Tabla de contenido
Ideas para resolver tareas y ganancias de experiencia
Soy Zheng Yin esperando su atención.

Hola a todos, les habla Zheng Yin, hoy les enseñare un caso relativamente criminal de reptiles
El rastreador de Python rastrea y descarga datos de sitios de investigación científica estadounidenses
No es fácil hacer un seguimiento gratuito y apoyarlo.
Introducción a la misión
-
Sitio web objetivo: https://app.powerbigov.us/view?r=eyJrIjoiYWEx…
-
Datos objetivo: descargue datos tabulares para 2009-2013 y guárdelos como archivo CSV
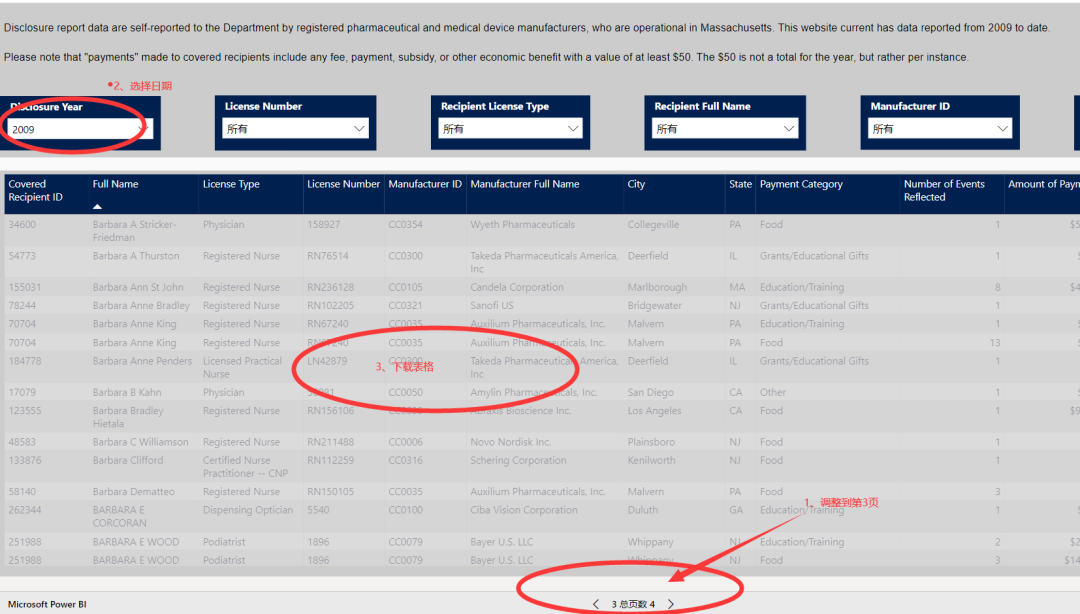
El sitio web de destino son los datos de investigación científica de Beautiful Country y los datos de la página web implementados por PowerBI. El contenido no se puede copiar con Ctrl + C. Por lo tanto, se nos pide que rastreemos para obtener ayuda.
Ideas para resolver tareas y ganancias de experiencia
En primer lugar, la tarea se puede dividir en dos partes: una es rastrear datos desde el sitio web hasta el local y la otra es analizar los datos y generar el archivo CSV :
-
Rastrear la parte de datos:
-
Analice la página web y encuentre la dirección de solicitud real y los parámetros para la carga asíncrona de datos
-
Escriba el código del rastreador para obtener todos los datos
-
-
Analizar la parte de datos
Esta es la principal dificultad de esta tarea. La dificultad radica en: en la lista de datos devueltos, el número de elementos no es un número fijo, solo valores diferentes de la fila anterior, y qué columna es diferente y qué columna es la mismo, es usar un valor "R" ” indica que la solución normal es invertir el JS para encontrar la función que analiza la relación R y completar el análisis . Sin embargo, debido a que el JS de la página web es muy complejo y muchos nombres de funciones son abreviados, es muy difícil de leer y no ha habido un éxito inverso.
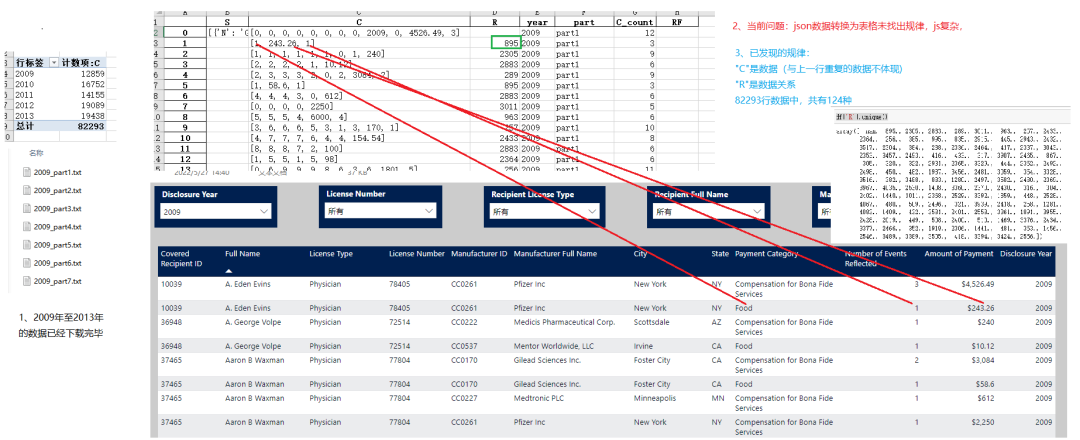
Para resolver este problema, la primera versión se consultó y resumió manualmente, y la primera versión se completó. Inesperadamente, al escribir este artículo para compartir, la idea se abrió repentinamente, cambiando la forma de solicitar datos y omitiendo los pasos de análisis. la relación R:
-
Opción 1: analizar datos usando la relación R de acuerdo con la solicitud normal
Después de descargar los datos completos y analizarlos, entre los datos requeridos de 2009 a 2013, hay un total de 124 relaciones R, con un valor mínimo de 0 y un valor máximo de 4083. Al consultar manualmente estas 124 relaciones, se obtiene un diccionario. hecho para completar el análisis. La relación resumida es la siguiente (consulta manual durante 5 horas, cansado):
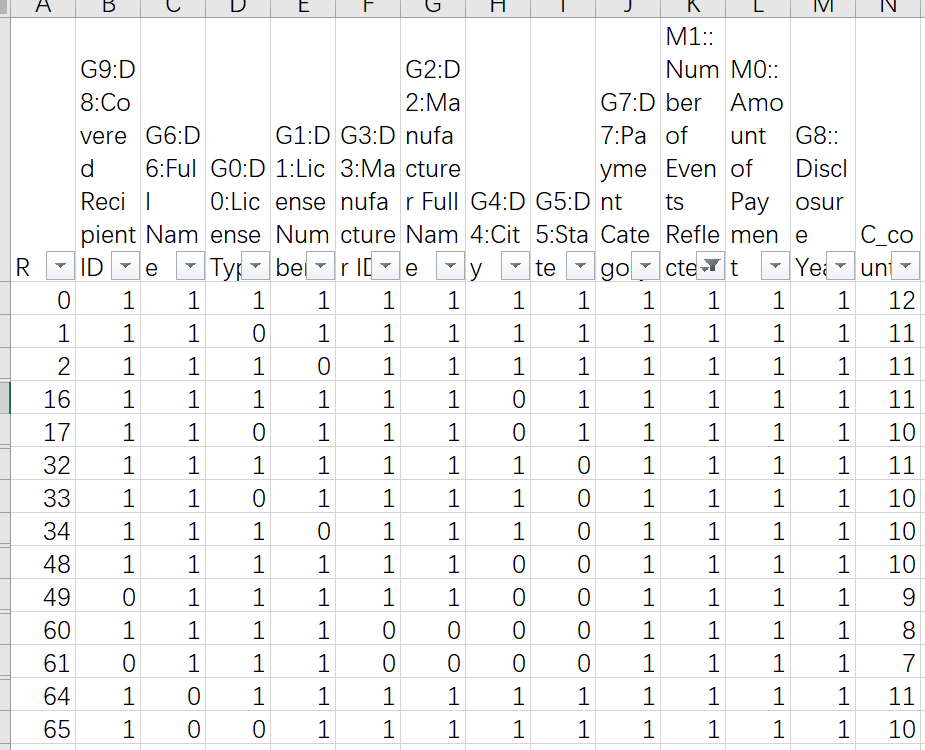
-
Opción 2: Intercambie tiempo por espacio y solicite solo una fila de datos a la vez, evitando la dificultad
de analizar la relación R. Al revisar los datos, de repente recuperé el sentido. La primera fila de los datos solicitados debe estar completa Si solo se solicita una fila de datos a la vez, entonces no hay posibilidad de que se produzca la misma situación que la línea anterior, en cuyo caso se puede evitar la dificultad de analizar la relación R. Después de la prueba, la solución es factible, pero es necesario considerar los siguientes aspectos:-
Active la aceleración de subprocesos múltiples para acortar el tiempo, pero incluso si se activan subprocesos múltiples, solo se pueden abrir 12 subprocesos de acuerdo con 12 años, y el año con la mayor cantidad de líneas es de aproximadamente 20,000 líneas, y el rastreador necesita para funcionar durante aproximadamente 5 a 6 horas
-
Los puntos de interrupción continúan aumentando para evitar la necesidad de comenzar desde el principio después de que el programa se interrumpe de manera anormal;
-
Pasos específicos
-
análisis del sitio de destino
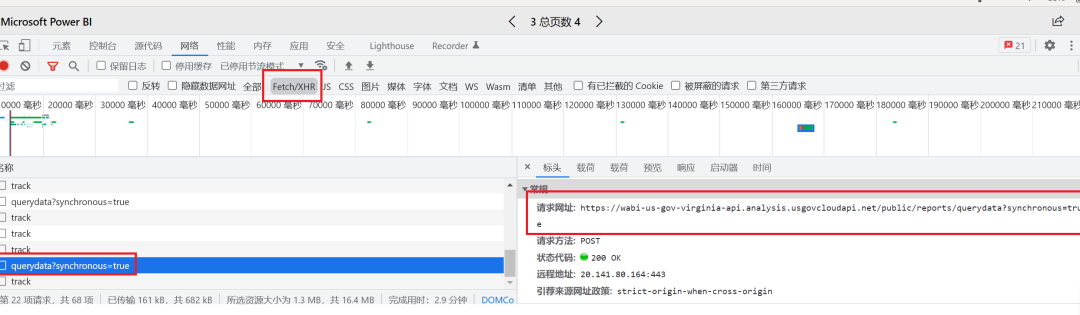
El primer paso es, por supuesto, analizar el sitio web de destino y encontrar la dirección de solicitud correcta para los datos. Esto es muy fácil. Abra el modo desarrollador de Chrome, arrastre la barra de desplazamiento hacia abajo y vea la nueva solicitud, que es la dirección real. Ir directamente al resultado:
Luego mire los parámetros de la solicitud POST
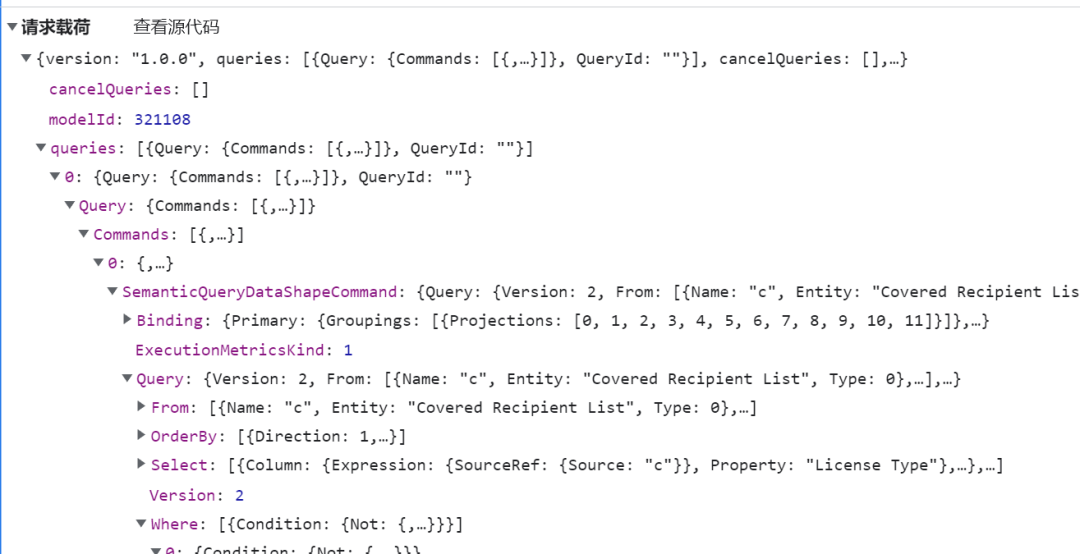
solicitar parámetros
Al volver a mirar los encabezados, ¡me sorprendió descubrir que no había antiescalada! ¡Ninguna escalada trasera! ¡Ninguna escalada trasera! Bueno, el sitio web de Pretty Country es el ambiente.
- Resumen del análisis:
# 完整参数就略过,关键参数以下三项: # 1.筛选年份的参数,示例: param['queries'][0]['Query']['Commands'][0]['SemanticQueryDataShapeCommand']['Query']['Where'][0]['Condition']['In']['Values'][0][0]['Literal']['Value'] = '2009L' # 2.请求下一批数据(请求首批数据时无需传入该参数),示例: param['queries'][0]['Query']['Commands'][0]['SemanticQueryDataShapeCommand']['Binding']['DataReduction']['Primary']['Window']['RestartTokens'] = [["'Augusto E Caballero-Robles'","'Physician'","'159984'","'Daiichi Sankyo, Inc.'","'CC0131'","'Basking Ridge'","'NJ'","'Compensation for Bona Fide Services'","2009L","'4753'"]] # 注:以上"RestartTokens"的值在前一批数据的response中,为上一批数据的返回字典值,示例res['results'][0]['result']['data']['dsr']['DS'][0]['RT'] # 3.请求页面的行数(浏览器访问默认是500行/页,但爬虫访问的话...你懂的),示例: param['queries'][0]['Query']['Commands'][0]['SemanticQueryDataShapeCommand']['Binding']['DataReduction']['Primary']['Window']['Count'] = 500 # 参数还有很多,例如排序的参数ordby,各种筛选项等-
URL para solicitar datos:
https://wabi-us-gov-virginia-api.analysis.usgovcloudapi.net/public/reports/querydata?synchronous=true -
Parámetros clave de POST:
-
-
Los pasos principales y el código del rastreador.
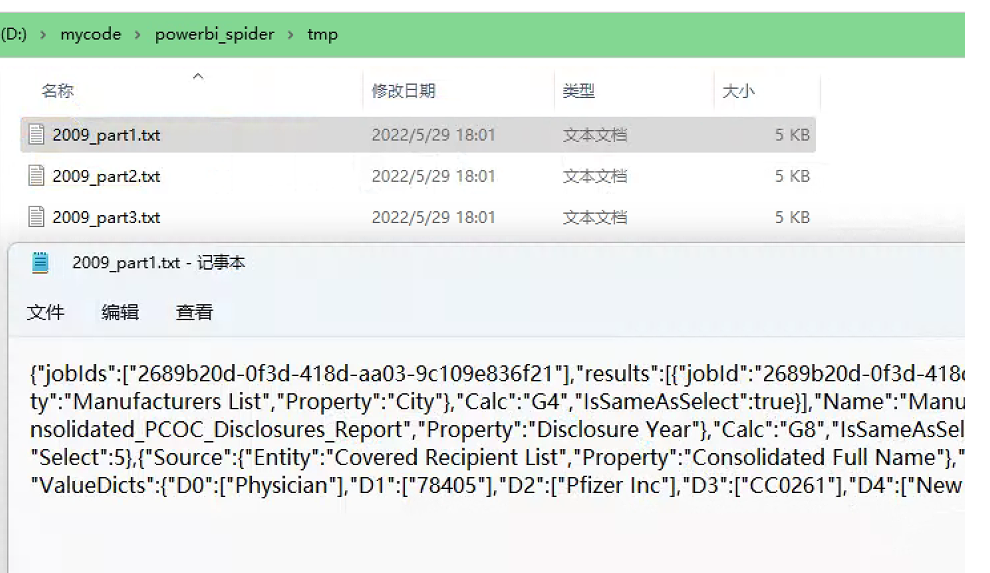
-
Para obtener todos los datos, se utiliza un ciclo infinito while True.Si hay una palabra clave "RT" en el valor de retorno de cada solicitud, los parámetros POST se modifican y se inicia la siguiente solicitud hasta que no haya una palabra clave "RT" en el valor de retorno, lo que significa que finaliza el rastreo de todos los datos (consulte el código para obtener más detalles)
-
Las excepciones en el proceso de solicitud deben detectarse y el siguiente paso se determina de acuerdo con el tipo de excepción. Dado que el sitio web no tiene anti-escalada, sino solo excepciones de tiempo de espera o error de conexión, solo es necesario reiniciar la solicitud, por lo que no es necesario seguir rastreando sin tener en cuenta el punto de interrupción.
-
Los pasos anteriores, el código detallado es el siguiente:
-
No hay anti-rastreo del sitio web. Después de encontrar la ruta y los parámetros correctos, la implementación del código del rastreador es relativamente simple. Puede iniciar directamente una solicitud de publicación. El código se implementa a través de la clase PageSpider (se adjunta el código detallado)
-
En la reanudación del punto de interrupción, el proceso se resuelve, cada línea de datos se almacena en el archivo TXT, el nombre del archivo registra el año y el número de líneas, primero lee los registros rastreados, encuentra el resultado de la última solicitud y luego iniciar las solicitudes posteriores.
-
""" 爬取页面数据的爬虫 """ import pathlib as pl import requests import json import time import threading import urllib3 def get_cost_time(start: time.time, end: time.time = None): """ 计算间隔时长的方法 :param start: 起始时间 :param end: 结束时间,默认为空,按最新时间计算 :return: 时分秒格式 """ if not end: end = time.time() cost = end - start days = int(cost / 86400) hours = int(cost % 86400 / 3600) mins = int(cost % 3600 / 60) secs = round(cost % 60, 4) text = '' if days: text = f'{text}{days}天' if hours: text = f'{text}{hours}小时' if mins: text = f'{text}{mins}分钟' if secs: text = f'{text}{secs}秒' return text class PageSpider: def __init__(self, year: int, nrows: int = 500, timeout: int = 30): """ 初始化爬虫的参数 :param year: 下载数据的年份,默认空,不筛选年份,取得全量数据 :param nrows: 每次请求获取的数据行数,默认500,最大30000(服务器自动限制,超过无效) :param timeout: 超时等待时长 """ self.year = year if year else 'all' self.timeout = timeout # 请求数据的地址 self.url = 'https://wabi-us-gov-virginia-api.analysis.usgovcloudapi.net/public/reports/querydata?synchronous=true' # 请求头 self.headers = { # 太长省略,自行在浏览器中复制 } # 默认参数 self.params = { # 太长省略,自行在浏览器中复制 } # 修改默认参数中的每次请求的行数 self.params['queries'][0]['Query']['Commands'][0]['SemanticQueryDataShapeCommand']['Binding']['DataReduction'][ 'Primary']['Window']['Count'] = nrows # 修改默认参数中请求的年份 if self.year != 'all': self.params['queries'][0]['Query']['Commands'][0]['SemanticQueryDataShapeCommand']['Query']['Where'][0][ 'Condition']['In']['Values'][0][0]['Literal']['Value'] = f'{year}L' @classmethod def read_json(cls, file_path: pl.Path): with open(file_path, 'r', encoding='utf-8') as fin: res = json.loads(fin.read()) return res def get_idx_and_rt(self): """ 获取已经爬取过的信息,最大的idx以及请求下一页的参数 """ single = True tmp_path = pl.Path('./tmp/') if not tmp_path.is_dir(): tmp_path.mkdir() files = list(tmp_path.glob(f'{self.year}_part*.txt')) if files: idx = max([int(filename.stem.replace(f'{self.year}_part', '')) for filename in files]) res = self.read_json(tmp_path / f'{self.year}_part{idx}.txt') key = res['results'][0]['result']['data']['dsr']['DS'][0].get('RT') if not key: single = False else: idx = 0 key = None return idx, key, single def make_params(self, key: list = None) -> dict: """ 制作请求体中的参数 :param key: 下一页的关键字RestartTokens,默认空,第一次请求时无需传入该参数 :return: dict """ params = self.params.copy() if key: params['queries'][0]['Query']['Commands'][0]['SemanticQueryDataShapeCommand']['Binding']['DataReduction'][ 'Primary']['Window']['RestartTokens'] = key return params def crawl_pages(self, idx: int = 1, key: list = None): """ 爬取页面并输出TXT文件的方法, :param idx: 爬取的索引值,默认为1,在每行爬取时,代表行数 :param key: 下一页的关键字RestartTokens,默认空,第一次请求时无需传入该参数 :return: None """ start = time.time() while True: # 创建死循环爬取直至结束 try: res = requests.post(url=self.url, headers=self.headers, json=self.make_params(key), timeout=self.timeout) except ( requests.exceptions.ConnectTimeout, requests.exceptions.ConnectionError, urllib3.exceptions.ConnectionError, urllib3.exceptions.ConnectTimeoutError ): # 捕获超时异常 或 连接异常 print(f'{self.year}_part{idx}: timeout, wait 5 seconds retry') time.sleep(5) # 休息5秒后再次请求 continue # 跳过后续步骤 except Exception as e: # 其他异常,打印一下异常信息 print(f'{self.year}_part{idx} Error: {e}') time.sleep(5) # 休息5秒后再次请求 continue # 跳过后续步骤 if res.status_code == 200: with open(f'./tmp/{self.year}_part{idx}.txt', 'w', encoding='utf-8') as fout: fout.write(res.text) if idx % 100 == 0: print(f'{self.year}的第{idx}行数据写入完成,已用时: {get_cost_time(start)}') key = json.loads(res.text)['results'][0]['result']['data']['dsr']['DS'][0].get('RT', None) if not key: # 如果没有RT值,说明已经全部爬取完毕了,打印一下信息退出 print(f'{self.year} completed max_idx is {idx}') return idx += 1 else: # 打印一下信息重新请求 print(f'{self.year}_part{idx} not 200,check please', res.text) continue def mul_crawl(year: int, nrows: int = 2): """ 多线程爬取的方法,注按行爬取 :param year: 需要爬取的年份 :param nrows: 每份爬取的行数,若每次仅爬取1行数据,nrows参数需要为2,才会有下一行,否则都是第一行 """ # 定义爬虫对象 spider = PageSpider(year, nrows=nrows) # 获取爬取对象已爬取的idx,key和是否完成爬取的信号single idx, key, single = spider.get_idx_and_rt() if not single: print(f'{year}年的共{idx}行数据已经全部下载,无需爬取') return print(f'{year}年的爬虫任务启动, 从{idx+1}行开始爬取') spider.crawl_pages(idx+1, key) # 特别注意,已经爬取了idx行,重启时,下一行需要+1,否则重启后,会覆盖一行数据 if __name__ == '__main__': pools = [] for y in range(2009, 2021): pool = threading.Thread( target=mul_crawl, args=(y, 2), name=f'{y}_thread' # 按行爬取,nrows参数需要为2 ) pool.start() pools.append(pool) for pool in pools: pool.join() print('任务全部完成')
-
Ejemplo de ejecución de código:
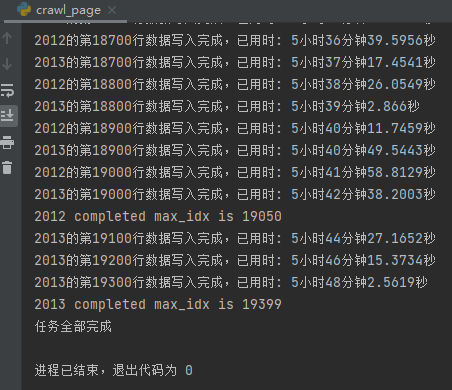
Intercambie tiempo por espacio, solicite solo una línea a la vez, sin pasar por el análisis relacional R
-
Datos analíticos
-
opcion uno
-
La parte difícil de analizar los datos es encontrar la relación entre R. Esta parte se resuelve mediante una consulta manual.Vamos directamente al código:
class ParseData:
"""
解析数据的对象
"""
def __init__(self, file_path: pl.Path = None):
"""
初始化对象
:param file_path: TXT数据存放的路径,默认自身目录下的tmp文件夹
"""
self.file_path = pl.Path('./tmp') if not file_path else file_path
self.files = list(self.file_path.glob('2*.txt'))
self.cols_dict = None
self.colname_dict = {
'D0': 'License Type',
'D1': 'License Number',
'D2': 'Manufacturer Full Name',
'D3': 'Manufacturer ID',
'D4': 'City',
'D5': 'State',
'D6': 'Full Name',
'D7': 'Payment Category',
'D8': 'Covered Recipient ID'
}
self.colname_dict_T = {v: k for k, v in self.colname_dict.items()}
def make_excels(self):
"""
将每个数据文件单独转换为excel数据表用于分析每份数据
:return:
"""
for file in self.files:
with open(file, 'r') as fin:
res = json.loads(fin.read())
dfx = pd.DataFrame(res['results'][0]['result']['data']['dsr']['DS'][0]['PH'][0]['DM0'])
dfx['filename'] = file.stem
dfx[['year', 'part']] = dfx['filename'].str.split('_', expand=True)
dfx['C_count'] = dfx['C'].map(len)
writer = pd.ExcelWriter(self.file_path / f'{file.stem}.xlsx')
dfx.to_excel(writer, sheet_name='data')
for k, v in res['results'][0]['result']['data']['dsr']['DS'][0]['ValueDicts'].items():
dfx = pd.Series(v).to_frame()
dfx.to_excel(writer, sheet_name=k)
writer.save()
print('所有数据均已转为Excel')
def make_single_excel(self):
"""
将所有数据生成一份excel文件,不包含字典
:return:
"""
# 合并成整个文件
df = pd.DataFrame()
for file in self.files:
with open(file, 'r') as fin:
res = json.loads(fin.read())
dfx = pd.DataFrame(res['results'][0]['result']['data']['dsr']['DS'][0]['PH'][0]['DM0'])
dfx['filename'] = file.stem
dfx[['year', 'part']] = dfx['filename'].str.split('_', expand=True)
dfx['C_count'] = dfx['C'].map(len)
df = pd.concat([df, dfx])
return df
def get_cols_dict(self):
"""
读取列关系的字典
:return:
"""
# 读取列字典表
self.cols_dict = pd.read_excel(self.file_path.parent / 'cols_dict.xlsx')
self.cols_dict.set_index('R', inplace=True)
self.cols_dict = self.cols_dict.dropna()
self.cols_dict.drop(columns=['C_count', ], inplace=True)
self.cols_dict.columns = [col.split(':')[-1] for col in self.cols_dict.columns]
self.cols_dict = self.cols_dict.astype('int')
def make_dataframe(self, filename):
"""
读取TXT文件,转换成dataframe
:param filename: 需要转换的文件
:return:
"""
with open(filename, 'r') as fin:
res = json.loads(fin.read())
df0 = pd.DataFrame(res['results'][0]['result']['data']['dsr']['DS'][0]['PH'][0]['DM0'])
df0['R'] = df0['R'].fillna(0)
df0['R'] = df0['R'].map(int)
values_dict = res['results'][0]['result']['data']['dsr']['DS'][0]['ValueDicts']
dfx = []
for idx in df0.index:
row_value = df0.loc[idx, 'C'].copy()
cols = self.cols_dict.loc[int(df0.loc[idx, 'R'])].to_dict()
row = {}
for col in ['License Type', 'License Number', 'Manufacturer Full Name', 'Manufacturer ID', 'City', 'State',
'Full Name', 'Payment Category', 'Disclosure Year', 'Covered Recipient ID', 'Amount of Payment',
'Number of Events Reflected']:
v = cols.get(col)
if v:
value = row_value.pop(0)
if col in self.colname_dict.values():
if not isinstance(value, str):
value_list = values_dict.get(self.colname_dict_T.get(col), [])
value = value_list[value]
row[col] = value
else:
row[col] = None
row['R'] = int(df0.loc[idx, 'R'])
dfx.append(row)
dfx = pd.DataFrame(dfx)
dfx = dfx.fillna(method='ffill')
dfx[['Disclosure Year', 'Number of Events Reflected']] = dfx[
['Disclosure Year', 'Number of Events Reflected']].astype('int')
dfx = dfx[['Covered Recipient ID', 'Full Name', 'License Type', 'License Number', 'Manufacturer ID',
'Manufacturer Full Name', 'City',
'State', 'Payment Category', 'Amount of Payment', 'Number of Events Reflected', 'Disclosure Year',
'R']]
return dfx
def parse_data(self, out_name: str = None):
"""
解析合并数据
:param out_name: 输出的文件名
:return:
"""
df = pd.DataFrame()
for n, f in enumerate(self.files):
dfx = self.make_dataframe(f)
df = pd.concat([df, dfx])
print(f'完成第{n + 1}个文件,剩余{len(self.files) - n - 1}个,共{len(self.files)}个')
df.drop(columns='R').to_csv(self.file_path / f'{out_name}.csv', index=False)
return df
-
Opción II
Al usar la solución 2 para procesar datos, después de realizar datos a posteriori, se encuentra que aún hay dos problemas detallados por resolver:
primero, aparece una nueva palabra clave "Ø" en el valor devuelto. Hay un caso en el que el valor en sí es nulo Después de recorrer los datos, se encuentra que solo hay 3 valores diferentes (60, 128, 2048), por lo tanto, col_dict se hace manualmente (ver el código para más detalles). \
class ParseDatav2:
"""
解析数据的对象第二版,将按行爬取的的json文件,转换成dataframe,增量写入csv文件,
因每次请求一行,首行数据不存在与上一行相同情形,因此,除个别本身无数据情况,绝大多数均为完整的12列数据,
"""
def __init__(self):
"""
初始化
"""
# 初始化一行的dataframe,
self.row = pd.DataFrame([
'Covered Recipient ID', 'Full Name', 'License Type', 'License Number', 'Manufacturer ID',
'Manufacturer Full Name', 'City', 'State', 'Payment Category', 'Amount of Payment',
'Number of Events Reflected', 'Disclosure Year'
]).set_index(0)
self.row[0] = None
self.row = self.row.T
self.row['idx'] = None
# 根据 Ø 值的不同选择不同的列,目前仅三种不同的Ø值,注0为默认值,指包含所有列
self.col_dict = {
# 完整的12列
0: ['License Type', 'License Number', 'Manufacturer Full Name', 'Manufacturer ID', 'City', 'State',
'Full Name', 'Payment Category', 'Disclosure Year', 'Covered Recipient ID', 'Amount of Payment',
'Number of Events Reflected'],
# 有4列是空值,分别是 'Manufacturer Full Name', 'Manufacturer ID', 'City', 'State'
60: ['License Type', 'License Number',
'Full Name', 'Payment Category', 'Disclosure Year', 'Covered Recipient ID', 'Amount of Payment',
'Number of Events Reflected'],
# 有1列是空值,是 'Payment Category'
128: ['License Type', 'License Number', 'Manufacturer Full Name', 'Manufacturer ID', 'City', 'State',
'Full Name', 'Disclosure Year', 'Covered Recipient ID', 'Amount of Payment',
'Number of Events Reflected'],
# 有1列是空值,是 'Number of Events Reflected'
2048: ['License Type', 'License Number', 'Manufacturer Full Name', 'Manufacturer ID', 'City', 'State',
'Full Name', 'Payment Category', 'Disclosure Year', 'Covered Recipient ID', 'Amount of Payment'],
}
# 列名转换字典
self.colname_dict = {
'License Type': 'D0',
'License Number': 'D1',
'Manufacturer Full Name': 'D2',
'Manufacturer ID': 'D3',
'City': 'D4',
'State': 'D5',
'Full Name': 'D6',
'Payment Category': 'D7',
'Covered Recipient ID': 'D8'
}
# 储存爬取的json文件的路径
self.data_path = pl.Path('./tmp')
# 获取json文件的迭代器
self.files = self.data_path.glob('*.txt')
# 初始化输出文件的名称及路径
self.file_name = self.data_path.parent / 'data.csv'
def create_csv(self):
"""
先输出一个CSV文件头用于增量写入数据
:return:
"""
self.row.drop(0, axis=0).to_csv(self.file_name, index=False)
def parse_data(self, filename: pl.Path):
"""
读取按1行数据请求获取的json文件,一行数据
:param filename: json文件的路径
:return: None
"""
row = self.row.copy() # 复制一行dataframe用于后续修改
res = PageSpider.read_json(filename)
# 获取数据中的valuedicts
valuedicts = res['results'][0]['result']['data']['dsr']['DS'][0]['ValueDicts']
# 获取数据中每行的数据
row_values = res['results'][0]['result']['data']['dsr']['DS'][0]['PH'][0]['DM0'][0]['C']
# 获取数据中的'Ø'值(若有),该值代表输出的行中,存在空白部分,用于确定数据列
cols = ic(self.col_dict.get(
res['results'][0]['result']['data']['dsr']['DS'][0]['PH'][0]['DM0'][0].get('Ø', 0)
))
# 遍历每行数据,修改row这个dataframe的值
for col, value in zip(cols, row_values):
ic(col, value)
colname = self.colname_dict.get(col) # colname转换,D0~D8
if colname: # 如果非空,则需要转换值
value = valuedicts.get(self.colname_dict.get(col))[0]
# 修改dataframe数据
row.loc[0, col] = value
# 写入索引值
row['idx'] = int(filename.stem.split('_')[-1].replace('part', ''))
return row
def run(self):
"""
运行写入程序
"""
self.create_csv()
for idx, filename in enumerate(self.files):
row = self.parse_data(filename)
row.to_csv(self.file_name, mode='a', header=None, index=False)
print(f'第{idx + 1}个文件{filename.stem}写入表格成功')
print('全部文件写入完成')
En segundo lugar, para cada fila de solicitudes de datos, nrows debe establecerse en 2 y la última fila de datos no se puede obtener de esta manera. Por lo tanto, la última fila de datos debe analizarse a partir de los últimos datos json devueltos (consulte el clase LastRow para más detalles)
class LastRow:
"""
获取并写入最后一行数据的类
由于每次请求一行数据的方式,存在缺陷,无法获取到最后一行数据,
本方法是对最后一个能够获取的json(倒数第二行)进行解析,取得最后一行数据,
本方法存在缺陷,即默认最后一行“Amount of Payment”列值一定与倒数第二行不同,
目前2009年至2020年共12年的数据中,均满足上述条件,没有出错。
除本方法外,还可以通过逆转排序请求的方式,获取最后一行数据
"""
def __init__(self):
"""
初始化
"""
self.file_path = pl.Path('./tmp') # 存储爬取json数据的路径
self.files_df = pd.DataFrame() # 初始化最后一份请求的dataframe
# 列名对应的字典
self.colname_dict = {
'D0': 'License Type',
'D1': 'License Number',
'D2': 'Manufacturer Full Name',
'D3': 'Manufacturer ID',
'D4': 'City',
'D5': 'State',
'D6': 'Full Name',
'D7': 'Payment Category',
'year': 'Disclosure Year',
'D8': 'Covered Recipient ID',
'M0': 'Amount of Payment',
'M1': 'Number of Events Reflected'
}
self.data = pd.DataFrame() # 初始化最后一行数据data
def get_last_file(self):
"""
遍历文件夹,取得最后一份请求的dataframe
"""
self.files_df = pd.DataFrame(list(self.file_path.glob('*.txt')), columns=['filename'])
self.files_df[['year', 'idx']] = self.files_df['filename'].map(lambda x: x.stem).str.split('_', expand=True)
self.files_df['idx'] = self.files_df['idx'].str.replace('part', '')
self.files_df['idx'] = self.files_df['idx'].astype(int)
self.files_df.sort_values(by=['year', 'idx'], inplace=True)
self.files_df = self.files_df.drop_duplicates('year', keep='last')
def get_last_row(self, ser: pd.Series) -> pd.DataFrame:
"""
解析文件,获取最后一行的数据
:param ser: 一行文件信息的series
"""
# 读取json数据
res = PageSpider.read_json(ser['filename'])
# 获取values_dict
values_dict = res['results'][0]['result']['data']['dsr']['DS'][0]['ValueDicts']
# 获取文件中的第一行数据
row_values = res['results'][0]['result']['data']['dsr']['DS'][0]['PH'][0]['DM0'][0]['C']
# 获取文件中的下一行数据,因文件是倒数第二行的数据,因此下一行即为最后一行
next_row_values = res['results'][0]['result']['data']['dsr']['DS'][0]['PH'][0]['DM0'][1]['C']
# 初始化Series
row = pd.Series()
# 解析数据填充series
for k, col in self.colname_dict.items():
value = row_values.pop(0)
if k.startswith('D'): # 如果K值是D开头
values = values_dict[k]
if len(values) == 2:
value = next_row_values.pop(0)
value = values[-1]
elif k == 'year':
pass
else:
if next_row_values:
value = next_row_values.pop(0)
row[col] = value
row['idx'] = ser['idx'] + 1
row = row.to_frame().T
return row
def run(self):
"""
运行获取最后一行数据的方法
"""
self.get_last_file()
for i in self.files_df.index:
self.data = pd.concat([self.data, self.get_last_row(self.files_df.loc[i])])
self.data = self.data[[
'Covered Recipient ID', 'Full Name', 'License Type', 'License Number', 'Manufacturer ID',
'Manufacturer Full Name', 'City', 'State', 'Payment Category', 'Amount of Payment',
'Number of Events Reflected', 'Disclosure Year', 'idx'
]]
filename = self.file_path.parent / 'data.csv'
self.data.to_csv(filename, mode='a', index=False, header=None)
return self.data
-
Visualización de resultados

año 2010
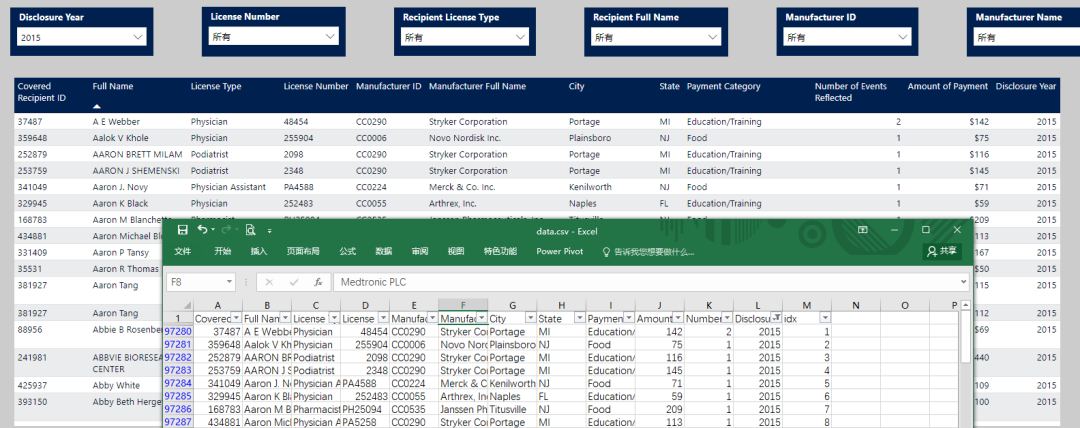
2015
finales de 2020
-
Pensamiento extendido
Si combina el esquema 1 anterior con el esquema 2, clasifique todas las muestras de filas de diferentes relaciones R, use el esquema 2 para rastrear una pequeña cantidad de ejemplos parciales, luego obtenga el diccionario completo de relaciones R y luego use el esquema 1 para rastrear y analizar, ahorrará mucho tiempo. Este método se puede considerar cuando la cantidad de datos supera con creces la cantidad actual.
Resumir
En el proceso de completar todo el proyecto, pasé por: oscuro y genial (completé algunas funciones del rastreador en menos de 1 hora) -> confundido (JS falló al revés, incapaz de resumir la relación entre R) -> ansiedad y irritabilidad (preocupación por no poder completar la tarea, consultar manualmente las reglas Más de 5 horas) -> Kaiqiao (descubrir repentinamente nuevas ideas durante el proceso de revisión) una serie de procesos. El resultado final fue una finalización relativamente fluida de toda la tarea, y la sensación más grande fue el desarrollo de ideas: cuando falla un camino, tal vez una dirección diferente pueda resolver el problema (Nota: el parámetro de conteo 500 se usó desde el principio, pero el número de solicitudes ha ido en aumento (el número de filas, y nunca pensé que un pequeño cambio como reducir el número de filas solicitadas podría traer un gran avance).
Soy Zheng Yin esperando su atención.
