slave replication has the following steps:
1. The master node must enable binary logging to record any events that modify database data.
2. Open a thread I/O Thread from the node to act as a mysql client, and request events in the binary log file of the master node through the mysql protocol
3. The main node starts a thread (dump Thread), checks the events in its own binary log, and compares it with the location requested by the other party. If there is no request location parameter, the main node will start from the first log file. Events are sent to slave nodes one by one.
4. The slave node receives the data sent by the master node and places it in the relay log file. And record the location of the binary log file of the primary node for this request.
5. Start another thread (sql Thread) from the node, read the events in the replaylog, and execute it again locally.
Its schematic diagram is as follows:
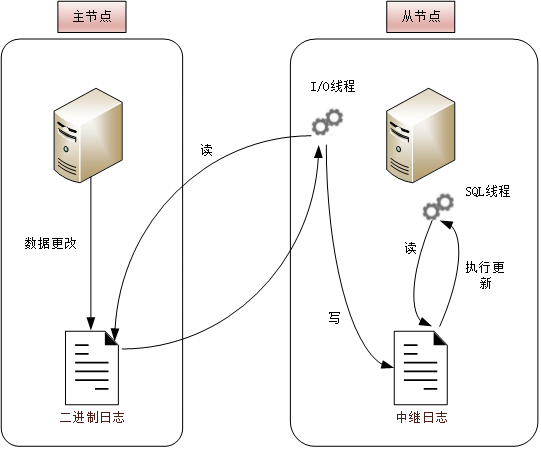
3. The role of threads in replication
From node:
I/O Thread: Request binary log events from the Master and save them in the relay log.
Sql Thread: Read log events from the relay log and complete the update locally.
master node:
Dump Thread: Start a dump thread for each Slave's I/O Thread to send binary events to slave nodes.
If the slave node needs to be the master node of other nodes, it is necessary to open the binary log file. This situation is called cascading replication. If it's just a slave node, you don't need to create a binary.
Fourth, the master-slave replication configuration process
master node:
1. Enable binary logging.
2. Set a globally unique server_id for the current node.
3. Create a user account replication slave with replication permissions.
From node:
1. Start the relay log.
2. Set a globally unique server_id for the current node.
3. Use a user account with replication permissions to connect to the master node and start the replication thread.
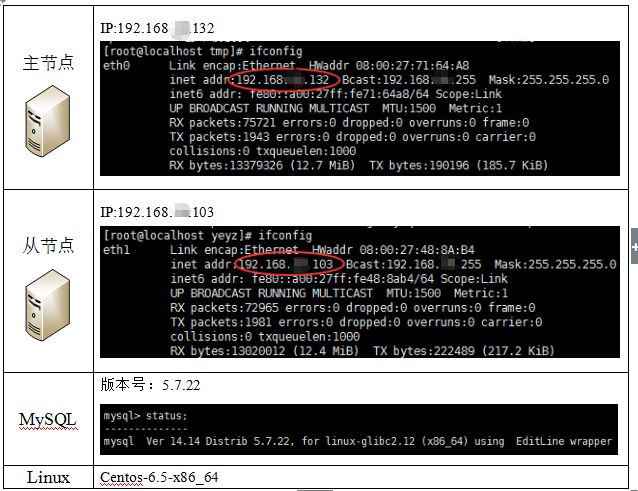
4.1 Test Environment
4.2 Master node configuration process
4.2.1 Editing the master node configuration file
Open the my.cnf document in Centos:
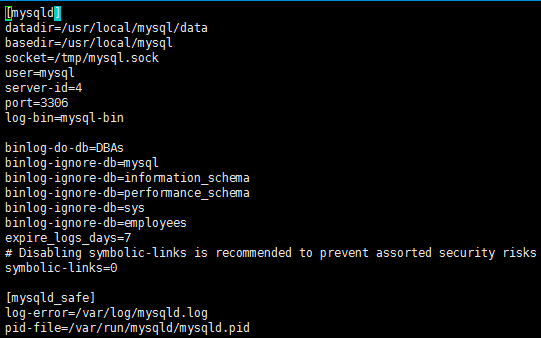
· Add: log-bin = mysql-bin (enable binary log)
· Add: server-id = 4 (to set the server id, the id of the master node and the slave node need to be different)
· Add: binlog-do-db=DBAs (determine which databases need to be synchronized)
· Add: binlog-ignore-db=mysql (you can add the database that needs to be ignored here)
Add: expire_logs_days=7 (automatically clean up log files 7 days ago, which can be modified as needed)
4.2.2 Start the primary node mysql service and connect to mysql
Under normal circumstances, the mysql service startup command is:
In order to start the mysql service more conveniently, create a soft connection for mysql
At this point, the startup command becomes:
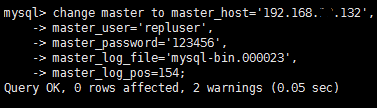
4.3.4 Configure the parameter information for accessing the master node on the slave node
Add the master node host, the user name and password for accessing the master node, and the binary file information of the master node.
Order:
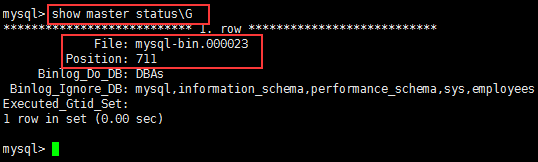
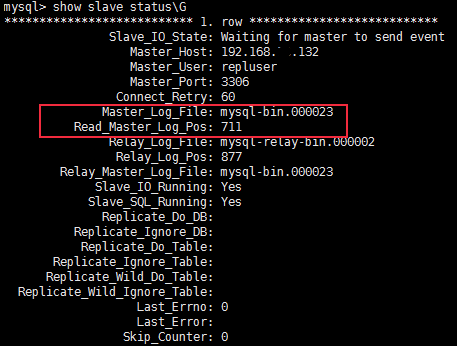
The master_log_file and master_log_pos here need to be consistent with the master node state.
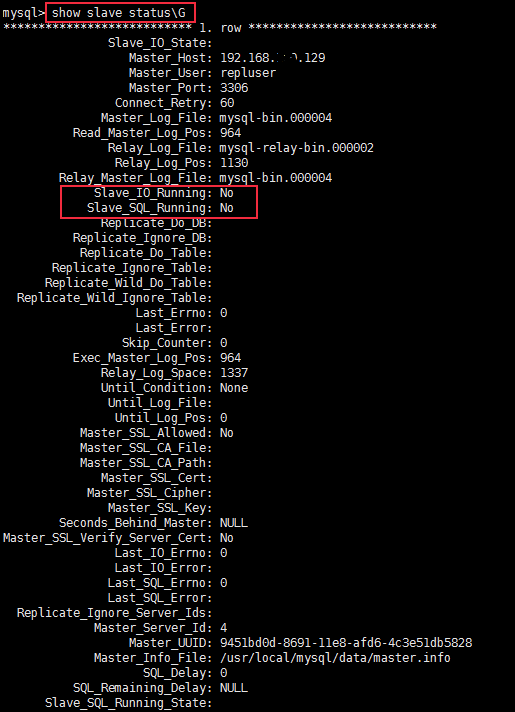
4.3.5 View the status information of the slave node
Because the replication thread of the slave node is not started, the I/O thread and SQL thread are both NO.
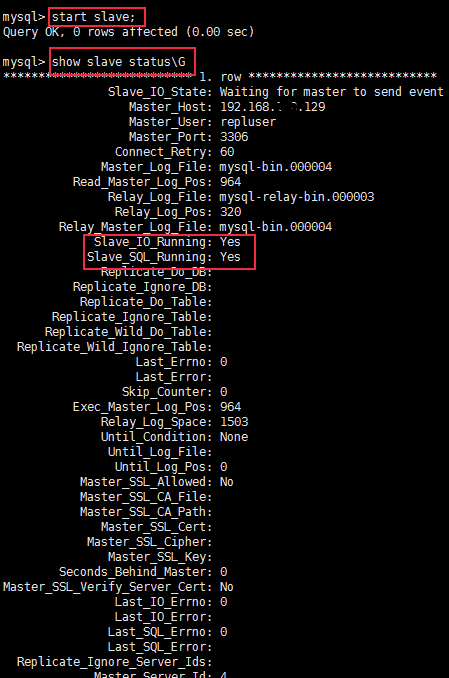
Use the start slave command to start the replication thread of the slave node, and then use the show slave status command to view the current slave node status.
4.4 Functional Test
Check the status of the master node,
2) Find the binary log information on the slave node and check whether the mydb database is successfully copied
Finally, check whether the data has been synchronized on the slave node, command:
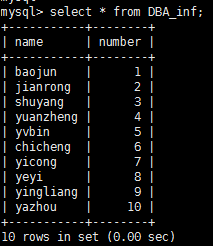
After verification, it proves that the master-slave replication synchronization is successful! ! !
Five, error troubleshooting summary
5.1 Connecting errors
The following errors sometimes occur during operation:
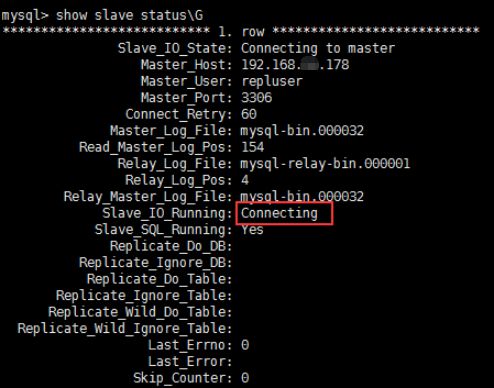
The troubleshooting idea is as follows:
1. Binary logging is not enabled
2.IPTABLES did not release the port
3. The corresponding host IP address is wrong
Actual operation: Turn off the firewall of the master node and restart the slave node to connect.
5.2 Slave_SQL_Running:NO
During the operation, the following error occurred in the operation of the SQL thread of the slave node
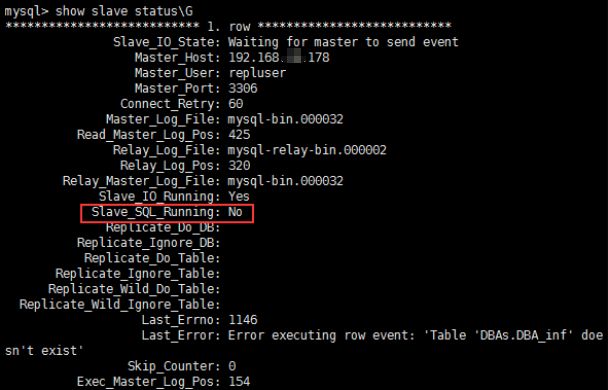
The troubleshooting idea is as follows:
- Check whether the network structure of NAT is used to cause problems with the network and cannot be connected.
- It is possible that there is a problem with my.cnf, the configuration file
- For authorization issues, replication slave and file permissions are required.
In fact, there is a problem with the network IP after changing the station, and the connection cannot be connected. After reconfiguring the network, the problem is solved.
node to connect.
5.2 Slave_SQL_Running:NO
During the operation, the following error occurred in the operation of the SQL thread of the slave node
The troubleshooting idea is as follows:
- Check whether the network structure of NAT is used to cause problems with the network and cannot be connected.
- It is possible that there is a problem with my.cnf, the configuration file
- For authorization issues, replication slave and file permissions are required.
In fact, there is a problem with the network IP after changing the station, and the connection cannot be connected. After reconfiguring the network, the problem is solved.
About MySQL master-slave replication, have you learned anything?
We sincerely invite you to join our big family.
There are not only the sharing of technical knowledge, but also the mutual help between bloggers
. Red envelopes are distributed from time to time, and there are monthly lucky draws, game consoles and physical books. Post)
Let's keep warm in a group and roll in. Build a beautiful C station. Looking forward to your joining.
Remarks: CSDN-xxxxxx (xxxxxx represents your csdn nickname)