Resumen
Basado en los datos de rodamientos de la Universidad Case Western Kitchen, en primer lugar, el método de aumento de datos se utiliza para sobremuestrear los datos originales para aumentar el número de muestras. Luego, usando la transformada wavelet continua, las muestras de entrenamiento unidimensionales se convierten en imágenes RGB bidimensionales. En segundo lugar, las muestras procesadas se dividen en conjuntos de entrenamiento y conjuntos de prueba, y se introducen en el entrenamiento de la red neuronal convolucional. Finalmente, el algoritmo de reducción de dimensionalidad T-SNE se utiliza para visualizar dinámicamente la capa de red especificada por el modelo.
conjunto de datos
Se presenta un conjunto de datos de referencia de fallas de rodamientos obtenido por el centro de datos de la Universidad Case Western Reserve (CWRU) en los Estados Unidos. Se utiliza un banco de pruebas experimental (como se muestra en la Figura 1) para detectar la señal de detección de defectos del rodamiento. La plataforma consta de un motor eléctrico de 1,5 W (izquierda), un decodificador de sensor de torsión (centro) y un medidor de prueba de potencia (derecha). El rodamiento está dañado por el uso de EDM, y las posiciones dañadas son el anillo exterior, el anillo interior y los elementos rodantes. Hay dos tipos de rodamientos, uno es el rodamiento colocado en el extremo de la transmisión, el modelo es SKF6205 y la frecuencia de muestreo es de 12Khz y 48Khz. El otro es el rodamiento colocado en el extremo del ventilador, el modelo es SKF6203 y la frecuencia de muestreo es de 12Khz. La adquisición de la señal de vibración se realiza mediante el acelerómetro. Los datos utilizados en este estudio provienen todos del rodamiento del extremo del variador con una frecuencia de muestreo de 12Khz. Mientras tanto, los diámetros de falla de los cojinetes utilizados en los experimentos fueron 0,007 pulgadas, 0,014 pulgadas y 0,021 pulgadas.

Figura 1 Datos de rodamientos de la Universidad Case Western Reserve
Dirección de descarga de la Universidad de Western Reserve: http://csegroups.case.edu/bearingdatacenter/pages/download-data-file
Los datos anteriores son los datos oficiales, descárguelos usted mismo y organícelos y clasifíquelos según sus propias necesidades. A continuación se muestra la carpeta de datos que he organizado yo mismo. 07, 14, 21 son tres tamaños de cojinetes; 0, 1, 2, 3 son 4 cargas diferentes; 1797, 1772, 1750, 1797 son velocidades para 4 cargas diferentes. como se muestra en la imagen 2.

Figura 2 Organización de datos de tipos de datos
Preprocesamiento de datos
En la parte de preprocesamiento de datos, use matlab para la mejora de datos y el cambio continuo de wavelet.
1. Aumento de datos
Aunque el aprendizaje profundo tiene una buena capacidad de aprendizaje, suele tener una desventaja: necesita una cantidad relativamente grande de datos para obtener un mejor efecto. Teniendo en cuenta que la cantidad de señales de vibración en cada tipo de falla de rodamiento es solo más de 120,000, de acuerdo con 1024 puntos de señal de vibración como muestra, solo hay 120 muestras como máximo. Por lo tanto, para mejorar la generalización y la solidez del modelo, se utilizan métodos de aumento de datos para expandir el conjunto de datos. Comprensión simple y aproximada, es como cortar una sandía. Originalmente, un gran trozo de sandía, cortas muchos cuchillos de acuerdo con una cierta distancia y dirección, y se convierte en varias piezas uniformes de sandía.
Referencia principal: https://blog.csdn.net/zhangjiali12011/article/details/98039748
2. Transformada Wavelet Continua
En comparación con la transformada de Fourier de tiempo corto, la transformada wavelet tiene las características de adaptación de ventana, es decir, la señal de alta frecuencia tiene alta resolución (pero baja resolución de frecuencia) y la señal de baja frecuencia tiene alta resolución de frecuencia (pero baja resolución). resolución temporal) En ingeniería, a menudo nos preocupamos por la frecuencia de las frecuencias bajas y el momento en que aparecen las frecuencias altas, por lo que han sido muy utilizadas en los últimos años. Comprensión simple y grosera, transforma los datos unidimensionales originales en una imagen bidimensional.
Referencia principal: https://blog.csdn.net/weixin_42943114/article/details/896032
3. Visualización de efectos
Debido a la configuración limitada de mi computadora, la velocidad de cálculo aún es un poco insuficiente en todos los aspectos, y solo se han realizado 6 tipos de diagnóstico de fallas. Como se muestra en la Figura 3.




105 datos internos




datos de 118 bolas




130 datos externos




119 datos de la bola




119datos internos




131 datos externos
Figura 3 Seis efectos de transformada wavelet
entrenamiento modelo
La estructura de la red neuronal convolucional VGG16 se muestra en la Figura 4. A través del apilamiento repetido de capas de convolución y capas de agrupación , hay 13 capas de convolución y 3 capas completamente conectadas . La capa de agrupación no cuenta los pesos, por lo que no está incluida en el número total de capas. La capa convolucional y la capa de agrupación son en realidad un proceso de extracción para la imagen de entrada. Las capas de agrupación convolucional multicapa se apilan una sobre otra, lo que hace que la red tenga un campo al tiempo que reduce los parámetros de la red.receptivo [10] . Las muestras se pueden clasificar a través de la capa totalmente conectada y la capa de salida, y la distribución de probabilidad de las muestras actuales que pertenecen a diferentes categorías se puede obtener a través de la función de activación softmax.

Figura 4 modelo VGG16
db_train = tf.data.Dataset.from_tensor_slices((x_train,y_train))
db_train = db_train.shuffle(1000).batch(4)
db_test = tf.data.Dataset.from_tensor_slices((x_test,y_test))
sample = next(iter(db_train))
print("sample: ",sample[0].shape,sample[1].shape)
#--------------------------------卷积神经网络-----------------------------------------
conv_layers = [
layers.Conv2D(64, kernel_size=[3, 3], padding="same", activation=tf.nn.relu),
layers.Conv2D(64, kernel_size=[3, 3], padding="same", activation=tf.nn.relu),
layers.MaxPool2D(pool_size=[4, 4], strides=4, padding='same'),
# unit 2
layers.Conv2D(128, kernel_size=[3, 3], padding="same", activation=tf.nn.relu),
layers.Conv2D(128, kernel_size=[3, 3], padding="same", activation=tf.nn.relu),
layers.MaxPool2D(pool_size=[4, 4], strides=4, padding='same'),
# unit 3
layers.Conv2D(256, kernel_size=[3, 3], padding="same", activation=tf.nn.relu),
layers.Conv2D(256, kernel_size=[3, 3], padding="same", activation=tf.nn.relu),
layers.MaxPool2D(pool_size=[4, 4], strides=4, padding='same'),
# unit 4
layers.Conv2D(512, kernel_size=[3, 3], padding="same", activation=tf.nn.relu),
layers.Conv2D(512, kernel_size=[3, 3], padding="same", activation=tf.nn.relu),
layers.MaxPool2D(pool_size=[2, 2], strides=2, padding='same'),
# unit 5
layers.Conv2D(512, kernel_size=[3, 3], padding="same", activation=tf.nn.relu),
layers.Conv2D(512, kernel_size=[3, 3], padding="same", activation=tf.nn.relu),
layers.MaxPool2D(pool_size=[2, 2], strides=2, padding='same')
]
def main():
conv_net = Sequential(conv_layers)
# 测试输出的图片尺寸
conv_net.build(input_shape=[None, 128, 128, 3])
x = tf.random.normal([4, 128, 128, 3])
out = conv_net(x)
print(out.shape)
# 设置全连接层
fc_net = Sequential([
layers.Dense(256, activation=tf.nn.relu),
layers.Dense(128, activation=tf.nn.relu),
layers.Dense(6, activation=None)
])
conv_net.build(input_shape=[None, 128, 128, 3])
fc_net.build(input_shape=[None, 512])
optimizer = optimizers.Adam(lr=0.00001)
variables = conv_net.trainable_variables + fc_net.trainable_variables
for epoch in range(50):
for step,(x,y) in enumerate(db_train):
with tf.GradientTape() as tape:
out = conv_net(x)
out = tf.reshape(out,[-1,512])
logits = fc_net(out)
y_hot = tf.one_hot(y,depth=3)
# 计算loss数值
loss = tf.losses.categorical_crossentropy(y_hot,logits,from_logits=True)
loss = tf.reduce_mean(loss)
grads = tape.gradient(loss,variables)
optimizer.apply_gradients(zip(grads,variables))
if step % 20 ==0:
print(epoch, step, "loss ", float(loss))
total_num = 0
totsl_correct = 0
for x,y in db_test:
x = tf.expand_dims(x,axis=0)
# print(x.shape)
out = conv_net(x)
out = tf.reshape(out,[-1,512])
logits = fc_net(out)
prob = tf.nn.softmax(logits,axis=1)
pred = tf.argmax(prob,axis=1)
pred = tf.cast(pred,dtype=tf.int32)
correct = tf.cast(tf.equal(pred,y),dtype=tf.int32)
correct = tf.reduce_sum(correct)
total_num += x.shape[0]
totsl_correct += int(correct)
acc = totsl_correct/total_num
print(epoch, acc)
conv_net.save('weights/conv.h5')
fc_net.save('weights/fc.h5')Pruebas de modelos
import tensorflow as tf
from tensorflow.keras import layers,optimizers,datasets,Sequential
import os
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'
os.environ['CUDA_VISIBLE_DEVICES'] = '/gpu:0'
tf.random.set_seed(2345)
from PIL import Image
import numpy as np
#-------------------------------读取待预测图片------------------------------------
ima1 = os.listdir('E:/prediction/')
def read_image1(filename):
img = Image.open('E:/prediction/'+filename).convert('RGB')
return np.array(img)
x_train = []
for i in ima1:
x_train.append(read_image1(i))
x_train = np.array(x_train)
#-------------------------------加载神经网络模型-----------------------------------
conv_net = tf.keras.models.load_model('weights/conv.h5')
fc_net = tf.keras.models.load_model('weights/fc.h5')
#-----------------------------------图片识别--------------------------------------
out = conv_net(x_train)
out = tf.reshape(out,[-1,512])
logits = fc_net(out)
prob = tf.nn.softmax(logits,axis=1)
prob = np.array(prob)
pred = tf.argmax(prob,axis=1)
pred = np.array(pred)
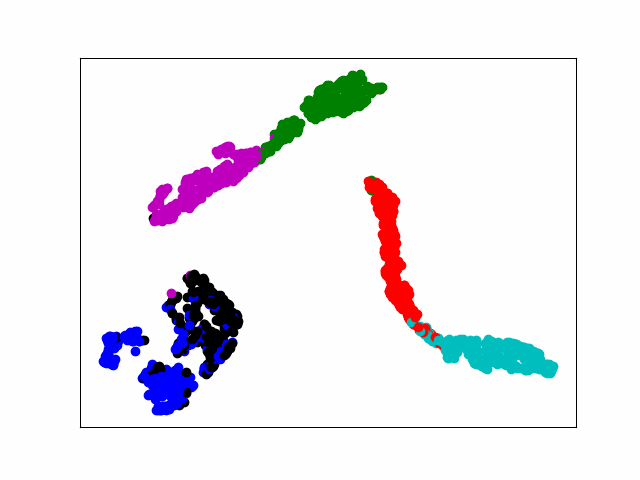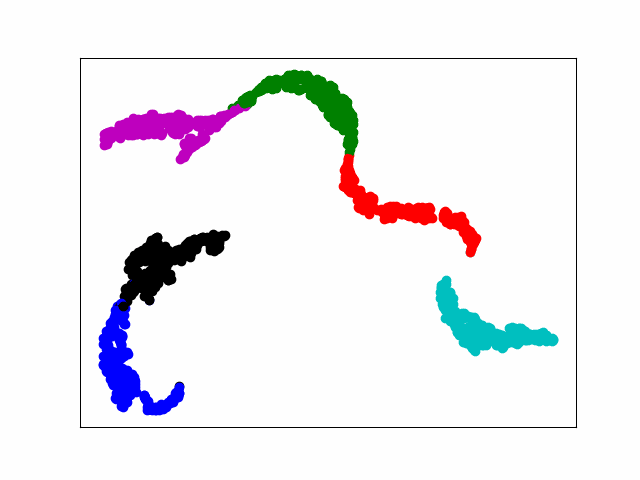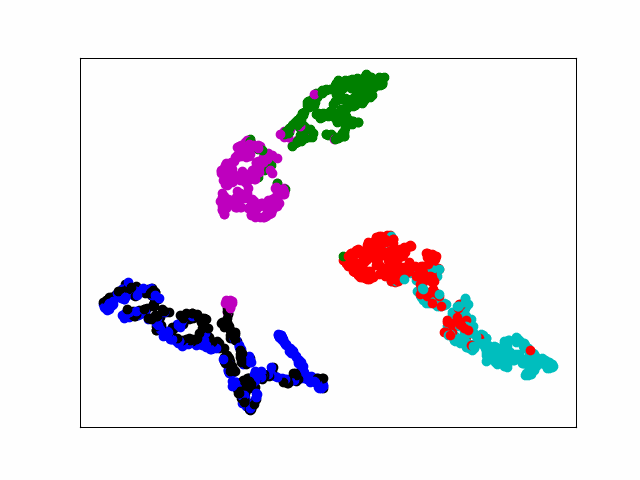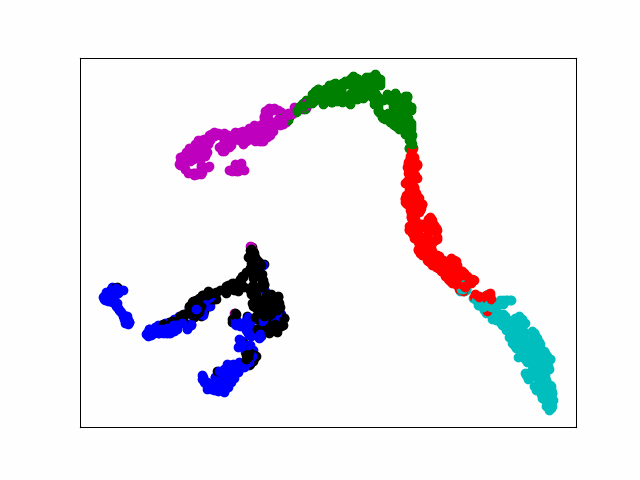
print(pred)Modelo T-SNE Pantalla dinámica
1. Genera una imagen
SNE es la incrustación de vecinos estocásticos.La idea básica es que los puntos de datos similares en un espacio de alta dimensión se asignan a un espacio de baja dimensión con distancias similares. SNE convierte esta relación de distancia en una probabilidad condicional para representar la similitud.
En este documento, nos enfocamos en la visualización dinámica de la última capa de salida de la capa completamente conectada. El primer paso es generar una figura para cada época y guardarla en la carpeta especificada. Finalmente, use la herramienta gif para hacer imágenes dinámicas. Hay muchas maneras de hacerlo, y es bueno poder lograr el efecto.
Referencia principal: https://blog.csdn.net/SweetSeven_/article/details/108010565
#轴承数据训练
for epoch in range(20):
# 定义列表,data_xx存放训练数据,data_y存放训练数据标签
data_xx = []
data_y = []
for step,(x,y) in enumerate(db_train):
with tf.GradientTape() as tape:
#计算一个batchsize的卷积神经网络输出
out = conv_net(x)
#卷积神经网络输出数据进行reshape[-1,512]
out = tf.reshape(out,[-1,512])
#reshape的数据输入到全连接层
logits = fc_net(out)
#最终输出数据进行one_hot转换
y_hot = tf.one_hot(y,depth=6)
# 计算loss数值
loss = tf.losses.categorical_crossentropy(y_hot,logits,from_logits=True)
loss = tf.reduce_mean(loss)
grads = tape.gradient(loss,variables)
optimizer.apply_gradients(zip(grads,variables))
#每隔20个bachsize,输出一次loss数值
if step % 20 ==0:
print(epoch, step, "loss ", float(loss))
if epoch >= 2:
# 列出对应元素的标签值
data_y.extend(y)
# 获取所有训练后的样本数据
for i in range(len(logits)):
# 得到训练的样本
data_xx.append(logits[i])
#每次epoch将data_y和data_xx列表转换为numpy数据
if epoch >= 2:
data_y = np.array(data_y)
data_xx = np.array(data_xx)
# print("data_xx", data_xx.shape)
# print("data_y", data_y.shape)
# print("data_y", data_y)
#进行tsne降维
tsne = manifold.TSNE(n_components=2, init='pca')
X_tsne = tsne.fit_transform(data_xx)
#将降维数据进行可视化显示
x_min, x_max = X_tsne.min(0), X_tsne.max(0)
X_norm = (X_tsne - x_min) / (x_max - x_min) # 归一化
for i in range(len(X_norm)):
# plt.text(X_norm[i, 0], X_norm[i, 1], str(y[i]), color=plt.cm.Set1(y[i]),
if data_y[i] == 0:
color = 'r'
if data_y[i] == 1:
color = 'g'
if data_y[i] == 2:
color = 'b'
if data_y[i] == 3:
color = 'c'
if data_y[i] == 4:
color = 'm'
if data_y[i] == 5:
color = 'k'
# fontdict={'weight': 'bold', 'size': 9})
plt.scatter(X_norm[i][0], X_norm[i][1], c=color, cmap=plt.cm.Spectral)
plt.xticks([])
plt.yticks([])
plt.savefig("E:/tsne_figure/" + str(epoch) + ".png")
plt.close('all')2. Generar gif
# 初始化图片地址文件夹途径
image_path = 'E:/tsne_figure/'
# 获取文件列表
files = os.listdir(image_path)
# 定义第一个文件的全局路径
file_first_path = os.path.join(image_path, files[0])
# 获取Image对象
img = Image.open(file_first_path)
# 初始化文件对象数组
images = []
for image in files[:]:
# 获取当前图片全量路径
img_path = os.path.join(image_path, image)
# 将当前图片使用Image对象打开、然后加入到images数组
images.append(Image.open(img_path))
# 保存并生成gif动图
img.save('beauty.gif', save_all=True, append_images=images, loop=0, duration=200)3. Demostración de efectos
El poder de cómputo de la computadora no es suficiente y 20 épocas funcionan toda la noche. Finalmente, la pérdida es estable alrededor de 0.005, lo cual es visualizado por tsne, que básicamente realiza la separación de diferentes tipos.