Un poco de mierda escrita en el frente:
¡Para los carnívoros, comer carne puede ser abrumador! Especialmente para la carne a la parrilla, ver cómo se cocinan lentamente los trozos de carne y escuchar el sonido de "zizi" en la parrilla, este tipo de anticipación no puede traerla ningún otro alimento. Si el postre es "feliz a primera vista", entonces la carne "nunca se cansa de ella".

Para beneficiar el "control de barbacoa", hoy usaré Python para rastrear los datos de los restaurantes de barbacoa de una ciudad y elegir el más adecuado.
Listo para trabajar
medioambiente
- pitón 3.6
- pycharm
- solicitudes >>> enviar solicitudes pip instalar solicitudes
- csv >>> guardar datos
Comprender las ideas más básicas de los reptiles.
1. Análisis de la fuente de datos
- ¿Determinar qué contenido rastreamos?
Rastrear datos del almacén
Descubre de dónde vienen estas
cosas- enviar solicitud, enviar solicitud de paquetes encontrados
- Obtenga datos, en función de los datos de respuesta que le devuelva el servidor
- Analizar los datos, extraer los datos de contenido que queremos
- guardar datos, guardar en archivo csv
- Rastreo de varias páginas, cambios según los parámetros de la dirección URL
proceso de implementación de código
- Enviar petición
url = 'https://apimobile.某tuan.com/group/v4/poi/pcsearch/70'
data = {
'uuid': '6e481fe03995425389b9.1630752137.1.0.0',
'userid': '266252179',
'limit': '32',
'offset': 32,
'cateId': '-1',
'q': '烤肉',
'token': '4MJy5kaiY_0MoirG34NJTcVUbz0AAAAAkQ4AAF4NOv8TNNdNqymsxWRtJVUW4NjQFW35_twZkd49gZqFzL1IOHxnL0s4hB03zfr3Pg',
}
# 请求头 都是可以从开发者工具里面直接复制粘贴
# ser-Agent: 浏览器的基本信息
headers = {
'Referer': 'https://chs.某tuan.com/',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/93.0.4577.63 Safari/537.36'
}
# 发送请求
response = requests.get(url=url, params=data, headers=headers)
200 indica que la solicitud fue exitosa y el código de estado es 403. No tiene derechos de acceso
2. Obtener datos
print(response.json())
3. Analizar los datos
result = response.json()['data']['searchResult']
# [] 列表 把里面每个元素都提取出来 for循环遍历
for index in result:
# pprint.pprint(index)
# f'{}' 字符串格式化
index_url = f'https://www.某tuan.com/meishi/{index["id"]}/'
# ctrl + D
dit = {
'店铺名称': index['title'],
'店铺评分': index['avgscore'],
'评论数量': index['comments'],
'人均消费': index['avgprice'],
'所在商圈': index['areaname'],
'店铺类型': index['backCateName'],
'详情页': index_url,
}
csv_writer.writerow(dit)
print(dit)
4. Guardar datos
f = open('烤肉数据.csv', mode='a', encoding='utf-8', newline='')
csv_writer = csv.DictWriter(f, fieldnames=[
'店铺名称',
'店铺评分',
'评论数量',
'人均消费',
'所在商圈',
'店铺类型',
'详情页',
])
csv_writer.writeheader() # 写入表头
5. Pasa la página
for page in range(0, 1025, 32):
url = 'https://apimobile.某tuan.com/group/v4/poi/pcsearch/70'
data = {
'uuid': '6e481fe03995425389b9.1630752137.1.0.0',
'userid': '266252179',
'limit': '32',
'offset': page,
'cateId': '-1',
'q': '烤肉',
'token': '4MJy5kaiY_0MoirG34NJTcVUbz0AAAAAkQ4AAF4NOv8TNNdNqymsxWRtJVUW4NjQFW35_twZkd49gZqFzL1IOHxnL0s4hB03zfr3Pg',
}
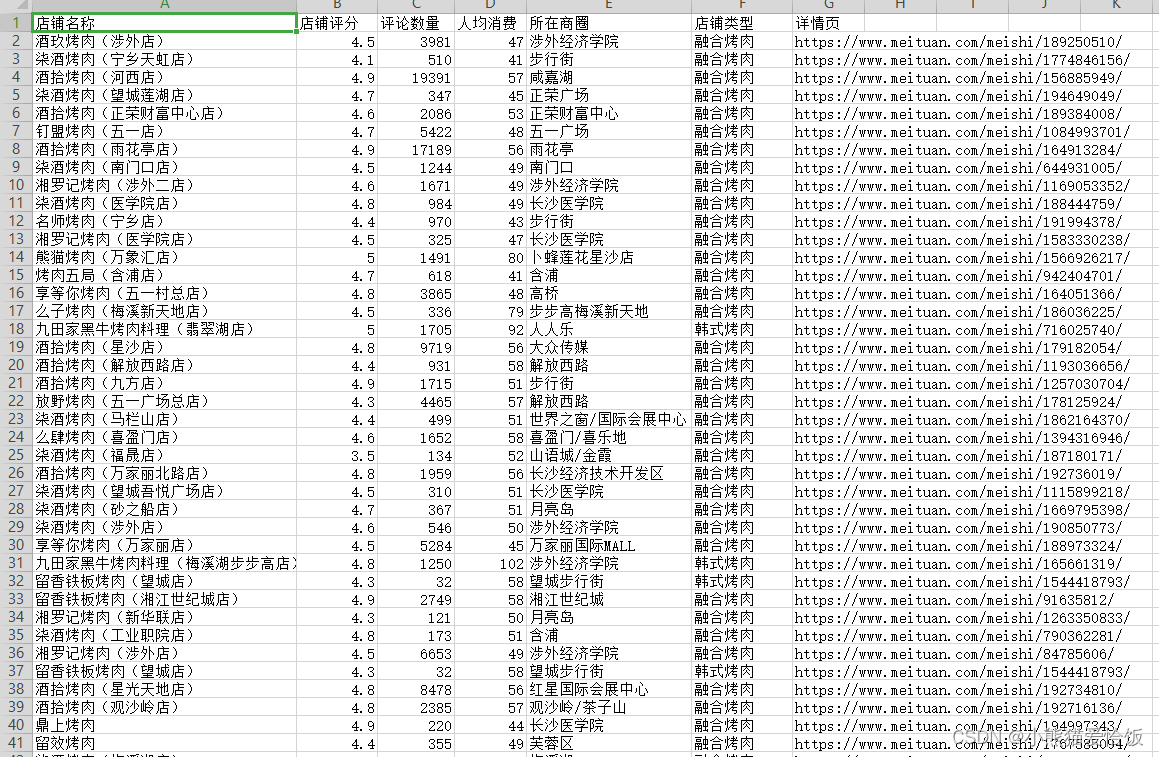
Ejecute el código para obtener los datos.

Se puede agregar más información al grupo Q, haga clic aquí
código completo
f = open('烤肉数据1.csv', mode='a', encoding='utf-8', newline='')
csv_writer = csv.DictWriter(f, fieldnames=[
'店铺名称',
'店铺评分',
'评论数量',
'人均消费',
'所在商圈',
'店铺类型',
'详情页',
])
csv_writer.writeheader() # 写入表头
for page in range(0, 1025, 32):
url = 'https://apimobile.某tuan.com/group/v4/poi/pcsearch/70'
data = {
'uuid': '6e481fe03995425389b9.1630752137.1.0.0',
'userid': '266252179',
'limit': '32',
'offset': page,
'cateId': '-1',
'q': '烤肉',
'token': '4MJy5kaiY_0MoirG34NJTcVUbz0AAAAAkQ4AAF4NOv8TNNdNqymsxWRtJVUW4NjQFW35_twZkd49gZqFzL1IOHxnL0s4hB03zfr3Pg',
}
headers = {
'Referer': 'https://chs.某tuan.com/',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/93.0.4577.63 Safari/537.36'
}
# 发送请求
response = requests.get(url=url, params=data, headers=headers)
# 200 表示请求成功 状态码 403 你没有访问权限
result = response.json()['data']['searchResult']
# [] 列表 把里面每个元素都提取出来 for循环遍历
for index in result:
# pprint.pprint(index)
# f'{}' 字符串格式化
index_url = f'https://www.meituan.com/meishi/{index["id"]}/'
# ctrl + D
dit = {
'店铺名称': index['title'],
'店铺评分': index['avgscore'],
'评论数量': index['comments'],
'人均消费': index['avgprice'],
'所在商圈': index['areaname'],
'店铺类型': index['backCateName'],
'详情页': index_url,
}
csv_writer.writerow(dit)
print(dit)