contenido
4. Comparación con bases de datos relacionales tradicionales
5. Comparación con otros componentes de big data
2. Crea una tabla de particiones
8. Eliminar una sola partición
9. Agrega múltiples particiones
10. Eliminar varias particiones
13. Modificar el nombre de la columna
14. Particionamiento en varias columnas
2. Agregar una nueva partición
Una serie de artículos sobre cómo empezar con big data
Aquí hay una breve introducción a algunos sustantivos comunes de Kudu, una estructura simple y algunas declaraciones de uso común. En cuanto a la introducción más detallada de seguimiento, este componente se presentará en detalle por separado, y puede seguir el blog para leer el seguimiento.
1. Concepto

Kudu es un nuevo tipo de sistema de almacenamiento en columnas de código abierto de Cloudera. Es miembro del ecosistema Apache Hadoop. Está diseñado para analizar rápidamente los datos que cambian rápidamente y llenar el vacío de la capa de almacenamiento Hadoop anterior.
Kudu proporciona funciones y modelos de datos que están más cerca de RDBMS, proporcionando una estructura de almacenamiento similar a las bases de datos relacionales para almacenar datos, lo que permite a los usuarios insertar, actualizar y eliminar datos de la misma manera que las bases de datos relacionales.
Kudu es solo una capa de almacenamiento, no almacena datos, sino que se basa en motores de procesamiento Hadoop externos (MapReduce, Spark, Impala). Kudu almacena datos en el sistema de archivos subyacente de Linux en su propio formato de almacenamiento en columnas.
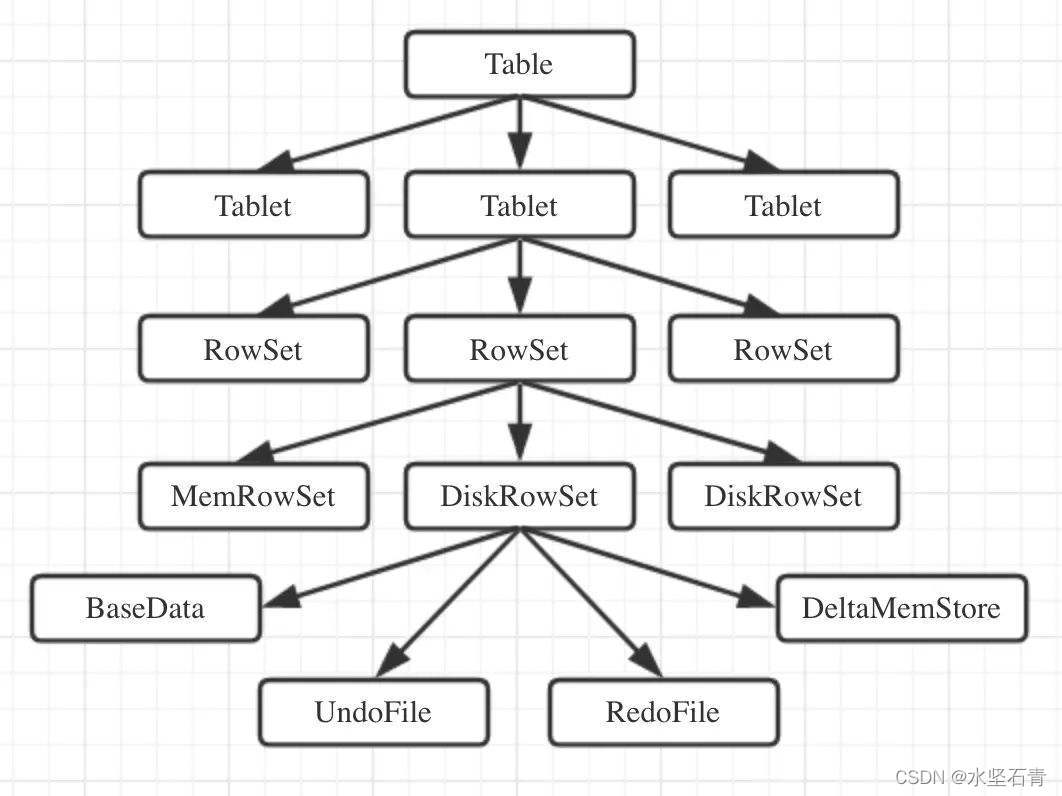
El núcleo de Kudu es un motor de almacenamiento basado en tablas. Kudu almacena su propia información de metadatos (sobre la tabla) y los datos del usuario, almacenados en la Tableta.
Kudu tiene Upsert para actualizar datos, similar a Merge de Oracle.
2. Arquitectura

Al igual que HDFS y HBase, Kudu utiliza un solo nodo maestro, que administra los metadatos del clúster, y cualquier cantidad de nodos de Tablet Server (compárese con la función RegionServer en HBase) para almacenar los datos reales. Se pueden implementar múltiples nodos maestros para mejorar la tolerancia a fallas. Los datos de una tabla Table se dividen en una o más Tabletas, que se implementan en Tablet Server para proporcionar servicios de lectura y escritura de datos.
1. Servidor maestro
El líder del clúster de Kudu puede tener varios servidores maestros para mejorar la tolerancia a fallas del clúster, pero solo un servidor maestro proporciona servicios externos y es responsable de administrar el clúster y administrar los metadatos.
2. Servidor de tabletas
Puede haber cualquier número de hermanos menores en el grupo Kudu, responsables de almacenar datos y leer y escribir datos. Las tabletas se almacenan en el servidor de tabletas. Para una tableta, solo uno de los servidores de mesa sirve como líder para proporcionar servicios de lectura y escritura, mientras que los otros servidores de mesa son todos seguidores y solo brindan servicios de lectura.
3. Mesa
Tabla: el concepto de tabla en Kudu incluye los conceptos de esquema y clave principal. La tabla en Kudu se dividirá horizontalmente en varios fragmentos de tableta y se almacenará en el servidor de tableta.
4. Tableta
Una tableta es un segmento continuo de una tabla, una tableta es una partición horizontal de una tabla, los rangos de clave principal entre tabletas no se superponen y todos los segmentos de tableta de una tabla constituyen todos los rangos de clave principal de la tabla. La tableta se almacenará de forma redundante en varios servidores de tabletas para configurar réplicas. En cualquier momento, solo un servidor de tabletas es el líder y los demás son seguidores.
3. Características
1. Importancia
1. La complejidad del análisis de big data a menudo se debe a las limitaciones del sistema de almacenamiento. Las limitaciones de Kudu son mucho más pequeñas, lo que hace que el análisis de big data sea más simple hasta cierto punto.
2. Los nuevos escenarios de aplicaciones requieren Kudu, como más y más aplicaciones que se centren en datos generados por máquinas y análisis en tiempo real.
3. Adaptarse al nuevo entorno de hardware, brindando así un mayor rendimiento y flexibilidad de aplicaciones.
2. Facilidad de uso
1. Proporcionar funciones y modelos de datos que están más cerca de RDBMS
2. Proporcionar una estructura de almacenamiento de tablas de base de datos similar a RDBMS
3. Permitir a los usuarios insertar, actualizar y eliminar datos de la misma manera que RDBMS.
3. Ventajas
Kudu también tiene la capacidad de insertar fila por fila, acceso aleatorio de baja latencia, actualización y escaneo de análisis rápido, por lo que es compatible tanto con OLAP como con OLTP Estas arquitecturas complejas que originalmente necesitaban múltiples sistemas de almacenamiento para admitir al mismo tiempo tiempo fueron reemplazados Solo hay un sistema de almacenamiento, y todos los datos se almacenan en este sistema de almacenamiento, lo que simplifica enormemente la arquitectura de big data.
4. Comparación con bases de datos relacionales tradicionales
1. Al igual que las bases de datos relacionales, las tablas de Kudu tienen una clave principal única.
2. Las funciones comunes en las bases de datos relacionales, como transacciones, claves foráneas e índices de clave no principal, actualmente no son compatibles con Kudu.
3. Kudu tiene algunas características OLAP y OLTP, pero carece de soporte para transacciones persistentes, consistencia, aislamiento y atomicidad entre filas.
4. Kudu se puede clasificar como una base de datos de tipo Hybrid Transaction/Analytic Processing (HTAP).
5.Kudu admite la recuperación rápida de claves primarias y puede analizar datos mientras los datos se ingresan continuamente, y el rendimiento de la base de datos OLAP generalmente no es muy bueno en este escenario.
6. La garantía de persistencia de Kudu es más parecida a la de una base de datos OLTP.
7. La capacidad de quórum de Kudu puede implementar un mecanismo llamado Fractured Mirrors, es decir, uno o dos nodos usan almacenamiento de filas y los otros nodos usan almacenamiento de columnas. De esta forma, se pueden ejecutar consultas de tipo OLTP en los nodos del almacén de filas y consultas OLAP en los nodos del almacén de columnas, mezclando las dos cargas de trabajo.
5. Comparación con otros componentes de big data
1. HDFS es bueno para el escaneo a gran escala, pero no para la lectura aleatoria. Estrictamente hablando, no admite la escritura aleatoria. Puede simular la escritura aleatoria mediante la fusión, pero el costo es muy alto.
2. HBase y Cassandra son buenos en el acceso aleatorio, leyendo y modificando datos aleatoriamente, pero tienen un rendimiento deficiente en el escaneo a gran escala.
3. El objetivo de Kudu es duplicar el rendimiento de escaneo de HDFS, mientras que el rendimiento de lectura aleatoria está conectado a HBase y Cassandra. El objetivo real es lograr una latencia de lectura/escritura aleatoria en SSD dentro de 1 ms.
Cuatro oraciones de uso común
1. Construye una mesa
Kudu requiere una clave principal para crear una tabla y la clave principal no puede estar vacía.
1. Construye una mesa común
create table test.test1 (
date_timekey string not null,
username string null,
product_qty string null
)
stored as kudu2. Crea una tabla de particiones
create table test.test1 (
date_timekey string not null,
username string null,
product_qty string null,
primary key (date_timekey)
)
partition by range (date_timekey) (value='20220417')
stored as kudu
2. Eliminar la tabla
drop table if exists test.test1;
3. Consulta de datos
Nota: Al consultar datos, es mejor traer las columnas a consultar, lo que puede reducir la cantidad de columnas de consulta y reducir la carga de la consulta. Al escribir SQL, el uso de las columnas especificadas ejerce menos presión sobre el clúster de big data y hace que el sistema sea más sólido.
select date_timekey,username from test.test1
4. Agregar datos
Nota: Antes de insertar datos en una tabla particionada, primero debe crear una partición.
insert into test.test1 (date_timekey,username)values('20200330','shuijianshiqing');
Nota: La clave principal de los datos agregados no puede estar vacía, de lo contrario, los datos no ingresarán.
insert into test.test1 (date_timekey,b)values(null,'shuijianshiqing');
5. Actualizar datos
upsert into test.test1 (date_timekey,username)values('20200330','shuijianshiqing');
6. Eliminar datos
Nota: Al eliminar datos, no puede usar la eliminación de alias, como test.test t, y luego la condición es t.date_timekey, por lo que los datos no se pueden eliminar.
delete from test.test1 where date_timekey='20200328';
7. Agrega una sola partición
alter table test.test1 add range partition value='20200325';
8. Eliminar una sola partición
alter table test.test1 drop range partition value='20200325';
9. Agrega múltiples particiones
alter table test.test1 add range partition '20200327'<=values<'20200331';
10. Eliminar varias particiones
alter table test.test1 drop range partition '20200327'<=values<'20200331';11. Nueva columna
alter table test.test1 add columns(column_new string);
12. Eliminar columnas
alter table test.test1 drop column column_new;
13. Modificar el nombre de la columna
nombredeusuario es el nombre antiguo de la columna, nombreusuario_nuevo es el nombre de la nueva columna,
alter table test.test1 change column username username_new string;
14. Particionamiento en varias columnas
1. Crear una nueva tabla
drop table if exists test.test2;
create table test.test2 (
id String not null,
date_timekey String not null,
hour_timekey String not null,
username STRING,
password STRING,
interface_time String,
primary key (id,date_timekey,hour_timekey)
)
partition by range (date_timekey,hour_timekey) (partition value=('20200601','20200601 0730'))
stored as kudu
2. Agregar una nueva partición
alter table test.test2_kudu add range partition value=('20200601','20200601 0830');
3. Eliminar la partición
alter table test.test2_kudu drop range partition value=('20200601','20200601 0830');Cinco, la lengua vernácula
Kudu es un motor de almacenamiento, similar a RDBMS, que puede agregar, eliminar, modificar y consultar, lo que hace que el análisis de big data sea más conveniente. Su almacenamiento no está basado en Hadoop, pero tiene un sistema independiente en Linux. En cuanto al contenido más detallado de la lectura y escritura de Kudu, se presentará en detalle más adelante.
6. Otros
Sopa de pollo: el mundo tiene más miedo a la palabra seriedad. ¡Estas dos palabras valen miles de dólares y miles de dólares no se pueden cambiar!
Una serie de artículos sobre cómo empezar con big data
1. Introducción a Big Data - ¿Qué es Big Data?
2. Introducción a Big Data: descripción general de la tecnología de Big Data (1)
3. Introducción a Big Data: descripción general de la tecnología de Big Data (2)
4. Introducción a los grandes datos: comprenda Hadoop en tres minutos
5. Introducción a los grandes datos: cinco minutos para comprender HDFS
6. Introducción a los grandes datos: cinco minutos para comprender Hive
¡No te pierdas a los chicos guapos y las bellezas que pasan, presta atención y disfruta de la cima de la vida! ! !