Haga clic en la tarjeta a continuación para seguir la cuenta pública " CVer "
Productos secos pesados AI/CV, entregados lo antes posible
Reimpreso de: Instituto de Investigación Jingdong
Este trabajo fue realizado conjuntamente por JD Discovery Research Institute y la Universidad de Sydney, ha sido aceptado por CVPR 2022 y se le ha dado la oportunidad de presentar una presentación oral. En este documento, proponemos un método que utiliza un decodificador de "vistazo" recursivo para explotar la información de la región de interés para acelerar de manera efectiva los algoritmos de detección de objetos basados en transformadores. Específicamente, tratamos de imitar el proceso de percepción visual humana y obtener información aproximada sobre la posición del objeto con la ayuda de un comportamiento similar al de una "mirada", y luego, a través de un proceso recursivo de varias etapas, ayudamos al modelo a enfocarse gradualmente en el área correcta del objeto. , De esta forma, se reduce en gran medida la dificultad del modelo para la detección de objetivos, y se reduce el periodo de entrenamiento necesario para ello. En experimentos con grandes conjuntos de datos, se demuestra que nuestro método reduce el período de entrenamiento requerido para los modelos actuales de última generación en alrededor de un 30 % sin degradar la precisión de la detección de objetos. Con el mismo período de entrenamiento, nuestro método puede mejorar aún más la precisión de detección en aproximadamente un 5 %.


Papel: https://arxiv.org/abs/2112.04632
Código: https://github.com/zhechen/Deformable-DETR-REGO
01
Antecedentes de la investigación
Recientemente, los algoritmos de detección de objetos basados en transformadores se han vuelto populares en el mundo académico. Este tipo de algoritmo puede generar directamente la ubicación detallada y la información de categoría de los objetos que aparecen en la imagen al modelar la información visual global. A diferencia de los algoritmos de detección de objetivos tradicionales, este tipo de algoritmo evita un proceso de posprocesamiento adicional y puede realizar la detección de objetivos con alta eficiencia y alta calidad.
Sin embargo, un inconveniente más importante de tales algoritmos es que a menudo requieren ciclos de entrenamiento extremadamente largos para optimizar los parámetros del modelo y garantizar que pueda enfocarse correctamente en las regiones del objeto. Específicamente, los algoritmos tradicionales generalmente requieren 12 o 24 ciclos de entrenamiento para obtener parámetros de modelo de alta calidad, mientras que el algoritmo de detección de objetivos basado en transformadores más primitivo requiere 500 ciclos de entrenamiento para obtener parámetros de modelo de la misma calidad. Esta deficiencia dificulta en gran medida el desarrollo y la aplicación de dichos algoritmos.
Después de la investigación, encontramos que algunos trabajos recientes intentan abordar este problema optimizando la representación de características o mejorando la estructura del modelo. En general, las mejoras actuales tienden a ayudar a los detectores de objetos basados en Transformer a encontrar las regiones de objetos correctas más rápido durante el entrenamiento, lo que reduce el proceso de entrenamiento general. Estas obras palian en cierta medida este problema.
A diferencia de los métodos actuales, encontramos que la información sobre las regiones de interés (región de interés) que pueden contener objetos puede ayudar de manera directa, simple y efectiva a acortar el período de capacitación requerido. Específicamente, tratamos de imitar el proceso de percepción visual humana y obtener información aproximada sobre la posición del objeto con la ayuda de un comportamiento similar al de una "mirada", y luego, a través de un proceso recursivo de varias etapas, ayudamos al modelo a enfocarse gradualmente en el área correcta del objeto. , De esta forma, se reduce en gran medida la dificultad del modelo para la detección de objetivos, y se reduce el periodo de entrenamiento necesario para ello. Después de esto, en este documento, proponemos un método que utiliza un decodificador de "vistazo" recursivo para explotar la información de la región de interés para acelerar de manera efectiva los algoritmos de detección de objetos basados en transformadores.
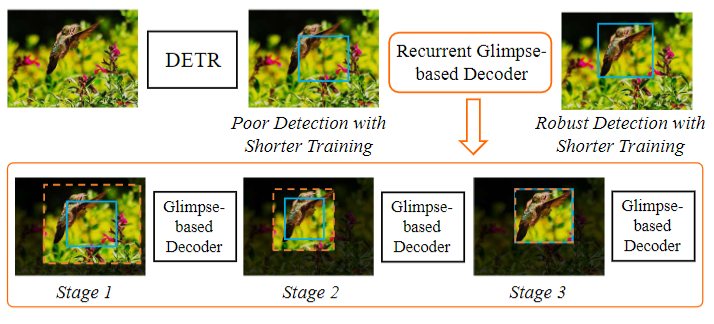
Figura 1 Representación conceptual del Decodificador basado en Vislumbres Recurrentes (REGO).
02
decodificador recursivo de "vistazo"
2.1 Descripción general del algoritmo
El decodificador recursivo de "vistazo" se implementa principalmente expandiendo la región de interés del objeto y extrayendo la información visual en él como un "vistazo". Luego, introducimos un decodificador visual para interpretar la información de "vistazo" obtenida, que puede ayudar a los detectores de objetos basados en Transformer a capturar regiones de objetos de manera más correcta. En la implementación, utilizamos una estrategia de procesamiento multietapa recursivo para mejorar de manera gradual y constante la salida del detector. En cada etapa recursiva, hacemos un "vistazo" y decodificamos. La información decodificada se combina con la información visual del algoritmo original de detección de objetos del Transformador, lo que da como resultado una mejor representación de la información visual y resultados de detección de objetos. La información visual final y los resultados de detección obtenidos en cada etapa se envían recursivamente a la siguiente etapa de procesamiento. La Figura 2 muestra el flujo de operación específico.
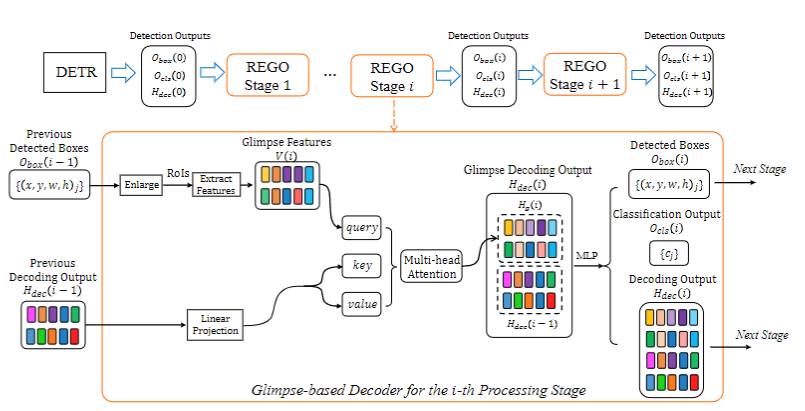
Figura 2. El diagrama de marco de procesamiento de cada etapa del decodificador de "vistazo" recursivo (REGO)
2.2 Detalles del algoritmo
En cada etapa, usamos la información de decodificación visual de la etapa anterior y sus resultados de predicción de cuadros de detección como entrada del algoritmo, y luego generamos la información de decodificación visual y los resultados de detección mejorados por la información de "vistazo" de esta etapa, incluida la resultados de reconocimiento de categorías de objetos y sus resultados de detección Resultados de predicción de cajas. Vale la pena mencionar que usamos la información visual y los resultados de predicción del marco de detección del algoritmo original de detección de objetivos basado en el transformador como entrada de la primera etapa, y las etapas posteriores pueden realizar recursivamente operaciones de decodificación y mejora de "vistazo".
En una etapa, primero extraemos información de "vistazo". El proceso de extracción se obtiene principalmente expandiendo el marco de detección predicho en la etapa anterior y luego extrayendo las características visuales en él. Asumiendo que representa la característica visual y representa la información de "vistazo" extraída, usamos la siguiente operación:
(1)
Entre ellos, representa la operación de extracción de características visuales, representa la operación de expansión del marco de detección y α representa el coeficiente de expansión utilizado en esta etapa.
A partir de la información de "vistazo" obtenida de la ecuación (1), usamos un decodificador, definido como , para decodificarla en una representación que se puede usar para mejorar la detección en función de la información de la etapa anterior:
(2)
Finalmente, combinamos el resultado de decodificación de "vistazo" y la información de decodificación visual de la etapa de propuesta para obtener la información de decodificación visual de esta etapa:
(3)
Después de obtener la información de decodificación visual en esta etapa, podemos dejar que la red neuronal genere predicciones sobre la posición del cuadro de detección de la máquina de categoría de objeto en función de esta información.
2.3 Resultados experimentales
En experimentos con grandes conjuntos de datos, se puede demostrar que nuestro método reduce el período de entrenamiento requerido por los modelos actuales de última generación en alrededor de un 30 % sin degradar la precisión de la detección de objetos. Con el mismo período de entrenamiento, nuestro método puede mejorar aún más la precisión de detección en aproximadamente un 5 %. Estos resultados demuestran la eficiencia de nuestro método propuesto en algoritmos de detección de objetos basados en transformadores y también demuestran que nuestro método representa el estado del arte en el desarrollo de este campo.
Específicamente, primero podemos mejorar la velocidad de convergencia del algoritmo original de detección de objetos basado en Transformer. La Figura 3 muestra el efecto de convergencia de nuestro método (línea roja) aplicado al detector de Transformador existente (línea gris).El eje horizontal representa la duración del período de entrenamiento y el eje vertical representa el efecto de detección. Se puede ver que nuestro método puede obtener un mejor efecto de detección que el resultado de convergencia de 50 ciclos del método original utilizando 36 ciclos, lo que reduce en gran medida el período de entrenamiento.
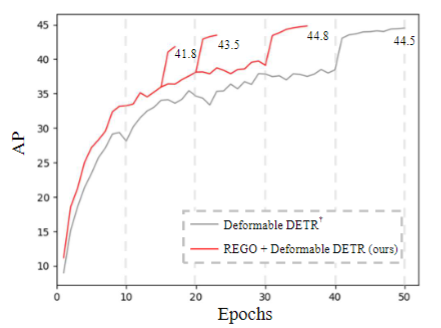
Figura 3 La mejora en la velocidad de convergencia de nuestro método (REGO) en relación con la línea base
Mostramos una comparación más detallada del rendimiento experimental en la detección de objetos en la Figura 4. Comparamos el rendimiento de detección del detector de transformador original mejorado (DETR) y el detector de transformador de última generación (DETR deformable) con y sin nuestro método propuesto (REGO). A partir de los resultados experimentales, podemos ver que nuestro método puede ayudar al método original a obtener resultados comparables al ciclo de entrenamiento original de 50 vueltas en un ciclo de entrenamiento de 36 vueltas. Al mismo tiempo, nuestro método también puede lograr una mejora relativa del 5% en la precisión de detección en 50 ciclos de entrenamiento. Al mismo tiempo, nuestro método solo introduce menos complejidad computacional y cantidad de parámetros.
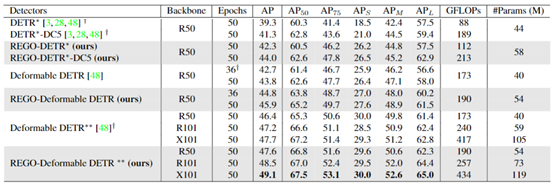
Tabla 1. Comparación del rendimiento de detección del algoritmo de detección de objetivos basado en transformadores y nuestro método (REGO)
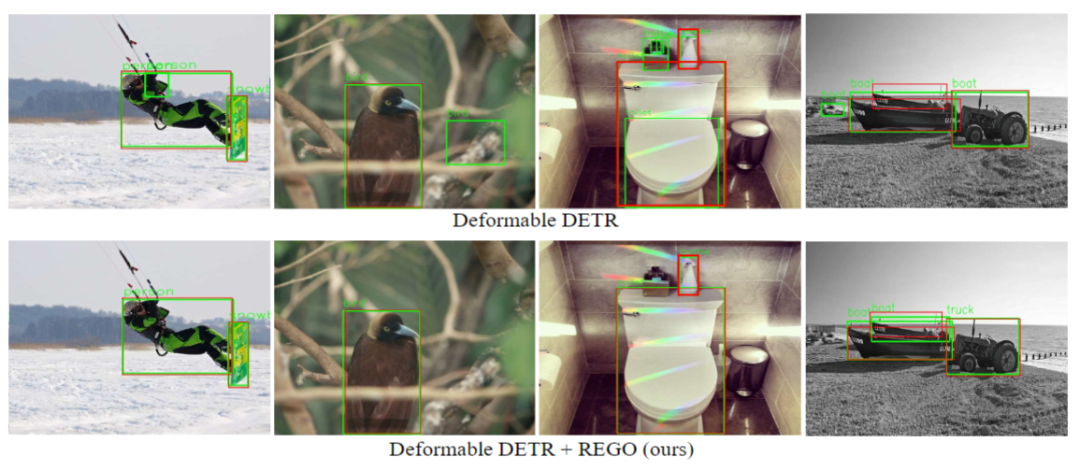
Fig. 4 Visualización de los resultados de detección de nuestro método (REGO) y el método original (Deformable DETR)
Mostramos además la visualización de los resultados de detección de nuestro método (REGO) y el método original (DETR deformable) en la Figura 4. Podemos ver que el método original todavía produce algunas detecciones falsas, y nuestro método puede ayudar a identificar y excluir estas detecciones falsas de manera efectiva.
03
En conclusión
En este documento, proponemos un método que utiliza un decodificador de "vistazo" recursivo para explotar la información de la región de interés para acelerar de manera efectiva los algoritmos de detección de objetos basados en transformadores. Tomamos prestado con éxito el concepto de "mirada" de la percepción visual humana e implementamos un eficiente proceso de decodificación de "mirada" recursiva de varias etapas, que ayuda al modelo a enfocarse gradualmente en el área correcta del objeto, reduciendo así en mayor medida. modelo para la detección de objetos reduce el período de entrenamiento que necesita. En cada etapa, realizamos la "mirada" expandiendo la región de interés del objeto y extrayendo la información visual en ella, y luego introducimos un decodificador visual para interpretar la información de "mirada" obtenida. Generamos resultados de detección de objetos para esta etapa en función de la salida del decodificador de visión, que luego se envía recursivamente a la siguiente etapa de procesamiento, lo que resulta en mejores resultados de detección de objetos. Los resultados de los experimentos en grandes conjuntos de datos demuestran la eficiencia de nuestro método propuesto en los algoritmos de detección de objetos basados en transformadores y también muestran que nuestro método representa los logros más avanzados en el campo.
referencias
[1] Chen, Zhe, Jing Zhang y Dacheng Tao. "Decodificador basado en Glimpse recurrente para detección con transformador". En CVPR, 2022.
[2] Carion, Nicolás, Francisco Massa, Gabriel Synnaeve, Nicolás Usunier, Alexander Kirillov y Sergey Zagoruyko. "Detección de objetos de extremo a extremo con transformadores". En ECCV, 2020.
[3] Meng, Depu, Xiaokang Chen, Zejia Fan, Gang Zeng, Houqiang Li, Yuhui Yuan, Lei Sun y Jingdong Wang. "Desactivación condicional para la convergencia de entrenamiento rápido". En ICCV. 2021.
[4] Zhu, Xizhou, Weijie Su, Lewei Lu, Bin Li, Xiaogang Wang y Jifeng Dai. "DETR deformable: transformadores deformables para la detección de objetos de extremo a extremo". En ICLR. 2020.
ICCV y CVPR 2021 Descarga de papel y código
Respuesta entre bastidores: CVPR2021, puede descargar los documentos de CVPR 2021 y la colección de documentos de código abierto
Respuesta de antecedentes: ICCV2021, puede descargar los documentos de ICCV 2021 y la colección de documentos de código abierto
Respuesta de fondo: revisión de Transformer, puede descargar las últimas 3 revisiones de Transformer en PDF
目标检测和Transformer交流群成立
扫描下方二维码,或者添加微信:CVer6666,即可添加CVer小助手微信,便可申请加入CVer-目标检测或者Transformer 微信交流群。另外其他垂直方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch、TensorFlow和Transformer等。
一定要备注:研究方向+地点+学校/公司+昵称(如目标检测或者Transformer+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群
▲扫码或加微信: CVer6666,进交流群
CVer学术交流群(知识星球)来了!想要了解最新最快最好的CV/DL/ML论文速递、优质开源项目、学习教程和实战训练等资料,欢迎扫描下方二维码,加入CVer学术交流群,已汇集数千人!
▲扫码进群
▲点击上方卡片,关注CVer公众号
整理不易,请点赞和在看