Autor丨Yan Tingshuai@zhihu (autorizado)
Fuente丨https://zhuanlan.zhihu.com/p/489892744
Editar 丨 Plataforma Gokushi
Debido a las necesidades laborales, recientemente se han complementado los conocimientos en formación distribuida. Después de un estudio teórico, todavía me siento sin terminar, y muchos puntos de conocimiento no se pueden obtener con precisión (por ejemplo: cómo debería ser la dispersión primitiva distribuida, all reduce y otros niveles de código, cómo se usa el algoritmo ring all reduce en la sincronización de gradiente, cómo se actualiza parcialmente el parámetro del servidor de parámetros).
"Lo que no puedo crear, no lo entiendo", estaba escrito en la pizarra de la oficina del famoso físico y premio Nobel Richard Feynman. También hay un eslogan de "muéstrame el código" en el mundo de los programadores. Por lo tanto, planeo escribir una serie de artículos sobre capacitación distribuida, presentar el concepto abstracto de capacitación distribuida en forma de código y asegurarme de que cada código sea ejecutable, verificable y reproducible, y contribuir con el código fuente para permitir que todos se comuniquen entre sí. otro.
Después de la investigación, se encontró que pytorch tiene una buena abstracción y una interfaz perfecta para el entrenamiento distribuido. Por lo tanto, esta serie de artículos se llevará a cabo con pytorch como marco principal. Muchos de los ejemplos en el artículo son de documentos de pytorch y depuración. y expansión.
Finalmente, dado que ya existen muchas introducciones teóricas a la formación distribuida en Internet, la introducción de la parte teórica no será el foco de esta serie de artículos, me centraré en la introducción a nivel de código.
Pytorch: experiencia minimalista de entrenamiento distribuido: https://zhuanlan.zhihu.com/p/477073906
Pytorch - Primitivas de comunicación distribuida (con código fuente): https://zhuanlan.zhihu.com/p/478953028
Pytorch: entrenamiento distribuido allreduce escrito a mano (con código fuente): https://zhuanlan.zhihu.com/p/482557067
Pytorch - Implementación paralela y minimalista entre operadores (con código fuente): https://zhuanlan.zhihu.com/p/483640235
Pytorch: implementación minimalista de varias máquinas y varias tarjetas (con código fuente): https://zhuanlan.zhihu.com/p/486130584
1. Introducción
Pytorch introdujo torchrun en 1.9.0 como reemplazo de las versiones anteriores a 1.9.0 torch.distributed.launch. Torchrun torch.distributed.launch agrega principalmente dos funciones basadas en la función:
Conmutación por error: cuando falla la capacitación de los trabajadores, todos los trabajadores se reiniciarán automáticamente para continuar con la capacitación;
Elástico: los nodos se pueden agregar o eliminar dinámicamente.Este artículo usará un ejemplo para ilustrar cómo se debe usar Elastic Training;
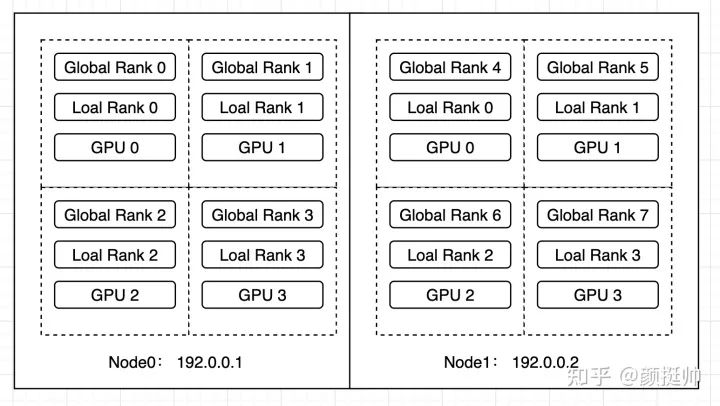
En este ejemplo, un grupo de trabajadores con 4 GPU se iniciará primero en el Nodo0 y, después de un período de capacitación, los trabajadores con 4 GPU se iniciarán en el Nodo1 y se formará un nuevo grupo de trabajadores con los trabajadores en el Nodo1, formando finalmente un grupo de trabajadores de GPU 2. Capacitación distribuida para 8 tarjetas.
2. Construcción de modelos
Un modelo de red neuronal modelo completamente conectado simple
class ToyModel(nn.Module):
def __init__(self):
super(ToyModel, self).__init__()
self.net1 = nn.Linear(10, 10)
self.relu = nn.ReLU()
self.net2 = nn.Linear(10, 5)
def forward(self, x):
return self.net2(self.relu(self.net1(x)))3. Procesamiento de puntos de control
Dado que cada vez que se agrega o elimina un nodo, se eliminarán todos los trabajadores y luego se reiniciarán todos los trabajadores para el entrenamiento. Por lo tanto, el estado de entrenamiento debe guardarse en el código de entrenamiento para garantizar que el entrenamiento pueda continuar con el último estado después de reiniciar.
La información que debe guardarse generalmente incluye lo siguiente:
modelo : información de parámetros del modelo
optimizador : la confianza del parámetro del optimizador
época: el número de épocas ejecutadas actualmente
El código para guardar y cargar es el siguiente
torch.save: use el pickle de python para serializar el objeto de python y guardarlo en un archivo local;torch.load: Deserialice el archivo local después de torch.save y cárguelo en la memoria;model.state_dict():Almacena cada capa del modelo y su correspondiente información de parámetrosoptimizer.state_dict(): Almacena la información de parámetros del optimizador
def save_checkpoint(epoch, model, optimizer, path):
torch.save({
"epoch": epoch,
"model_state_dict": model.state_dict(),
"optimize_state_dict": optimizer.state_dict(),
}, path)
def load_checkpoint(path):
checkpoint = torch.load(path)
return checkpoint4. Código de entrenamiento
La lógica de inicialización es la siguiente:
Líneas 1~3: salida de las variables de entorno clave del trabajador actual para una visualización posterior de los resultados
Líneas 5-8: Cree el modelo, el optimizador y la función de pérdida
Líneas 10 a 12: información de parámetros de inicialización
Líneas 14 a 19: si hay un punto de control, cargue el punto de control y asígnelo a modelo, optimizador y firt_epoch
local_rank = int(os.environ["LOCAL_RANK"])
rank = int(os.environ["RANK"])
print(f"[{os.getpid()}] (rank = {rank}, local_rank = {local_rank}) train worker starting...")
model = ToyModel().cuda(local_rank)
ddp_model = DDP(model, [local_rank])
loss_fn = nn.MSELoss()
optimizer = optim.SGD(ddp_model.parameters(), lr=0.001)
optimizer.zero_grad()
max_epoch = 100
first_epoch = 0
ckp_path = "checkpoint.pt"
if os.path.exists(ckp_path):
print(f"load checkpoint from {ckp_path}")
checkpoint = load_checkpoint(ckp_path)
model.load_state_dict(checkpoint["model_state_dict"])
optimizer.load_state_dict(checkpoint["optimize_state_dict"])
first_epoch = checkpoint["epoch"]Lógica de entrenamiento:
Línea 1: el número de ejecuciones de epoch es desde first_epoch hasta max_epoch, por lo que la época original puede continuar entrenándose después de reiniciar el trabajador;
Línea 2: para mostrar el efecto de agregar nodos dinámicamente, agregue la función de suspensión aquí para reducir la velocidad de entrenamiento;
Líneas 3 a 8: modelo de proceso de formación;
Línea 9: Para simplificar, el texto se guarda como un punto de control por época, la época actual, el modelo y el optimizador se guardan en el punto de control;
for i in range(first_epoch, max_epoch):
time.sleep(1) # 为了展示动态添加node效果,这里添加sleep函数来降低训练的速度
outputs = ddp_model(torch.randn(20, 10).to(local_rank))
labels = torch.randn(20, 5).to(local_rank)
loss = loss_fn(outputs, labels)
loss.backward()
print(f"[{os.getpid()}] epoch {i} (rank = {rank}, local_rank = {local_rank}) loss = {loss.item()}\n")
optimizer.step()
save_checkpoint(i, model, optimizer, ckp_path)5. Cómo empezar
Dado que usamos torchrun para iniciar tareas de múltiples máquinas y tarjetas, no es necesario usar la interfaz de generación para iniciar múltiples procesos (torchrun será responsable de iniciar nuestro script de python como un proceso), así que llame directamente a la función de tren escrita arriba, y por separado antes y después Simplemente agregue las funciones de inicialización y efecto de DistributedDataParallel.
El siguiente código describe la invocación de la interfaz de tren anterior.
def run():
env_dict = {
key: os.environ[key]
for key in ("MASTER_ADDR", "MASTER_PORT", "WORLD_SIZE", "LOCAL_WORLD_SIZE")
}
print(f"[{os.getpid()}] Initializing process group with: {env_dict}")
dist.init_process_group(backend="nccl")
train()
dist.destroy_process_group()
if __name__ == "__main__":
run()En este ejemplo, torchrun se utiliza para realizar tareas de entrenamiento distribuidas en varias máquinas y varias tarjetas (Nota: torch.distributed.launch ha sido eliminada por pytorch, intente no volver a usarla). El script de inicio se describe a continuación (Nota: tanto el nodo 0 como el nodo 1 se inician a través de este script)
--nnodes=1:3: Indica que la tarea de entrenamiento actual acepta al menos 1 nodo y como máximo 3 nodos participan en el entrenamiento distribuido;--nproc_per_node=4: Indica que hay 4 procesos en el nodo en cada nodo--max_restarts=3: El número máximo de reinicios de un grupo de trabajo; debe tenerse en cuenta aquí que la falla del nodo, la reducción del nodo y el aumento del nodo provocarán el reinicio;--rdzv_id=1: una identificación de trabajo única, todos los nodos usan la misma identificación de trabajo;--rdzv_backend: La implementación backend de rendezvous admite tanto c10d como etcd de forma predeterminada; rendezvous se utiliza para la comunicación y la coordinación entre varios nodos;--rdzv_endpoint: La dirección de encuentro, que debe ser la IP del host y el puerto de un nodo;
torchrun \
--nnodes=1:3\
--nproc_per_node=4\
--max_restarts=3\
--rdzv_id=1\
--rdzv_backend=c10d\
--rdzv_endpoint="192.0.0.1:1234"\
train_elastic.py6. Análisis de resultados
Código: BetterDL - train_elastic.py: https://github.com/tingshua-yts/BetterDL/blob/master/test/pytorch/DDP/train_elastic.py
Entorno operativo: máquinas v100 de 2 x 4 tarjetas
image: pytorch/pytorch:1.11.0-cuda11.3-cudnn8-runtime
gpu: v100Primero ejecute el script de inicio en el nodo0
torchrun \
--nnodes=1:3\
--nproc_per_node=4\
--max_restarts=3\
--rdzv_id=1\
--rdzv_backend=c10d\
--rdzv_endpoint="192.0.0.1:1234"\
train_elastic.pyobtener el siguiente resultado
Líneas 2 a 5: el inicio actual es una tarea de entrenamiento de 4 tarjetas de una sola máquina, por lo que WORLD_SIZE es 4 y LOCAL_WORKD_SIZE también es 4
Líneas 6~9: Un total de 4 rangos participan en entrenamiento distribuido, rango0~rango3
Líneas 10~18: rank0~rank3 todos empiezan a entrenar desde epoch=0
r/workspace/DDP# sh run_elastic.sh
[4031] Initializing process group with: {'MASTER_ADDR': '192.0.0.1', 'MASTER_PORT': '44901', 'WORLD_SIZE': '4', 'LOCAL_WORLD_SIZE': '4'}
[4029] Initializing process group with: {'MASTER_ADDR': '192.0.0.1', 'MASTER_PORT': '44901', 'WORLD_SIZE': '4', 'LOCAL_WORLD_SIZE': '4'}
[4030] Initializing process group with: {'MASTER_ADDR': '192.0.0.1', 'MASTER_PORT': '44901', 'WORLD_SIZE': '4', 'LOCAL_WORLD_SIZE': '4'}
[4032] Initializing process group with: {'MASTER_ADDR': '192.0.0.1', 'MASTER_PORT': '44901', 'WORLD_SIZE': '4', 'LOCAL_WORLD_SIZE': '4'}
[4029] (rank = 0, local_rank = 0) train worker starting...
[4030] (rank = 1, local_rank = 1) train worker starting...
[4032] (rank = 3, local_rank = 3) train worker starting...
[4031] (rank = 2, local_rank = 2) train worker starting...
[4101] epoch 0 (rank = 1, local_rank = 1) loss = 0.9288564920425415
[4103] epoch 0 (rank = 3, local_rank = 3) loss = 0.9711472988128662
[4102] epoch 0 (rank = 2, local_rank = 2) loss = 1.0727070569992065
[4100] epoch 0 (rank = 0, local_rank = 0) loss = 0.9402943253517151
[4100] epoch 1 (rank = 0, local_rank = 0) loss = 1.0327017307281494
[4101] epoch 1 (rank = 1, local_rank = 1) loss = 1.4485043287277222
[4103] epoch 1 (rank = 3, local_rank = 3) loss = 1.0959293842315674
[4102] epoch 1 (rank = 2, local_rank = 2) loss = 1.0669530630111694
...Ejecute el mismo script que el anterior en el nodo1
torchrun \
--nnodes=1:3\
--nproc_per_node=4\
--max_restarts=3\
--rdzv_id=1\
--rdzv_backend=c10d\
--rdzv_endpoint="192.0.0.1:1234"\
train_elastic.pyEl resultado en el nodo 1 es el siguiente:
Líneas 2 a 5: debido a la adición del nodo 1, actualmente se ejecuta la tarea de entrenamiento distribuido de 2 máquinas y 8 tarjetas, por lo que WORLD_SIZE=8, LOCAL_WORLD_SIZE=4
Líneas 6 a 9: el rango actual de los trabajadores en el nodo 1 es rango 4 ~ rango 7
Líneas 13 a 20: dado que se agregó el nodo 1 cuando el entrenamiento de trabajo en el nodo 0 llegó a la época 35, comenzó a entrenar después de la época 35
/workspace/DDP# sh run_elastic.sh
[696] Initializing process group with: {'MASTER_ADDR': '192.0.0.1', 'MASTER_PORT': '42913', 'WORLD_SIZE': '8', 'LOCAL_WORLD_SIZE': '4'}
[697] Initializing process group with: {'MASTER_ADDR': '192.0.0.1', 'MASTER_PORT': '42913', 'WORLD_SIZE': '8', 'LOCAL_WORLD_SIZE': '4'}
[695] Initializing process group with: {'MASTER_ADDR': '192.0.0.1', 'MASTER_PORT': '42913', 'WORLD_SIZE': '8', 'LOCAL_WORLD_SIZE': '4'}
[694] Initializing process group with: {'MASTER_ADDR': '192.0.0.1', 'MASTER_PORT': '42913', 'WORLD_SIZE': '8', 'LOCAL_WORLD_SIZE': '4'}
[697] (rank = 7, local_rank = 3) train worker starting...
[695] (rank = 5, local_rank = 1) train worker starting...
[694] (rank = 4, local_rank = 0) train worker starting...
[696] (rank = 6, local_rank = 2) train worker starting...
load checkpoint from checkpoint.ptload checkpoint from checkpoint.pt
load checkpoint from checkpoint.pt
load checkpoint from checkpoint.pt
[697] epoch 35 (rank = 7, local_rank = 3) loss = 1.1888569593429565
[694] epoch 35 (rank = 4, local_rank = 0) loss = 0.8916441202163696
[695] epoch 35 (rank = 5, local_rank = 1) loss = 1.5685604810714722
[696] epoch 35 (rank = 6, local_rank = 2) loss = 1.11683189868927
[696] epoch 36 (rank = 6, local_rank = 2) loss = 1.3724170923233032
[694] epoch 36 (rank = 4, local_rank = 0) loss = 1.061527967453003
[695] epoch 36 (rank = 5, local_rank = 1) loss = 0.96876460313797
[697] epoch 36 (rank = 7, local_rank = 3) loss = 0.8060566782951355
...El resultado en el nodo0 es el siguiente:
Líneas 6 a 9: cuando se ejecuta el trabajo en el nodo 0 hasta la época 35, el script de entrenamiento se ejecuta en el nodo 1 y solicita que se agregue a la tarea de entrenamiento.
Líneas 10~13: Todos los trabajadores se reinician Dado que se agregó el nodo 1, la tarea de capacitación distribuida de 2 máquinas y 8 tarjetas se ejecuta actualmente, por lo que WORLD_SIZE=8, LOCAL_WORLD_SIZE=4
Líneas 14 a 17: el rango actual de trabajos en el nodo 1 es rango 0 ~ rango 3
Líneas 18~21: punto de control de carga
Líneas 22-30: Luego, el modelo, el optimizador y la época en el punto de control continúan entrenando
...
[4100] epoch 35 (rank = 0, local_rank = 0) loss = 1.0746158361434937
[4101] epoch 35 (rank = 1, local_rank = 1) loss = 1.1712706089019775
[4103] epoch 35 (rank = 3, local_rank = 3) loss = 1.1774182319641113
[4102] epoch 35 (rank = 2, local_rank = 2) loss = 1.0898035764694214
WARNING:torch.distributed.elastic.multiprocessing.api:Sending process 4100 closing signal SIGTERM
WARNING:torch.distributed.elastic.multiprocessing.api:Sending process 4101 closing signal SIGTERM
WARNING:torch.distributed.elastic.multiprocessing.api:Sending process 4102 closing signal SIGTERM
WARNING:torch.distributed.elastic.multiprocessing.api:Sending process 4103 closing signal SIGTERM
[4164] Initializing process group with: {'MASTER_ADDR': '192.0.0.1', 'MASTER_PORT': '42913', 'WORLD_SIZE': '8', 'LOCAL_WORLD_SIZE': '4'}
[4165] Initializing process group with: {'MASTER_ADDR': '192.0.0.1', 'MASTER_PORT': '42913', 'WORLD_SIZE': '8', 'LOCAL_WORLD_SIZE': '4'}
[4162] Initializing process group with: {'MASTER_ADDR': '192.0.0.1', 'MASTER_PORT': '42913', 'WORLD_SIZE': '8', 'LOCAL_WORLD_SIZE': '4'}
[4163] Initializing process group with: {'MASTER_ADDR': '192.0.0.1', 'MASTER_PORT': '42913', 'WORLD_SIZE': '8', 'LOCAL_WORLD_SIZE': '4'}
[4162] (rank = 0, local_rank = 0) train worker starting...
[4163] (rank = 1, local_rank = 1) train worker starting...
[4164] (rank = 2, local_rank = 2) train worker starting...
[4165] (rank = 3, local_rank = 3) train worker starting...
load checkpoint from checkpoint.pt
load checkpoint from checkpoint.pt
load checkpoint from checkpoint.pt
load checkpoint from checkpoint.pt
[4165] epoch 35 (rank = 3, local_rank = 3) loss = 1.3437936305999756
[4162] epoch 35 (rank = 0, local_rank = 0) loss = 1.5693414211273193
[4163] epoch 35 (rank = 1, local_rank = 1) loss = 1.199862003326416
[4164] epoch 35 (rank = 2, local_rank = 2) loss = 1.0465545654296875
[4163] epoch 36 (rank = 1, local_rank = 1) loss = 0.9741991758346558
[4162] epoch 36 (rank = 0, local_rank = 0) loss = 1.3609280586242676
[4164] epoch 36 (rank = 2, local_rank = 2) loss = 0.9585908055305481
[4165] epoch 36 (rank = 3, local_rank = 3) loss = 0.9169824123382568
...Este artículo es solo para uso académico, si hay alguna infracción, comuníquese para eliminar el artículo.
Descarga y estudio de productos secos
Respuesta entre bastidores: material didáctico de la Universitat Autònoma de Barcelona , puede descargar el material didáctico de alta calidad 3D Vison acumulado por universidades extranjeras durante varios años
Respuesta de fondo: libros de visión por computadora , puede descargar el pdf de libros clásicos en el campo de la visión 3D
Respuesta entre bastidores: cursos de visión 3D, puede aprender excelentes cursos en el campo de la visión 3D
Sitio web oficial del taller de visión artificial: 3dcver.com
1. Tecnología de fusión de datos multisensor para conducción autónoma
2. ¡Una ruta de aprendizaje completa para la detección de objetivos de nube de puntos 3D en el campo de la conducción autónoma! (Monomodal + multimodal/datos + código)
3. Comprender a fondo la reconstrucción visual en 3D: análisis de principios, explicación del código y optimización y mejora
4. El primer curso de procesamiento de nubes de puntos doméstico para combate a nivel industrial
5. Visión láser - Clasificación del algoritmo SLAM de fusión IMU-GPS
y
explicación
del código Principio del algoritmo clave SLAM láser para interiores y exteriores, código y combate real (cartógrafo + LOAM + LIO-SAM)
11. El despliegue real de modelos de aprendizaje profundo en la conducción autónoma
12. Modelo de cámara y calibración (monocular + binocular + ojo de pez)
13. ¡Pesado! Cuadricópteros: algoritmos y práctica
14. ROS2 desde el inicio hasta el dominio: teoría y práctica
15. El primer tutorial de detección de defectos 3D en China: teoría, código fuente y combate real
¡Pesado! Taller de Visión por Computador - Se ha establecido un Grupo de Intercambio de Aprendizaje
Escanee el código para agregar un asistente de WeChat, y puede solicitar unirse al taller de visión 3D: grupo de intercambio WeChat de redacción y envío de artículos académicos, que tiene como objetivo intercambiar asuntos de redacción y envío, como conferencias principales, revistas principales, SCI e EI.
Al mismo tiempo , también puede solicitar unirse a nuestro grupo de intercambio de dirección de subdivisión. En la actualidad, hay principalmente aprendizaje de código fuente de la serie ORB-SLAM, visión 3D , CV y aprendizaje profundo , SLAM , reconstrucción 3D , posprocesamiento de nubes de puntos , conducción automática, introducción de CV, medición 3D, VR / AR, reconocimiento facial 3D, imágenes médicas, detección de defectos, reidentificación de peatones, seguimiento de objetivos, aterrizaje visual de productos, competencia visual, reconocimiento de matrículas, selección de hardware, estimación de profundidad, intercambios académicos , intercambios de búsqueda de empleo y otros grupos de WeChat, escanee la siguiente cuenta de WeChat más el grupo, comentarios: "dirección de investigación + escuela/empresa + apodo", por ejemplo: "visión 3D + Universidad Jiaotong de Shanghái + Jingjing". Comente de acuerdo con el formato, de lo contrario no será aprobado. Después de que la adición sea exitosa, se invitará al grupo WeChat relevante de acuerdo con la dirección de la investigación. Póngase en contacto con las presentaciones originales .

▲Presione prolongadamente para agregar un grupo de WeChat o contribuir

▲Presione prolongadamente para seguir la cuenta oficial
Visión 3D desde la entrada hasta el planeta del conocimiento competente : cursos de video para el campo de la visión 3D (serie de reconstrucción 3D , serie de nube de puntos 3D, serie de luz estructurada , calibración mano-ojo, calibración de cámara , láser/visión SLAM, conducción automática, etc. ) , resumen de puntos de conocimiento, entrada y ruta de aprendizaje avanzado, el último papel compartido y respuesta a preguntas para un cultivo en profundidad, y orientación técnica de ingenieros de algoritmos de varias fábricas grandes. Al mismo tiempo, Planet cooperará con empresas conocidas para publicar posiciones de desarrollo de algoritmos relacionados con la visión 3D e información de acoplamiento de proyectos, creando un área de reunión para fanáticos acérrimos que integra tecnología y empleo. Casi 4,000 miembros de Planet hacen progresos comunes y conocimiento para crear un mejor mundo de IA.
Aprenda la tecnología central de la visión 3D, escanee y vea la introducción, reembolso incondicional dentro de los 3 días

Hay materiales tutoriales de alta calidad en el círculo, que pueden responder preguntas y ayudarlo a resolver problemas de manera eficiente
Lo encuentro útil, por favor dale me gusta y mira ~