EfficientDet of Paper: traducción e interpretación de "Detección de objetos escalable y eficiente: detección de objetos escalable y eficiente"
Introducción : el 21 de noviembre de 2019, el equipo de Google Brain publicó el documento EfficientDet: Detección de objetos escalable y eficiente.
Tres líderes de Auto ML del equipo de Google Brain, Mingxing Tan Ruoming Pang Quoc V. Le, publicaron recientemente este artículo en Arxiv, y algunos internautas especularon que fue votado por CVPR 2020. Al mejorar la estructura de la fusión de características multiescala en FPN y basarse en el método de escalado del modelo de EfficientNet , se propone un modelo de algoritmo de detección de objetos escalable y eficiente EfficientDet.
Este trabajo puede verse como una extensión de EfficientNet: Replanteamiento del escalado de modelos para redes neuronales convolucionales en ICML 2019 Oral, que se extiende desde tareas de clasificación hasta tareas de detección (Detección de objetos).
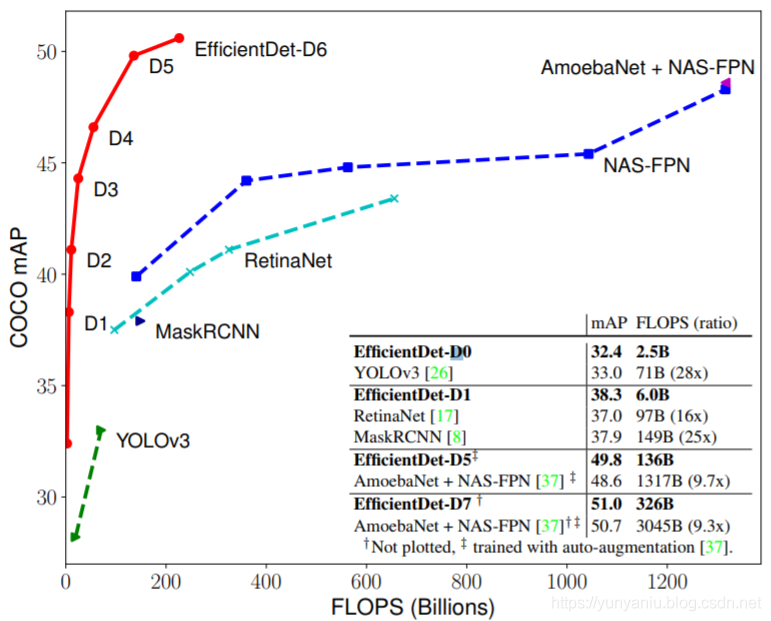
En la Figura 1, se puede ver que existe un cierto equilibrio entre la velocidad de FLOPS de la red neuronal y la precisión de mAP de acuerdo con los requisitos de la escena. A partir de la curva de EfficientDet D1 ~ EfficientDet D7, se puede ver que FLOPS se vuelve gradualmente más lento, mientras que mAP aumenta gradualmente.
contenido
Traducción e interpretación de Detección de Objetos Escalable y Eficiente
Traducción e interpretación de Detección de Objetos Escalable y Eficiente
Dirección del artículo : https://arxiv.org/pdf/1911.09070.pdf
Autor del artículo: Mingxing Tan Ruoming Pang Quoc V. Le Google Research, Brain Team {tanmingxing, rpang, qvl}@google.com
Resumen
| La eficiencia del modelo se ha vuelto cada vez más importante en la visión artificial. En este artículo, estudiamos sistemáticamente varias opciones de diseño de arquitectura de redes neuronales para la detección de objetos y proponemos varias optimizaciones clave para mejorar la eficiencia. En primer lugar, proponemos una red piramidal de características bidireccional ponderada (BiFPN), que permite una fusión de características multiescala fácil y rápida; En segundo lugar, proponemos un método de escalado compuesto que escala uniformemente la resolución , la profundidad y el ancho para todas las redes de predicción de red troncal, de características y de caja/clase al mismo tiempo. En base a estas optimizaciones, hemos desarrollado una nueva familia de detectores de objetos, llamada EfficientDet, que logran consistentemente una mejor eficiencia en un orden de magnitud que la técnica anterior en un amplio espectro de limitaciones de recursos. En particular, sin campanas ni silbatos, nuestro EfficientDet-D7 logra 51,0 mAP de última generación en el conjunto de datos COCO con 52 millones de parámetros y 326B FLOPS1, siendo 4 veces más pequeño y usando 9,3 veces menos FLOPS pero aún más preciso (+0,3 % mAP) que el mejor detector anterior. | La eficiencia del modelo es cada vez más importante en la visión artificial. En este artículo, estudiamos sistemáticamente las opciones de diseño de varias arquitecturas de redes neuronales para la detección de objetos y proponemos varios esquemas de optimización clave para mejorar la eficiencia. En primer lugar, proponemos una red piramidal de características bidireccionales ponderadas (BiFPN) , que puede fusionar características de múltiples escalas de manera conveniente y rápida; en segundo lugar, proponemos un método de escalado híbrido que, simultáneamente, la resolución, la profundidad y el ancho de la red de predicción se escalan de manera uniforme. Con base en estas optimizaciones, desarrollamos una nueva familia de detectores de objetos, llamada EfficientDet , que logra de manera constante una eficiencia mucho mayor que los detectores de última generación dentro de una amplia gama de limitaciones de recursos. En particular, sin ninguna característica adicional, nuestro EfficientDet-D7 alcanza los 51,0 mAP de última generación en el conjunto de datos COCO con 52 millones de parámetros y 326B FLOPS1, 4 veces más pequeño que el mejor detector anterior, menos con 9,3x FLOPS, pero aún así más preciso (+0,3% mAP) que el detector anterior. |
1. Introducción
|
Figura 1: Precisión del modelo FLOPS frente a COCO: todos los números son para un solo modelo de una sola escala. Nuestro EfficientDet logra una precisión mucho mejor con menos cálculos que otros detectores. En particular, el EfficientDet-D7 logra un nuevo estado del arte del 51,0 %. COCO mAP con 4 veces menos parámetros y 9,3 veces menos FLOPS Los detalles se encuentran en la Tabla 2. |
|
| En los últimos años se han hecho enormes progresos hacia una detección de objetos más precisa; mientras tanto, los detectores de objetos de última generación también se vuelven cada vez más caros. Por ejemplo, el último detector NASFPN basado en AmoebaNet [37] requiere 167M de parámetros y 3045B FLOPS (30 veces más que RetinaNet [17]) para lograr una precisión de vanguardia. Los grandes tamaños de los modelos y los elevados costos de computación impiden su implementación en muchas aplicaciones del mundo real, como la robótica y los automóviles autónomos, donde el tamaño del modelo y la latencia están muy limitados. Dadas estas limitaciones de recursos del mundo real, la eficiencia del modelo se vuelve cada vez más importante para la detección de objetos. | En los últimos años, se ha logrado un gran progreso en la mejora de la precisión de la detección de objetos; al mismo tiempo, los detectores de objetos de última generación se han vuelto cada vez más caros. Por ejemplo, el detector NASFPN de última generación basado en AmoebaNet [37] requiere 167 millones de parámetros y 3045B FLOPS (30 veces más que RetinaNet [17]) para lograr una precisión de última generación. Los tamaños de modelo grandes y los costos computacionales elevados dificultan su implementación en muchas aplicaciones del mundo real, como la robótica y los automóviles autónomos, donde el tamaño del modelo y la latencia están muy limitados. Dadas estas limitaciones de recursos realistas, la eficiencia del modelo se vuelve cada vez más importante para la detección de objetos. |
| Ha habido muchos trabajos anteriores con el objetivo de desarrollar arquitecturas de detectores más eficientes, como detectores de una etapa [20, 25, 26, 17] y sin anclaje [14, 36, 32], o comprimir modelos existentes [21, 22]. Aunque estos métodos tienden a lograr una mayor eficiencia, por lo general sacrifican la precisión. Además, la mayoría de los trabajos anteriores solo se enfocan en un rango pequeño o específico de requisitos de recursos, pero la variedad de aplicaciones del mundo real, desde dispositivos móviles hasta centros de datos, a menudo exigen diferentes restricciones de recursos. | 之前有许多致力于开发更高效的探测器架构的工作,如onestage[20,25,26,17]和无锚探测器[14,36,32],或压缩现有模型[21,22]。虽然这些方法趋向于获得更好的效率,但它们通常会牺牲准确性。此外,以前的大多数工作只关注特定的或小范围的资源需求,但是从移动设备到数据中心的各种实际应用程序常常需要不同的资源约束。 |
A natural question is: Is it possible to build a scalable detection architecture with both higher accuracy and better efficiency across a wide spectrum of resource constraints (e.g., from 3B to 300B FLOPS)? This paper aims to tackle this problem by systematically studying various design choices of detector architectures. Based on the onestage detector paradigm, we examine the design choices for backbone, feature fusion, and class/box network, and identify two main challenges:
|
一个很自然的问题是:是否有可能构建一个可伸缩的检测架构,该架构具有更高的准确性和更大的效率,可以跨越各种资源约束(例如,从3B到300B FLOPS)?本文旨在通过系统地研究探测器结构的各种设计选择来解决这一问题。基于onestage检测器范例,我们检查了主干、特征融合和类/盒网络的设计选择,并确定了两个主要挑战:
|
| Finally, we also observe that the recently introduced EfficientNets [31] achieve better efficiency than previous commonly used backbones (e.g., ResNets [9], ResNeXt [33], and AmoebaNet [24]). Combining EfficientNet backbones with our propose BiFPN and compound scaling, we have developed a new family of object detectors, named EfficientDet, which consistently achieve better accuracy with an order-of-magnitude fewer parameters and FLOPS than previous object detectors. Figure 1 and Figure 4 show the performance comparison on COCO dataset [18]. Under similar accuracy constraint, our EfficientDet uses 28x fewer FLOPS than YOLOv3 [26], 30x fewer FLOPS than RetinaNet [17], and 19x fewer FLOPS than the recent NASFPN [5]. In particular, with single-model and single testtime scale, our EfficientDet-D7 achieves state-of-the-art 51.0 mAP with 52M parameters and 326B FLOPS, being 4x smaller and using 9.3x fewer FLOPS yet still more accurate (+0.3% mAP) than the best previous models [37]. Our EfficientDet models are also up to 3.2x faster on GPU and 8.1x faster on CPU than previous detectors, as shown in Figure 4 and Table 2. |
最后,我们还观察到,最近推出的EfficientNets [31]比之前常用的骨干(例如,ResNets [9], ResNeXt [33], AmoebaNet[24])的效率更高。我们将effecentnet主干与我们提出的BiFPN和复合标度相结合,开发了一个新的对象检测器家族,命名为efficient entdet,与以前的对象检测器相比,它始终能够在较少数量级的参数和错误的情况下获得更好的准确性。图1和图4显示了对COCO数据集[18]的性能比较。在类似的精度约束下,我们的effecentdet使用的FLOPS比YOLOv3[26]少28倍,比RetinaNet[17]少30倍,比最近的NASFPN[5]少19倍。特别地,在单模型和单测试时间尺度的情况下,我们的效率测点- d7在52M参数和326B FLOPS的情况下,实现了最先进的51.0 mAP,比以前最好的模型[37]小4倍,减少了9.3倍的FLOPS,但仍然比以前的模型更精确(+0.3% mAP)。我们的EfficientDet模型在GPU上比以前的检测器快3.2倍,在CPU上比以前的检测器快8.1倍,如图4和表2所示。 |
| Our contributions can be summarized as: • We proposed BiFPN, a weighted bidirectional feature network for easy and fast multi-scale feature fusion. • We proposed a new compound scaling method, which jointly scales up backbone, feature network, box/class network, and resolution, in a principled way. • Based on BiFPN and compound scaling, we developed EfficientDet, a new family of detectors with significantly better accuracy and efficiency across a wide spectrum of resource constraints. |
我们的贡献可以总结为: •我们提出了一个加权的双向特征网络BiFPN,用于方便快速的多尺度特征融合。•我们提出了一种新的复合标度方法,可以原则性地对主干、feature network、box/class network、resolution进行联合标度。•基于BiFPN和复合标度,我们开发了EfficientDet,这是一种新的探测器家族,在广泛的资源约束范围内具有更高的准确性和效率。 |
2. Related Work
| One-Stage Detectors: Existing object detectors are mostly categorized by whether they have a region-ofinterest proposal step (two-stage [6, 27, 3, 8]) or not (onestage [28, 20, 25, 17]). While two-stage detectors tend to be more flexible and more accurate, one-stage detectors are often considered to be simpler and more efficient by leveraging predefined anchors [11]. Recently, one-stage detectors have attracted substantial attention due to their efficiency and simplicity [14, 34, 36]. In this paper, we mainly follow the one-stage detector design, and we show it is possible to achieve both better efficiency and higher accuracy with optimized network architectures. | |
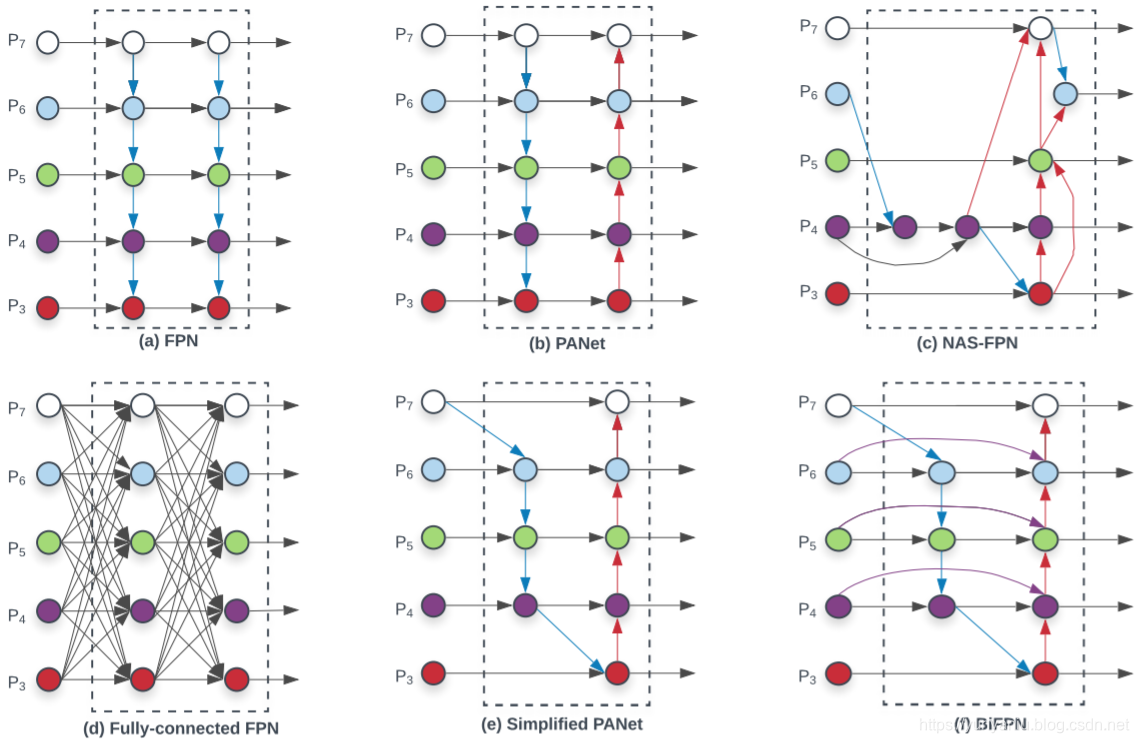
| Multi-Scale Feature Representations: One of the main difficulties in object detection is to effectively represent and process multi-scale features. Earlier detectors often directly perform predictions based on the pyramidal feature hierarchy extracted from backbone networks [2, 20, 28]. As one of the pioneering works, feature pyramid network (FPN) [16] proposes a top-down pathway to combine multi-scale features. Following this idea, PANet [19] adds an extra bottom-up path aggregation network on top of FPN; STDL [35] proposes a scale-transfer module to exploit cross-scale features; M2det [34] proposes a U-shape module to fuse multi-scale features, and G-FRNet [1] introduces gate units for controlling information flow across features. More recently, NAS-FPN [5] leverages neural architecture search to automatically design feature network topology. Although it achieves better performance, NAS-FPN requires thousands of GPU hours during search, and the resulting feature network is irregular and thus difficult to interpret. In this paper, we aim to optimize multi-scale feature fusion with a more intuitive and principled way. | |
| Model Scaling: In order to obtain better accuracy, it is common to scale up a baseline detector by employing bigger backbone networks (e.g., from mobile-size models [30, 10] and ResNet [9], to ResNeXt [33] and AmoebaNet [24]), or increasing input image size (e.g., from 512x512 [17] to 1536x1536 [37]). Some recent works [5, 37] show that increasing the channel size and repeating feature networks can also lead to higher accuracy. These scaling methods mostly focus on single or limited scaling dimensions. Recently, [31] demonstrates remarkable model efficiency for image classification by jointly scaling up network width, depth, and resolution. Our proposed compound scaling method for object detection is mostly inspired by [31]. |
3、BiFPN
| In this section, we first formulate the multi-scale feature fusion problem, and then introduce the two main ideas for our proposed BiFPN: efficient bidirectional cross-scale connections and weighted feature fusion. | |
|
Figure 2: Feature network design – (a) FPN [16] introduces a top-down pathway to fuse multi-scale features from level 3 to 7 (P3 - P7); (b) PANet [19] adds an additional bottom-up pathway on top of FPN; (c) NAS-FPN [5] use neural architecture search to find an irregular feature network topology; (d)-(f) are three alternatives studied in this paper. (d) adds expensive connections from all input feature to output features; (e) simplifies PANet by removing nodes if they only have one input edge; (f) is our BiFPN with better accuracy and efficiency trade-offs. |
|
3.1. Problem Formulation
| Multi-scale feature fusion aims to aggregate features at different resolutions. Formally, given a list of multi-scale features P~ in = (P in l1 , Pin l2 , ...), where P in li represents the feature at level li , our goal is to find a transformation f that can effectively aggregate different features and output a list of new features: P~ out = f(P~ in). As a concrete example, Figure 2(a) shows the conventional top-down FPN [16]. It takes level 3-7 input features P~ in = (P in 3 , ...Pin 7 ), where P in i represents a feature level with resolution of 1/2 i of the input images. For instance, if input resolution is 640x640, then P in 3 represents feature level 3 (640/2 3 = 80) with resolution 80x80, while P in 7 represents feature level 7 with resolution 5x5. The conventional FPN aggregates multi-scale features in a top-down manner:
|
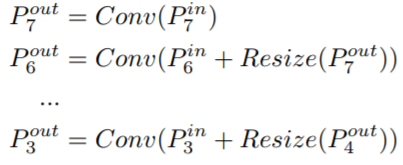
3.2. Cross-Scale Connections
| Conventional top-down FPN is inherently limited by the one-way information flow. To address this issue, PANet [19] adds an extra bottom-up path aggregation network, as shown in Figure 2(b). Cross-scale connections are further studied in [13, 12, 34]. Recently, NAS-FPN [5] employs neural architecture search to search for better cross-scale feature network topology, but it requires thousands of GPU hours during search and the found network is irregular and difficult to interpret or modify, as shown in Figure 2(c). | |
| By studying the performance and efficiency of these three networks (Table 4), we observe that PANet achieves better accuracy than FPN and NAS-FPN, but with the cost of more parameters and computations. To improve model efficiency, this paper proposes several optimizations for cross-scale connections: First, we remove those nodes that only have one input edge. Our intuition is simple: if a node has only one input edge with no feature fusion, then it will have less contribution to feature network that aims at fusing different features. This leads to a simplified PANet as shown in Figure 2(e); Second, we add an extra edge from the original input to output node if they are at the same level, in order to fuse more features without adding much cost, as shown in Figure 2(f); Third, unlike PANet [19] that only has one top-down and one bottom-up path, we treat each bidirectional (top-down & bottom-up) path as one feature network layer, and repeat the same layer multiple times to enable more high-level feature fusion. Section 4.2 will discuss how to determine the number of layers for different resource constraints using a compound scaling method. With these optimizations, we name the new feature network as bidirectional feature pyramid network (BiFPN), as shown in Figure 2(f) and 3. |
3.3. Weighted Feature Fusion
| When fusing multiple input features with different resolutions, a common way is to first resize them to the same resolution and then sum them up. Pyramid attention network [15] introduces global self-attention upsampling to recover pixel localization, which is further studied in [5]. | |
| Previous feature fusion methods treat all input features equally without distinction. However, we observe that since different input features are at different resolutions, they usually contribute to the output feature unequally. To address this issue, we propose to add an additional weight for each input during feature fusion, and let the network to learn the importance of each input feature. Based on this idea, we consider three weighted fusion approaches: | |
| Unbounded fusion: O = P i wi · Ii , where wi is a learnable weight that can be a scalar (per-feature), a vector (per-channel), or a multi-dimensional tensor (per-pixel). We find a scale can achieve comparable accuracy to other approaches with minimal computational costs. However, since the scalar weight is unbounded, it could potentially cause training instability. Therefore, we resort to weight normalization to bound the value range of each weight. | |
| Fusión basada en Softmax: O = P ie wi P je wj · Ii . Una idea intuitiva es aplicar softmax a cada peso, de modo que todos los pesos se normalicen para ser una probabilidad con un rango de valores de 0 a 1, que representa la importancia de cada entrada. Sin embargo, como se muestra en nuestro estudio de ablación en la sección 6.3, el softmax adicional conduce a una ralentización significativa en el hardware de la GPU. Para minimizar el costo de latencia adicional, proponemos además un enfoque de fusión rápida. |