Segmentación de instancias 1 para la escuela gratuita: Tensorflow2 construye la plataforma de segmentación de instancias Mask R-CNN
- prólogo del estudio
- ¿Qué es Máscara R-CNN?
- Descarga del código fuente
- Enmascarar ideas de implementación de R-CNN
-
- 1. Parte de predicción
-
- 1. Introducción a la red troncal
- 2. Construcción de Pirámide de Características FPN
- 3. Obtener el buzón de sugerencias de Propuestas
- 4. Decodificación del buzón de sugerencias de propuestas
- 5. Utilice el cuadro de sugerencias de propuestas (Roi Align)
- 6. Decodificación del cuadro de predicción
- 7. Adquisición de información de segmentación semántica de máscara
- la parte de entrenamiento
- Entrena tu propio modelo de Máscara-RCNN
prólogo del estudio
Implementé Mask RCNN con tensorflow2, al menos para estar al día, ¿verdad?

¿Qué es Máscara R-CNN?

Mask R-CNN es la obra maestra de He Kaiming en 2017. Realiza la segmentación de instancias mientras realiza la detección de objetivos y ha logrado excelentes resultados.
El diseño de su red también es relativamente simple: sobre la base de Faster R-CNN, se agrega una rama a las dos ramas originales (clasificación + regresión de coordenadas) para la segmentación semántica.
Descarga del código fuente
https://github.com/bubbliiiing/mask-rcnn-tf2 Si
te gusta, puedes hacer clic en una estrella.
Enmascarar ideas de implementación de R-CNN
1. Parte de predicción
1. Introducción a la red troncal
Mask-RCNN usa Resnet101 como la red de extracción de características principal, que corresponde a la parte CNN en la imagen. Tiene requisitos de tamaño para la imagen de entrada, que debe ser divisible a la sexta potencia de 2. Después de la extracción de características, las capas de características cuya longitud y anchura se comprimen dos, tres, cuatro y cinco veces se utilizan para construir la estructura piramidal de características.
ResNet101 tiene dos bloques básicos, llamados Conv Block y Identity Block. Las dimensiones de la entrada y salida del Conv Block son diferentes, por lo que no se pueden conectar en serie. Su función es cambiar la dimensión de la red; la dimensión de entrada y salida del bloque de identidad son diferentes Las dimensiones son las mismas y se pueden conectar en serie para profundizar la red.
La estructura de Conv Block es la siguiente:
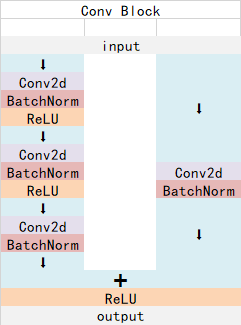
La estructura de Identity Block es la siguiente:

Ambas son estructuras de red residuales.
Tomando como ejemplo la forma de entrada del conjunto de datos de coco utilizado oficialmente, la forma de entrada es 1024x1024, y los cambios de forma son los siguientes:

sacamos los resultados de la compresión de longitud y anchura dos, tres, cuatro y cinco veces para construir la estructura de la pirámide característica.
Código de implementación:
from tensorflow.keras.layers import (Activation, Add, BatchNormalization,
Conv2D, MaxPooling2D, ZeroPadding2D)
from tensorflow.keras.regularizers import l2
#----------------------------------------------#
# conv_block和identity_block的区别主要就是:
# conv_block会压缩输入进来的特征层的宽高
# identity_block用于加深网络
#----------------------------------------------#
def identity_block(input_tensor, kernel_size, filters, stage, block, use_bias=True, weight_decay=0, train_bn=True):
nb_filter1, nb_filter2, nb_filter3 = filters
conv_name_base = 'res' + str(stage) + block + '_branch'
bn_name_base = 'bn' + str(stage) + block + '_branch'
x = Conv2D(nb_filter1, (1, 1), name=conv_name_base + '2a', use_bias=use_bias, kernel_regularizer=l2(weight_decay))(input_tensor)
x = BatchNormalization(name=bn_name_base + '2a')(x, training=train_bn)
x = Activation('relu')(x)
x = Conv2D(nb_filter2, (kernel_size, kernel_size), padding='same', name=conv_name_base + '2b', use_bias=use_bias, kernel_regularizer=l2(weight_decay))(x)
x = BatchNormalization(name=bn_name_base + '2b')(x, training=train_bn)
x = Activation('relu')(x)
x = Conv2D(nb_filter3, (1, 1), name=conv_name_base + '2c', use_bias=use_bias, kernel_regularizer=l2(weight_decay))(x)
x = BatchNormalization(name=bn_name_base + '2c')(x, training=train_bn)
x = Add()([x, input_tensor])
x = Activation('relu', name='res' + str(stage) + block + '_out')(x)
return x
def conv_block(input_tensor, kernel_size, filters, stage, block, strides=(2, 2), use_bias=True, weight_decay=0, train_bn=True):
nb_filter1, nb_filter2, nb_filter3 = filters
conv_name_base = 'res' + str(stage) + block + '_branch'
bn_name_base = 'bn' + str(stage) + block + '_branch'
x = Conv2D(nb_filter1, (1, 1), strides=strides, name=conv_name_base + '2a', use_bias=use_bias, kernel_regularizer=l2(weight_decay))(input_tensor)
x = BatchNormalization(name=bn_name_base + '2a')(x, training=train_bn)
x = Activation('relu')(x)
x = Conv2D(nb_filter2, (kernel_size, kernel_size), padding='same', name=conv_name_base + '2b', use_bias=use_bias, kernel_regularizer=l2(weight_decay))(x)
x = BatchNormalization(name=bn_name_base + '2b')(x, training=train_bn)
x = Activation('relu')(x)
x = Conv2D(nb_filter3, (1, 1), name=conv_name_base + '2c', use_bias=use_bias, kernel_regularizer=l2(weight_decay))(x)
x = BatchNormalization(name=bn_name_base + '2c')(x, training=train_bn)
shortcut = Conv2D(nb_filter3, (1, 1), strides=strides, name=conv_name_base + '1', use_bias=use_bias, kernel_regularizer=l2(weight_decay))(input_tensor)
shortcut = BatchNormalization(name=bn_name_base + '1')(shortcut, training=train_bn)
x = Add()([x, shortcut])
x = Activation('relu', name='res' + str(stage) + block + '_out')(x)
return x
#----------------------------------------------#
# 获得resnet的主干部分
#----------------------------------------------#
def get_resnet(input_image, train_bn=True, weight_decay=0):
#----------------------------------------------#
# 假设输入进来的图片为1024,1024,3
#----------------------------------------------#
# 1024,1024,3 -> 512,512,64
x = ZeroPadding2D((3, 3))(input_image)
x = Conv2D(64, (7, 7), strides=(2, 2), name='conv1', use_bias=True, kernel_regularizer=l2(weight_decay))(x)
x = BatchNormalization(name='bn_conv1')(x, training=train_bn)
x = Activation('relu')(x)
# 512,512,64 -> 256,256,64
x = MaxPooling2D((3, 3), strides=(2, 2), padding="same")(x)
C1 = x
# 256,256,64 -> 256,256,256
x = conv_block(x, 3, [64, 64, 256], stage=2, block='a', strides=(1, 1), weight_decay=weight_decay, train_bn=train_bn)
x = identity_block(x, 3, [64, 64, 256], stage=2, block='b', weight_decay=weight_decay, train_bn=train_bn)
x = identity_block(x, 3, [64, 64, 256], stage=2, block='c', weight_decay=weight_decay, train_bn=train_bn)
C2 = x
# 256,256,256 -> 128,128,512
x = conv_block(x, 3, [128, 128, 512], stage=3, block='a', weight_decay=weight_decay, train_bn=train_bn)
x = identity_block(x, 3, [128, 128, 512], stage=3, block='b', weight_decay=weight_decay, train_bn=train_bn)
x = identity_block(x, 3, [128, 128, 512], stage=3, block='c', weight_decay=weight_decay, train_bn=train_bn)
x = identity_block(x, 3, [128, 128, 512], stage=3, block='d', weight_decay=weight_decay, train_bn=train_bn)
C3 = x
# 128,128,512 -> 64,64,1024
x = conv_block(x, 3, [256, 256, 1024], stage=4, block='a', weight_decay=weight_decay, train_bn=train_bn)
block_count = 22
for i in range(block_count):
x = identity_block(x, 3, [256, 256, 1024], stage=4, block=chr(98 + i), weight_decay=weight_decay, train_bn=train_bn)
C4 = x
# 64,64,1024 -> 32,32,2048
x = conv_block(x, 3, [512, 512, 2048], stage=5, block='a', weight_decay=weight_decay, train_bn=train_bn)
x = identity_block(x, 3, [512, 512, 2048], stage=5, block='b', weight_decay=weight_decay, train_bn=train_bn)
x = identity_block(x, 3, [512, 512, 2048], stage=5, block='c', weight_decay=weight_decay, train_bn=train_bn)
C5 = x
return [C1, C2, C3, C4, C5]
2. Construcción de Pirámide de Características FPN

La construcción de la pirámide de funciones FPN es lograr una fusión de funciones a múltiples escalas. En Mask R-CNN, sacamos los resultados de comprimir la longitud y el ancho de dos veces C2, tres veces C3, cuatro veces C4 y cinco veces C5 en la red troncal de extracción de características Construya la estructura piramidal de características.

Los P2, P3, P4, P5 y P6 extraídos se pueden usar como la capa de características efectiva de la red RPN. La red de buzones de sugerencias de RPN se usa para realizar la siguiente operación en la capa de características efectiva y se decodifica el marco a priori. para obtener el marco de sugerencia.
Los P2, P3, P4 y P5 extraídos se pueden usar como capas de características efectivas de las redes Classifier y Mask. La red de marcos de predicción del Clasificador se usa para realizar la siguiente operación en la capa de características efectiva, y el marco propuesto se decodifica para Para obtener el cuadro de predicción final, se utiliza la red de segmentación semántica Máscara, el siguiente paso se realiza sobre la capa de características efectiva para obtener los resultados de segmentación semántica dentro de cada cuadro de predicción.
El código de implementación es el siguiente:
#----------------------------------------------#
# 组合成特征金字塔的结构
# P5长宽共压缩了5次
# P5为32,32,256
#----------------------------------------------#
P5 = Conv2D(config.TOP_DOWN_PYRAMID_SIZE, (1, 1), name='fpn_c5p5')(C5)
#----------------------------------------------#
# 将P5上采样和P4进行相加
# P4长宽共压缩了4次
# P4为64,64,256
#----------------------------------------------#
P4 = Add(name="fpn_p4add")([
UpSampling2D(size=(2, 2), name="fpn_p5upsampled")(P5),
Conv2D(config.TOP_DOWN_PYRAMID_SIZE, (1, 1), name='fpn_c4p4')(C4)])
#----------------------------------------------#
# 将P4上采样和P3进行相加
# P3长宽共压缩了3次
# P3为128,128,256
#----------------------------------------------#
P3 = Add(name="fpn_p3add")([
UpSampling2D(size=(2, 2), name="fpn_p4upsampled")(P4),
Conv2D(config.TOP_DOWN_PYRAMID_SIZE, (1, 1), name='fpn_c3p3')(C3)])
#----------------------------------------------#
# 将P3上采样和P2进行相加
# P2长宽共压缩了2次
# P2为256,256,256
#----------------------------------------------#
P2 = Add(name="fpn_p2add")([
UpSampling2D(size=(2, 2), name="fpn_p3upsampled")(P3),
Conv2D(config.TOP_DOWN_PYRAMID_SIZE, (1, 1), name='fpn_c2p2')(C2)])
#-----------------------------------------------------------#
# 各自进行一次256通道的卷积,此时P2、P3、P4、P5通道数相同
# P2为256,256,256
# P3为128,128,256
# P4为64,64,256
# P5为32,32,256
#-----------------------------------------------------------#
P2 = Conv2D(config.TOP_DOWN_PYRAMID_SIZE, (3, 3), padding="SAME", name="fpn_p2")(P2)
P3 = Conv2D(config.TOP_DOWN_PYRAMID_SIZE, (3, 3), padding="SAME", name="fpn_p3")(P3)
P4 = Conv2D(config.TOP_DOWN_PYRAMID_SIZE, (3, 3), padding="SAME", name="fpn_p4")(P4)
P5 = Conv2D(config.TOP_DOWN_PYRAMID_SIZE, (3, 3), padding="SAME", name="fpn_p5")(P5)
#----------------------------------------------#
# 在建议框网络里面还有一个P6用于获取建议框
# P5为16,16,256
#----------------------------------------------#
P6 = MaxPooling2D(pool_size=(1, 1), strides=2, name="fpn_p6")(P5)
#----------------------------------------------#
# P2, P3, P4, P5, P6可以用于获取建议框
#----------------------------------------------#
rpn_feature_maps = [P2, P3, P4, P5, P6]
#----------------------------------------------#
# P2, P3, P4, P5用于获取mask信息
#----------------------------------------------#
mrcnn_feature_maps = [P2, P3, P4, P5]
3. Obtener el buzón de sugerencias de Propuestas
La capa de características efectiva obtenida en el paso anterior es el Mapa de características de la imagen, que tiene dos aplicaciones, una se usa en combinación con ROIAsign y la otra es para ingresar a Region Proposal Network para obtener el marco de propuesta.
Al obtener el marco de propuesta, las capas de características efectivas que usamos son P2, P3, P4, P5 y P6. Usan la misma red de marco de propuesta RPN para obtener los parámetros de ajuste de marco a priori y si el marco a priori contiene objetos.
En Mask R-cnn, la estructura de la red de cajas de propuestas de RPN es similar a la red de cajas de propuestas de RPN en Faster RCNN.
Primero, se realiza una convolución de 3x3 con un número de canal de 512.
Luego realice una convolución de anclas_por_ubicación x 4 y una convolución de anclas_por_ubicación x 2 respectivamente .
La convolución de anclas_por_ubicación x 4 se usa para predecir el cambio de cada cuadro anterior en cada punto de cuadrícula en la capa de características comunes. (¿Por qué es un cambio? Esto se debe a que el resultado de la predicción de Faster-RCNN debe combinarse con el cuadro anterior para obtener el cuadro de predicción, y el resultado de la predicción es el cambio del cuadro anterior).
La convolución de anclas_por_ubicación x 2 se usa para predecir si hay un objeto dentro de cada cuadro de predicción en cada punto de cuadrícula en la capa de características comunes .
Cuando la forma de nuestra imagen de entrada es 1024x1024x3, la forma de la capa de características comunes es 256x256x256, 128x128x256, 64x64x256, 32x32x256, 16x16x256, lo que equivale a dividir la imagen de entrada en cuadrículas de diferentes tamaños, y luego cada cuadrícula existe de forma predeterminada 3 (anchors_per_location) cajas a priori, que tienen diferentes tamaños y están densamente empaquetadas en la imagen.
El resultado de la convolución de anclas_por_ubicación x 4 ajustará estas casillas anteriores para obtener una nueva casilla.
La convolución de anclas_por_ubicación x 2 determinará si el nuevo cuadro obtenido arriba contiene objetos.
En este punto podemos obtener algunos cuadros útiles, que usarán la convolución de anclas_por_ubicación x 2 para determinar si hay un objeto.
Llegados a este punto, solo se trata de una tosca adquisición de un buzón, es decir, un buzón de sugerencias . Luego seguiremos buscando cosas en el buzón de sugerencias .
El código de implementación es:
#------------------------------------#
# 五个不同大小的特征层会传入到
# RPN当中,获得建议框
#------------------------------------#
def rpn_graph(feature_map, anchors_per_location, weight_decay=0):
#------------------------------------#
# 利用一个3x3卷积进行特征整合
#------------------------------------#
shared = Conv2D(512, (3, 3), padding='same', activation='relu',
name='rpn_conv_shared', kernel_regularizer=l2(weight_decay))(feature_map)
#------------------------------------#
# batch_size, num_anchors, 2
# 代表这个先验框是否包含物体
#------------------------------------#
x = Conv2D(anchors_per_location * 2, (1, 1), padding='valid', activation='linear', name='rpn_class_raw', kernel_regularizer=l2(weight_decay))(shared)
rpn_class_logits = Reshape([-1,2])(x)
rpn_probs = Activation("softmax", name="rpn_class_xxx")(rpn_class_logits)
#------------------------------------#
# batch_size, num_anchors, 4
# 这个先验框的调整参数
#------------------------------------#
x = Conv2D(anchors_per_location * 4, (1, 1), padding="valid", activation='linear', name='rpn_bbox_pred', kernel_regularizer=l2(weight_decay))(shared)
rpn_bbox = Reshape([-1, 4])(x)
return [rpn_class_logits, rpn_probs, rpn_bbox]
#------------------------------------#
# 建立建议框网络模型
# RPN模型
#------------------------------------#
def build_rpn_model(anchors_per_location, depth, weight_decay=0):
input_feature_map = Input(shape=[None, None, depth], name="input_rpn_feature_map")
outputs = rpn_graph(input_feature_map, anchors_per_location, weight_decay=weight_decay)
return Model([input_feature_map], outputs, name="rpn_model")
4. Decodificación del buzón de sugerencias de propuestas
A través del segundo paso, obtenemos los resultados de predicción de muchas cajas a priori. El resultado de la predicción consta de dos partes.
La convolución de anclas_por_ubicación x 4 se usa para predecir el cambio de cada cuadro anterior en cada punto de cuadrícula en la capa de entidades efectiva . **
La convolución de anclas_por_ubicación x 1 se usa para predecir si hay un objeto dentro de cada cuadro de predicción en cada punto de cuadrícula en la capa de entidades efectiva .
Es equivalente a dividir toda la imagen en varias grillas, luego establecer 3 casillas a priori desde el centro de cada grilla, cuando la imagen de entrada es 1024, 1024, 3, el total de casillas a priori es 196608+49152+12288+ 3072+768 = 261,888
Cuando la forma de la imagen de entrada es diferente, el número de cuadros a priori también cambiará.
Aunque el marco a priori puede representar cierta información de posición de marco e información de tamaño de marco , es limitado y no puede representar ninguna situación, por lo que debe ajustarse.
El anclas_por_ubicación en anclas_por_ubicación x 4 indica el número de casillas a priori contenidas en este punto de cuadrícula, y 4 indica el ajuste del centro y la longitud y anchura de la casilla.
El código de implementación es el siguiente:
#------------------------------------------------------------------#
# 利用先验框调整参数调整先验框,获得建议框的坐标
#------------------------------------------------------------------#
def apply_box_deltas_graph(boxes, deltas):
#---------------------------------------#
# 计算先验框的中心和宽高
#---------------------------------------#
height = boxes[:, 2] - boxes[:, 0]
width = boxes[:, 3] - boxes[:, 1]
center_y = boxes[:, 0] + 0.5 * height
center_x = boxes[:, 1] + 0.5 * width
#---------------------------------------#
# 计算出调整后的先验框的中心和宽高
#---------------------------------------#
center_y += deltas[:, 0] * height
center_x += deltas[:, 1] * width
height *= tf.math.exp(deltas[:, 2])
width *= tf.math.exp(deltas[:, 3])
#---------------------------------------#
# 计算左上角和右下角的点的坐标
#---------------------------------------#
y1 = center_y - 0.5 * height
x1 = center_x - 0.5 * width
y2 = y1 + height
x2 = x1 + width
result = tf.stack([y1, x1, y2, x2], axis=1, name="apply_box_deltas_out")
return result
def clip_boxes_graph(boxes, window):
wy1, wx1, wy2, wx2 = tf.split(window, 4)
y1, x1, y2, x2 = tf.split(boxes, 4, axis=1)
y1 = tf.maximum(tf.minimum(y1, wy2), wy1)
x1 = tf.maximum(tf.minimum(x1, wx2), wx1)
y2 = tf.maximum(tf.minimum(y2, wy2), wy1)
x2 = tf.maximum(tf.minimum(x2, wx2), wx1)
clipped = tf.concat([y1, x1, y2, x2], axis=1, name="clipped_boxes")
clipped.set_shape((clipped.shape[0], 4))
return clipped
#----------------------------------------------------------#
# Proposal Layer
# 该部分代码用于将先验框转化成建议框
#----------------------------------------------------------#
class ProposalLayer(Layer):
def __init__(self, proposal_count, nms_threshold, config=None, **kwargs):
super(ProposalLayer, self).__init__(**kwargs)
self.config = config
self.proposal_count = proposal_count
self.nms_threshold = nms_threshold
def call(self, inputs):
#----------------------------------------------------------#
# 输入的inputs有三个内容
# inputs[0] rpn_class : Batch_size, num_anchors, 2
# inputs[1] rpn_bbox : Batch_size, num_anchors, 4
# inputs[2] anchors : Batch_size, num_anchors, 4
#----------------------------------------------------------#
#----------------------------------------------------------#
# 获得先验框内部是否有物体[Batch_size, num_anchors, 1]
#----------------------------------------------------------#
scores = inputs[0][:, :, 1]
#----------------------------------------------------------#
# 获得先验框的调整参数[batch, num_rois, 4]
#----------------------------------------------------------#
deltas = inputs[1]
#----------------------------------------------------------#
# 获得先验框的坐标
#----------------------------------------------------------#
anchors = inputs[2]
#----------------------------------------------------------#
# RPN_BBOX_STD_DEV[0.1 0.1 0.2 0.2] 改变数量级
#----------------------------------------------------------#
deltas = deltas * np.reshape(self.config.RPN_BBOX_STD_DEV, [1, 1, 4])
#----------------------------------------------------------#
# 筛选出得分前6000个的框
#----------------------------------------------------------#
pre_nms_limit = tf.minimum(self.config.PRE_NMS_LIMIT, tf.shape(anchors)[1])
#----------------------------------------------------------#
# 获得这些框的索引
#----------------------------------------------------------#
ix = tf.nn.top_k(scores, pre_nms_limit, sorted=True,
name="top_anchors").indices
#----------------------------------------------------------#
# 获得先验框、及其得分与调整参数
#----------------------------------------------------------#
scores = batch_slice([scores, ix], lambda x, y: tf.gather(x, y),
self.config.IMAGES_PER_GPU)
deltas = batch_slice([deltas, ix], lambda x, y: tf.gather(x, y),
self.config.IMAGES_PER_GPU)
pre_nms_anchors = batch_slice([anchors, ix], lambda a, x: tf.gather(a, x),
self.config.IMAGES_PER_GPU,
names=["pre_nms_anchors"])
#----------------------------------------------------------#
# [batch, pre_nms_limit, (y1, x1, y2, x2)]
# 对先验框进行解码
#----------------------------------------------------------#
boxes = batch_slice([pre_nms_anchors, deltas],
lambda x, y: apply_box_deltas_graph(x, y),
self.config.IMAGES_PER_GPU,
names=["refined_anchors"])
#----------------------------------------------------------#
# [batch, pre_nms_limit, (y1, x1, y2, x2)]
# 防止超出图片范围
#----------------------------------------------------------#
window = np.array([0, 0, 1, 1], dtype=np.float32)
boxes = batch_slice(boxes,
lambda x: clip_boxes_graph(x, window),
self.config.IMAGES_PER_GPU,
names=["refined_anchors_clipped"])
#---------------------------------------------------------#
# 在非极大抑制后
# 获得一个shape为[batch, NMS_ROIS, 4]的proposals
#---------------------------------------------------------#
def nms(boxes, scores):
indices = tf.image.non_max_suppression(
boxes, scores, self.proposal_count,
self.nms_threshold, name="rpn_non_max_suppression")
proposals = tf.gather(boxes, indices)
padding = tf.maximum(self.proposal_count - tf.shape(proposals)[0], 0)
proposals = tf.pad(proposals, [(0, padding), (0, 0)])
return proposals
proposals = batch_slice([boxes, scores], nms, self.config.IMAGES_PER_GPU)
return tf.reshape(proposals, (-1, self.proposal_count, 4))
def compute_output_shape(self, input_shape):
return (None, self.proposal_count, 4)
5. Utilice el cuadro de sugerencias de propuestas (Roi Align)
Tengamos una comprensión general del cuadro de propuesta:
de hecho, el cuadro de propuesta es una proyección preliminar de qué área de la imagen tiene objetos.
De hecho, el funcionamiento de Mask R-CNN aquí es que, a través de la red troncal de extracción de características, podemos obtener múltiples capas de características comunes, y luego el cuadro de propuesta interceptará estas capas de características comunes.
De hecho, cada punto en la capa de características comunes es equivalente a la concentración de todas las características dentro de un área determinada en la imagen original.
El cuadro de sugerencias interceptará su capa de características públicas correspondiente y luego cambiará el tamaño del resultado interceptado. En el modelo clasificador, el contenido interceptado se redimensionará a un tamaño de 7x7x256. En el modelo de máscara, el contenido interceptado se redimensionará a 14x14x256.

Al usar el cuadro de sugerencias para interceptar la capa de entidades común, debe tenerse en cuenta que para encontrar a qué capa de entidades pertenece el cuadro de sugerencias, esto debe juzgarse por el tamaño del cuadro de sugerencias.
En el modelo del clasificador, se utilizará una convolución de 7x7 con un número de canal de 1024 y una convolución de 1x1 con un número de canal de 1024 para convolucionar el área de 7x7x256 obtenida por ROIAlign y el doble de canales. La convolución de 1024 se utiliza para simular el conexión completa de 1024 dos veces, y luego conéctese completamente a num_classes y num_classes * 4, respectivamente, que representan los objetos en este cuadro de propuesta y los parámetros de ajuste de este cuadro de propuesta.
En el modelo de máscara, primero realiza cuatro circunvoluciones de 256 canales de 3x3 en la capa de características locales redimensionada, luego realiza una deconvolución y luego realiza una convolución con la cantidad de canales num_classes, y el resultado final representa cada píxel. La forma final es 28x28xnum_classes, que representa la clase de cada píxel.
El código interceptado por el cuadro de sugerencias para la capa de entidades compartidas es el siguiente:
def log2_graph(x):
return tf.math.log(x) / tf.math.log(2.0)
def parse_image_meta_graph(meta):
"""
将meta里面的参数进行分割
"""
image_id = meta[:, 0]
original_image_shape = meta[:, 1:4]
image_shape = meta[:, 4:7]
window = meta[:, 7:11] # (y1, x1, y2, x2) window of image in in pixels
scale = meta[:, 11]
active_class_ids = meta[:, 12:]
return {
"image_id": image_id,
"original_image_shape": original_image_shape,
"image_shape": image_shape,
"window": window,
"scale": scale,
"active_class_ids": active_class_ids,
}
#----------------------------------------------------------#
# ROIAlign Layer
# 利用建议框在特征层上截取内容
#----------------------------------------------------------#
class PyramidROIAlign(Layer):
def __init__(self, pool_shape, **kwargs):
super(PyramidROIAlign, self).__init__(**kwargs)
self.pool_shape = tuple(pool_shape)
def call(self, inputs):
#----------------------------------------------------------#
# 获得建议框的坐标
#----------------------------------------------------------#
boxes = inputs[0]
#----------------------------------------------------------#
# image_meta包含了一些必要的图片信息
#----------------------------------------------------------#
image_meta = inputs[1]
#----------------------------------------------------------#
# 取出所有的特征层[batch, height, width, channels]
#----------------------------------------------------------#
feature_maps = inputs[2:]
#----------------------------------------------------------#
# 获得建议框的宽高
#----------------------------------------------------------#
y1, x1, y2, x2 = tf.split(boxes, 4, axis=2)
h = y2 - y1
w = x2 - x1
#----------------------------------------------------------#
# 获得输入进来的图像的大小
#----------------------------------------------------------#
image_shape = parse_image_meta_graph(image_meta)['image_shape'][0]
#----------------------------------------------------------#
# 通过建议框的大小找到这个建议框属于哪个特征层
#----------------------------------------------------------#
image_area = tf.cast(image_shape[0] * image_shape[1], tf.float32)
roi_level = log2_graph(tf.sqrt(h * w) / (224.0 / tf.sqrt(image_area)))
roi_level = tf.minimum(5, tf.maximum(2, 4 + tf.cast(tf.round(roi_level), tf.int32)))
roi_level = tf.squeeze(roi_level, 2)
pooled = []
box_to_level = []
# 分别在P2-P5中进行截取
for i, level in enumerate(range(2, 6)):
#-----------------------------------------------#
# 找到每个特征层对应的建议框
#-----------------------------------------------#
ix = tf.where(tf.equal(roi_level, level))
level_boxes = tf.gather_nd(boxes, ix)
box_to_level.append(ix)
#-----------------------------------------------#
# 获得这些建议框所属的图片
#-----------------------------------------------#
box_indices = tf.cast(ix[:, 0], tf.int32)
# 停止梯度下降
level_boxes = tf.stop_gradient(level_boxes)
box_indices = tf.stop_gradient(box_indices)
#--------------------------------------------------------------------------#
# 利用建议框对特征层进行截取
# [batch * num_boxes, pool_height, pool_width, channels]
#--------------------------------------------------------------------------#
pooled.append(tf.image.crop_and_resize(
feature_maps[i], level_boxes, box_indices, self.pool_shape,
method="bilinear"))
pooled = tf.concat(pooled, axis=0)
#--------------------------------------------------------------------------#
# 将顺序和所属的图片进行堆叠
#--------------------------------------------------------------------------#
box_to_level = tf.concat(box_to_level, axis=0)
box_range = tf.expand_dims(tf.range(tf.shape(box_to_level)[0]), 1)
box_to_level = tf.concat([tf.cast(box_to_level, tf.int32), box_range], axis=1)
# box_to_level[:, 0]表示第几张图
# box_to_level[:, 1]表示第几张图里的第几个框
sorting_tensor = box_to_level[:, 0] * 100000 + box_to_level[:, 1]
# 进行排序,将同一张图里的某一些聚集在一起
ix = tf.nn.top_k(sorting_tensor, k=tf.shape(
box_to_level)[0]).indices[::-1]
# 按顺序获得图片的索引
ix = tf.gather(box_to_level[:, 2], ix)
pooled = tf.gather(pooled, ix)
#--------------------------------------------------------------------------#
# 重新reshape为如下
# [batch, num_rois, POOL_SIZE, POOL_SIZE, channels]
#--------------------------------------------------------------------------#
shape = tf.concat([tf.shape(boxes)[:2], tf.shape(pooled)[1:]], axis=0)
pooled = tf.reshape(pooled, shape)
return pooled
def compute_output_shape(self, input_shape):
return input_shape[0][:2] + self.pool_shape + (input_shape[2][-1], )
El modelo de clasificación del clasificador y el modelo de máscara de máscara se construyen diamagnéticamente de la siguiente manera:
#------------------------------------#
# 建立classifier模型
# 这个模型的预测结果会调整建议框
# 获得最终的预测框
#------------------------------------#
def fpn_classifier_graph(rois, feature_maps, image_meta,
pool_size, num_classes, train_bn=True,
fc_layers_size=1024, weight_decay=0):
#---------------------------------------------------------------#
# ROI Pooling,利用建议框在特征层上进行截取
# x : [batch, num_rois, POOL_SIZE, POOL_SIZE, channels]
#---------------------------------------------------------------#
x = PyramidROIAlign([pool_size, pool_size], name="roi_align_classifier")([rois, image_meta] + feature_maps)
#------------------------------------------------------------------#
# 利用卷积进行特征整合
# x : [batch, num_rois, 1, 1, fc_layers_size]
#------------------------------------------------------------------#
x = TimeDistributed(Conv2D(fc_layers_size, (pool_size, pool_size), padding="valid", kernel_regularizer=l2(weight_decay)), name="mrcnn_class_conv1")(x)
x = TimeDistributed(BatchNormalization(), name='mrcnn_class_bn1')(x, training=train_bn)
x = Activation('relu')(x)
#------------------------------------------------------------------#
# x : [batch, num_rois, 1, 1, fc_layers_size]
#------------------------------------------------------------------#
x = TimeDistributed(Conv2D(fc_layers_size, (1, 1), kernel_regularizer=l2(weight_decay)), name="mrcnn_class_conv2")(x)
x = TimeDistributed(BatchNormalization(), name='mrcnn_class_bn2')(x, training=train_bn)
x = Activation('relu')(x)
#------------------------------------------------------------------#
# x : [batch, num_rois, fc_layers_size]
#------------------------------------------------------------------#
shared = Lambda(lambda x: K.squeeze(K.squeeze(x, 3), 2), name="pool_squeeze")(x)
#------------------------------------------------------------------#
# Classifier head
# 这个的预测结果代表这个先验框内部的物体的种类
# mrcnn_probs : [batch, num_rois, num_classes]
#------------------------------------------------------------------#
mrcnn_class_logits = TimeDistributed(Dense(num_classes), name='mrcnn_class_logits')(shared)
mrcnn_probs = TimeDistributed(Activation("softmax"), name="mrcnn_class")(mrcnn_class_logits)
#------------------------------------------------------------------#
# BBox head
# 这个的预测结果会对先验框进行调整
# mrcnn_bbox : [batch, num_rois, num_classes, 4]
#------------------------------------------------------------------#
x = TimeDistributed(Dense(num_classes * 4, activation='linear'), name='mrcnn_bbox_fc')(shared)
mrcnn_bbox = Reshape((-1, num_classes, 4), name="mrcnn_bbox")(x)
return mrcnn_class_logits, mrcnn_probs, mrcnn_bbox
#----------------------------------------------#
# 建立mask模型
# 这个模型会利用预测框对特征层进行ROIAlign
# 根据截取下来的特征层进行语义分割
#----------------------------------------------#
def build_fpn_mask_graph(rois, feature_maps, image_meta,
pool_size, num_classes, train_bn=True, weight_decay=0):
#--------------------------------------------------------------------#
# ROI Pooling,利用预测框在特征层上进行截取
# x : batch, num_rois, MASK_POOL_SIZE, MASK_POOL_SIZE, channels
#--------------------------------------------------------------------#
x = PyramidROIAlign([pool_size, pool_size], name="roi_align_mask")([rois, image_meta] + feature_maps)
#--------------------------------------------------------------------#
# x : batch, num_rois, MASK_POOL_SIZE, MASK_POOL_SIZE, 256
#--------------------------------------------------------------------#
x = TimeDistributed(Conv2D(256, (3, 3), padding="same", kernel_regularizer=l2(weight_decay)), name="mrcnn_mask_conv1")(x)
x = TimeDistributed(BatchNormalization(), name='mrcnn_mask_bn1')(x, training=train_bn)
x = Activation('relu')(x)
#--------------------------------------------------------------------#
# x : batch, num_rois, MASK_POOL_SIZE, MASK_POOL_SIZE, 256
#--------------------------------------------------------------------#
x = TimeDistributed(Conv2D(256, (3, 3), padding="same", kernel_regularizer=l2(weight_decay)), name="mrcnn_mask_conv2")(x)
x = TimeDistributed(BatchNormalization(), name='mrcnn_mask_bn2')(x, training=train_bn)
x = Activation('relu')(x)
#--------------------------------------------------------------------#
# x : batch, num_rois, MASK_POOL_SIZE, MASK_POOL_SIZE, 256
#--------------------------------------------------------------------#
x = TimeDistributed(Conv2D(256, (3, 3), padding="same", kernel_regularizer=l2(weight_decay)), name="mrcnn_mask_conv3")(x)
x = TimeDistributed(BatchNormalization(), name='mrcnn_mask_bn3')(x, training=train_bn)
x = Activation('relu')(x)
#--------------------------------------------------------------------#
# x : batch, num_rois, MASK_POOL_SIZE, MASK_POOL_SIZE, 256
#--------------------------------------------------------------------#
x = TimeDistributed(Conv2D(256, (3, 3), padding="same", kernel_regularizer=l2(weight_decay)), name="mrcnn_mask_conv4")(x)
x = TimeDistributed(BatchNormalization(), name='mrcnn_mask_bn4')(x, training=train_bn)
x = Activation('relu')(x)
#--------------------------------------------------------------------#
# x : batch, num_rois, 2xMASK_POOL_SIZE, 2xMASK_POOL_SIZE, 256
#--------------------------------------------------------------------#
x = TimeDistributed(Conv2DTranspose(256, (2, 2), strides=2, activation="relu", kernel_regularizer=l2(weight_decay)), name="mrcnn_mask_deconv")(x)
#--------------------------------------------------------------------#
# 反卷积后再次进行一个1x1卷积调整通道,
# 使其最终数量为numclasses,代表分的类
# x : batch, num_rois, 2xMASK_POOL_SIZE, 2xMASK_POOL_SIZE, numclasses
#--------------------------------------------------------------------#
x = TimeDistributed(Conv2D(num_classes, (1, 1), strides=1, activation="sigmoid", kernel_regularizer=l2(weight_decay)), name="mrcnn_mask")(x)
return x
6. Decodificación del cuadro de predicción
La caja propuesta obtenida en la cuarta parte también representa algunas zonas de la imagen, que también juega el papel de caja a priori en el modelo clasificador posterior.
Es decir, el resultado de la predicción del modelo clasificador representa el tipo y los parámetros de ajuste del objeto dentro del cuadro de propuesta.
El resultado del ajuste del cuadro de sugerencias, es decir, el resultado final de la predicción, el resultado de la predicción se puede dibujar en la imagen.
El proceso de decodificación del marco de predicción incluye los siguientes pasos:
1. Sacar el marco de sugerencia que no pertenece al fondo y cuya puntuación es mayor que config.DETECTION_MIN_CONFIDENCE.
2. Luego use los resultados de predicción del cuadro propuesto y el modelo clasificador para decodificar y obtener la posición del cuadro de predicción final.
3. Use la puntuación y la posición del cuadro de predicción final para la supresión no máxima para evitar la detección repetida.
El código para el proceso de decodificación del buzón de sugerencias es el siguiente:
#----------------------------------------------------------#
# 利用classifier的预测结果对建议框进行调整获得预测框
# 获得每一个预测框的种类
#----------------------------------------------------------#
def refine_detections_graph(rois, probs, deltas, window, config):
#----------------------------------------------------------#
# 输入为:
# rois : N, 4
# probs : N, num_classes
# deltas : N, num_classes, 4
# window : 4,
#
# 输出为:
# detections : num_detections, 6
#----------------------------------------------------------#
#----------------------------------------------------------#
# 找到得分最高的类
#----------------------------------------------------------#
class_ids = tf.argmax(probs, axis=1, output_type=tf.int32)
#----------------------------------------------------------#
# 序号+类,用于取出成绩与建议框的调整参数
#----------------------------------------------------------#
indices = tf.stack([tf.range(probs.shape[0]), class_ids], axis=1)
#----------------------------------------------------------#
# 取出成绩与建议框的调整参数
#----------------------------------------------------------#
class_scores = tf.gather_nd(probs, indices)
deltas_specific = tf.gather_nd(deltas, indices)
#----------------------------------------------------------#
# 进行解码
# refined_rois : boxes, 4
#----------------------------------------------------------#
refined_rois = apply_box_deltas_graph(rois, deltas_specific * config.BBOX_STD_DEV)
refined_rois = clip_boxes_graph(refined_rois, window)
#----------------------------------------------------------#
# 去除背景和得分小的区域
#----------------------------------------------------------#
keep = tf.where(class_ids > 0)[:, 0]
if config.DETECTION_MIN_CONFIDENCE:
conf_keep = tf.where(class_scores >= config.DETECTION_MIN_CONFIDENCE)[:, 0]
keep = tf.compat.v1.sets.set_intersection(tf.expand_dims(keep, 0),
tf.expand_dims(conf_keep, 0))
keep = tf.compat.v1.sparse_tensor_to_dense(keep)[0]
#----------------------------------------------------------#
# 获得除去背景并且得分较高的框还有种类与得分
#----------------------------------------------------------#
pre_nms_class_ids = tf.gather(class_ids, keep)
pre_nms_scores = tf.gather(class_scores, keep)
pre_nms_rois = tf.gather(refined_rois, keep)
unique_pre_nms_class_ids = tf.unique(pre_nms_class_ids)[0]
def nms_keep_map(class_id):
ixs = tf.where(tf.equal(pre_nms_class_ids, class_id))[:, 0]
class_keep = tf.image.non_max_suppression(
tf.gather(pre_nms_rois, ixs),
tf.gather(pre_nms_scores, ixs),
max_output_size=config.DETECTION_MAX_INSTANCES,
iou_threshold=config.DETECTION_NMS_THRESHOLD)
class_keep = tf.gather(keep, tf.gather(ixs, class_keep))
gap = config.DETECTION_MAX_INSTANCES - tf.shape(class_keep)[0]
class_keep = tf.pad(class_keep, [(0, gap)],
mode='CONSTANT', constant_values=-1)
class_keep.set_shape([config.DETECTION_MAX_INSTANCES])
return class_keep
#------------------------------------------------------------#
# 对获取到的满足得分门限且不属于背景的预测框进行非极大抑制
#------------------------------------------------------------#
nms_keep = tf.map_fn(nms_keep_map, unique_pre_nms_class_ids, dtype=tf.int64)
nms_keep = tf.reshape(nms_keep, [-1])
nms_keep = tf.gather(nms_keep, tf.where(nms_keep > -1)[:, 0])
keep = tf.compat.v1.sets.set_intersection(tf.expand_dims(keep, 0), tf.expand_dims(nms_keep, 0))
keep = tf.compat.v1.sparse_tensor_to_dense(keep)[0]
#------------------------------------------------------------#
# 寻找得分最高的num_keep个框
#------------------------------------------------------------#
roi_count = config.DETECTION_MAX_INSTANCES
class_scores_keep = tf.gather(class_scores, keep)
num_keep = tf.minimum(tf.shape(class_scores_keep)[0], roi_count)
top_ids = tf.nn.top_k(class_scores_keep, k=num_keep, sorted=True)[1]
keep = tf.gather(keep, top_ids)
#------------------------------------------------------------#
# 将预测结果进行堆叠,获得的最终shape为[N,6]
# 即:N, (y1, x1, y2, x2, class_id, score)
#------------------------------------------------------------#
detections = tf.concat([
tf.gather(refined_rois, keep),
tf.cast(tf.gather(class_ids, keep), tf.float32)[..., tf.newaxis],
tf.gather(class_scores, keep)[..., tf.newaxis]
], axis=1)
#------------------------------------------------------------#
# 如果达不到数量的话就padding
#------------------------------------------------------------#
gap = config.DETECTION_MAX_INSTANCES - tf.shape(detections)[0]
detections = tf.pad(detections, [(0, gap), (0, 0)], "CONSTANT")
return detections
def norm_boxes_graph(boxes, shape):
h, w = tf.split(tf.cast(shape, tf.float32), 2)
scale = tf.concat([h, w, h, w], axis=-1) - tf.constant(1.0)
shift = tf.constant([0., 0., 1., 1.])
return tf.divide(boxes - shift, scale)
#----------------------------------------------------------#
# Detection Layer
# 利用classifier的预测结果对建议框进行调整获得预测框
#----------------------------------------------------------#
class DetectionLayer(Layer):
def __init__(self, config=None, **kwargs):
super(DetectionLayer, self).__init__(**kwargs)
self.config = config
def call(self, inputs):
#------------------------------------------------------------------#
# 获得的inputs
# rpn_rois : Batch_size, proposal_count, 4
# mrcnn_class : Batch_size, num_rois, num_classes
# mrcnn_bbox : Batch_size, num_rois, num_classes,
#------------------------------------------------------------------#
rois = inputs[0]
mrcnn_class = inputs[1]
mrcnn_bbox = inputs[2]
image_meta = inputs[3]
#------------------------------------------------------------------#
# 找到window的小数形式
#------------------------------------------------------------------#
m = parse_image_meta_graph(image_meta)
image_shape = m['image_shape'][0]
window = norm_boxes_graph(m['window'], image_shape[:2])
#------------------------------------------------------------------#
# 对每一张图的结果进行解码
#------------------------------------------------------------------#
detections_batch = batch_slice(
[rois, mrcnn_class, mrcnn_bbox, window],
lambda x, y, w, z: refine_detections_graph(x, y, w, z, self.config),
self.config.IMAGES_PER_GPU)
#------------------------------------------------------------#
# 最终输出的shape为
# Batch_size, num_detections, 6]
#------------------------------------------------------------#
return tf.reshape(
detections_batch,
[self.config.BATCH_SIZE, self.config.DETECTION_MAX_INSTANCES, 6])
def compute_output_shape(self, input_shape):
return (None, self.config.DETECTION_MAX_INSTANCES, 6)
7. Adquisición de información de segmentación semántica de máscara
En el sexto paso, obtenemos el marco de predicción final, que es más preciso que el marco de propuesta obtenido anteriormente, por lo que usamos este marco de predicción como la parte de intercepción de la región del modelo de máscara y usamos este marco de predicción para corregir el modelo de máscara. La capa de características comunes utilizada se intercepta.
Después de la interceptación, el modelo de máscara se utiliza para clasificar los píxeles para obtener los resultados de la segmentación semántica.
la parte de entrenamiento
La función de pérdida utilizada para el entrenamiento Faster-RCNN consta de varias partes, una parte es la función de pérdida de la red de cajas de propuestas, una parte es la función de pérdida de la red clasificadora y la otra parte es la función de pérdida de la red de máscara.
1. Capacitación de la red de buzones de sugerencias
Si la capa de entidades públicas quiere obtener el resultado de predicción del cuadro propuesto, debe realizar una convolución de 3x3, una convolución de 1x1 de anclas_por_ubicación x 1 canal y una convolución de 1x1 de anclas_por_ubicación x 4 canales.
En Mask R-CNN, anclas_por_ubicación, es decir, el número de casillas a priori es 3 por defecto, por lo que el resultado de dos convoluciones 1x1 es en realidad:
La convolución de anclas_por_ubicación x 4 se usa para predecir el cambio de cada cuadro anterior en cada punto de cuadrícula en la capa de entidades efectiva . **
La convolución de anclas_por_ubicación x 1 se usa para predecir si cada cuadro de propuesta contiene un objeto en cada punto de cuadrícula en la capa de entidades efectiva.
Es decir, el resultado predicho directamente por la red de marcos de propuesta de Mask R-CNN no es la posición real del marco de propuesta en la imagen, y debe decodificarse para obtener la posición real.
Durante el entrenamiento, necesitamos calcular la función de pérdida, que es relativa al resultado de la predicción de la red de cajas de propuestas de Mask R-CNN . Necesitamos ingresar la imagen en la red del cuadro de propuesta de Máscara R-CNN actual para obtener el resultado del cuadro de propuesta; al mismo tiempo, también necesitamos codificar , esta codificación es para convertir el formato de información de posición del real cuadro en el resultado de la predicción de la información de formato de cuadro de propuesta de máscara R-CNN .
Es decir, necesitamos encontrar el cuadro anterior correspondiente a cada cuadro real de cada imagen utilizada para el entrenamiento , y averiguar cuál debería ser el resultado de la predicción de nuestro cuadro de propuesta si queremos obtener dicho cuadro real.
El proceso de obtención del cuadro de verdad fundamental a partir del resultado de predicción del cuadro de propuesta se denomina decodificación, y el proceso de obtención del resultado de predicción del cuadro de propuesta a partir del cuadro de verdad fundamental es el proceso de codificación.
Por lo tanto, solo necesitamos invertir el proceso de decodificación y es el proceso de codificación.
El código de implementación es el siguiente:
def build_rpn_targets(image_shape, anchors, gt_class_ids, gt_boxes, config):
#------------------------------#
# rpn_match中
# 1代表正样本、-1代表负样本
# 0代表忽略
#------------------------------#
rpn_match = np.zeros([anchors.shape[0]], dtype=np.int32)
#-----------------------------------------------#
# 创建该部分内容利用先验框和真实框进行编码
#-----------------------------------------------#
rpn_bbox = np.zeros((config.RPN_TRAIN_ANCHORS_PER_IMAGE, 4))
'''
iscrowd=0的时候,表示这是一个单独的物体,轮廓用Polygon(多边形的点)表示,
iscrowd=1的时候表示两个没有分开的物体,轮廓用RLE编码表示,比如说一张图片里面有三个人,
一个人单独站一边,另外两个搂在一起(标注的时候距离太近分不开了),这个时候,
单独的那个人的注释里面的iscrowing=0,segmentation用Polygon表示,
而另外两个用放在同一个anatation的数组里面用一个segmention的RLE编码形式表示
'''
crowd_ix = np.where(gt_class_ids < 0)[0]
if crowd_ix.shape[0] > 0:
non_crowd_ix = np.where(gt_class_ids > 0)[0]
crowd_boxes = gt_boxes[crowd_ix]
gt_class_ids = gt_class_ids[non_crowd_ix]
gt_boxes = gt_boxes[non_crowd_ix]
crowd_overlaps = compute_overlaps(anchors, crowd_boxes)
crowd_iou_max = np.amax(crowd_overlaps, axis=1)
no_crowd_bool = (crowd_iou_max < 0.001)
else:
no_crowd_bool = np.ones([anchors.shape[0]], dtype=bool)
#-----------------------------------------------#
# 计算先验框和真实框的重合程度
# [num_anchors, num_gt_boxes]
#-----------------------------------------------#
overlaps = compute_overlaps(anchors, gt_boxes)
#-----------------------------------------------#
# 1. 重合程度小于0.3则代表为负样本
#-----------------------------------------------#
anchor_iou_argmax = np.argmax(overlaps, axis=1)
anchor_iou_max = overlaps[np.arange(overlaps.shape[0]), anchor_iou_argmax]
rpn_match[(anchor_iou_max < 0.3) & (no_crowd_bool)] = -1
#-----------------------------------------------#
# 2. 每个真实框重合度最大的先验框是正样本
#-----------------------------------------------#
gt_iou_argmax = np.argwhere(overlaps == np.max(overlaps, axis=0))[:,0]
rpn_match[gt_iou_argmax] = 1
#-----------------------------------------------#
# 3. 重合度大于0.7则代表为正样本
#-----------------------------------------------#
rpn_match[anchor_iou_max >= 0.7] = 1
#-----------------------------------------------#
# 正负样本平衡
# 找到正样本的索引
#-----------------------------------------------#
ids = np.where(rpn_match == 1)[0]
#-----------------------------------------------#
# 如果大于(config.RPN_TRAIN_ANCHORS_PER_IMAGE // 2)则删掉一些
#-----------------------------------------------#
extra = len(ids) - (config.RPN_TRAIN_ANCHORS_PER_IMAGE // 2)
if extra > 0:
ids = np.random.choice(ids, extra, replace=False)
rpn_match[ids] = 0
#-----------------------------------------------#
# 找到负样本的索引
#-----------------------------------------------#
ids = np.where(rpn_match == -1)[0]
#-----------------------------------------------#
# 使得总数为config.RPN_TRAIN_ANCHORS_PER_IMAGE
#-----------------------------------------------#
extra = len(ids) - (config.RPN_TRAIN_ANCHORS_PER_IMAGE -
np.sum(rpn_match == 1))
if extra > 0:
# Rest the extra ones to neutral
ids = np.random.choice(ids, extra, replace=False)
rpn_match[ids] = 0
#-----------------------------------------------#
# 找到内部真实存在物体的先验框,进行编码
#-----------------------------------------------#
ids = np.where(rpn_match == 1)[0]
ix = 0
for i, a in zip(ids, anchors[ids]):
gt = gt_boxes[anchor_iou_argmax[i]]
#-----------------------------------------------#
# 计算真实框的中心,高宽
#-----------------------------------------------#
gt_h = gt[2] - gt[0]
gt_w = gt[3] - gt[1]
gt_center_y = gt[0] + 0.5 * gt_h
gt_center_x = gt[1] + 0.5 * gt_w
#-----------------------------------------------#
# 计算先验框中心,高宽
#-----------------------------------------------#
a_h = a[2] - a[0]
a_w = a[3] - a[1]
a_center_y = a[0] + 0.5 * a_h
a_center_x = a[1] + 0.5 * a_w
#-----------------------------------------------#
# 编码运算
#-----------------------------------------------#
rpn_bbox[ix] = [
(gt_center_y - a_center_y) / np.maximum(a_h, 1),
(gt_center_x - a_center_x) / np.maximum(a_w, 1),
np.log(np.maximum(gt_h / np.maximum(a_h, 1), 1e-5)),
np.log(np.maximum(gt_w / np.maximum(a_w, 1), 1e-5)),
]
#-----------------------------------------------#
# 改变数量级
#-----------------------------------------------#
rpn_bbox[ix] /= config.RPN_BBOX_STD_DEV
ix += 1
return rpn_match, rpn_bbox
Usando el código anterior, podemos obtener todas las cajas a priori de iou más grandes correspondientes a la caja real , y calcular los resultados de predicción que deberían tener todas las cajas a priori de iou más grandes correspondientes a la caja real.
Mask R-CNN ignorará algunas casillas a priori con un grado de coincidencia relativamente alto pero no muy alto, y generalmente ignorará casillas a priori con un grado de coincidencia entre 0,3-0,7.
La pérdida de la red de cajas de propuestas se puede obtener comparando los resultados de predicción que debería tener la red de cajas de propuestas con los resultados de predicción reales.
2. Entrenamiento del modelo Clasificador
La parte anterior proporciona la pérdida de la red RPN.En el modelo Mask R-CNN, también necesitamos ajustar el cuadro propuesto para obtener el cuadro de predicción final. En el modelo clasificador, la casilla de propuesta es equivalente a la casilla anterior.
Por lo tanto, necesitamos calcular el grado de coincidencia de todas las casillas propuestas y las casillas reales , y filtrarlas.Si el grado de coincidencia entre una casilla real y una propuesta es superior a 0,5, la casilla propuesta se considera una muestra positiva. , y si el grado de coincidencia es inferior a 0,5, se considera que el Buzón de sugerencias es una muestra negativa
Por lo tanto, podemos codificar la caja real, y esta codificación es relativa a la caja propuesta, es decir, cuando tenemos estas cajas propuestas, ¿qué tipo de resultados de predicción necesita tener nuestro modelo Classiffier para ajustar estas cajas propuestas a cajas reales? .
El código de implementación es el siguiente:
#----------------------------------------------------------#
# Detection Target Layer
# 该部分代码会输入建议框
# 判断建议框和真实框的重合情况
# 筛选出内部包含物体的建议框
# 利用建议框和真实框编码
# 调整mask的格式使得其和预测格式相同
#----------------------------------------------------------#
#----------------------------------------------------------#
# 对输入进来的真实框进行编码
#----------------------------------------------------------#
def box_refinement_graph(box, gt_box):
box = tf.cast(box, tf.float32)
gt_box = tf.cast(gt_box, tf.float32)
height = box[:, 2] - box[:, 0]
width = box[:, 3] - box[:, 1]
center_y = box[:, 0] + 0.5 * height
center_x = box[:, 1] + 0.5 * width
gt_height = gt_box[:, 2] - gt_box[:, 0]
gt_width = gt_box[:, 3] - gt_box[:, 1]
gt_center_y = gt_box[:, 0] + 0.5 * gt_height
gt_center_x = gt_box[:, 1] + 0.5 * gt_width
dy = (gt_center_y - center_y) / height
dx = (gt_center_x - center_x) / width
dh = tf.math.log(gt_height / height)
dw = tf.math.log(gt_width / width)
result = tf.stack([dy, dx, dh, dw], axis=1)
return result
#----------------------------------------------------------#
# Detection Target Layer
# 该部分代码会输入建议框
# 判断建议框和真实框的重合情况
# 筛选出内部包含物体的建议框
# 利用建议框和真实框编码
# 调整mask的格式使得其和预测格式相同
#----------------------------------------------------------#
def detection_targets_graph(proposals, gt_class_ids, gt_boxes, gt_masks, config):
asserts = [
tf.Assert(tf.greater(tf.shape(proposals)[0], 0), [proposals],
name="roi_assertion"),
]
with tf.control_dependencies(asserts):
proposals = tf.identity(proposals)
#----------------------------------------------------------#
# 为了满足数据长度,在先前使用了padding部分
# 在这里需要去掉
#----------------------------------------------------------#
proposals, _ = trim_zeros_graph(proposals, name="trim_proposals")
gt_boxes, non_zeros = trim_zeros_graph(gt_boxes, name="trim_gt_boxes")
gt_class_ids = tf.boolean_mask(gt_class_ids, non_zeros, name="trim_gt_class_ids")
gt_masks = tf.gather(gt_masks, tf.where(non_zeros)[:, 0], axis=2, name="trim_gt_masks")
#----------------------------------------------------------#
# 忽略掉coco数据集中的crowd部分,这些部分不易区分
# 训练时直接忽略
#----------------------------------------------------------#
crowd_ix = tf.where(gt_class_ids < 0)[:, 0]
non_crowd_ix = tf.where(gt_class_ids > 0)[:, 0]
crowd_boxes = tf.gather(gt_boxes, crowd_ix)
gt_class_ids = tf.gather(gt_class_ids, non_crowd_ix)
gt_boxes = tf.gather(gt_boxes, non_crowd_ix)
gt_masks = tf.gather(gt_masks, non_crowd_ix, axis=2)
#----------------------------------------------------------#
# 计算建议框和所有真实框的重合程度
# overlaps : proposals, gt_boxes
#----------------------------------------------------------#
overlaps = overlaps_graph(proposals, gt_boxes)
#----------------------------------------------------------#
# 计算建议框和crowd boxes的重合程度
# overlaps : proposals, crowd_boxes
#----------------------------------------------------------#
crowd_overlaps = overlaps_graph(proposals, crowd_boxes)
crowd_iou_max = tf.reduce_max(crowd_overlaps, axis=1)
no_crowd_bool = (crowd_iou_max < 0.001)
#----------------------------------------------------------#
# 每个建议框与真实框的最大重合程度
# roi_iou_max : proposals,
#----------------------------------------------------------#
roi_iou_max = tf.reduce_max(overlaps, axis=1)
#----------------------------------------------------------#
# 1. 正样本建议框和真实框的重合程度大于0.5
#----------------------------------------------------------#
positive_roi_bool = (roi_iou_max >= 0.5)
positive_indices = tf.where(positive_roi_bool)[:, 0]
#----------------------------------------------------------#
# 2. 负样本建议框和真实框的重合程度小于0.5
# 那些和crowd重合度比较大的建议框忽略掉
#----------------------------------------------------------#
negative_indices = tf.where(tf.logical_and(roi_iou_max < 0.5, no_crowd_bool))[:, 0]
#----------------------------------------------------------#
# 进行正负样本的平衡,取出最大33%的正样本
#----------------------------------------------------------#
positive_count = int(config.TRAIN_ROIS_PER_IMAGE * config.ROI_POSITIVE_RATIO)
positive_indices = tf.random.shuffle(positive_indices)[:positive_count]
positive_count = tf.shape(positive_indices)[0]
#----------------------------------------------------------#
# 保持正负样本比例
#----------------------------------------------------------#
r = 1.0 / config.ROI_POSITIVE_RATIO
negative_count = tf.cast(r * tf.cast(positive_count, tf.float32), tf.int32) - positive_count
negative_indices = tf.random.shuffle(negative_indices)[:negative_count]
#----------------------------------------------------------#
# 获得正样本和负样本
#----------------------------------------------------------#
positive_rois = tf.gather(proposals, positive_indices)
negative_rois = tf.gather(proposals, negative_indices)
#----------------------------------------------------------#
# 获取建议框和真实框重合程度
#----------------------------------------------------------#
positive_overlaps = tf.gather(overlaps, positive_indices)
#----------------------------------------------------------#
# 判断是否有真实框
#----------------------------------------------------------#
roi_gt_box_assignment = tf.cond(
tf.greater(tf.shape(positive_overlaps)[1], 0),
true_fn = lambda: tf.argmax(positive_overlaps, axis=1),
false_fn = lambda: tf.cast(tf.constant([]),tf.int64)
)
#----------------------------------------------------------#
# 找到每一个建议框对应的真实框和种类
#----------------------------------------------------------#
roi_gt_boxes = tf.gather(gt_boxes, roi_gt_box_assignment)
roi_gt_class_ids = tf.gather(gt_class_ids, roi_gt_box_assignment)
#----------------------------------------------------------#
# 编码获得网络应该有得预测结果
#----------------------------------------------------------#
deltas = box_refinement_graph(positive_rois, roi_gt_boxes)
deltas /= config.BBOX_STD_DEV
#----------------------------------------------------------#
# 切换mask的形式[N, height, width, 1]
#----------------------------------------------------------#
transposed_masks = tf.expand_dims(tf.transpose(gt_masks, [2, 0, 1]), -1)
#----------------------------------------------------------#
# 取出每一个建议框对应的mask层
#----------------------------------------------------------#
roi_masks = tf.gather(transposed_masks, roi_gt_box_assignment)
#----------------------------------------------------------#
# 利用建议框在mask上进行截取,作为训练用的mask
#----------------------------------------------------------#
boxes = positive_rois
if config.USE_MINI_MASK:
y1, x1, y2, x2 = tf.split(positive_rois, 4, axis=1)
gt_y1, gt_x1, gt_y2, gt_x2 = tf.split(roi_gt_boxes, 4, axis=1)
gt_h = gt_y2 - gt_y1
gt_w = gt_x2 - gt_x1
y1 = (y1 - gt_y1) / gt_h
x1 = (x1 - gt_x1) / gt_w
y2 = (y2 - gt_y1) / gt_h
x2 = (x2 - gt_x1) / gt_w
boxes = tf.concat([y1, x1, y2, x2], 1)
box_ids = tf.range(0, tf.shape(roi_masks)[0])
masks = tf.image.crop_and_resize(tf.cast(roi_masks, tf.float32), boxes,
box_ids,
config.MASK_SHAPE)
masks = tf.squeeze(masks, axis=3)
masks = tf.round(masks)
#----------------------------------------------------------#
# 一般传入config.TRAIN_ROIS_PER_IMAGE个建议框进行训练,
# 如果数量不够则padding
#----------------------------------------------------------#
rois = tf.concat([positive_rois, negative_rois], axis=0)
N = tf.shape(negative_rois)[0]
P = tf.maximum(config.TRAIN_ROIS_PER_IMAGE - tf.shape(rois)[0], 0)
rois = tf.pad(rois, [(0, P), (0, 0)])
roi_gt_boxes = tf.pad(roi_gt_boxes, [(0, N + P), (0, 0)])
roi_gt_class_ids = tf.pad(roi_gt_class_ids, [(0, N + P)])
deltas = tf.pad(deltas, [(0, N + P), (0, 0)])
masks = tf.pad(masks, [[0, N + P], (0, 0), (0, 0)])
return rois, roi_gt_class_ids, deltas, masks
class DetectionTargetLayer(Layer):
"""
找到建议框的ground_truth
Inputs:
proposals : [batch, N, (y1, x1, y2, x2)] 建议框
gt_class_ids : [batch, MAX_GT_INSTANCES] 每个真实框对应的类
gt_boxes : [batch, MAX_GT_INSTANCES, (y1, x1, y2, x2)] 真实框的位置
gt_masks : [batch, MINI_MASK_SHAPE[0], MINI_MASK_SHAPE[1], MAX_GT_INSTANCES] 真实框的语义分割情况
Returns:
rois : [batch, TRAIN_ROIS_PER_IMAGE, (y1, x1, y2, x2)] 内部真实存在目标的建议框
target_class_ids: [batch, TRAIN_ROIS_PER_IMAGE] 每个建议框对应的类
target_deltas : [batch, TRAIN_ROIS_PER_IMAGE, (dy, dx, log(dh), log(dw)] 每个建议框应该有的调整参数
target_mask : [batch, TRAIN_ROIS_PER_IMAGE, height, width] 每个建议框语义分割情况
"""
def __init__(self, config, **kwargs):
super(DetectionTargetLayer, self).__init__(**kwargs)
self.config = config
def call(self, inputs):
proposals = inputs[0]
gt_class_ids = inputs[1]
gt_boxes = inputs[2]
gt_masks = inputs[3]
# 对真实框进行编码
names = ["rois", "target_class_ids", "target_bbox", "target_mask"]
outputs = batch_slice([proposals, gt_class_ids, gt_boxes, gt_masks],
lambda w, x, y, z: detection_targets_graph(w, x, y, z, self.config),
self.config.IMAGES_PER_GPU, names=names)
return outputs
def compute_output_shape(self, input_shape):
return [
(None, self.config.TRAIN_ROIS_PER_IMAGE, 4), # rois
(None, self.config.TRAIN_ROIS_PER_IMAGE), # class_ids
(None, self.config.TRAIN_ROIS_PER_IMAGE, 4), # deltas
(None, self.config.TRAIN_ROIS_PER_IMAGE, self.config.MASK_SHAPE[0],
self.config.MASK_SHAPE[1]) # masks
]
def compute_mask(self, inputs, mask=None):
return [None, None, None, None]
3. Entrenamiento del modelo de máscara
Al entrenar el modelo de máscara, se debe tener en cuenta que cuando usamos la red de marcos propuesta para interceptar la capa de características comunes que necesita usar el modelo de máscara, la situación de intercepción es diferente a la del marco real, por lo que es necesario calcular para qué lo usamos Se obtiene la posición del fotograma interceptado con respecto al fotograma real para obtener la información de segmentación semántica correcta.
El código utilizado es el siguiente, y una gran parte del medio se utiliza para calcular la posición de la caja real en relación con la caja propuesta . Una vez que se completa el cálculo, la posición relativa se puede usar para interceptar la información de segmentación semántica para obtener la información semántica correcta.
# Compute mask targets
boxes = positive_rois
if config.USE_MINI_MASK:
# Transform ROI coordinates from normalized image space
# to normalized mini-mask space.
y1, x1, y2, x2 = tf.split(positive_rois, 4, axis=1)
gt_y1, gt_x1, gt_y2, gt_x2 = tf.split(roi_gt_boxes, 4, axis=1)
gt_h = gt_y2 - gt_y1
gt_w = gt_x2 - gt_x1
y1 = (y1 - gt_y1) / gt_h
x1 = (x1 - gt_x1) / gt_w
y2 = (y2 - gt_y1) / gt_h
x2 = (x2 - gt_x1) / gt_w
boxes = tf.concat([y1, x1, y2, x2], 1)
box_ids = tf.range(0, tf.shape(roi_masks)[0])
masks = tf.image.crop_and_resize(tf.cast(roi_masks, tf.float32), boxes,
box_ids,
config.MASK_SHAPE)
En este caso, el modelo se puede entrenar combinando la máscara obtenida y el resultado de predicción del modelo.
Entrena tu propio modelo de Máscara-RCNN
La estructura general de carpetas de Mask-RCNN es la siguiente:

En primer lugar, la preparación del conjunto de datos.
Este artículo entrena su propio conjunto de datos a través del formato de conjunto de datos COCO.
Si el conjunto de datos no ha sido etiquetado, primero puede usar labelme para etiquetar los datos. Los archivos marcados incluyen archivos de imagen y archivos json, ambos ubicados en la carpeta anterior. Para conocer el formato específico, consulte el conjunto de datos de formas.
Al etiquetar objetivos, debe tenerse en cuenta que diferentes objetivos del mismo tipo deben estar separados por _.
Por ejemplo, si desea entrenar la red para detectar triángulos y cuadrados , cuando hay dos triángulos en una imagen, se marcan como:
triangle_1
triangle_2
Ponlo en la carpeta antes:

En segundo lugar, el procesamiento de conjuntos de datos.
Modifique los parámetros en coco_annotation.py. Para el primer entrenamiento, solo se puede modificar classs_path, y classs_path se usa para apuntar al txt correspondiente a la categoría detectada.
Al entrenar su propio conjunto de datos, puede crear un archivo cls_classes.txt usted mismo y escribir las categorías que necesita distinguir en él.
El contenido del archivo model_data/cls_classes.txt es:
cat
dog
...
Modifique class_path en coco_annotation.py para que corresponda a cls_classes.txt y ejecute coco_annotation.py.

3. Comienza a entrenar la red
Hay muchos parámetros para el entrenamiento, que están todos en train.py. Puede leer los comentarios cuidadosamente después de descargar la biblioteca. La parte más importante sigue siendo la ruta de clases en train.py.
class_path se usa para apuntar al txt correspondiente a la categoría de detección, que es el mismo que el txt en coco_annotation.py. ¡Se debe modificar el entrenamiento de su propio conjunto de datos!
Después de modificar la ruta de clases, puede ejecutar train.py para comenzar a entrenar. Después de entrenar varias épocas, los pesos se generarán en la carpeta de registros.

4. Modelo de predicción
La predicción de resultados de entrenamiento requiere dos archivos, mask_rcnn.py y predict.py.
Primero, debe ir a mask_rcnn.py para modificar model_path y classes_path.Estos dos parámetros deben modificarse.
model_path apunta al archivo de pesos entrenados, en la carpeta de registros.
class_path apunta al txt correspondiente a la categoría de detección.
Después de completar la modificación, puede ejecutar predict.py para la detección. Después de ejecutar, ingrese la ruta de la imagen para detectar.
