Autor|Yang Yang@zhihu
Fuente|https://zhuanlan.zhihu.com/p/163266388
Desde mayo del año pasado, he estado pendiente del trabajo de Anchor-free. Esta vez, aproveché de compartir la lectura de papel en el grupo para organizar un trabajo relacionado con Anchor free. Por un lado, compartiré algunos trabajos recientes en el campo de la detección de objetivos. Por otro lado, resolveré con ustedes los modelos de red muy candentes CenterNet y FCOS. Cuando los migremos a otras tareas como la segmentación y multi -seguimiento de objetivos, el tipo grande cómo fueron diseñados.



1. Aplicación de Anchor Free en la detección de objetivos
En primer lugar, tenemos que responder ¿por qué hay un ancla? En años anteriores, el problema de detección de objetos generalmente se modelaba como el problema de clasificar y retroceder algunas regiones candidatas. En el detector de una sola etapa, estas regiones candidatas son los anclajes generados por el método de la ventana deslizante; en el detector de dos etapas, las regiones candidatas son las propuestas generadas por el RPN, pero el RPN en sí aún debe clasificar y retroceder los anclajes. generada por el método de la ventana deslizante.

Los varios métodos sin anclaje que enumeré aquí resuelven el problema de detección por otros medios. CornetNet caracteriza el cuadro objetivo al predecir pares de puntos clave (esquina superior izquierda y esquina inferior derecha); CenterNet y FCOS caracterizan el cuadro objetivo al predecir el punto central del objeto y su distancia al cuadro; ExtremeNet detecta los cuatro puntos extremos de el objeto, cuatro puntos extremos se forman en un marco de detección de objetos; AutoAssign también es un artículo reciente, que propone una nueva estrategia de asignación para etiquetas de muestras positivas y negativas en el detector sin ancla; Point-Set es un trabajo reciente de ECCV 2020, Se propone una representación de anclaje basada en puntos más generalizada, que unifica las tres tareas principales de detección de objetivos, segmentación de instancias y estimación de poses, que ampliaremos más adelante.
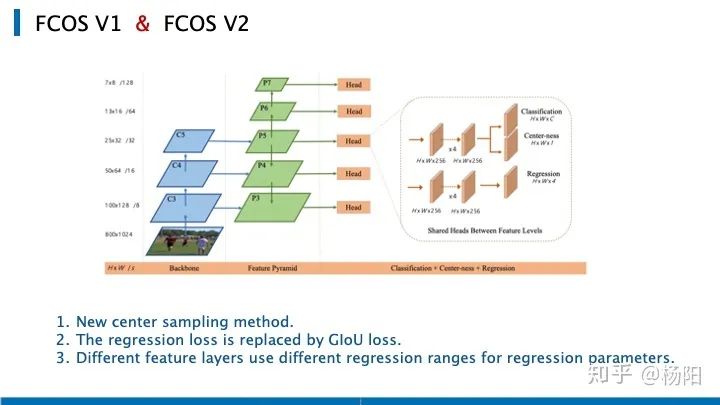
Primero, revisemos brevemente la arquitectura de red de FCOS, donde C3, C4, C5 representan los mapas de características de la red troncal y P3 a P7 son los niveles de características utilizados para la predicción final. Los mapas de características de estas cinco capas estarán seguidos por un encabezado, que incluye tres ramas, que se utilizan para la clasificación, la confianza del punto central y la predicción de regresión. La arquitectura general es muy simple y muchas personas modifican la rama de salida de FCOS para resolver otras tareas, como la segmentación de instancias, la detección de puntos clave y el seguimiento de objetivos.
A continuación, enumero tres ajustes realizados por el autor original al actualizar la versión del artículo. Primero, se utilizó el nuevo método de muestreo de punto central. Al evaluar muestras positivas y negativas, se consideró el tamaño de paso en diferentes etapas. Para ajustar el tamaño de la caja donde se encuentra la muestra positiva. En lugar de juzgar directamente si cae en el gt bbox como en FCOS v1. Este nuevo método de muestreo central reduce la cantidad de muestras difíciles de discriminar, y también se reduce la diferencia de precisión causada por el uso de la rama central. El segundo es reemplazar la pérdida de regresión con la pérdida de GIOU. La tercera es que las diferentes capas de funciones de FCOS v2 usan diferentes rangos de registro (divididos por zancada) cuando retroceden los parámetros. (En FCOS v1, se multiplicó por un parámetro de aprendizaje, que se retuvo en FCOS v2, pero con una importancia reducida).
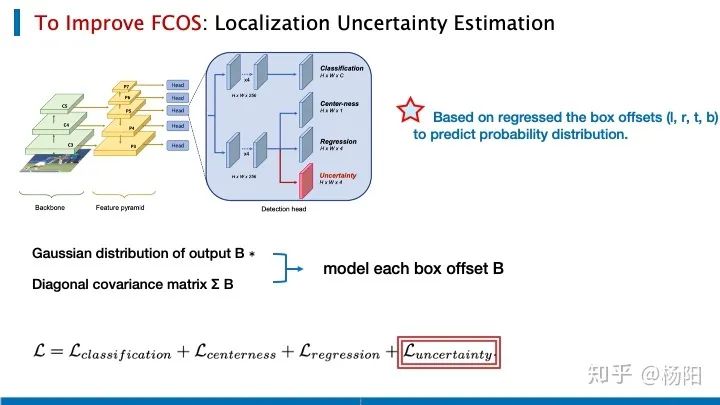
Para mejorar el efecto de fcos, especialmente considerando algunos entornos inestables, debido al ruido del sensor o datos incompletos, el detector de objetivos debe considerar la confianza de la predicción de posicionamiento Algunas personas proponen agregar una rama para predecir la incertidumbre del bbox .
La incertidumbre aquí se obtiene al predecir la distribución de las cuatro compensaciones del bbox. Aquí se supone que cada ejemplo es independiente, y el desplazamiento de cada bbox está representado por la salida de la distribución gaussiana multivariante y la matriz diagonal de la matriz de covarianza. Sobre las tres pérdidas de clasificación FCOS, punto central y regresión, se agrega una nueva pérdida que mide la incertidumbre del desplazamiento de bbox. Echemos un vistazo más de cerca a cómo se implementa.

Las compensaciones de caja aquí están representadas por (l, r, t, b), que son los parámetros que se pueden aprender de la red, la dimensión de B es 4 y μ es la compensación de bbox, y se menciona la distribución gaussiana multivariante calculada. La matriz diagonal de la matriz de covarianza de ,
La pérdida que se introduce en el diseño de la red para medir la incertidumbre del desplazamiento del bbox, podemos centrarnos en el elemento a la izquierda de la línea roja. Cuando el μ predicho es muy diferente de la distribución gaussiana del bbox real, la red tenderá a obtener una desviación estándar grande significa que la incertidumbre en este momento es muy grande. Por supuesto, hay una restricción similar a la regularización detrás de esto, por lo que el límite no debería ser demasiado grande.
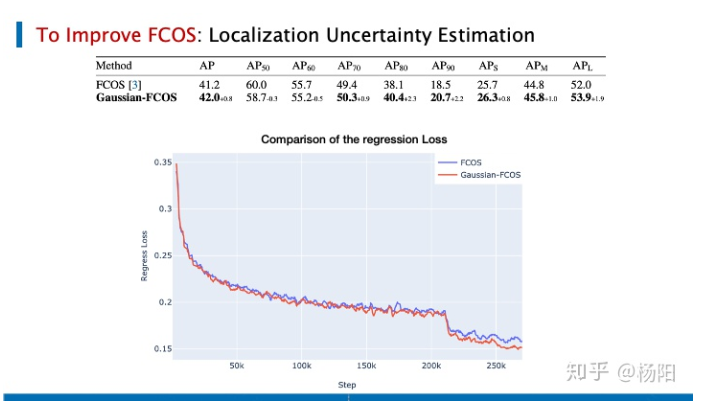
En comparación con FCOS, que también utiliza el marco ResNet-50, puede mejorar AP en 0,8 puntos en el conjunto de datos de coco. Comparando las dos pérdidas, la situación de regresión también es mejor.
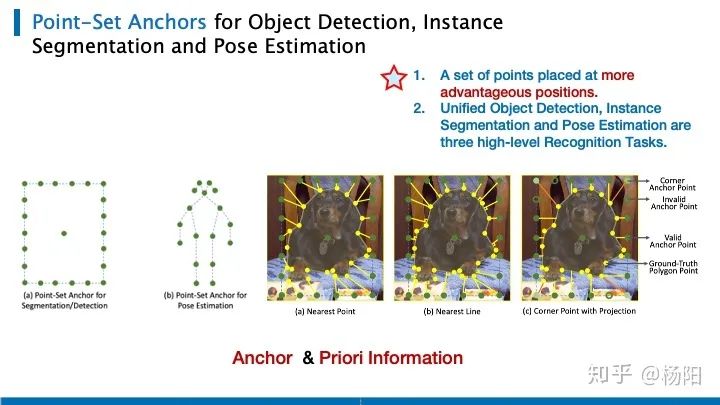
Echemos un vistazo a cómo la red basada en puntos "Anclajes de conjuntos de puntos para detección de objetos, segmentación de instancias y estimación de poses" utiliza la idea de regresión para unificar las tres tareas principales de detección de objetos, segmentación de instancias y estimación de poses. Los autores dicen que esta es la primera persona en unificar estas tres tareas.
El autor cree que en el campo de la detección de objetos, ya sea que varios anclajes con un IOU superior a cierto umbral representen muestras positivas, o que el punto central del objeto represente muestras positivas. Ya sea un método basado en ancla o sin ancla, para el posicionamiento de la muestra positiva en la imagen original, se basa en la forma de regresión para volver directamente a las coordenadas rectangulares, o la longitud y la anchura del rectángulo + el desplazamiento del punto central del rectángulo. Hasta cierto punto, Anchor representa solo información a priori. Anchor puede ser un punto central o un rectángulo. Al mismo tiempo, también puede proporcionar más ideas de diseño de modelos, como la asignación de muestras positivas y negativas, clasificación, función de regresión. selección _ La idea de todos los autores es si pueden proponer un ancla más generalizada, que se pueda aplicar a más tareas, no solo a la detección de objetivos, y dar una mejor información previa.
Para la segmentación de instancias y la detección de objetos, use el ancla más a la izquierda, que tiene dos partes: un punto central y n puntos de anclaje ordenados En cada ubicación de imagen, cambiamos la escala y la relación de aspecto del cuadro delimitador para formar un ancla, como el ancla basado en el método, implica el establecimiento de algunos hiperparámetros. Para anclas en la estimación de poses, use la pose más común en el conjunto de entrenamiento. La tarea de regresión de la detección de objetos es relativamente simple, solo use el punto central o el punto de la esquina superior izquierda/inferior derecha para regresar. Para la segmentación de instancias, el autor utiliza criterios de coincidencia específicos para hacer coincidir los puntos de anclaje en el anclaje de conjunto de puntos verde en la imagen de la derecha y los puntos de la instancia gt amarilla, y convertirlos en tareas de regresión.
Las tres figuras de la derecha conectan los puntos verde y amarillo con el punto más cercano; conectan el punto verde con el borde más cercano; el centro en el extremo derecho es el método optimizado del autor, y el punto diagonal adopta el método del punto más cercano, según al ángulo Los cuatro puntos más cercanos obtenidos dividen el contorno de gt en 4 regiones. Haga líneas verticales correspondientes a los puntos verdes en los límites superior e inferior a los puntos gt válidos (si no están en el área, no son válidos, como los puntos huecos verdes en la figura).
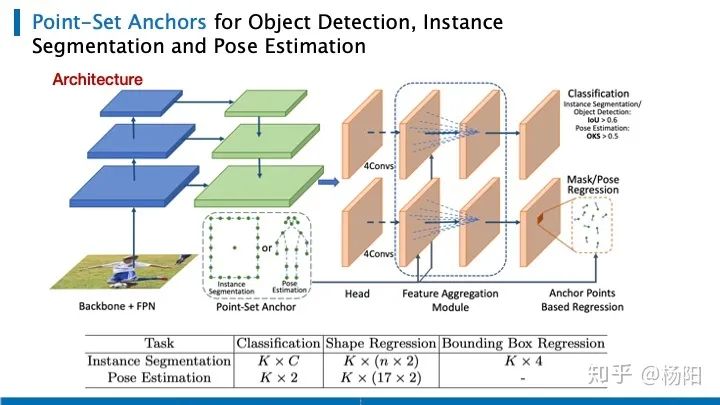
En general, Point-set reemplaza los anclajes rectangulares tradicionales con su nuevo diseño de anclaje propuesto y adjunta una rama de regresión paralela a la cabeza para segmentación de instancias o estimación de pose. La figura muestra su arquitectura de red. Al igual que retinanet, el autor utiliza capas de características de diferentes escalas. La cabeza contiene subredes para clasificación, regresión de pose de segmentación y regresión de cuadros de detección. Cada subred consta de cuatro capas convolucionales de 3 por 3 con paso 1, un módulo FAM que se usa solo para tareas de estimación de pose y una capa de salida. En la siguiente tabla, se enumeran las dimensiones de la capa de salida, correspondientes a tres tareas.
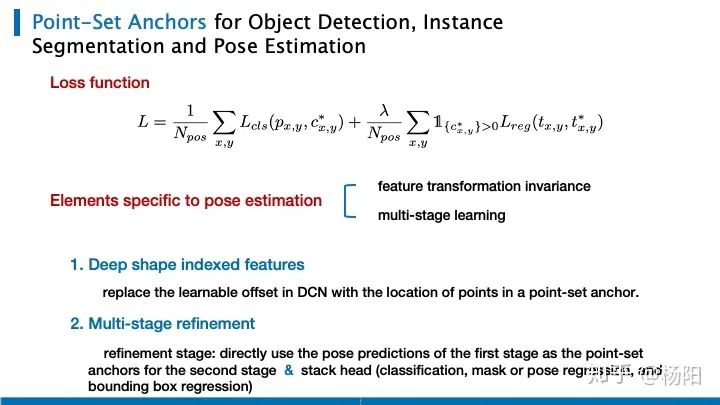
La función de pérdida es muy simple, usando pérdida focal para clasificación y pérdida L1 para tareas de regresión.
Además de la normalización de objetivos y la incorporación de conocimientos previos en la forma del ancla, el autor también menciona cómo podemos usar aún más el ancla para agregar características para garantizar la invariancia de la transformación de características y extender el aprendizaje en varias etapas.
(1) Reemplazamos el desplazamiento aprendible en la convolución variable con la posición del punto medio del ancla basada en puntos.
(2) Debido a esta regresión de la forma del cuerpo humano, es relativamente más difícil de detectar. Por un lado, tiene requisitos muy grandes para la extracción de características y, por otro lado, existen diferencias entre diferentes puntos clave. Por lo tanto, el autor propone que la predicción de pose de la primera etapa se puede usar directamente como ancla de la segunda etapa (clasificación, máscara o regresión de pose, regresión de cuadro delimitador), y se usa una etapa de refinamiento adicional para la estimación de pose.

2. Introducir tres modelos en el campo de la segmentación de instancias
Todos hacen referencia a la práctica de FCOS, y migran la idea libre de anclas en la detección de objetivos a la tarea de segmentación de instancias. Los detalles específicos de la red no se discutirán aquí, solo qué ajustes han hecho en la arquitectura general de FCOS al resolver la tarea de segmentación de instancias.
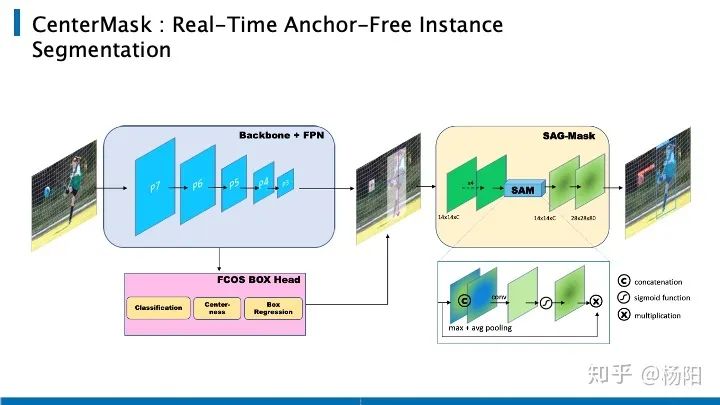
Lo primero que mencioné es CenterMask , lo pongo en la parte superior porque su idea es muy directa, esta estructura se puede entender como una rama de la máscara de FCOS + MaskRCNN.
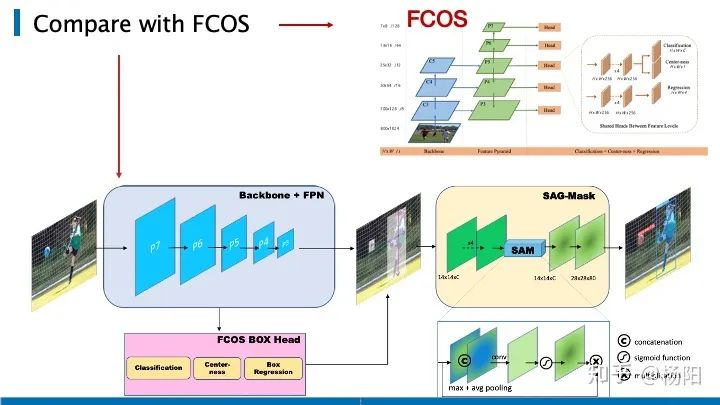
Podemos compararlo con FCOS. La imagen de entrada obtiene el cuadro de destino a través de FCOS. Esta parte es la misma. Después de eso, similar a MaskRCNN, use ROIAlign para recortar el área correspondiente, cambie su tamaño a 14 x14 y finalmente calcule la pérdida a través de la rama de la máscara. La idea es muy simple.
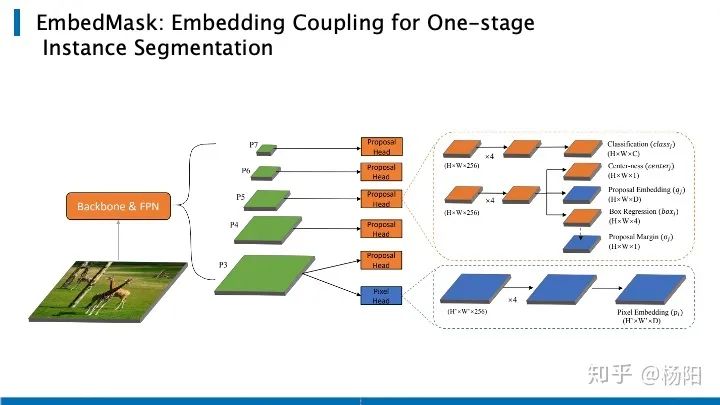
El segundo es EmbedMask.Sobre la base de garantizar la precisión aproximada, su velocidad más rápida puede alcanzar tres veces la de MaskRCNN. Adopta un método de una etapa, que es equivalente a usar directamente la segmentación semántica para obtener resultados de segmentación, y luego usar el agrupamiento o algún medio para integrar la misma instancia para obtener el resultado final de la segmentación de la instancia.
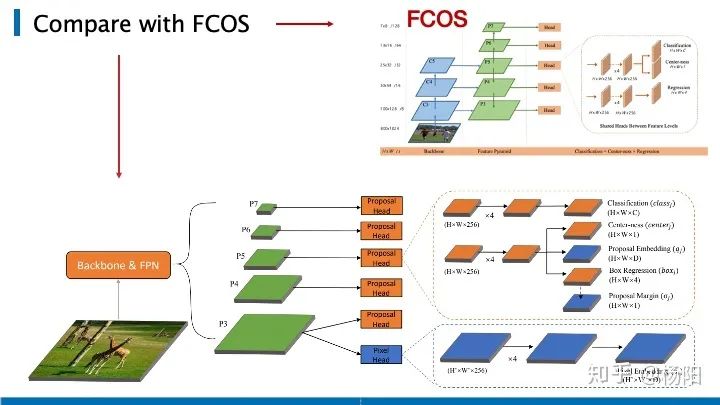
La estructura de toda la red se muestra en la figura anterior, que sigue siendo una estructura FPN. En la función con la resolución más grande, P3 usó la incrustación de píxeles y cada píxel se incrustó en un vector de longitud D, por lo que el resultado final es el mapa de características de H_W_D . A continuación, utilice el encabezado de la propuesta para cada mapa de características P3, P4, P5, P6 y P7, que es el encabezado de la detección de objetivos tradicional. La mejora es que cada propuesta también está integrada en un vector de longitud D. Se utiliza un margen para definir el grado de asociación entre dos incrustaciones, si es más pequeño que la incrustación, se considera que el píxel y la propuesta son la misma instancia. Sin embargo, el uso de un margen definido artificialmente causará algunos problemas, por lo tanto, este documento propone un margen aprendible, que permite que la red aprenda automáticamente el margen de cada propuesta, al igual que el margen de la propuesta que se muestra en la ruta de resultados. En comparación con FCOS, EmbedMask agrega el módulo azul en la figura.
Aunque EmbedMask y CenterMask se basan en un algoritmo de detección de una etapa para la segmentación de instancias, sus puntos centrales no han cambiado. Todos se basan en un detector lo suficientemente bueno como para generar máscaras a partir de la propuesta. Resulta que esto es muy efectivo.El método de segmentación de instancias basado en un detector lo suficientemente bueno no solo conduce a encontrar más máscaras, sino que la generación de estas máscaras a su vez mejorará el efecto del detector en sí. Entonces pueden ver que la caja AP de estas dos segmentaciones de instancias es más alta que la de FCOS, por supuesto, esto es inevitable.
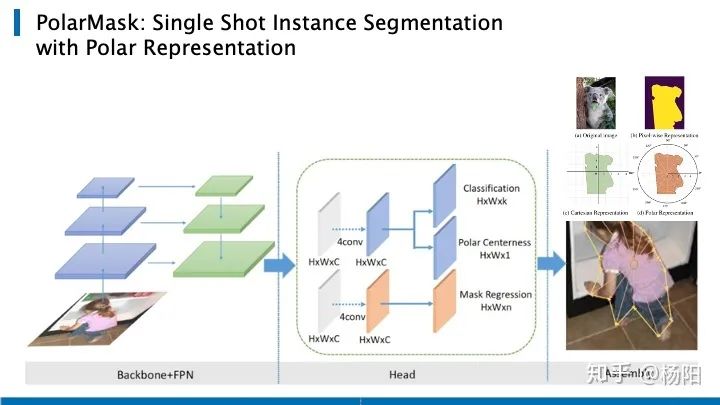
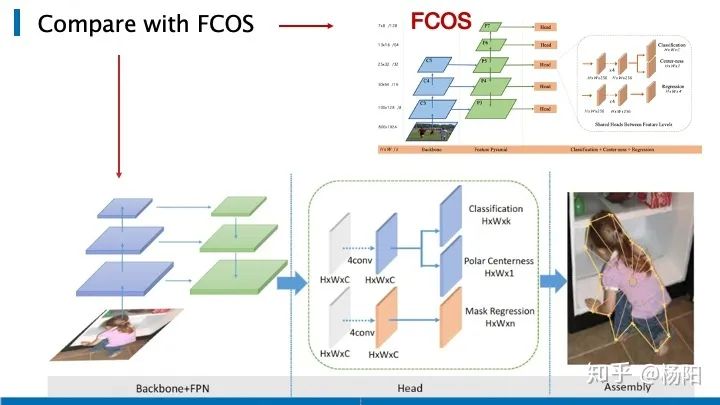
El tercer artículo es PolarMask , que también se basa en FCOS y unifica la segmentación de instancias en el marco de FCN. PolarMask propone un nuevo método de modelado de segmentación de instancias, que divide las coordenadas polares de 360 grados en 36 puntos y obtiene el contorno del objeto al predecir la distancia desde el borde hasta el centro de coordenadas polares en estas 36 direcciones.

3. Algunas preocupaciones en el campo del seguimiento de objetivos múltiples
Aquí comparamos principalmente dos trabajos extendidos basados en CenterNet. Primero, presente brevemente la tarea de MOT (seguimiento de múltiples objetos), que necesita detectar objetos en cada cuadro del video y asignar una identificación a cada objeto para rastrear el objetivo.
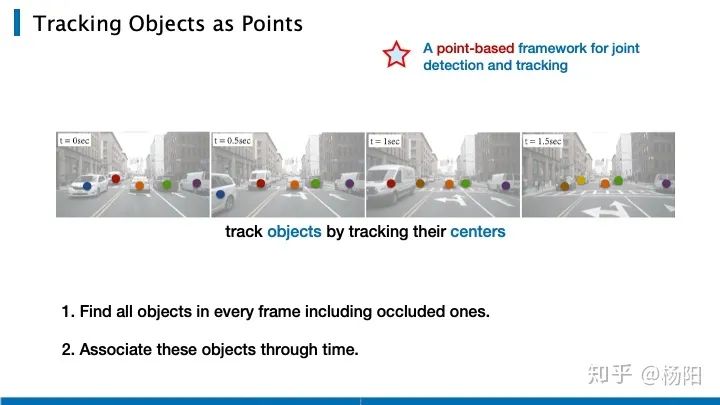
CenterTrack es el trabajo realizado por el autor original de CenterNet. Al extender la tarea de detección de objetivos a la detección de múltiples objetivos, el autor resuelve el problema de seguimiento rastreando el punto central del objeto. Hay dos claves para la tarea de detección de múltiples objetivos: Primero, necesitamos detectar los objetos en cada cuadro, incluidos los objetos que ocluyen, segundo, necesitamos hacer coincidir la identificación de los objetos en la dimensión del tiempo.
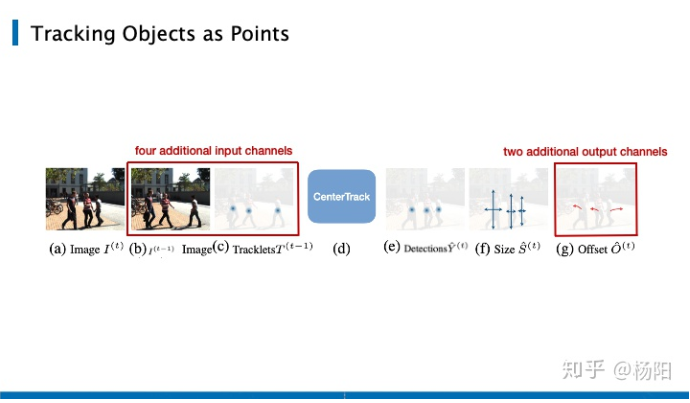
El área roja en la imagen a continuación es para resolver la tarea de seguimiento. Se ingresan la imagen en el momento t, la imagen en el momento t-1 y todos los objetos detectados en el momento t-1. El área roja aquí es diferente de la detección del objetivo tarea. , se agregan cuatro nuevos canales (tres de los cuales son la entrada de la imagen, y el cálculo de un canal se ampliará más adelante).
En la parte de salida, además de generar el mapa de calor del punto pico central detectado y el mapa de características de la longitud y el ancho previstos, la red también genera una compensación de 2 canales, donde la compensación representa la distancia de movimiento del objeto entre dos marcos
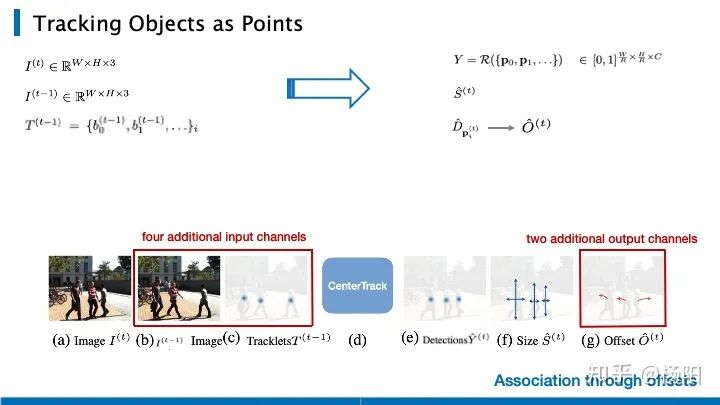
A la izquierda está la entrada de la red ya la derecha está la salida de la red. Matemáticamente, I representa la entrada de la imagen, b en T representa el bbox, y el lado derecho es el punto máximo central detectado, el mapa de características de largo y ancho, y el desplazamiento del movimiento del objeto.

Las anteriores son las expresiones específicas de las tres funciones de pérdida correspondientes al punto pico central, el mapa de características de largo y ancho, y el desplazamiento del movimiento del objeto durante el entrenamiento de la red. Al resolver la tarea de predicción del punto central, aquí se usa la pérdida focal, x e y representan la posición del punto en el mapa de calor, y c es la categoría. Y es un mapa de pico perteneciente a 0, 1, y es un pico convexo que representa una forma gaussiana. Para cada posición, si tiene un punto central en un cierto número de categorías, se formará un pico en el canal correspondiente. Tome la altura máxima de pendiente para cada ubicación. donde p es el punto central y q es la posición. Después de obtener estas alturas máximas de pendiente, las colocamos en un mapa de calor de 1 canal como parte de la entrada de la red. Y la imagen de tres canales del cuadro anterior, constituye la entrada de los 4 canales recién agregados al resolver la tarea de seguimiento.
Para el cálculo de pérdidas de longitud, anchura y desplazamiento, se utiliza una pérdida L1 simple. Con una predicción de compensación lo suficientemente buena, la red puede correlacionar el objetivo en el momento anterior. Para cada posición de detección p, le asignamos el mismo id que el objeto más cercano anterior, y si en un radio κ no hay un objetivo en el momento anterior, generamos una nueva pista.
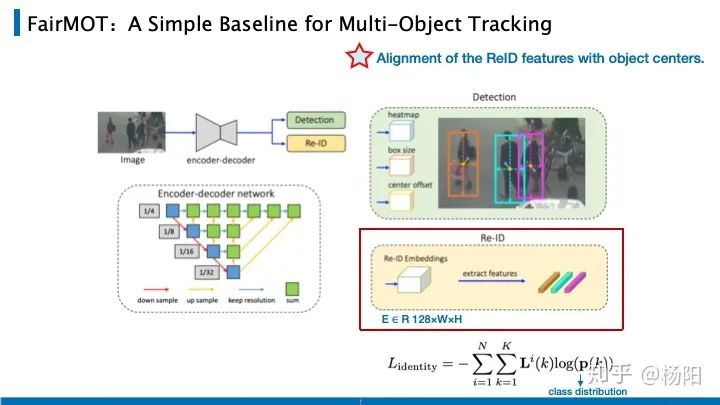
FairMOT también se basa en el trabajo de CenterNet, que es del mismo período que CenterTrack. A diferencia de CenterTrack, que introduce el desplazamiento de la distancia de movimiento del marco objetivo en los marcos delantero y trasero, se basa en la idea de reidentificación y agrega una rama Re-ID a la rama de detección, que utiliza la incrustación identificada por la identificación del objetivo como una tarea de clasificación. En el momento del entrenamiento, todas las instancias de objetos con la misma identificación en todos los conjuntos de entrenamiento se consideran como una clase. Adjuntando un vector de incrustación de 128 dimensiones a cada punto en el mapa de características y finalmente asignando este vector a la puntuación p(k) de cada clase. Donde k es el número de categorías (es decir, el id que ha aparecido), es la codificación one-hot de gt y finalmente calcula la pérdida con softmax.
Actualización del 24 de julio de 2020: algunas personas pueden tener algunas dudas sobre el mapeo de la incrustación en la clasificación aquí. Cuando aparece una gran cantidad de personas nuevas en los marcos posteriores, FairMot puede darles a estas nuevas personas una nueva identificación correcta. Cuando el autor resuelve este problema, la pérdida de clasificación se usa en el entrenamiento y la distancia cos se usa para el juicio en la fase de prueba. Y, cuando el reid no es confiable, el bbox IOU se usa para hacer coincidir. Específicamente, si la incrustación de reid no coincide con el bbox, se utiliza IOU para obtener los posibles fotogramas de seguimiento en el fotograma anterior, se calcula la matriz de similitud entre ellos y, finalmente, se utiliza el algoritmo húngaro para obtener el resultado final.


Finalmente, se adjuntan algunos enlaces a artículos técnicos que me han beneficiado en el proceso de este estudio y clasificación:
Tourbillon: Detección de objetos: era sin anclaje
Chen Kai: Reencarnación de la detección de objetos: basado en anclas y sin anclas https://zhuanlan.zhihu.com/p/62372897

Este artículo es solo para uso académico, si hay alguna infracción, comuníquese para eliminar el artículo.
Descarga y estudio de productos secos
Respuesta entre bastidores: material didáctico de la Universitat Autònoma de Barcelona , puede descargar el material didáctico de alta calidad 3D Vison acumulado por universidades extranjeras durante varios años
Respuesta de fondo: libros de visión por computadora , puede descargar el pdf de libros clásicos en el campo de la visión 3D
Respuesta entre bastidores: cursos de visión 3D, puede aprender excelentes cursos en el campo de la visión 3D
Cursos de calidad visual 3D recomendados:
1. Tecnología de fusión de datos multisensor para conducción autónoma
2. ¡Una ruta de aprendizaje de pila completa para la detección de objetivos de nube de puntos 3D en el campo de la conducción autónoma! (Monomodal + multimodal/datos + código)
3. Comprender a fondo la reconstrucción visual en 3D: análisis de principios, explicación del código y optimización y mejora
4. El primer curso de procesamiento de nubes de puntos doméstico para combate a nivel industrial
5. Visión láser -Combinación de algoritmo SLAM de fusión IMU-GPS
y explicación de
código
Principio de algoritmo clave SLAM láser para interiores y exteriores, código y combate real (cartógrafo + LOAM + LIO-SAM)
11. El despliegue real de modelos de aprendizaje profundo en la conducción autónoma
12. Modelo de cámara y calibración (monocular + binocular + ojo de pez)
13. ¡Pesado! Cuadricópteros: algoritmos y práctica
14. ROS2 desde el inicio hasta el dominio: teoría y práctica
¡Pesado! Taller de Visión por Computador - Se ha establecido un Grupo de Intercambio de Aprendizaje
Escanee el código para agregar un asistente de WeChat, y puede solicitar unirse al taller de visión 3D: grupo de intercambio WeChat de redacción y envío de artículos académicos, que tiene como objetivo intercambiar asuntos de redacción y envío, como conferencias principales, revistas principales, SCI e EI.
Al mismo tiempo , también puede solicitar unirse a nuestro grupo de intercambio de dirección de subdivisión. En la actualidad, hay principalmente aprendizaje de código fuente de la serie ORB-SLAM, visión 3D , CV y aprendizaje profundo , SLAM , reconstrucción 3D , posprocesamiento de nubes de puntos , conducción automática, introducción de CV, medición 3D, VR / AR, reconocimiento facial 3D, imágenes médicas, detección de defectos, reidentificación de peatones, seguimiento de objetivos, aterrizaje visual de productos, competencia visual, reconocimiento de matrículas, selección de hardware, estimación de profundidad, intercambios académicos , intercambios de búsqueda de empleo y otros grupos de WeChat, escanee la siguiente cuenta de WeChat más el grupo, comentarios: "dirección de investigación + escuela/empresa + apodo", por ejemplo: "visión 3D + Universidad Jiaotong de Shanghái + Jingjing". Comente de acuerdo con el formato, de lo contrario no será aprobado. Después de que la adición sea exitosa, se invitará al grupo de WeChat relevante de acuerdo con la dirección de la investigación. Póngase en contacto con las presentaciones originales .

▲Presione prolongadamente para agregar un grupo de WeChat o contribuir

▲Presione prolongadamente para seguir la cuenta oficial
Visión 3D desde la entrada hasta el planeta del conocimiento competente : cursos de video para el campo de la visión 3D (serie de reconstrucción 3D , serie de nube de puntos 3D, serie de luz estructurada , calibración mano-ojo, calibración de cámara , láser/visión SLAM, conducción automática, etc. ) , resumen de puntos de conocimiento, entrada y ruta de aprendizaje avanzado, el último papel compartido y respuesta a preguntas para un cultivo en profundidad, y orientación técnica de ingenieros de algoritmos de varias fábricas grandes. Al mismo tiempo, Planet cooperará con empresas conocidas para lanzar trabajos de desarrollo de algoritmos relacionados con la visión 3D e información de acoplamiento de proyectos, creando un área de reunión para fanáticos acérrimos que integra tecnología y empleo. conocimiento para crear un mejor mundo de IA.
Aprenda la tecnología central de la visión 3D, escanee y vea la introducción, reembolso incondicional dentro de los 3 días

Hay materiales tutoriales de alta calidad en el círculo, que pueden responder preguntas y ayudarlo a resolver problemas de manera eficiente
Lo encuentro útil, por favor dale me gusta y mira ~