que es DCM
Las aplicaciones modernas manejan datos todo el tiempo, el cálculo de datos está en todas partes, estadísticas de informes, análisis de datos, procesamiento comercial, etc. Los principales medios de procesamiento de datos actuales siguen siendo tecnologías relacionadas representadas por bases de datos relacionales.Aunque los lenguajes de alto nivel (como Java) pueden codificarse para lograr varios cálculos, son mucho menos convenientes que las bases de datos (SQL) y Las bases de datos todavía se utilizan en el procesamiento de datos contemporáneo y juegan un papel importante.
Sin embargo, con el desarrollo de la tecnología de la información y el surgimiento de arquitecturas y conceptos como la separación del almacenamiento y la computación, los microservicios, la precomputación y la computación perimetral, las bases de datos demasiado pesadas y cerradas se están volviendo cada vez más difíciles de hacer frente a estos escenarios. . La base de datos requiere que los datos se almacenen para poder calcularlos. Sin embargo, cuando se enfrenta a una gran cantidad de fuentes de datos diversas, el almacenamiento de datos no solo es ineficiente y requiere muchos recursos, sino que tampoco puede garantizar el rendimiento en tiempo real. Algunos datos solo se almacenan temporalmente. utilizado pero necesita ser almacenado en la base de datos para la persistencia. Además, para escenarios como los microservicios y la computación perimetral que requieren que la potencia informática esté precargada en el lado de la aplicación, también es difícil integrar la base de datos para su uso.
En este contexto, si existe una tecnología de computación y procesamiento de datos que no dependa de bases de datos, tenga capacidades de computación abiertas y pueda incorporarse e integrarse con aplicaciones, entonces estos problemas pueden resolverse bien. Este es el middleware de computación de datos (Data Middleware informático) Middleware, denominado DCM). Los escenarios de aplicación de DCM son muy amplios y se puede decir que son omnipresentes. Puede desempeñar un papel importante en la optimización del desarrollo de aplicaciones, la implementación de microservicios, el reemplazo de procedimientos almacenados, el desacoplamiento de bases de datos, la asistencia de ETL, la computación de diversas fuentes de datos, la preparación de datos de BI, etc. Casi todos los escenarios que involucran la interacción de datos de la aplicación pueden usar DCM para mejorar la estructura de la aplicación y mejorar el desarrollo y la eficiencia informática.
Escenarios de aplicación de DCM
Optimizar el desarrollo de aplicaciones
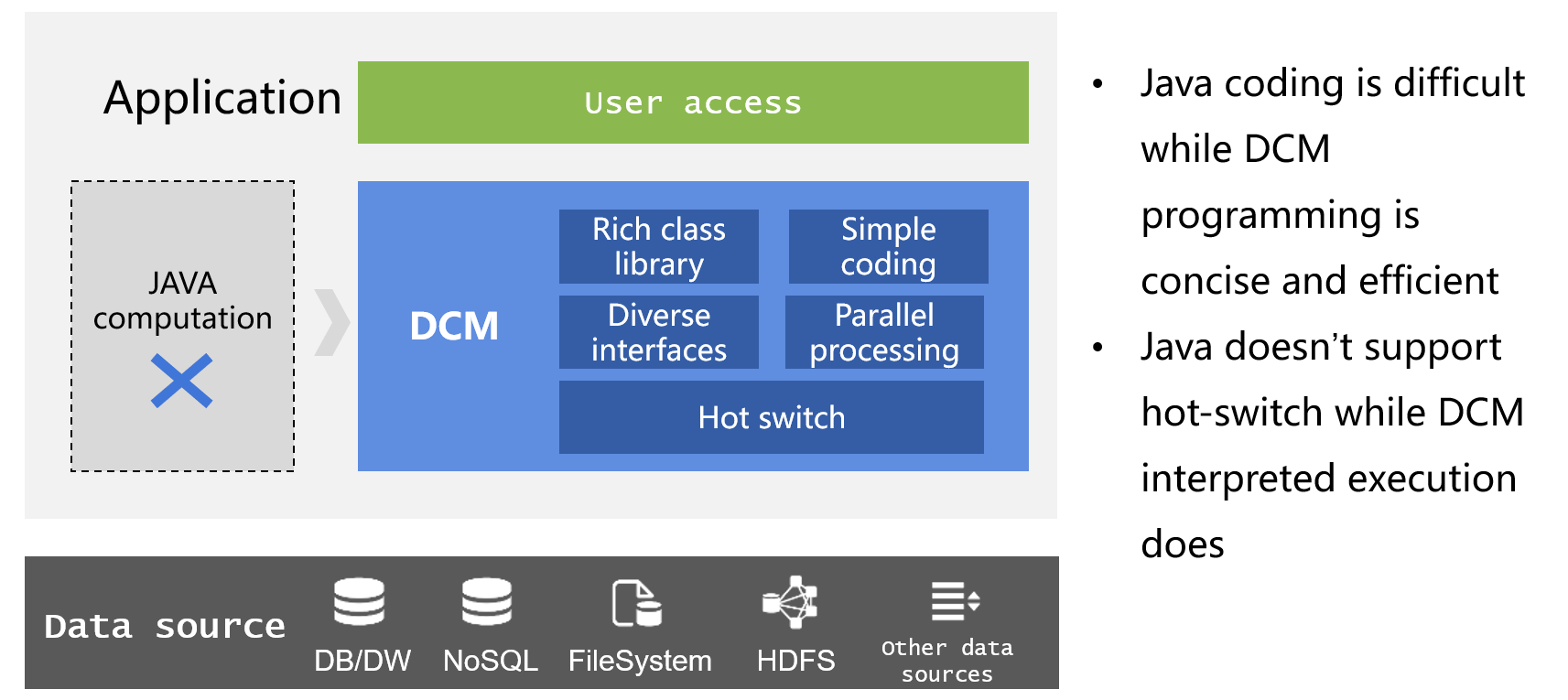
La lógica de procesamiento de datos en la aplicación solo se puede implementar mediante codificación. A menudo, es difícil usar la implementación nativa de Java debido a la falta de la biblioteca de clases de computación estructurada necesaria. Incluso usando el Stream/Kotlin recientemente agregado, no mejora significativamente. Con la ayuda de la tecnología ORM, el dilema de desarrollo se puede aliviar hasta cierto punto, pero todavía faltan tipos de datos estructurados profesionales, las operaciones establecidas no son convenientes y el código al leer y escribir la base de datos es engorroso y complejo. Los cálculos son difíciles de lograr. Estas deficiencias de ORM a menudo conducen a que la eficiencia de desarrollo de la lógica empresarial no solo no mejore significativamente, sino que incluso se reduzca en gran medida. Además, estas implementaciones pueden generar problemas estructurales en la aplicación. La lógica informática implementada en Java debe implementarse junto con la aplicación principal, lo que genera un acoplamiento estrecho y también es problemático porque no admite el desarrollo y la operación de implementación en caliente.
Si utiliza la computación ágil, la fácil integración, la conmutación en caliente y otras características de DCM para reemplazar a Java en las aplicaciones para implementar la lógica de procesamiento de datos, los problemas anteriores se pueden resolver bien, no solo mejorando la eficiencia del desarrollo, sino también optimizando la estructura de la aplicación y realizando el desacoplamiento de módulos informáticos y admite implementación en caliente.
Cálculo de fuente de datos de diversidad
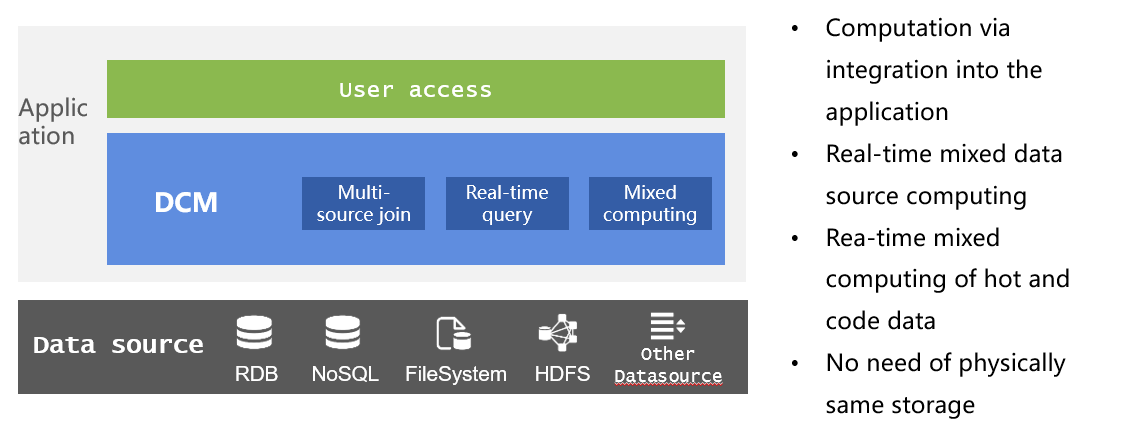
Las aplicaciones modernas también enfrentan a menudo el problema de las diversas fuentes de datos. El procesamiento de bases de datos no solo requiere el almacenamiento de datos, lo cual es ineficiente, sino que tampoco puede garantizar la naturaleza en tiempo real de los datos. Las diferentes fuentes de datos tienen sus propias ventajas. RDB tiene una gran potencia de cálculo, pero un rendimiento de E/S débil; NoSQL tiene una alta eficiencia de E/S pero una potencia de cálculo débil; y los datos de archivo, como el texto, no tienen ninguna potencia de cálculo, pero su uso es muy flexible. Forzar estos datos en el repositorio perderá las ventajas de estas fuentes de datos originales.
A través de la capacidad de cálculo mixto de múltiples fuentes de DCM, no solo se pueden mezclar y calcular directamente RDB, texto, Excel, JSON, XML, NoSQL y otros datos de interfaz de red para garantizar el rendimiento en tiempo real de los datos y el cálculo, sino también varios Las fuentes de datos pueden conservarse al mismo tiempo.ventajas y dar rienda suelta a su eficacia.
Implementación de microservicios
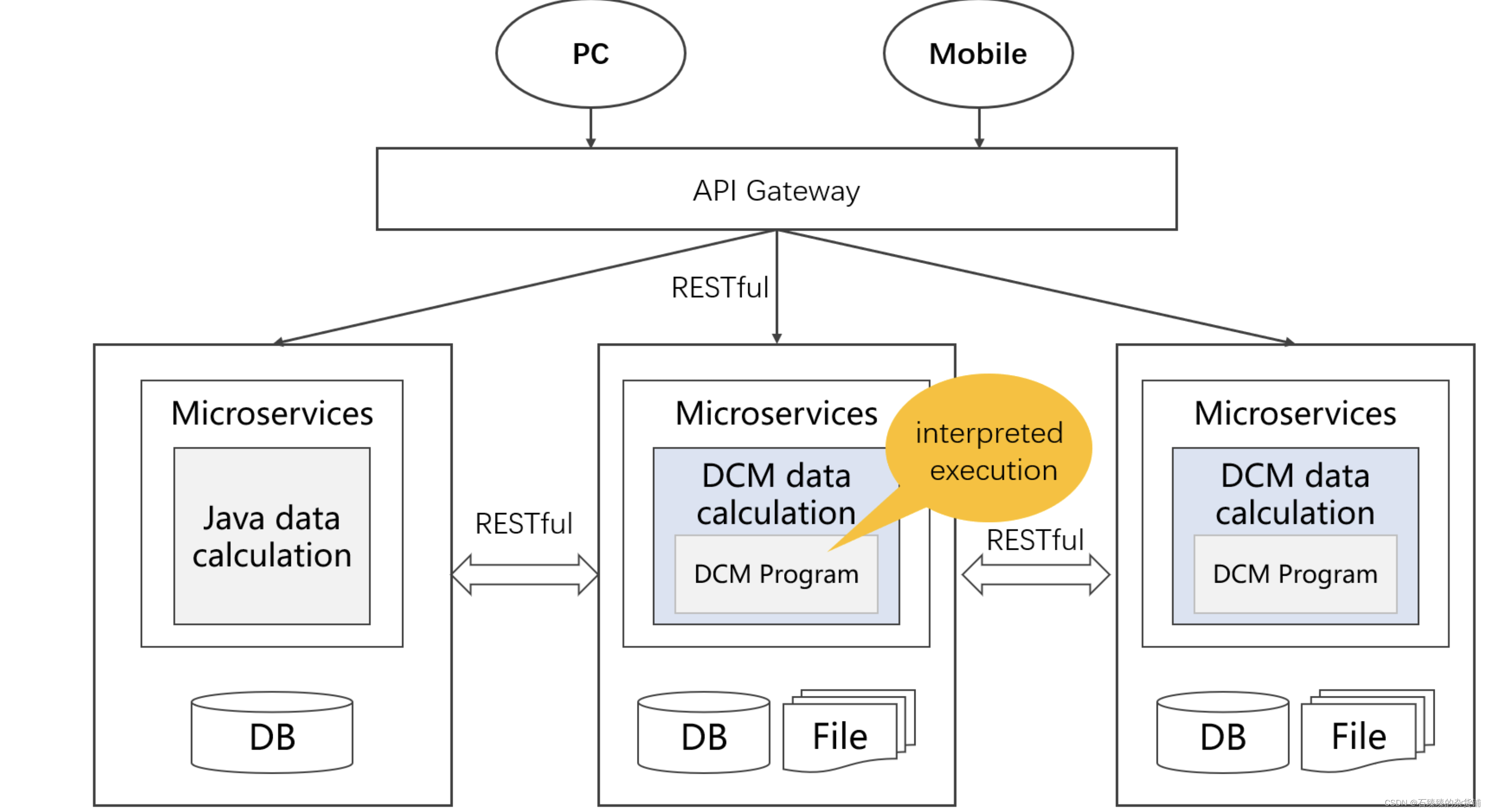
La implementación actual de microservicios todavía depende en gran medida de Java y bases de datos para el procesamiento de datos. La desventaja de Java es que es complejo de implementar y no se puede intercambiar en caliente; mientras que la base de datos tiene la limitación de "biblioteca", los datos de múltiples fuentes pueden solo se calcula después de almacenarse en la biblioteca, y la flexibilidad es muy baja. No solo no se puede garantizar la puntualidad de los datos, sino que tampoco se pueden utilizar por completo las ventajas de varias fuentes de datos.
Integre el DCM integrable en cada enlace de la oficina intermedia o microservicio para completar la recopilación y clasificación de datos, el procesamiento de datos y las tareas informáticas previas a los datos.El uso del sistema informático abierto puede aprovechar al máximo las ventajas de múltiples fuentes de datos y mejorar la flexibilidad. Los problemas como el procesamiento de datos de múltiples fuentes, la computación en tiempo real y la implementación en caliente se pueden resolver fácilmente.
reemplazo de procedimiento almacenado
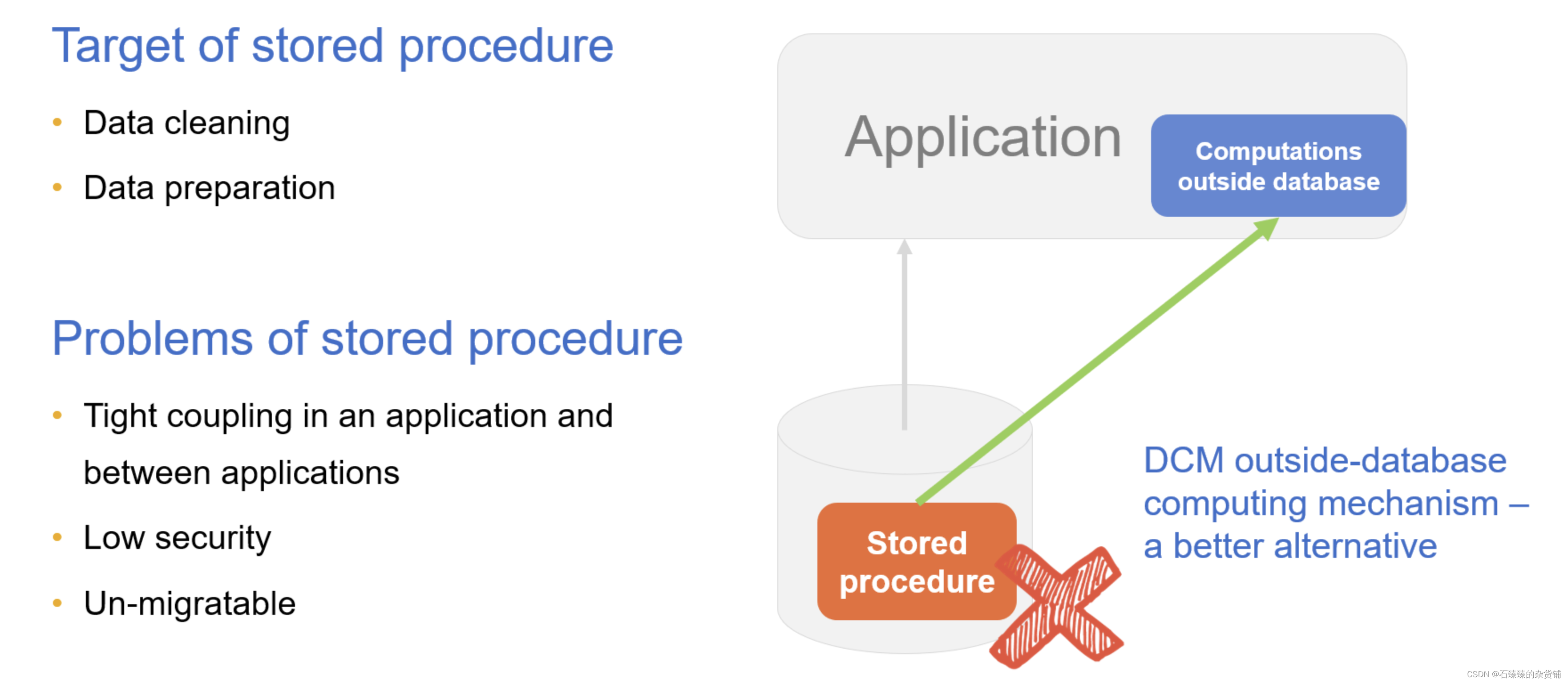
En el pasado, los procedimientos almacenados se usaban a menudo para implementar cálculos complejos u organizar datos.Los procedimientos almacenados tienen ciertas ventajas en la computación en la biblioteca, pero las desventajas también son obvias. Los procedimientos almacenados carecen de portabilidad, la edición y la depuración son difíciles, la creación y el uso de procedimientos almacenados requieren muchos permisos y existen problemas de seguridad.
Al externalizar el procedimiento almacenado en la aplicación a través de DCM, se puede realizar el "procedimiento de almacenamiento externo", y la base de datos se utiliza principalmente para el almacenamiento. Desacoplar el procedimiento almacenado de la base de datos puede resolver varios problemas causados por el procedimiento almacenado.
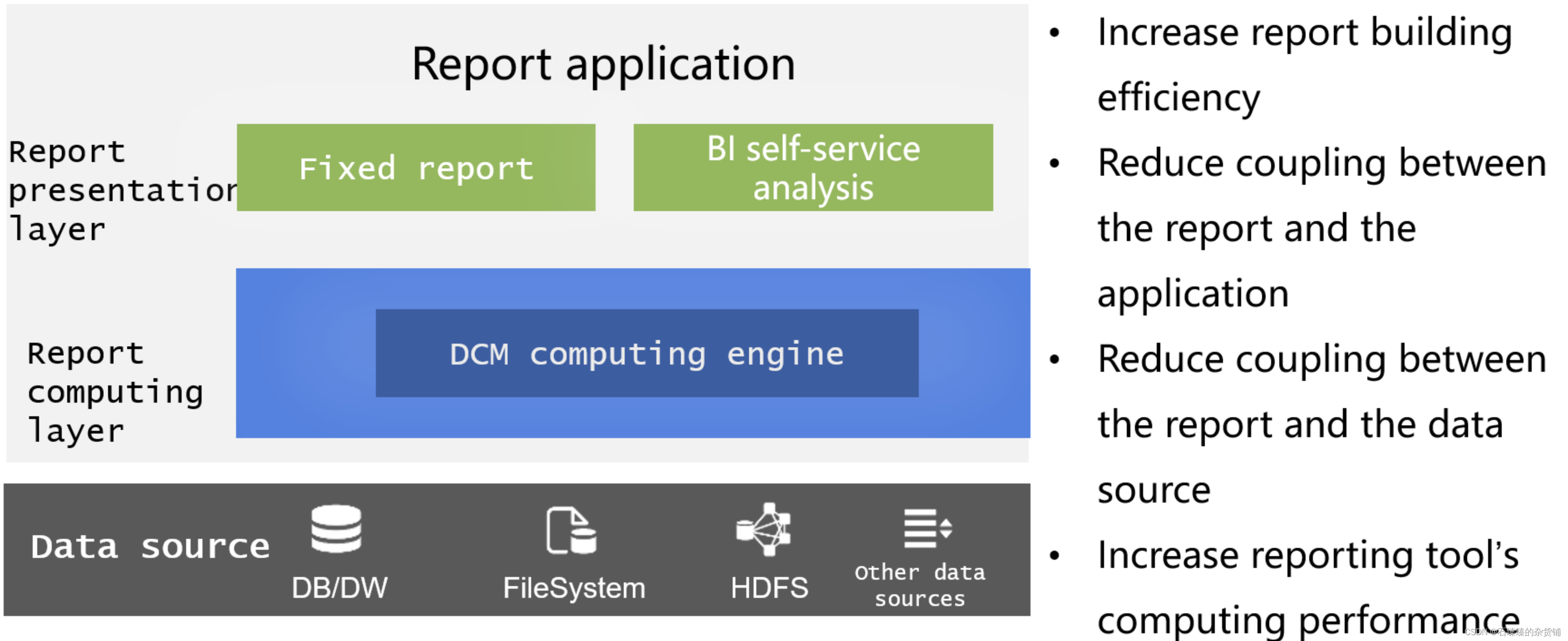
Informe de preparación de datos de BI
La preparación de datos para informes es un escenario importante para DCM. En el pasado, el uso de bases de datos para preparar datos para informes presentaba problemas tales como una alta dificultad de implementación y un fuerte acoplamiento, y los propios informes carecían de potencia informática y no podían completar muchos cálculos complejos. Con el gran poder de cómputo fuera de la biblioteca, DCM puede proporcionar una capa de cómputo de datos dedicada para los informes, que no solo puede desacoplar la base de datos para reducir la carga de la base de datos, sino que también compensa la falta de poder de cómputo de la propia herramienta de generación de informes. . Después de una lógica estratificación, el desarrollo y el mantenimiento de informes son muy refrescantes.
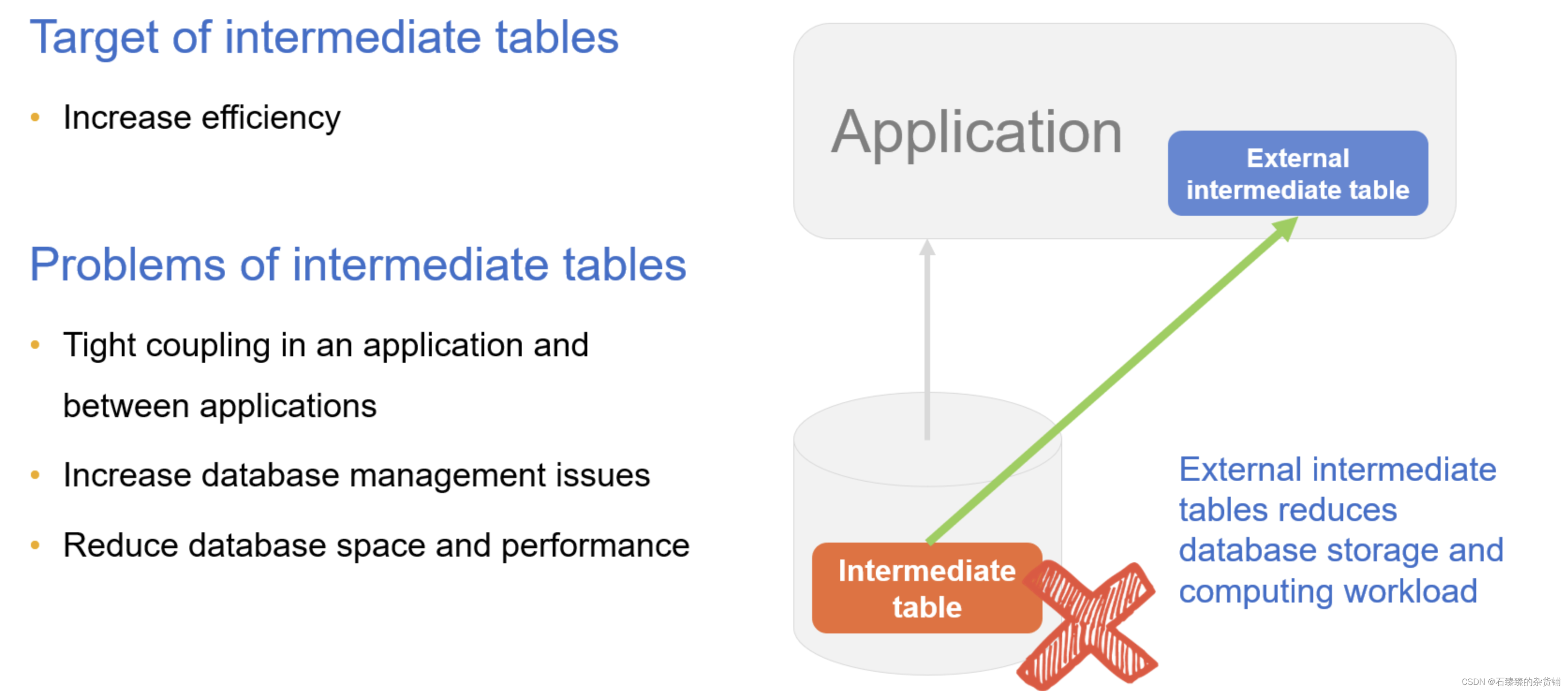
Eliminación de mesa intermedia
A veces, para acelerar la eficiencia de la consulta, los datos a consultar se procesan en una tabla de resultados y se almacenan en la base de datos, que es la tabla intermedia. Además, algunos cálculos complejos necesitan guardar resultados intermedios y también guardarlos como tablas intermedias; varias fuentes de datos también deben almacenarse como tablas intermedias antes de que puedan mezclarse en la base de datos. De manera similar al procedimiento almacenado, una vez que se establece la tabla intermedia, puede ser utilizada por varias aplicaciones (módulos), lo que genera un acoplamiento estrecho entre la aplicación y la base de datos. Al mismo tiempo, debido a que la tabla intermedia no se puede eliminar fácilmente, el número se acumulará. Demasiadas tablas intermedias causarán problemas de capacidad y rendimiento de la base de datos. El almacenamiento de tablas intermedias requiere espacio, y el procesamiento de tablas intermedias requiere recursos informáticos de la base de datos.
A través de DCM, la tabla intermedia se puede externalizar al sistema de archivos, y DCM se puede usar para implementar el cálculo, y la base de datos de desacoplamiento puede reducir la carga del almacenamiento y el cálculo de la base de datos. La clave aquí es que DCM hace que el archivo también tenga poder de cómputo, por lo que la tabla intermedia en la biblioteca se puede colocar fuera de la biblioteca. Originalmente, la tabla intermedia se colocó en la biblioteca principalmente para obtener el poder de cómputo de la base de datos. Ahora el la tabla intermedia con el poder de cómputo de DCM se almacena en la biblioteca. No importa de qué forma sea, es mejor colocarla externamente al sistema de archivos.
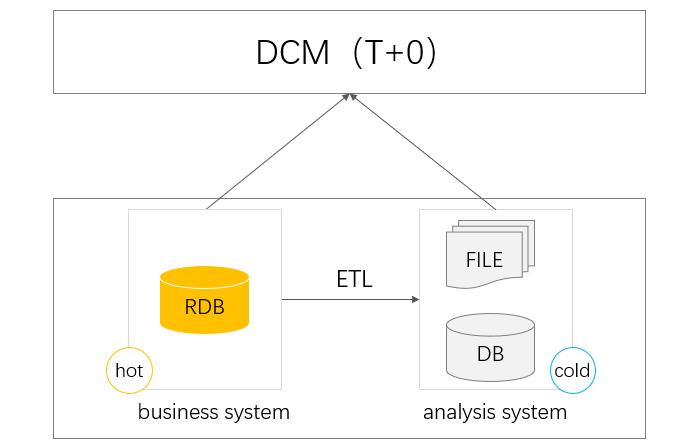
Consulta T+0
Cuando la cantidad de datos se acumula hasta cierto punto, la consulta basada en la base de datos de producción afectará la transacción. En este momento, una gran cantidad de datos históricos se eliminarán en otras bases de datos históricas para separar los datos fríos y calientes. En este momento, si desea consultar la cantidad total de datos, debe completar la consulta entre bases de datos, el enrutamiento de datos calientes y fríos, etc. La base de datos tiene muchos problemas para la consulta entre bases de datos, especialmente entre bases de datos heterogéneas. No solo es ineficiente, sino que también tiene muchas deficiencias, como la transmisión de datos inestable y la baja escalabilidad, que no pueden realizar bien la consulta de datos completos T+0.
Y estos problemas pueden ser resueltos por DCM. Debido a su capacidad informática perfecta e independiente, puede buscar y calcular desde diferentes bases de datos, por lo que puede adaptarse bien a la situación de bases de datos heterogéneas, y también puede decidir si calcular de acuerdo con el estado de recursos de la base de datos.Implementado en base de datos o DCM, muy flexible. En términos de implementación informática, las capacidades informáticas ágiles de DCM también pueden simplificar la informática compleja en consultas T+0 y mejorar la eficiencia del desarrollo.
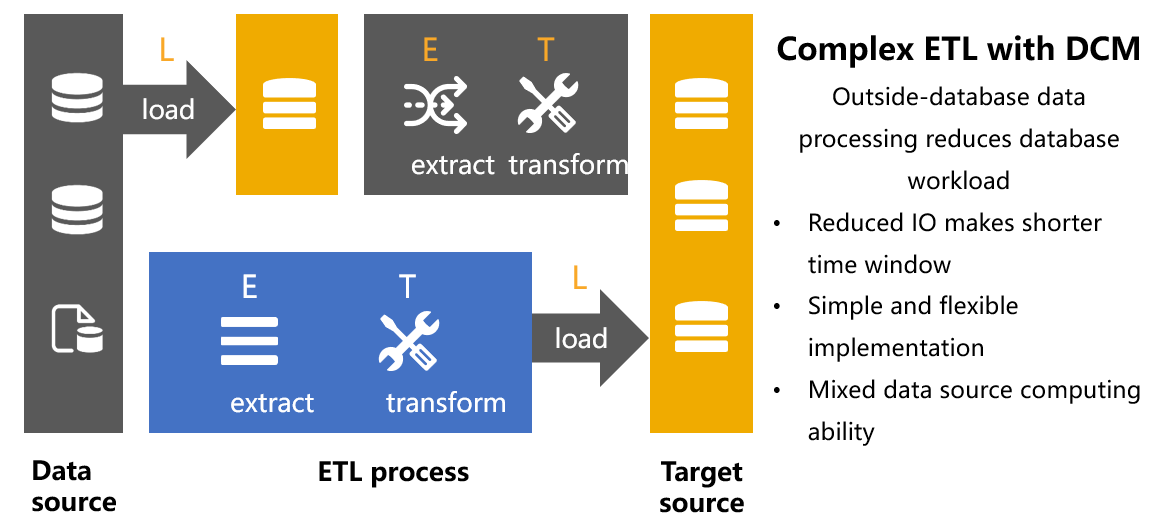
ETL
ETL necesita limpiar y transformar los datos y luego cargarlos en el destino. Sin embargo, dado que los datos de origen pueden provenir de múltiples fuentes (texto, base de datos, web) y la calidad de los datos es desigual, los dos pasos de E y T implicarán una gran cantidad de cálculo de datos. En la actualidad, además de la base de datos, otras fuentes de datos no tienen tal poder de cómputo, si desea completar estos cálculos, primero debe cargarlos en la base de datos y luego realizarlos, lo que forma el LET. Una gran cantidad de datos inútiles almacenados en la base de datos ocupará mucho espacio de almacenamiento, lo que puede conducir fácilmente a problemas de capacidad. Sin embargo, presionar el trabajo de cálculo de limpieza y conversión a la base de datos aumentará el tiempo de procesamiento de datos y agregará una gran cantidad de tiempo de almacenamiento de datos sin procesar que no se han limpiado ni convertido. Es probable que la ventana de tiempo ETL limitada sea insuficiente. Si el trabajo de ETL no se puede completar dentro del tiempo especificado Afectará el negocio al día siguiente.
La introducción de DCM en la tarea ETL puede completar la limpieza de E, la conversión de T y la carga de L en secuencia, resolviendo varios problemas que enfrenta LET. Con la ayuda de las capacidades informáticas abiertas de DCM, los datos de múltiples fuentes se limpian y convierten fuera de la biblioteca. DCM tiene capacidades informáticas sólidas para manejar varios cálculos complejos y finalmente instala los datos ordenados en el lado de destino para lograr un verdadero ETL.
Características del MCD
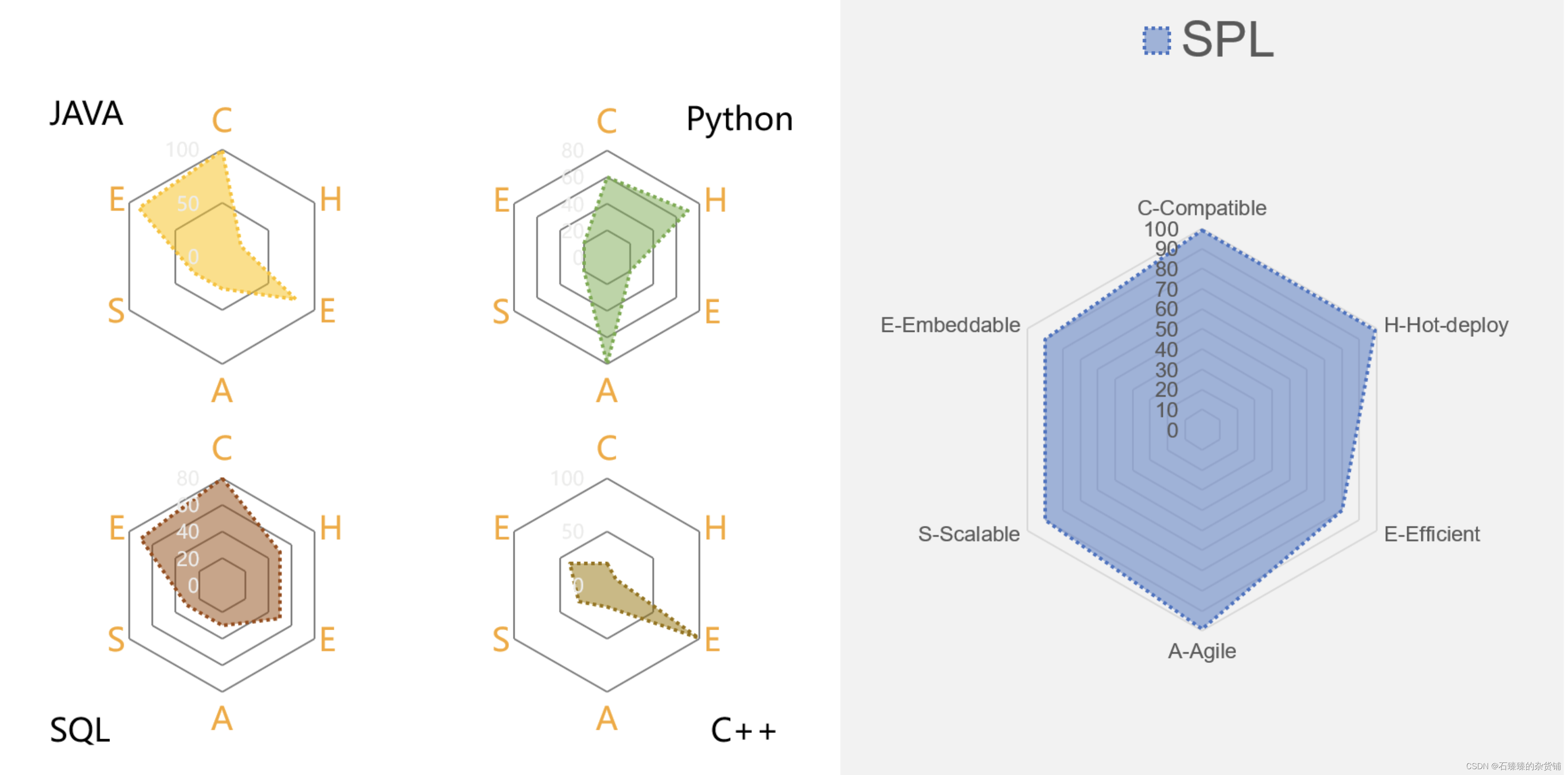
Se puede ver que los escenarios de aplicación de DCM son muy amplios. Entonces, para lidiar bien con estos escenarios, ¿qué características debe tener un excelente DCM?
Compatible
En primer lugar, DCM debe tener una buena compatibilidad, se puede usar en todas las plataformas y puede ejecutarse bien en varios sistemas operativos, plataformas en la nube y servidores de aplicaciones, lo que determina el alcance del uso de DCM.
Además, la compatibilidad también significa que puede ser compatible con diversas fuentes de datos, sin importar qué tipo de fuentes de datos se puedan usar directamente y cálculo mixto, lo que requiere que DCM tenga una apertura lo suficientemente fuerte.
Implementación en caliente
El procesamiento de datos es un escenario de alta frecuencia y menos estable. En el proceso de desarrollo comercial, a menudo se agregan tareas informáticas nuevas y modificadas. Esto requiere que DCM tenga características de implementación en caliente. La modificación de la lógica de procesamiento de datos se puede realizar sin reiniciar la aplicación (servicio ). efectivo.
Alto rendimiento (Eficiente)
El rendimiento informático es el aspecto clave de los escenarios de informática de datos y, a veces, se convierte en el foco principal. DCM debe poder procesar datos de manera eficiente y proporcionar mecanismos de garantía de alto rendimiento, como bibliotecas informáticas de alto rendimiento, soluciones de almacenamiento de alto rendimiento y computación paralela.
Agilidad
La agilidad requiere que los DCM puedan implementar rápidamente la lógica de procesamiento de datos y tener capacidades informáticas completas.Especialmente en escenarios informáticos complejos, el procesamiento de datos se puede completar con una codificación bastante simple y, al mismo tiempo, puede ejecutarse de manera eficiente. Esto requiere que DCM brinde soporte, como mecanismos de programación ágiles y un entorno de desarrollo fácil de usar.
Escalable
Cuando la capacidad informática no puede satisfacer las necesidades, el DCM debe tener la flexibilidad para escalar horizontalmente. La escalabilidad es muy importante para las aplicaciones contemporáneas y la escalabilidad determina el límite superior de DCM.
Embebible
DCM debe poder integrarse bien con la aplicación, actuar como un motor informático dentro de la aplicación y empaquetarse e implementarse con la aplicación como parte de la aplicación. De esta forma, la propia aplicación ha obtenido una gran potencia informática y, una vez que ya no depende en gran medida de la base de datos, puede hacer frente a escenarios como la separación del almacenamiento y la informática, los microservicios y la informática perimetral. Además, la buena integración es otro aspecto de la agilidad. DCM es muy ligero y se puede integrar y utilizar junto con aplicaciones en cualquier momento y en cualquier lugar.
Si se combinan las iniciales de estas características de DCM, es muy parecido a CHEESE (queso) (QUESO), y DCM actúa como queso en una hamburguesa, si falta, el sabor y la nutrición serán mucho peores.

De esta manera, se puede examinar si se puede utilizar como un DCM ideal utilizando el estándar CHEASE. Aquí, echemos un vistazo a la satisfacción de algunas de las principales tecnologías para DCM.
Lo último
sql
La base de datos es la posición principal para usar SQL. La base de datos generalmente tiene un gran poder de cómputo. El rendimiento de cómputo de algunas bases de datos principales también es muy fuerte, lo que básicamente puede satisfacer las necesidades de alto rendimiento (E). Además, la base de datos está demasiado cerrada y los datos solo se pueden calcular después de almacenarse en la base de datos, lo que no puede satisfacer las necesidades de diversos escenarios de fuentes de datos, y la compatibilidad (C) es deficiente.
Para la integración (E), dado que la mayoría de las bases de datos se utilizan de forma independiente, muy pocas bases de datos (como SQLite) que admiten la incorporación a menudo no cumplen los requisitos de función y rendimiento, por lo que la base de datos apenas cumple los requisitos de integración.
Como un lenguaje informático de conjunto especial, SQL es muy conveniente para implementar cálculos simples, pero es muy engorroso expresar cálculos complejos en SQL, y a menudo es necesario anidar varias capas. En los negocios reales, a menudo puede ver miles de filas de SQL "largo", que no solo es difícil de escribir, el mantenimiento no es conveniente, por lo que SQL no cumple con los requisitos de agilidad (A).
Las tecnologías relacionadas con Hadoop, similares a las bases de datos, también tienen los mismos problemas. La cerrazón conduce a desventajas como poca compatibilidad, agilidad insuficiente y básicamente ninguna integración. Aunque es mejor que las bases de datos en términos de escalabilidad, generalmente no cumple con los requisitos de MCD. . El rendimiento de Spark es ligeramente mejor, pero Scala no admite la implementación en caliente, y no es conveniente implementar cálculos complejos, y Spark SQL todavía tiene esos problemas de SQL. Estas tecnologías son demasiado pesadas para satisfacer las necesidades de DCM en términos de agilidad, integración, implementación en caliente, etc.
Java
Como lenguaje de programación nativo, Java puede ejecutarse bien en todas las plataformas y también puede completar tareas informáticas de múltiples fuentes de datos a través de la codificación, por lo que la compatibilidad (C) es muy buena. Y para la mayoría de las aplicaciones desarrolladas en Java, la integración (E) no es un problema.
Pero las deficiencias de Java también son obvias: como lenguaje compilado, no se puede lograr la implementación en caliente (H). Debido a la falta de la biblioteca de clases de computación estructurada necesaria, se necesitan docenas de líneas de código para completar la agrupación y el resumen simples, sin mencionar la computación compleja. Aunque la codificación de Java se usa a menudo para completar el procesamiento de datos en arquitecturas de microservicios, de hecho, la implementación del cálculo es mucho más complicada que SQL. A) Extremadamente inadecuada. Aunque Stream se introdujo después de Java8, la potencia informática no ha mejorado sustancialmente (Kotlin tiene un problema similar).
Aunque Java teóricamente puede implementar varios algoritmos de alto rendimiento, si solo sirve para una determinada aplicación/proyecto, es una inversión excesiva implementar estos paquetes de algoritmos de alto rendimiento. Por lo tanto, desde la perspectiva de la aplicación práctica, Java no tiene el Alto características de rendimiento (E). La escalabilidad (S) tiene el mismo problema. Por lo tanto, en general, Java es difícil de usar como una excelente tecnología DCM.
Pitón
Como una tecnología informática popular, debe mencionarse Python. Python tiene una gran compatibilidad (C) y puede admitir fuentes multiplataforma y de datos múltiples. En particular, los ricos paquetes de procesamiento de datos hacen que Python sea extremadamente aplicable.
En comparación con Java y otras tecnologías, Python tiene ventajas considerables en el procesamiento de datos estructurados, pero es difícil decir que es perfecto, especialmente cuando se trata de cálculos complejos como la agrupación ordenada.Python carece ligeramente de agilidad (A).
No solo eso, sino que el rendimiento (E) de Pandas a menudo no cumple con los requisitos, especialmente para cálculos de gran volumen de datos, lo que tiene mucho que ver con la eficiencia de implementación del algoritmo.La sintaxis ágil puede implementar fácilmente algoritmos de alto rendimiento. . Del mismo modo, en términos de escalabilidad (S), Python no es satisfactorio. Esencialmente, Python como lenguaje de programación necesita invertir muchos recursos para desarrollarse y tener una buena escalabilidad, que es lo mismo que Java.
El mayor problema con Python es la integración (E), que es difícil de integrar con las aplicaciones existentes. Aunque las llamadas entre servicios se pueden realizar a través de patrones como sidecars, están inherentemente lejos del requisito de DCM de integrarse (el mismo proceso) junto con la aplicación. El escenario de aplicación principal de Python no es hacer un desarrollo de aplicaciones de nivel empresarial como Java. En el análisis final, las cosas profesionales también necesitan herramientas profesionales.
Middleware de computación de datos profesional SPL
El esProc SPL de código abierto es un middleware informático profesional de datos. Tiene capacidades informáticas completas que no dependen de la base de datos. Al mismo tiempo, las capacidades informáticas abiertas pueden mezclar y calcular diversos datos. Al mismo tiempo, la interpretación y ejecución de SPL, naturalmente, admite la implementación en caliente, y su buena integración puede ser muy conveniente.Es fácil de integrar en las aplicaciones, por lo que las aplicaciones tienen una gran potencia informática y aprovechan al máximo la eficacia de DCM.
compatibilidad
SPL está desarrollado en Java, y sus capacidades multiplataforma son consistentes con Java, y puede funcionar bien en varios sistemas operativos y plataformas en la nube. En términos de compatibilidad con múltiples fuentes de datos, SPL tiene capacidades informáticas abiertas y puede conectarse a múltiples fuentes de datos, como RDB, NoSQL, CSV, Excel, JSON/XML, Hadoop, RESTful y Webservice. El rendimiento del cálculo en tiempo real puede estar bien garantizado.

El soporte informático de múltiples fuentes ha resuelto el problema de que la base de datos original no podía calcular datos externos y de fuentes cruzadas. Junto con la potencia informática completa de SPL y la sintaxis más concisa que SQL, la aplicación es equivalente a la base de datos (más de ) poder computacional.
Además de la sintaxis informática nativa, SPL también proporciona compatibilidad con SQL (equivalente al estándar SQL92), que puede utilizar SQL para consultar fuentes de datos que no son RDB, como texto, Excel y NoSQL, lo que facilita en gran medida a los desarrolladores de aplicaciones que están familiarizados con SQL. .

Solo con el soporte del sistema informático abierto, DCM puede tener una compatibilidad lo suficientemente fuerte y adaptarse a más escenarios de aplicación.
despliegue en caliente
SPL adopta un mecanismo de ejecución interpretado y, naturalmente, admite la implementación en caliente. Esto es muy amigable para algunas empresas (como informes y microservicios) que a menudo necesitan agregar y modificar la lógica de cálculo con poca estabilidad.
alto rendimiento
En términos de rendimiento, SPL proporciona muchos algoritmos de alto rendimiento y mecanismos de almacenamiento de alto rendimiento. En el escenario mencionado anteriormente de DCM eliminando tablas intermedias y ETL, los datos a menudo se almacenan en archivos fuera de la base de datos. En este caso, el uso de almacenamiento en formato de archivo SPL puede lograr un rendimiento mucho mayor que los formatos abiertos como el texto.
SPL proporciona dos tipos de almacenamiento: archivos de conjuntos y tablas de grupos. El archivo establecido adopta tecnología de compresión (huella más pequeña y lectura más rápida), almacena tipos de datos (no necesita analizar el tipo de datos y lee más rápido), admite el mecanismo de segmentación de multiplicación para datos agregables y puede lograr fácilmente el paralelismo mediante el uso de la estrategia de segmentación Compute to garantizar el rendimiento informático. La tabla de grupos admite el almacenamiento en columnas, lo que tiene grandes ventajas cuando el número de columnas (campos) involucrados en el cálculo es pequeño. La tabla de grupos también implementa el índice minmax y admite la segmentación por multiplicación, que no solo disfruta de las ventajas del almacenamiento en columnas, sino que también facilita la mejora del rendimiento informático en paralelo.
SPL también admite varios algoritmos de alto rendimiento. Por ejemplo, la operación TopN común, en SPL, TopN se entiende como una operación de agregación, que puede convertir la clasificación de alta complejidad en operaciones de agregación de baja complejidad y puede ampliar el ámbito de aplicación.
| UN | ||
|---|---|---|
| 1 | =archivo(“datos.ctx”).crear().cursor() | |
| 2 | =A1.grupos(;arriba(10,cantidad)) | 10 pedidos principales |
| 3 | =A1.groups(área;arriba(10,cantidad)) | Los 10 pedidos principales por región |
No hay una palabra de ordenación en la declaración aquí, y no ocurrirá una gran acción de ordenación. La sintaxis para calcular TopN en el conjunto completo o agrupación es básicamente la misma, y ambos tendrán un mayor rendimiento. Hay muchos algoritmos similares en SPL.
SPL también es fácil de implementar computación paralela, aprovechando múltiples CPU. Hay muchas funciones informáticas en SPL que proporcionan mecanismos paralelos, como lectura, filtrado y clasificación de archivos, siempre que se agregue una opción @m, la computación paralela se puede implementar automáticamente, lo cual es simple y conveniente. Al mismo tiempo, también puede mostrar la escritura de programas paralelos y mejorar el rendimiento informático a través del paralelismo de subprocesos múltiples.
Agilidad
SPL proporciona una sintaxis informática nativa y un entorno IDE conciso y fácil de usar. En el IDE, no solo es conveniente para codificar y depurar, sino que también se pueden ver los resultados de cálculo de cada paso del proceso en tiempo real. Como resultado, no hay necesidad de definir variables, lo cual es simple y conveniente.
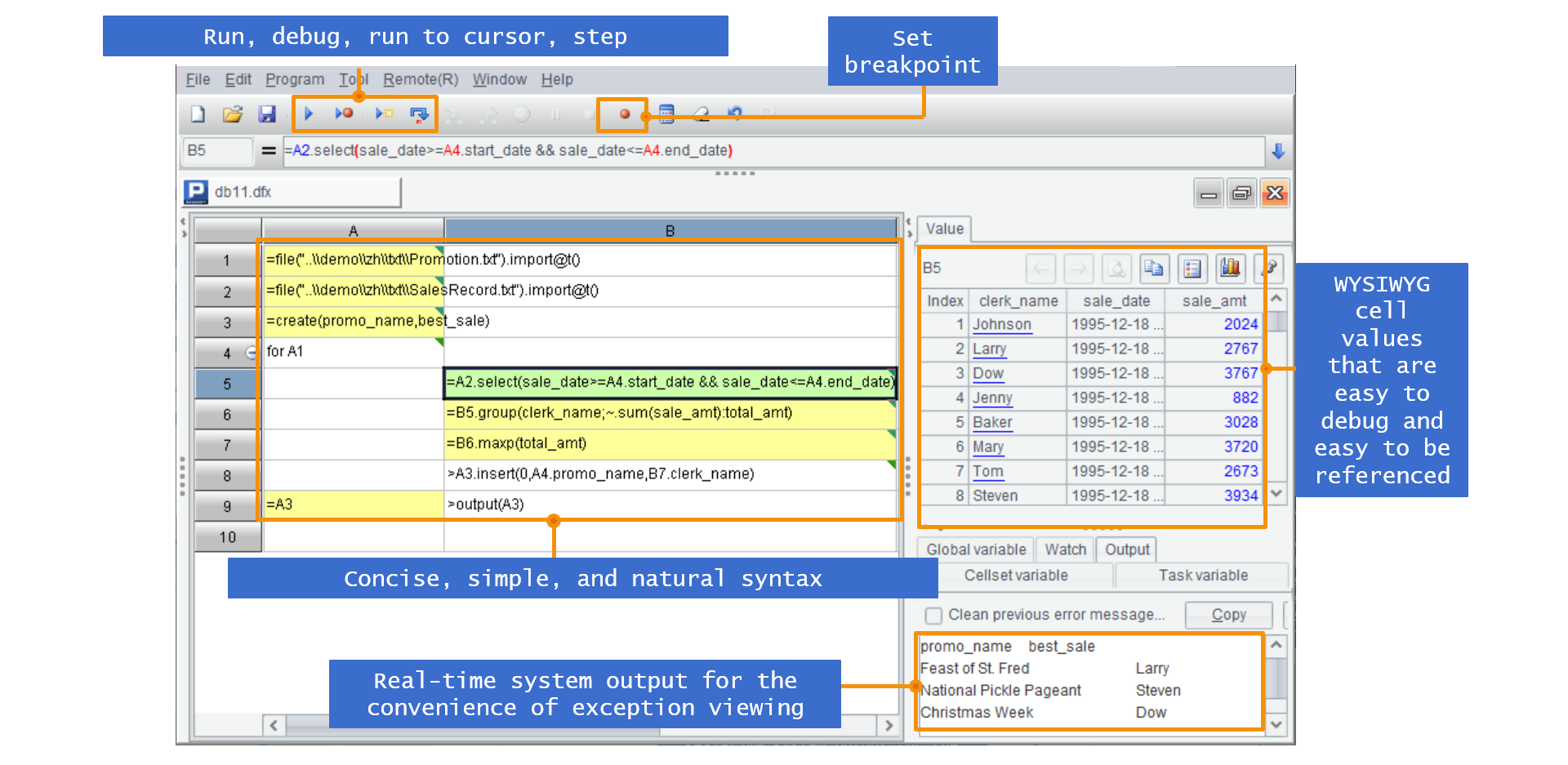
Al mismo tiempo, es más conveniente implementar el cálculo de datos estructurados basado en la rica biblioteca de clases informáticas de SPL, que incluye resumen de agrupación, bucle, filtrado, operación de conjuntos y cálculo ordenado.

SPL es especialmente bueno en cálculos complejos.Es muy conveniente usar SPL para cálculos que requieren que se aniden muchas capas de SQL. Por ejemplo, ¿cuántos días es el aumento continuo más largo de una acción según los registros de existencias? SPL es mucho más simple que SQL.

El SQL anterior está anidado en 3 capas, y es muy confuso de leer, sin mencionar la escritura; el SPL siguiente se basa completamente en el pensamiento natural y se puede implementar en solo 3 líneas, y se realiza el juicio.
Una buena agilidad no solo puede mejorar la eficiencia del desarrollo, sino que muchos algoritmos de alto rendimiento se pueden implementar fácilmente a través de SPL. Los algoritmos no solo deben pensarse, sino también implementarse. La mejor implementación es simple. SPL brinda esta posibilidad.
Extensibilidad
Para escenarios con altos requisitos de rendimiento informático, SPL también puede implementar servicios informáticos independientes, admitir clústeres distribuidos de varias máquinas, admitir mecanismos de equilibrio de carga y tolerancia a fallas, y aumentar la potencia informática a través de la expansión horizontal cuando los recursos informáticos alcanzan el límite superior.
En la computación distribuida, los usuarios pueden personalizar de manera flexible la distribución de datos y los esquemas de redundancia de acuerdo con las características de los datos y las tareas informáticas, lo que puede reducir efectivamente la cantidad de transmisión de datos entre nodos, lograr un mayor rendimiento y lograr una distribución de datos controlable.
SPL adopta un diseño de clúster no central. El clúster no tiene un nodo maestro central permanente, lo que permite a los programadores controlar los nodos que participan en el cálculo con código, evitando así un único punto de falla. Al mismo tiempo, SPL decidirá si asigna tareas de acuerdo con la inactividad (número de subprocesos) de cada nodo para lograr un equilibrio efectivo entre la carga y los recursos.
En términos de tolerancia a fallos, SPL proporciona dos tipos de mecanismos de tolerancia a fallos de datos: tolerancia a fallos de redundancia de memoria externa y tolerancia a fallos de rueda de repuesto de memoria. Admite tolerancia a fallas informáticas. Cuando un nodo falla, la tarea informática del nodo se migra automáticamente a otros nodos para continuar.
integración
Como un aspecto de la combinación de DCM con aplicaciones, SPL proporciona interfaces JDBC/ODBC/RESTful estándar, y las aplicaciones pueden solicitar resultados de cálculo de SPL como llamar a procedimientos almacenados.
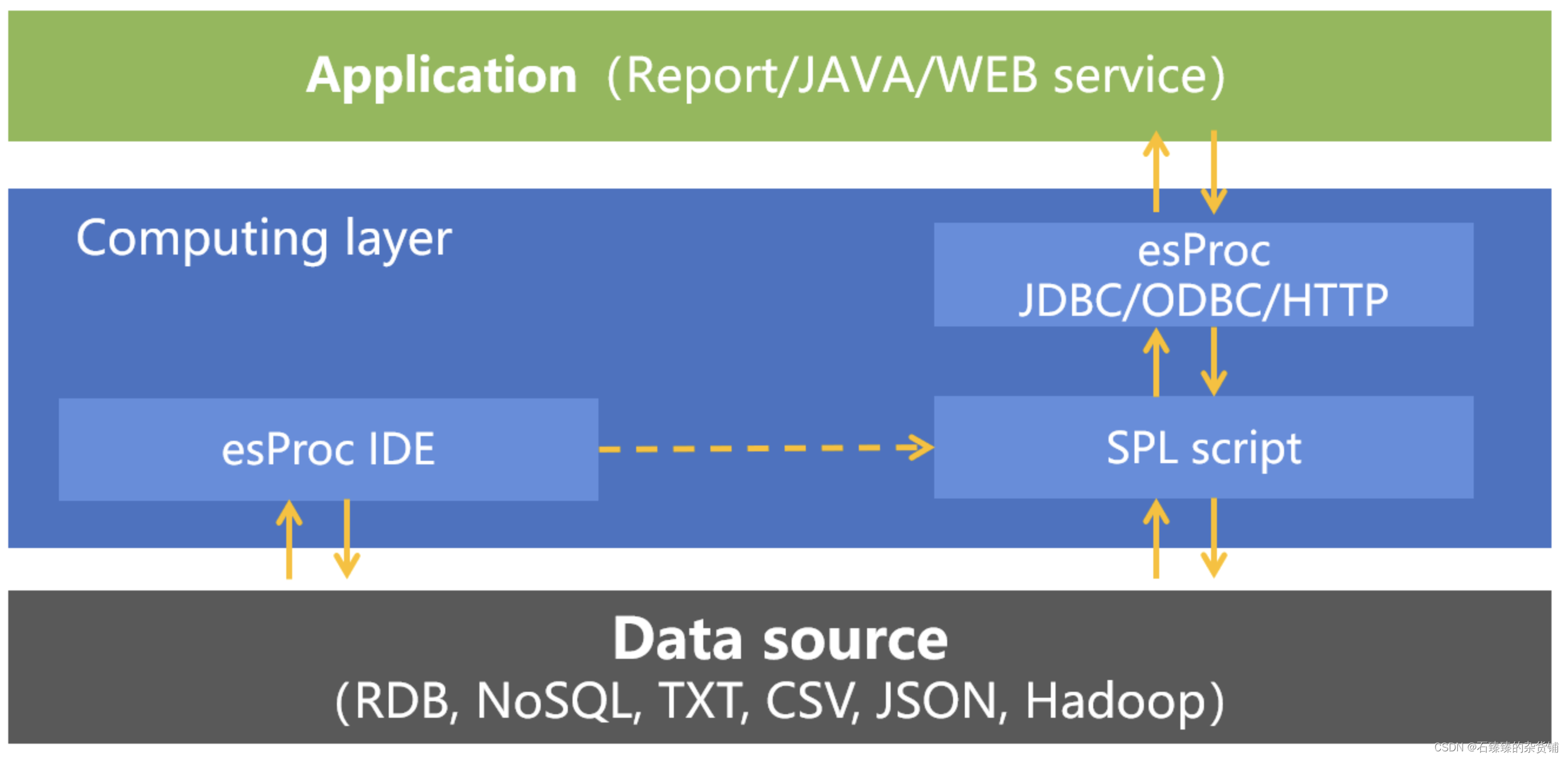
Lógicamente, como DCM, SPL implementa el procesamiento de datos entre las aplicaciones y las fuentes de datos, brinda servicios informáticos para el lado superior y protege las diferencias de diversas fuentes de datos para el lado inferior, lo que demuestra plenamente el importante papel de DCM.
Ejemplo de código SPL de llamada JDBC:
Class.forName("com.esproc.jdbc.InternalDriver");
Connection conn =DriverManager.getConnection("jdbc:esproc:local://");
CallableStatement st = conn.prepareCall("{call splscript(?, ?)}");
st.setObject(1, 3000);
st.setObject(2, 5000);
ResultSet result=st.execute();
En conjunto, desde la perspectiva de las seis características (CHEASE) de DCM, SPL tiene una capacidad muy equilibrada en todos los aspectos, es muy superior a otras tecnologías en su conjunto y es una opción ideal para DCM.
Información SPL
Bienvenido a agregar un pequeño ayudante (número VX: SPL-helper) que esté interesado en SPL, únase al grupo de intercambio técnico de SPL