contenido
2 Modelo matemático de optimización de Harris Eagle
2.1 Fórmula de actualización de posición
2.2 Fórmula lineal decreciente para la reducción de energía de presa
2.5 Adoptar una estrategia de envolvimiento suave de picado rápido progresivo
2.6 Adoptar una estrategia de cerco duro de picado rápido progresivo
3 implementación de código matlab
1 escrito al frente
Sé divertido primero:

En la naturaleza, el halcón de Harris usa sus agudos ojos para explorar el entorno y rastrear a sus presas. Pero en las vastas extensiones del sur de Arizona, a veces la vida no es fácil. En las áreas desérticas, a menudo lleva horas esperar, observar y rastrear presas.
Harris Hawks Optimizer (HHO) es un algoritmo metaheurístico propuesto por Heidari, Mirjalili y otros en 2019. ¡Debo decir que el profesor Mirjalili es realmente increíble! El águila de Harris, que vive principalmente en el sur de Arizona, es única porque participa en actividades cooperativas únicas de alimentación con otros miembros de la familia en el grupo, mientras que otras especies de aves rapaces suelen cazar a sus presas solas. Debido a esto, el comportamiento único de depredación de enjambres del águila de Harris es muy adecuado para ser modelado como un proceso de optimización de inteligencia de enjambres.
Para discutir cómo es un algoritmo, primero debemos ver sus ventajas: el algoritmo tiene una fuerte capacidad de búsqueda global y tiene las ventajas de que es necesario ajustar menos parámetros.

2 Modelo matemático de optimización de Harris Eagle
2.1 Fórmula de actualización de posición
Harris Hawk Optimization (HHO) es una idea de optimización basada en la población propuesta en los últimos dos años. En la fase de exploración de HHO, para simular el estado de la presa de exploración del águila de Harris, la posición individual del grupo de águilas se actualiza aleatoriamente de la siguiente manera:

Entre ellos , q , r 1, r 2, r 3 y r 4 son todos números aleatorios en [0,1], ub y lb son los límites superior e inferior del espacio de búsqueda; Xrand es una posición individual aleatoria; Xrabbit es la posición de la presa, y Xave es la posición promedio de todos los individuos dentro de una población. r3 es un factor de escala que aumenta aún más la aleatoriedad de la estrategia una vez que el valor de r4 se acerca a 1. Similar al algoritmo de optimización de ballenas , el contenido en el valor absoluto se puede considerar como la distancia relativa entre dos cuerpos; r 1 es un coeficiente de escala aleatoria, que proporciona una tendencia de diversificación para el hábitat del águila Harris y le permite explorar el espacio de características de diferentes regiones.
2.2 Fórmula lineal decreciente para la reducción de energía de presa
Al igual que otros algoritmos de inteligencia de enjambre, la transición entre las fases de exploración y desarrollo de HHO está controlada por una ecuación lineal decreciente que simula la reducción de la energía de la presa. Harris Hawk puede cambiar entre diferentes estados de acuerdo con la energía de escape de la presa (Little Rabbit). Durante el escape de la presa, su energía de escape E se reducirá considerablemente:
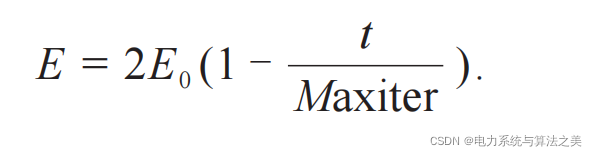
En la fórmula, E es la energía inicial de la presa, que se actualiza en el rango de (-1, 1) en cada iteración; Maxiter representa el álgebra de máxima iteración.
En vista de las diferencias en la energía de escape entre diferentes presas, el texto original hace que E0 (el valor inicial de la energía de escape) varíe aleatoriamente dentro de [-1, 1] durante el proceso de iteración del algoritmo. En cuanto al valor inicial de esta energía de escape, el texto original da la siguiente explicación:
“ Cuando el valor de E0 disminuye de 0 a -1, el conejo se está debilitando físicamente, mientras que cuando el valor de E0 aumenta de 0 a 1, significa que el conejo se está fortaleciendo. La energía de escape dinámica E tiene una tendencia decreciente durante las iteraciones. ”
Cuando E0 disminuye de 0 a -1 (E0<0), ¿está el conejo "cada vez más cansado"? De hecho, se puede entender que el escape constante de Tutu consume mucha energía, por lo que se vacía cada vez más; cuando E0 aumenta de 0 a 1 (E0>0), Tutu está en la etapa de recuperación de energía. Cuando | E |≥1, Harris Hawk busca diferentes áreas para explorar más a fondo la posición de la presa, lo que corresponde a la etapa de búsqueda global; cuando | E |<1, Harris Hawk realiza exploración local para soluciones adyacentes, por lo que Corresponde a la etapa de búsqueda local etapa de desarrollo.
Por otro lado, la etapa de desarrollo en HHO se puede dividir en las siguientes 4 estrategias según los diferentes modos de persecución de Harris Hawk:
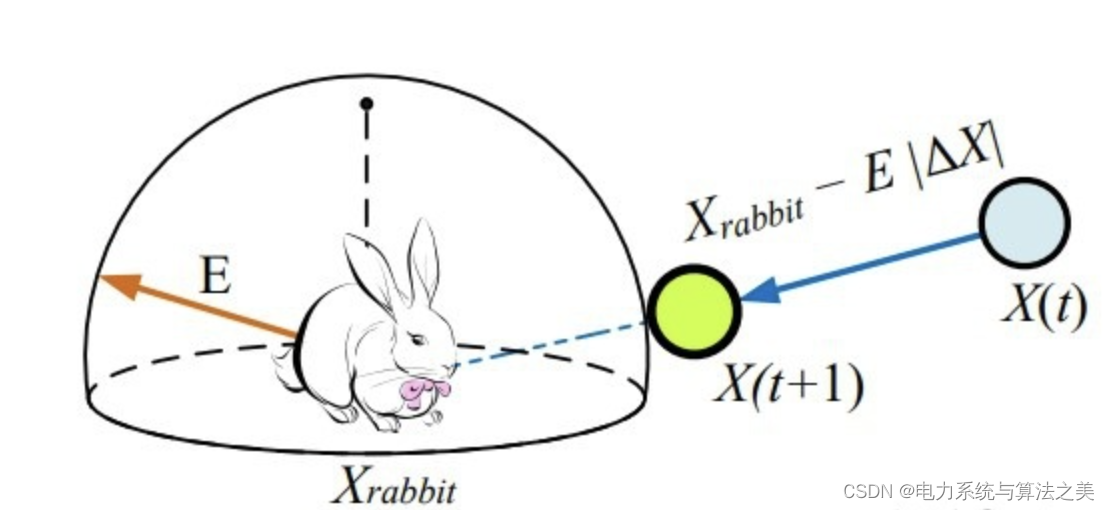
Antes de hablar de las cuatro estrategias, primero debemos mencionar la premisa del ataque. Supongamos que r es la probabilidad de escape del conejo, r < 0,5 es un escape exitoso y r ≥ 0,5 es un escape fallido. Por lo general, los halcones de Harris capturan a sus presas en un asedio duro o suave (uno suave y otro firme, hay que admirar la imaginación del autor). Este estilo de asedio significa que Harris Hawk atacará a la presa suavemente o con fuerza desde diferentes direcciones dependiendo de la energía restante de la presa. En situaciones del mundo real, los halcones de Harris se acercan cada vez más a la presa prevista y aumentan las posibilidades de matar cooperativamente mediante incursiones. Con el tiempo, la presa perderá más y más energía, momento en el que el águila Harris intensifica el proceso de asedio para capturar a la presa. En este proceso, el papel de la energía de escape E es evidente. El texto original supone que cuando | E | ≥0.5, se realiza un asedio suave; cuando | E | <0.5, se realiza un asedio duro.
2.3 Sonido envolvente suave
Se puede expresar mediante la siguiente fórmula :
![]()
Entre ellos , J es la distancia de salto del conejo durante el proceso de escape, y J =2*(1-rand).
Si el enemigo es fuerte, me retiraré, y si el enemigo está cansado, avanzaré. Se ha utilizado la gran estrategia de Lao Mao, ¡alabanza!
Tutu tiene demasiada energía, así que comencemos con gotas suaves:

2.4 Envolvente duro
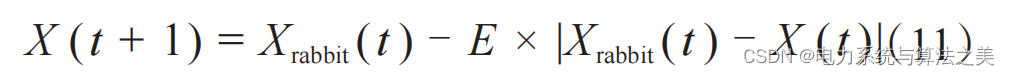
2.5 Adoptar una estrategia de envolvimiento suave de picado rápido progresivo
LF( ) es la expresión matemática del vuelo de Levi.Basado en la dimensión conocida D del grupo, la estrategia de actualización se puede expresar como:
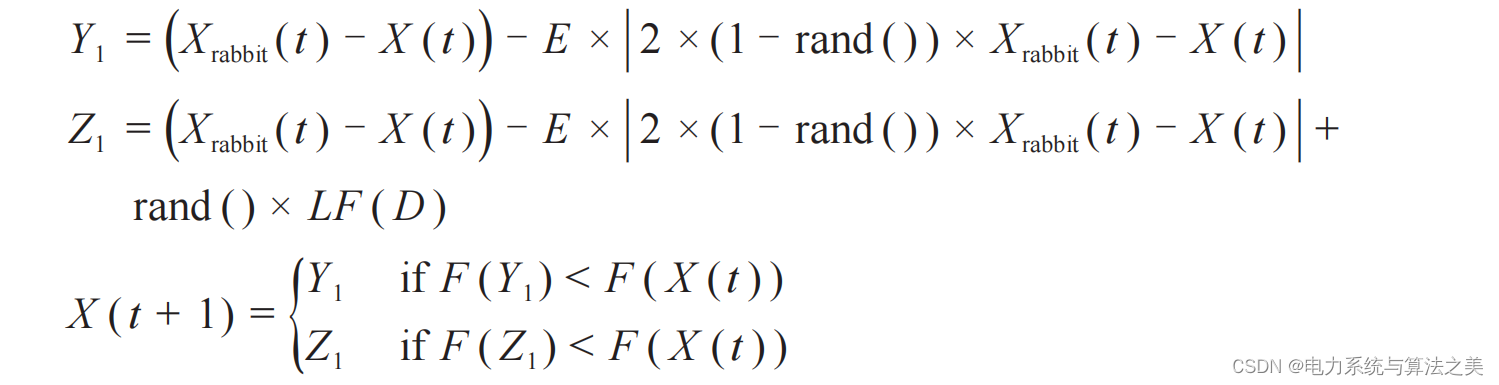
2.6 Adoptar una estrategia de cerco duro de picado rápido progresivo

3 implementación de código matlab
3.1 Código
%%===欢迎关注公众号:电力系统与算法之美===
clear
close all
clc
SearchAgents_no = 30 ; % 种群规模
dim = 10 ; % 粒子维度
Max_iter = 1000 ; % 迭代次数
ub = 5 ;
lb = -5 ;
%% 初始化猎物位置和逃逸能量
Rabbit_Location=zeros(1,dim);
Rabbit_Energy=inf;
%% 初始化种群的位置
Positions= lb + rand(SearchAgents_no,dim).*(ub-lb) ;
Convergence_curve = zeros(Max_iter,1);
%% 开始循环
for t=1:Max_iter
for i=1:size(Positions,1)
FU=Positions(i,:)>ub;FL=Positions(i,:)<lb;Positions(i,:)=(Positions(i,:).*(~(FU+FL)))+ub.*FU+lb.*FL;
fitness=sum(Positions(i,:).^2);
if fitness<Rabbit_Energy
Rabbit_Energy=fitness;
Rabbit_Location=Positions(i,:);
end
end
E1=2*(1-(t/Max_iter));
%% 鹰群的个体位置位置更新
for i=1:size(Positions,1)
E0=2*rand()-1; %-1<E0<1
Escaping_Energy=E1*(E0);
if abs(Escaping_Energy)>=1
%%
q=rand();
rand_Hawk_index = floor(SearchAgents_no*rand()+1);
X_rand = Positions(rand_Hawk_index, :);
if q<0.5
%%
Positions(i,:)=X_rand-rand()*abs(X_rand-2*rand()*Positions(i,:));
elseif q>=0.5
Positions(i,:)=(Rabbit_Location(1,:)-mean(Positions))-rand()*((ub-lb)*rand+lb);
end
elseif abs(Escaping_Energy)<1
%%
%% phase 1
r=rand();
if r>=0.5 && abs(Escaping_Energy)<0.5
Positions(i,:)=(Rabbit_Location)-Escaping_Energy*abs(Rabbit_Location-Positions(i,:));
end
if r>=0.5 && abs(Escaping_Energy)>=0.5
Jump_strength=2*(1-rand());
Positions(i,:)=(Rabbit_Location-Positions(i,:))-Escaping_Energy*abs(Jump_strength*Rabbit_Location-Positions(i,:));
end
%% phase 2
if r<0.5 && abs(Escaping_Energy)>=0.5
Jump_strength=2*(1-rand());
X1=Rabbit_Location-Escaping_Energy*abs(Jump_strength*Rabbit_Location-Positions(i,:));
if sum(X1.^2)<sum(Positions(i,:).^2)
Positions(i,:)=X1;
else
beta=1.5;
sigma=(gamma(1+beta)*sin(pi*beta/2)/(gamma((1+beta)/2)*beta*2^((beta-1)/2)))^(1/beta);
u=randn(1,dim)*sigma;v=randn(1,dim);step=u./abs(v).^(1/beta);
o1=0.01*step;
X2=Rabbit_Location-Escaping_Energy*abs(Jump_strength*Rabbit_Location-Positions(i,:))+rand(1,dim).*o1;
if (sum(X2.^2)<sum(Positions(i,:).^2))% improved move
Positions(i,:)=X2;
end
end
end
if r<0.5 && abs(Escaping_Energy)<0.5
Jump_strength=2*(1-rand());
X1=Rabbit_Location-Escaping_Energy*abs(Jump_strength*Rabbit_Location-mean(Positions));
if sum(X1.^2)<sum(Positions(i,:).^2)
Positions(i,:)=X1;
else
beta=1.5;
sigma=(gamma(1+beta)*sin(pi*beta/2)/(gamma((1+beta)/2)*beta*2^((beta-1)/2)))^(1/beta);
u=randn(1,dim)*sigma;v=randn(1,dim);step=u./abs(v).^(1/beta);
o2=0.01*step;
X2=Rabbit_Location-Escaping_Energy*abs(Jump_strength*Rabbit_Location-mean(Positions))+rand(1,dim).*o2;
if (sum(X2.^2)<sum(Positions(i,:).^2))% improved move
Positions(i,:)=X2;
end
end
end
%%
end
end
Convergence_curve(t)=Rabbit_Energy;
if mod(t,50)==0
display(['At iteration ', num2str(t), ' the best fitness is ', num2str(Rabbit_Energy)]);
end
end
figure('unit','normalize','Position',[0.3,0.35,0.4,0.35],'color',[1 1 1],'toolbar','none')
subplot(1,2,1);
x = -5:0.1:5;y=x;
L=length(x);
f=zeros(L,L);
for i=1:L
for j=1:L
f(i,j) = x(i)^8+y(j)^8;
end
end
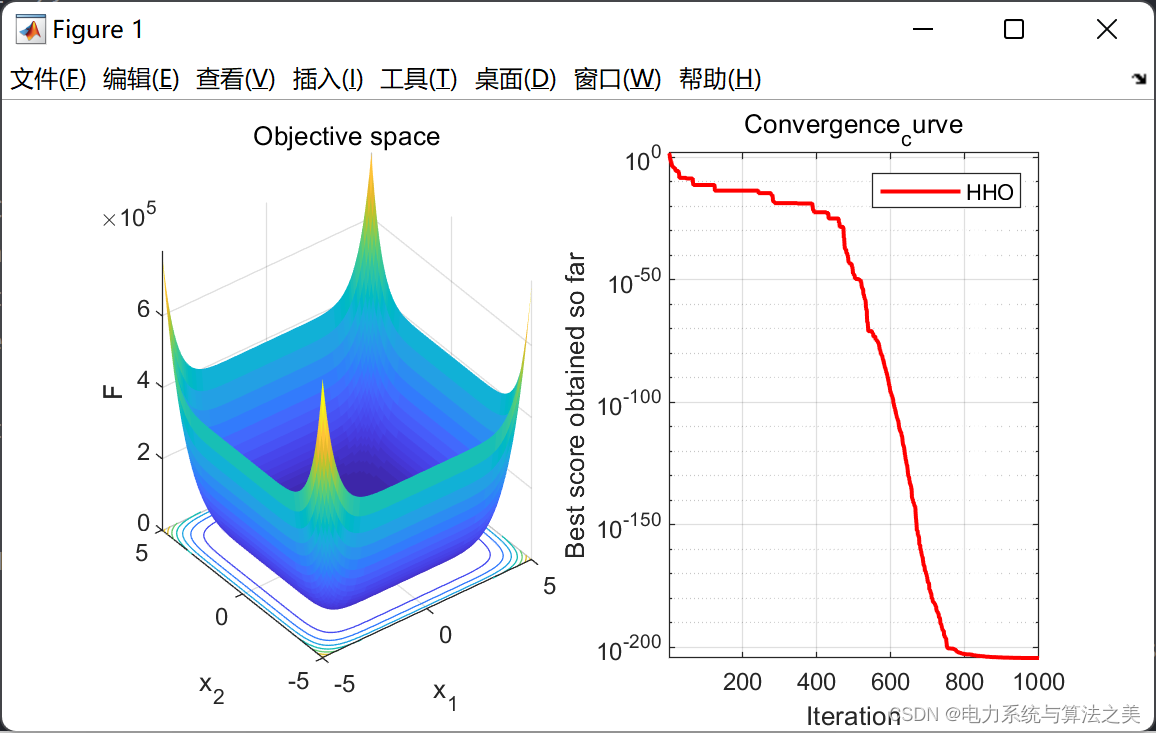
surfc(x,y,f,'LineStyle','none');
xlabel('x_1');
ylabel('x_2');
zlabel('F')
title('Objective space')
subplot(1,2,2);
semilogy(Convergence_curve,'Color','r','linewidth',1.5)
title('Convergence_curve')
xlabel('Iteration');
ylabel('Best score obtained so far');
axis tight
grid on
box on
legend('HHO')
display(['The best solution obtained by HHO is : ', num2str(Rabbit_Location)]);
display(['The best optimal value of the objective funciton found by HHO is : ', num2str(Rabbit_Energy)]);
3.2 Resultados